DeepImageSearch:当图像检索需要"侦探式推理",现有AI还差多远?
你翻开手机相册,想找去年秋天和朋友在那家屋顶有红色风车的餐厅吃饭时拍的照片。你记得那天下午阳光很好,桌上有一瓶意大利红酒,朋友穿了件条纹衬衫。但你不记得确切日期,也不记得餐厅的名字。
这个看似平常的检索需求,对现有的图像检索系统来说,几乎是不可能完成的任务。
CLIP能帮你找到"红酒"的照片、"条纹衬衫"的照片、"风车建筑"的照片------但它不知道这些线索指向的是同一次聚餐。它无法把分散在不同照片中的碎片化记忆串联起来,定位到那个特定的下午。
来自中国人民大学的Chenlong Deng等13位研究者在ICML上发表了DeepImageSearch,正式向这个盲区发起挑战。他们提出了一个根本性的问题:当检索需要跨越时间线、在数万张照片中进行多步推理时,我们需要的不再是一个"搜索引擎",而是一个"侦探"。
论文标题:DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories
论文链接:https://arxiv.org/abs/2602.10809
1. 三种检索范式:从"直觉"到"推理"再到"探索"
要理解DeepImageSearch的定位,先看它与传统检索的本质区别。
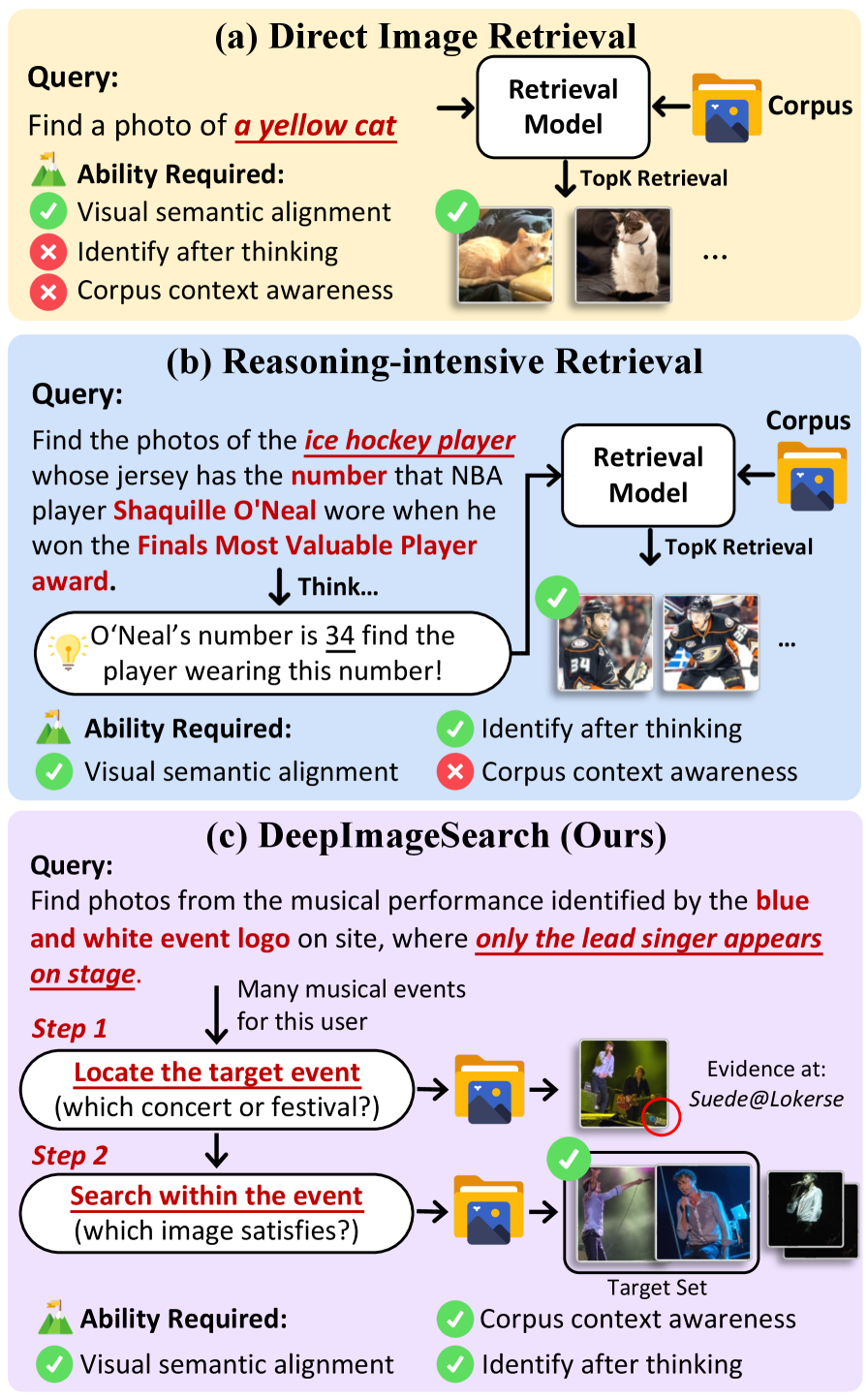
第一种:直接检索(Direct Retrieval) 。用户说"找一张黄色的猫",系统用CLIP之类的模型算一下查询和每张图片的语义相似度,排个序返回。这是过去十年图像检索的主流做法,快速且高效,但只能处理语义独立的查询------每张图片是否相关,只取决于图片本身。
第二种:推理密集型检索(Reasoning-Intensive Retrieval)。用户说"找一张和这个建筑同一个城市、但在河边拍的照片",系统需要先识别建筑所在的城市(比如通过地标识别推断出是巴黎),再用"巴黎+河边"去检索。这里多了一步推理,但推理完成后,检索本身还是一次性匹配。
第三种就是DeepImageSearch提出的范式:上下文感知检索 。用户的查询本质上是"在我的视觉历史中,满足一组跨照片、跨时间约束的那些照片"。系统需要像侦探破案一样------先根据某条线索定位到一个事件,再在那个事件里验证其他约束,可能还需要跳到另一个事件去交叉验证。线索和目标分散在不同的照片中,没有任何单张照片能独立满足查询条件。
