一、语言模型
LLM 的训练本质是以 "预测下一个词" 为目标的监督学习,核心步骤如下:
- 数据准备:海量文本数据集(数百亿 + 词),提取句子 / 片段作为输入;
- 核心任务:模型根据输入上下文(Context)预测下一个词的概率分布;
- 参数优化:对比 "预测结果" 和 "真实下一个词",通过更新参数最小化差异;
- 训练目标:反复训练让参数收敛,最终精准预测下一个词,获得语言生成能力。
基础语言模型(Base LLM)通过反复预测下一个词来训练的方式进行训练,没有明确的目标导向。因此,如果给它一个开放式的 prompt ,它可能会通过自由联想生成戏剧化的内容。而对于具体的问题,基础语言模型也可能给出与问题无关的回答。例如,给它一个 Prompt ,比如"中国的首都是哪里?",很可能它数据中有一段互联网上关于中国的测验问题列表。这时,它可能会用"中国最大的城市是什么?中国的人口是多少?"等等来回答这个问题。但实际上,您只是想知道中国的首都是什么,而不是列举所有这些问题。
python
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
api_key = os.getenv("ZHIPUAI_API_KEY")
# 极简版调用函数
def get_completion(prompt, model="glm-4-flash"):
client = OpenAI(
api_key=api_key,
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0
)
return response.choices[0].message.content
# 测试调用
if __name__ == "__main__":
print(get_completion("中国的首都是哪里?"))中国的首都是北京。北京是中国的政治、文化、国际交流和科技创新中心,也是世界上著名的历史文化名城之一。
进程已结束,退出代码为 0
相比之下,指令微调的语言模型 (Instruction Tuned LLM)则进行了专门的训练,以便更好地理解问题并给出符合指令的回答。例如,对"中国的首都是哪里?"这个问题,经过微调的语言模型很可能直接回答"中国的首都是北京",而不是生硬地列出一系列相关问题。指令微调使语言模型更加适合任务导向的对话应用。它可以生成遵循指令的语义准确的回复,而非自由联想。因此,许多实际应用已经采用指令调优语言模型。熟练掌握指令微调的工作机制,是开发者实现语言模型应用的重要一步。
那么,如何将基础语言模型转变为指令微调语言模型呢?
-
第一步:预训练 Base LLM(耗时耗力)
- 无监督训练:基于数千亿词的海量数据;
- 资源消耗:超级计算系统,耗时数月;
- 目标:掌握语言规律,能精准预测下一个词。
-
第二步:有监督微调(SFT)(核心转型)
- 数据:小数据集(指令 + 对应回复示例,可人工构造);
- 目标:让模型学会 "理解指令→输出匹配回答",而非自由联想。
-
第三步:基于人类反馈的强化学习(RLHF)(提升质量)
- 流程:人类对模型输出评级(有用 / 真实 / 无害等)→ 调整模型参数,提高高评级输出的概率;
- 作用:优化输出质量,贴合人类意图。
二、Tokens
到目前为止对 LLM 的描述中,我们将其描述为一次预测一个单词,但实际上还有一个更重要的技术细节。即 LLM 实际上并不是重复预测下一个单词,而是重复预测下一个 token 。对于一个句子,语言模型会先使用分词器将其拆分为一个个 token ,而不是原始的单词。对于生僻词,可能会拆分为多个 token 。这样可以大幅降低字典规模,提高模型训练和推断的效率。例如,对于 "Learning new things is fun!" 这句话,每个单词都被转换为一个 token ,而对于较少使用的单词,如 "Prompting as powerful developer tool",单词 "prompting" 会被拆分为三个 token,即"prom"、"pt"和"ing"。

