
kafka设置数据压缩的方式及作用
Apache Kafka 是一个分布式流处理平台,它被广泛用于构建实时数据管道和流式应用程序。Kafka 提供了多种方式来存储和管理数据,其中包括数据压缩。数据压缩在 Kafka 中主要有以下几个作用和设置方式:
1. 作用
减少存储空间需求:压缩可以显著减少存储在磁盘上的数据量,从而节省存储成本。
减少网络传输带宽:在网络传输数据时,压缩可以减少数据的体积,降低网络传输的成本和延迟。
提高数据处理的效率:压缩后的数据在处理时可以更快地被读取和写入,尤其是在处理大量数据时,可以提升整体性能。
2. 设置方式
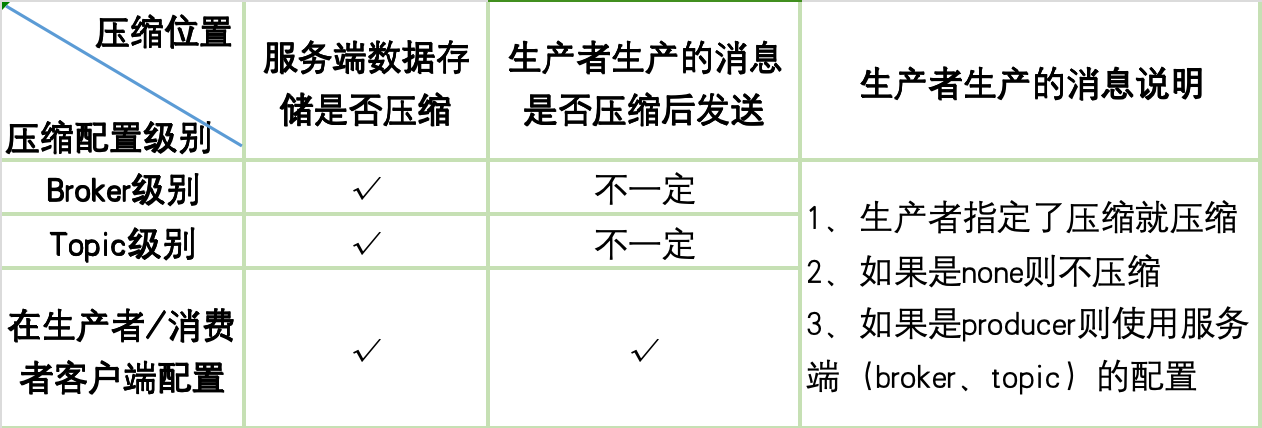
在 Kafka 中,可以通过配置 compression.type 属性来设置生产者和消费者使用的压缩方式。这个属性可以在 broker 级别、topic 级别或者生产者/消费者客户端级别进行配置。
a. 在 Broker 级别配置
在 Kafka 的 server.properties 文件中,可以设置全局默认的压缩类型:
bash
# [uncompressed, zstd, lz4, snappy, gzip, producer]
compression.type=producer这里 producer 表示使用生产者设置的压缩类型。如果不设置,默认为 producer。
如果这在broker直接指定压缩算法(zstd、lz4、snappy、gzip),那么不管生产者是否设置压缩服务端的该broker都会将数据压缩后存储。
说明:Broker指 Kafka 集群中的一个节点(或服务器)
b. 在 Topic 级别配置
在创建 topic 时,可以使用 kafka-topics.sh 脚本的 --config 选项来设置特定的压缩类型:
bash
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic my-topic --config compression.type=gzip如果这在topic直接指定压缩算法(zstd、lz4、snappy、gzip),那么不管生产者是否设置压缩服务端都会将数据压缩后存储。
说明:Topic级别配置指Kafka集群中的所有节点都采用该配置。
c. 在生产者/消费者客户端配置
在生产者或消费者的配置中,可以直接设置 compression.type 属性:
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("compression.type", "gzip"); // 设置压缩类型为 gzip3. 支持的压缩类型
Kafka 支持多种压缩算法,包括:
- gzip:使用 gzip 算法进行压缩。
- snappy:使用 Snappy 算法进行压缩,通常比 gzip 快,但压缩率略低。
- lz4:使用 LZ4 算法进行压缩,通常提供良好的压缩速度和压缩率。
- zstd:使用 Zstandard (zstd) 算法进行压缩,提供更高的压缩率但可能在某些情况下牺牲速度。
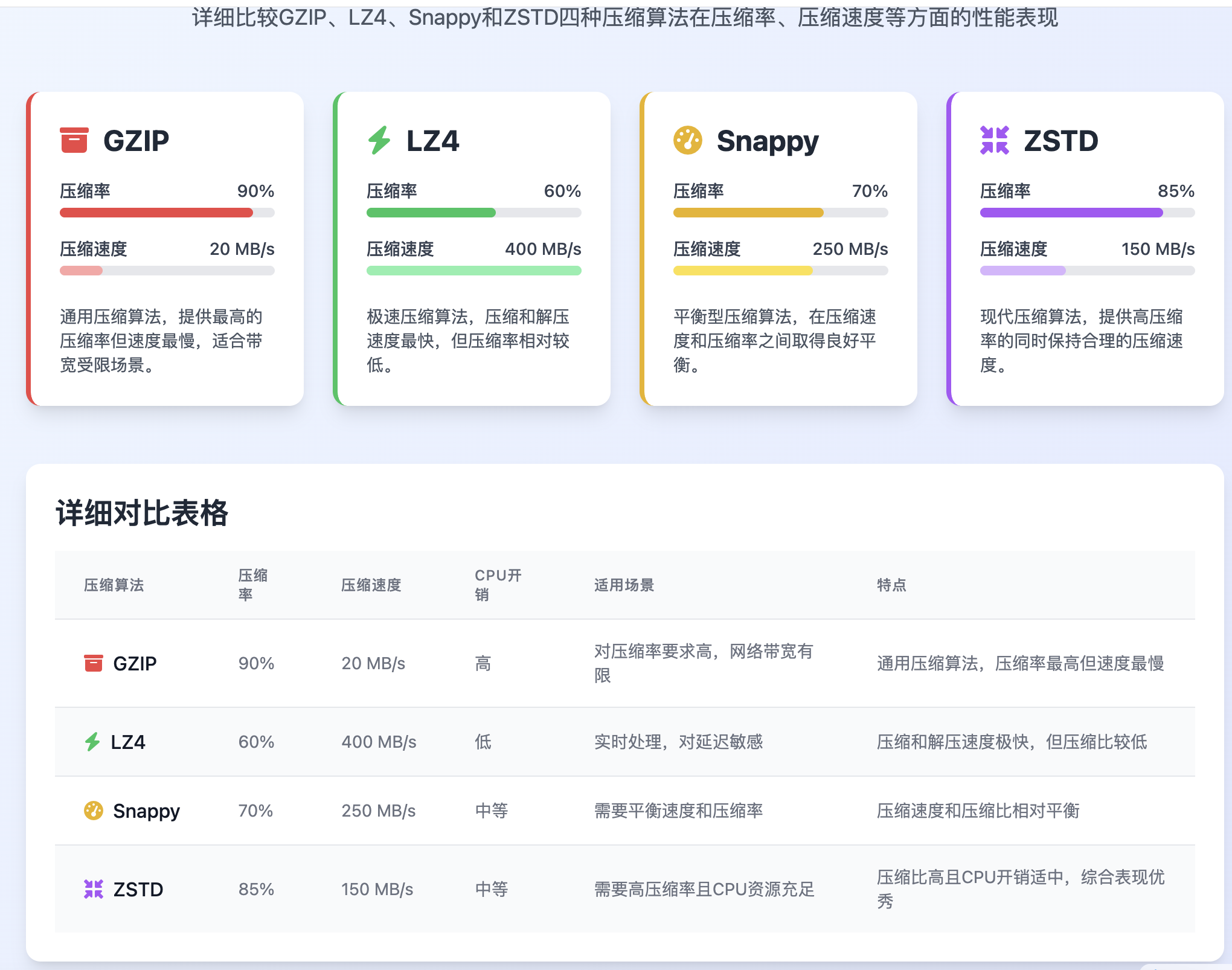
4. 选择合适的压缩方式