这三种范式的关键区分在于:前两种可以用一个embedding模型"一步到位",而第三种从根本上需要多步、交互式的探索策略。这不是模型能力不够的问题,而是范式本身就不对。
2. 两类查询:事件内 vs 跨事件
DISBench中的查询被精心分为两类,每类对应不同的推理模式。
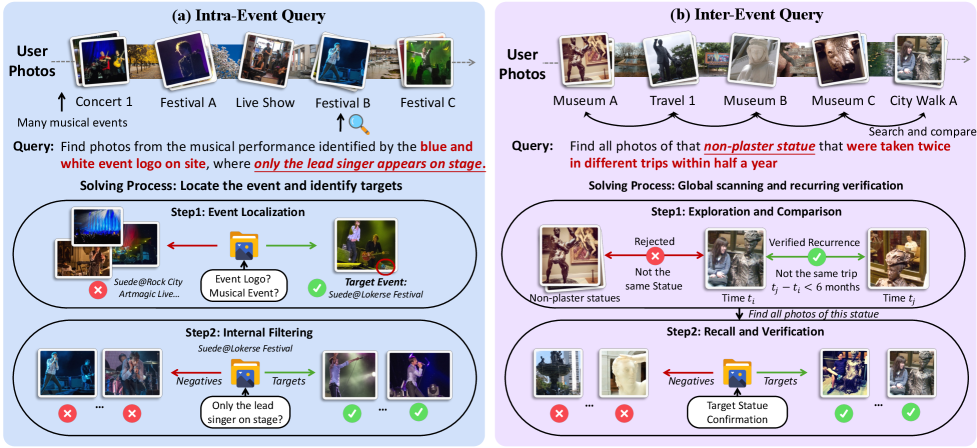
事件内查询(Intra-Event)
想象一下:你去年参加了三场不同乐队的演唱会。现在你想找"那场舞台背景是蓝白条纹Logo的演唱会里,只有主唱一个人在台上的照片"。
解题路径大致是:
- 在你的所有照片中搜索"蓝白条纹Logo"------这是锚定线索
- 找到包含这个Logo的照片后,确定它属于哪场演唱会------这是事件定位
- 在这场演唱会的所有照片中,筛选出"台上只有一个人"的------这是目标过滤
注意:蓝白Logo照片本身不是你要找的目标,它只是帮你定位到正确事件的"跳板"。这种线索与目标分离的结构,正是传统检索无法应对的原因。
跨事件查询(Inter-Event)
更复杂的情况:你想找"过去一年中,我在不同城市旅行时重复看到的那座铜雕像的所有照片"。
这要求系统:
- 扫描你的整个视觉历史
- 识别出反复出现在不同时间、不同地点的同一实体
- 确认时间范围约束(过去一年)
- 收集所有符合条件的照片
跨事件查询需要在全局尺度上做模式匹配,而不是锁定在某个局部事件里。从数据集统计看,跨事件查询占53.3%,略多于事件内查询的46.7%,两者大致均衡。
3. 数据集构建:一条保留率仅6.1%的严苛流水线
构建这样一个数据集的难度远超常规。人工标注者要浏览数万张照片,发现照片之间的隐含关联,再基于这些关联编写需要多步推理的查询------这在规模上不可行。
作者的解法是一条人机协作流水线,让VLM承担繁重的上下文发现工作,人类负责最终的质量把关。
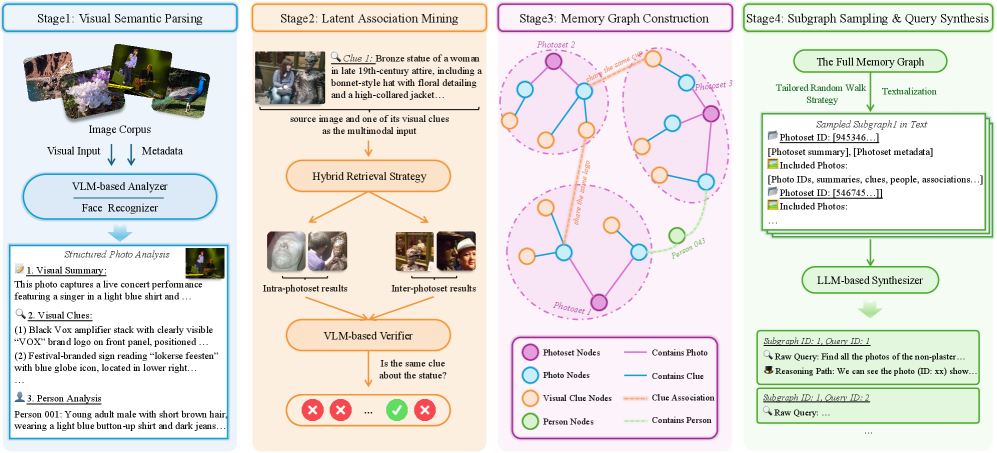
阶段一:视觉语义解析
对YFCC100M数据集中57个用户的109,467张照片进行逐张分析。VLM提取每张照片中的关键视觉线索:地标建筑、商店招牌上的文字、独特的物体(比如一个粉色行李箱)、人物属性(服装、配饰)等。这些线索会在后续阶段中充当"连接不同照片的桥梁"。
