OpenClaw-RL:让AI Agent在对话中自主学习进化
想象一下,你的AI助手每与你互动一次,就自动变得更懂你的偏好------无需额外标注,无需人工干预,仅仅是"在使用中学习"。这正是OpenClaw-RL带来的突破性范式:将每一次对话的"下一状态信号"转化为实时在线学习源,实现Agent的持续进化。
论文标题:OpenClaw-RL: Train Any Agent Simply by Talking
来源:arXiv:2603.10165v1 cs.CL + https://arxiv.org/abs/2603.10165
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
当前AI Agent系统的训练存在一个根本性浪费:每一次交互都会产生"下一状态信号"------用户的回复、工具执行结果、终端输出或GUI状态变化------但现有系统仅将其作为下一轮对话的上下文,而非学习信号。作者敏锐地指出,这些信号实际上蕴含两类宝贵信息:评估性信号(判断动作好坏)和指导性信号(指示应该如何改进)。然而,现有RL系统要么忽略这些信号,要么仅以离线方式利用,无法实现真正的实时在线学习。
研究问题
现有Agent训练面临三大核心缺陷:
- 信号浪费:每一个Agent交互都会生成下一状态信号,但现有agentic RL系统无一将其恢复为实时的在线学习源。
- 标量奖励的信息损失:传统RL方法将丰富的下一状态信息压缩为单一标量奖励,丢失了用户反馈中"应该如何改进"的方向性信息。
- 系统架构瓶颈:现有RL基础设施假设批量数据收集,而非从实时部署中持续学习,无法支持多流异构交互的同时训练。

主要贡献
作者提出了OpenClaw-RL框架,其核心贡献按重要性排序如下:
核心洞察:下一状态信号作为在线学习源。作者发现用户回复、工具输出、测试判决等下一状态信号编码了评估性和指导性两类信息,可被统一恢复为训练信号,适用于个人对话、终端、GUI、SWE、工具调用等所有Agent交互场景。
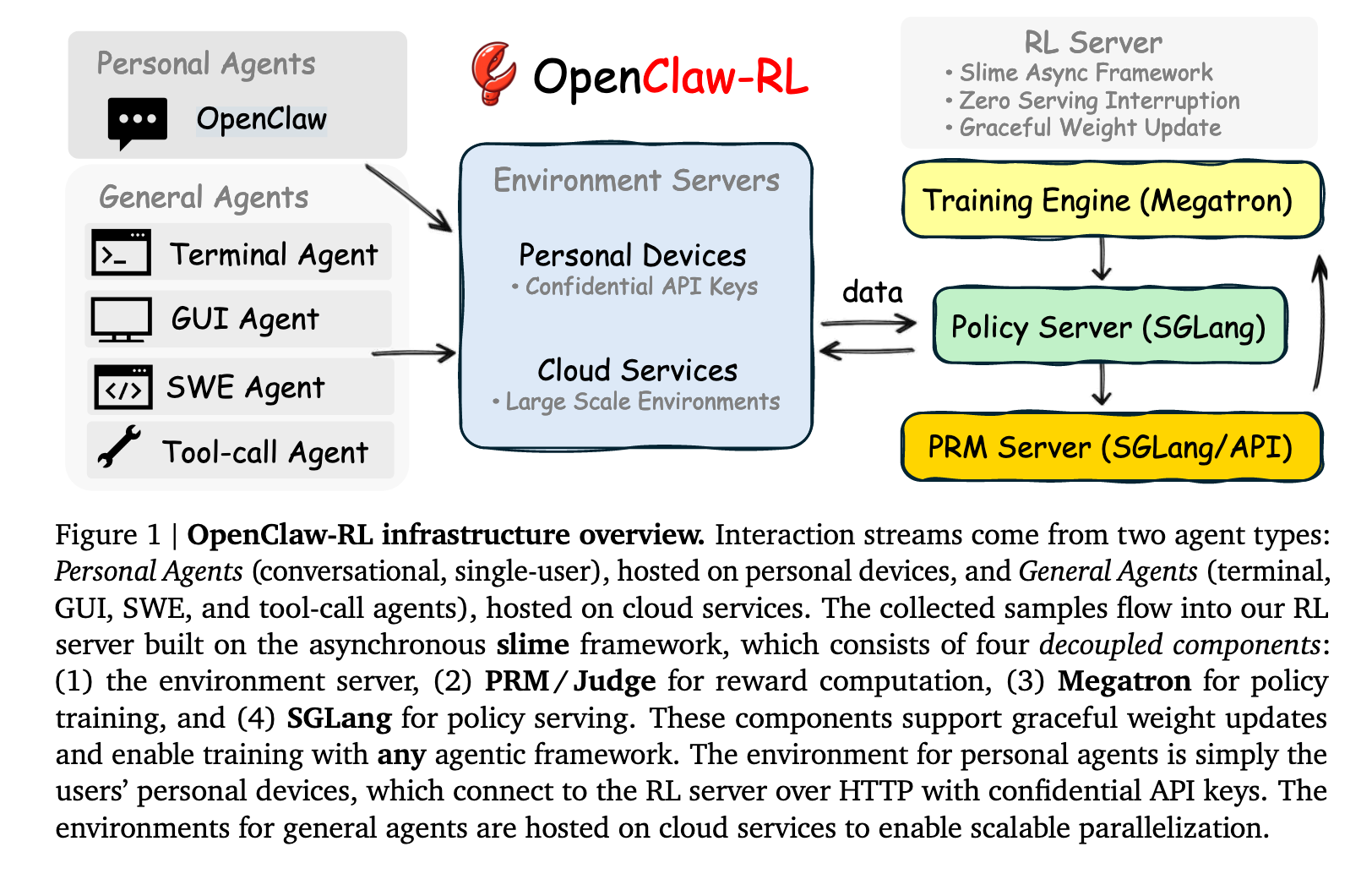
