论文详解 | TWScan:基于收紧窗口的增强扫描统计,实现不规则形状空间热点精准检测
原文参考:Enhanced scan statistic with tightened window for detecting irregularly shaped hotspots
摘要与核心创新点
2.1 摘要核心内容
空间点数据中的热点,是指任意形状区域内密度显著高于背景的点聚集模式。在现有热点识别方法中,空间扫描统计因定位原理简洁、可输出统计显著性,成为各领域应用最广泛的方法之一。但现有方法高度依赖预定义的扫描窗口形状(如圆形、椭圆等规则几何图形,或行政区划等预划分单元),无法精准捕捉热点的不规则真实形态,最终导致检测结果偏差、范围估计失准。
本文通过引入收紧窗口(Tightened Window) 对传统空间扫描统计进行了底层增强,该窗口可自适应贴合热点的真实形状,无需勾勒热点的精确几何轮廓,仅通过最近邻距离统计即可估计收紧窗口的面积,进而完成目标函数的计算。
模拟数据实验证明,本文提出的TWScan(Tightened Window Scan)算法在四大核心维度全面优于现有主流方法:热点显著性检验的准确性、不规则形状热点的识别能力、热点空间范围的估计精度、参数选择的低主观性。基于北京出租车上车点数据的实证研究表明,该方法可精准识别地铁出口、商业街等高出租车需求区域与潜在交通拥堵点,具备极强的真实场景落地能力。
2.2 核心创新点
- 范式级概念创新:提出「收紧窗口」核心概念,突破了传统空间扫描统计近半个世纪以来对预定义几何窗口的路径依赖,实现了从「用固定窗口匹配热点」到「让窗口自适应贴合热点真实形态」的底层逻辑转变。
- 无边界面积估计方法:基于k近邻距离统计,提出了热点真实面积的无边界估计方法------无需勾勒热点几何边界、无需预知热点形状,仅通过点集的最近邻特征即可精准计算热点真实占据的空间范围,彻底摆脱了规则几何窗口的约束。
- 全维度性能超越:设计的TWScan算法在统计显著性、不规则热点识别精度、范围估计准确性、参数鲁棒性上,全面超越椭圆扫描、DBSCAN、显著性DBSCAN、谱聚类、深度聚类等主流方法。
- 强工程落地价值:算法完全基于经典空间统计理论,无黑箱、可解释性强,无需大量标注数据,在城市交通、公共卫生、犯罪分析、地震监测等领域具备直接的落地能力,可满足政务、科研等场景的合规性要求。
一、研究背景与科学问题(Introduction深度解读)
论文的Introduction部分完整梳理了空间热点检测领域的发展脉络、核心挑战与现有方法的系统性缺陷,最终锚定了本文要解决的核心科学问题,我们将其拆解为4个核心模块进行深度解读。
1.1 空间热点检测的科学意义与应用价值
论文开篇给出了空间热点的严格定义:在空间点数据集中,热点是指局部受限空间内,点的聚集程度显著高于周边背景区域的点子集 。这个定义里有两个核心关键词:显著高于背景 、局部受限空间,这也是热点检测的两个核心难点------既要判断聚集的统计显著性,又要精准刻画聚集的空间范围。
空间热点的背后,往往对应着现实世界中自然与社会现象的核心模式,论文中列举了四大核心应用领域,每一个领域的热点检测都具备极强的现实意义:
- 犯罪热点分析:犯罪事件的空间聚集,可指导警力的精准部署、防控策略的制定,是智慧警务的核心技术支撑;
- 地震聚类分析:地震震中的空间聚集区,往往对应着活动断裂带与发震危险区,是地震风险评估、临震预警的关键依据;
- 疾病暴发监测:传染病病例的空间聚集,是疫情暴发的早期信号,精准的热点检测可实现疫情的早发现、早溯源、早防控;
- 交通事件监测:交通事故、出租车上车点的空间聚集,对应着交通拥堵点、高出行需求区域,是城市交通管理、路网优化、运力调度的核心数据支撑。
论文特别强调:精准识别空间热点,不仅能帮助我们探索现象背后的成因,更能对未来的自然与社会事件进行预测,进而支撑针对性的预案制定。比如地震热点的识别,可直接揭示发震断裂带的空间范围,为强震风险预警提供核心依据;而城市出租车热点的识别,可直接指导出租车运力调度、缓解交通拥堵、优化城市公共设施布局。
也正因如此,开发高效、精准、鲁棒的空间热点检测方法,是地理信息科学、空间统计学、城市计算等领域持续数十年的核心研究方向。而这个领域里,一个长期存在且极具挑战性的科学问题始终没有被完美解决:如何精准捕捉热点的不规则真实形状。
论文中指出,这个问题的根源在于:现实世界中的热点,极少是标准的圆形、椭圆等规则形状,反而大多呈现复杂的不规则形态------比如沿河流分布的疾病暴发热点、沿断裂带分布的地震聚集热点、沿城市道路分布的出租车热点。这些热点的几何与统计特征难以通过预定义的规则窗口来定义和提取,最终导致传统方法的检测结果严重失真。
1.2 现有热点检测方法的分类与系统性缺陷
论文将现有主流的空间热点检测方法分为三大类,系统性地分析了每一类方法的原理与固有缺陷,这也是本文研究的核心出发点。
1.2.1 基于聚类的方法
这类方法的核心原理是:根据点的空间相似性,通过不同的聚合策略将相邻的点划分为不同的簇,最终将高密度簇识别为热点。根据聚合策略的不同,又可分为四大子类:
- 基于划分的聚类:如K-Means等;
- 基于层次的聚类:如AGNES等;
- 基于图谱的聚类:如谱聚类;
