Pandas操作财报数据
Series
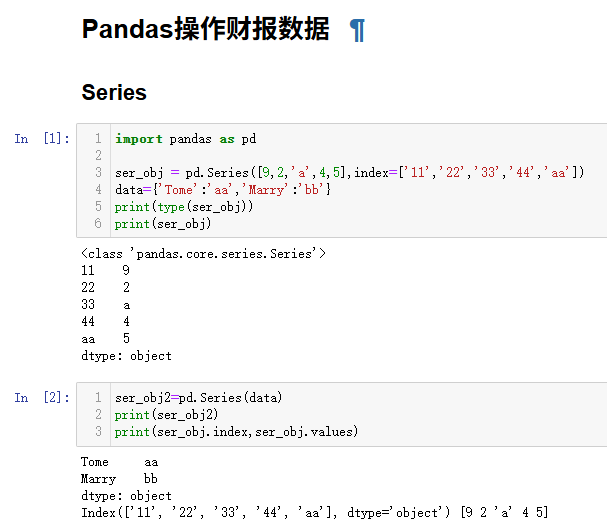
type() 返回变量类型
可见ser_obj类型为<class 'pandas.core.series.Series'>
python
import pandas as pd
ser_obj = pd.Series([9,2,'a',4,5],index=['11','22','33','44','aa'])
data={'Tome':'aa','Marry':'bb'}
print(type(ser_obj))
print(ser_obj)
ser_obj2=pd.Series(data)
print(ser_obj2)
print(ser_obj.index,ser_obj.values)DataFrame
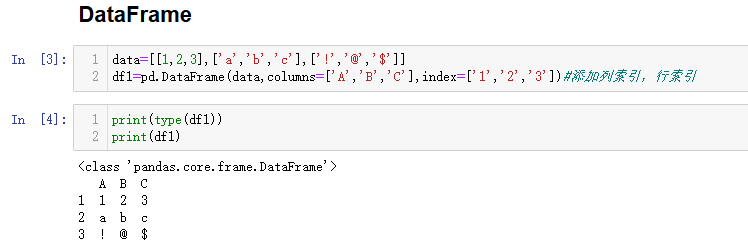
df类型为<class 'pandas.core.frame.DataFrame'>
python
data=[[1,2,3],['a','b','c'],['!','@','$']]
df1=pd.DataFrame(data,columns=['A','B','C'],index=['1','2','3'])#添加列索引,行索引
print(type(df1))
print(df1)读文件内容
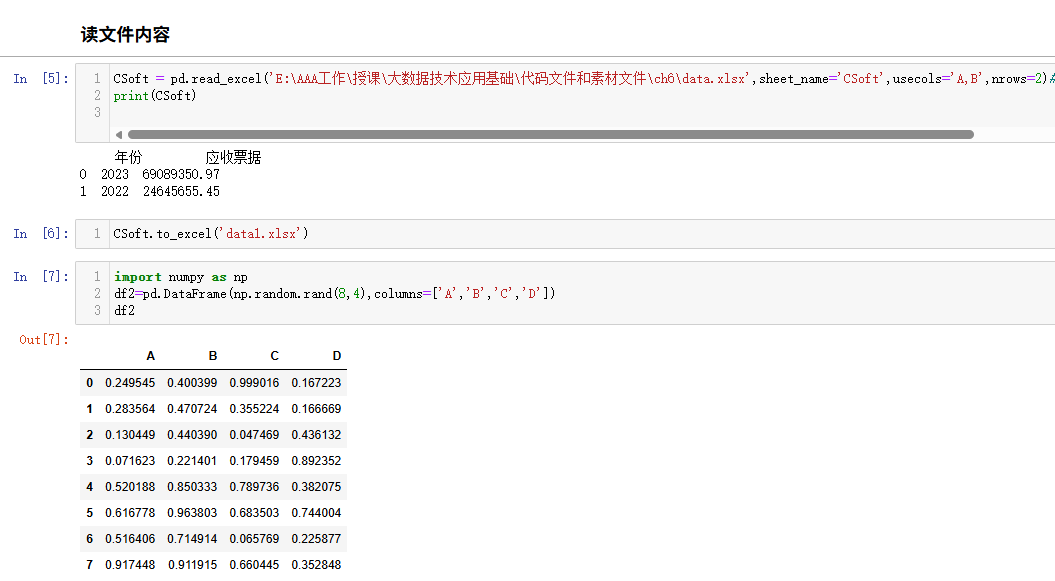
python
