目录
[1.1 LangChain与LangGraph:一对"互补者"](#1.1 LangChain与LangGraph:一对“互补者”)
[1.2 Agent的核心组件:五层架构](#1.2 Agent的核心组件:五层架构)
[1.3 ReAct推理范式:思考与行动的交替](#1.3 ReAct推理范式:思考与行动的交替)
[2.1 State机制:Agent的"工作记忆"](#2.1 State机制:Agent的“工作记忆”)
[2.2 Conditional Edge:动态路由的艺术](#2.2 Conditional Edge:动态路由的艺术)
[2.3 自我反思Agent的实现架构](#2.3 自我反思Agent的实现架构)
[3.1 工具调用的完整流程与最佳实践](#3.1 工具调用的完整流程与最佳实践)
[3.2 Memory机制:从Demo到生产](#3.2 Memory机制:从Demo到生产)
当我们谈论Agent时,我们在谈论什么?是工具调用、状态管理,还是推理范式?本文将从零开始,循序渐进地梳理LangChain/LangGraph生态的核心知识点,帮助你构建完整的知识图谱。
一、基础认知:理解Agent的DNA
1.1 LangChain与LangGraph:一对"互补者"
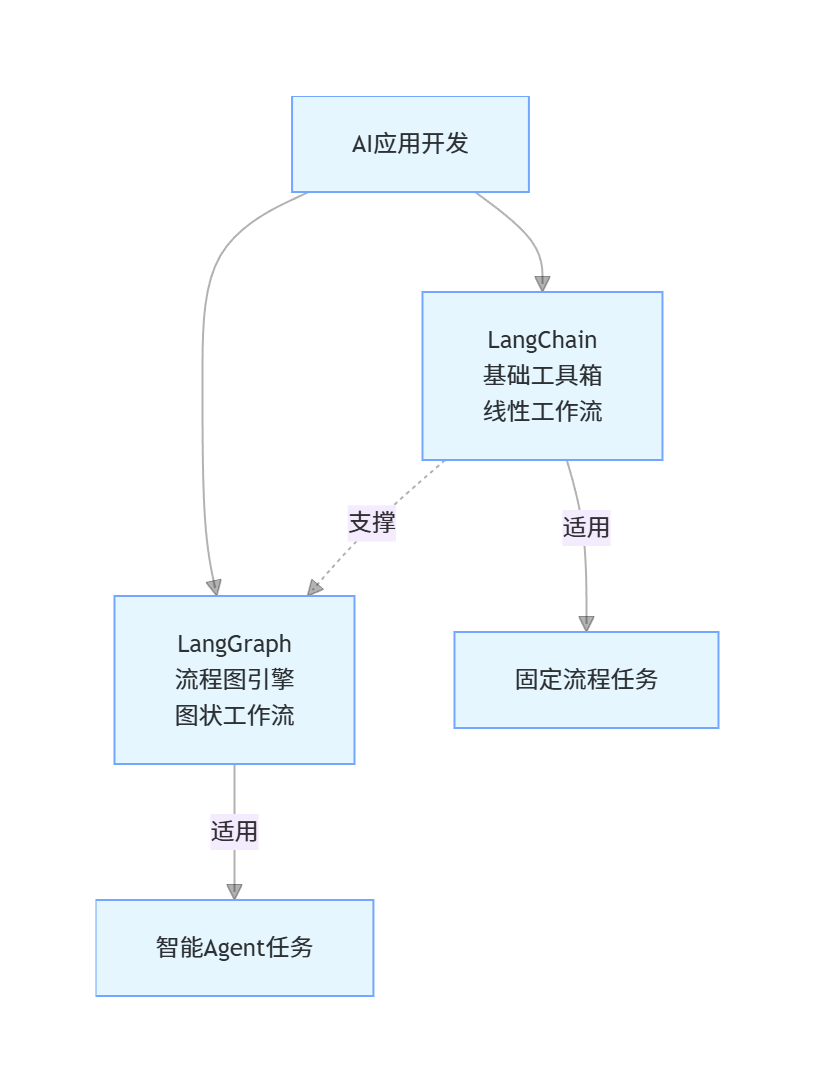
在AI应用开发的世界里,LangChain和LangGraph就像是一对互补的伙伴,它们解决不同层面的问题,却又紧密相连。
LangChain可以理解为一个"AI应用开发工具箱"。它提供了构建LLM应用所需的各种基础组件:
- Models:统一接口对接各类大模型(OpenAI、Claude、本地模型)
- Prompts:模板化管理提示词
- Chains:将多个步骤串联成工作流
- Agents:让LLM具备工具调用能力
- Memory:管理对话历史
- Indexes:对接外部知识库
它的核心抽象是Chain------一种线性、确定性的任务流。就像工厂的流水线,原料从一端进入,经过固定工序,从另一端产出成品。这种模式适合翻译、摘要、信息提取等流程固定的任务。