这里有一个数据来源的细节值得注意。YFCC100M是2014年发布的大规模照片数据集,包含了9920万张由Flickr用户上传的Creative Commons授权照片,涵盖2004年到2014年间的影像。每张照片都带有元数据:拍摄时间、上传时间、GPS坐标(如果有的话)、用户ID等。这些元数据天然地构成了"视觉历史"的时空框架,非常适合本文的研究目标。
阶段二:潜在关联挖掘
这一步是整个流水线的核心创新。系统使用检索-验证策略,在不同照片之间发现潜在的语义关联。比如,两张照片虽然拍摄时间相隔半年、地点相距千里,但都包含了同一座教堂的不同角度------这就是一条有价值的跨事件关联。
具体做法是:对阶段一提取的视觉线索进行跨照片检索,找到可能相关的线索对,然后用VLM验证这些关联是否真实成立。这种自动化的关联发现极大地扩展了数据集的覆盖面,因为人类标注者不可能在十万张照片中穷举所有的隐含联系。
阶段三:记忆图构建
将所有实体和关联组织成一个异构图(Heterogeneous Graph)。图中有四种节点:照片、照片集(属于同一事件的照片群)、视觉线索、人物。边表示它们之间的关系("包含"、"属于"、"关联于"等)。
这个图的作用是为下一步的查询生成提供结构化的推理基础。一个好的查询,本质上对应图中的一条需要多步遍历才能走完的路径。
阶段四:子图采样与查询合成
从记忆图中采样子图,然后让VLM基于子图的结构生成自然语言查询。生成的查询必须满足:
- 不能通过单步语义匹配解决
- 必须需要利用子图中的多跳关联
- 语言表达自然、符合真实用户的搜索习惯
人工验证:6.1%的保留率
最后一步至关重要。专家团队对每一条自动生成的查询进行严格审核,检查三个维度:
- 正确性:查询描述的关联是否真实存在于照片中
- 难度:能否通过直接语义匹配解决(如果能,则淘汰)
- 标注:目标照片的标注是否准确完整
最终保留率仅为6.1%。也就是说,每生成约16条候选查询,只有1条能通过所有检验。这个极低的保留率侧面说明了两件事:一是自动化流水线虽然能大量生成候选,但质量参差不齐;二是最终留下的查询确实经过了千锤百炼,每一条都代表一个真正有挑战性的检索问题。
数据集最终规模
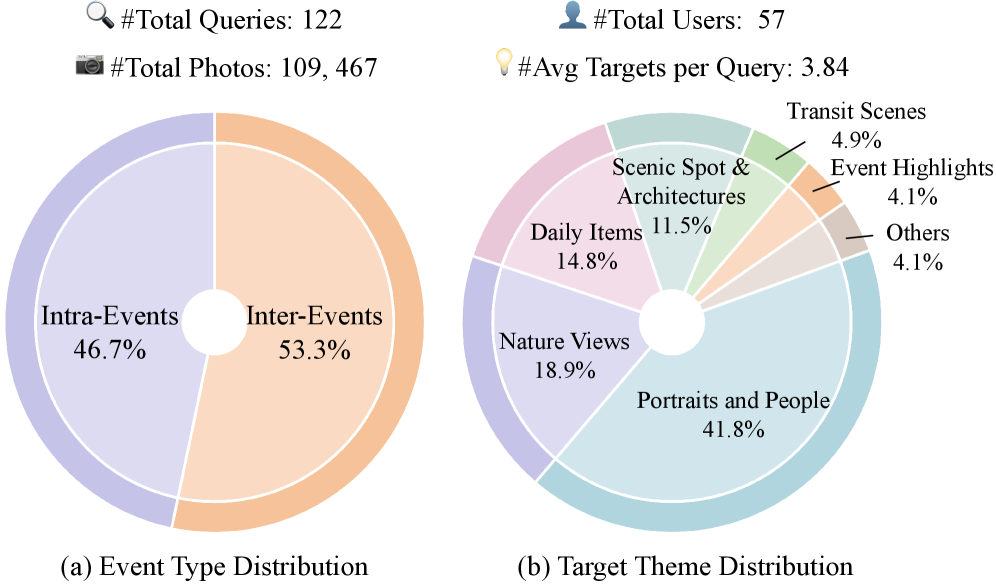
最终的DISBench包含:
- 122条查询
- 57个用户的视觉历史
- 109,467张照片
- 每个用户的视觉历史平均跨度3.4年
- 平均每条查询的目标照片数为3.84张(不是找一张,是找一组)
从事件类型分布看,涉及旅行、日常生活、节日活动、体育赛事等多种场景。目标照片的主题涵盖建筑、自然风光、人物活动、食物、动物等。地理分布覆盖全球,从北美到欧洲到东亚都有涉及。