异步解耦架构。设计了四大完全解耦的异步组件:策略服务(SGLang)、环境托管、PRM评判(SGLang/API)、策略训练(Megatron)。各组件零阻塞依赖,模型服务请求的同时,PRM评判上一轮响应,训练器更新参数------三者互不等待。
双路径信号恢复方法。Binary RL通过PRM将评估性信号转换为密集标量过程奖励;Hindsight-Guided On-Policy Distillation(OPD)从下一状态提取文本提示,构建增强教师上下文,提供token级别的方向性监督。两者结合可实现显著增益。
跨场景实证验证。在个人Agent和通用Agent(终端、GUI、SWE、工具调用)两类场景下全面验证,证明框架的有效性和可扩展性。
方法论精要
问题形式化
OpenClaw-RL将每个交互流形式化为MDP ( S , A , T , r ) (\mathcal{S}, \mathcal{A}, \mathcal{T}, r) (S,A,T,r):状态 s t s_t st为完整对话或环境上下文;动作 a t a_t at为策略 π θ \pi_\theta πθ生成的token序列;转移 T ( s t + 1 ∣ s t , a t ) \mathcal{T}(s_{t+1}|s_t, a_t) T(st+1∣st,at)确定性取决于环境;奖励 r ( a t , s t + 1 ) r(a_t, s_{t+1}) r(at,st+1)通过PRM从下一状态信号推断。
关键洞察在于:标准RLVR仅使用最终结果 o o o作为轨迹奖励,但过程奖励 r ( a t , s t + 1 ) r(a_t, s_{t+1}) r(at,st+1)包含更丰富的信号。特别是当下一状态包含"应该如何改进"的明确指导信息时,可通过在线蒸馏实现方向性改进。
异步流水线架构
核心架构原则是完全解耦。策略服务、环境托管、PRM评判、策略训练作为四个独立异步循环运行,彼此零阻塞依赖。这使得从实时异构交互流持续训练变得可行:无需暂停或批量任何流以适配其他组件的调度。

对于个人Agent,模型通过保密API连接以保障私有安全部署,无需修改个人Agent框架,并可优雅更新权重而中断推理。对于大规模通用Agent训练,异步设计允许各组件独立进行,缓解长程rollout导致的尾部问题。

Binary RL:评估性信号恢复
给定响应 a t a_t at和下一状态 s t + 1 s_{t+1} st+1,评判模型评估 a t a_t at质量:
PRM ( a t , s t + 1 ) → r ∈ { + 1 , − 1 , 0 } \text{PRM}(a_t, s_{t+1}) \rightarrow r \in \{+1, -1, 0\} PRM(at,st+1)→r∈{+1,−1,0}
具体而言,PRM根据用户下一响应或工具调用结果评判每个动作。工具调用结果通常有明确结论;用户下一响应可能包含满意或不满意信号。若无明确用户反应迹象,模型也会根据场景估计,同时鼓励用户提供更明确反馈。
系统运行 m m m次独立查询,取多数投票 r f i n a l = MajorityVote ( r 1 , ... , r m ) r_{final} = \text{MajorityVote}(r_1, \ldots, r_m) rfinal=MajorityVote(r1,...,rm)。训练目标采用PPO风格的裁剪代理目标:
L p g = − E t min ρ t A t , clip ( ρ t , 1 − ε , 1 + ε h i g h ) ⋅ A t \mathcal{L}_{pg} = -\mathbb{E}_t \min\left\\rho_t A_t, \\text{clip}(\\rho_t, 1-\\varepsilon, 1+\\varepsilon_{high}) \\cdot A_t\\right Lpg=−EtminρtAt,clip(ρt,1−ε,1+εhigh)⋅At
其中 ρ t = π θ ( a t ∣ s t ) / π o l d ( a t ∣ s t ) \rho_t = \pi_\theta(a_t|s_t) / \pi_{old}(a_t|s_t) ρt=πθ(at∣st)/πold(at∣st), ε = 0.2 \varepsilon = 0.2 ε=0.2, ε h i g h = 0.28 \varepsilon_{high} = 0.28 εhigh=0.28。
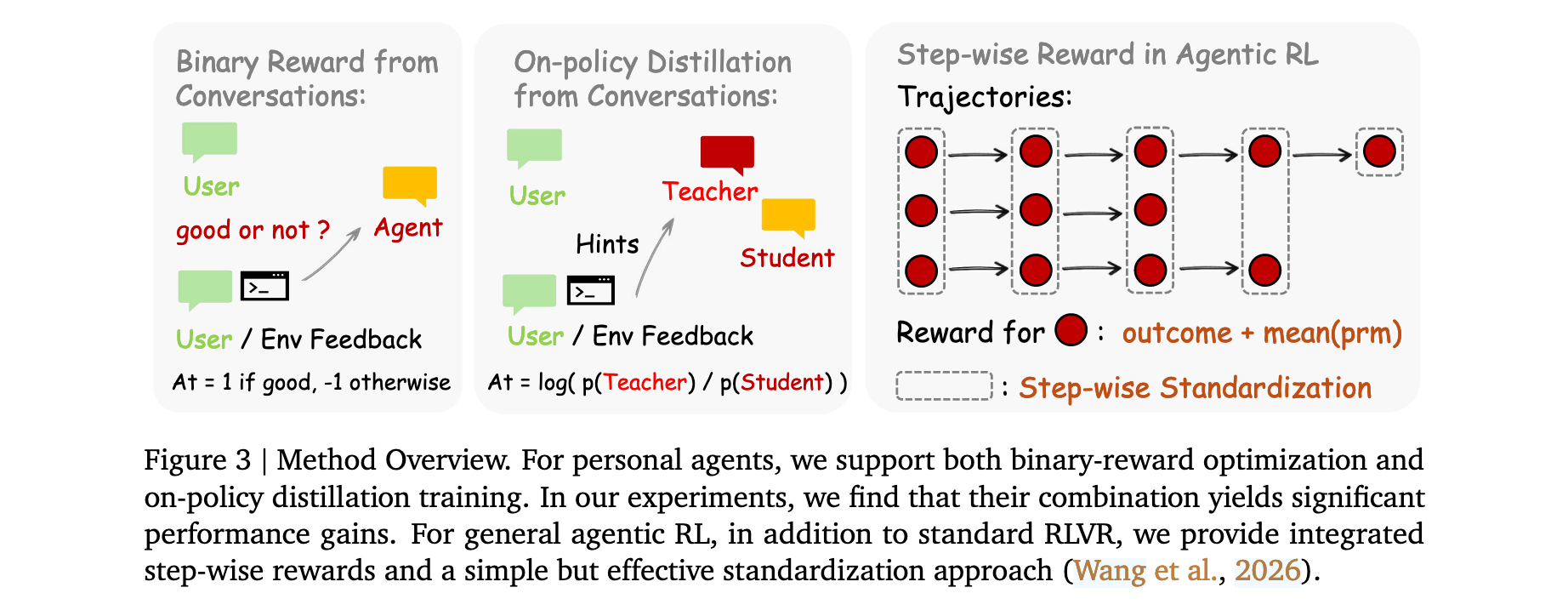
Hindsight-Guided OPD:指导性信号恢复