而LangGraph 则是在这个工具箱之上构建的"流程图引擎"。它将工作流建模为有向图,引入了三个核心概念:
- State(状态):整个工作流共享的数据容器
- Node(节点):执行具体任务的单元
- Edge(边):连接节点,决定执行顺序
为什么要引入图?因为真实的Agent往往不是线性的。一个智能Agent可能需要:
- 循环:自我反思、修正答案
- 分支:根据用户意图走不同路径
- 并行:同时执行多个工具调用
这正是LangGraph的价值所在------它让我们能够构建真正"智能"的Agent。
1.2 Agent的核心组件:五层架构
一个完整的Agent系统可以分解为五个核心组件,它们像人体的不同器官,各司其职又协同工作:
第一层:大脑(LLM)
大语言模型是Agent的决策中枢。它负责理解用户意图、选择合适工具、规划执行步骤。但LLM本身只是一个"思考者",它需要其他组件才能"行动"。
第二层:手脚(Tools)
工具是Agent与外部世界交互的桥梁。通过工具,Agent可以:
- 查询数据库获取实时信息
- 调用API完成特定操作
- 执行计算解决数学问题
- 搜索网络获取最新知识
第三层:执行器(Agent)
Agent执行器是大脑和手脚之间的调度员。它解析LLM的输出,决定是否需要调用工具,如何调用,以及如何处理工具返回的结果。
第四层:记忆(Memory)
记忆组件让Agent具备上下文感知能力。它记录对话历史,维护用户偏好,追踪任务进展。没有记忆的Agent每次对话都是"初次见面"。
第五层:指挥官(Prompts)
提示词是Agent的行动指南。它告诉LLM:
- 你是谁(角色定位)
- 你要做什么(核心任务)
- 你能用什么(工具清单)
- 你该怎么做(思考范式)
这五个组件的协作流程可以用一个循环来描述:
用户输入 → 指挥官(Prompt) → 大脑(LLM) → 需要工具?→ 执行器调用工具 → 观察结果 → 大脑继续思考 → 生成最终答案 → 记忆更新
1.3 ReAct推理范式:思考与行动的交替
