作业:
从github上下载老师的资料
https://github.com/embedded-idea/AJourneyFrom0and1
1. 准备文件(关键!路径不能错)
- 在compiler这个文件下:
- ✅
compiler.py:课本里给的编译器源码(核心文件,实现编译逻辑); - ✅
program.asm:你要编译的汇编源文件(自己写的汇编代码,比如之前提到的main相关指令)。
2. 执行编译器(运行 Python 代码)
- 打开电脑的 "命令提示符(CMD)" 或 "终端";
- 先切换到这个文件夹的路径(cd /d "E:\Datawhale 2026\从零入门计算机系统202602\compiler");
- 输入运行命令:
python compiler.py;

- 回车执行,编译器会自动读取同目录的
program.asm,编译后生成program.bin(目标机器码文件)。
记事本打开.bin 文件显示乱码 → 正常现象,是文本编辑器解析二进制数据的必然结果。
用 Hex 编辑器或命令行查看十六进制机器码:在文件所在目录执行以下命令(Windows 系统):
certutil -dump program.bin输出文件的十六进制内容如下:

作业完成!
笔记:
编译器的定义、作用与工作流程,通过 C 编译器实例建立感性认知,掌握简易 Python 编译器的实现逻辑,抓住编译器 "高级表示转低级表示" 的核心本质。
一、编译器基础定义与核心作用
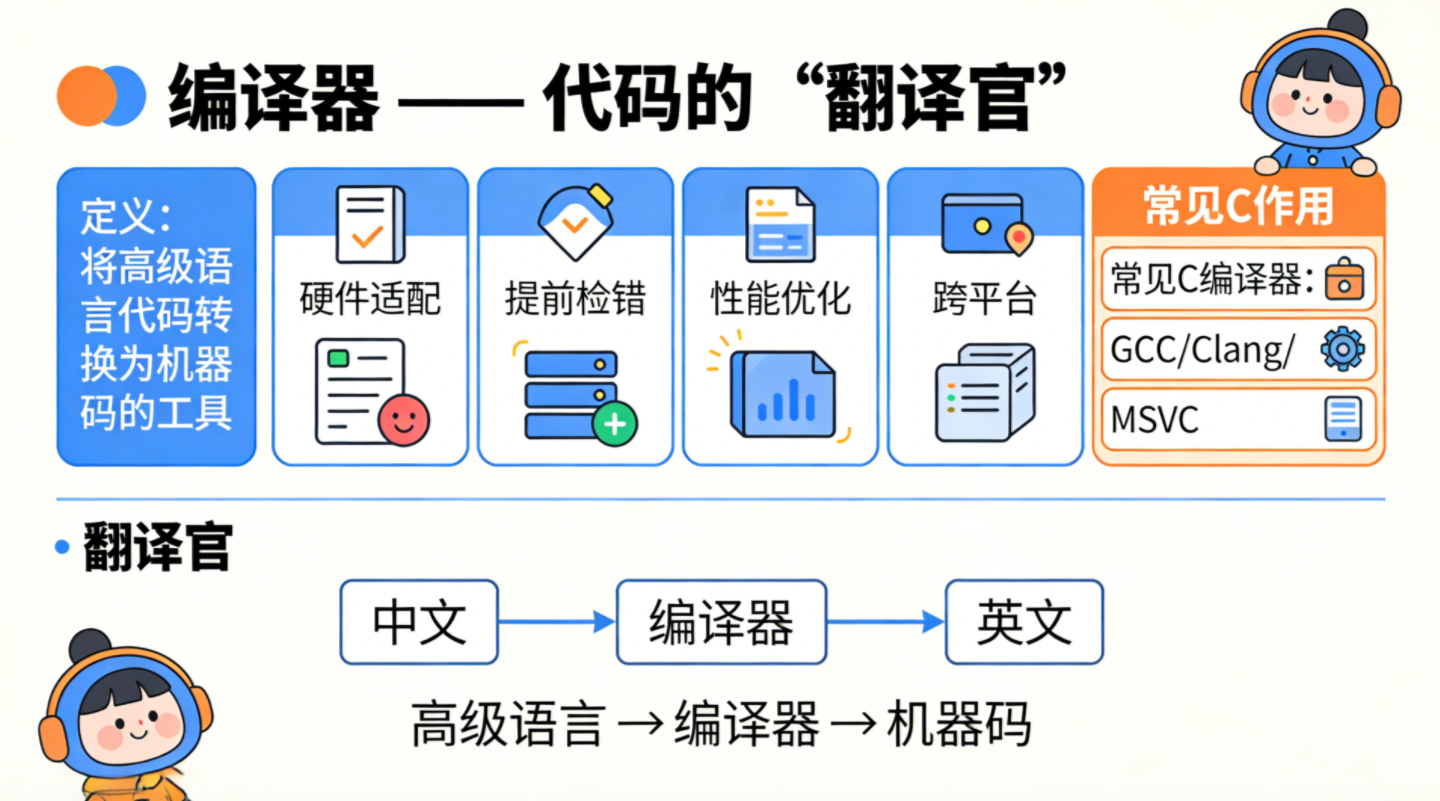
- 定义 :将人类编写的高级语言源代码 翻译为机器可执行的机器码目标程序的软件工具,不仅完成翻译,还会做错误检查和程序优化。
- 核心作用(为何需要编译器)
- 硬件适配:CPU 仅能识别机器码,高级语言必须经编译器转为指令序列才能运行;
- 提前检错:在程序运行前发现类型不匹配、变量未定义等语法 / 语义错误;
- 性能优化:通过循环优化、内联、寄存器分配等让程序运行更快;
- 跨平台特性:同一份源码可针对不同 CPU / 系统编译出对应的可执行文件 / 库。
二、编译器的形象类比与常见 C 编译器
- 类比 :编译器是高级语言(中文) 与机器语言(英文,0 和 1) 之间的 "翻译官",让计算机理解人类编写的代码;
