Transformer实战(36)------Transformer模型部署
0. 前言
我们已经学习了如何从零开始训练和使用 Transformer 模型,还掌握了如何针对多种任务进行微调。但我们尚未学习如何在实际生产环境中部署这些模型。本节将介绍如何在生产环境中部署基于 Transformer 的自然语言处理 (Natural Language Processing, NLP) 解决方案。我们将介绍 TensorFlow Extended (TFX) 作为机器学习部署的解决方案。此外,还会讲解如何通过 FastAPI 等工具将 Transformer 模型作为 API 提供服务。还将了解 Docker 的基础知识,并学习如何将服务 Docker 化以便于部署。最后,将学习如何使用 Locust 对基于 Transformer 的解决方案进行速度和负载测试。
1. 使用 FastAPI 部署 Transformer 模型
我们可以使用多种 Web 框架来部署模型,例如 Sanic、Flask 和 FastAPI。在本节中,我们将使用 FastAPI 部署模型,还将使用 Pydantic 来定义数据类。
(1) 在开始之前,需要安装 Pydantic 和 FastAPI:
shell
$ pip install pydantic
$ pip install fastapi(2) 接下来,使用 Pydantic 为 API 的输入定义数据模型。在定义数据模型之前,我们需要了解模型的结构并确定输入数据的形式。本节,我们将使用一个问答 (Question Answering, QA) 模型,输入数据包括问题和上下文。
(3) 定义 QA 数据模型,用于构建问答数据模型:
python
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
class QADataModel(BaseModel):
question: str
context: str(4) 我们需要预先加载模型,而不是在每次请求时加载。因为每次我们向服务器发送请求时,都会调用端点函数,如果每次都加载模型会导致效率低下:
python
from transformers import pipeline
model_name = 'distilbert-base-cased-distilled-squad'
model = pipeline(model=model_name, tokenizer=model_name, task='question-answering')(5) 接下来,创建一个 FastAPI 实例来管理应用程序:
python
app = FastAPI()(6) 然后,创建一个FastAPI端点:
python
@app.post("/question_answering")
async def qa(input_data: QADataModel):
result = model(question = input_data.question, context=input_data.context)
return {"answer": result["answer"]}使用 async 关键字可以使函数以异步模式运行,从而并行处理多个请求。还可以通过设置 workers 参数来增加 API 的工作进程数,使其能够同时处理多个独立的 API 调用。
(7) 使用 uvicorn 运行应用程序并将其作为 API 提供服务。uvicorn 是一个超快的 Python API 服务器实现,能够最大限度地提升运行速度。使用以下代码运行服务:
python
if __name__ == '__main__':
uvicorn.run('main:app', workers=1) (8) 将上述代码保存为 .py 文件 (main.py),然后通过以下命令运行:
python
python main.py运行后,在终端中可以看到以下输出:
 )
)
(9) 接下来,测试 API。我们可以使用多种工具进行测试,Postman 是其中最好的工具之一。在学习如何使用 Postman 之前,先使用以下代码进行测试:
shell
$ curl --location --request POST 'http://127.0.0.1:8000/question_answering' --header 'Content-Type: application/json' --data-raw '{ "question":"What is extractive question answering?", "context":"Extractive Question Answering is the task of extracting an answer from a text given a question. An exampleof a question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune amodel on a SQuAD task, you may leverage the `run_squad.py`."}'输出结果如下所示:
shell
{"answer":"the task of extracting an answer from a text given a question"}cURL 是一个有用的工具,但不如 Postman 方便。Postman 提供图形用户界面,比命令行工具 cURL 更易于使用。
(10) 下载并安装 Postman 后,可以轻松使用,如下图所示:
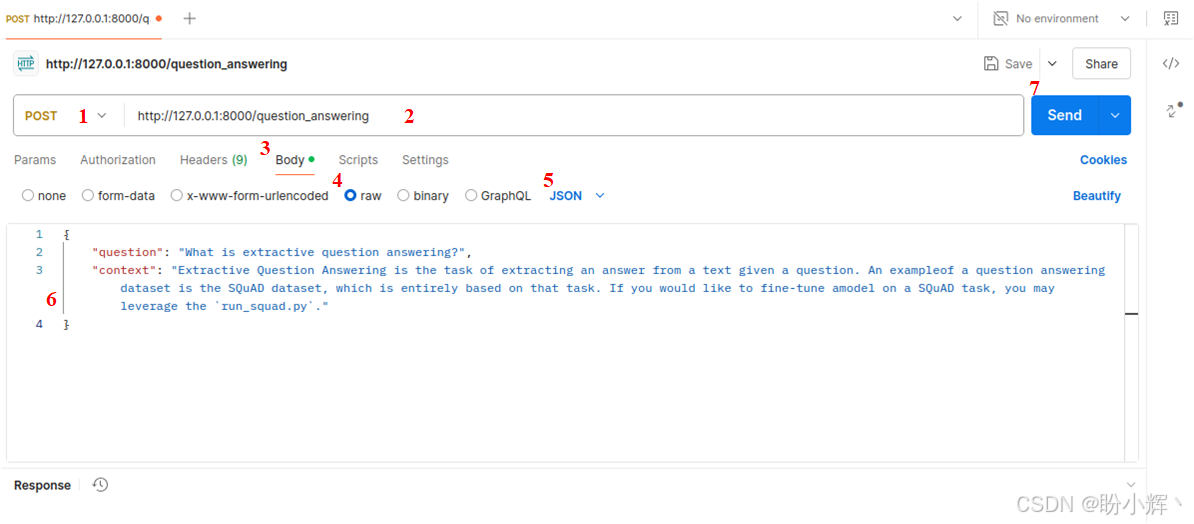
(11) Postman 设置步骤如下所示,图中标号对应以下步骤:
- 选择
POST作为请求方法 - 输入完整的端点
URL - 选择
Body(请求体) - 设置
Body为raw - 选择
JSON数据类型 - 以
JSON格式输入数据 - 点击
Send(发送)
完成后,可以在 Postman 的底部区域看到结果。
2. Docker 化 API
接下来,将学习如何将基于 FastAPI 的 API 进行 Docker 化。掌握 Docker 的基础知识对于打包和部署 API至关重要。
为了节省生产时间并简化部署过程,使用 Docker 是至关重要的。Docker 可以很好地隔离服务和应用程序,确保相同的代码可以在任何操作系统上运行。为了实现这一点,Docker 提供了强大的功能和打包能力。在使用 Docker 之前,需要按照 Docker 官方文档中的步骤安装Docker。
(1) 首先,将 main.py 文件放入 app 目录中。
(2) 接下来,删除代码的最后一部分,即以下内容:
python
if __name__ == '__main__':
uvicorn.run('main:app', workers=1) (3) 为 FastAPI 服务创建一个 Dockerfile,Dockerfile 内容如下:
python
FROM python:3.10
RUN pip install torch
RUN pip install fastapi uvicorn transformers
EXPOSE 80
COPY ./app /app
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port",
"8000"](4) 接下来,构建 Docker 容器:
shell
$ docker build -t qaapi .(5) 然后使用以下命令启动容器:
shell
$ docker run -p 8000:8000 qaapi现在,可以通过端口 8000 访问自定义 API。同样可以按照上一小节介绍的步骤,使用 Postman 进行测试。
3. 使用 TFX 提升 Transformer 模型服务速度
我们已经学习了如何基于 Transformer 模型创建自己的 API,并使用 FastAPI 部署模型,同时还掌握了如何将其 Docker 化。接下来,我们将学习如何通过 TFX 来提升模型服务性能。