- 基于密度的聚类:如DBSCAN、OPTICS、HDBSCAN等。
其中,基于密度的聚类是这类方法中最主流的热点检测方法,因为它能在噪声存在的场景下,识别任意形状、任意大小的热点。其核心逻辑是:基于点的空间最近邻距离计算局部密度,找到高密度、连通的点子集作为热点。
但论文中尖锐地指出,这类方法存在两个无法回避的核心缺陷:
- 参数选择高度敏感,结果主观性极强
这类方法需要提前预设核心参数(如DBSCAN的Eps邻域半径和MinPts最小点数),而参数的确定大多依赖经验方法,不仅计算成本高,还很难找到适配所有场景的最优参数。一旦参数选择不当,结果就会出现严重偏差------Eps过大,会把不同热点合并为一个;Eps过小,会把一个完整热点拆分为多个碎片,甚至识别不出热点。 - 缺乏统计显著性检验,易产生大量虚假热点
传统的密度聚类方法,没有融入统计显著性检验的逻辑,只要是高密度的点集就会被识别为热点,无法区分「真实的显著聚集」和「随机分布产生的偶然高密度」,最终输出大量虚假热点。
针对第二个缺陷,学界也提出了改进方法,最具代表性的就是Significant DBSCAN,它通过热点内的点数作为检验统计量,为聚类结果增加了显著性检验。但论文中指出,这个改进依然存在两个致命缺陷:
- 第一,它在识别出显著热点后,需要通过网格化研究区域的方式,移除热点及其覆盖范围,再进行下一轮搜索。网格化的过程会引入大量不确定性和复杂度,尤其是对于形状不规则、结构复杂的热点,网格化的偏差会被进一步放大;
- 第二,作为密度聚类方法,它始终无法像空间扫描统计一样,考虑背景数据的分布(如流行病学中的风险人口)。比如在公共卫生研究中,一个区域的病例数上升,不一定是疾病暴发,还可能是这个区域的人口基数更大,必须结合背景人口才能准确评估疾病的流行程度,而这正是密度聚类方法的天然短板。
1.2.2 基于学习的方法
这类方法的核心原理是:通过标注数据训练分类模型,再用训练好的模型识别热点。主流模型包括支持向量机(SVM)、决策树、深度学习聚类模型等。
论文中指出,尽管这类方法在部分场景下能取得不错的效果,但存在三个无法突破的固有局限:
- 性能高度依赖训练数据的数量与质量。在公共卫生、地震监测等领域,高质量的标注热点数据极其稀缺,直接限制了这类方法的应用;
- 极易出现过拟合/欠拟合问题。训练策略不当、数据分布不均,都会导致模型的泛化能力极差,换一个研究区域、换一个数据集,结果就会严重失真;
- 大多是黑箱模型,可解释性极差。这也是这类方法最致命的缺陷------在公共卫生、公共安全、城市管理等领域,热点检测的结果往往是政府决策的依据,必须具备完整的可解释性,而深度学习等黑箱模型无法给出「为什么这个区域是热点」的统计依据,根本无法满足政务、科研等场景的合规性要求。
1.2.3 基于统计的方法
这类方法的核心原理是:通过统计指标识别统计显著的热点,无需大量参数和标注数据,是目前空间热点检测领域最主流、最受认可的方法,也是本文的研究基础。论文将其进一步分为两个子类:
子类1:基于研究区域预划分的方法
代表方法包括LISA(局部空间自相关指标)、Getis-Ord Gi*、STING等。这类方法的核心流程是:先把研究区域划分为预定义的网格/行政单元,再把原始点聚合到每个子单元中,统计每个子单元的点数,最终识别出数值显著偏高的子单元作为热点。
论文中指出,这类方法的核心缺陷,是地理学中经典的可变面元问题(MAUP):热点识别结果对区域划分的形状、大小高度敏感,预划分的子单元边界,根本无法匹配热点的真实边界。比如一个沿道路分布的线性热点,会被网格切分为多个碎片,最终无法被完整识别;而一个跨两个行政单元的热点,会被拆分为两个独立的部分,完全丢失了聚集的整体性。
子类2:基于扫描窗口的方法
这类方法又分为两个分支:
- 第一分支是核密度估计(KDE):通过滑动的圆形窗口和核函数,生成点的密度分布图。但它只能输出密度的空间分布,无法精准划定热点的具体位置和空间范围,也无法输出统计显著性,只能作为可视化工具,无法用于严谨的热点识别;
- 第二分支是空间扫描统计:这是本文的核心研究基础,也是目前空间热点检测领域的里程碑式方法。
1.3 传统空间扫描统计的发展历程与核心痛点
论文中完整梳理了空间扫描统计的发展脉络,清晰地指出了其核心优势与未解决的痛点。
1.3.1 空间扫描统计的发展与核心优势
空间扫描统计的开创性工作,是1987年Openshaw等人提出的地理分析机(GAM) ,它首次提出了用固定半径的圆形窗口滑动遍历整个研究区域,识别高密度聚集区;随后Besag和Newell在1991年提出了固定窗口内点数的圆形扫描方法。但这两个开创性方法,都面临着统计学中经典的多重检验问题------多次重复假设检验会导致假阳性率急剧上升,最终输出大量虚假热点。
1995-1997年,Kulldorff提出了经典的空间扫描统计方法,用可变大小的圆形窗口,通过统一的显著性标准对窗口内的聚集进行检验,彻底解决了多重检验问题,成为空间扫描统计的里程碑。
论文中总结了Kulldorff空间扫描统计的三大核心优势,这也是它能在各领域广泛应用的原因:
- 彻底解决了多重检验问题,假阳性率可控,结果具备严谨的统计学意义;
- 窗口大小可变,比固定窗口的方法灵活性更高,结果更准确;