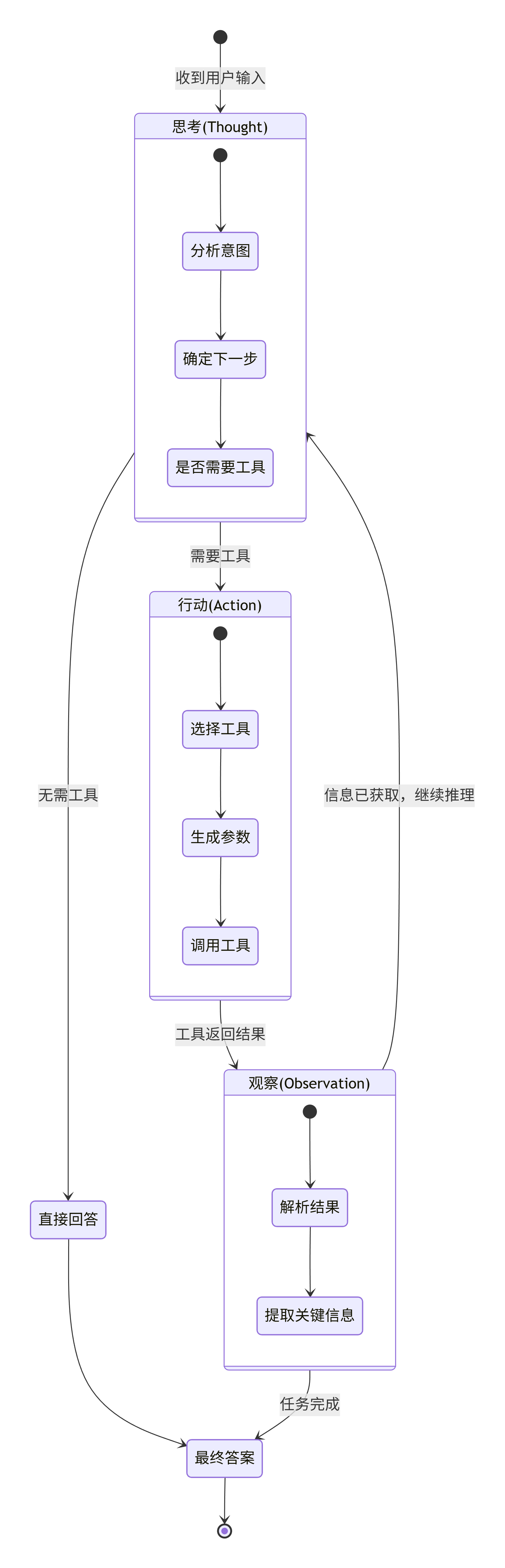
ReAct是"Reason + Act"的缩写,它是一种让LLM在推理和行动之间交替进行的思维模式。这种模式解决了传统LLM无法处理多步复杂任务的问题。
一个典型的ReAct循环包含四个阶段:
思考(Thought):LLM分析当前情况,决定下一步该做什么
"用户问特斯拉最新财报,我需要先查到财报数据才能分析"
行动(Action):LLM选择并调用合适的工具
调用search_tool,关键词"特斯拉2024年Q4财报"
观察(Observation):Agent执行工具后返回结果
返回财报关键数据:营收、利润、交付量等
循环或结束:根据观察结果,LLM决定是继续思考还是给出答案
数据已获取,可以开始分析 → 生成最终回答
这种"思考-行动-观察"的循环让Agent能够:
- 分解复杂问题:把大问题拆解为小步骤
- 依赖外部信息:突破LLM知识的时间限制
- 自我验证:检查每一步的执行结果
二、进阶核心:LangGraph的关键机制
2.1 State机制:Agent的"工作记忆"
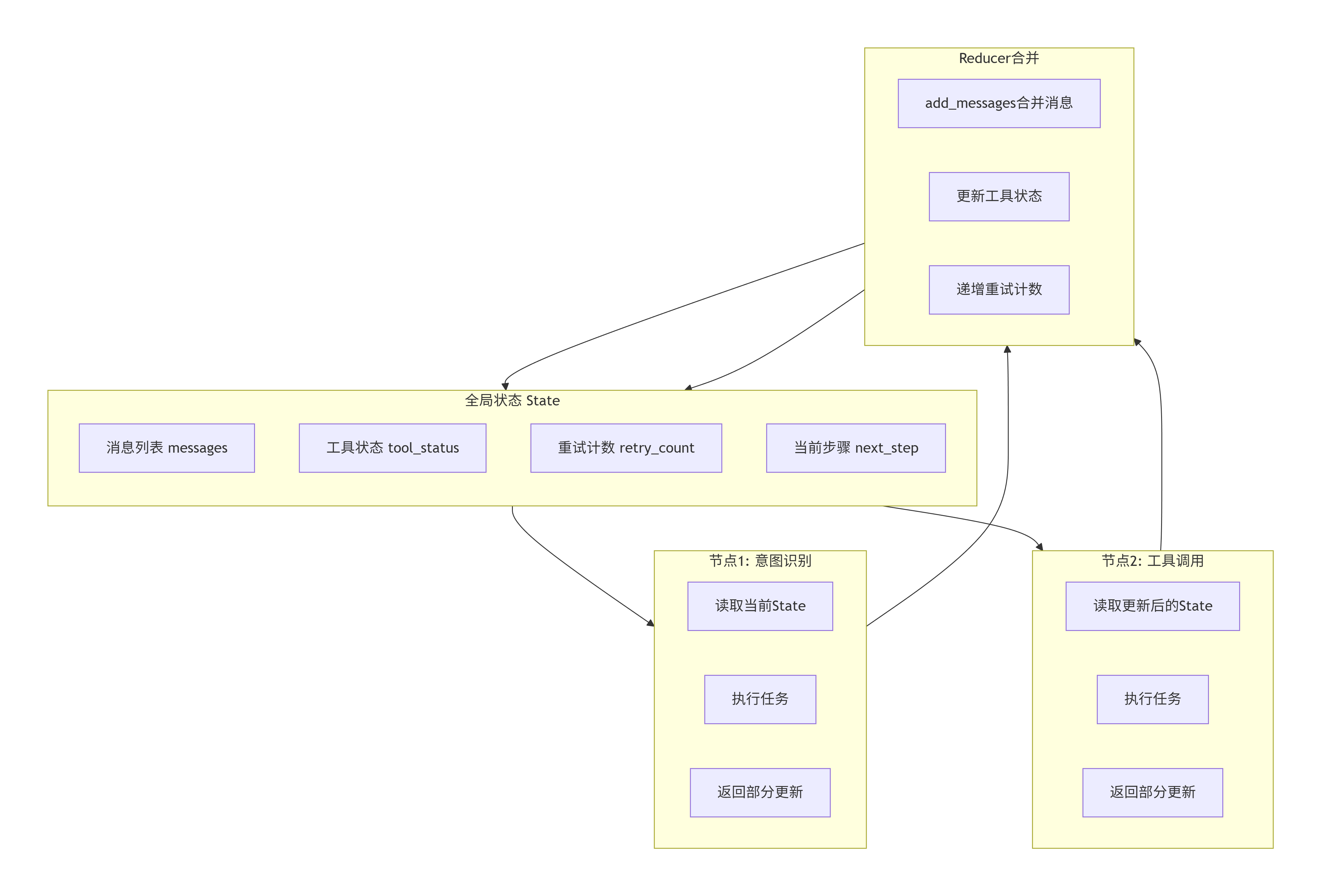
在LangGraph中,**State(状态)**是最核心的抽象。它像是一个贯穿整个工作流的"共享笔记本",所有节点都可以读取和写入。
State通常被定义为一个TypedDict或Pydantic模型:
python
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
# 消息历史,使用add_messages reducer自动合并
messages: Annotated[list, add_messages]
# 当前步骤
next_step: str
# 工具调用状态
tool_status: dict
# 重试计数
retry_count: intState机制的工作原理可以概括为三个步骤:
第一步:初始化
当工作流启动时,创建一个初始State,通常包含用户输入、空的历史记录、默认参数等。
第二步:节点执行与更新
