🌟 写在前面
大家好,今天要解读的是一篇很有意思的 CVPR 论文------《ARoFace: Alignment Robustness to Improve Low-Quality Face Recognition》。这篇文章提出了一个全新的视角:低质量人脸识别失败的重要原因,可能不是图片本身的质量,而是对齐误差(Face Alignment Error, FAE)。
之前我们聊过 FIE(图像增强)和 CSM(公共空间映射)两条技术路线,今天这篇文章可以看作是 CSM 路线的一个巧妙变种------它不直接模拟图像质量的退化,而是模拟人脸对齐的误差。
目录
[🌟 写在前面](#🌟 写在前面)
[🎯 核心洞察:一个被忽视的问题](#🎯 核心洞察:一个被忽视的问题)
[1.1 惊人的发现](#1.1 惊人的发现)
[1.2 为什么这个问题被忽视了?](#1.2 为什么这个问题被忽视了?)
[🛠️ 方法详解:ARoFace](#🛠️ 方法详解:ARoFace)
[2.1 核心思想](#2.1 核心思想)
[2.2 技术框架](#2.2 技术框架)
[2.3 关键创新点](#2.3 关键创新点)
[创新二:基于 Landmark 的约束条件](#创新二:基于 Landmark 的约束条件)
[🔍 深度解析 ARoFace 核心公式](#🔍 深度解析 ARoFace 核心公式)
[1. 寻找"最难"的对齐误差(内部最大化)](#1. 寻找“最难”的对齐误差(内部最大化))
[2. 终极训练目标:左右互搏(Min-Max 优化)](#2. 终极训练目标:左右互搏(Min-Max 优化))
[3. 制定"游戏规则":基于关键点的约束](#3. 制定“游戏规则”:基于关键点的约束)
[4. 引入随机性:让模型见多识广](#4. 引入随机性:让模型见多识广)
[📝 总结](#📝 总结)
🎯 核心洞察:一个被忽视的问题
1.1 惊人的发现
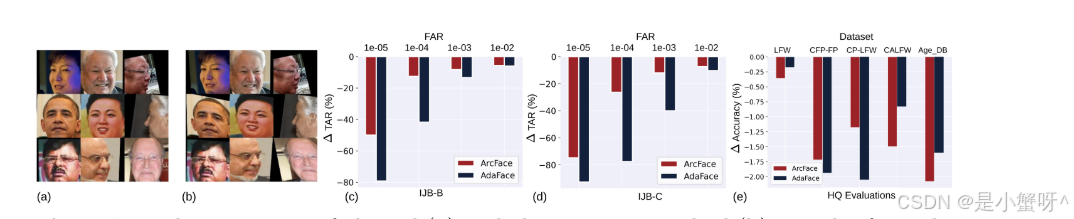
作者做了一个简单的实验:对已经对齐好的人脸图片,手动添加微小的空间变换(缩放、旋转、平移),然后观察识别性能的变化。
结果如图 1 所示:
-
高质量图片:模型对这些微小的对齐误差几乎无感,性能下降很小
-
低质量图片:同样的对齐误差,导致识别率断崖式下跌------TAR@FAR=1e-5 直接腰斩 50% 以上!
这个发现告诉我们:低质量图片本身已经很难识别了,再加上对齐误差,就成了压垮模型的最后一根稻草。
1.2 为什么这个问题被忽视了?
以往的低质量人脸识别研究,主要关注的是:
-
图像分辨率低怎么办?
-
模糊怎么办?
-
光照差怎么办?
但很少有人问:在低质量图片上,人脸检测和对齐的精度本身就会下降,导致输入到识别模型的人脸本来就是歪的------这个问题谁来管?
🛠️ 方法详解:ARoFace
2.1 核心思想
ARoFace 的目标很明确:让模型在对齐不准的情况下也能认对人。
怎么做?答案很直接:在训练时,故意给图片加一些对齐误差,让模型提前适应。
但这有一个关键问题:怎么加误差才能既有效,又不破坏图片的语义(比如让人脸变形到认不出)?
