sss
HTML 不只是"整页文件",也可以是"片段结构数据"。
例如这不是完整页面,只是一个 HTML 片段:
<ul> <li>第一点</li> <li><strong>第二点</strong></li> </ul>
浏览器会把它解析成 DOM 树(节点结构):
- ul 节点
- 里面两个 li 子节点
- 第二个 li 里还有 strong 子节点
这就叫"解析成 HTML 结构"。
你现在代码用 textContent,效果是把 <li>...</li> 当普通文字写进去,不会变成节点。
如果用 innerHTML(或 createElement 创建节点并 append),才是在写"结构"。
所以答案是:
- 完整页面是 HTML 的一种形式(含 html/head/body)。
- 编辑器里常用的是 HTML 片段,也是一种可操作的数据结构。

Range 是浏览器 DOM 里的"选区片段对象"。
它表示文档中一段连续区域,用两个边界定义:
- startContainer + startOffset
- endContainer + endOffset
你可以把它理解为"光标/选中范围的结构化坐标",不是纯文本。
常见用法:
- window.getSelection().getRangeAt(0):拿当前选区的第一个 Range
- range.cloneContents():复制该范围内的 DOM 结构(可保留标签)
- range.deleteContents():删除范围内容
- range.insertNode(node):在范围处插入节点
所以你这次改动里,用 Range.cloneContents() 才能拿到 HTML 结构,而不只是字符串
Toast提示风格核心特点(2025-2026标准):
- 极简单行文本(推荐15-45字符)
- 直接完成式表述,省略主语和多余副词
- 无感叹号、无完整长句
- 常用过去分词开头(如 "Appended successfully")
- 自动消失(2-5秒),底部居中或角落显示
 radial 不是贴图通道,也不是自动的 T/B;它是"基于中心点和轴现场算出来的方向
radial 不是贴图通道,也不是自动的 T/B;它是"基于中心点和轴现场算出来的方向
你理解对。radial 就是"辐射状、从中心向外"的意思。
在图形里通常指两类方向:
- 径向方向
- 从中心指向点:R = normalize(P - C)
- 环向方向(围着轴转)
- T = normalize(cross(Axis, R))
Blender 的 Radial Tangent 名字里有 Tangent,所以它更偏第 2 类(环向切线),不是单纯第 1 类径向向量。

不是为了"球形法线"的视觉效果,而是为了定义各向异性反射的主方向场(anisotropy direction field)。
Radial Tangent 的核心用途是:
在没有可靠 UV tangent,或需要"绕某个轴旋转的方向场"时,提供一个连续、可控、与几何结构匹配的切线方向。
它解决的是 BRDF 方向性问题,而不是法线重建问题。

如果你不提供合理的 T,拉伸高光的方向就不可控。
Radial Tangent 提供的是:
T = normalize( axis × (P − C) )
这意味着:
• T 在表面上是绕轴旋转的
• 它在空间中连续
• 它不依赖 UV
• 它不会因为 UV 接缝产生跳变
这对头发、刷金属、旋转加工件、瞳孔、车漆拉丝等非常重要。


可以这样"泛化"理解,但在技术语境里需要分层,否则容易把不同现象混在一起。
严格的物理定义里:
各向异性(anisotropy)指的是 BRDF 在切平面内对不同方向响应不同 。
也就是说,分布函数 D(h) 在 T/B 两个主方向上具有不同的粗糙度参数(例如 αx ≠ αy)。
这是微表面模型层面的定义。
你说的那种"只要用 TBN 和 V 影响高光形状就算各向异性",其实包含三种不同类别:
第一类:真正的各向异性 NDF
例如:
-
GGX Anisotropic
-
Ashikhmin--Shirley
-
Ward
-
Hair models
特征是:
D(h) = f( (h·T)/αx , (h·B)/αy )
高光拉伸方向取决于 TBN,并且在旋转物体时会真实跟着材质方向走。
这是严格意义上的 anisotropic BRDF。
为什么要区分?