分词方式也会对语言模型的理解能力产生影响。当您要求 ChatGPT 颠倒 "lollipop" 的字母时,由于分词器(tokenizer),ChatGPT 难以正确输出字母的顺序。这时可以通过在字母间添加分隔,让每个字母成为一个token,以帮助模型准确理解词中的字母顺序。
python
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量(智谱API Key)
load_dotenv()
api_key = os.getenv("ZHIPUAI_API_KEY")
# 核心调用函数
def get_completion(prompt, model="glm-4-flash"):
client = OpenAI(
api_key=api_key,
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0
)
return response.choices[0].message.content
# 测试1:未分隔的lollipop(模型因Token拆分出错)
prompt1 = "Take the letters in lollipop and reverse them"
response1 = get_completion(prompt1)
print("未分隔的输出结果:", response1)
# 测试2:分隔后的l-o-l-l-i-p-o-p(模型能正确翻转)
prompt2 = "Take the letters in l-o-l-l-i-p-o-p and reverse them"
response2 = get_completion(prompt2)
print("分隔后的输出结果:", response2)
因此,语言模型以 token 而非原词为单位进行建模,这一关键细节对分词器的选择及处理会产生重大影响。开发者需要注意分词方式对语言理解的影响,以发挥语言模型最大潜力。
❗❗❗ 对于英文输入,一个 token 一般对应 4 个字符或者四分之三个单词;对于中文输入,一个 token 一般对应一个或半个词。不同模型有不同的 token 限制,需要注意的是,这里的 token 限制是输入的 Prompt 和输出的 completion 的 token 数之和,因此输入的 Prompt 越长,能输出的 completion 的上限就越低。 ChatGPT3.5-turbo 的 token 上限是 4096。
三、Helper function 辅助函数 (提问范式)
语言模型提供了专门的"提问格式",可以更好地发挥其理解和回答问题的能力。
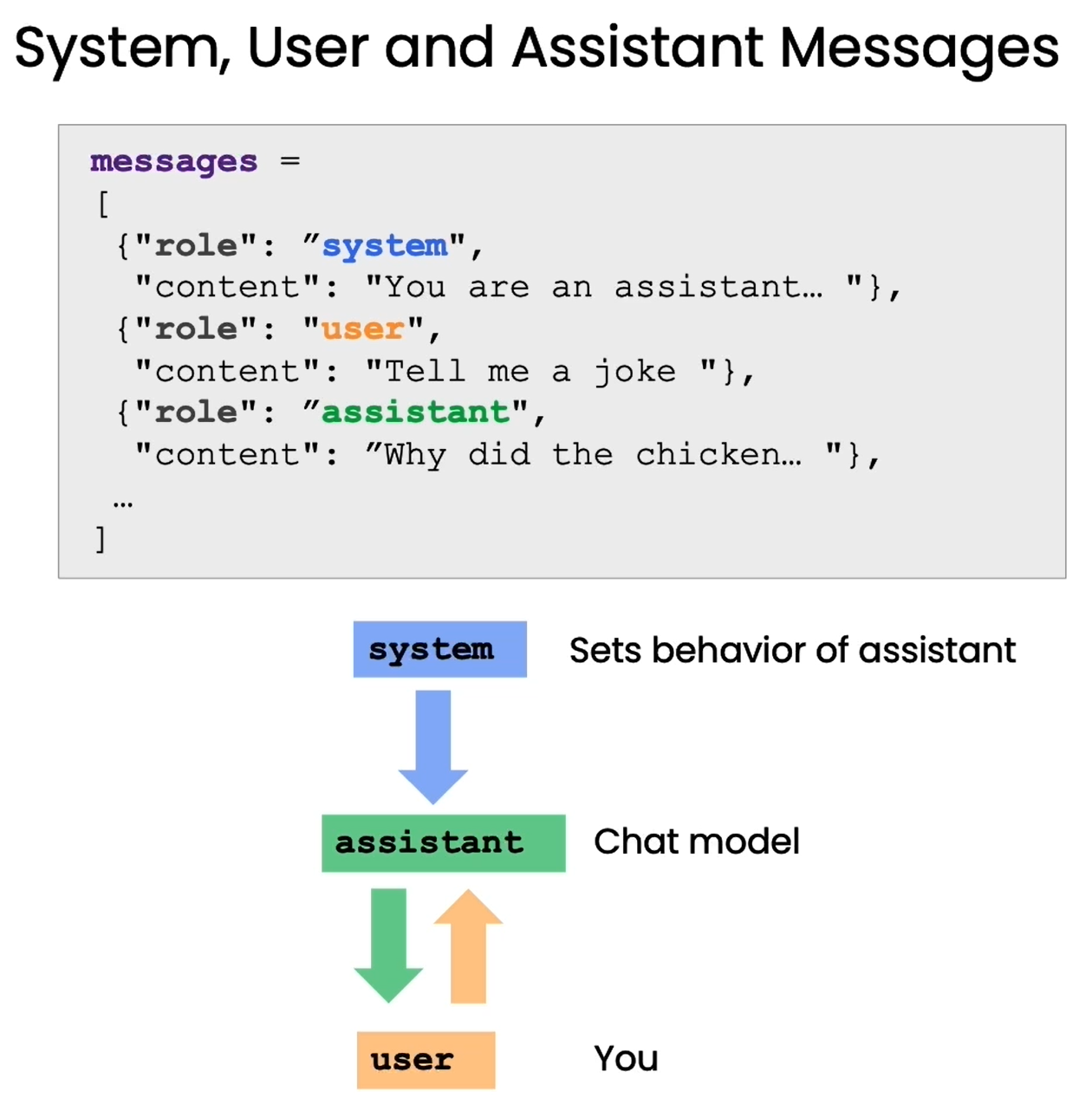
通过区分system(系统指令)和user(用户问题)两类消息,给模型明确的角色 / 规则,大幅提升回复的针对性,减少无效输出:
system消息:定义模型的角色、回答风格、输出规则(如 "苏斯博士风格""只回答一句话");user消息:用户的具体问题 / 需求;- 优势:相比单一 Prompt,能更精准地约束模型行为,适配复杂场景。
| 函数名 | 核心功能 | 适用场景 |
|---|---|---|
get_completion_from_messages |
支持多角色消息列表调用模型,可配置温度 / 最大 Token | 基础的多轮 / 角色约束对话 |
get_completion_and_token_count |