TensorFlow Extended (TFX) 提供了一种更快速、更高效的方式来服务基于深度学习的模型,但在使用之前,需要了解一些重要的关键点。模型必须是 TensorFlow 的保存模型文件格式,才能被 TFX Docker 或 CLI 使用。
(1) 可以通过使用 TensorFlow 的 SavedModel 格式来进行 TFX 模型服务。要将 Transformer 模型转换为 TensorFlow 保存的模型文件格式,可以使用以下代码:
python
from transformers import TFBertForSequenceClassification
model = TFBertForSequenceClassification.from_pretrained("nateraw/bert-base-uncased-imdb", from_pt=True)
model.save_pretrained("tfx_model", saved_model=True)(2) 在使用 TFX 服务之前,需要拉取 TFX 的 Docker 镜像:
shell
$ docker pull tensorflow/serving(3) 拉取 Docker 镜像后,运行 Docker 容器并将保存的模型文件复制到容器中:
shell
$ docker run -d --name serving_base tensorflow/serving(4) 将保存的模型文件复制到 Docker 容器:
shell
$ docker cp tfx_model/saved_model tfx:/models/bert(5) 复制到容器后,提交更改:
shell
$ docker commit --change "ENV MODEL_NAME bert" tfx my_bert_model(6) 一切准备就绪后,可以停止 Docker 容器:
shell
$ docker kill tfx现在模型已经准备就绪,可以通过 TFX 模型的 Docker 容器提供服务,我们可以将其与其他服务结合使用。我们需要另一个服务来调用 TFX 的原因在于,基于 Transformer 的模型需要通过分词器 (tokenizer) 提供特殊的输入格式。
(7) 为此,需要创建一个 FastAPI 服务,用于将由 TensorFlow 服务容器提供的模型 API 进行包装。在编写服务代码之前,应当通过指定参数来启动 Docker 容器并运行基于 BERT 的模型。这有助于在出现错误时进行调试:
shell
$ docker run -p 8501:8501 -p 8500:8500 --name bert my_bert_model(8) main.py文件的内容如下:
python
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
from transformers import BertTokenizerFast, BertConfig
import requests
import json
import numpy as np
tokenizer = BertTokenizerFast.from_pretrained("nateraw/bert-base-uncased-imdb")
config = BertConfig.from_pretrained("nateraw/bert-base-uncased-imdb")
class DataModel(BaseModel):
text: str
app = FastAPI()
@app.post("/sentiment")
async def sentiment_analysis(input_data: DataModel):
print(input_data.text)
tokenized_sentence = [dict(tokenizer(input_data.text))]
