本节主要介绍常见的数据库对象之一的视图(View),他是一个或者多个数据表里的数据的逻辑显示,视图不存储数据。
1.视图概述
1.1 为什么使用视图
视图具有两大好处,一方面可以帮我们使用表的一部分而不是全部的表,另一方面可以针对不同的用户制定不同的查询视图。
eg:一个公司的销售人员,我们只想给看部分的数据,而特殊的数据比如采购价格,则不会给他权限查看;或者人员薪酬是个敏感的字段,他的开放往往只给某个级别之上的人开放,其他人的查询视图中不提供该字段。
1.2 视图的理解
- 视图是一种虚拟表,自身不具有数据,占用很少的内存空间;
- 视图建立在已有表的基础之上,视图赖以建立的这些表称为基表;
- 视图的创建和删除只影响视图本身,不影响对应的基表。但是当视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应的发生变化;
- 向视图提供数据内容的语句为SELECT语句,可以将视图理解为存储起来的SELECT语句。
2.创建视图
2.1 创建单表视图
示例1:
sql
CREATE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary
FROM emps;查询视图:
sql
SELECT * FROM vu_emp1;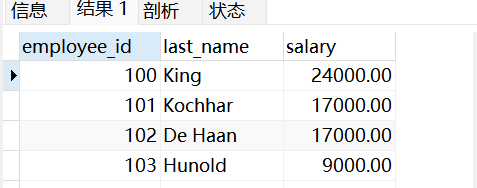
示例2:带别名
sql
CREATE VIEW vu_emp2
AS
SELECT employee_id emp_id,last_name lname,salary
FROM emps
WHERE salary>8000;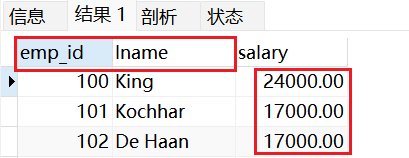
示例3:小括号中字段个数与查询语句字段数目相同
sql
CREATE VIEW vu_emp3(emp_id,lname,m_salary)
AS
SELECT employee_id,last_name,salary
FROM emps
WHERE salary>8000;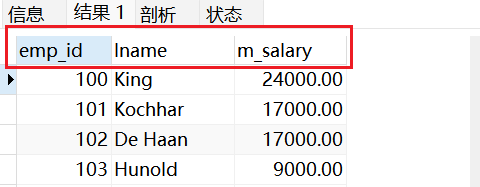
示例4:查看原表中不存在的内容
sql
CREATE VIEW vu_emp4
AS
SELECT department_id,AVG(salary)
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;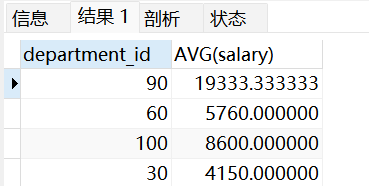
2.2 创建多表视图
示例1:
sql
CREATE VIEW vu_emp5
AS
SELECT e.employee_id,d.department_id,d.department_name
FROM emps e JOIN depts d
ON e.department_id = d.department_id;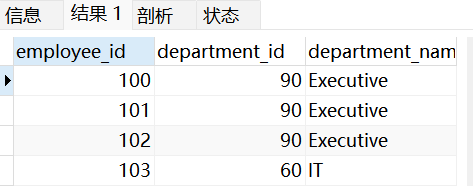
示例2:使用视图进行格式化表示
输出员工姓名和对应的部门名,对应格式为 emp_name(department_name),就可以使用视图来完成数据格式化的操作:
sql
CREATE VIEW vu_emp6
AS
SELECT CONCAT(e.last_name,'(',d.department_name,')') emp_info
FROM emps e JOIN depts d
ON e.department_id = d.department_id;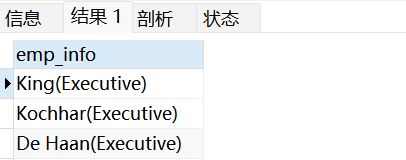
2.3 基于视图创建视图
当创建好一个视图之后,还可以在他的基础上继续创建视图。
示例:基于vu_emp1视图创建一个新的视图
sql
CREATE VIEW vu_emp7
AS
SELECT employee_id,last_name
FROM vu_emp1;3.查看视图
(1)查看数据库的表对象、视图对象
sql
SHOW TABLES;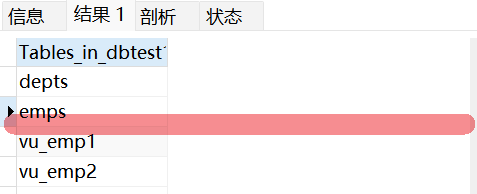
(2)查看视图结构
sql
DESC vu_emp1;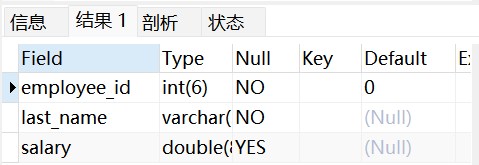
(3)查看视图属性信息
sql