- 用窗口内外点数计算的似然比作为检验统计量,不仅考虑了点的局部密度,还考虑了底层的点过程和窗口外的背景分布,比密度聚类方法的显著性检验更全面、更严谨。
也正因如此,Kulldorff的空间扫描统计被广泛应用于疾病监测、犯罪制图、灾害分析等数十个领域,成为空间热点检测的金标准方法。
1.3.2 传统空间扫描统计的核心痛点
尽管优势显著,但Kulldorff的方法存在一个致命的、困扰学界近30年的缺陷:固定的圆形窗口,根本无法匹配现实世界中不规则形状的热点。
为了解决这个问题,学界从两个方向做了大量改进,论文中对这些改进做了系统性梳理,并指出了它们的固有缺陷:
- 方向1:设计更灵活的规则几何窗口
学者们提出了椭圆、矩形、环形、线形等规则窗口,替代原来的圆形窗口。其中最具代表性的就是椭圆扫描统计(EllipticScan),它通过调整椭圆的长短轴、旋转角度,实现了比圆形窗口更高的灵活性。但论文中尖锐地指出:无论怎么调整规则几何窗口的参数,它本质上还是预定义的规则形状,依然无法贴合热点的不规则真实形态。比如I型、十字形、环形的热点,椭圆窗口为了覆盖完整热点,必然会包含大量窗口内的噪声点,最终导致似然比计算偏差、热点范围高估。 - 方向2:用连通的预划分子区域作为扫描窗口
这类方法用预划分的网格/行政单元作为基本单元,通过邻接算法将连通的子区域拼接成扫描窗口,比如遗传算法、蚁群优化算法、多边形传播算法等。但论文中指出,这类方法存在两个无法解决的缺陷:- 第一,枚举所有连通子区域的计算量是爆炸式增长的,根本无法实现全遍历,只能通过演化算法寻找最优解,而演化算法的局部最优特性,必然会导致结果次优;
- 第二,窗口的形状依然受限于预划分的子单元,无法精准贴合热点的真实边界,依然会包含大量噪声点。
论文用图1 直观地展示了这两类方法的核心缺陷:
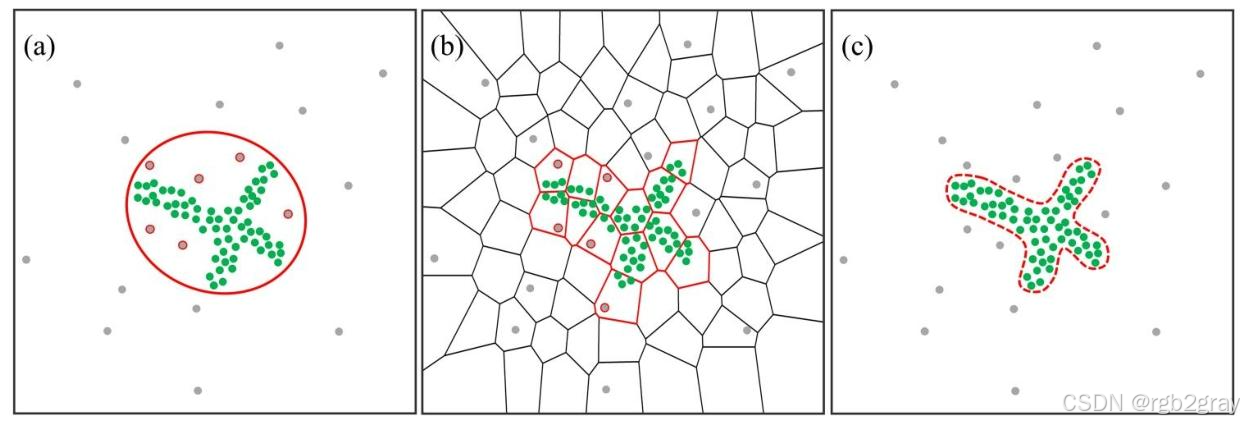
图1 三类扫描窗口的对比示例
图注:(a) 椭圆扫描窗口;(b) 连通子区域拼接的扫描窗口;© 本文提出的收紧窗口。绿色点为真实热点,灰色点为背景噪声,红色线为扫描窗口边界。
- 图1(a)的椭圆窗口和图1(b)的连通子区域窗口,都远大于真实热点的范围,包含了大量红圈标注的噪声点,最终导致热点检测结果失真;
- 图1©的收紧窗口,红色虚线完全贴合热点的真实轮廓,既不包含外部噪声,也不丢失热点内部区域,完美解决了前两种窗口的核心缺陷。
1.4 本文的研究目标与核心思路
基于对现有方法的系统性分析,论文明确了本文的核心研究目标:对传统空间扫描统计进行增强,引入可自适应贴合热点真实形状的收紧窗口,无需勾勒热点的精确几何轮廓,即可完成扫描统计量的计算,最终实现不规则形状热点的精准识别、准确范围估计与严谨显著性检验。
论文的核心思路可以概括为:沿用传统空间扫描统计的滑动遍历框架,在每个原始规则扫描窗口内,新增「收紧窗口构建」的核心步骤------先剔除窗口内的噪声点,再基于最近邻距离统计估计剩余密集点的局部密度,最终通过「点数/密度」间接计算出热点真实占据的面积(即收紧窗口的面积),用收紧窗口的面积和密集点数量,替代传统公式中规则窗口的面积和总点数,完成对数似然比的计算与显著性检验。
这个思路的点睛之笔在于:热点检测的对数似然比计算,仅需要窗口的面积,根本不需要知道窗口的具体几何形状。论文正是抓住了这个核心逻辑,彻底绕开了「勾勒不规则热点边界」这个世纪难题,用最简洁的空间统计方法,解决了最核心的科学问题。
二、核心方法论:TWScan算法全流程深度拆解
本文提出的TWScan算法,完整继承了传统空间扫描统计的统计学严谨性,同时通过「收紧窗口」的核心创新,突破了规则窗口的形状限制。我们将算法全流程拆解为3个核心模块,逐步骤深度解读其原理、公式与设计逻辑。
2.1 传统空间扫描统计的基础理论
TWScan算法基于经典的空间扫描统计框架构建,首先需要明确其核心数学原理与公式的物理意义。
空间扫描统计的核心逻辑:用滑动窗口遍历整个研究区域,通过似然比检验判断窗口内是否存在统计显著的热点,最终找到对数似然比最大的窗口作为最可能热点。
2.1.1 泊松模型与似然比公式
空间点模式分析中,泊松过程是描述随机点分布的最经典模型,也是空间扫描统计的理论基础。论文中采用齐次泊松过程假设,即研究区域内背景点的分布是随机、独立的,密度恒定。
对于一个给定的扫描窗口WWW,似然比LR(W)LR(W)LR(W)定义为备择假设(窗口内存在热点) 与原假设(研究区域内无热点,点完全随机分布) 的似然值之比:
LR(W)=L(W)L0=(nWμW)nW(N−nWN−μW)N−nWLR(W)=\frac{L(W)}{L_0}=\left(\frac{n_W}{\mu_W}\right)^{n_W}\left(\frac{N-n_W}{N-\mu_W}\right)^{N-n_W}LR(W)=L0L(W)=(μWnW)nW(N−μWN−nW)N−nW
- 当nW≤μWn_W \le \mu_WnW≤μW时,LR(W)=1LR(W)=1LR(W)=1。物理意义:如果窗口内的实际点数≤理论期望点数,说明窗口内的点密度不高于背景,不可能是热点,直接赋值为1;
- 变量物理意义:
- nWn_WnW:窗口WWW内的实际观测点数;
- μW\mu_WμW:原假设下,窗口WWW内的理论期望点数;
- NNN:整个研究区域内的总点数。
2.1.2 期望点数与窗口面积的关系
齐次泊松过程下,窗口内的期望点数与窗口面积成正比,公式如下:
μW=λSW\mu_W = \lambda S_WμW=λSW
- λ\lambdaλ:研究区域整体的背景点密度,λ=研究区域总点数研究区域总面积\lambda = \frac{研究区域总点数}{研究区域总面积}λ=研究区域总面积研究区域总点数,是整个研究过程中的恒定值;
- SWS_WSW:扫描窗口WWW的面积。
传统方法的核心痛点根源:此处的SWS_WSW使用的是预定义规则窗口(圆、椭圆)的面积,而非热点真实占据的面积。如果窗口面积远大于热点真实面积,μW\mu_WμW会被严重高估,最终导致似然比计算偏差,甚至无法识别出真实热点;如果窗口面积小于热点真实面积,又会导致热点范围被低估,丢失部分热点区域。
2.1.3 对数似然比LLR
对似然比取自然对数,是空间统计中的经典处理方式,论文中也采用对数似然比(LLR)作为核心检验统计量,公式如下:
LLR(W)=nWlog(nWλSW)+(N−nW)log(N−nWN−λSW)LLR(W) = n_W\log\left(\frac{n_W}{\lambda S_W}\right) + (N-n_W)\log\left(\frac{N-n_W}{N-\lambda S_W}\right)LLR(W)=nWlog(λSWnW)+(N−nW)log(N−λSWN−nW)
对数变换的核心优势有三点:
- 简化乘除运算,降低计算复杂度;
- 稳定方差,让统计推断更稳健;
- 对数似然比在独立事件间具备可加性,更适合多轮扫描与多热点检测。
2.1.4 蒙特卡洛模拟与p值计算
空间扫描统计采用蒙特卡洛模拟法计算热点的p值,实现统计显著性检验,步骤如下:
- 在原假设下,生成999组完全随机分布的点数据(论文中采用999次重复,是空间统计领域的经典设置);
- 对每组随机数据,遍历所有扫描窗口,计算全局最大LLR值;
- 统计随机数据中,最大LLR超过真实数据最大LLR的次数NExtremeN_{Extreme}NExtreme,通过下式计算p值:
p=NExtreme+1NRep+1p = \frac{N_{Extreme} + 1}{N_{Rep} + 1}p=NRep+1NExtreme+1
- NRepN_{Rep}NRep为蒙特卡洛重复次数,通常取999;
- 若p值小于预设显著性水平(如0.05/0.01),则判定该热点统计显著,拒绝原假设。
2.1.5 多热点检测的非相交准则
找到最显著的热点后,论文采用空间扫描统计领域经典的非相交准则检测后续热点:移除所有与已识别热点相交的扫描窗口,在剩余区域继续迭代检测,直到无统计显著的窗口,或达到预设的热点数量。这个准则的核心目的是避免热点重叠,保证每个热点的独立性。
2.2 核心创新:收紧窗口的构建原理与步骤
TWScan算法的核心突破,是在每个原始圆形扫描窗口内,构建一个完全贴合热点真实形状的收紧窗口,并用收紧窗口的面积STWS_{TW}STW、密集点数量ndn_dnd,替代传统公式中的SWS_WSW和nWn_WnW,完成LLR计算。
论文中对收紧窗口的严格定义是:在原始规则扫描窗口内,完全贴合热点真实形态的窗口,即剔除噪声后,密集热点点集所占据的空间范围。
最关键的设计思路:无需勾勒热点的几何边界,仅通过k近邻距离统计,即可精准估计收紧窗口的面积 。整个构建过程分为三个核心步骤,我们结合图2 逐步骤深度解读:
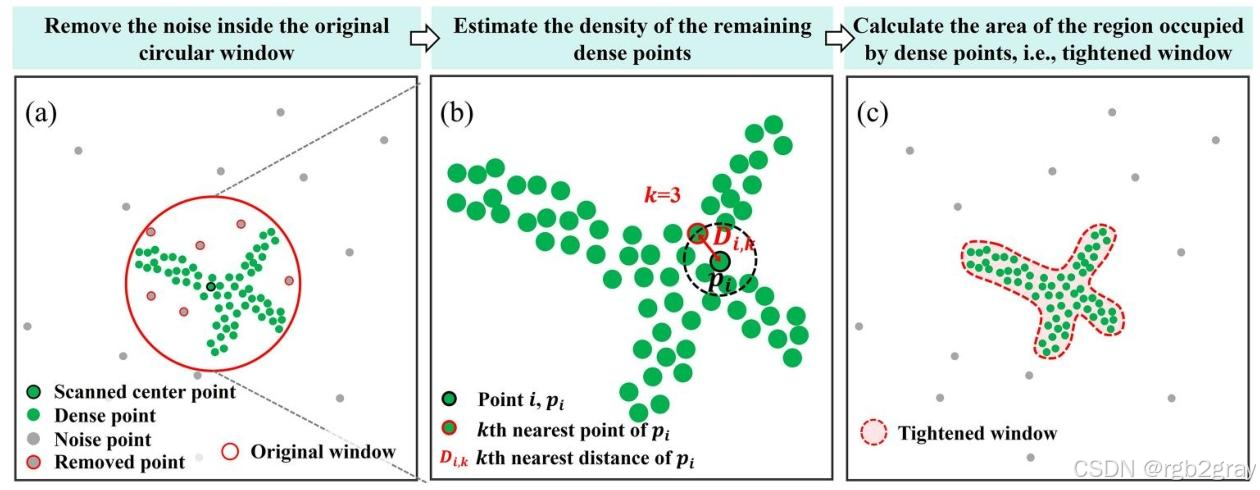
图2 收紧窗口构建的三步法示意图
图注:(a) 原始窗口内噪声去除;(b) 密集点密度估计;© 收紧窗口面积计算。
2.2.1 步骤1:原始窗口内的噪声点去除
第一步的核心目标:在原始圆形扫描窗口内,区分密集的热点候选点与稀疏的噪声点,剔除噪声,仅保留有效密集点,避免噪声对后续密度估计和面积计算的干扰。
核心原理:齐次泊松过程下,点的k近邻距离存在明确的概率分布,我们可以通过这个分布设定距离阈值,超过阈值的点即为稀疏噪声点。
- k近邻距离的概率分布公式
对于均匀泊松过程中的任意点,其第k近邻距离DkD_kDk的互补累积分布函数为:
P(Dk≥x)=∑m=0k−1e−λπx2(λπx2)mm!=1−FDk(x)P\left(D_k \geq x\right)=\sum_{m=0}^{k-1} \frac{e^{-\lambda \pi x^2}\left(\lambda \pi x^2\right)^m}{m!}=1-F_{D_k}(x)P(Dk≥x)=m=0∑k−1m!e−λπx2(λπx2)m=1−FDk(x)
- FDk(x)F_{D_k}(x)FDk(x)为DkD_kDk的累积分布函数;
- λ\lambdaλ为原始扫描窗口内的点密度;
- xxx为待求解的距离阈值。
这个公式的物理意义:在均匀随机分布的点集中,一个点的第k近邻距离大于等于x的概率。如果一个点的k近邻距离超过了95%显著性水平下的阈值,说明它在随机分布中出现的概率小于5%,属于异常稀疏的点,即噪声。
- k值的自适应选择