data_send = {"instances": tokenized_sentence}
response = requests.post("http://localhost:8501/v1/models/bert:predict", data=json.dumps(data_send))
result = np.abs(json.loads(response.text)["predictions"][0])
return {"sentiment": config.id2label[np.argmax(result)]}
if __name__ == '__main__':
uvicorn.run('main:app', workers=1) (9) 我们加载了配置文件,因为标签存储在其中,我们需要将这些标签返回给结果。通过以下命令运行这个 Python 文件:
shell
$ python main.py现在,服务已启动并准备就绪。可以通过 Postman 进行访问,如下图所示:
基于 TFX Docker 中的服务的整体架构如下图所示:

我们已经学习了如何使用 TFX 部署模型。了解服务的性能极限以及何时通过量化 (quantization) 或剪枝 (pruning)进行优化非常重要。在下一节中,我们将介绍如何使用 Locust 测试模型在高负载下的性能表现。
4. 使用 Locust 进行负载测试
有许多应用程序可以用来对服务进行负载测试,这些应用程序和库大多能提供有关服务响应时间和延迟的有用信息,同时也能提供故障率的相关数据。本节中,我们将使用 Locust 对三种基于 Transformer 模型的服务方法进行负载测试:仅使用 FastAPI、使用 Docker 化的 FastAPI 和基于 TFX 的 FastAPI 服务。
(1) 首先,需要安装 Locust:
python
pip install locust接下来,我们需要确保所有服务使用相同的模型来执行相同的任务。通过固定测试中的两个重要参数,可以确保所有服务已被设计为执行单一的任务。使用相同的模型有助于我们固定其他因素,专注于对比不同部署方法的性能。
(2) 接下来,可以开始对 API 进行负载测试。需要准备一个 locustfile 实例来定义用户及其行为。以下是一个简单的 locustfile 代码示例:
python
from locust import HttpUser, task
from random import choice
from string import ascii_uppercase
class User(HttpUser):
@task
def predict(self):
payload = {"text": ''.join(choice(ascii_uppercase) for i in range(20))}
self.client.post("/sentiment", json=payload)通过创建继承自 HttpUser 的 User 类,我们可以定义一个 HttpUser 类。@task 装饰器是定义用户在生成后必须执行的任务。predict 函数是用户在创建后会重复执行的实际任务。它将生成一个长度为 20 的随机字符串,并将其发送到 API。
(3) 要开始测试,首先需要启动启动服务。服务启动后,运行以下代码来启动 Locust 负载测试:
python
locust -f locust_file.pyLocust 将根据 locustfile 中提供的设置启动。在终端可以看到以下内容:

(4) 打开负载测试的 Web 界面,即 http://0.0.0.0:8089。打开 URL 后,可以看到如下界面:
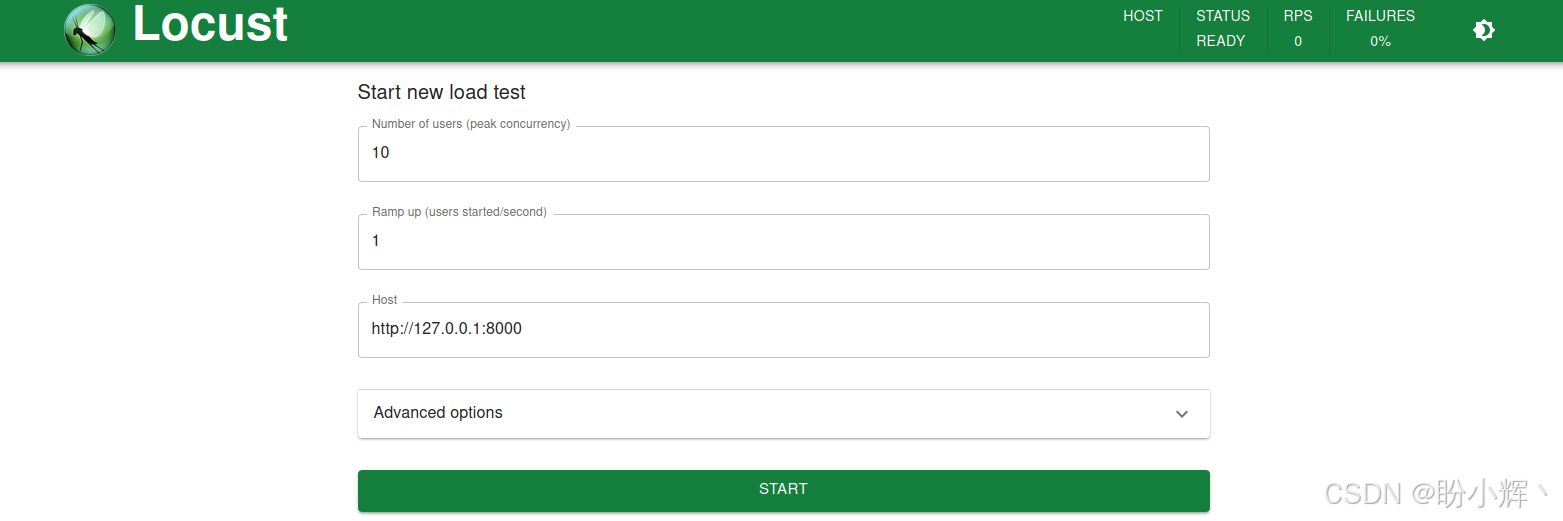
如图所示,将 "Number of total users to simulate" (模拟的用户总数)设置为 10,"Spawn rate" (生成速率)设置为 1,"Host" 设置为 http://127.0.0.1:8000,即服务运行的地方。设置这些参数后,点击 "Start swarming" 开始测试。