因为从渲染方程角度看:
BRDF 各向异性 = 微表面统计分布各向异性
而不是"高光形状看起来拉长"。
如果你在 SIGGRAPH 语境下说:
"anything using TBN to shape highlight is anisotropic"
那会被认为是不严谨的。
更准确的说法应该是:
"directionally-dependent specular shaping"
或者:
"anisotropic appearance"
_HighlightLength 只改阈值宽度,不改方向。
"横/竖"由 bDotMixV 的等值线决定,而等值线由这两件事决定:
- 方向(你现在的 B/Radial Tangent 定义)
- mixV(你的视角偏移向量)
为什么会变"竖向":
- 你把旧的特殊 B 换成了 Radial Tangent(环向方向场),方向场本身就变了。
- abs(dot(...)) 做的是"与该方向的夹角门控",结果条带总是和该方向场正交出现。
- 所以你看到的是"竖向 clamp",本质是当前方向场在该区域对应竖向,不是 _HighlightLength 把它变竖了。
一句话:length 控宽度,dot 里的方向定义控朝向。
你这个现象在 SkinnedMeshRenderer 上是正常的:你在 Inspector 里改"头发那一层 GameObject 的 Transform",并不等价于改 shader 里看到的 Object Space 原点。
原因是:SkinnedMesh 的"对象空间/对象矩阵"在渲染时往往不是用这个子物体的 Transform 来定义的,而是由 蒙皮根骨骼(Root Bone)/骨骼矩阵链决定,Unity 会把很多"对象 Transform 的位移"吸收到 skinning 的矩阵里,让最终顶点世界位置不变,从而你看到:
-
Scene 里 pivot 小工具位置变化(编辑器层面的 Transform gizmo)
-
但 shader 里你用的
positionOS、unity_ObjectToWorld对应的"渲染对象空间"不按你想的动
结合你截图右侧:Skinned Mesh Renderer 的 Root Bone = Root (Transform)。这通常意味着 Unity 在绘制这个 skinned renderer 时,把"对象到世界"的参考系锚在 Root Bone(或与其等价的空间)上,而不是你这个 hair 子节点的 Transform。
渲染层面的"对象空间"
SkinnedMesh 的顶点变换是:
P_ws = Σ( weight_i * (BoneMatrix_i * P_bind) )
其中 BoneMatrix_i 通常是:
M_bone_world * M_bindpose_i
关键点:
SkinnedMeshRenderer 渲染时用的"对象到世界矩阵"往往等价于:
unity_ObjectToWorld ≈ rootBone.localToWorldMatrix
而不是这个 hair 子节点的 transform.localToWorldMatrix。
这是为了保证蒙皮空间一致,避免双重 TRS。
因此在 shader 里:
-
positionOS 是"绑定姿态对象空间"
-
unity_ObjectToWorld 更接近 rootBone 空间
所以你看到的现象是:
改 hair Transform.position
→ Scene 里 gizmo 变了
→ 但 shader 里的 object origin 不跟着变
因为渲染空间锚在 rootBone。
不是"每个模型都这样"
普通 MeshRenderer:
unity_ObjectToWorld 就是它自己的 transform.localToWorldMatrix。
SkinnedMeshRenderer:
通常锚在 rootBone。
你的推理是对的:只记录"相对 root 的静态偏移"在动画里不成立。头骨相对 root 的位移/旋转是每帧变化的(尤其是颈部链条、呼吸、跑跳、上半身 IK、表情/附加骨等),所以 center 必须跟着骨骼更新。
但结论不一定是"只能 CPU 每帧写参数、浪费带宽"。有三个层级的实现选项,你可以按成本/准确度选。
-
最简单且通常足够:CPU 每帧写 1~2 个 float3(CenterWS + AxisWS)
带宽非常小。每个 renderer 每帧更新一次,传 24~48 bytes(加上对齐也就百字节级)。除非你有成百上千个角色同时在屏幕上,否则这通常不是瓶颈。
注意点:用 LateUpdate,确保骨骼动画已更新;用 MaterialPropertyBlock,避免实例化材质。
-
更"正确"且依然轻:用 bone matrix 在 CPU 直接算 head transform,再写 1 个 center
你本来就能直接拿 headBone.position / headBone.up,这个是 Unity 已经算好的结果,不需要你自己遍历骨骼矩阵。你只是在把结果喂给 shader。
-
真正 GPU-only:从 GPU skinning 的骨骼矩阵/纹理读取 Head bone
这在 Unity 的内置管线/URP/HDRP 里没那么"随手可用",因为骨骼矩阵存放方式因管线、平台、优化策略(CPU skinning / GPU skinning / compute skinning)而异,而且默认 shader 里并不保证你能访问"某个骨骼的矩阵"。要做也行,但属于"侵入式"方案:
-
你要有一个骨骼矩阵缓冲(StructuredBuffer 或 bone texture)
-
知道 head bone 的 index
-
在 shader 里读取矩阵,取其平移当 centerWS
-
axisWS 取矩阵的某一列(旋转基)
"pet" (as a verb) means to stroke or touch gently with affection, which can include patting or rubbing someone's head (e.g., "She pets his head to comfort him."). "Pets" is its plural form or third-person singular, retaining the same sense.
I need to think about it. My current goal is to replicate the effect, and this aspect is about performance optimization (probably, just my opinion). How can I quickly replicate it? What should I do? Am I just replicating it? I don't want to just replicate it. If I replicate it, what will I do next? I want to make an animation using that AI automatic motion software UR, but I also want to learn more about performance optimization. It's too broad, and I can't reach a conclusion yet, so for now, first replicate it and then make a small video introduction.
headBone.position 默认就是世界坐标(World Space)。
所以我把 shader 参数命名成 _HeadCenterWS。
流程是:
- 脚本传世界坐标:_HeadCenterWS = headBone.position
- shader 内再转对象空间:TransformWorldToObject(_HeadCenterWS.xyz)
- 用这个对象空间中心和 i.positionOS 做 radialOS = i.positionOS - headCenterOS
这样坐标空间是统一的,不会混用。
不挂脚本的话,会用材质里的默认值。
你现在 shader 里定义的是:
_HeadCenterWS = (0,0,0,1)
所以实际就是 (0,0,0)。
不会自动变成别的值。
关键不是"轴是不是固定",而是这两个要同时对:
- center 必须是头部中心(不是网格错误原点)
- axisOS 必须在同一对象空间里与头部上轴一致
你现在最该先验证一件事:
- HeadCenterBinder 是否真的挂到当前头发 SkinnedMeshRenderer 上,并且 headBone 已赋值。
否则 _HeadCenterWS 仍是默认 (0,0,0),你就等于在绕错误中心算场。

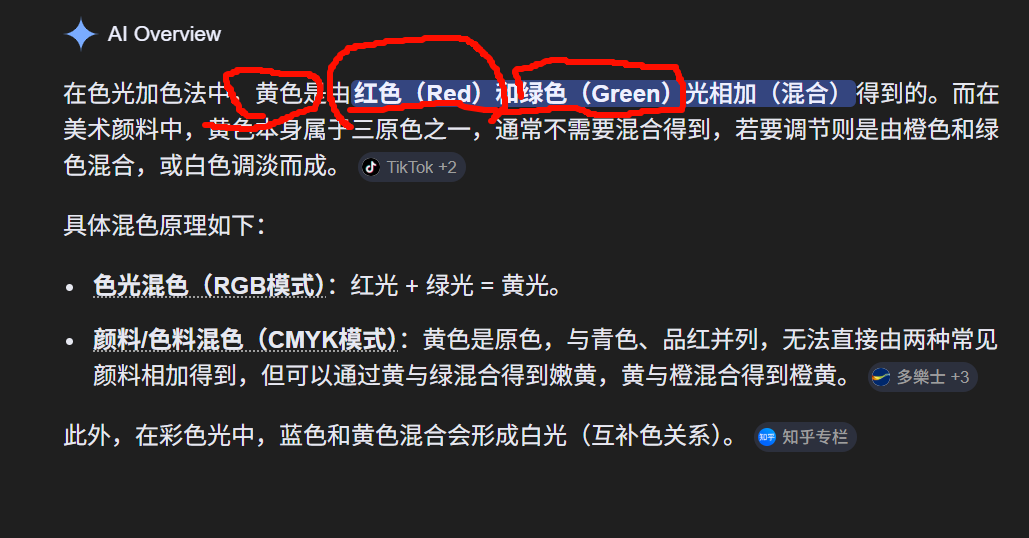
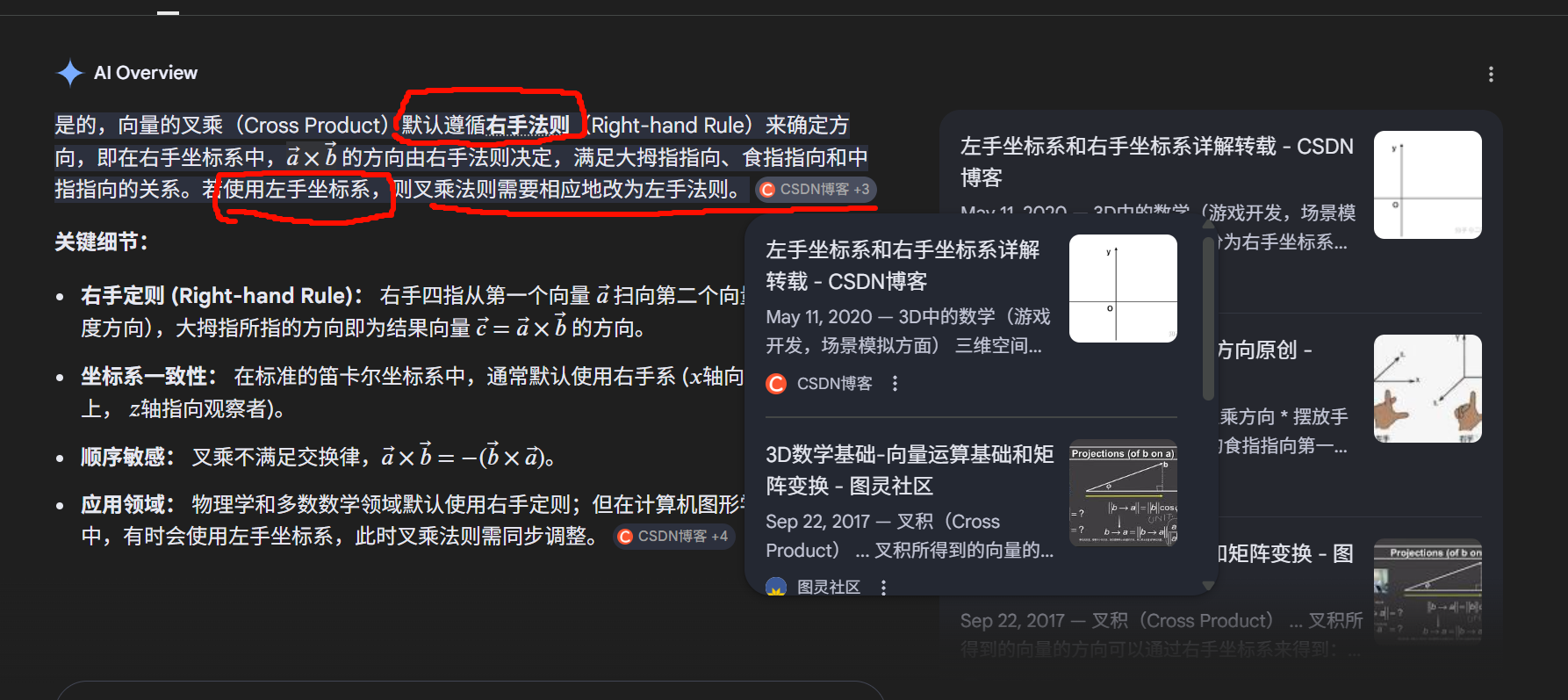
但 Vector3.Cross 使用的是标准数学叉乘公式。关键在于:
"叉乘遵循哪只手"并不是一个独立属性,而是由坐标基底的手性决定的。
更精确的说法是:
叉乘公式本身是固定的。
当你把它放进一个左手正交基底中,它的几何意义就对应左手定则。
我把回答拉回"数学默认右手"的原因,本质是:
-
我在避免术语误用(担心你把运算规则和空间手性混淆)。
-
我优先保证定义层面的严谨性。
是的,Shader Model(SM)本质上就是一套可编程阶段的能力规格,最早在 DirectX 8 引入,用来定义"这代 GPU 至少能支持哪些指令、寄存器数量、分支能力、纹理采样能力等"。你在 Unity ShaderLab 里写的 #pragma target 3.0 / 4.5 / 5.0,本质上是在声明:
这段 HLSL 代码需要至少某个 Shader Model 的能力。
它既是语言特性门槛,也是硬件能力下限约束。
一、Shader Model 到底定义什么?