4. ImageSeeker:一个侦探式的智能体基线
仅仅有了数据集还不够,还需要一个合理的基线来展示"什么样的系统架构能应对这种任务"。作者设计了ImageSeeker,一个模块化的智能体框架。
4.1 工具箱
ImageSeeker给模型配备了五把"瑞士军刀":
| 工具名称 | 功能 | 类比 |
|---|---|---|
TgImageSearch |
多模态相似度搜索 | 侦探的"嫌疑人画像比对" |
TgGetMetadata |
获取照片的时间戳和地点信息 | 查看证物的"鉴定报告" |
TgFilterMetadata |
按时空条件过滤照片集 | 缩小"作案时间和地点范围" |
TgViewPhotos |
将照片注入上下文进行视觉检查 | 亲眼查看证物 |
TgWebSearch |
外部网络搜索 | 查阅"外部资料库" |
这套工具设计的精妙之处在于粒度的把控 。TgImageSearch负责"广撒网"式的粗筛,TgFilterMetadata负责基于硬约束的过滤,TgViewPhotos负责需要视觉判断的精细检查。三者组合起来,形成了一条从粗到细的检索漏斗。
4.2 双记忆系统
长程搜索任务中,模型面临一个根本性的困境:上下文窗口是有限的,但搜索过程可能需要几十步交互,产生的历史信息远超窗口容量。
ImageSeeker的解决方案是双记忆系统:
显式状态记忆(Explicit State Memory) :允许模型将中间搜索结果保存为命名子集。比如,模型搜索到一批"包含蓝白Logo的照片",可以把它存为concert_with_blue_logo,后续直接在这个子集内做进一步检索,而不需要重新搜索。这类似于侦探在调查中把不同线索分别归档,需要时随时调取。
压缩上下文记忆(Compressed Context Memory):当交互历史过长时,系统会自动压缩早期的交互记录,只保留高层目标和当前计划的摘要。这就像侦探写的案件摘要------不需要记住每一句证人证词的原文,但要保持对案件全貌的把握。
这个设计选择反映了一个深层次的工程判断:在大规模视觉搜索中,记忆管理比推理能力更可能成为瓶颈。一个推理能力很强但没有良好记忆管理的系统,在第30步搜索时可能已经忘了第5步发现的关键线索。
5. 实验结果:最强模型也只答对了三分之一
5.1 主实验