(5) 测试开始后,可以随时点击 "Stop" 按钮停止测试。
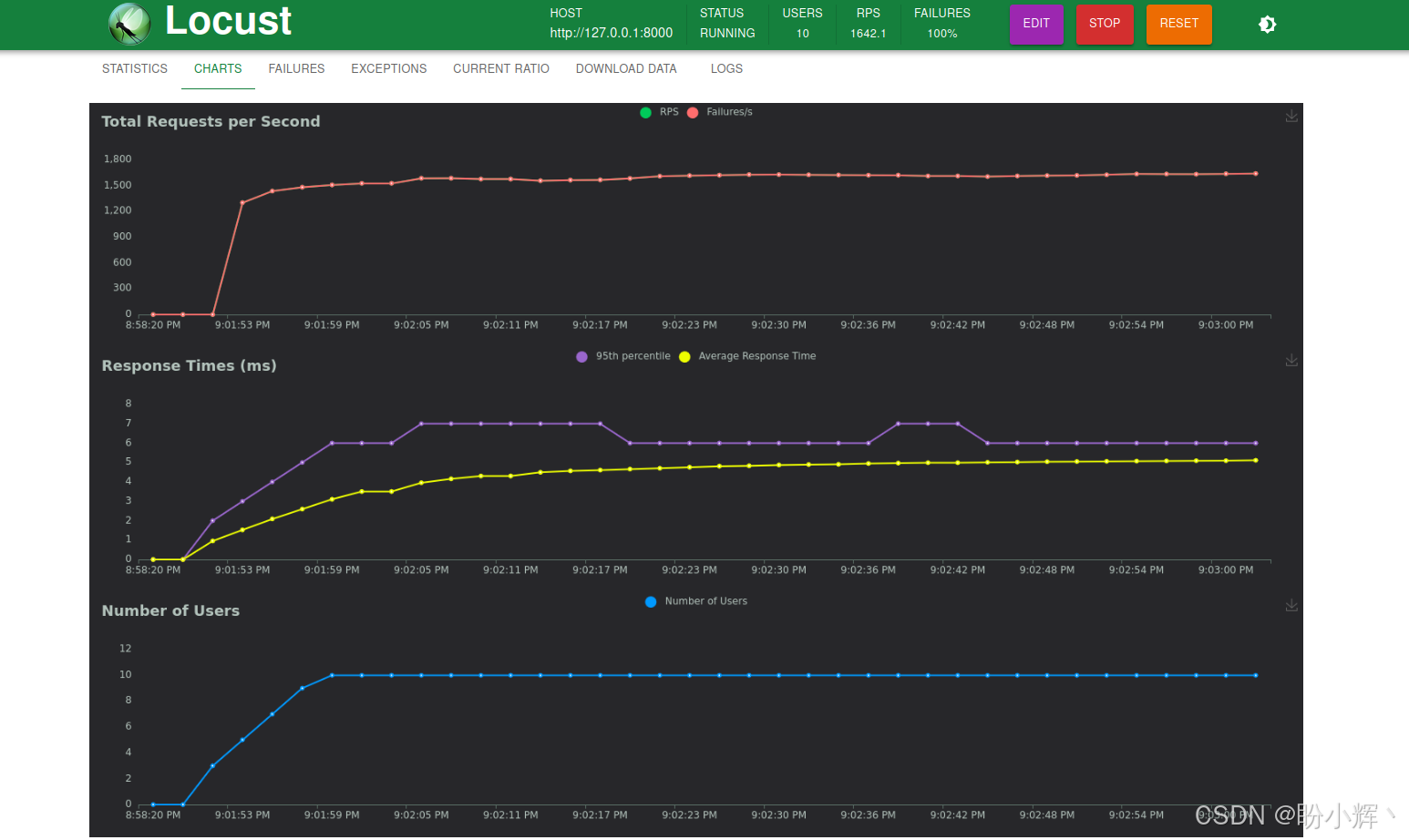
(6) 还可以点击 "Charts" 选项卡,查看结果的可视化图表。
(7) 现在,API 的测试已经准备就绪,我们测试将测试仅使用 FastAPI、使用 Docker 化的 FastAPI 和基于 TFX 的 FastAPI 服务三种版本,并比较结果,观察哪个版本表现更好。需要注意的是,服务必须在希望部署它们的机器上独立测试。换句话说,必须一次运行一个服务:先运行并测试第一个服务,然后关闭它,再运行并测试第二个服务,依此类推。
测试结果如下表所示:
| 基于 TFX 的 FastAPI | FastAPI | Docker 化的 FastAPI | |
|---|---|---|---|
| RPS | 38.5 | 33 | 34 |
| RT | 237 | 275 | 270 |
在上表中,每秒请求数 (requests per second, RPS) 表示 API 每秒处理的请求数量,而响应时间 (response time, RT) 表示服务响应一个请求所需的毫秒数。这些结果显示,基于 TFX 的 FastAPI 是最快的,它具有更高的 RPS 和更低的平均 RT。
在本节中,我们学习了如何测试 API 并衡量其性能,重点关注了 RPS 和 RT 等重要参数。但现实世界中的 API 还可以进行许多其他压力测试,例如增加用户数量,模拟真实用户行为。为了更真实地执行这些测试并报告结果,可以通过阅读 Locust 官方文档,学习如何进行更高级的测试。
推理 (Inference) 在部署模型时始终起着至关重要的作用。在下一节中,我们将使用 ONNX 来加速模型的推理。
5. 使用 ONNX 加速推理
ONNX (Open Neural Network Exchange) 为训练好的模型提供了更快的推理速度。而 Optimum 库提供了更简便的 ONNX 导出功能,可以处理基于 Hugging Face 的模型管道,使用和实现非常简单。
(1) 首先,使用 pip 命令安装 optimum 和 onnxruntime 库:
python
pip install optimum[onnxruntime](2) 使用 Optimum 加载管道:
python
from optimum.pipelines import pipeline
pipe = pipeline("text-classification", "cardiffnlp/twitter-xlm-roberta-base-sentiment", accelerator="ort")有两种加速器可供选择:ONNX 运行时 (ORT, ONNX Runtime) 和 BETTERTRANSFORMER。ORT 用于将模型导出为 ONNX 格式。在本节示例中,我们选择了基于 XLM-Roberta 的多语言情感分析模型。模型转换为 ONNX 格式后,可以轻松运行管道:
python
pipe("It was a great movie!")
# [{'label': 'positive', 'score': 0.9436209201812744}]通过简单地更改模型加载方式并将其转换为 ONNX 格式,显著提高了模型的延迟性能,并提供了更快的推理速度。
小结
在本节中,学习了如何使用 FastAPI 部署 Transformer 模型,还介绍了如何通过更高级和更高效的方法(例如使用 TFX )来部署模型。接着,学习了负载测试的基础知识以及如何创建用户,并报告压力测试的结果。此外,还了解了 Docker 的基础,并学习了如何将应用打包成 Docker 容器。最后,学习了如何提供基于 Transformer 的模型服务。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型
Transformer实战(35)------跨语言相似性任务