Shader Model 并不是 API 版本号,而是硬件能力等级。它主要约束:
指令集能力
是否支持动态分支(if/loop)
是否支持整数运算
是否支持位运算
是否支持更高精度
资源访问能力
可用纹理数量
可用 sampler 数量
UAV(unordered access view)支持与否
RWTexture / StructuredBuffer
寄存器数量
常量寄存器数量
临时寄存器数量
输出插值寄存器数量
可编程阶段数量
SM2:只有 VS/PS
SM3:增强 VS/PS
SM4(DX10):引入 Geometry Shader
SM5(DX11):Compute Shader / UAV / Tessellation
SM6:DX12 + DXIL + wave ops
二、为什么会有这个分级体系?
在 DX8 之前是固定管线(Fixed Function Pipeline)。
DX8 引入可编程 VS/PS,但当时硬件能力差异巨大。
微软为了:
给开发者一个明确能力边界
避免程序在低端 GPU 上崩溃
让驱动可以拒绝不支持的 shader
于是引入 Shader Model 作为能力等级。
它相当于:
"这张显卡至少支持到 SM X.X 的全部能力。"
三、Unity 里为什么还要写 target?
因为 Unity 需要:
决定是否为某个平台编译这段 shader
决定是否 fallback 到 simpler variant
控制移动端/老显卡兼容性
例如:
Copy code
#pragma target 3.0
意味着:
不允许使用 SM4+ 特性
不允许 compute shader
不允许 UAV
不允许高级整数操作
如果你写:
Copy code
#pragma target 5.0
Unity 会:
只在支持 DX11+/Metal/Vulkan 等的设备上编译
老显卡直接跳过这个 pass
这就是你听说的"兼容性考虑"。
四、它和 DX 版本的关系
大致对应关系:
DX8 → SM1
DX9 → SM2 / SM3
DX10 → SM4
DX11 → SM5
DX12 → SM6(但 SM6 不再是简单能力等级,而是 DXIL 体系)
但注意:
DX 版本 ≠ Shader Model
因为不同 GPU 可能支持不同 SM,但 API 版本可能更高。
五、现代为什么感觉"没那么重要了"?
原因:
绝大多数 PC 显卡至少支持 SM5
移动端走的是 GLES / Metal,不完全遵循 DX SM
DX12 时代更多依赖 feature level + DXIL + wave ops
不过在跨平台引擎里(Unity/Unreal),Shader Model 仍然是一个重要的能力裁剪开关。
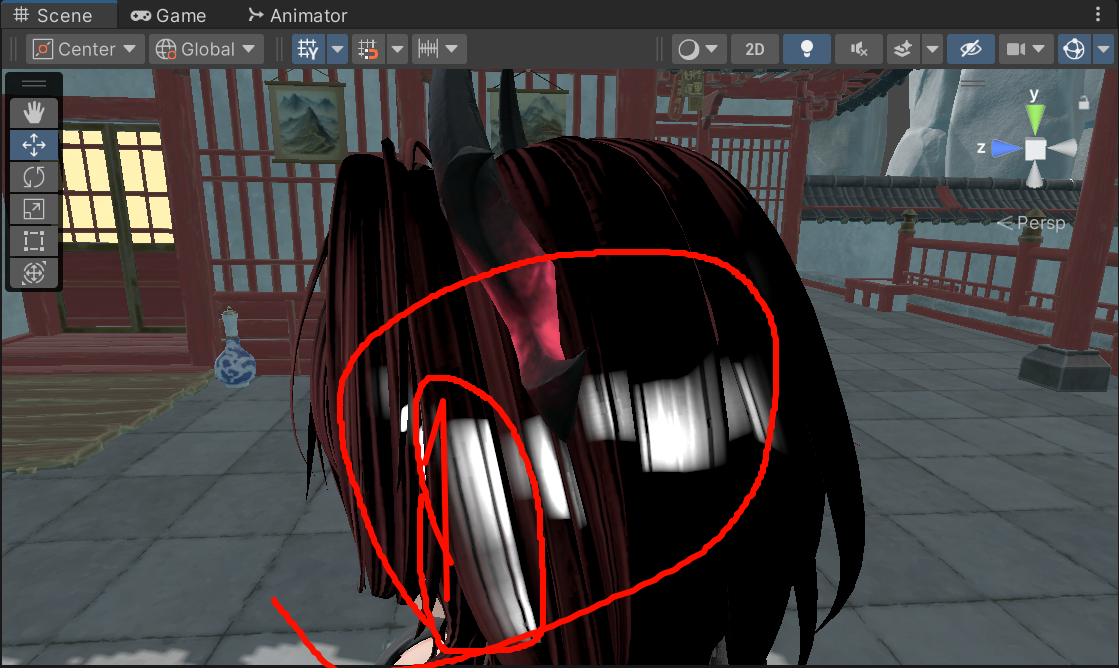
这一块的突变怎么办?要从图的采样开始下手吗,
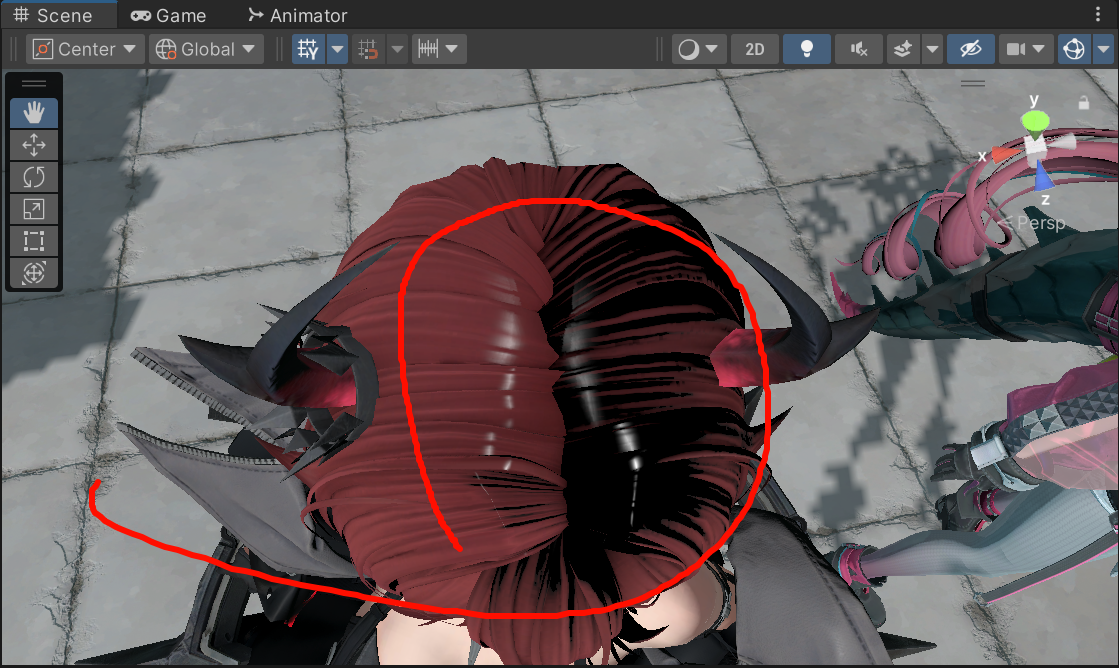
用v朝向来影响顶部的高光!
