OLAP数据库HashJoin性能优化揭秘
业界OLAP数据库基本上都配备了向量化执行引擎。众所周知,面向行式的数据库执行模型都是基于火山模型,即每次迭代执行仅处理一个元组,为减少函数调用次数和减少cache miss,向量化执行引擎就登场了,一个迭代可以处理一批数据。HashJoin在向量化执行中怎么设计才高效呢?
1、openGauss的实现机制
openGauss中实现了两种HashJoin的向量化执行模式,第一种hash表里需要存储需要的所有列值,也就是hash表的数据和桶是放在一起的,并且hash entry以行的形式组织。当发生hash冲突时,以链表的形式管理hash entry。探测时外表的VectorBatch批量计算hash值,然后在join投影阶段和hash桶中的key值进行比较,如果满足条件就放到输出VectorBatch中。
这种做法的缺点:数据和hash表放在一起,相对来说内存中hash表的hash entry数目就会变少,内表的hash表就会提前溢出到磁盘,从而导致外表也跟着溢出磁盘,进而数据IO代价就会变大。另外,数据以行的形式存储,也不利于VectorBatch批量执行和构建join结果,数据的cache miss也会变大。
openGauss还有另一种模式,VecSonicHashJoin模式,这种模式专门针对列式存储,以列的形式管理hash表,并且将hash表与数据分离,内存中放的hash entry数更多,能够延迟内表hash表溢出,减少列数据的cache miss。
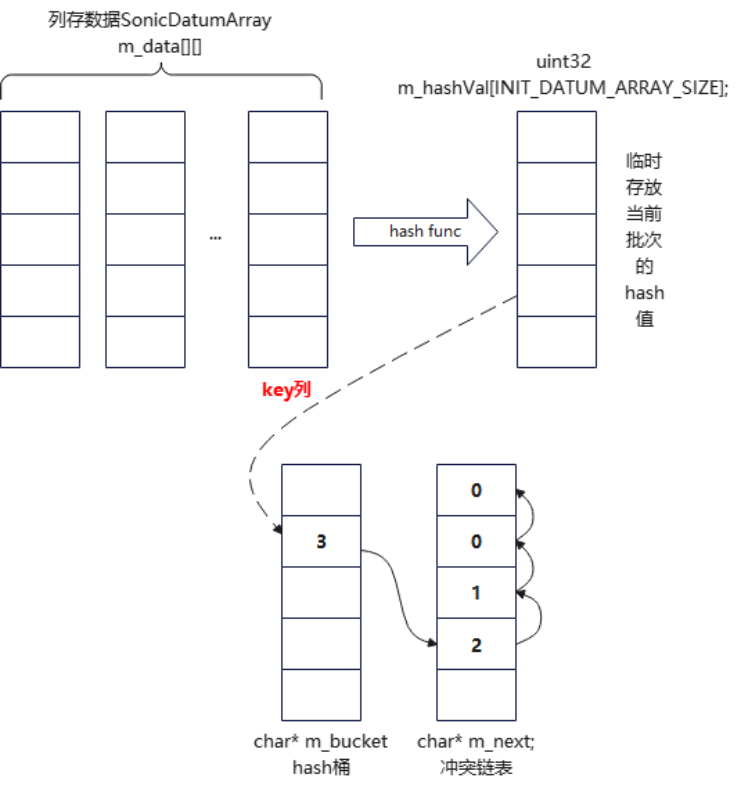
如上图所示,hash表的hash桶是一个一字节大小的m_bucket数组 ,存储链表头也就是m_next的序号 。m_next链表是冲突链表,同一个hash值向链表头部插入,m_nexti表示第i行下一个冲突值在m_next\[\]数组中的序号,i值是全局行号,和m_data\[\]\[\]数组对应,取数据时m_data1i是第1列的第i行值。通过hash值确定桶头后,遍历m_next数组,得到第i行,然后从**m_datakeyi**取key数据进行key值比较。
探测时,外表一批数据批量计算hash值,放到m_hashVal中,根据m_hashVal值确定桶号,遍历m_next数组,取出m_datakeyi中的key值进行比较。也就是探测时CPU cache中需要放m_hashVal值、m_bucket数组、m_next数组和m_datakey\[\]这列值。相当于hash表:m_bucket+m_next+m_datakey值。相对于行式存储hash表存放所有值来说,hash表要小得多。
当然,这么做也有缺点:key比较时,外表的每一行相同hash值下,如果key是多列,就需要提取多列值进行比较,这种本质上是随机访问,行存储的局部性优势更明显;如果是列式,由于需要多列值,增加了缓存未命中次数。
2、DuckDB的实现机制
DuckDB同样实现了数据和hash表分离,大体上也是提高内存中hash表的容量,在内存中容纳更多的hash桶。
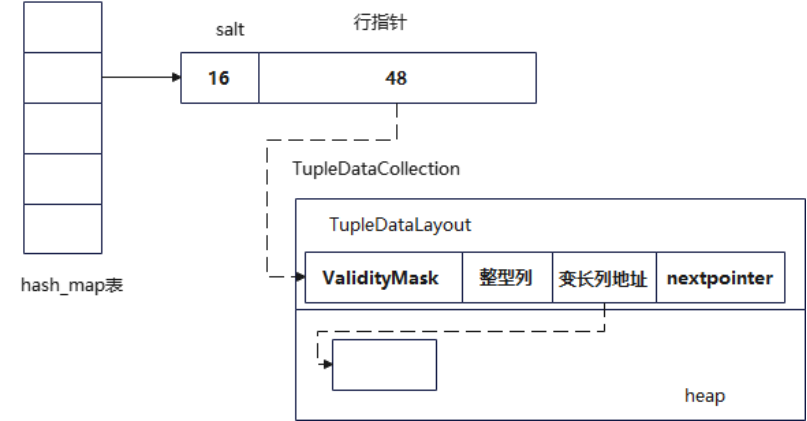
如上图所示,hash表的ht_entry_t是固定的64字节,hash值取余后得到桶号,根据桶号取ht_entry_t。它将64字节的桶值设计成了两部分,高16位作为salt,低48位作为行指针。取出hash桶值后先与高16位比较,若相同再取行指针,减少hash冲突时不必要的键值比较,提高探测效率。根据行指针,取一行值对key进行比较,将匹配的内表值位置和外部上分布使用一个数组来标记,够一个batch大小后,根据数组标记构建hash join结果向量。当然,他也是通过链表来管理hash冲突,通过nextpointer指针将同一个hash值的不同数据串起来。
Salt值仅在hash表荣太郎超过8192时才启用,因为小表可以完全放入CPU cache中,有salt反而会增加开销。
3、StarRocks的实现机制
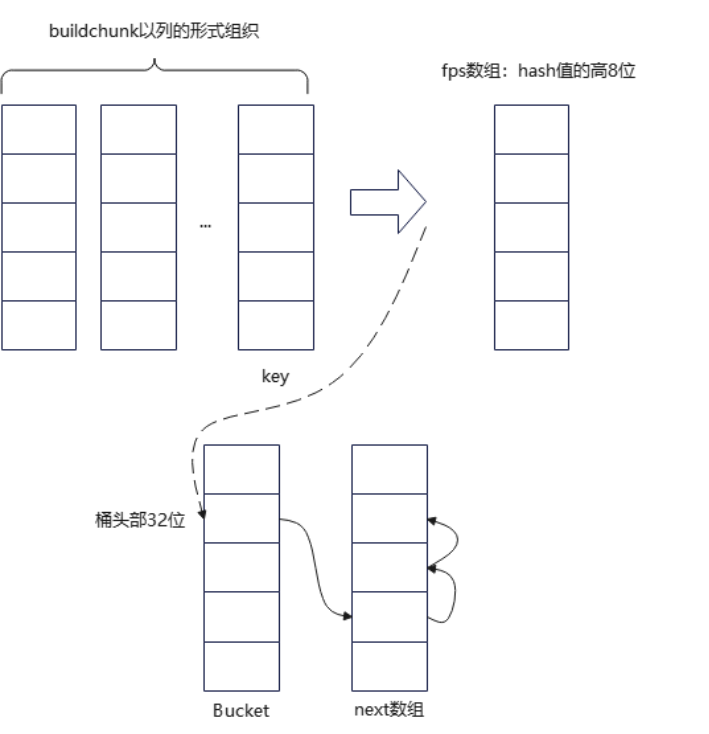
如上图所示,它的实现方式和openGauss基本一样,只不过增加了一个可选的fps数组,存储hash值的高8位,用于快速过滤,完成的功能和DuckDB的salt一样。
4、OceanBase的实现机制
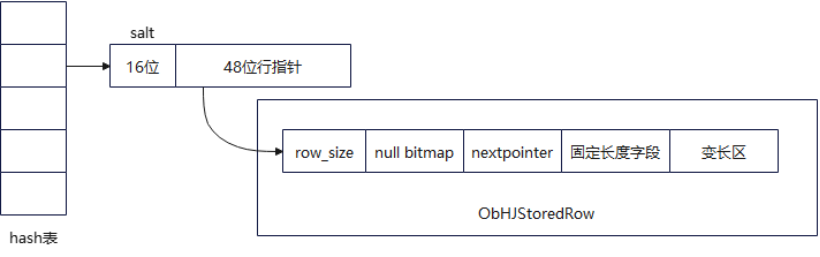
如上图所示,OceanBase中的Hash表也是数据与hash表分离方式,实现和DuckDB类似,数据也是以行的形式组织,通过nextpointer管理同一个hash值的数据。探测时采用两级预取机制,先预取hash桶,再预取行数据,通过__builtin_prefetch提取将数据加载到缓存,减少内存访问延迟。