选择哪种压缩方式取决于具体的应用场景。例如,如果你对延迟敏感,可能会选择 snappy 或 lz4;如果对压缩率有较高要求,可能会选择 gzip 或 zstd。在实际部署前,建议根据数据特性和性能需求进行测试,以确定最合适的压缩方式。
通过合理配置和使用数据压缩,可以优化 Kafka 的存储效率和网络传输效率,从而提升整体性能和降低成本。
附件一:图表总结
附件二:kafka常用命令
Kafka的常用命令主要涵盖服务管理、Topic管理、消息生产与消费、消费者组管理以及偏移量查询等操作。
服务管理
- 启动服务 :使用
kafka-server-start.sh脚本,通常需要指定配置文件。- 前台启动:
bin/kafka-server-start.sh config/server.properties - 后台启动:
bin/kafka-server-start.sh -daemon config/server.properties Kraft模式启动:bin/kafka-server-start.sh config/kraft/server.properties
- 前台启动:
- 停止服务 :使用
kafka-server-stop.sh脚本。
Topic管理
- 创建Topic :使用
kafka-topics.sh脚本,需指定Zookeeper连接、Topic名称、分区数和副本因子。- 示例:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test --partitions 3 --replication-factor 1
- 示例:
- 查看Topic列表 :
bin/kafka-topics.sh --list --zookeeper localhost:21811 - 查看Topic详情 :
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test- 可使用
--unavailable-partitions或--under-replicated-partitions参数检查问题分区。
- 可使用
- 修改Topic分区数(仅可增加) :
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic test --partitions 5 - 删除Topic :
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test
生产与消费
- 发送消息(生产者) :使用
kafka-console-producer.sh脚本,需指定Broker列表和Topic名称。- 示例:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
- 示例:
- 消费消息(消费者) :使用
kafka-console-consumer.sh脚本,需指定Bootstrap Server和Topic名称。- 从头开始消费:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning - 从最新位置消费:不加
--from-beginning参数。 - 可指定消费者组、分区、偏移量或最大消息数等参数进行更精细控制。
- 从头开始消费: