目录
[1. 引入](#1. 引入)
[2. Lambda的语法](#2. Lambda的语法)
[3. Lambda的使用](#3. Lambda的使用)
[4. Lambda的类型](#4. Lambda的类型)
[5. 函数对象与Lambda](#5. 函数对象与Lambda)
[1. function包装器](#1. function包装器)
[2. bind 绑定](#2. bind 绑定)
一、Lambda表达式
1. 引入
在C++98中,如果想要对一个数据集合中的元素进行排序,可以使用std::sort函数进行排序,这对于内置类型来说,排升序与降序只需要传递库中的仿函数即可决定了,但是对于自定义类型,则就需要我们自己写一个仿函数来定义排序规则。比如以下数据:
cpp
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
// 构造函数
Goods(const char* str, double price, int evaluate)
: _name(str)
, _price(price)
, _evaluate(evaluate)
{ }
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
return 0;
}我们需要对这个v中的这些自定义类型的数据进行排序,如果我们使用sort来排序,则就需要我们自己定义仿函数(重载了operator()的类)来规定排序规则。如下所示:
cpp
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
// 构造函数
Goods(const char* str, double price, int evaluate)
: _name(str)
, _price(price)
, _evaluate(evaluate)
{ }
};
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
struct CompareEvaluateGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._evaluate > gr._evaluate;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), ComparePriceLess()); // 按照价格排升序
sort(v.begin(), v.end(), ComparePriceGreater()); // 按照价格排降序
sort(v.begin(), v.end(), CompareEvaluateGreater()); // 按照评价排降序