- 常见 C 编译器:GCC(GNU Compiler Collection)、Clang(LLVM 的 C 语言前端)、MSVC(Microsoft Visual C++)。
三、C 语言编译器的翻译全流程
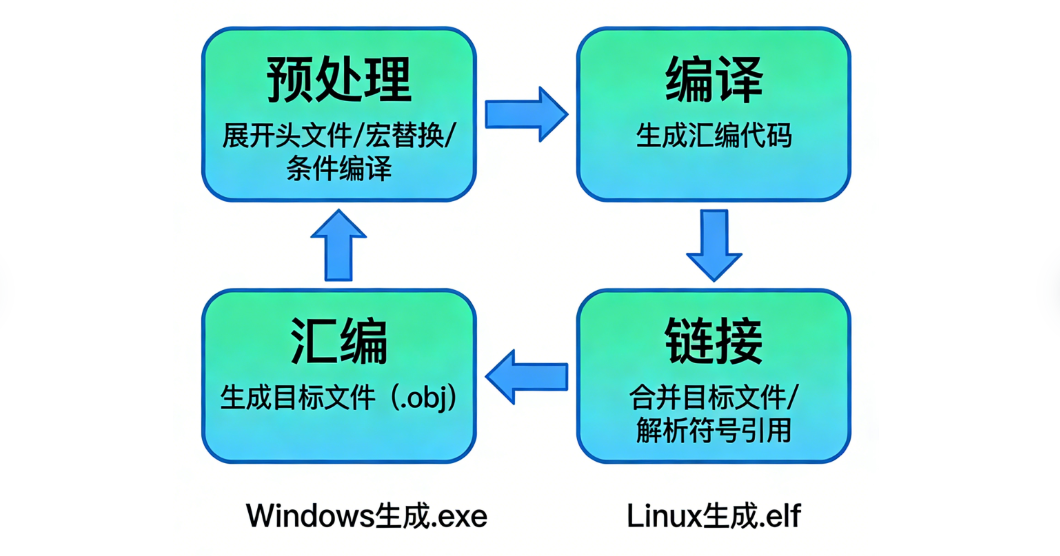
C 编译器将.c 源码转为可执行文件分为4 个核心阶段,最终 Windows 生成.exe 文件,Linux 生成.elf 文件:
- 预处理 :处理
#include(头文件包含)、#define(宏定义)等预处理指令; - 编译:把 C 语言源代码翻译为汇编语言;
- 汇编:把汇编语言进一步翻译为机器码;
- 链接:将多个目标文件、库函数组合,生成最终的可执行文件。
四、C 代码编译为汇编语言的实操解析
以int main(){int a=9;int b=19;return a+b;}为例
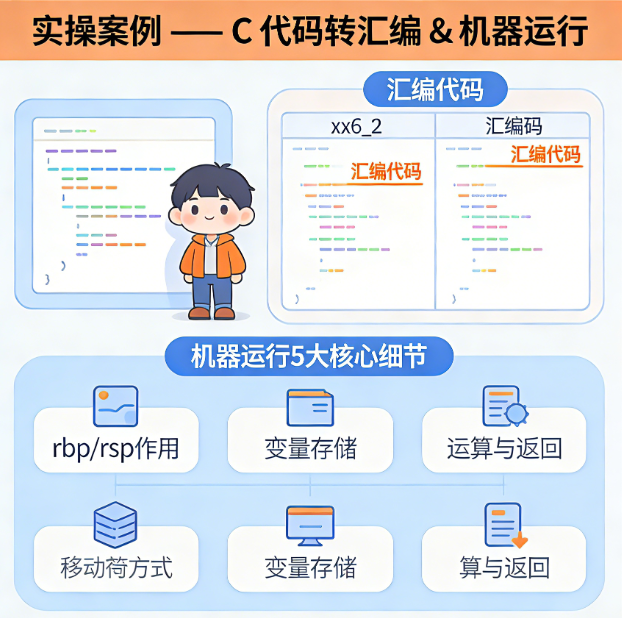
以 GCC 编译器、x86 架构 64 位处理器为环境,核心分为 3 步:
1. 词法 / 语义分析 + 中间表示(IR)
编译器将代码转为抽象语法树,生成中间表示,明确代码执行逻辑:
- 分配变量 a,赋值 9;分配变量 b,赋值 19;
- 执行 a+b 运算,返回运算结果。
2. 生成汇编语言(简化版,带核心注释)
asm
main:
push rbp ; 保存旧的栈帧指针
mov rbp,rsp ; 设置新的栈帧
mov DWORD PTR [rbp-4],9 ; 给int a赋值9,存储在栈中
mov DWORD PTR [rbp-8],19 ; 给int b赋值19,存储在栈中
mov eax,DWORD PTR [rbp-4] ; 把a的值加载到返回值寄存器eax
add eax,DWORD PTR [rbp-8] ; 把b的值加到eax,完成a+b
pop rbp ; 恢复旧的栈帧
ret ; 返回eax中的结果(a+b),作为程序退出码3. 机器运行时的核心细节
rbp/rsp:栈帧管理寄存器,负责保存 / 设置栈指针,处理函数调用;eax:约定俗成的返回值寄存器,用于存储函数的返回结果;- 局部变量 a、b:存储在栈中,对应 rbp 的偏移量位置;
