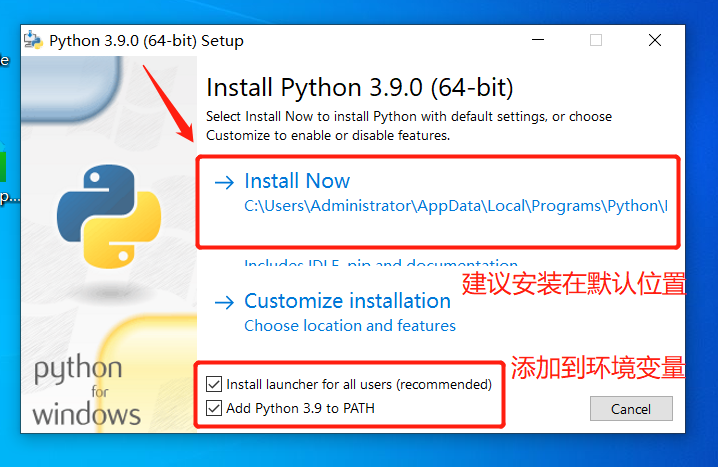
安装步骤
官方网站
https://www.python.org/downloads/
镜像下载网站【国内】
https://mirrors.huaweicloud.com/python/
基础数据类型
python
# 字符串
my_name = "Jiudan"
# 整数
my_age = 20
# 浮点型
my_height = 172.0
# 布尔类型
is_student= False
# 空类型
money = None注意使用 Python 推荐的【蛇形命名法】来为变量命名,格式为 xx_xx_xxx,务必养成良好的命名习惯。
变量和格式化输出
python
# 字符串
my_name = "Jiudan"
# 整数
my_age = 20
# 浮点型
my_height = 172.0
# 布尔类型
is_student = False
# 空类型
money = None
# 格式化输出
# 1 基础方法
print("name: " + my_name + "age: " + str(my_age))
print("name: ", my_name, "age: ", my_age)
# 2 前导符 f
# 注意 f' <- 这个 f 我们称之为前导符, 意为该字符串内 {} 的名称为变量, 打印时会自动替换
print(f"name: {my_name} age: {my_age}")
# 3 特殊的转义字符
# \t 代表制表符 \n 代表换行符
print("name\tJiudan\tage\t20\n")
# 4 前导符 r
# 注意 r' <- 这个 r 是前导符, 意为该字符串内的所有内容均不做任何转义, 常用于文件路径, URL
print(r"name: {my_name} age: {my_age}")获取输入
python
# 注意获取到的输入默认是字符串类型, 所以你需要使用 int 方法转换为整数类型
guess_age = int(input("请输入你的身高: "))循环判断语句
For 循环
python
# range(start, stop, [step])
# start: 计数从 start 开始。
# end: 计数到 end 结束,但不包括 end。
# step:步长,默认为1。
for i in range(0, 10, 2):
print(i, end=' -> ') # end: 以指定字符串结尾, 默认为 /n
else: # for ... else ... : 循环正常结束后会执行else下的代码
print('END')
# 0 -> 2 -> 4 -> 6 -> 8 -> ENDwhile 循环
python
add = 0
# 当 add < 10 的时候会执行下面的代码
while add < 10:
add += 1
if add % 2 == 0:
# 跳过本次循环
continue
elif add >= 6:
# 结束循环 (非正常结束)
break
else:
print(add, end=' -> ')
# 循环正常结束后会打印 END
else:
print('END')break, continue, pass 语句的作用
-
1、break 提前结束循环 (非正常结束)
-
2、continue 跳过当前循环并且进入下一次循环
-
3、pass 相当于占位符, 什么都不做
列表和字典
列表
# 1.查看列表元素
webList = ['Baidu', 'Google', 'Taobao', 'Tencent']
print(webList)
print(webList[1])
print(webList[-1])
print(webList[1:3])
print(webList[1:])
# 打印附带下标
for i, v in enumerate(webList):
print(i, v)
# 2.查看元素下标
webList = ['Baidu', 'Google', 'Taobao', 'Tencent']
print(webList.index('Baidu')) # 打印'Baidu'的下标index
# 3.增
webList = ['Baidu', 'Google', 'Taobao', 'Tencent']
webList.append('Weibo') # 在末尾追加一个新的元素
webList.insert(3, 'Iqiyi') # 在指定位置插入一个新的元素
print(webList)
# 4.改
webList = ['Baidu', 'Google', 'Taobao', 'Tencent']
webList[2] = 'Weibo'
print(webList)
webList.reverse() # 将列表反转 #reverse:反转
print(webList)
# 5.删
webList = ['Baidu', 'Google', 'Taobao', 'Tencent']
webList.remove('Google')
print(webList)
del webList[2]
print(webList)
webList.pop(1) # 根据索引删除元素,删除不存在的元素时会报错
print(webList)
webList.clear() # 删除整个列表
print(webList)
# 6.计数
webList = ['jiudan', 'jiudan', 'Jiudan', 'color']
print(webList.count('jiudan'))
# 7.排序
print('排序')
list = [1, 5, 9, 6, 4, 3]
list.sort()
print('升序排列:', list)
list.sort(reverse=True)