return 0;
}后来人们觉得这种写法太复杂了,每次为了实现一个排序算法,都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。因此,在C++11语法中出现了Lambda表达式。
2. Lambda的语法
Lambda表达式实际是一个匿名函数。它允许你在需要函数的地方直接写出函数的逻辑,而不需要提前定义一个正式的函数名。
Lambda 表达式的基本语法如下:
cpp
[capture-list] (parameters) mutable -> return-type { statement }下面是对此的说明:
[capture-list]: 捕获列表,决定了哪些外部变量可以在 lambda 内部使用。常见的捕获方式包括:
[=]: 按值捕获包含lambda函数的语句块的所有变量(包括 this)。[&]: 按引用捕获包含lambda函数的语句块的所有变量(包括 this)。[var]: 按值捕获特定变量var。[&var]: 按引用捕获特定变量var。[this]: 在类成员函数中,按值捕获当前对象的 this 指针。
(parameters): 参数列表,类似于普通函数的参数列表。如果不需要参数,可以省略括号。
mutable:可变修饰符。默认情况下(即不加mutable),Lambda 会将其按值捕获 的变量视为 const常量。加上 mutable后就允许 Lambda 修改按值捕获的变量。
-> return_type: 返回类型声明。没有返回值时可省略;返回值类型明确情况下,也可省略,省略后会由编译器对返回类型进行自动推导。
{ statement }: 函数体,在该函数体内,除了可以使用其参数外,还可以使用所有捕获 到的变量。。
以上就是对Lambda的基础语法了,但对于它的使用我们还有一些细节,接下来就来看看它是如何使用的。
3. Lambda的使用
通过上面的语法我们可以知道,返回值和参数列表都是可以省略的,而捕捉列表和函数体可以为 空。因此C++11中最简单的lambda函数为:\[\]{}; 该lambda函数不能做任何事情。即:
cpp
int main()
{
[] {}; // 最简单的lambda表达式, 该lambda表达式没有任何意义
return 0;
}如果我们要实现一个简单的加法函数,就可以像如下所示这样写:
cpp
int main()
{
int a = 3, b = 5;
//auto add = [](int x, int y)->int{ return x + y; };
auto add = [](int x, int y){ return x + y; }; // 省略返回值,让编译器自动推导
int c = add(a, b);
