一. 前言
在上篇中,我们已经系统地梳理了 C++ 单继承的基本规则:
访问权限、构造与析构顺序、成员隐藏等问题,本质上都围绕着派生类对象中包含一个完整的基类子对象这一事实展开
然而,当继承关系不再是一对一,而是多个基类同时存在时,事情就开始变得复杂起来。
-
同名成员该访问哪一个
-
一个对象里到底有几个基类子对象
-
为什么会出现二义性
-
编译器又是如何通过虚继承解决这些问题的
这些问题几乎都集中在多继承与菱形继承场景中,也是 C++ 继承机制最容易被误解、最容易出错的部分。
因此,在这一篇中,我们将重点讨论:
-
多继承的对象布局与二义性问题
-
菱形继承产生的根本原因
-
虚继承的设计目的与工作原理
理解了这些内容,才能真正走向理解继承在底层是如何工作的
二. 基类与派生类之间的转换
在 public 继承体系中,派生类不仅包含了自己新增的成员,还完整地包含了基类的成员。基于这种关系,C++ 允许在基类和派生类之间进行特定的类型转换
假如我们有一个 Person 类和一个 Student 类
cpp
class Person
{
pubic:
std::string _name;
int _age;
bool _sex;
}
class Student : public Person
{
public:
int _grade;
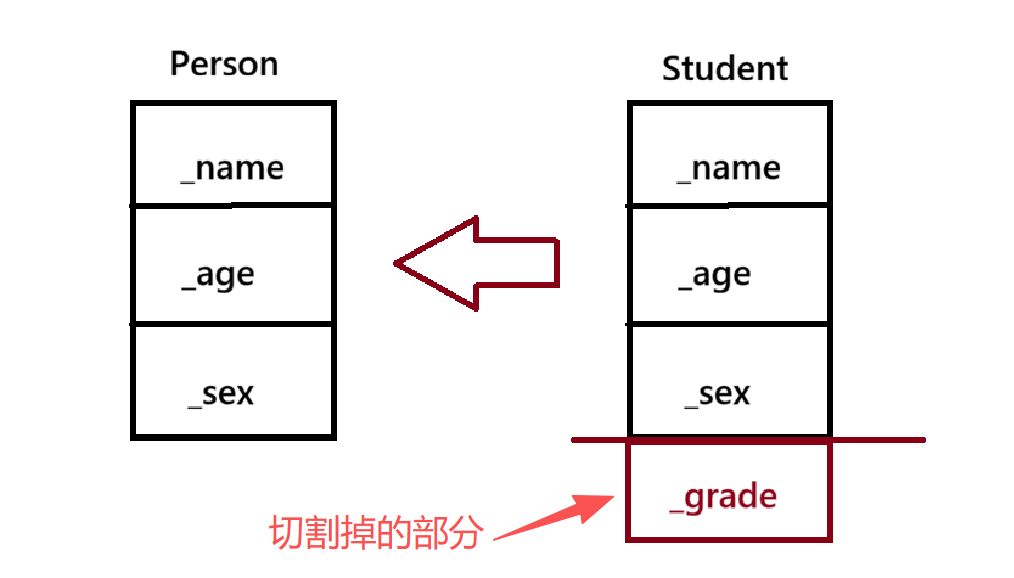
}- 向上转型(Upcasting)与形象的切片
我们可以将派生类对象赋值给基类的对象 / 指针 / 引用。在 C++ 中,这个过程有一个非常形象的叫法------切片(切割)
对象赋值: 如果是赋值给基类对象(Base b = d;),派生类特有的成员会被真正切掉丢弃,只保留基类部分。
指针/引用赋值: 如果是赋值给基类指针或引用(Base* pb = &d;),并不会发生真正的数据丢失,只是指针的视野被限制在了切出来的基类那部分。
cpp
Student stu;
// 1. 切片(向上转型):天然支持,非常安全
Person per1 = stu; // 对象切片:派生类成员被丢弃,只把基类成员拷贝
Person* per2 = &stu; // 指针切片:stu 指向 per2 中的基类部分
Person& per3 = stu; // 引用切片:stu 引用 per3 中的基类部分- 严禁反向赋值:基类对象不能赋值给派生类对象
这是一个硬性规定。因为派生类通常比基类拥有更多的成员变量。如果允许把基类对象赋值给派生类对象,派生类中多出来的那部分成员将处于未初始化状态,这是极其危险的,因此编译器会直接报错。
cpp
// 2. 错误示范:基类对象绝对不能赋给派生类对象
Person per;
Student stu;
stu = per; // 编译报错- 向下转型(Downcasting):指针/引用的强制转换
基类对象不行,那基类的指针或引用可以赋值给派生类吗?