论文测试了当前最强的一批闭源和开源多模态模型。评价指标使用Exact Match (EM) 和 F1------EM要求找到的照片集与标注完全一致,F1则允许部分匹配。
| 模型 | 类型 | Intra-Event EM | Inter-Event EM | Overall EM | Overall F1 |
|---|---|---|---|---|---|
| GPT-4o | 闭源 | 5.3 | 9.2 | 7.4 | 22.2 |
| GPT-5.2 | 闭源 | 10.5 | 12.3 | 11.5 | 35.1 |
| Claude-Sonnet-4.5 | 闭源 | 22.8 | 12.3 | 17.2 | 39.4 |
| Claude-Opus-4.5 | 闭源 | 35.1 | 29.2 | 32.0 | 55.5 |
| Qwen3-VL-235B | 开源 | 12.3 | 6.2 | 9.0 | 25.3 |
| GLM-4.6V | 开源 | 14.0 | 10.8 | 12.3 | 30.4 |
几个关键观察:
Claude Opus 4.5遥遥领先。EM 32.0、F1 55.5,几乎是第二名Claude Sonnet 4.5的两倍(EM 17.2)。这个差距比平常的模型排行榜上的差距大得多,说明这个任务极其吃模型的综合能力------不仅是视觉理解,还有长程规划、工具使用、记忆管理。
GPT-4o表现惊人地差。EM仅7.4、F1仅22.2,被自家的GPT-5.2大幅超越。考虑到GPT-4o在很多通用基准上仍然是第一梯队的模型,这个结果说明DeepImageSearch确实触及了一个全新的能力维度。
开源模型的差距仍然明显。Qwen3-VL-235B这样的超大规模开源模型,EM也只有9.0,和Claude Opus 4.5的32.0差距悬殊。这可能不完全是模型能力的问题------开源模型在工具调用和复杂指令遵循方面的训练数据可能不如闭源模型充分。
Intra-Event普遍比Inter-Event更容易,但不是绝对的。多数模型在事件内查询上的EM更高,这符合直觉------在一个事件内搜索比跨多个事件搜索的范围更小。但GPT-4o和GPT-5.2反倒是在Inter-Event上略好,这可能与它们的搜索策略有关。
5.2 传统检索方法的彻底失败
论文还测试了纯粹的embedding检索方法(把查询和所有照片都编码成向量,按相似度排序),结果堪称灾难性的:
- Recall@3:约10-14%
- NDCG@5:约13-17%