return 0;
}这样看来,这其实和函数的定义很像,只是加了一个捕捉列表而已。
首先捕捉列表在最前面,参数列表负责表示传递的参数(可以是值传参,也可以引用传参),返回值可以省略让编译器自动推导类型,函数体定义函数的功能。最后整个表达式可以用一个auto推导的类型接收作为函数名(Lambda表达式的名字很复杂,使用auto才能知道)。
下面我们来介绍一下捕捉列表的使用。
如果我们写一个交换的函数,通过Lambda来写就是这样:
那么如果我们不使用参数列表呢?使用捕捉列表也可以完成交换,捕捉列表的使用有一些几个情况:
[=]: 按值捕获包含lambda函数的语句块的所有变量(包括 this)。[&]: 按引用捕获包含lambda函数的语句块的所有变量(包括 this)。[var]: 按值捕获特定变量var。[&var]: 按引用捕获特定变量var。[this]: 在类成员函数中,按值捕获当前对象的 this 指针。
那么如果使用值传递捕捉来进行交换,使用方法如下: 可以看到这时无法修改,如果想要修改,则需加上 mutable ,这样值捕捉的变量就可以修改了。如下所示:
可以看到这时无法修改,如果想要修改,则需加上 mutable ,这样值捕捉的变量就可以修改了。如下所示: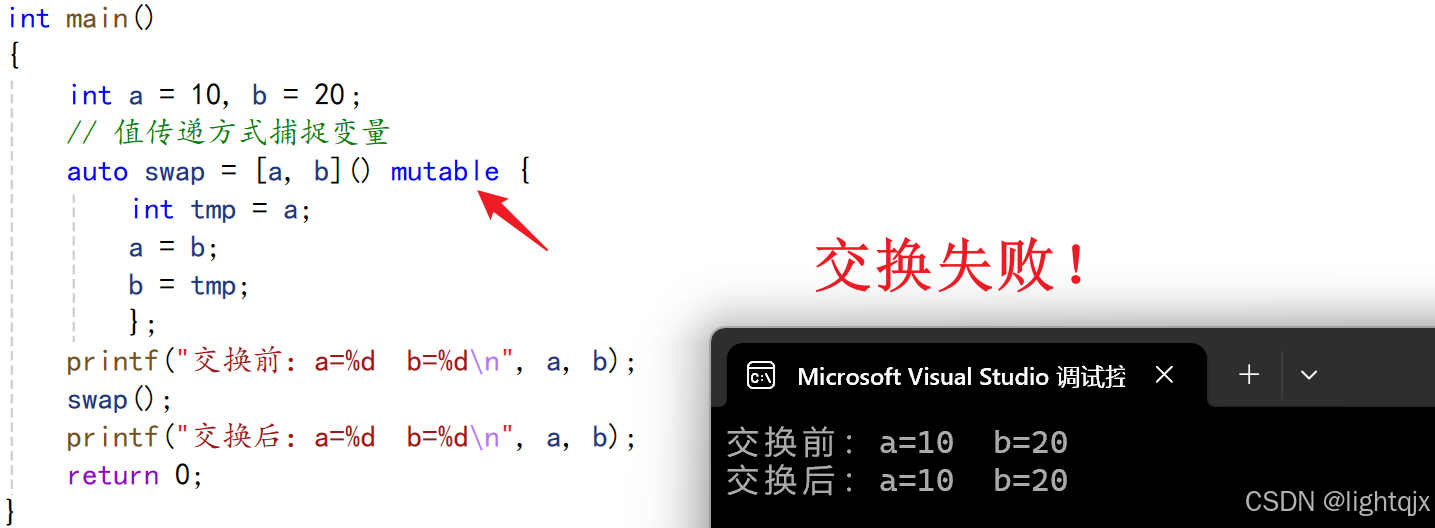 但是这样也无法修改,所以我们就需要使用引用捕捉,这样就可以完成交换了,如下所示:
但是这样也无法修改,所以我们就需要使用引用捕捉,这样就可以完成交换了,如下所示: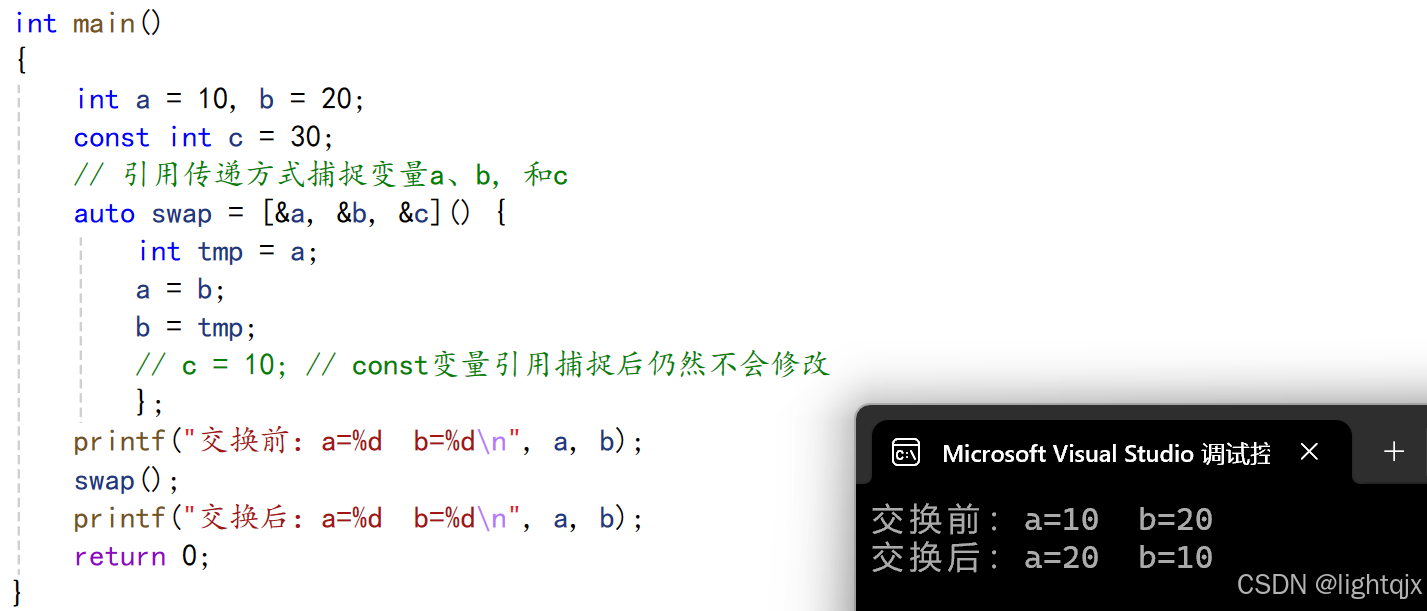
这就是捕捉列表的基本用法了。除此之外,捕捉列表直接使用 = 和 \& ,就可以将包含lambda函数的语句块的所有变量都捕捉, = 是将所有变量都传值捕捉;\& 是将所有变量都引用捕捉。
还有一些需要注意的事项:
- 语法上捕捉列表可由多个捕捉项组成,并以逗号分割 。
比如:=, \&a, \&b:以引用传递的方式捕捉变量 a 和 b,值传递方式捕捉其他所有变量 \&,a, this:值传递方式捕捉变量 a 和 this,引用方式捕捉其他变量- 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:=, a:= 已经以值传递方式捕捉了所有变量,捕捉 a 重复在块作用域以外的lambda函数捕捉列表必须为空。- 在块作用域中的 lambda 函数仅能捕捉父作用域(即包含lambda函数的语句块)中的局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
- lambda 表达式之间不能相互赋值 ,即使看起来类型相同(因为即使每个 Lambda 表达式的代码完全一模一样,但它们各自都有自己独一无二的类型,所以类型不同,就不能赋值)