语法上可以通过强制类型转换将基类指针/引用转为派生类指针/引用。
只有当这个基类指针原本就指向一个派生类对象时,这种转换才是安全的。如果它本来指向的就是个纯基类对象,强转后去访问派生类成员就会导致越界崩溃。
dynamic_cast: 如果基类是多态类型,C++ 提供了基于 RTTI(运行时类型识别)的 dynamic_cast 来进行安全检查。如果转换不安全,它会返回空指针
cpp
// 3. 向下转型:有条件的安全
Student stu;
Person* per1 = &stu; // per1 实际指向派生类
Person* per2 = new Person(); // per2 实际指向基类
Student* stu1 = (Student*)per1; // 安全:因为 per1 本来指的就是 Student
Student* stu2 = (Student*)per2; // 危险:语法能过,但 per2 实际是 Person
per2->_grade = 1; // 越界访问!程序可能崩溃三. 多继承的基本问题
3.1 什么是多继承
cpp
class A {};
class B {};
class C : public A, public B {};C 类同时继承自 A 类和 B 类,其对象内部包含来自 A 类和 B 类的子对象
这在语法上完全合法
3.2 多继承引发的二义性问题
cpp
class A { public: int x; };
class B { public: int x; };
class C : public A, public B {};
C c;
c.x; // 二义性问题!当 A 类和 B 类中都包含成员变量 x 时,编译器无法确定用户具体使用的 x 属于哪个类
解决方式
cpp
c.A::x;
c.B::x;四. 菱形继承与数据冗余
菱形继承是多继承中的一种特殊情形。通过分析对象成员模型可以看出,菱形继承会导致数据冗余和二义性问题,例如在 Assistant 对象中会出现两份 Person 成员。实际上,只要支持多继承就必然存在菱形继承的可能性。为了避免这个问题,例如 Java 这样的语言直接选择不支持多继承。在实际开发中,我们也不建议采用菱形继承的设计模式
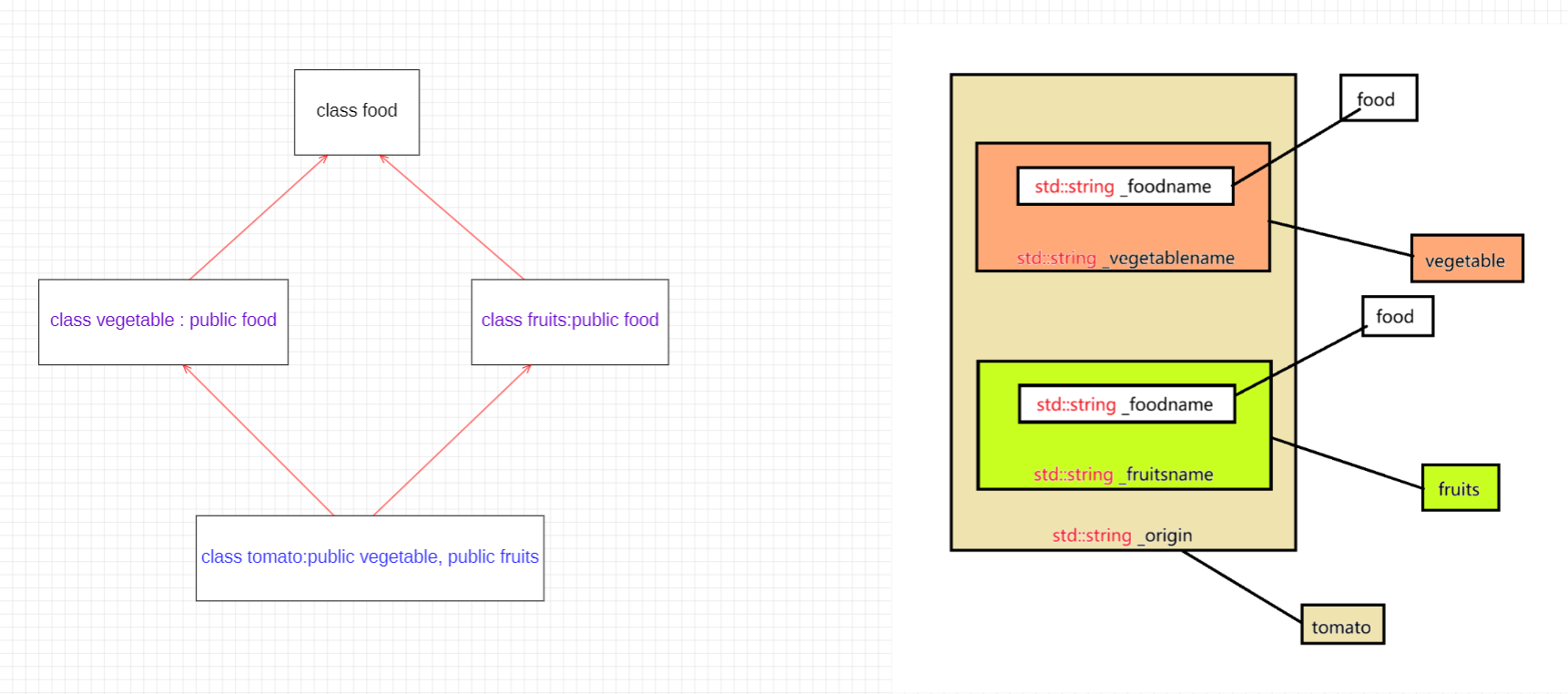
cpp
class food
{
public:
std::string _foodname;
}
class vegetable : public food
{
public:
std::string _vegetablename;
}
class fruits : public food
{
public:
std::string _fruitsname;
}
class tomato : public vegetable, public fruits
{
public:
std::string _origin; // 产地
}问题核心: food 被继承了两次
tomato 类中有两个 food 子对象, 这会导致数据冗余和成员访问二义性问题
五. 虚继承
很多人认为 C++ 语法复杂,其中多继承就是典型例子。多继承会引发菱形继承问题,进而导致菱形虚拟继承,这使得底层实现变得异常复杂,并可能带来性能损耗。因此,建议尽量避免设计出菱形继承结构。可以说,多继承是C++的一个设计缺陷,这也解释了为什么后续的编程语言(如Java)都摒弃了多继承机制。
虚继承语法
cpp
class vegetable : virtual public food {};
class fruits : virtual public food {};
class tomato : public vegetable, puslic fruits {};效果与代价
在 tomato 中仅保留一份 food,vegetable 和 fruits 共享同一个 food 实例
虚继承不是让继承变虚,而是让基类子对象唯一化。
然而虚继承会增加对象布局的复杂性,并改变构造顺序,因此通常不建议主动使用。只有在确实遇到菱形继承问题时,才考虑采用这种方案
经典面试题
这里 t 对象中 _foodname 是"carrot", "apple", "banana"中的哪一个?
cpp
class food
{
public:
food(const char* _name) :_foodname(_name)
{}
std::string _foodname;
}
class vegetable : public food
{
public:
vegetable(const char* _name) :food(_name)
{}
}
class fruits : public food
{
public:
fruits(const char* _name) :food(_name)
{}
}
class tomato : public vegetable, public fruits
{
public:
Assistant(const char* name1, const char* name2, const char* name3)
:food(name3)
,vegetable(name1)
,fruits (name2)
{}
}
int main()
{
tomato t("carrot", "apple", "banana");
return 0;
}核心考点:虚基类由最底层的派生类负责初始化
在普通的单继承或多继承中,派生类只需要负责调用其直接基类的构造函数。但在这段代码中,涉及到了虚继承构成的菱形继承体系。
为了解决数据冗余,虚继承保证了最顶层的基类 food 在整个 tomato 对象的内存中只有唯一的一份实例。既然只有一份,那到底该听谁的来初始化呢?是听 vegetable 的,还是听 fruits 的?