论文中取k=log10(n)k=log_{10}(n)k=log10(n),其中nnn是原始窗口内的总点数。这个对数取值的设计,是空间点模式分析中的经典最优选择,论文中也给出了它的核心优势:
- 平衡k值过大/过小的问题:k值过小,易受局部噪声干扰;k值过大,会丢失局部密度特征,对数取值刚好实现了平衡;
- 随窗口内数据量自适应缩放:窗口内点数多,k值自动增大;点数少,k值自动减小,适配不同大小的扫描窗口,避免固定k值带来的偏差。
- 距离阈值求解与噪声判定
在95%的显著性水平下,令P(Dk≥x)=0.05P(D_k \geq x)=0.05P(Dk≥x)=0.05,求解对应的xxx作为距离阈值。
- 若某点的k近邻距离>阈值,判定为噪声,从窗口内移除;
- 若≤阈值,判定为密集点,保留用于后续计算。
关键设计细节:k近邻的计算仅在原始圆形扫描窗口内进行,而非整个研究区域。这个局部化设计的核心意义:保证分析完全聚焦于当前扫描的局部区域,避免全局远距离点的干扰,精准捕捉局部的密度差异。
2.2.2 步骤2:密集点的局部密度估计
剔除噪声后,需要对窗口内剩余的ndn_dnd个密集点,估计其局部真实密度λd\lambda_dλd,这是后续计算收紧窗口面积的核心基础。
论文中采用基于k近邻距离的无偏密度估计方法,公式如下:
λd=kπE(Di,k2)=ndkπ∑i=1ndDi,k2\lambda_d=\frac{k}{\pi E\left(D_{i,k}^2\right)}=\frac{n_d k}{\pi \sum_{i=1}^{n_d} D_{i,k}^2}λd=πE(Di,k2)k=π∑i=1ndDi,k2ndk
- Di,kD_{i,k}Di,k:第iii个密集点的第k近邻距离;
- ndn_dnd:窗口内保留的密集点总数;
- k值:取k=log10(nd)k=log_{10}(n_d)k=log10(nd),与步骤1的对数取值保持一致性。
论文中特别强调了这个公式的两个核心优势:
- 普适性强:既适用于均匀点分布,也适用于异质点分布,无论热点内的密度是否均匀,都能实现无偏估计;
- 局部性强:k近邻的计算仅在窗口内的密集点中进行,完全聚焦于热点本身,避免了背景噪声和全局点分布的干扰,保证了密度估计的准确性。
同时论文中也解释了:这个密度估计公式本身对k值的变化不敏感,采用对数取值主要是为了和步骤1保持一致性,实现算法的全流程自适应。
2.2.3 步骤3:收紧窗口的面积计算
这一步是整个算法的点睛之笔,基于空间点过程最基础的逻辑:区域面积 = 区域内点数 / 区域内点密度。
因此,密集点(真实热点)占据的区域面积,即收紧窗口的面积STWS_{TW}STW,计算公式为:
STW=ndλdS_{TW} = \frac{n_d}{\lambda_d}STW=λdnd
这个公式的突破性意义:无需勾勒热点的几何边界,无需知道热点的具体形状,仅通过点数和密度估计,就能精准计算出热点真实占据的面积,彻底摆脱了传统方法对预定义窗口形状的依赖,完美解决了不规则热点的范围估计难题。
2.2.4 收紧窗口的对数似然比计算
得到收紧窗口的面积STWS_{TW}STW和密集点数量ndn_dnd后,将其代入传统的对数似然比公式,即可计算收紧窗口的对数似然比LLR(TW)LLR(TW)LLR(TW):
LLR(TW)=ndlog(ndλSTW)+(N−nd)log(N−ndN−λSTW)LLR(TW) = n_d\log\left(\frac{n_d}{\lambda S_{TW}}\right) + (N-n_d)\log\left(\frac{N-n_d}{N-\lambda S_{TW}}\right)LLR(TW)=ndlog(λSTWnd)+(N−nd)log(N−λSTWN−nd)
- λ\lambdaλ:整个研究区域的背景点密度,与传统公式一致,全程恒定;
- NNN:研究区域总点数,与传统公式一致。
最终,TWScan算法遍历所有扫描窗口,选择LLR(TW)LLR(TW)LLR(TW)最大的收紧窗口作为最可能的热点。这个热点不仅剔除了所有噪声,形状完全贴合真实形态,还能通过STWS_{TW}STW精准输出热点的空间范围,完美解决了传统方法的所有核心痛点。
2.3 TWScan算法的计算复杂度与工程实现
论文中对TWScan算法的计算复杂度做了严谨的分析,同时给出了工程实现的优化方向。
2.3.1 时间复杂度分析
TWScan与传统空间扫描统计的计算差异,仅来自收紧窗口的构建过程,而该过程的核心计算是k近邻距离的求解。在空间数据处理中,基于KD-Tree的k近邻搜索时间复杂度为O(nlogn)O(n log n)O(nlogn)(nnn为窗口内的点数),因此TWScan单次扫描的整体时间复杂度为O(nlogn)O(n log n)O(nlogn),与传统空间扫描统计处于同一量级。
2.3.2 并行化优化
论文中特别指出,TWScan算法具备天然的可并行性:每个扫描窗口的统计量计算相互独立,完全可以通过多进程并行计算大幅提升运行效率。这也是算法能落地到大规模城市数据处理的核心基础。
2.3.3 工程实现
论文中所有实验均基于Python 3.8.1实现,运行环境为1.80 GHz CPU、16GB内存的Windows 10系统,证明了算法在普通办公电脑上即可稳定运行,工程落地门槛极低。同时,论文已开源算法的全部代码与实验数据,可直接复现与二次开发。
三、模拟数据实验:全场景性能验证与对比分析
论文通过两组模拟数据实验,全面验证了TWScan算法的性能,并与5种主流热点检测方法进行了系统性对比。我们将从实验设计、评价指标、结果解读三个维度,做深度分析。
3.1 模拟数据集设计:针对性覆盖所有核心痛点
论文设计了两组共5个模拟数据集,每个数据集的设计都有明确的针对性,专门用于测试算法在不同场景下的性能,覆盖了现实世界中热点的所有典型特征。
3.1.1 Group I:单不规则热点场景(Case1-Case3)
这一组的3个数据集,每个都包含1个不规则形状的热点,专门测试算法对不同不规则形态热点的识别能力,每个热点包含700个点,背景泊松噪声300个点。
| 案例编号 | 热点形状 | 真实面积 | 热点/背景密度比 | 设计目的 |
|---|---|---|---|---|
| Case1 | 环形(Ring) | 0.064 | 34倍 | 测试算法对空心结构热点的处理能力,专门针对传统椭圆窗口会包含中心空心噪声的痛点 |
| Case2 | 矩形(Rectangle) | 0.038 | 58倍 | 测试算法对规则多边形热点的处理能力,作为基准对照 |
| Case3 | I型(I-shaped) | 0.034 | 66倍 | 测试算法对长条弯折、非凸不规则热点的处理能力,专门针对传统规则窗口无法贴合不规则形态的痛点 |
3.1.2 Group II:多热点并存场景(Case4-Case5)
这一组的2个数据集,包含多个不同形状、不同大小、不同密度的热点,专门测试算法在多热点并存场景下的识别能力,更贴近真实世界的复杂场景。
| 案例编号 | 热点构成 | 设计目的 |
|---|---|---|
| Case4 | 同时包含Case1-Case3的3个不规则热点,每个热点700个点,背景噪声400个点 | 测试算法对同区域多不规则热点的区分与识别能力,避免热点合并、拆分 |
| Case5 | 4个不同点数、不同形状的热点:900点矩形、900点环形、450点椭圆、100点圆形,背景噪声400个点 | 测试算法对不同规模、不同密度热点的识别能力,尤其是小而密的热点,专门针对Significant DBSCAN会遗漏小热点的痛点 |
论文中对每个Case都生成了50次重复模拟,所有结果均为50次实验的平均值,保证了实验结果的统计稳定性与可靠性。
3.2 评价指标
论文采用机器学习与模式识别领域通用的精准率(Precision) 和召回率(Recall) 作为核心评价指标,同时用热点面积估计误差作为辅助评价指标,全面评估算法的性能。
3.2.1 精准率与召回率
Precision=TPTP+FPPrecision = \frac{TP}{TP+FP}Precision=TP+FPTP
Recall=TPTP+FNRecall = \frac{TP}{TP+FN}Recall=TP+FNTP
- TP(真阳性):正确识别的热点点数,即真实热点中被算法判定为热点的点;
- FP(假阳性):被错误识别为热点的噪声点数,即真实背景中被算法判定为热点的点;
- FN(假阴性):被错误识别为噪声的热点点数,即真实热点中被算法判定为背景的点。
对于多热点场景,论文采用宏精准率(macro-precision) 和宏召回率(macro-recall):先计算每个热点的精准率和召回率,再取算术平均值,避免大热点的结果掩盖小热点的性能。
3.2.2 面积估计误差
通过算法估计的热点面积与真实面积的偏差,评估算法对热点空间范围的估计精度,这也是本文算法的核心优势维度。
3.3 对比方法选择
论文选择了5种主流的热点检测方法作为对比,覆盖了聚类、学习、统计三大类方法,保证了对比的全面性与公平性:
- EllipticScan:椭圆窗口的空间扫描统计,是传统空间扫描统计的主流改进方法,与本文方法同属统计扫描类,是最核心的对比基准;
- DBSCAN:经典密度聚类算法,是基于聚类的热点检测方法的代表;
- Spectral Clustering:谱聚类,基于图谱的聚类方法代表;
- Deep Embedding Clustering:深度嵌入聚类,深度学习类热点检测方法的代表;
- Significant DBSCAN:加入统计显著性检验的DBSCAN改进方法,是密度聚类领域的最新主流方法。
论文中所有对比方法的参数,均严格按照原论文的建议设置,保证了对比的公平性。
3.4 实验结果深度解读
3.4.1 TWScan的基础检测性能
TWScan在5个Case中的检测结果如图4 所示,从可视化结果可直观看到:
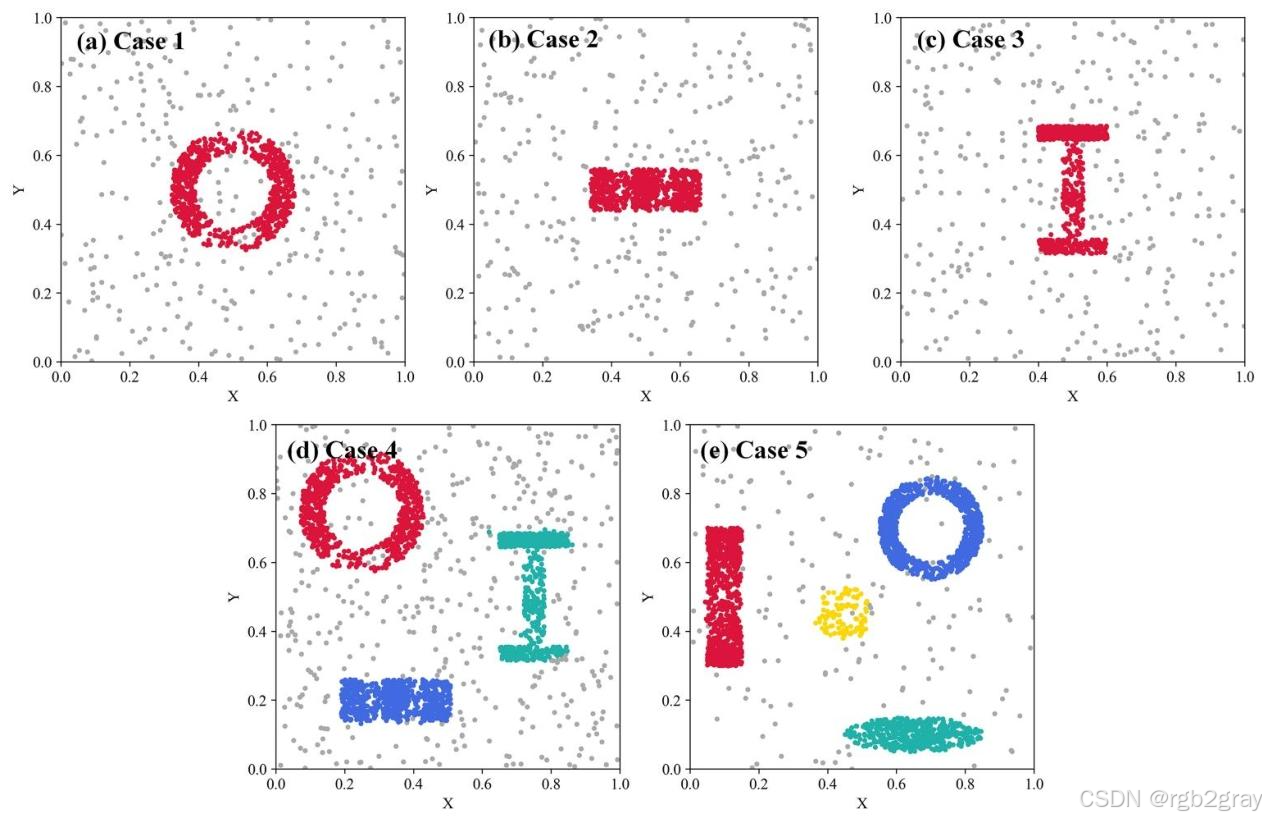
图4 TWScan在模拟数据上的检测结果
图注:彩色点为TWScan识别的热点,灰色点为识别的噪声。
- 对于Case1的环形热点,TWScan完美识别了环形结构,未将中心空心区域的噪声判定为热点,无漏检、无误判;
- 对于Case3的I型热点,TWScan完整识别了整个I形结构,未出现传统方法只识别部分区域的问题;
- 对于多热点的Case4和Case5,TWScan精准区分了每个独立热点,未出现合并、拆分问题,即使是Case5中仅100个点的小圆形热点,也被完整识别,无遗漏。