4. Lambda的类型
在 C++ 中,Lambda 表达式的类型是一个由编译器自动生成的、独一无二的、无名的类类型。 由于这个类型名是由编译器生成的,它在不同编译器下的表现形式不同。你可以通过 tepyid 来观察它。
比如以下代码:
cpp
#include <iostream>
#include <typeinfo>
using namespace std;
int main()
{
auto f1 = [](int x, int y) {return x + y; };
auto f2 = [](int x, int y) {return x + y; };
cout << typeid(f1).name() << endl;
cout << typeid(f2).name() << endl;
return 0;
}在VS2022中的结果就是:
在Dev-C++中,则是:
5. 函数对象与Lambda
函数对象,又称为仿函数,即可以想函数一样使用的对象,就是在类中重载了operator( )运算符的 类对象。而Lambda的底层其实就是仿函数。接下来我们来看以下这段代码:
cpp
class Fun
{
public:
Fun(int x)
:_tmp(x)
{ }
int operator()(int x, int y)
{
return x * y * _tmp;
}
private:
int _tmp;
};
int main()
{
// 函数对象
int a = 10;
Fun f1(a);
f1(3, 5);
// Lambda
auto f2 = [=](int x, int y) ->int{return x * y * a; };
f1(3, 5);
return 0;
}从使用方式上来看,函数对象与lambda表达式完全一样。下面我们通过汇编代码可以看到:
它们其实是一样的,所以说实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator() 。可以理解为Lambda的底层其实就是仿函数。
二、包装器
1. function包装器
function包装器是用来解决可调用对象类型不统一的问题的。
我们知道的可调用的类型有三种:函数指针,仿函数,Lambda,而这三个的类型是不同的,那么当我们通过它们的模板使用时,就可以会导致效率低下的问题。比如以下代码:
cpp
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x); // 调用可调用对象
}
// 函数指针
double f(double i)
{
return i / 2;
}
// 仿函数
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
// 函数指针
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lambda表达式
cout << useF([](double d)->double { return d / 4; }, 11.11) << endl;
return 0;
}运行后: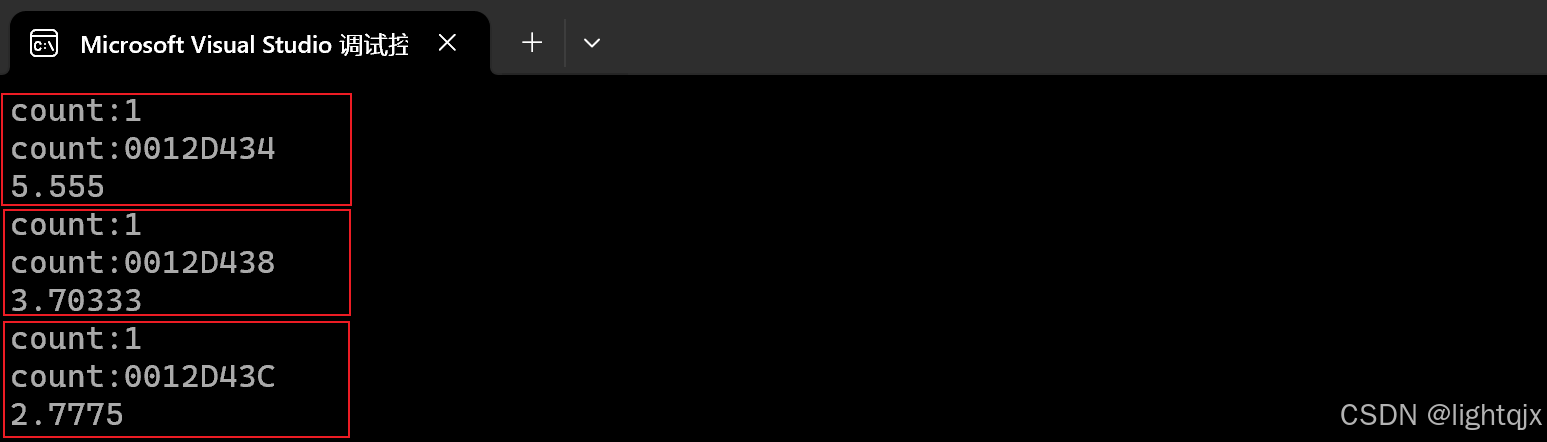
可以看到同名的静态变量的地址并不相同,说明这里的的模板实例化了三份,但是它们使用的都是可调用对象,因为这三种可调用对象的类型不同,导致了不同的实例化。
在一些时候我们可以函数指针,也可能使用仿函数,还可能使用Lambda,这是如果我们的程序就会将同一个本来是同一个功能的模板实例化成多份,这就会降程序的效率。
所以,在C++11中就出现了包装器,它就是专门来解决这个问题的。它需要使用function来定义类型,它的类模板原型如下所示:
使用function需要包含头文件<functional>。
使用语法如下所示:
cpp
// 函数指针
int f(int x,int y)
{
return x + y;
}
// 仿函数
struct Functor
{
int operator()(int x, int y)
{
return x + y;
}
};
int main()
{
// 函数指针
function<int(int, int)> fun1 = f;
// 函数对象
function<int(int, int)> fun2 = Functor();
// lambda表达式
function<int(int, int)> fun3 = [](int x, int y)->int {return x + y; };
return 0;
}其中function的使用解释如下所示:
通过function这样就可以将这三种不同类型的可调用类型都包装为了他一种类型,比如我们使用typedid打印观察:
cpp
// 函数指针
int f(int x,int y)
{
return x + y;
}
// 仿函数
struct Functor
{
int operator()(int x, int y)
{
return x + y;
}
};
int main()
{
cout << "使用包装器前:" << endl;
cout << typeid(f).name() << endl; // 函数指针
cout << typeid(Functor()).name() << endl; // 函数对象
auto a = [](int x, int y)->int {return x + y; };