这个结果清楚地证明了论文的核心论点:上下文感知的检索问题无法通过语义匹配范式解决。embedding模型看到"只有主唱在台上的照片",会检索出所有看起来像"一个人在舞台上"的照片------不管是哪场演唱会、是不是你要找的那个主唱。它缺乏把"蓝白Logo"这条线索与"主唱在台上"这个目标关联起来的能力。
5.3 消融实验
以Gemini-3-Flash-Preview为基准模型,逐个移除ImageSeeker框架中的组件,观察性能变化:
| 移除的组件 | F1下降 | 说明 |
|---|---|---|
| GetMetadata | -5.7 | 时空信息对定位事件至关重要 |
| FilterMetadata | -5.0 | 硬约束过滤是缩小搜索范围的关键 |
| Explicit Memory | -4.9 | 对跨事件查询影响尤为严重 |
| WebSearch | -2.3 | 外部知识查询的作用相对有限 |
GetMetadata的影响最大(-5.7),这很好理解:没有时间戳和地点信息,模型就失去了判断"这些照片属于同一次旅行"的关键依据。FilterMetadata紧随其后(-5.0),说明仅靠视觉相似度搜索不够,硬性的时空约束过滤是不可或缺的。
显式状态记忆的移除导致F1下降4.9,但更关键的是它对跨事件查询的影响------没有记忆机制,模型在搜索第三个事件时已经忘了第一个事件中发现的线索,导致跨事件推理链断裂。
6. 规模扩展分析:并行试错能提多少分?
一种直觉的想法是:如果单次搜索准确率不够,能不能多跑几次,然后取最好的结果?
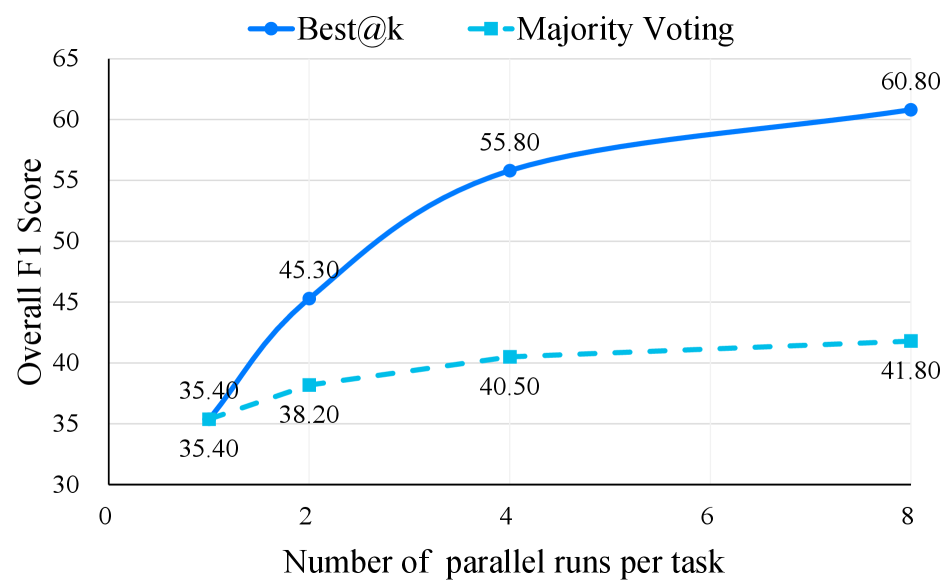
论文测试了两种扩展策略,并行运行次数从1到8:
Best@k策略:跑k次取F1最高的那次结果。Claude Opus 4.5从55.5(k=1)提升到60.8(k=8),提升了约5个F1点。这说明模型的搜索策略存在一定的随机性,多次尝试确实能覆盖更多的成功路径。
Majority Voting策略:跑k次后,对多次结果中出现频率最高的照片进行投票。这个策略的效果不如Best@k,原因可能是错误答案的模式比正确答案更多样------多次错误的答案互不相同,投票反而会淹没那次唯一正确的结果。
从Best@k的增长曲线看,k从1到4的提升幅度较大,之后趋于平缓。这暗示了一个实用规则:跑3-4次取最优即可获得大部分收益,再增加次数性价比急剧下降。
7. 错误归因:模型到底在哪里翻车?