量化结果显示:TWScan在所有Case中,精准率和召回率均超过98%,几乎无误判和漏判;对热点面积的估计值与真实值的平均误差小于5%,与设计值几乎完全一致。这证明了TWScan算法在不规则热点识别、范围估计上的极致精度。
3.4.2 与主流方法的性能对比
各方法的精准率与召回率量化对比如下表所示:
| TWScan | EllipticScan | DBSCAN | Spectral | Deep | Sig. DBSCAN | ||
|---|---|---|---|---|---|---|---|
| Case 1 | Precision | 98.49% | 97.71% | 66.65% | 51.81% | 51.78% | 89.81% |
| Recall | 98.00% | 98.98% | 52.44% | 51.66% | 51.80% | 88.12% | |
| Case 2 | Precision | 99.25% | 97.57% | 90.31% | 53.12% | 53.94% | 98.65% |
| Recall | 99.24% | 97.01% | 86.30% | 53.34% | 53.70% | 100.00% | |
| Case 3 | Precision | 99.07% | 69.51% | 76.39% | 62.41% | 60.16% | 97.73% |
| Recall | 99.35% | 56.55% | 66.89% | 65.26% | 61.72% | 99.98% | |
| Case 4 | Precision | 98.62% | 93.55% | 75.31% | 74.12% | 78.74% | 75.42% |
| Recall | 98.49% | 92.62% | 71.23% | 82.24% | 88.18% | 74.64% | |
| Case 5 | Precision | 99.35% | 98.68% | 96.43% | 80.20% | 85.08% | 74.26% |
| Recall | 98.95% | 98.69% | 96.50% | 83.70% | 87.74% | 73.56% |
结合可视化结果图5 ,我们可以得出四大核心结论:

图5 5种对比方法的检测结果
图注:列从左到右为Case1-Case5,行从上到下为EllipticScan、DBSCAN、谱聚类、深度聚类、Significant DBSCAN。
-
TWScan在所有场景下性能均为第一
TWScan在几乎所有Case中,精准率和召回率均为最高,尤其是在Case3的I型热点、Case4的多不规则热点、Case5的小热点场景中,优势极其明显。而其他方法均存在明显的场景短板:
- EllipticScan在Case1、Case2的简单场景中性能尚可,但在Case3的I型热点中,精准率和召回率直接暴跌至70%和57%,仅能识别I型热点的顶部水平部分,完全无法捕捉不规则形态;
- DBSCAN在所有场景中均出现严重的热点拆分、过度聚类问题,精准率和召回率远低于TWScan,且结果高度依赖参数设置;
- 谱聚类和深度聚类在所有场景中性能均垫底,不仅需要提前输入热点数量,还极易将噪声和热点混为一谈,完全无法满足实际应用需求;
- Significant DBSCAN在单热点场景中性能尚可,但在多热点的Case4、Case5中,性能直接暴跌,不仅会拆分完整热点,还会遗漏Case5中的小热点,完全无法处理热点规模差异大的场景。
-
TWScan的热点面积估计精度碾压传统方法
热点面积估计的对比如下表所示:
| Shape | True value | TWScan | EllipticScan | |
|---|---|---|---|---|
| Case 1 | Ring | 0.064 | 0.061 | 0.122 |
| Case 2 | Rectangle | 0.038 | 0.039 | 0.046 |
| Case 3 | I | 0.034 | 0.036 | 0.011 |
| Case 4 | Ring | 0.064 | 0.061 | 0.116 |
| Rectangle | 0.038 | 0.038 | 0.024 | |
| I | 0.034 | 0.035 | 0.026 | |
| Case 5 | Rectangle | 0.040 | 0.042 | 0.047 |
| Ring | 0.039 | 0.042 | 0.102 | |
| Ellipse | 0.031 | 0.035 | 0.031 | |
| Circle | 0.020 | 0.020 | 未识别 |
从表中可直观看到:
- TWScan估计的面积与真实值几乎完全一致,平均误差小于5%;
- EllipticScan对环形热点的面积高估近100%,对I型热点的面积低估近70%,甚至完全无法识别Case5中的小圆形热点;
- DBSCAN、谱聚类、深度聚类、Significant DBSCAN,均无法直接输出热点的面积,完全无法满足对热点空间范围的量化需求。-