CSoft = pd.read_excel('E:\AAA工作\授课\大数据技术应用基础\代码文件和素材文件\ch6\data.xlsx',sheet_name='CSoft',usecols='A,B',nrows=2)# 只导入AB列,前两行
print(CSoft)
CSoft.to_excel('data1.xlsx')
import numpy as np
df2=pd.DataFrame(np.random.rand(8,4),columns=['A','B','C','D'])
df2读取
ser0 位置索引
ser'name'标签索引
ser0:4 【0,4)位置切片
ser'a':'d' 【'a','d'】标签切片
ser\['a','d','f'] 用列表盛放多个
df列索引行索引
df.loc(x,y) 标签 【x,y】 闭区间
df.iloc(x,y) 位置 【x,y)左闭右开区间
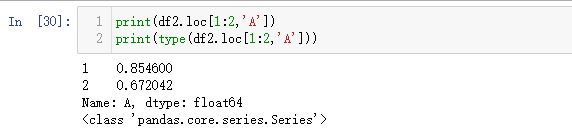
python
print(df2.loc[1:2,'A'])
print(type(df2.loc[1:2,'A']))排序
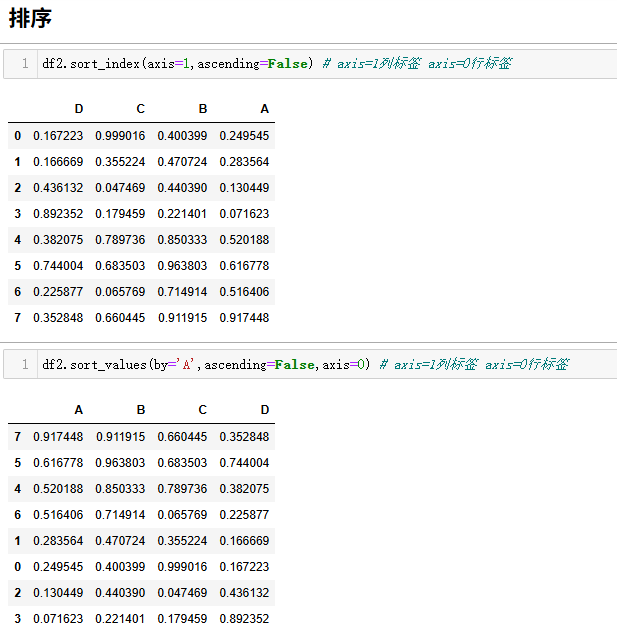
python
df2.sort_index(axis=1,ascending=False) # axis=1列标签 axis=0行标签
df2.sort_values(by='A',ascending=False,axis=0) # axis=1列标签 axis=0行标签计算
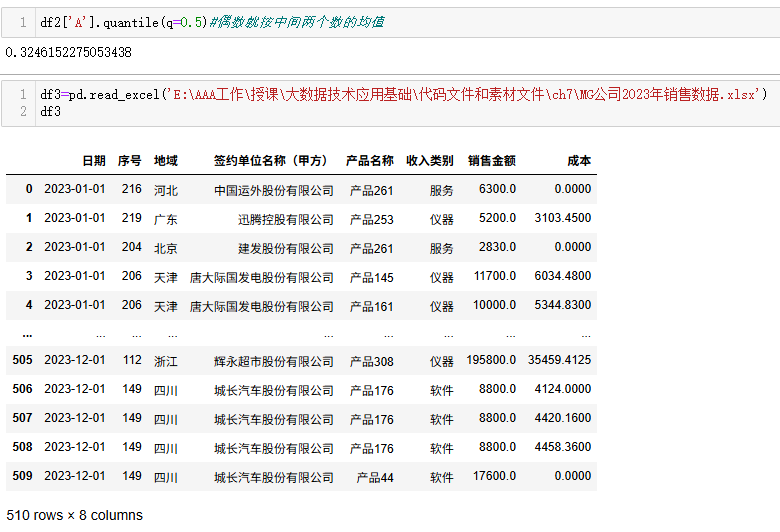
python
df2['A'].quantile(q=0.5)#偶数就按中间两个数的均值
df3=pd.read_excel('E:\AAA工作\授课\大数据技术应用基础\代码文件和素材文件\ch7\MG公司2023年销售数据.xlsx')
df3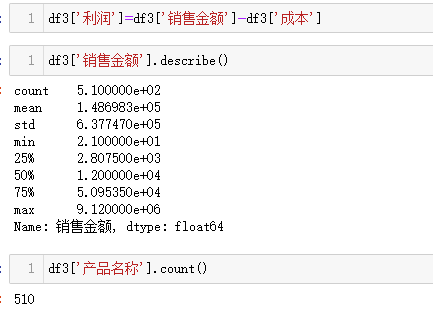
python
df3['利润']=df3['销售金额']-df3['成本']
df3['销售金额'].describe()
df3['产品名称'].count()groupby
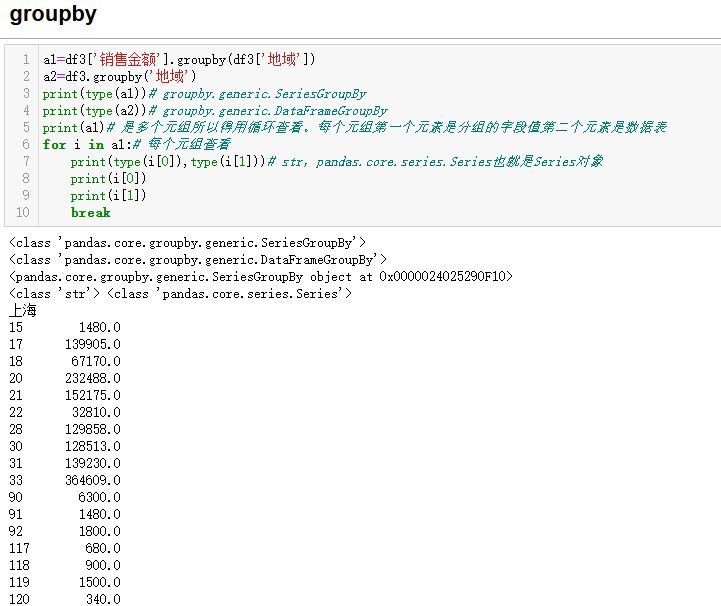
python
a1=df3['销售金额'].groupby(df3['地域'])
a2=df3.groupby('地域')
print(type(a1))# groupby.generic.SeriesGroupBy
print(type(a2))# groupby.generic.DataFrameGroupBy
print(a1)# 是多个元组所以得用循环查看。每个元组第一个元素是分组的字段值第二个元素是数据表
for i in a1:# 每个元组查看
print(type(i[0]),type(i[1]))# str,pandas.core.series.Series也就是Series对象
print(i[0])
print(i[1])
break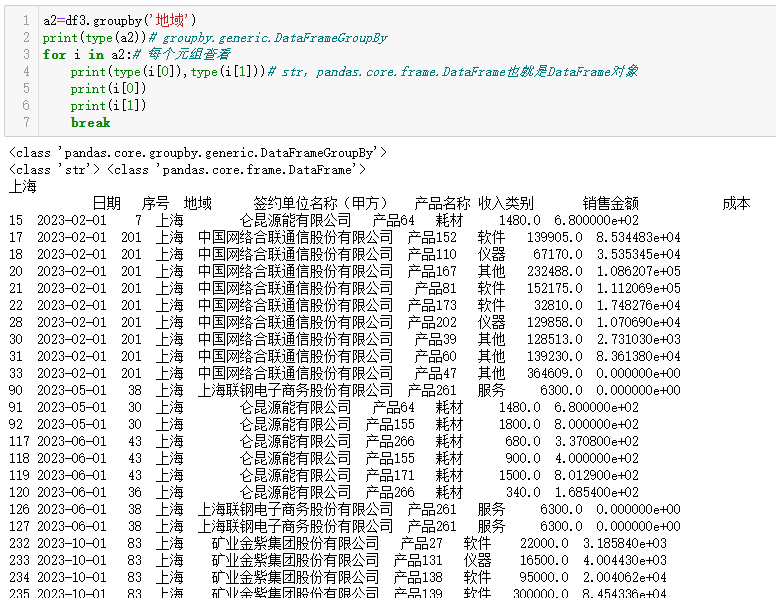
python
a2=df3.groupby('地域')
print(type(a2))# groupby.generic.DataFrameGroupBy
for i in a2:# 每个元组查看
print(type(i[0]),type(i[1]))# str,pandas.core.frame.DataFrame也就是DataFrame对象
print(i[0])
print(i[1])
break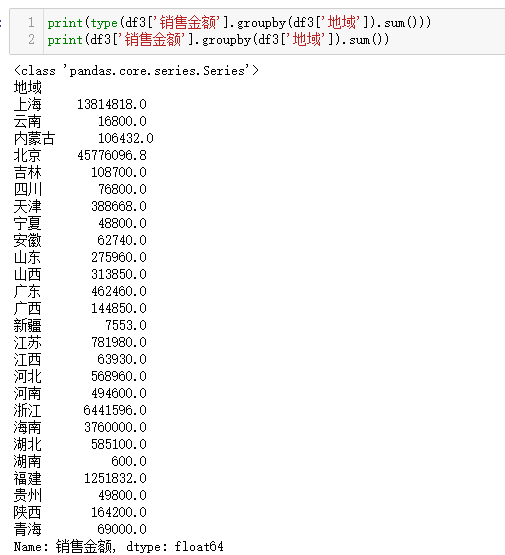
对分组后的组对象可以对其值求和,这里就是按地域分组后的销售金额求和
python
print(type(df3['销售金额'].groupby(df3['地域']).sum()))
print(df3['销售金额'].groupby(df3['地域']).sum())# 求和使得数据类型变为pandas.core.series.Series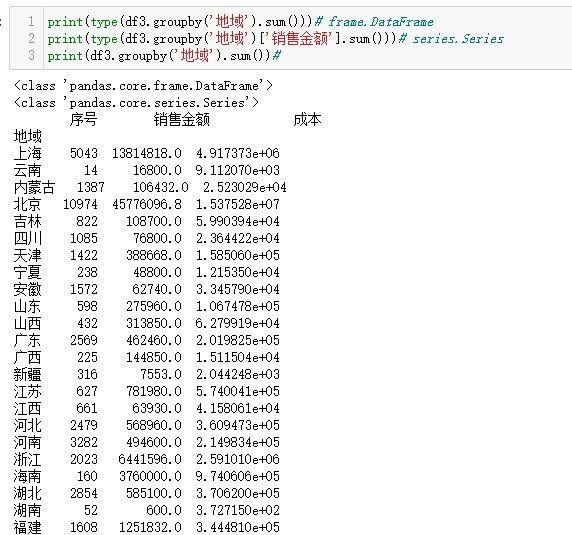
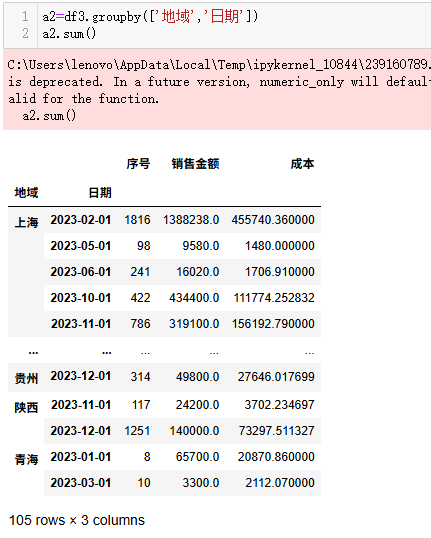
以上代码由于df3.groupby('地域')得到的组对象中还是个矩阵DataFrame,所以.sum()就将所有列分别求和了
python
print(type(df3.groupby('地域').sum()))# frame.DataFrame
print(type(df3.groupby('地域')['销售金额'].sum()))# series.Series
print(df3.groupby('地域').sum())#一般还是先分组再取列更常用
python
a2=df3.groupby(['地域','日期'])
a2.sum()