Binary RL将 s t + 1 s_{t+1} st+1的全部信息内容压缩为单一标量 r ∈ { + 1 , − 1 , 0 } r \in \{+1, -1, 0\} r∈{+1,−1,0}。然而,用户说"你应该先检查文件再编辑"传达的信息远不止此:不仅表示响应错误,还指出哪些token应该不同、如何不同。这种方向性信息被标量奖励完全丢失。
OPD通过将下一状态信号转换为token级别训练信号来恢复这些信息。核心洞察是:如果用从 s t + 1 s_{t+1} st+1提取的文本提示增强原始prompt,同一模型会产生不同的token分布------"知道"正确响应应该是什么样的。提示增强分布与学生分布的逐token差距提供方向性优势:在应该增强的token处为正,在应该抑制的token处为负。
步骤1:后见提示提取。评判模型生成简洁的可操作指令:
Judge ( a t , s t + 1 ) → { score ∈ { + 1 , − 1 } , hint ∈ T ∗ } \text{Judge}(a_t, s_{t+1}) \rightarrow \{\text{score} \in \{+1, -1\}, \text{hint} \in \mathcal{T}^*\} Judge(at,st+1)→{score∈{+1,−1},hint∈T∗}
若score = +1,产生[HINT_START]...[HINT_END]格式的简洁提示。关键设计选择是不直接使用 s t + 1 s_{t+1} st+1作为提示------原始下一状态信号往往嘈杂冗长,评判模型将其蒸馏为简洁可操作的指令。
步骤2:提示选择与质量过滤。在带有超过10字符提示的正投票中,选择最长的(信息最丰富的)。若无有效提示,则丢弃样本------OPD以样本数量换取信号质量。
步骤3:增强教师构建 。提示附加到最后用户消息形成增强prompt s e n h a n c e d = s t ⊕ hint s_{enhanced} = s_t \oplus \text{hint} senhanced=st⊕hint。
步骤4:Token级别优势 。在 s e n h a n c e d s_{enhanced} senhanced下查询策略模型,强制输入原始响应 a t a_t at,计算每个响应token的对数概率:
A t = log π t e a c h e r ( a t ∣ s e n h a n c e d ) − log π θ ( a t ∣ s t ) A_t = \log \pi_{teacher}(a_t|s_{enhanced}) - \log \pi_\theta(a_t|s_t) At=logπteacher(at∣senhanced)−logπθ(at∣st)
A t > 0 A_t \gt 0 At>0表示教师(知道提示)对该token赋予更高概率,学生应增强; A t < 0 A_t \lt 0 At<0表示教师认为该提示下token不太合适,学生应抑制。这与所有token推向同一方向的标量优势根本不同,提供逐token方向性指导。
双方法组合
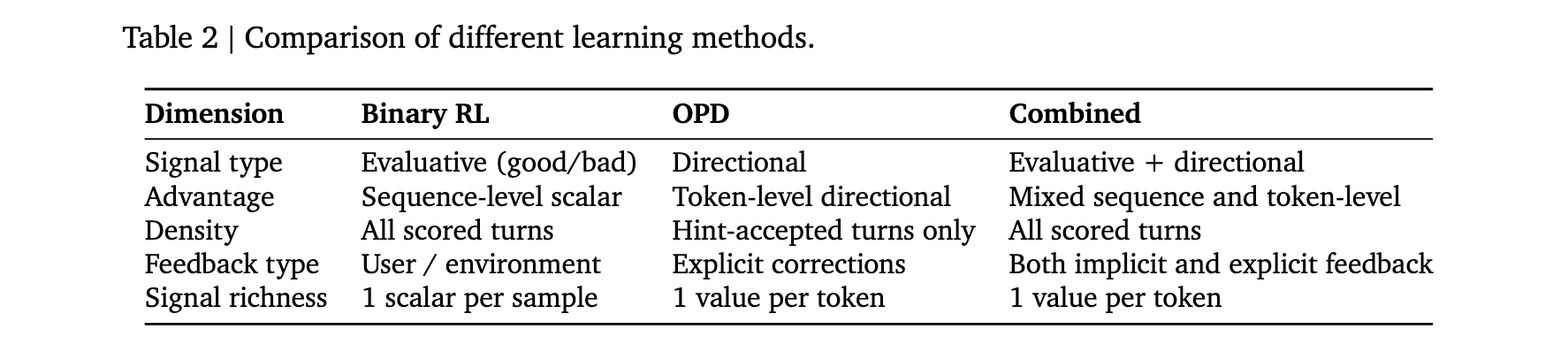
Binary RL与OPD互补而非竞争。Binary RL接受每个评分轮次,无需提示提取,适用于任何下一状态信号;OPD在交互流可能携带丰富指导内容时额外启用。实践中推荐同时运行两者:Binary RL提供跨所有轮次的广泛梯度覆盖,OPD在对有方向性信号的轮次提供高分辨率逐token修正。
组合优势采用加权损失:
A t = w b i n a r y ⋅ r f i n a l + w o p d ⋅ ( log π t e a c h e r ( a t ∣ s e n h a n c e d ) − log π θ ( a t ∣ s t ) ) A_t = w_{binary} \cdot r_{final} + w_{opd} \cdot (\log \pi_{teacher}(a_t|s_{enhanced}) - \log \pi_\theta(a_t|s_t)) At=wbinary⋅rfinal+wopd⋅(logπteacher(at∣senhanced)−logπθ(at∣st))
默认 w b i n a r y = w o p d = 1 w_{binary} = w_{opd} = 1 wbinary=wopd=1。
通用Agent的过程奖励