2.2 技术框架
ARoFace 的整体框架如图 2 所示,包含两个核心步骤:
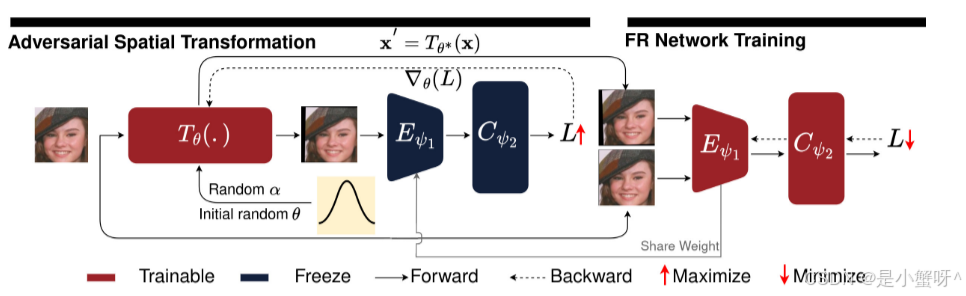
Step 1: 对抗性变换生成(内层最大化)
对于每个训练样本 x,我们要找到一个空间变换参数 θ,使得变换后的图片 ,对当前模型来说最难识别:
这个优化用投影梯度下降(PGD)求解,迭代 k 步。
Step 2: 模型训练(外层最小化)
用原始样本和对抗变换后的样本一起训练模型:
2.3 关键创新点
创新一:用空间变换模拟对齐误差
ARoFace 用的空间变换 包含三个分量:
-
旋转 :
-
平移 :
(水平和垂直)
-
缩放 :
这些变换通过可微分的 Spatial Transformer Network (STN) 实现,可以直接进行梯度反向传播。
创新二:基于 Landmark 的约束条件
传统对抗攻击常用 范数约束,但这对空间变换不适用------平移一个像素可能导致
距离剧增,但视觉上几乎没有感知差异。ARoFace 采用人脸关键点的位移作为约束集
:
其中:
-
-
-
该约束的优势在于:无需额外运行 Landmark 检测器,直接利用训练数据的对齐模板即可计算。
创新三:随机化步长增加多样性
为了让模型适应更真实的、非固定模式的对齐误差,ARoFace 将 PGD 攻击的步长 进行了随机化处理:
通过这种方式,同一张图片可以产生多种不同的对齐误差形态,从而显著增强模型的泛化能力。
🔍 深度解析 ARoFace 核心公式
1. 寻找"最难"的对齐误差(内部最大化)
为了让模型具备鲁棒性,首先要找出当前模型最害怕什么样的对齐偏差。这是通过对抗数据增强来实现的。
公式 (1):目标函数
【参数详解】
💡 通俗释义:
这个公式是让"攻击者"发力。它的目的是寻找一组空间变换参数 ,使得原本正常的图片
经过扭曲
后,能让当前的人脸识别网络
错得最离谱 (即损失函数
最大)。
为了求解上述的 ,作者使用了 PGD(投影梯度上升法),这引出了第二个公式。
公式 (2):PGD 迭代求解
【参数详解】
💡 通俗释义:
既然我们要找"最难"的图片,就顺着损失函数变大的方向(梯度方向)去修改变换参数 。每次改一点点(步长
),但绝对不能越界(用
兜底)。
2. 终极训练目标:左右互搏(Min-Max 优化)
找到了最难的对齐误差后,我们就要训练模型去克服它。
公式 (7):整体目标函数
【参数详解】
💡 通俗释义:
这就是深度学习中经典的"对抗训练"思想。中括号里有两部分:第一部分要求模型学好标准答案,第二部分要求模型学会应对最刁钻的变体。通过更新参数 使得两者总损失最小,模型就练成了"金钟罩",既认得准标准图,也不怕偏离图。
3. 制定"游戏规则":基于关键点的约束
在公式(2)中我们提到了约束空间 。传统的对抗攻击喜欢限制像素值的改变(比如
范数),但这在空间几何变换中不适用(图片整体平移1个像素,视觉上没变,但
差异极大)。因此,ARoFace 提出了基于 人脸关键点(Landmarks)的约束。
公式 (8):关键点位移约束
【参数详解】
💡 通俗释义:
图片可以歪,但五官不能乱跑!这个公式规定,无论 怎么旋转平移图片,五个人脸关键点的移动距离总和,不能超过我们设定的一个最大阈值。这就保证了变换后的图像依然是一张"合法"的人脸。
4. 引入随机性:让模型见多识广
如果每次攻击的套路都一样,模型容易过拟合。为了模拟真实世界中千奇百怪的对齐误差(FAE 的不确定性),作者对 PGD 的步长动了手脚。
公式 (9):带有随机步长的 PGD
【参数详解】
💡 通俗释义:
在找茬(生成对抗样本)的时候,每次探索的"步伐大小"都是随机的。这种随机性极大丰富了生成的空间变换种类,确保模型能在训练阶段见识到更多样、更复杂的对齐偏差。
📝 总结
ARoFace 的核心贡献可以概括为三点:
-
发现问题:首次指出对齐误差是低质量人脸识别失败的重要原因
-
提出方法:用对抗性空间变换模拟对齐误差,让模型提前适应
-
验证效果:在多个低质量数据集上显著提升,且与现有方法正交
这篇文章给我们的启发是:有时候问题不在你关注的地方,而在你习以为常的地方。当大家都在卷图像质量的时候,有人发现了"对齐"这个被忽略的角落,就找到了新的突破口。