每个节点接收当前State,执行自己的任务,然后返回一个"部分更新"。例如,一个工具调用节点可能只更新tool_status字段。
第三步:合并状态
LangGraph框架会自动将节点的部分更新合并到全局State中。这个过程通过Reducer函数控制,确保更新的确定性。
这种设计带来了三个重要好处:
- 集中管理:所有节点共享同一数据源,避免参数传递混乱
- 可追溯:每个状态变更都有记录,便于调试和回放
- 解耦节点 :节点只关心自己需要的状态字段,不依赖其他节点的实现细节
2.2 Conditional Edge:动态路由的艺术
如果说State是LangGraph的数据层,那么**Conditional Edge(条件边)**就是它的控制层。条件边让工作流能够根据当前State动态决定下一步走向。
条件边的工作原理很简单:它关联一个判断函数,这个函数接收当前State,返回下一个节点的名称。
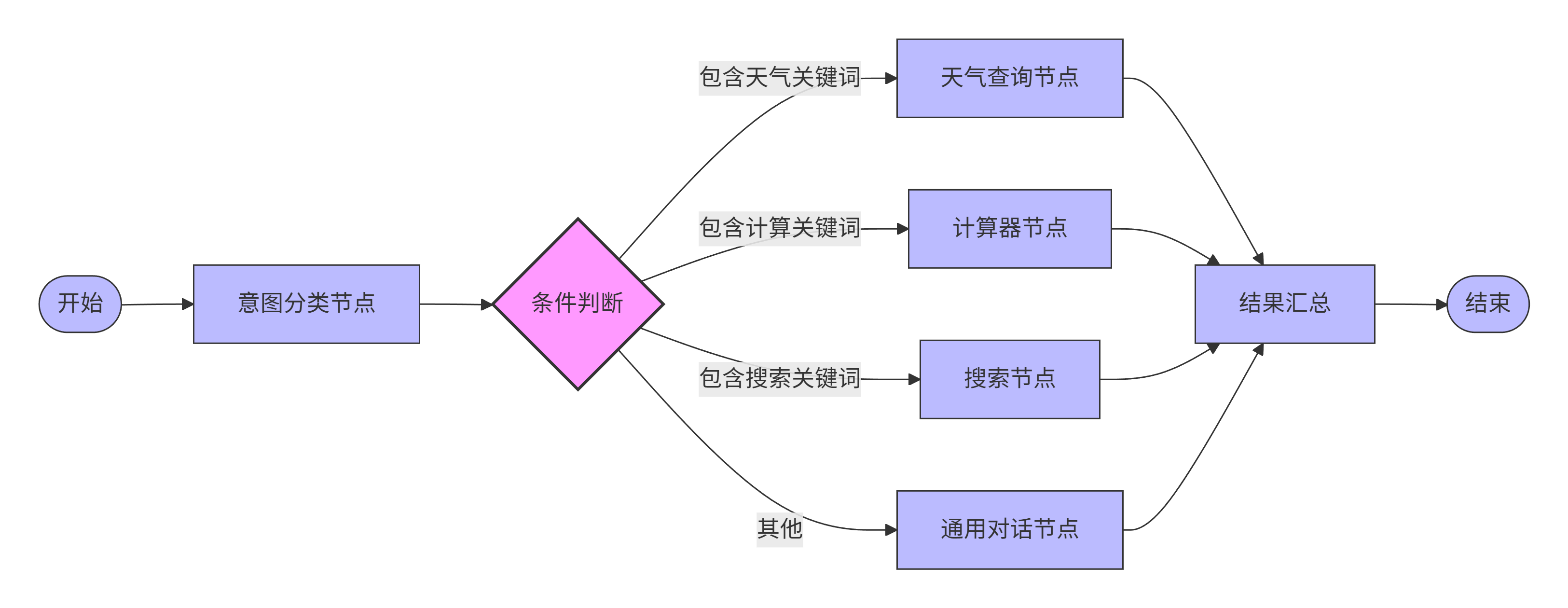
python
def route_based_on_intent(state: AgentState) -> str:
"""根据用户意图决定路由"""
last_message = state["messages"][-1].content
if "天气" in last_message:
return "weather_node"
elif "计算" in last_message:
return "calculator_node"
elif "搜索" in last_message:
return "search_node"
else:
return "general_chat_node"
# 在图中添加条件边
graph.add_conditional_edges(
"intent_classifier", # 源节点
route_based_on_intent, # 路由函数
{
"weather_node": "weather_node",
"calculator_node": "calculator_node",