cout << typeid(a).name() << endl; // lambda表达式
cout << "使用包装器后:" << endl;
function<int(int, int)> fun1 = f;// 函数指针
function<int(int, int)> fun2 = Functor();// 函数对象
function<int(int, int)> fun3 = [](int x, int y)->int {return x + y; }; // lambda表达式
cout << typeid(fun1).name() << endl;
cout << typeid(fun2).name() << endl;
cout << typeid(fun3).name() << endl;
return 0;
}运行结果: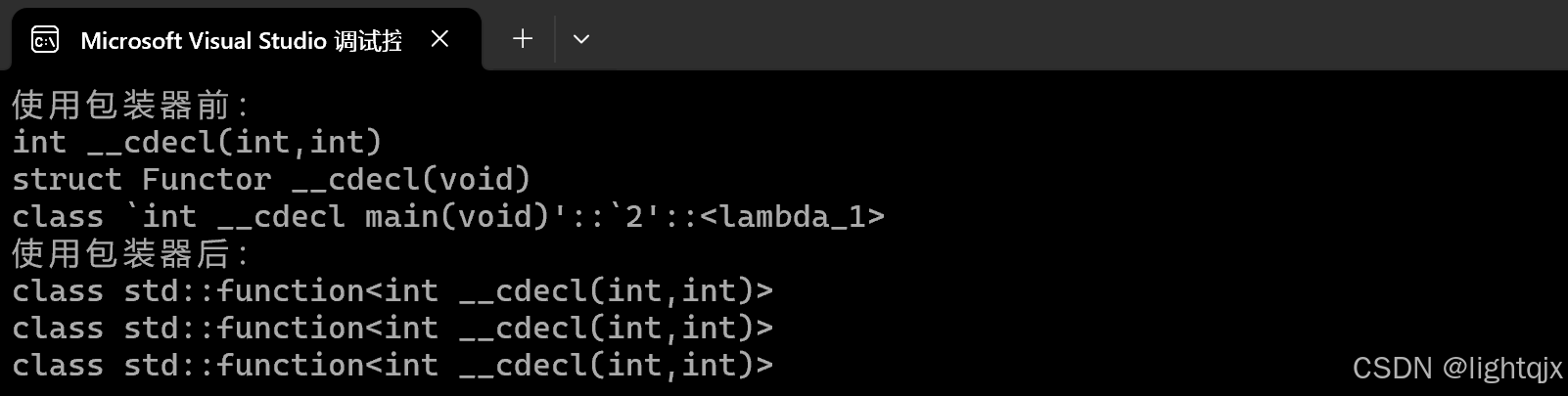
这样我们也就可以将不同的可调用对象存入同一个容器了,如:
cpp
int main()
{
function<int(int, int)> fun1 = f;// 函数指针
function<int(int, int)> fun2 = Functor();// 函数对象
function<int(int, int)> fun3 = [](int x, int y)->int {return x + y; }; // lambda表达式
vector<function<int(int, int)>> v = { fun1,fun2,fun3 };
return 0;
}那么此时我们最开始的代码的模板就可以只实例化为一份了,如:
cpp
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x); // 调用可调用对象
}
// 函数指针
double f(double i)
{
return i / 2;
}
// 仿函数
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
function<double(double)> fun1 = f;// 函数指针
function<double(double)> fun2 = Functor();// 函数对象
function<double(double)> fun3 = [](double d)-> double { return d / 4; }; // lambda表达式
// 函数指针
cout << useF(fun1, 11.11) << endl;
// 函数对象
cout << useF(fun2, 11.11) << endl;