# 显示数据表的存储引擎、版本、数据行数和数据大小等
SHOW TABLE STATUS LIKE 'vu_emp1';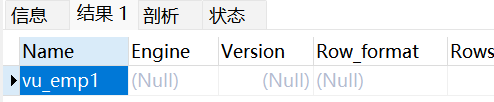
(4)查看视图详细定义信息
sql
SHOW CREATE VIEW vu_emp1;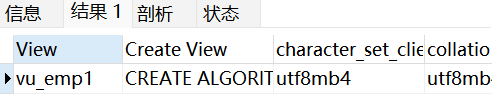
4.更新视图的数据
4.1 一般情况
MySQL支持使用INSERT、UPDATE和DELETE语句对视图中的数据进行插入、更新和删除操作。当视图中的数据发生变化时,数据表中的数据也会发生变化,反之亦然。
以UPDATE操作为例:
sql
UPDATE vu_emp1
SET salary = 25000
WHERE employee_id = 100;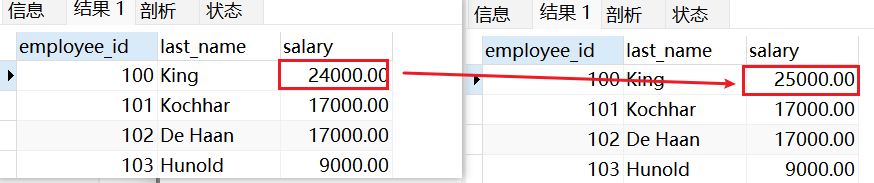
4.2 特殊情况
视图中数据的更新并不一定能够成功的,在一些情况下也会不支持更新操作。
例如:在定义视图的SELECT语句中使用了JOIN联合查询,视图将不支持INSERT和DELETE操作;
示例:上面我们创建了一个用于查询部门平均薪资的视图vu_emp4,如果对这个视图进行更新操作则行不通。
sql
UPDATE vu_emp4
SET AVG(salary) = 8000
WHERE department_id = 100;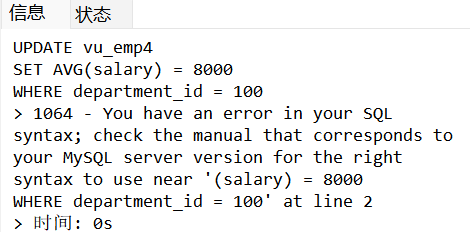
虽然可以更新视图数据,但总的来说,视图作为虚拟表,主要用于方便查询,不建议更新视图的数据。对视图数据的更改,都是通过对实际数据表里数据的操作来完成的。
5.修改、删除视图
5.1 修改视图
方式一:使用CREATE OR REPLACE VIEW 子句修改
sql
CREATE OR REPLACE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email
FROM emps
WHERE salary >7000;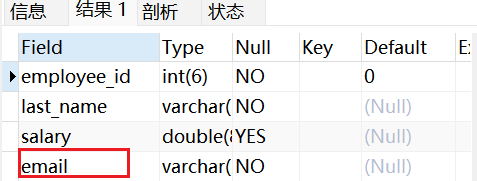
方式二:ALTER VIEW子句修改
sql
ALTER VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email,hire_date
FROM emps
WHERE salary >7000;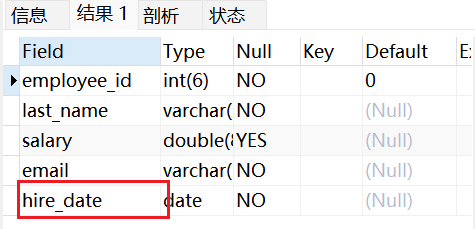
5.2 删除视图
删除视图仅仅是删除视图的定义,这不会删除基表中的数据。
sql
DROP VIEW IF EXISTS vu_emp5;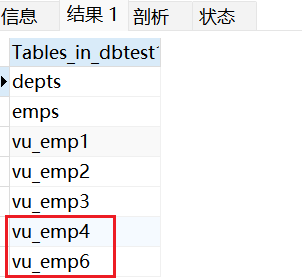
基于视图a、b创建了新的视图c,如果将视图a或者视图b删除,会导致视图c的查询失败。这样的视图c需要手动删除或修改,否则影响使用。
6.总结
6.1 优点
- 操作简单:将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简化了开发人员对数据库的操作。
- 减少数据冗余:视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。(类比创建一个子表)
- 数据安全:MySQL将用户对数据的
访问限制在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用户不必直接查询或操作数据表。这也可以理解为视图具有隔离性。视图相当于在用户和实际的数据表之间加了一层虚拟表。同时,MySQL可以根据权限将用户对数据的访问限制在某些视图上,用户不需要查询数据表,可以直接通过视图获取数据表中的信息。这在一定程度上保障了数据表中数据的安全性。 - 适应灵活的需求:当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多。
- 分解复杂的查询逻辑:数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
6.2 缺点
实际项目中,如果视图过多,会导致数据库维护成本的问题。 如果实际数据表的结构变更了,我们就需要及时对相关的视图进行相应的维护 。特别是嵌套的视图(就是在视图的基础上创建视图),维护会变得比较复杂,可读性不好,容易变成系统的潜在隐患。