为了解决这个冲突,C++ 制定了严格的规则:
一锤定音: 虚基类(food)的初始化工作,绝对且唯一地交由最底层的派生类(tomato)来直接负责。
中间层靠边站: 当我们创建 Assistant 对象时,编译器在执行构造函数时,会自动忽略中间层基类(vegetable 和 fruits)初始化列表里对 food 的调用请求。
复盘代码:
-
首先执行了 tomato t("carrot", "apple", "banana");
-
编译器看到 tomato 的初始化列表:food(name3), vegetable(name1), fruits(name2)
-
编译器首先直接调用 food(name3),此时 name3 的值是 "banana"。这唯一的 food 实例就被初
始化了。
- 接着编译器去调用 vegetable 和 fruits 的构造函数。虽然 vegetable 想传 "carrot" 给 food,fruits
想传 "apple" 给 food,但因为 food 是虚基类,且已经被最底层的 tomato 初始化过了,所以 vegetable 和 fruits 里的 :food(_name) 会被编译器直接无视。
这也是为什么在使用虚继承时,即使最底层的派生类在字面上与虚基类隔了好几层,我们也必须在最底层派生类的初始化列表中显式调用虚基类的构造函数(如果虚基类没有默认构造函数的话),否则编译器会报错
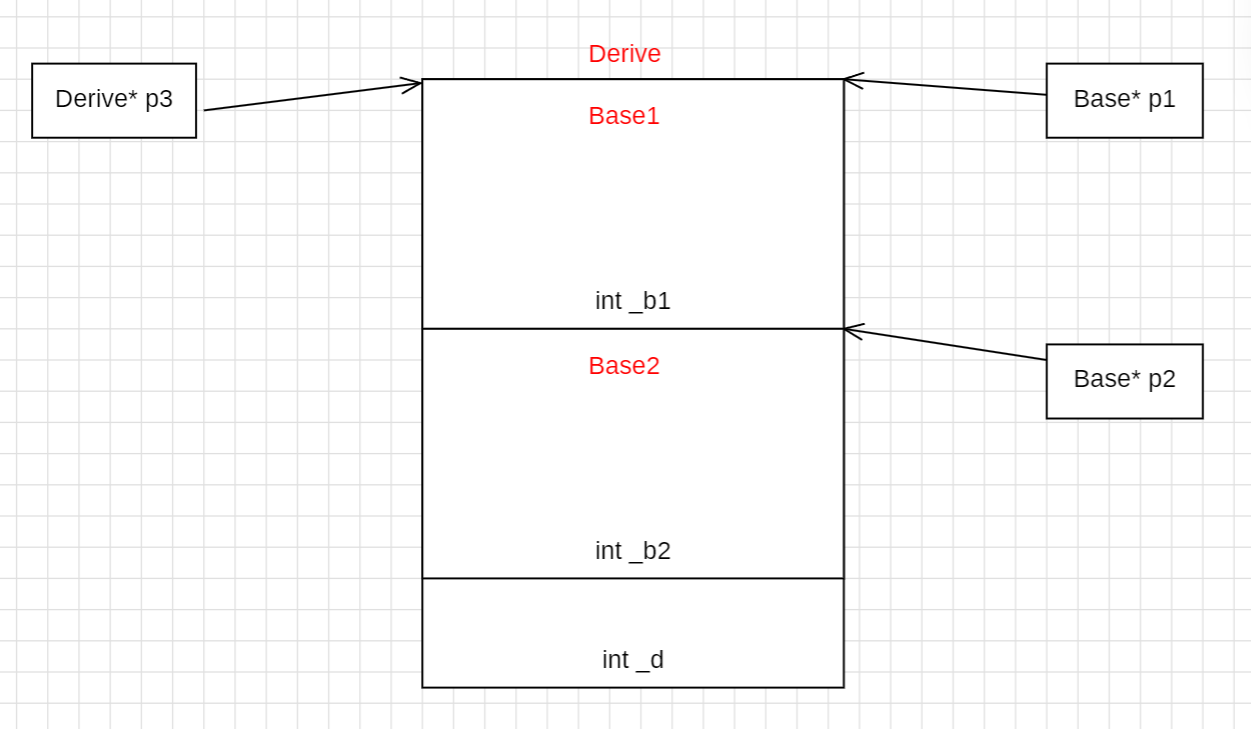
多继承中指针偏移问题
下面说法正确的是( )
A:p1 == p2 == p3 B:p1 < p2 < p3 C:p1 == p3 != p2 D:p1 != p2 != p3
cpp
class Base1 { public: int _b1; };
class Base2 { public: int _b2; };
class Derive : public Base1, public Base2 { public: int _d; };
int main() {
Derive d;
Base1* p1 = &d;
Base2* p2 = &d;
Derive* p3 = &d;
return 0;
}核心原理解析:多继承的对象内存模型
在 C++ 中,当一个类发生多继承时,编译器会在底层按照继承列表的声明顺序,将基类的内存依次排列,最后再放派生类自己的成员。
针对上面这道题,Derive d; 对象的内存布局是这样的:
Base1 子对象(排在最前面,因为声明时写在前面)
Base2 子对象(紧跟在 Base1 后面)
Derive 自身的成员 _d(排在最后)
三个指针的赋值操作(本质上是发生了指针切片):
Derive* p3 = &d :p3 是派生类指针,理所当然指向整个 d 对象的起始地址。
Base1* p1 = &d :p1 期望指向 Base1 部分。因为 Base1 刚好排在内存的最开头,所以 p1 的地址和 d 对象的起始地址完全重合。因此,p1 == p3。
Base2* p2 = &d :p2 期望指向 Base2 部分。编译器知道 Base2 前面还挡着一个 Base1,所以会自动给地址加上一个偏移量(即 Base1 的大小),让 p2 准确指向 Base2 子对象的开头。因此,p2 的内存地址比 p1 和 p3 都要大。最终得出 p1 == p3 != p2。
IO库中的菱形虚拟继承
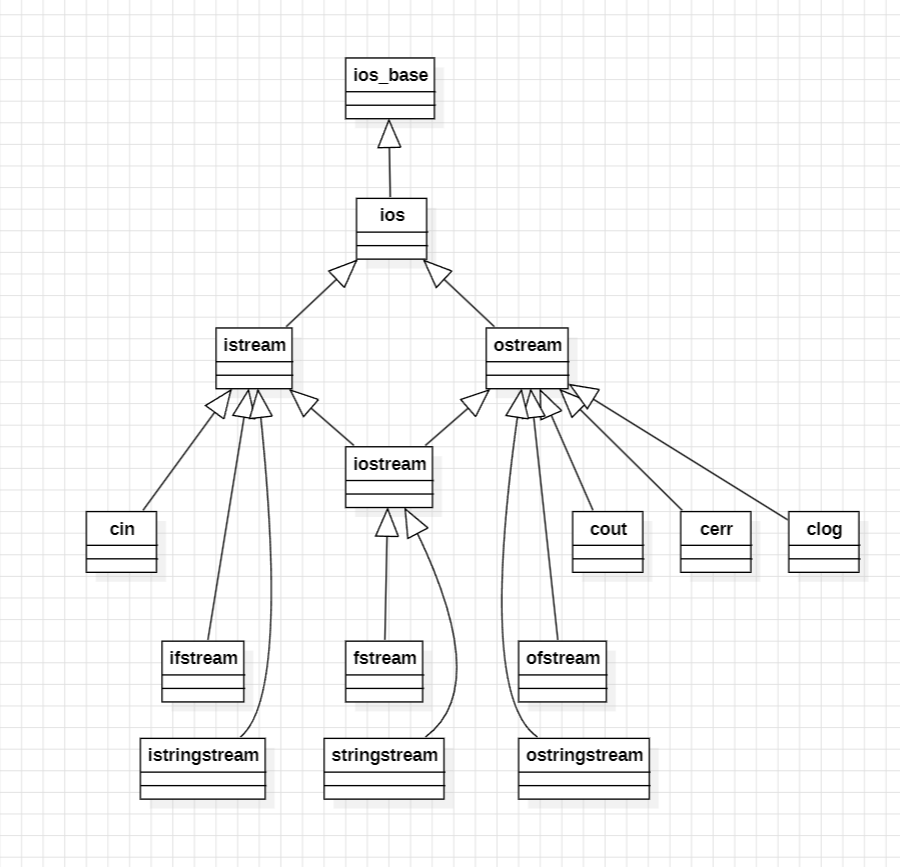
从这张图可以看到,C++ IO 库内部实际上采用了一种典型的菱形继承结构:ios_base 提供流的最基础能力,ios 在其之上封装了缓冲区和状态管理,而 istream 与 ostream 分别表示输入流和输出流,它们同时继承自 ios。当 iostream 需要同时具备输入和输出能力时,便不可避免地同时继承自 istream 和 ostream,从而形成菱形继承。如果这里采用普通继承,iostream 内部将包含两份 ios 子对象,不仅造成状态与资源的重复,还会引发成员访问的二义性。为了解决这一问题,标准库在 istream 和 ostream 中对 ios 采用了虚继承,从而保证在最终的 iostream 对象中只存在唯一的一份 ios 子对象。这样的设计清晰地体现了虚继承存在的现实意义与必要性。
六. 继承与组合
在面向对象编程中,当我们想要复用已有类的代码时,通常面临两种选择:继承 (Inheritance)和组合(Composition)。理解它们之间的区别,是写出高内聚、低耦合代码的关键。
1. 逻辑关系的本质区别
继承是 is-a(是一个)的关系:每个派生类对象不仅拥有基类的全部特征,它在逻辑上本身就是一个基类对象。例如:Student is a Person(学生是一个人)。
