ICML'25
在开始这篇论文之前,先说个背景。
swe-bench的训练集是没有docker镜像环境的。之前我们测试的时候使用的是test dataset,测试集是肯定要有镜像环境,不然如何测试代码到底能否运行?这个SWE-gym针对的就是训练集没有测试环境,所以agent修改完代码无法得到运行反馈开展的。
SWE-Gym 论文解决的问题:
- SWE-Bench 训练集 只有 git patch,没有 Docker 镜像
- 所以没法让模型在训练阶段获得"跑单元测试"这个反馈信号
Abstract
我们介绍 SWE-Gym,这是第一个用于训练软件工程(software engineering, SWE)智能体的环境。SWE-Gym 包含 2,438 个真实世界的任务实例,每个实例都包括一个 Python 代码库、一个可执行的运行时环境、单元测试unit tests 以及一个用自然语言描述的任务。我们使用 SWE-Gym 训练基于语言模型的 SWE 智能体SWE agents,在广受认可的 SWE-Bench Verified 和 Lite 测试集上实现了最高 19% 的解决率绝对提升。
我们还通过在 SWE-Gym 采样的智能体轨迹agent trajectories上训练过的验证器 **verifiers**trained on agent trajectories sampled from SWE-Gym,对推理时扩展进行了实验。与我们微调后的 SWE 智能体相结合,我们在 SWE-Bench Verified 和 Lite 上分别达到了 32.0% 和 26.0%,创下了开放权重 SWE 智能体的新最优水平。为促进进一步研究,我们公开发布了 SWE-Gym、模型权重及智能体轨迹数据。
1. Introduction
语言模型(LM)在自动化软件工程(SWE)任务方面展现出巨大潜力,这一点从 SWE-Bench(Jimenez 等,2024)和 Commit0(Zhao 等,2024)等基准测试的近期进展中可以得到最直观的体现。尽管基于语言模型的 SWE 智能体通过改进智能体-计算机交互界面agent-computer interfaces(Yang 等,2024)和提示策略prompting strategies(Wang 等,2024c)取得了显著的性能提升,但 SWE 智能体的进步始终受制于对闭源模型的依赖,针对底层语言模型本身的改进研究十分有限。
与对话(Ouyang 等,2022)、数学推理(Shao 等,2024;Yuan 等,2024)和网页导航(Pan 等,2024)等领域不同------在这些领域中,监督微调和强化学习已显著提升了语言模型的能力------软件工程领域目前缺乏合适的训练环境,而构建此类环境又面临独特的挑战。真实的软件工程任务要求与一个可执行的运行时环境进行交互,该环境需预先配置好相应的软件依赖software dependencies和可复现的测试套件reproducible test suites,以及其他必要条件。这些挑战在现有资源中均有所体现(见表1)。
Table 1: SWE-Gym is the first publicly available training environment combining real-world SWE tasks from GitHub issues with pre-installed dependencies and executable test verification. Repository-level: whether each task is situated in a sophisticated repository; Executable Environment: whether each task instance comes with an executable environment with all relevant dependencies pre-installed; Real task: whether task instruction is collected from human developers.
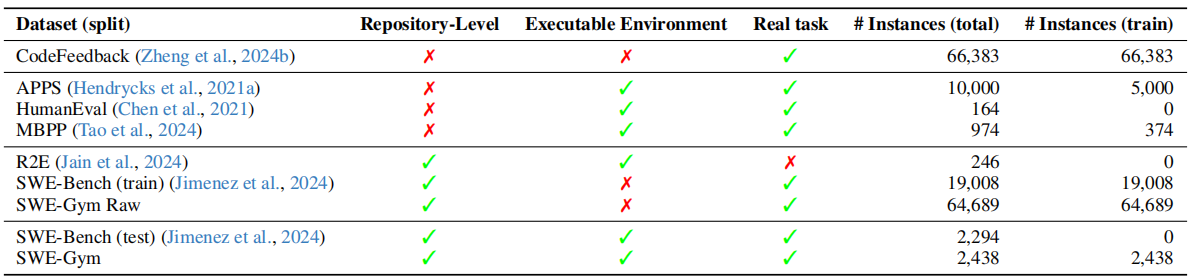
例如,SWE-Bench(Jimenez 等,2024)的训练集仅包含解决方案(即解决任务的 git 补丁),缺少开发者生成每个解决方案时所采取的逐步操作,以及可执行环境和奖励信号。R2E(Jain 等,2024)使用的合成任务与真实问题相去甚远,而 APPS(Hendrycks 等,2021a)等数据集则只关注孤立的编程任务,而非真实的仓库级代码问题。
为填补这一空白,我们提出了 SWE-Gym------第一个将来自 GitHub issue 的真实软件工程任务与预装依赖及可执行测试验证相结合的训练环境。SWE-Gym 包含来自 11 个热门开源代码仓库的 2,438 个 Python 任务(见表2),为将语言模型训练为智能体和验证器提供了实用的环境支撑。
Table 2: Statistics comparing SWE-Gym with the SWE-Bench test split (in parenthesis).
Except for size metrics, we report the average value across instances.