当vpos转换到模型空间后,原点到vpos的向量和model space的y轴做夹角判断,当接近头顶的时候就把BVmask影响高速降低,来阻止头部的异常高光,给我一个巨变的角度参数,,,那我该选什么公式合适?
这个节点组本质是一个 "查表版菲涅耳/镜面响应计算器",不是在做几何变形。
一句话版:
用 NdotV 和 roughness 去查 PreIntegratedFGD LUT,然后用 fresnel0 把查到的两项组合成最终反射系数。
可以按这 4 步理解:
- 生成查表坐标
- u = sqrt(clampedNdotV)
- v = perceptualRoughness
- 再过 Remap01ToHalfTexelCoord,避免采样到像素边界(半 texel 偏移)
- 查预积分纹理
- 用 (u,v) 采样 PreIntegratedFGD... 纹理,得到颜色通道 R,G,B
- 用 fresnel0 逐通道混合
- 对 RGB 每个通道都做:mix(R, G, fresnel0_channel)
- 等价公式:result = R * (1 - F0) + G * F0(按通道)
- 输出
- 主输出向量是上面这个 result(给后续高光/反射用)
- 另外还把 LUT 的某些通道(如 B、G)单独输出给后面节点用
所以它的作用是:
把实时算很贵的 BRDF/Fresnel 一部分,改成"2D 纹理查表 + 简单混合",更快也更稳定。
你这类 "PreIntegratedFGD / DFG LUT" 图,通常不是手画的,而是把 BRDF 里那部分难积分的项离线(或启动时)数值积分出来,写进一张 2D 纹理。
如果你说的就是最常见的那张 2 通道 LUT(R/G 存两项,最后用 F0*A + B 组合),它的生成方式基本如下(以 UE4 风格 GGX + Smith + Schlick Fresnel 为例):
轴的含义
横轴:NoV = saturate(dot(N, V))(N·V)
纵轴:roughness(有的实现用 perceptual roughness,有的用 α=roughness²;生成时要和你运行时一致)
对每一个像素 (NoV, roughness) 做蒙特卡洛积分
你要计算的是镜面 IBL 的 split-sum 里 "BRDF 积分项",通常写成两项系数 A、B,使得:
integratedSpec ≈ A * F0 + B
常见的累积写法(核心点:把 Schlick Fresnel 展开,拆成与 F0 线性相关的两部分):
Schlick 的 Fc = (1 - VoH)^5
定义一个"可见性权重"项(UE4 常用): G_Vis = (G_Smith * VoH) / (NoH * NoV)
然后: A += (1 - Fc) * G_Vis B += Fc * G_Vis
最后 A /= sampleCount, B /= sampleCount,把 (A,B) 写进 LUT 的 RG。
采样怎么做(关键在重要性采样)
为了收敛快,通常不是均匀采样半球,而是对 GGX 分布做重要性采样:
方案 A:采样半向量 H(GGX importance sample / VNDF sampling),再反射得到 L
方案 B:直接用 Heitz 的 GGX VNDF 采样(更稳,尤其低 NoV)
每个样本流程大概是:
已知 N(可固定为 (0,0,1))和 V(由 NoV 构造)
采样得到 H
L = reflect(-V, H)
计算 NoL, NoH, VoH,如果 NoL <= 0 跳过
计算 Smith G(用 roughness/α)
累积 A/B
输出是什么样的"图"
把 A、B 映射到 0..1 灰度或伪彩显示,你就会看到一张平滑渐变的 2D 图;在引擎里一般作为 8/16bit RG 纹理使用(很多用 RG16F 以减少误差)。
在哪生成
离线工具:C++/Python/任何脚本跑 Monte Carlo,导出 EXR/PNG/DDs
或引擎启动时:Compute Shader 直接写一张 RenderTexture(Unity/HDRP 也常见这种方式)
