chain
langchain框架的基础组织单元 ,解决"如何把AI模型、工具、逻辑按顺序组合成一个可执行任务"的问题。本质上是一个调用语言模型或其他工具、并按照特定顺序处理输入输出的对象。它封装了"接收输入 -> 执行一系列操作 -> 返回输出"的完整流程。
LCEL
LCEL (LangChain Expression Language) :这是框架的声明式组合语法 ,解决"如何更优雅、更健壮地构建和调用上述链"的问题。是langchain在2023年引入的革命性特性 。它提供了一种使用管道操作符 |来声明式组合链的语法,极大地提升了代码的可读性、可维护性和内置了高级功能(如流式传输、异步、并行、重试等)。
- 核心逻辑 :LCEL让链的构建从"面向对象式的配置"转变为"函数式的流水线组装"。每一个组件(如提示词模板、模型、输出解析器)都是一个可调用的对象,通过
|连接,表示"将前一个的输出作为后一个的输入"。
基本方法
- stream: 流式返回响应的块
- invoke: 接受输入返回输出
- batch: 接受批量输入返回输出列表,核心是并发优化
batch效率
invoke我们之前已经用过,stream也简单是一个流式输出。batch的核心是并发优化,那么我们就可以简单写一个demo来印证下batch相比invoke的提效到底有多少。
Coding
构造chain
ini
# 1. 创建LCEL链
chain = (
ChatPromptTemplate.from_template("用一句话介绍{topic}")
| ChatTongyi()
| StrOutputParser()
)
# 2. 准备批量输入
topics = ["人工智能", "区块链", "量子计算", "基因编辑"]
inputs = [{"topic": topic} for topic in topics] invoke
ini
# 3. 单次调用计时 串行执行,一个个主题执行
start = time.time()
single_results = [chain.invoke({"topic": topic}) for topic in topics]
single_time = time.time() - startbatch
ini
start = time.time()
# 注意事项
# API供应商可能有批量请求限制(如每分钟请求数)
# 输入列表中的所有字典必须有相同的键结构
# 批量处理不适合有状态的操作(如带记忆的对话链)
batch_results = chain.batch(inputs) # 关键批量调用方法
batch_time = time.time() - start结果
python
# 5. 结果对比
print(f"\n=== 单次调用耗时: {single_time:.2f}s ===")
for i, res in enumerate(single_results):
print(f"{topics[i]}: {res}")
print(f"\n=== 批量调用耗时: {batch_time:.2f}s (加速 {single_time/batch_time:.1f}x) ===")
for i, res in enumerate(batch_results):
print(f"{topics[i]}: {res}")
运行结果,正印证了batch的并行优化特性,他不仅仅是简单的批处理。
stream和batch
那stream又有什么特性呢?他和普通的invoke有何区别?
stream()方法返回一个生成器(Generator),可以逐块(chunk)地产生输出。这对于大语言模型生成文本、构建聊天机器人等需要实时反馈的场景至关重要。它能将首字符响应时间(Time to First Token, TTFT)优化到最佳,极大提升用户体验。
那么stream和batch到底该怎么选呢?我们结合invoke综合对比一下。
| 特性 | invoke | batch | stream |
|---|---|---|---|
| 🧠技术原理 | 同步阻塞的单次请求-响应,最简单、最直接的RPC模式。 | 并发/并行的批量作业,利用I/O多路复用或后端批量推理接口,实现并发处理 | 基于生成器(Generator)的增量处理。建立一种长连接或持续的数据通道,允许服务器在生成结果的过程中就逐步返回数据片段(如token) |
| 🔑技术关键 | 错误处理与重试。重点是保证单次调用的健壮性,如网络超时、模型降级等策略。 | 1. 后端批量推理支持 :这是效率提升的前提。 2. 批次大小(Batch Size)优化 :寻找内存、延迟和吞吐量的最佳平衡点。 3. 动态批处理:高级系统能动态合并不同时间的请求 | 1. 前后端协议 :需使用SSE、WebSocket等支持流式的协议。 2. 增量解析 :下游组件必须能处理不完整的数据块。 3. 中断与取消:需要支持用户中途取消生成。 |