- 真正的运算:由
add指令执行,最终通过ret指令将结果返回操作系统。
五、简易 Python 编译器的实现(核心:不到 200 行代码,覆盖编译器最小闭环)
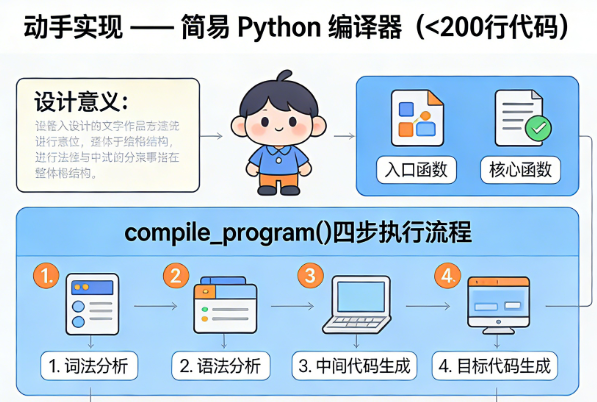
1. 整体结构
分为入口函数 和核心函数两部分,实现 "读源文件→预处理→译机器码→写目标文件" 的最小闭环:
表格
| 函数部分 | 核心职责 |
|---|---|
| 入口函数 | 调用核心编译函数,捕捉语法错误并提示,编译结束后输出compiling completed |
核心函数compile_program() |
编译器的核心,承担所有实质性编译工作 |
2. 核心函数compile_program()的执行步骤
- 读取源文件:打开同目录下的
program.asm汇编源文件,逐行读取并去除注释、多余空白; - 构造指令对象:为每条有效汇编指令构造
Code类对象,拆解操作码(OPcode) 和操作数(寄存器、立即数等); - 翻译机器码:调用
compile_code()方法,将汇编指令转为二进制机器码; - 写入目标文件:将机器码按顺序写入
program.bin文件,生成可在虚拟机 / 自制 CPU 上运行的可执行代码。
3. 运行与扩展说明
- 运行条件:机器安装 Python 环境,直接执行编译器脚本
compiler.py; - 文件要求:汇编源文件必须命名为
program.asm,且与编译器脚本在同一目录; - 扩展方向:可自行修改代码,实现动态指定源文件名、增加更多编译功能等。
六、总结
- 编译器的本质:高级表示(源代码 / 汇编)向低级表示(机器码)的转化工具,伴随检错、优化、链接等附加功能;
- 编译的核心逻辑:无论工业级还是简易编译器,都遵循 "读取源文件→预处理→翻译→生成目标文件" 的核心流程;
- 简易编译器的价值:覆盖编译器的最小闭环,是初学者入门编译原理的最佳实操范例,理解其逻辑即可抓住编译器的核心思想。
- 编译器是一款运行在电脑上的翻译软件,专门把程序员写的、人能看懂的高级语言代码,翻译成 CPU 能执行的机器码,同时还会检查代码错误、优化程序性能,它和 CPU 一个是软件、一个是硬件,没有从属关系。