在长程Agent任务中,仅结果奖励只在终止步骤提供梯度信号,绝大多数轮次无监督。PRM根据下一状态信号为每轮分配奖励,提供轨迹全过程的密集信用分配。
集成结果与过程奖励采用简单相加: o + 1 m ∑ i = 1 m r i o + \frac{1}{m}\sum_{i=1}^m r_i o+m1∑i=1mri作为步骤 t t t的奖励。由于存在步骤级奖励,优势计算采用同步骤索引的动作分组。
实验洞察
个人Agent轨迹:对话信号学习
作者设计了两个模拟场景验证方法有效性:
学生场景:使用OpenClaw完成作业的学生,不希望被发现使用AI。使用GSM8K数据集,Qwen3-4B模型。评估以相同LLM模拟器对OpenClaw首次生成解答打分。
教师场景:使用OpenClaw批改作业的教师,希望评语具体友好。
实验结果表明,组合方法在学生场景仅需36次问题求解交互、教师场景仅需24次批改交互即可实现显著可见改进。如表3所示,组合方法更新16步后得分为0.81,远超Binary RL(0.23)和OPD(0.72)单独使用。
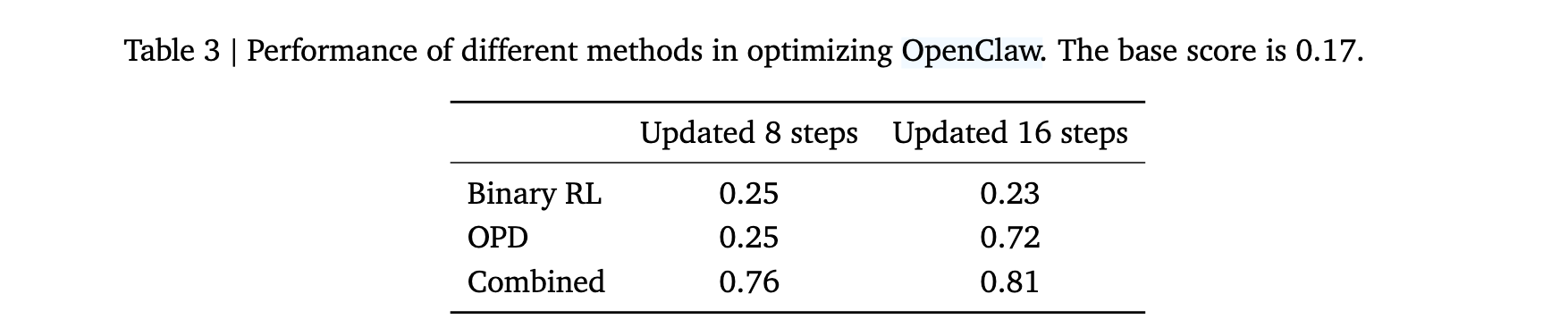
优化效果具体体现为:学生场景下,Agent学会避免明显AI化表达(如"bold"词汇、过度结构化的步骤响应),转向更自然随意的风格;教师场景下,Agent学会撰写更友好详细的反馈。
通用Agent轨迹:跨场景统一RL
在终端、GUI、SWE、工具调用四种场景下验证框架竞争力。使用Qwen3-8B、Qwen3VL-8B-Thinking、Qwen3-32B、Qwen3-4B-SFT分别作为终端、GUI、SWE、工具调用Agent的基础模型。大规模环境并行化(终端128、GUI/SWE各64、工具调用32个并行环境)进一步提升RL训练可扩展性。
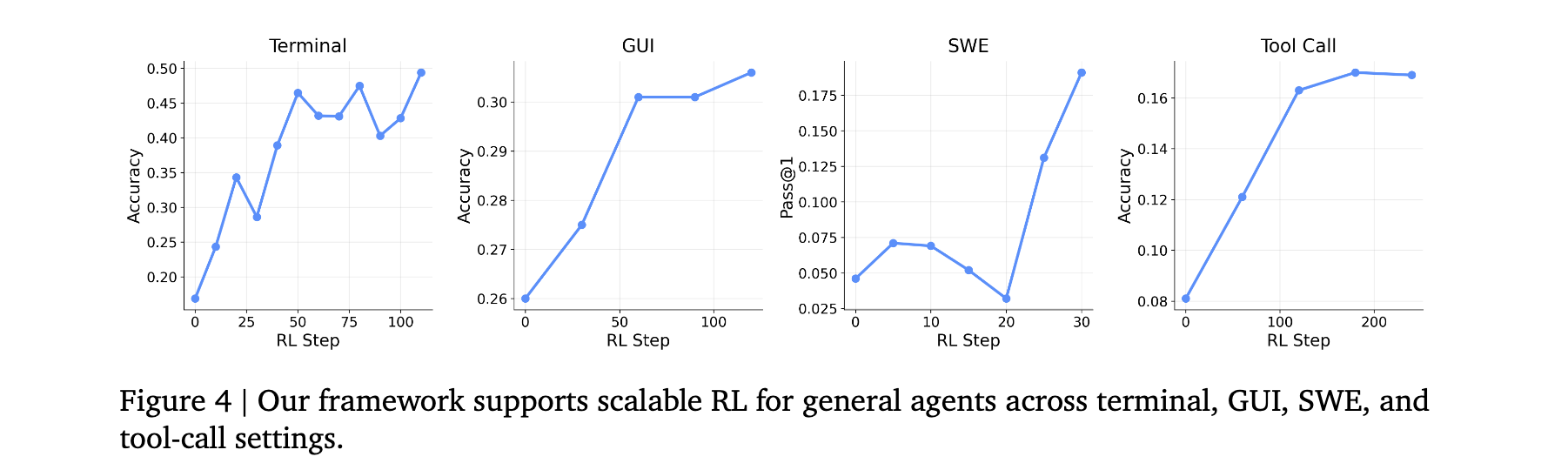

过程奖励有效性验证显示(表4),集成结果与过程奖励的工具调用场景准确率达0.30(vs 仅结果奖励0.17),GUI场景达0.33(vs 0.31)。权衡在于托管PRM需要额外资源。
作者强调,这证明了同一框架可同时支持个人Agent个性化与长程Agent任务的大规模RL训练------全部源自其已进行的交互,无需任何数据预收集阶段。