"search_node": "search_node",
"general_chat_node": "general_chat_node"
}
)条件边最常见的应用场景有三个:
场景一:循环控制
实现自我反思Agent时,需要根据反思结果决定是结束还是继续优化:
python
def should_continue(state: AgentState) -> str:
if state.get("task_complete"):
return "end"
elif state.get("reflection_count", 0) < 3:
return "reflect_again"
else:
return "fallback"场景二:分支路由
根据用户意图分流到不同的处理流程,如客服系统中区分咨询、投诉、查询等。
场景三:终止判断
检查任务是否完成、是否超过重试次数、是否超出时间限制,决定是否终止工作流。
2.3 自我反思Agent的实现架构
自我反思是高级Agent的重要能力------它能够审视自己的输出,发现问题并主动修正。在LangGraph中,这种能力可以通过"生成-反思-优化"的循环来实现。
核心架构包含三个节点:生成、反思、优化
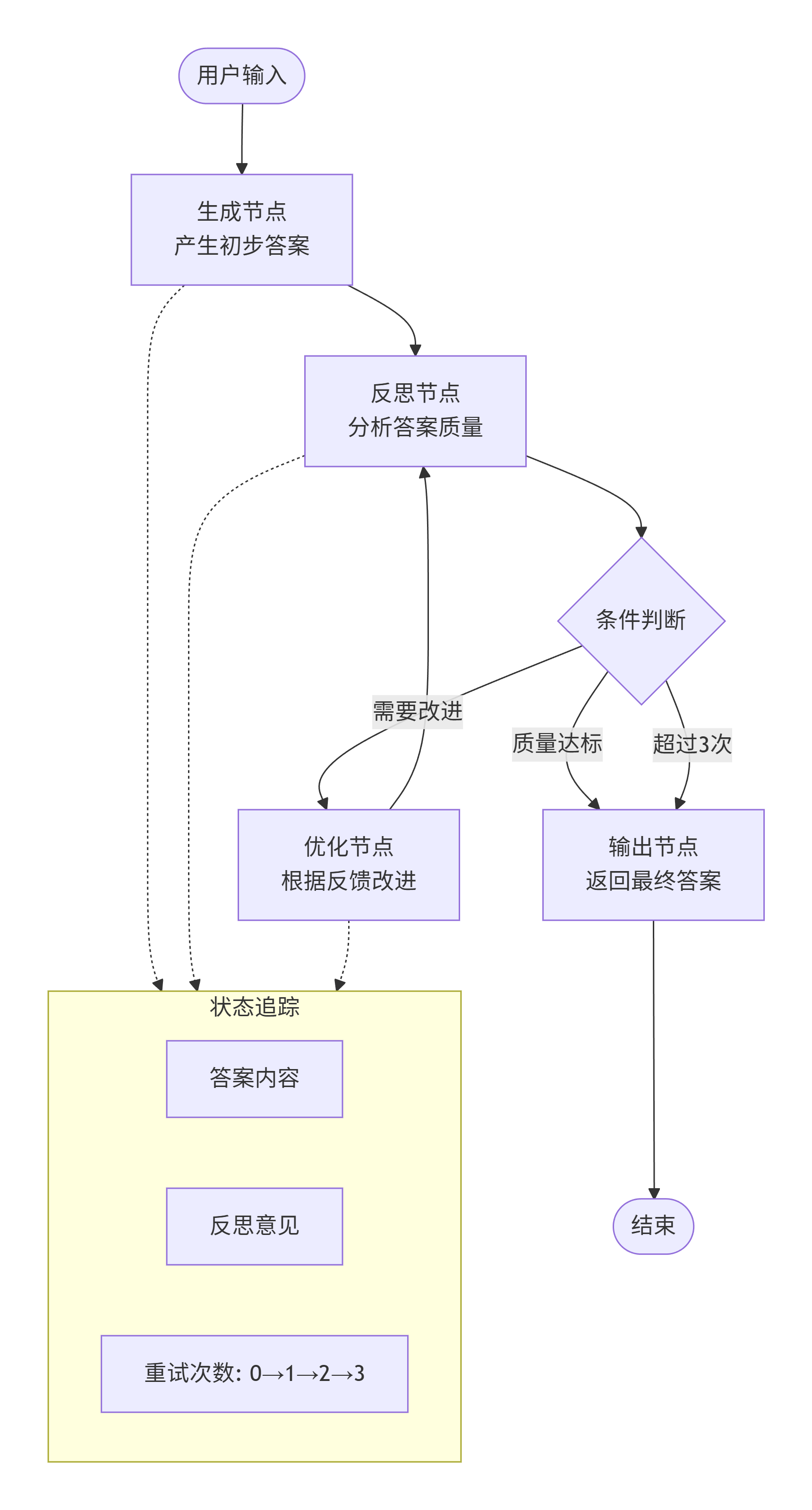
python
# 1. 生成节点:产生初步答案
def generate_answer(state: AgentState) -> AgentState:
query = state["messages"][-1].content
# 调用LLM生成答案
answer = llm.invoke(query)
state["messages"].append(answer)
state["current_answer"] = answer
return state
# 2. 反思节点:分析答案质量
def reflect_on_answer(state: AgentState) -> AgentState:
answer = state["current_answer"]
# 让LLM反思:是否有遗漏?是否准确?是否清晰?
reflection = llm.invoke(f"请分析这个答案的质量:{answer}")
state["reflection"] = reflection
state["reflection_count"] = state.get("reflection_count", 0) + 1
return state
# 3. 优化节点:根据反思改进答案
def improve_answer(state: AgentState) -> AgentState:
original = state["current_answer"]
feedback = state["reflection"]
# 根据反馈优化
improved = llm.invoke(f"原答案:{original}\n改进建议:{feedback}\n请输出改进后的答案")
state["current_answer"] = improved
return state配合条件边实现循环控制:
python
def decide_next(state: AgentState) -> str:
# 检查是否达到质量标准或超过最大迭代次数
if state.get("reflection_count", 0) >= 3:
return "output"
if "无需改进" in state.get("reflection", ""):
return "output"
return "improve"
# 构建图
builder = StateGraph(AgentState)
builder.add_node("generate", generate_answer)
builder.add_node("reflect", reflect_on_answer)
builder.add_node("improve", improve_answer)
builder.add_node("output", output_final)
builder.add_edge("generate", "reflect")
builder.add_conditional_edges("reflect", decide_next, {
"improve": "improve",
"output": "output"
})
builder.add_edge("improve", "reflect")这种架构让Agent具备了"迭代优化"的能力,能够不断提高答案质量。
三、工具与记忆:Agent的能力延伸
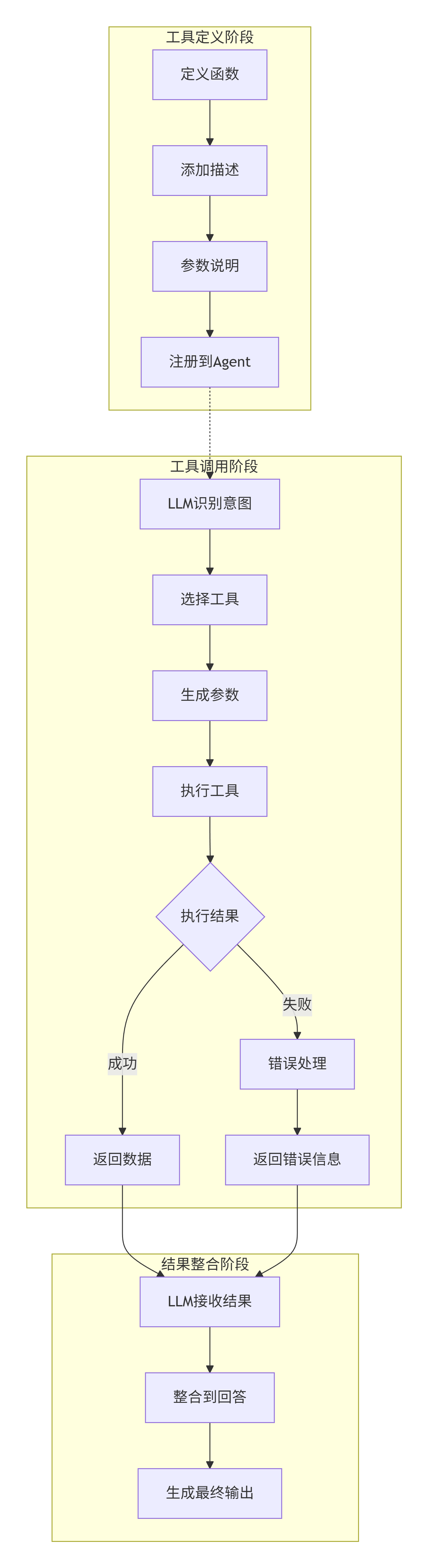
3.1 工具调用的完整流程与最佳实践
工具调用是Agent连接外部世界的桥梁。一个完整的工具调用流程包含七个步骤:
第一步:工具定义
每个工具需要三个要素:名称、描述、参数说明。其中描述最为关键,它是LLM决定是否调用该工具的依据。
python
from langchain.tools import tool
@tool
def get_stock_price(symbol: str) -> dict:
"""
获取股票的实时价格。
适用场景:用户询问股价、涨跌幅、市值等
参数说明:symbol为股票代码,如"AAPL"、"TSLA"
返回数据:包含当前价、涨跌幅、成交量
"""
# 实际调用外部API
result = stock_api.query(symbol)
return {
"symbol": symbol,
"price": result.price,
"change": result.change_percent,
"volume": result.volume
}第二步:工具注册
将定义好的工具注册给Agent:
tools = [get_stock_price, search_web, calculate]
agent = create_react_agent(llm, tools)第三步:意图识别
当用户提问时,LLM首先理解意图,判断是否需要使用工具。
第四步:工具选择
如果需要工具,LLM从注册的工具列表中选择最合适的一个或多个。
第五步:参数生成
LLM根据用户问题和工具描述,生成调用工具所需的参数。
第六步:工具执行
Agent框架实际调用工具函数,传入LLM生成的参数。
第七步:结果整合
工具返回的结果被传回给LLM,LLM将其整合到最终回答中。
最佳实践要点:
实践一:描述要精准
工具描述直接决定了LLM的调用准确率。好的描述应该包含:
- 什么情况下该用这个工具(意图映射)
- 参数应该是什么格式(输入约束)
- 返回什么数据(输出预期)
实践二:错误处理要完善
python
@tool
def call_external_api(params):
try:
response = requests.get(url, timeout=5)
response.raise_for_status()
return response.json()
except requests.Timeout:
return {"error": "服务超时,请稍后重试"}
except requests.RequestException as e:
return {"error": f"调用失败:{str(e)}"}实践三:参数验证要严格
使用Pydantic模型定义参数,自动进行类型检查和验证:
python
from pydantic import BaseModel, Field
class StockInput(BaseModel):
symbol: str = Field(description="股票代码,如AAPL")
market: str = Field(default="US", description="市场:US/HK/CN")
@tool(args_schema=StockInput)
def get_stock_price(symbol: str, market: str = "US"):
# 参数会自动验证
pass3.2 Memory机制:从Demo到生产
Memory是Agent保持对话连续性的关键。但在生产环境中,简单的内存存储远远不够,我们需要一套完整的记忆管理方案。
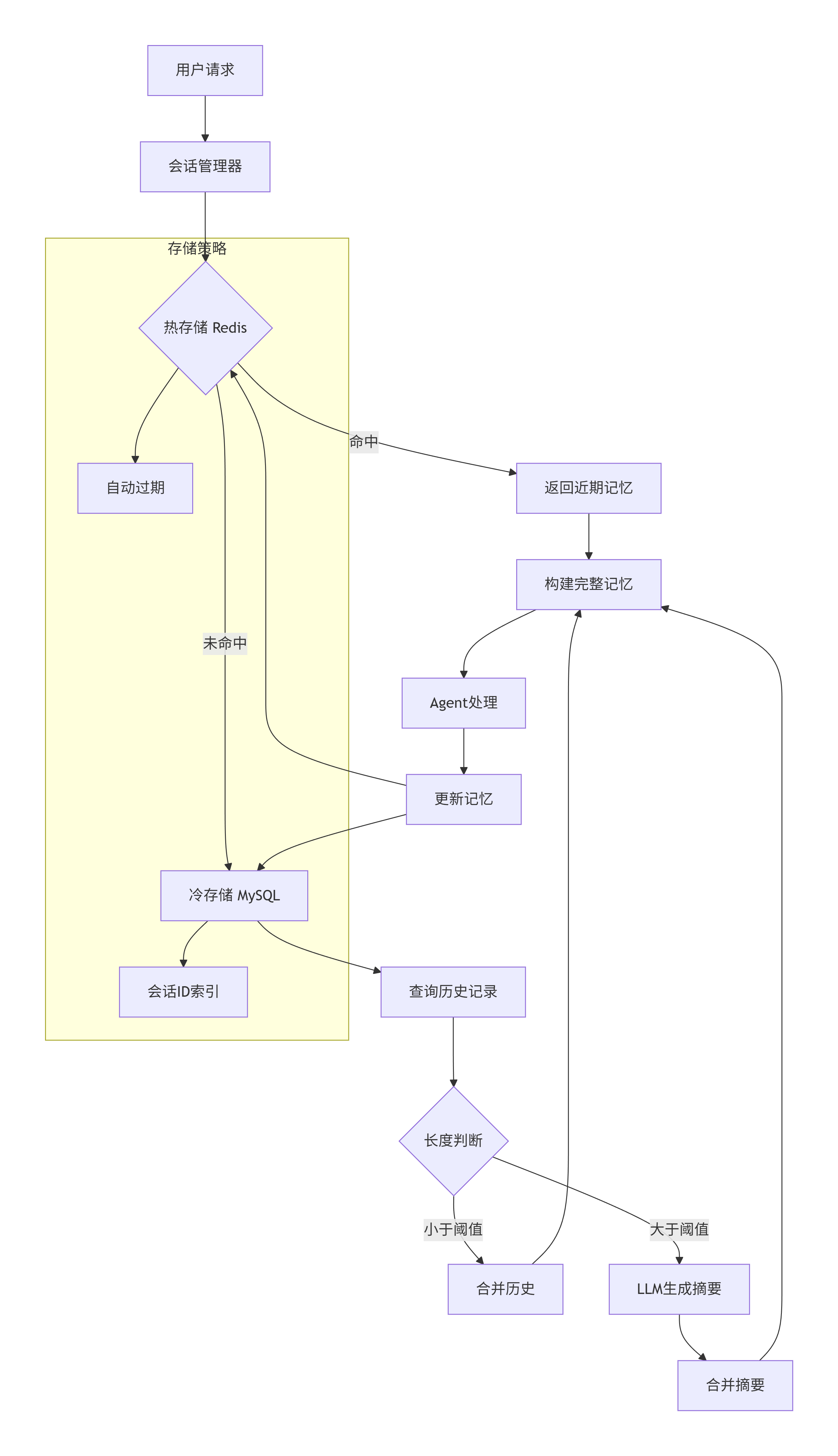
记忆的分层架构
成熟的记忆系统采用分层存储策略:
python
class ProductionMemory:
def __init__(self):
self.hot_storage = RedisClient() # 近期记忆
self.cold_storage = MySQLPool() # 长期记忆
self.summary_cache = {} # 摘要缓存
async def get_memory(self, session_id: str, query: str) -> list:
# 1. 从热存储获取最近对话
recent = await self.hot_storage.get(f"session:{session_id}")
# 2. 判断是否需要加载历史
if self.needs_history(query, recent):
history = await self.cold_storage.query(
"SELECT * FROM conversations WHERE session_id=? ORDER BY time DESC LIMIT 50",
session_id
)
# 3. 如果历史过长,生成摘要
if len(history) > 10:
summary = await self.summarize_history(history)
return recent + [summary]
return recent + history
return recent记忆的三种形态
生产环境中的记忆往往以三种形态存在:
形态一:原始记录
完整保存每一次对话的输入输出,用于精确回溯。
形态二:摘要压缩
当历史过长时,用LLM生成摘要,保留关键信息:
python
async def summarize_history(messages: list) -> str:
prompt = f"""
请将以下对话压缩成摘要,保留:
1. 用户的核心诉求
2. 已经确认的事实
3. 未完成的任务
对话:{messages}
"""
return await llm.invoke(prompt)形态三:结构化知识
从对话中提取实体、偏好、关系,形成结构化知识:
python
class ExtractedKnowledge(BaseModel):
user_preferences: dict # 用户偏好
entities: list # 提及的实体
pending_tasks: list # 待办事项
facts: list # 已确认的事实会话隔离与并发控制
在多用户高并发场景下,需要确保记忆的隔离性:
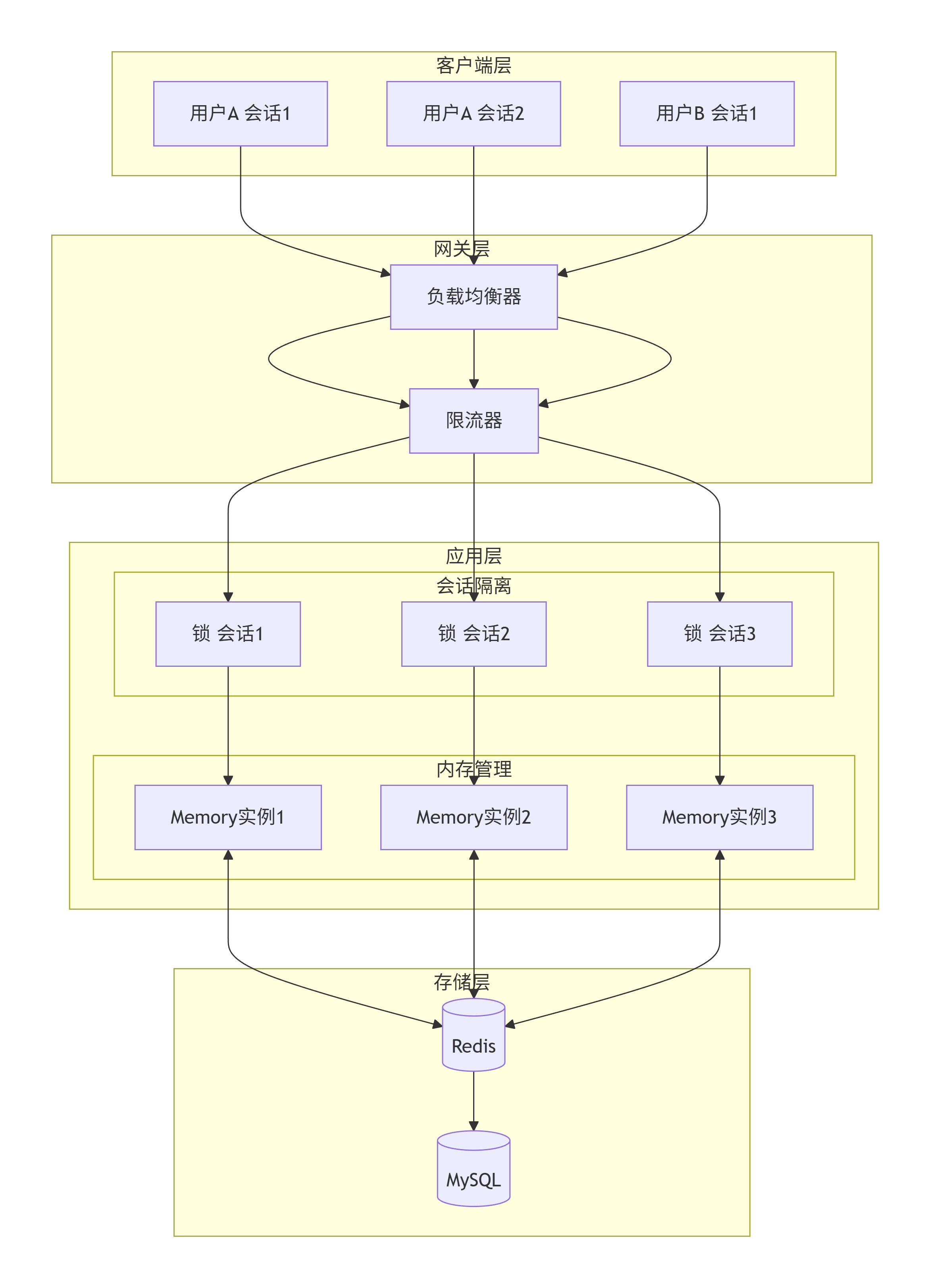
python
class MemoryManager:
def __init__(self):
self.sessions = {} # session_id -> memory
self.locks = defaultdict(asyncio.Lock)
async def get_session_memory(self, session_id: str):
async with self.locks[session_id]: # 每个会话独立锁
if session_id not in self.sessions:
self.sessions[session_id] = await self.load_memory(session_id)
return self.sessions[session_id]