| 🎯核心目标 | 简单性、确定性与可靠性 | 最大化吞吐量(Throughput) | 最小化延迟(Latency ),尤其是首字延迟(TTFT) |
| 📊数据处理 | 完整输入,完整输出 | 批量输入,批量输出 | 增量输入/输出 |
| ⚙️资源利用 | 通常最低。请求间存在大量空闲的I/O等待时间(网络、磁盘),CPU/GPU经常处于闲置状态。 | 最高。通过将计算任务密集打包,让GPU等昂贵硬件满负荷运转,摊薄了单次请求的固定开销。 | 中等但更公平。计算资源随用随取,适合高并发在线服务,能更公平、及时地响应多个并发的流式请求。 |
| 😀用户体验 | "等待-结果"模式。可能存在等待焦虑。 | 无实时交互的离线体验。适用于后台任务。 | "实时交互"模式。持续反馈,体验流畅、自然,符合人类对话习惯。 |
| 🚀应用场景 | 1. 简单的单轮问答。 2. 执行一次性的、独立的工具调用。 3. 原型开发与功能测试。 | 1. 离线数据处理 :批量生成文档摘要、嵌入向量。 2. 报表生成 :夜间批量分析日志,生成日报。 3. 模型评估:在测试集上批量运行模型以评估指标。 | 1. 对话式AI :如ChatGPT,逐字生成回复。 2. 实时翻译/字幕 :语音或文字流实时转换。 3. 代码补全 :IDE中随着输入实时推荐代码。 4. 长文生成:逐步输出文章段落,让用户提前阅读。 |
func Vs chain
缘起
我们之前传统的编程中,一个集中的功能块被称为函数。当然ICEL中内置并自动连接了许多函数,那么当我们需要将一个自定义的函数运用到ICEL中该怎么办?
-
函数 :是执行特定任务的原子操作。它接收输入,返回输出,但其内部逻辑对调用者是不透明的,通常缺乏执行过程的可观测性,也难以与其他AI组件(如LLM调用、工具调用)无缝连接。
-
LCEL Chain :是使用LCEL语法(主要通过
|操作符)将多个可运行体 连接起来的工作流。其核心是Runnable协议 。任何实现了此协议的对象(如LLM模型、工具、甚至另一个Chain)都可以被连接。Chain的优势在于提供了标准的接口 、内置的流式处理 、日志与追踪 ,以及异步、批处理等能力。
Runnable协议
可见,其转换核心便是 Runnable 协议。其本质:为所有能在LCEL管道(通过 |连接)中工作的对象,规定了一套必须实现的"通用语言"和"标准操作" 。
简单说,它是LCEL这个"生态系统"里的宪法,确保了千差万别的组件(从LLM调用、工具函数到简单的数据转换)能够用统一的方式进行交互、组合和执行。
协议核心的方法主要就是上面讲到的几个LCEL基本方法:
- invoke(input, config?) -> output (同步调用)
- 功能:最基础的调用方式,输入一个值,返回一个值。
- 工程意义:定义了组件最直接的、阻塞式的单次执行逻辑。
- ainvoke(input, config?) -> output (异步调用)
- 功能:invoke的异步版本。
- 工程意义:支撑高并发应用的关键。当链中有网络请求(如调用LLM API)时,使用此方法可避免阻塞,极大提升吞吐量。
- batch(inputs, config?) -> outputs (同步批处理)
- 功能:接受一个输入列表,返回一个输出列表。注意:它不一定是简单的for循环,框架或具体实现可能会进行并行优化。
- 工程意义:为批量处理任务提供标准化接口,是高效数据处理的基础。
- abatch(inputs, config?) -> outputs (异步批处理)
- 功能:batch的异步版本,是处理大批量任务的推荐方式。
- 工程意义:结合了批量与并发的优势,是实现高性能AI应用流水线的核心技术。
- stream(input, config?) -> Iteratoroutput (流式输出)
- 功能:返回一个生成器,逐步产出结果。这对于LLM生成长文本、实时返回中间结果至关重要。
- 工程意义:实现了端到端的流式用户体验,是构建响应式应用的核心。
至于,将函数转换到LCEL中使用的方法。后面会着重讲解。
RunnableSequence
顺序处理 ,处理链的"传送带"。是LCEL中最基础、最常用的组件,用于顺序执行多个任务。它将前一个"可运行对象"(Runnable)的输出,作为后一个的输入。
- 本质:定义了一个函数调用链
f(g(h(x)))。每个环节可以是LLM调用、提示词模板、输出解析器或任意函数。LCEL负责处理类型校验、异步支持、流式传输等底层复杂性。或者更简单地说就是我们以往用的|连接符。 - case:
ini
# 顺序执行每一个节点
chain = RunnableSequence(prompt,model,out)
# 等同于 | 连接符,如下
# chain = prompt | model | outRunnableParallel
并行处理 ,任务分发的"多叉路口"。接收一个输入,同时分发给多个Runnable,各分支独立运行,最后将结果按指定键名汇总。
- 与