除生成回复外,还返回 Token 使用量(输入 / 输出 / 总) | 需监控 Token 消耗、控制成本的场景 |
python
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量(智谱API Key)
load_dotenv()
api_key = os.getenv("ZHIPUAI_API_KEY")
# 初始化客户端
client = OpenAI(
api_key=api_key,
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
# 1. 基础多消息调用函数(对应get_completion_from_messages)
def get_completion_from_messages(messages, model="glm-4-flash", temperature=0, max_tokens=500):
"""
支持system/user角色的多消息调用函数
:param messages: 消息列表,每个元素是{"role": "system/user/assistant", "content": 内容}
:param model: 调用的模型
:param temperature: 随机性,0-1
:param max_tokens: 最大输出Token数
:return: 模型回复内容
"""
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
# 2. 带Token计数的调用函数(对应get_completion_and_token_count)
def get_completion_and_token_count(messages, model="glm-4-flash", temperature=0, max_tokens=500):
"""
生成回复并返回Token使用量
:return: 回复内容, Token字典(prompt_tokens/completion_tokens/total_tokens)
"""
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
content = response.choices[0].message.content
# 提取Token统计(智谱API返回的usage字段和OpenAI一致)
token_dict = {
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
return content, token_dict
# ==================== 测试示例 ====================
if __name__ == "__main__":
# 示例1:苏斯博士风格写短诗
messages1 = [
{"role": "system", "content": "你是一个助理,并以 Seuss 苏斯博士的风格作出回答。"},
{"role": "user", "content": "就快乐的小鲸鱼为主题给我写一首短诗"},
]
response1 = get_completion_from_messages(messages1, temperature=1)
print("示例1输出:\n", response1, "\n")
# 示例2:限制回复为一句话
messages2 = [
{"role": "system", "content": "你的所有答复只能是一句话"},
{"role": "user", "content": "写一个关于快乐的小鲸鱼的故事"},
]
response2 = get_completion_from_messages(messages2, temperature=1)