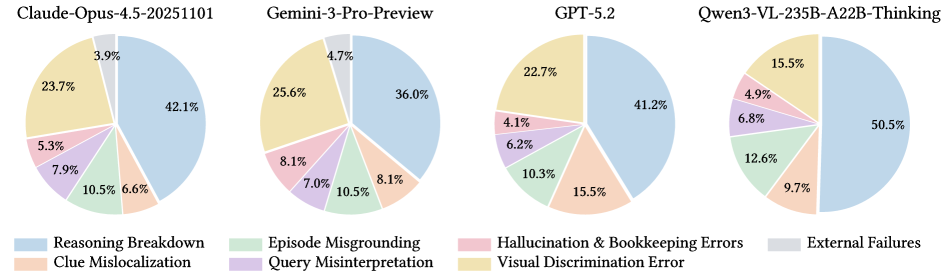
论文对四个代表性模型(Claude Opus 4.5、Gemini-3-Pro、GPT-5.2、Qwen3-VL)的失败案例进行了详细的错误归因分析,归纳出七大错误类型:
推理崩塌(Reasoning Breakdown):占比36-50%
这是最主要的失败模式。模型已经找到了正确的上下文信息(比如成功定位到了正确的事件),但在执行多步计划时"迷失了方向"------忘记了某个约束条件、跳过了某个验证步骤、或者把中间结果错误地当成了最终答案。
这个现象在所有模型中普遍存在,也是最难解决的。它本质上反映的是当前大模型在长程规划和执行一致性方面的不足------能理解任务、能想出计划、能使用工具,但无法在几十步的执行过程中始终保持对全局目标和局部约束的精确追踪。
线索错位(Clue Mislocalization)
模型找到了某条线索,但把它关联到了错误的事件或时间段。比如查询要求找"去年夏天那次露营时看到的鹿",模型找到了一张鹿的照片,但那是两年前在另一个地方拍的。
事件错锚(Episode Misgrounding)
模型整体的搜索方向就偏了------在完全错误的事件集合中搜索。这通常是因为初始锚定线索就被错误匹配了。
查询误解(Query Misinterpretation)
模型对查询的理解本身就有偏差。比如把"我上次去那个城市时"理解成了"我第一次去那个城市时"。
幻觉与记录错误(Hallucination & Bookkeeping Errors)
模型"看到"了照片中实际不存在的元素,或者在记录中间结果时出现了数据混乱(比如把照片A的ID记成了照片B的)。
视觉辨别错误(Visual Discrimination Error)
在需要精细视觉判断的场景中失败------比如区分两个穿着相似的人、或者辨认一个半遮挡的建筑。
外部故障(External Failures)
工具调用失败、API超时等技术层面的问题。
从错误分布看,一个耐人寻味的规律是:推理崩塌在所有模型中都是最大的瓶颈,但模型越强,视觉辨别错误和线索错位的占比越低。换言之,更强的模型在"看"和"找"这些基础能力上进步明显,但在"维持长链条推理的一致性"方面,进步有限。
8. 为什么这篇论文值得关注?