RunnableSequence组合 :这是构建复杂Agent的核心模式。通常结构为:Parallel(并行收集信息)->Sequence(串联分析决策)。 - case:
python
# 1. 模拟两个"信息源"------通常它们是外部API、数据库查询或工具调用
def query_knowledge_base(product_name: str) -> str:
"""模拟查询产品知识库(可能访问数据库或内部文档)"""
time.sleep(0.2) # 模拟网络延迟
knowledge = {
"智能音箱X3": "这是我们的旗舰款智能音箱。核心特色:1. 搭载8核AI芯片,唤醒率99.9%;2. 支持全屋智能联动;3. 内置Hi-Fi级音响,获得金耳朵认证;4. 待机时间长达72小时。"
}
return knowledge.get(product_name, "未找到该产品的官方资料。")
def query_recent_feedback(product_name: str) -> str:
"""模拟查询近期用户评论(可能调用舆情分析API)"""
time.sleep(0.3) # 模拟另一个服务的延迟
feedback_db = {
"智能音箱X3": "最近30天用户评价精华:1. 音质受到普遍好评,低音表现突出;2. 与'智慧家居'App偶尔出现连接不稳定(占比约5%的反馈);3. 新出的'儿童模式'很受家庭用户欢迎。"
}
return feedback_db.get(product_name, "暂无该产品的近期用户反馈。")
# 2. 核心:构建 RunnableParallel 来并行收集
# 它接收一个字典,定义多个并行的执行分支
parallel_info_gathering = RunnableParallel({
"official_info": RunnableLambda(lambda x: query_knowledge_base(x["product_name"])),
"user_feedback": RunnableLambda(lambda x: query_recent_feedback(x["product_name"])),
# RunnablePassthrough() 用于将原始输入(如product_name)也传递下去
"product_name": RunnablePassthrough()
})
# 4. 构建 RunnableSequence 来串联分析与决策
# 这是一个提示词模板,它将接收parallel_info_gathering输出的所有信息
analysis_prompt = ChatPromptTemplate.from_template("""
你是一名专业的客服助理。请根据以下关于产品"{product_name}"的信息,生成一份给用户的回复要点。
【官方产品信息】
{official_info}
【近期用户反馈摘要】
{user_feedback}
---
生成要求:
1. 首先概括产品的核心优势(来自官方信息)。
2. 然后,提及用户反馈中注意到的亮点。
3. 最后,如果用户反馈中提到了任何潜在问题或顾虑,请用委婉、专业的方式在回复中有所提及或安抚。
4. 回复语言口语化,亲切,面向最终消费者。
请直接输出回复内容:
""")
# 5. 将并行和串行组合成完整的链
# 使用管道操作符 `|` 连接,形成:输入 -> Parallel -> Sequence -> 输出
agent_chain = (
{"product_name": RunnablePassthrough()} # 将用户输入转化为字典格式,键为"product_name"
| parallel_info_gathering
| analysis_prompt
| ChatTongyi()
| StrOutputParser()
)RunnablePassthrough
LCEL中的 "透明管道"与"数据中继",是一个什么也不做的"透明人"。他好比一个快递员,他只负责把文件原封不动地从一个部门送到下一个部门,不查看、不修改。
数据传递
就是啥也不做,原样传递。前面在RunnableParallel的示例代码中已经见过,这里的作用就是将原始输入(如product_name)原封不动地传递下去。
css
parallel_info_gathering = RunnableParallel({
"official_info": RunnableLambda(lambda x: query_knowledge_base(x["product_name"])),
"user_feedback": RunnableLambda(lambda x: query_recent_feedback(x["product_name"])),
# RunnablePassthrough() 用于将原始输入(如product_name)也传递下去
"product_name": RunnablePassthrough()