// lambda表达式
cout << useF(fun3, 11.11) << endl;
return 0;
}运行结果: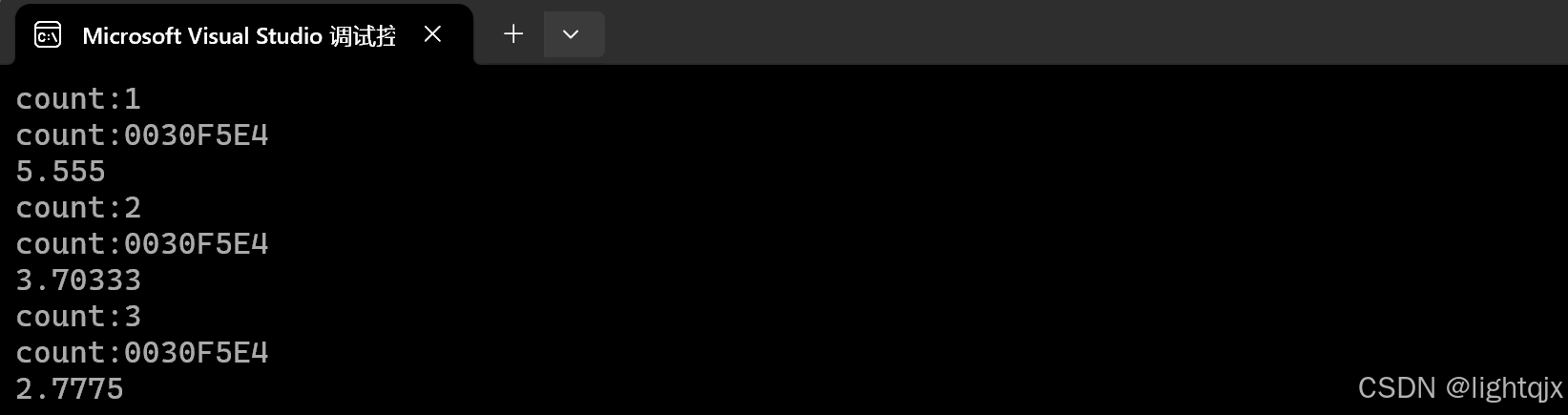
2. bind 绑定
bind 也定义在头文件<function>中,它是一个函数模板,它就像一个函数包装器(适配器),接受一个可 调用对象(callable object),生成一个新的可调用对象来"适应"原对象的参数列表。
可以通过function来接收bind绑定后的类型(以下为了方便使用的都是auto)。比如一个简单的绑定如下所示:
cpp
int func(int a, int b)
{
return a + b;
}
int main()
{
//function<int(int,int)> Fun1 = bind(func, std::placeholders::_2, std::placeholders::_1);
auto Fun1 = bind(func, std::placeholders::_2, std::placeholders::_1);
return 0;
}这里的Fun1就是绑定后的新可调用对象。那它具体是怎么使用的呢?接下来就来介绍一下。
对于bind绑定可以发挥的具体功能有:可以改变一个函数的传参顺序,可以改变函数传参的个数。我们掌握它的基本使用方法就行。
(1)改变传参顺序
以全局函数为例。
比如对于以下函数:
cpp
int fun(int a, int b)
{
return a - b;
}如果我们想改变这个函数的参数传递顺序呢?就可以使用bind来绑定它,使用方法如下所示:
cpp
int fun(int a, int b)
{
return a - b;
}
int main()
{
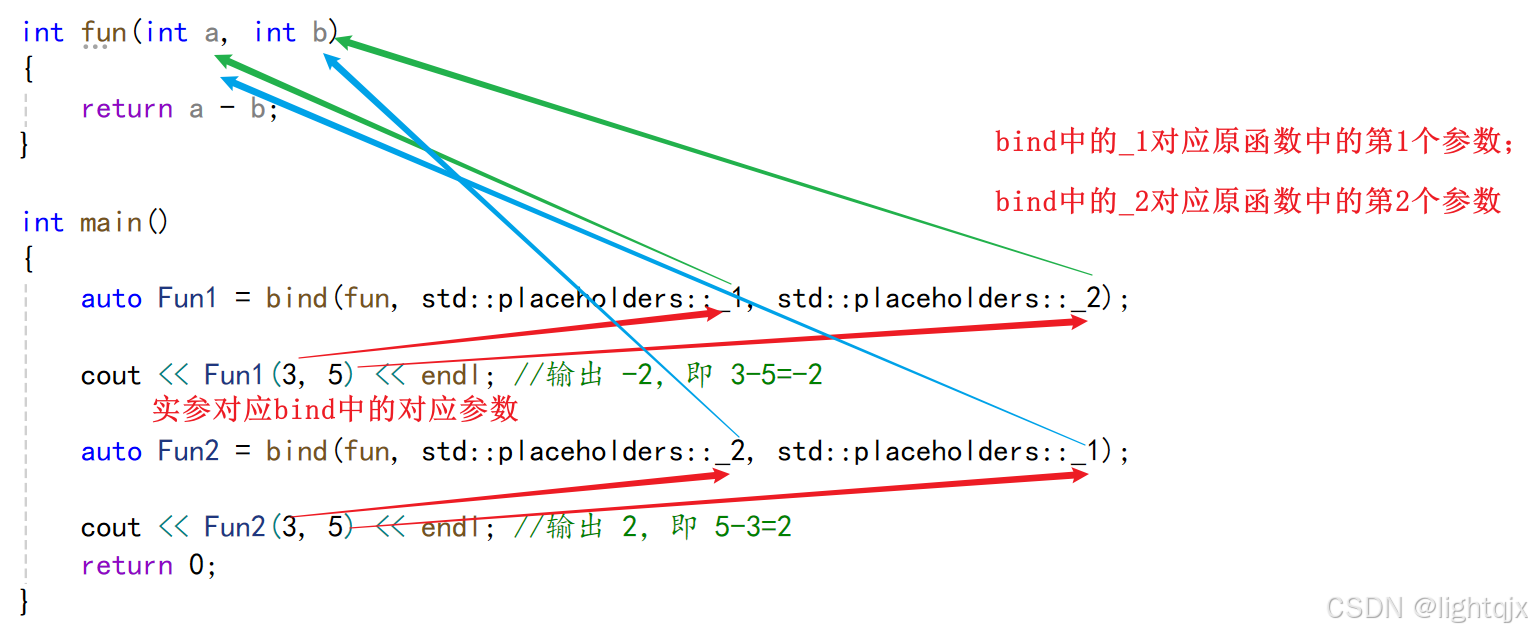
auto Fun1 = bind(fun, std::placeholders::_1, std::placeholders::_2);
cout << Fun1(3, 5) << endl; //输出 -2,即 3-5=-2
auto Fun2 = bind(fun, std::placeholders::_2, std::placeholders::_1);
cout << Fun2(3, 5) << endl; //输出 2,即 5-3=2
return 0;
}解释:
placeholders是一个命名空间,即: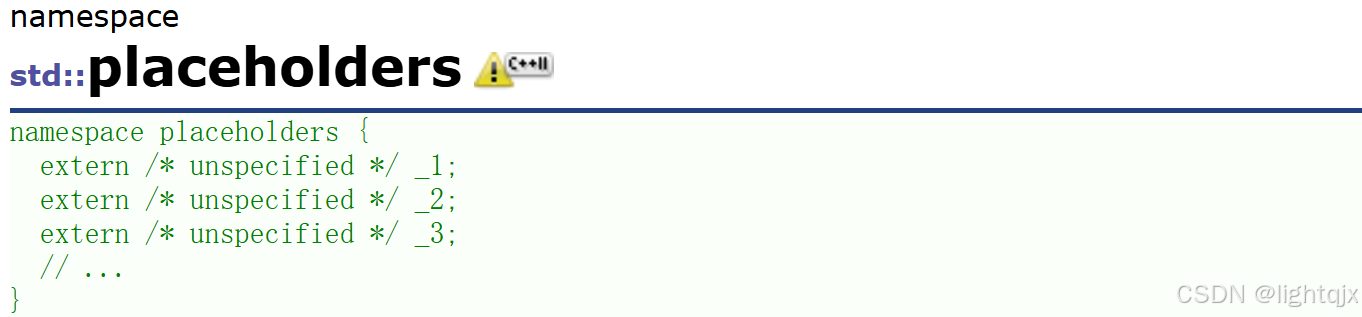
这里的_1就表示原本的函数中的第1个参数,_2表示第2个参数,_3表示第3个参数,_4表示第4个参数,...... 。