8.1 它指出了检索领域一个真实而被忽视的盲区
过去十年的图像检索研究,从最初的BoW、CNN特征,到CLIP、BLIP2等多模态模型,核心范式始终是**"查询-文档独立匹配"**。这个范式在商品搜索、通用图片检索等场景下效果很好,但它有一个隐含假设:一张图片是否与查询相关,只取决于图片本身的内容。
DeepImageSearch打破了这个假设。它指出,在个人相册、监控视频、医疗影像序列等场景中,上下文才是决定相关性的关键因素。同一张照片,在不同的时间线索下,可能是目标也可能是干扰项。这是一个真实存在的需求,而不是一个人为构造的学术问题。
8.2 它为"智能体式检索"提供了第一个严谨的基准
"用Agent做搜索"这个想法并不新鲜------微软的MMCTAgent、各种Agentic RAG系统都在探索类似的方向。但此前缺乏一个公认的、专门设计的基准来衡量这些系统在真实视觉历史上的多步推理能力。
DISBench填补了这个空白。122条查询看起来数量不多,但考虑到6.1%的保留率和109,467张照片的规模,每一条查询都是一个高质量的测试案例。而且,从目前最强模型仅32% EM的结果来看,这个基准在相当长一段时间内都不会饱和。
8.3 它暴露了当前多模态Agent的真实短板
推理崩塌占比36-50%这个数字非常有冲击力。它说明长程规划能力是当前多模态Agent最薄弱的环节------不是"看不见"、也不是"不理解",而是"执行不下去"。这为未来的模型改进指明了一个具体的方向:不是继续堆视觉编码器的参数,而是提升Agent在长序列决策中的一致性和鲁棒性。
9. 局限性与开放问题
公平地说,这篇论文也有一些值得讨论的局限:
数据规模与多样性。122条查询、57个用户------这个规模对于一个标杆基准来说偏小。虽然质量很高(6.1%保留率),但可能无法覆盖所有有趣的查询模式。未来是否能扩展到千级别的查询,同时保持质量?
评估成本。每次评估需要让Agent在十万张照片中进行多步搜索,API调用成本可观。论文提到使用了Claude Opus 4.5等顶级模型,单次完整评估的费用可能高达数百美元。这对学术界的复现和跟进构成了一定门槛。
工具设计的影响。ImageSeeker的五种工具是人工设计的,工具的粒度和能力边界直接影响了模型的发挥空间。如果给模型更灵活的工具(比如自定义SQL查询),结果会不会很不一样?
查询的自然度。虽然论文强调了生成查询的自然性,但由人机协作流水线生成再人工筛选的查询,与用户在真实场景中的自然语言描述之间,可能仍然存在分布偏移。
10. 它启示了什么样的未来?
从技术趋势看,DeepImageSearch描绘的不仅仅是一个检索问题,而是AI系统与个人数据交互的一种新范式。
设想一下:未来的手机相册App不再只有按日期排列和人脸分类两种浏览方式。你可以对它说------"帮我找找看,去年是不是有两次旅行都路过了同一座桥?"------然后一个Agent在后台默默地扫描你的整个相册,追踪时空线索,最终返回两组照片和一个解释:"对,你3月在布拉格和9月在布达佩斯都走过了查理大桥。等等,这不是同一座桥,但它们确实风格相似------一座是14世纪的,另一座是19世纪的仿造品。"
这种交互方式需要的不是更好的CLIP,而是一个能规划、能记忆、能推理的Agent。DeepImageSearch为衡量我们离这个未来有多远,提供了一把精确的尺子。
按照目前的进度------最强模型EM 32%,这把尺子告诉我们:还挺远的。但至少,路已经看清了。
论文信息
- 标题: DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories
- 作者: Chenlong Deng, Mengjie Deng, Junjie Wu, Dun Zeng, Teng Wang, Qingsong Xie, Jiadeng Huang, Shengjie Ma, Changwang Zhang, Zhaoxiang Wang, Jun Wang, Yutao Zhu, Zhicheng Dou
- 机构: 中国人民大学等
- 会议: ICML 2026
- 链接 : arXiv | GitHub | HuggingFace Dataset