})数据增强-assign特性
利用assign特性将数据增强后继续传递。如下,执行后:
- 原数据:{'k1': 'hello world'}
- 新数据:{'k1': 'hello world', 'modified': 'hello world!!!'}
ini
# 数据增强,增强后进行继续传递
chain = RunnableParallel(
passed = RunnablePassthrough().assign(modified= lambda x: x["k1"]+"!!!"),
)
# 增强调用,需要使用字典格式
print(chain.invoke({"k1": "hello world"}))RunnableLambda
函数包装器 ,接入旧世界的"万能适配器"。我们前面讲到的自定义函数在LCEL中使用就是需要使用这个。它包装一个普通函数,使其符合Runnable接口,从而能够与其他LCEL组件无缝衔接。
示例函数
python
# 创建一个Pydantic模型, 用于估算费用
class TripDetails(BaseModel):
destination: str = Field(description="旅行目的地城市")
duration: int = Field(description="旅行天数")
estimated_cost_per_person: float = Field(description="估算人均成本", default=None)
summary: str = Field(description="给用户的旅行建议摘要")
def calculate_total_cost(trip_details: TripDetails) -> TripDetails:
"""根据旅行天数和目的地,估算一个非常粗略的人均成本"""
daily_cost = {"北京": 600, "东京": 1200}.get(trip_details.destination, 500)
trip_details.estimated_cost_per_person = daily_cost * trip_details.duration
return trip_details方法1-RunnableLambda
ini
# 将函数封装为Runnable
chain = prompt | model | out | RunnableLambda(calculate_total_cost)方法2-@chain装饰器
python
# 使用@chain装饰器
@chain
def chain_calculate_total_cost(trip_info: dict) -> dict:
return calculate_total_cost(trip_info)
# 直接使用装饰后的方法名,无需RunnableLambda
chain = prompt | model | out | chain_calculate_total_cost其他代码
ini
model = ChatTongyi()
out = PydanticOutputParser(pydantic_object=TripDetails)
format_instructions = out.get_format_instructions()
prompt = ChatPromptTemplate.from_template("""
你是一名专业的旅游助手。请根据以下关于旅游信息"{tripInfo}",生成一份给用户的回复要点\n{format_instructions}。
【旅游信息】
{tripInfo}
""")
prompt = prompt.partial(format_instructions=format_instructions)
# 方法1
chain = prompt | model | out | RunnableLambda(calculate_total_cost)
# 方法2
# chain = prompt | model | out | chain_calculate_total_cost
result = chain.invoke({"tripInfo": "北京-东京 3天"})
print(result.model_dump()) # 查看完整的结构化结果
print("-" * 50)
print(result.summary) # 访问文本回复
print("-" * 50)
print(f"估算成本:{result.estimated_cost_per_person}") # 访问计算后的成本RunnableMap
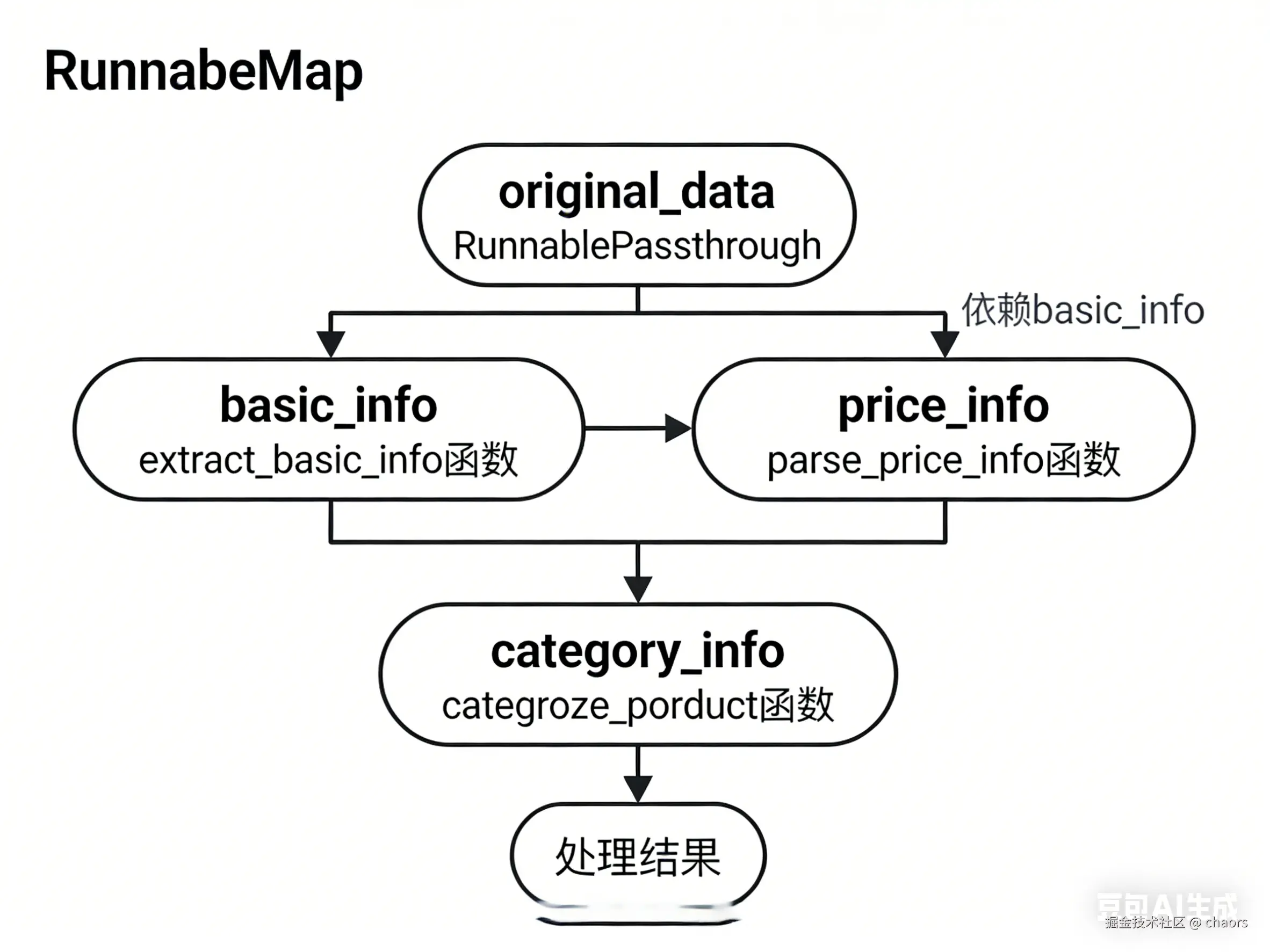
数据转换器 ,规整数据的"操作台"。常用于在链中顺序执行输入数据的转换,是"精加工,重新包装"的过程,核心目标在于为下一步做准备。常用语数据分析师整理和清洗已收集的数据。