print('降序排列:', list)
# 进阶
list_str = ['A', 'b', 'C', 'j']
list_str.sort()
print('区分大小写升序排列:', list_str) # 默认区分大小写
list_str.sort(reverse=True)
print('区分大小写降序排列:', list_str) # 默认区分大小写
list_str.sort(key=str.lower)
print('不区分大小写升序排列:', list_str) # 不区分大小写,升序排列
list_str.sort(key=str.lower, reverse=True)
print('不区分大小写降序排列:', list_str) # 不区分大小写,降序排列
# 8.列表的拓展
webList1 = ['Baidu', 'Google', 'Taobao', 'Tencent']
webList2 = ['Weibo', 'Iqiyi', 'Zhihu']
webList1.extend(webList2) # 拓展列表,将两个列表内容合并
print(webList1, webList2) # 但不会清除webList2列表字典
# 创建一个空字典
dict1 = {}
# dict.fromkeys()函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值(初始值只能为一个,默认为 None)。
Tuple = ('Google', 'Baidu', 'Taobao') # 元组 字典键值列表。
List = ['Google', 'Baidu', 'Taobao'] # 列表
Set = {'Google', 'Baidu', 'Taobao'} # 集合
Dict = dict.fromkeys(Tuple, 10)
print(f"新字典为 : {dict1}")
dict2 = Dict.fromkeys(List, 10)
print(f"新字典为 : {dict2}")
dict3 = Dict.fromkeys(Set, 10)
print(f"新字典为 : {dict3}")
# 查找
info = {
'1101': 'jiudan',
'1102': 'alex',
'1103': 'color',
'1104': 'jack'
}
print(info) # 打印字典
# 遍历方法
for k in info.values():
print(k)
for v in info.values():
print(v)
for k, v in info.items():
print(k, v)
# 根据 key ,打印目标内容
print(info['1101'])
print(info.get('1105', 0)) # 查找 如果没有则返回参数0 而不会报错 可用于去重
# 修改/更新
info = {
'1101': 'jiudan',
'1102': 'alex',
'1103': 'color',
'1104': 'jack'}
info2 = {
'1105': 'may',
'1106': 'abby',
'1101': 'JIUDAN'}
info['1101'] = '玖淡' # 修改 , key(1101)已存在
info.update(info2) # 将info字典与info2字典合并 并将内容更新(将1101的玖淡更新为JIUDAN)
info.setdefault('1105', 'jiudan') # 如果目标存在则不修改而返回原来的值,如果不存在则添加一个新的元素
print(info)
# 增加
info = {
'1101': 'jiudan',
'1102': 'alex',
'1103': 'color',
'1104': 'jack'
}
info['1105'] = 'Alice' # 增加 ,key(1105)不存在
print(info)
# 删除
info = {
'1101': 'jiudan',
'1102': 'alex',
'1103': 'color',
'1104': 'jack'
}
info.pop('1103') # 删 , 删除不存在的key会报错
del info['1104'] # 删 , 删除不存在的key会报错
info.popitem() # 随机删
info.clear() # 清空字典
print(info)
# 查重计数
print('查重计数'.center(20, '-'))
tsDict = {}
tsList = [0, 3, 3, 5, 4, 7, 8, 2, 9, 12, 12, 5, 6, 7, 7, 8, 4, 3, 99, 99]
for i in tsList:
tsDict[i] = tsDict.get(i, 0) + 1
for k, v in tsDict.items():
print(f'数字 {k} 出现的次数 : {v}')列表推导式
# 列表推导式 [i for i in iter if i ...]
list_derive = [i for i in range(15) if i > 3]
list_derive2 = [(i, j) for i, j in [(1, 2), (2, 3), (3, 4)] if i > 1 and j < 4]
print(list_derive, list_derive2)
# 字典推导式 [key: value for key, value in iter if key ..., value ...]
dict_derive = {key: value for key, value in [(1, 2), (2, 3), (3, 4)] if key > 1 and value < 4}
print(dict_derive)