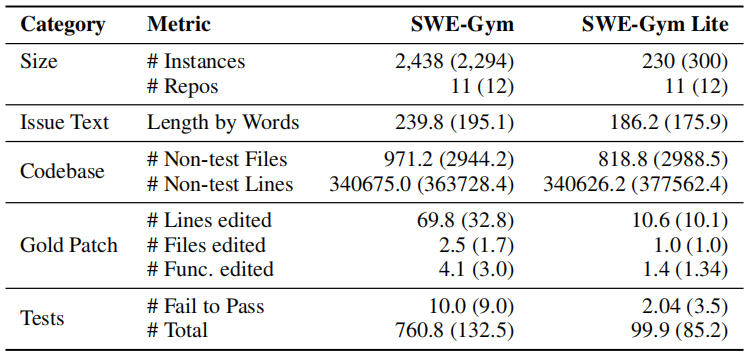
这张表是在比较 SWE-Gym 和 SWE-Bench 测试集(括号内是 SWE-Bench 的数据)的统计特征
Size(规模)
- Instances:任务数量。SWE-Gym 有 2,438 个,SWE-Bench 测试集有 2,294 个
- Repos:来自几个代码仓库。都是 11 个
Issue Text(issue 描述)
- Length by Words:issue 描述的平均词数。SWE-Gym 约 240 词,比 SWE-Bench 的 195 词更长,说明任务描述更复杂
Codebase(代码库)
- Non-test Files:非测试文件数量。SWE-Gym 平均 971 个文件,但 SWE-Bench 有 2,944 个,说明 SWE-Bench 的仓库更大
- Non-test Lines:非测试代码行数。两者都在 34 万行左右,量级相当
Gold Patch(标准答案补丁) 这三个指标最能说明任务难度:
- Lines edited:平均修改行数。SWE-Gym 是 69.8 行 ,而 SWE-Bench 只有 32.8 行,SWE-Gym 的任务改动量是 SWE-Bench 的两倍多
- Files edited:平均修改文件数。SWE-Gym 是 2.5 个文件,SWE-Bench 是 1.7 个
- Func. edited:平均修改函数数。SWE-Gym 是 4.1 个,SWE-Bench 是 3.0 个
Tests(测试)
- Fail to Pass:需要从失败变为通过的测试数。SWE-Gym 平均 10 个,SWE-Bench 是 9 个,差不多
- Total:总测试数量。SWE-Gym 平均 760 个,SWE-Bench 只有 132 个,说明 SWE-Gym 的测试套件规模大得多
SWE-Gym 支持训练最先进的开放权重 SWE 智能体。基于面向通用软件开发的 OpenHands(Wang 等,2024c)智能体框架agent scaffold(§2),我们仅使用从 SWE-Gym 中采样的 491 条智能体-环境交互轨迹对 32B Qwen-2.5 coder模型(Hui 等,2024b)进行微调,在 SWE-Bench Lite 和 SWE-Bench Verified 上的解决率分别取得了 +12.3%(达到 15.3%)和 +13.6%(达到 20.6%)的显著绝对提升(§4.2)。
SWE-Gym 在不同智能体框架下均表现有效。在另一个基于专用工作流的智能体框架agent scaffold(MoatlessTools;Örwall 2024;§2)中,我们进行了自我提升实验------语言模型与 SWE-Gym 交互,从中获得奖励信号,并通过拒绝采样微调来不断自我改进。这一自我提升机制使模型在 SWE-Bench Lite 上的性能最高提升至 19.7%。
SWE-Gym 支持训练验证器模型verifier models,从而实现推理时扩展。我们利用 SWE-Gym 中包含的测试套件来判断采样的智能体轨迹是否成功。
基于这些样本,我们训练了一个验证器模型verifier model(即结果监督奖励模型an outcome-supervised reward model;Cobbe 等,2021),用于估计一条轨迹的成功概率。这使得推理时扩展成为可能------我们对多条智能体轨迹进行采样,并根据验证器选择估计奖励最高的那条。这进一步将 SWE-Bench Verified 上的解决率提升至 32.0%(绝对提升 +11.4%)(§5.1.1;图1下),SWE-Bench Lite 上达到 26.0%(§5.1.2),在公开权重的系统中创下了新的最优水平(表9)。我们在 SWE-Gym 上的基线训练方法和推理时扩展方法随着算力的增加持续取得更好的结果(图1)。在训练阶段,性能随采样轨迹数量的增加而持续提升,直至我们当前 491 条轨迹的上限,这表明当前性能的瓶颈在于采样的算力预算,而非 SWE-Gym 中任务的数量。类似地,使用由 SWE-Gym 训练的智能体和验证器,图1下半部分表明,在推理阶段投入更多算力可以稳步提升性能。
为什么是"采样轨迹"?
这里的"轨迹"是指一次完整的 agent 解题过程,包括它看了哪些文件、执行了哪些命令、最终生成了什么补丁。采样的意思是让 GPT-4o 和 Claude 在 SWE-Gym 环境里真实跑任务,记录下整个过程。
为什么只有 491 条?
论文里明确说了:不是任务不够,是钱不够。 SWE-Gym 有 2,438 个任务,但每跑一次任务要调用 GPT-4o/Claude API,费用大概 $1 以上一个任务,还要启动 Docker 环境执行代码。491 条是他们算力预算的上限,论文也明确指出性能还没饱和,多采样还能继续涨。
你说得对,这就是 SFT,不是 RL。
具体做法是:
- 用 GPT-4o/Claude 在 SWE-Gym 跑任务,收集轨迹
- 只保留成功的轨迹(单元测试通过的)
- 用这 491 条成功轨迹对 Qwen-2.5-32B 做监督微调
这叫拒绝采样微调(Rejection Sampling Fine-tuning)------采样很多,拒绝掉失败的,只用成功的训练。本质上是模仿学习,不是 RL。
那为什么不做 RL?
论文也承认这个问题,在结论里把"用 PPO 等 RL 方法做自我改进"列为未来工作。他们也试过自我改进(用微调后的模型自己采样再训练),但效果反而下降了,说明简单的 on-policy SFT 在这个任务上还不够稳定。
SWE-Gym 和 SWE-Bench 来自完全不同的代码仓库。
"These repositories are separate from those used in SWE-Bench to avoid contamination."