- RunnableMap与RunnableLambda的关键区别在于意图 。Map明确表示"我将输入映射为一个新的字典",这通常用于数据整形。而Lambda可以返回任何类型。在复杂链中,用Map来保证数据接口一致性,能使流程更清晰。
一个简单的🌰:电商商品信息处理流水线 - RunnableMap。场景:处理用户上传的商品信息,生成标准化商品详情页
示例数据
makefile
# 示例输入:用户上传的商品原始数据
raw_product_data = {
"title": "Apple iPhone 15 Pro Max 256GB 原色钛金属 行货正品",
"price": "8999.00",
"seller": "Apple官方旗舰店",
"specs": "6.7英寸, A17 Pro芯片, 4800万像素, 5倍长焦",
"tags": "手机|苹果|iPhone|旗舰|5G",
"description": "全新iPhone 15 Pro Max,采用航空级钛金属设计,史上最轻的Pro机型。",
"timestamp": "2024-03-15T14:30:00Z"
}多个处理函数
📢:数据处理流水线,这里每个步骤都依赖上一步的输出。
- 提取基础信息
python
def extract_basic_info(data: Dict) -> Dict:
"""提取基础信息 - 假设我们需要品牌和型号"""
title = data.get("title", "")
# 简单解析品牌和型号
if "iPhone" in title:
brand = "Apple"
model = "iPhone 15 Pro Max"
elif "小米" in title or "Xiaomi" in title:
brand = "Xiaomi"
model = "未知型号"
else:
brand = "其他"
model = "未知"
return {
"brand": brand,
"model": model,
"title_cleaned": title.replace("行货正品", "").strip()
}- 解析价格信息
python
def parse_price_info(data: Dict) -> Dict:
"""解析价格信息 - 依赖基础信息中的品牌"""
price_str = data.get("price", "0")
try:
price = float(price_str)
except:
price = 0.0
# 根据品牌确定货币单位
brand = data.get("brand", "未知")
currency = "CNY" if brand in ["Apple", "Xiaomi", "华为"] else "USD"
return {
"price_numeric": price,
"currency": currency,
"price_formatted": f"{currency} {price:,.2f}"
}- 分类商品
python
def categorize_product(data: Dict) -> Dict:
"""分类商品 - 依赖清理后的标题和价格"""
title = data.get("title_cleaned", "")
price = data.get("price_numeric", 0)
category = "电子产品"
subcategory = "手机"
if price > 8000:
price_segment = "高端"
elif price > 3000:
price_segment = "中端"
else:
price_segment = "入门"
return {
"category": category,
"subcategory": subcategory,
"price_segment": price_segment
}RunnableMap
scss
# 1.2 使用RunnableMap构建数据处理流水线
# 注意:这里每个步骤都依赖上一步的输出
data_processing_pipeline = RunnableMap({
"basic_info": RunnableLambda(extract_basic_info),
"price_info": RunnableLambda(lambda x: parse_price_info({**x, **extract_basic_info(x)})),
"category_info": RunnableLambda(lambda x: categorize_product({
**x,
**extract_basic_info(x),
**parse_price_info({**x, **extract_basic_info(x)})
})),
"original_data": RunnablePassthrough()
})
print("执行RunnableMap数据清洗...")
start_time = time.time()
processed_data = data_processing_pipeline.invoke(raw_product_data)
map_time = time.time() - start_time
print(f"\n✅ RunnableMap处理结果(耗时: {map_time:.3f}秒):")
print("清洗后的数据:")
for key, value in processed_data.items():
if key != "original_data":
print(f" {key}: {value}")🤔和RunnableParallel混用思考???
RunnableMap处理有依赖的数据,如果这个【电商项目】继续展开还能做啥?
-
使用RunnableParallel并行获取:
- 竞品信息
- 市场分析
- 库存和物流
- SEO关键词
-
获取到后再使用RunnableMap,依赖前面的生成一个【电商项目xxx报告】
-
总结RunnableMap + RunnableParallel的混合使用场景:
- 先用Map清洗/准备数据(清洗、验证、标准化)
- 然后用Parallel并发独立操作(并发获取外部数据)
- 最后用另一个Map整合结果(整合、丰富、格式化)
RunnableBranch
LCEL中实现条件逻辑 和动态路由 的核心组件,是流程"决策树" 。它是实现if-else逻辑的核心,其根据条件动态选择下一步执行哪个分支。它接收一个(条件, 分支)的列表和一个默认分支。例如,根据用户问题意图判断是走"问答分支"、"数据查询分支"还是"闲聊分支"。
在大模型应用中,简单地说就好比你问一个问题,RunnableBranch先判断这个问题属于哪个分治,然后调用哪个分治链来解决。废话少说上🌰:一个产品信息系统,包括价格查询、技术咨询、退款流程等。
条件判断函数
python
# 1. 定义条件判断函数
def classify_query(query_data: dict) -> str:
"""根据查询内容分类"""
query = query_data.get("query", "").lower()
if "价格" in query or "多少钱" in query or "cost" in query:
return "price_inquiry"
elif "故障" in query or "问题" in query or "error" in query:
return "technical_issue"
elif "退货" in query or "退款" in query or "return" in query:
return "refund_request"
elif "客服" in query or "人工" in query or "support" in query:
return "human_support"
else:
return "general_inquiry"分支链
价格咨询分支
python
# 价格查询分支
price_chain = (
ChatPromptTemplate.from_template("""
你是一个专业的销售顾问。用户询问价格信息。
用户查询:{query}
请以专业、友好的方式回答价格相关问题。
如果知道具体价格,请明确告知。
如果不知道,请提供获取价格的途径。
""")
| llm
| StrOutputParser()
)技术咨询分支
python