如果原本函数有m个参数,那么bind的时候,最高的就是_m,比如如果有三个参数,则这里placeholders中就是_1、_2、_3 。
(2)改变传参个数
以全局函数为例。
我们可以在bind的时候就设置参数值,这样就在调用绑定的函数时就可以少传递参数了。比如:
cpp
int fun(int a, int b, int c)
{
return (a - b) * c;
}
int main()
{
// 第三个参数指定为20
auto Fun1 = bind(fun, std::placeholders::_1, std::placeholders::_2, 20);
cout << Fun1(3, 5) << endl; //(3-5)*20 = -40
// 调用时就可以只传两个参数了
return 0;
}当然也可以指定第1个参数,或者第2个参数,则需要这样做:
cpp
int fun(int a, int b, int c)
{
return (a - b) * c;
}
int main()
{
// 第1个指定为20
auto Fun1 = bind(fun, 20, std::placeholders::_1, std::placeholders::_2);
cout << Fun1(3, 5) << endl; //(20-3)*5 = 85
// 第2个指定为20
auto Fun2 = bind(fun, std::placeholders::_1, 20, std::placeholders::_2);
cout << Fun2(3, 5) << endl; //(3-20)*5 = -85
return 0;
}要注意,这里的placeholders必须从_1开始,依次向后使用。比如如果原函数有4个参数,我们指定了1个,则placeholders就是_1,_2,_3,如果指定了2个,则就是_1,_2。
(3)对于类中成员函数的情况
对于类中的成员函数的绑定有两种:静态成员函数与普通的成员函数,它们的处理情况又有一些不同。比如对于下面这个类:
cpp
class FunClass
{
public:
static int fun1(int a, int b, int c) //静态成员函数
{
return (a - b) * c;
}
int fun2(int a, int b, int c)
{
return (a - b) * c;
}
};对于静态成员函数,它的绑定如下所示:
对于普通的成员函数,它的绑定如下所示:
如果是要改变参数顺序或个数的功能,和全局函数的使用是一样的(前面已经介绍了)。
最后要注意的是:
对于bind的底层认识其实和Lambda一样,底层都是一个重载了operator()的类。
感谢各位观看!希望能多多支持!