cpp
class Person {};
class Student : public Person {};组合是 has-a(有一个)的关系:类 B 中包含了类 A 作为它的成员变量。B 只是借用了 A 的功能,但 B 在逻辑上并不等同于 A。例如:Car has a Engine(汽车有一个发动机)。
cpp
class Engine {};
class Car { Engine engine; };2. 复用方式与封装性:白箱 vs 黑箱
继承的白箱复用(White-box Reuse) :
在继承中,基类的内部细节(如 protected 成员)对派生类是完全可见的。这种复用一定程度上破坏了基类的封装性。一旦基类的内部实现发生改变,派生类往往会受到波及。因此,基类与派生类之间的依赖关系极强,耦合度极高。
组合的黑箱复用(Black-box Reuse):
在组合中,被组合的对象仅仅作为一个黑箱出现,它的内部细节对外是完全隐藏的,只暴露设计良好的公共接口。因此,组合类之间没有很强的依赖关系,耦合度低,极大地保护了各个类的封装性。
3. 终极设计原则:优先使用对象组合,而不是类继承
在实际的工程开发中,我们应该遵循这样的最佳实践:
-
只要业务逻辑上可以接受,优先使用组合。组合带来的低耦合能让代码的后期维护轻松许多。
-
如果两个类之间的关系既可以理解为 is-a,也可以勉强理解为 has-a,毫不犹豫地选择组合。
何时必须用继承?
继承也绝非一无是处。当两个类之间是非常严格的 is-a 关系时(例如猫和动物),或者我们需要利用基类来实现多态时,继承依然是不可替代的唯一选择。
七. 总结
在 C++ 中,继承不仅是一种语法机制,更是一种对象模型的核心组成部分。理解继承的本质需要从对象的内存布局入手,特别是当继承关系变得复杂时(如多继承、菱形继承等场景),掌握对象内部布局比单纯记忆语法规则更为重要。
具体来说,C++ 的继承体系会直接影响对象的内存结构:
- 单继承时,派生类对象包含基类子对象和自身成员,内存布局相对简单
- 多继承时,派生类对象会包含多个基类子对象,可能导致内存对齐问题的复杂变化
- 菱形继承(虚继承)时,需要通过虚基类指针(vbptr)来解决数据冗余问题,这会显著改变对象的内存布局
在实际工程中,继承应当谨慎使用,而组合往往是更稳健的选择。