# 技术问题分支
tech_chain = (
ChatPromptTemplate.from_template("""
你是一个技术专家。用户遇到技术问题。
用户查询:{query}
请提供详细的技术解决方案。
分步骤说明,确保用户能理解。
如果问题复杂,建议联系技术支持。
""")
| llm
| StrOutputParser()
)退款分支
python
# 退款请求分支
refund_chain = (
ChatPromptTemplate.from_template("""
你是一个客服专员。用户希望退款或退货。
用户查询:{query}
请友好地解释退款政策。
询问订单详细信息以便协助。
提供明确的后续步骤。
""")
| llm
| StrOutputParser()
)默认查询分治
这里就像我们传统编程的switch,为了程序健壮性,总是有一个默认default。
python
# 通用查询分支
general_chain = (
ChatPromptTemplate.from_template("""
你是一个有用的助手。回答用户的通用查询。
用户查询:{query}
请提供有帮助的回答。
""")
| llm
| StrOutputParser()
)RunnableBranch
python
# 3. 创建RunnableBranch
# 格式:RunnableBranch( (条件1, 分支1), (条件2, 分支2), ..., 默认分支 )
query_router = RunnableBranch(
# 条件是一个函数,接收输入数据,返回True/False
(lambda x: classify_query(x) == "price_inquiry", price_chain),
(lambda x: classify_query(x) == "technical_issue", tech_chain),
(lambda x: classify_query(x) == "refund_request", refund_chain),
# 默认分支(当所有条件都不满足时执行)
general_chain
)完整链
ini
# 4. 构建完整链:接收查询 -> 路由 -> 处理
full_chain = RunnableLambda(
lambda x: {"query": x} # 将字符串包装为字典
) | query_router测试代码
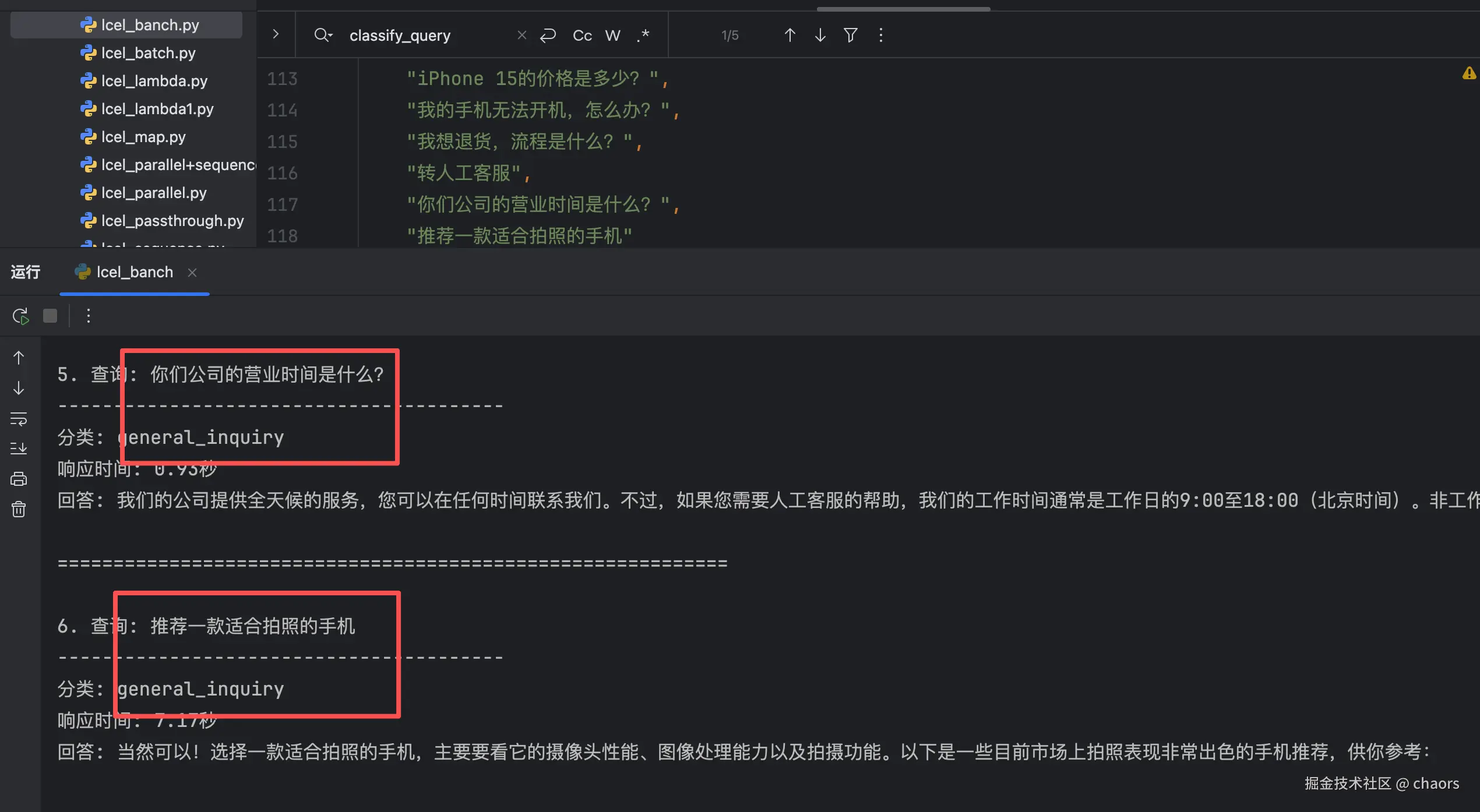
python
# 5. 测试不同查询
test_queries = [
"iPhone 15的价格是多少?",
"我的手机无法开机,怎么办?",
"我想退货,流程是什么?",
"转人工客服",
"你们公司的营业时间是什么?",
"推荐一款适合拍照的手机"
]
print("测试不同查询的路由结果:\n")
for i, query in enumerate(test_queries, 1):
print(f"{i}. 查询: {query}")
print("-" * 40)
start_time = time.time()
try:
response = full_chain.invoke(query)
elapsed = time.time() - start_time
# 显示分类结果
category = classify_query({"query": query})
print(f"分类: {category}")
print(f"响应时间: {elapsed:.2f}秒")