print("示例2输出:\n", response2, "\n")
# 示例3:结合风格+长度限制
messages3 = [
{"role": "system", "content": "你是一个助理,并以 Seuss 苏斯博士的风格作出回答,只回答一句话"},
{"role": "user", "content": "写一个关于快乐的小鲸鱼的故事"},
]
response3 = get_completion_from_messages(messages3, temperature=1)
print("示例3输出:\n", response3, "\n")
# 示例4:带Token计数
response4, token_dict4 = get_completion_and_token_count(messages1)
print("示例4输出:\n", response4)
print("Token使用情况:\n", token_dict4)示例1输出:
在深海里游荡,
快乐的小鲸鱼,
尾巴摇摇摆摆,
笑声传遍海浪。
蓝蓝的海水中,
它自由自在游,
快乐的小鲸鱼,
心中满是阳光。
翻滚的波浪间,
它追逐着梦想,
快乐的小鲸鱼,
快乐永不荒凉。
海豚相伴左右,
海鸥欢快歌唱,
快乐的小鲸鱼,
快乐如诗如画。
示例2输出:
小鲸鱼快乐地在海洋里游弋,用尾巴击打水面,欢快地唱歌。
示例3输出:
快乐的小鲸鱼在海洋里畅游,尾巴摇曳着,歌声如银铃般清脆,让所有海底朋友都为之动容。
示例4输出:
在深海里游荡,
快乐的小鲸鱼,
尾巴摇摆如风铃,
笑声洒满海浪。
阳光透过波光,
照亮它的梦想,
自由自在地游,
快乐永不藏。
海豚相伴左右,
海鸥在头顶飞,
小鲸鱼心中唱,
快乐之歌不停息。
无论风起云涌,
无论潮起潮落,
快乐的小鲸鱼,
永远快乐如初。
Token使用情况:
{'prompt_tokens': 32, 'completion_tokens': 88, 'total_tokens': 120}
进程已结束,退出代码为 0
在AI应用开发领域,Prompt技术的出现无疑是一场革命性的变革。然而,这种变革的重要性并未得到广泛的认知和重视。传统的监督机器学习工作流程中,构建一个能够分类餐厅评论为正面或负面的分类器,需要耗费大量的时间和资源。
首先,我们需要收集并标注大量带有标签的数据。这可能需要数周甚至数月的时间才能完成。接着,我们需要选择合适的开源模型,并进行模型的调整和评估。这个过程可能需要几天、几周,甚至几个月的时间。最后,我们还需要将模型部署到云端,并让它运行起来,才能最终调用您的模型。整个过程通常需要一个团队数月时间才能完成。
相比之下,基于 Prompt 的机器学习方法大大简化了这个过程。当我们有一个文本应用时,只需要提供一个简单的 Prompt ,这个过程可能只需要几分钟,如果需要多次迭代来得到有效的 Prompt 的话,最多几个小时即可完成。在几天内(尽管实际情况通常是几个小时),我们就可以通过API调用来运行模型,并开始使用。一旦我们达到了这个步骤,只需几分钟或几个小时,就可以开始调用模型进行推理。因此,以前可能需要花费六个月甚至一年时间才能构建的应用,现在只需要几分钟或几个小时,最多是几天的时间,就可以使用Prompt构建起来。这种方法正在极大地改变AI应用的快速构建方式。
需要注意的是,这种方法适用于许多非结构化数据应用,特别是文本应用,以及越来越多的视觉应用,尽管目前的视觉技术仍在发展中。但它并不适用于结构化数据应用,也就是那些处理 Excel 电子表格中大量数值的机器学习应用。然而,对于适用于这种方法的应用,AI组件可以被快速构建,并且正在改变整个系统的构建工作流。构建整个系统可能仍然需要几天、几周或更长时间,但至少这部分可以更快地完成。