Cascadeur 的"AI"本质上不是联网推理或基于云端大模型的预测系统,而是本地运行的物理约束优化 + 数据驱动姿态建模 + 机器学习辅助控制器的组合。它更接近"智能约束求解器"而非生成式AI。
下面按技术结构拆解。
一、核心思想:物理一致性驱动的姿态优化
Cascadeur 的关键在于 AutoPhysics。其底层不是传统动画曲线编辑,而是:
-
构建刚体骨架模型
每个骨骼带质量、质心、惯量张量等物理参数。
本质是一个简化的 articulated rigid body system。
-
使用约束求解
典型约束包括:
-
关节旋转限制
-
接触约束(地面、支撑点)
-
动量守恒
-
质心投影
-
角动量约束
-
这部分更接近:
-
拉格朗日乘子法
-
PBD(Position Based Dynamics)
-
或基于能量最小化的非线性优化
目标函数通常形态类似:
min E = E_pose + λ1 E_balance + λ2 E_momentum + λ3 E_contact
也就是说它通过优化使姿态"物理上合理"。
这完全可以在本地执行,不需要网络。
二、AutoPosing:数据驱动的姿态空间插值
AutoPosing 不是生成式模型,而是:
-
构建了一个高维姿态数据库(人类动作先验)
-
使用机器学习做姿态空间降维
可能使用:
-
PCA
-
Autoencoder
-
manifold embedding
-
-
在低维空间进行插值与约束投影
当你拖动某个控制器时:
-
系统不是简单IK
-
而是在 learned pose manifold 上寻找最接近的合理姿态
这是一种:
data-constrained inverse kinematics
依然是本地模型推理,不需要联网。
三、AI Assist 的真实含义
Cascadeur 所谓 AI 实际上包含三类机制:
-
姿态合理性评估模型
一个监督学习模型,用来评估"这个姿态是否像真实人类"。
-
预测式补偿
当你修改一条肢体轨迹时:
-
系统预测其它肢体应该如何补偿以维持平衡
-
本质是训练过的回归模型
-
-
动作平滑与过渡生成
类似基于时间序列的局部预测模型
但不是大型神经网络
推测实现规模:
-
小型前馈网络
-
或梯度提升模型
-
不太可能是Transformer级别模型
四、是否联网?
结论:
Cascadeur 不需要联网进行姿态预判。
原因:
-
所有模型都随软件本地部署
-
没有远程推理依赖
-
不涉及云端生成
它的"AI"更像:
"数据驱动的物理一致性辅助系统"
而不是 ChatGPT 类模型。
五、与真实ML生成动画的区别
对比一下:
Cascadeur:
-
基于物理约束优化
-
姿态空间投影
-
小规模机器学习模型
-
非生成式
-
非在线推理
像 SIGGRAPH 上的:
-
Motion Diffusion
-
Transformer Motion Generation
-
Neural State Machine
那是完全不同的技术栈。
六、和游戏引擎技术的对比(你熟悉的方向)
如果用 Unity/DX12 的类比来讲:
Cascadeur 的 AI 更接近:
-
一个带 learned prior 的 IK solver
-
类似在 DOTS 上实现的 physics-constrained pose optimization
-
而不是 runtime neural animation inference
它不是:
-
不涉及 GPU Tensor 推理
-
不涉及在线模型下载
-
不涉及 LLM 或 diffusion
七、底层实现推测
综合公开资料和行为推断,它可能包含:
-
PCA 或 autoencoder 降维的姿态空间
-
非线性优化器(SQP / Gauss-Newton)
-
PBD 风格约束系统
-
小型 MLP 回归模型
-
动量与质心物理模拟
架构属于:
Hybrid Data + Physics Optimization System
而不是"生成式AI系统"。
八、总结
Cascadeur 的 AI 本质是:
一个本地运行的、基于物理约束的姿态优化系统,
辅以姿态空间学习模型,
用来保证动作符合人类动力学逻辑。