print(f"回答: {response}")
except Exception as e:
print(f"错误: {e}")
print("\n" + "=" * 60 + "\n")测试结果


RunnableWithMessageHistory
对话的"记忆体",这是构建对话式Agent的基石。今天不做扩展,后续我们在记忆模块再做专题学习。
综合对比

| 特性 | 技术原理 | 核心功能 | 应用场景 | 注意事项 | 性能特点 | 组合模式 |
|---|---|---|---|---|---|---|
| RunnableSequence | 函数管道模式,将多个Runnable按顺序组合,前一个输出作为后一个输入 | 顺序执行多个任务,形成处理流水线 | 1. 多步骤处理流程 2. LLM调用链 3. 数据预处理+模型调用+后处理 | 1. 链条过长时调试困难 2. 错误会沿链传递 3. 需注意步骤间的数据类型匹配 | 总耗时=各步骤耗时之和,无并行优化 | 基础组合单元,可与所有其他组件组合 |
| RunnableParallel | 并行执行模式,将同一输入同时分发给多个独立分支,结果合并为字典 | 并行执行多个独立任务,提升吞吐量 | 1. 同时调用多个外部API 2. 并行查询多个数据源 3. 独立的数据处理任务 | 1. 分支间不能有数据依赖 2. 一个分支失败可能影响整个并行块 3. 需注意资源竞争 | 总耗时≈最慢分支耗时,显著提升IO密集型任务性能 | 常与Sequence组合:Parallel收集 → Sequence处理 |
| RunnableLambda | 适配器模式,将任意Python函数包装为Runnable接口 | 集成自定义业务逻辑到LCEL链 | 1. 调用外部API/数据库 2. 复杂业务规则计算 3. 数据验证与清洗 4. 格式转换 | 1. 过度使用破坏声明式风格 2. 函数应尽量保持纯函数特性 3. 需自行处理错误 | 取决于函数逻辑,可能成为性能瓶颈 | 可插入任何需要自定义逻辑的位置 |
| RunnableMap | 数据转换模式,对输入进行结构化转换,输出单个字典 | 数据清洗、格式标准化、字段提取与映射 | 1. 数据预处理 2. API响应格式化 3. 特征工程 4. 输入输出格式适配 | 1. 常与RunnableLambda混淆 2. 输出必须是字典 3. 是顺序执行,非并行 | 顺序执行,总耗时=各转换步骤之和 | 常用于链的开头(数据准备)或结尾(结果格式化) |
| RunnableBranch | 条件路由模式,根据条件函数动态选择执行分支 | 实现if-else逻辑,动态工作流路由 | 1. 意图识别与路由 2. 多级决策树 3. 异常处理与降级 4. A/B测试路由 | 1. 条件顺序重要(短路评估) 2. 条件函数应轻量 3. 必须提供默认分支 4. 条件函数应是纯函数 | 条件判断开销+选中分支开销,条件函数应高效 | 可构建复杂决策树,常与Parallel组合实现动态工作流 |
| RunnablePassthrough | 恒等函数模式,原样传递输入,不做任何处理 | 数据传递、上下文保留、占位符 | 1. 在Parallel中保留原始输入 2. 链中传递上下文 3. 调试时检查中间状态 4. 配合.assign()动态添加字段 | 1. 常被误解为"无用"组件 2. 不提供并行能力 3. 可能意外传递可变对象引用 | 近乎零开销,是最轻量的Runnable | 常与Parallel组合保留原始数据,或用于链中数据传递 |