TWScan的统计显著性检验能力更严谨
仅TWScan、EllipticScan、Significant DBSCAN可输出统计显著性,但三者存在本质差异:
- EllipticScan的显著性检验基于整个椭圆窗口,而非真实热点,窗口内的噪声会导致检验结果偏差;
- Significant DBSCAN仅用热点内的点数作为检验统计量,未考虑热点面积,会遗漏小而密的热点;
- TWScan的显著性检验完全基于热点的真实范围,既考虑了热点内的点数,也考虑了热点的真实面积和背景分布,检验结果最严谨、最准确。
-
TWScan的参数主观性最低,鲁棒性最强
TWScan仅需设置最大扫描半径这一个参数,且参数设置的容错率极高,论文中所有Case均采用0.25的最大半径,无需针对不同场景调参;而其他方法均需要提前设置多个核心参数,且参数对结果影响极大,需要大量的经验调参,主观性极强。
四、真实世界案例:北京出租车上车点热点检测落地验证
模拟实验验证了算法的理论性能后,论文通过北京出租车上车点的真实城市数据,验证了TWScan算法在真实世界复杂场景中的落地能力。我们从研究设计、结果解读、对比分析三个维度,做深度拆解。
4.1 研究设计
4.1.1 研究区域选择
论文选取了北京两个典型的城市区域作为研究对象,两个区域的用地类型、热点形态差异极大,可全面测试算法在不同城市场景下的性能:
- 研究区域A:北京西二环内的传统核心商业区,包含北京金融街、西单商业街,是商业、金融机构的高度聚集区,人流密集,出租车热点主要沿城市道路呈线性分布,形态不规则;
- 研究区域B:北京东北三环至四环之间的混合用地区域,包含密集住宅区、地铁站、医院、高校,用地类型复杂,热点形态多样,包括地铁口的十字形热点、住宅区的片状热点、医院周边的不规则热点。
两个研究区域的位置与出租车上车点分布如图6所示:
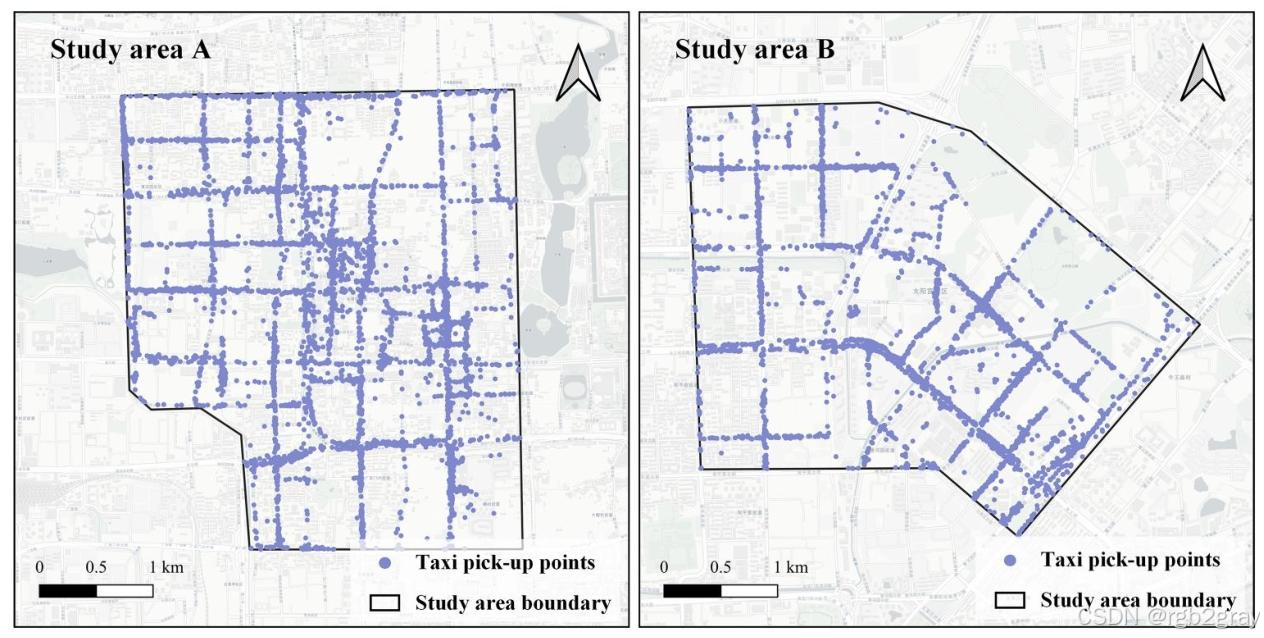
图6 研究区域与出租车上车点分布
图注:左侧为研究区域A,右侧为研究区域B,黑色点为出租车上车点。
4.1.2 实验数据
论文采用的是2014年10月21日-23日的北京出租车上车点公开数据集,每条数据包含出租车ID、上车点地理坐标、上车时间,是城市交通与空间分析领域的经典基准数据集,可保证实验结果的可复现性。
4.1.3 对比方法
由于谱聚类和深度聚类在模拟实验中性能垫底,且无法处理真实场景中的噪声,论文中仅选取了4种主流方法进行对比:TWScan、EllipticScan、DBSCAN、Significant DBSCAN,所有方法的参数均严格按照场景特征与原论文建议设置,保证对比公平性。
4.2 TWScan的检测结果与地理意义解读
TWScan在两个研究区域识别的Top3热点如图7 所示,我们结合城市地理特征,对每个热点的实际意义做深度解读:
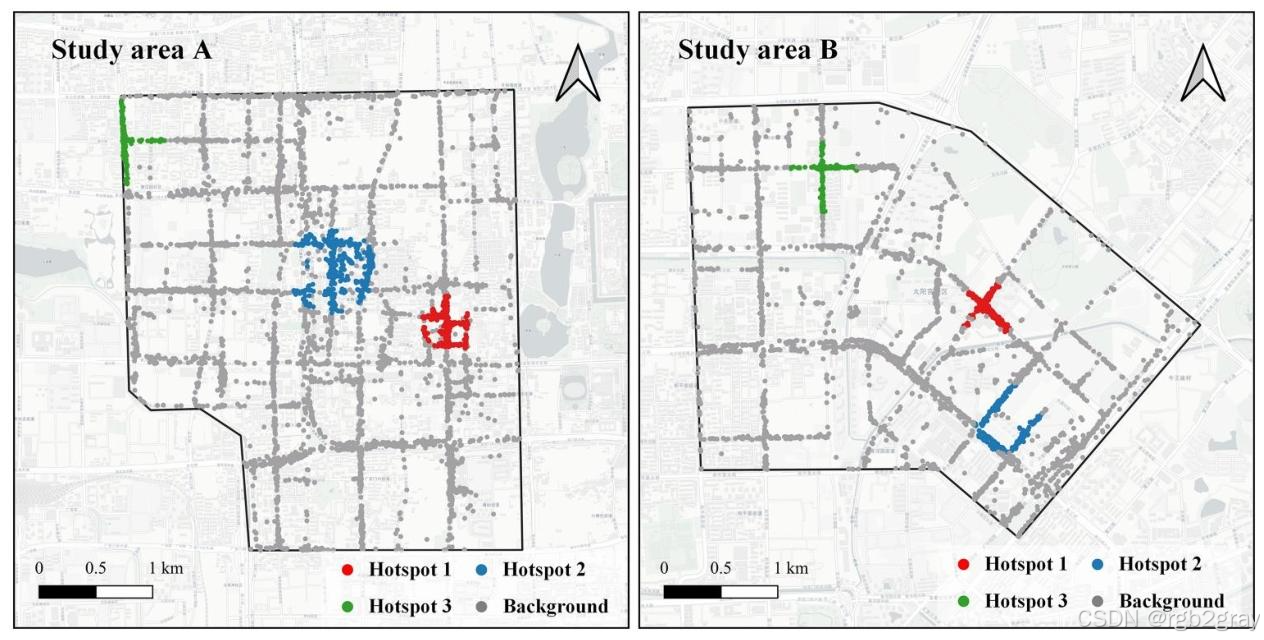
图7 TWScan识别的Top3出租车上车点热点
图注:彩色点为识别的热点,灰色点为背景上车点。
4.2.1 研究区域A的检测结果
研究区域A的Top3热点,完全对应了北京西城区的核心人流聚集区,且热点形态完美贴合实际场景:
- 热点1:西单商业街
热点以北西单大街为中轴线,完美覆盖了道路两侧的西单购物中心、汉光百货、西单大悦城、华为大厦等大型商业综合体,呈线性分布,精准贴合商业街的走向。这个区域是北京核心的商圈,周末与节假日人流极大,出租车出行需求极高,与检测结果完全匹配。TWScan输出的热点面积约153061㎡。 - 热点2:北京金融街
热点完整覆盖了金融街的银行、保险、证券等金融机构聚集区,呈片状分布。金融街是北京的金融核心区,商务出行需求极高,早晚高峰出租车流量极大,是典型的高需求热点。TWScan输出的热点面积约508424㎡,是区域内最大的热点,与金融街的实际规模完全匹配。 - 热点3:三里河路沿线
热点沿三里河路分布,覆盖了周边的政府机关与大型住宅区,对应公务出行与居民日常通勤的出租车需求。TWScan输出的热点面积约97444㎡。
4.2.2 研究区域B的检测结果
研究区域B的Top3热点,完美匹配了混合用地区域的人流特征,尤其是对地铁口十字形热点的识别,充分体现了TWScan对不规则形态的捕捉能力:
- 热点1:太阳宫地铁站
热点呈十字形,完美覆盖了太阳宫地铁站的四个出口,精准捕捉了地铁换乘带来的「最后一公里」出租车高需求。这个十字形的不规则形态,是传统椭圆窗口完全无法匹配的,而TWScan完美贴合了热点的真实形状。TWScan输出的热点面积约73818㎡。 - 热点2:曙光里、凤凰城等密集住宅区
热点覆盖了周边多个大型成熟社区,呈不规则片状分布,对应居民日常通勤、购物、出行的出租车需求。TWScan输出的热点面积约115001㎡。 - 热点3:中日友好医院、对外经贸大学周边
热点覆盖了医院、高校与周边住宅区,对应就医、上学、通勤带来的复合出行需求,形态完全贴合人流聚集的实际范围。TWScan输出的热点面积约69328㎡。
从结果可以看到:TWScan不仅能精准识别热点的位置,还能通过收紧窗口的面积,精准量化热点的空间范围,为城市交通管理、运力调度、公共设施优化提供了精准的量化数据支撑,这是其他方法完全无法实现的。
4.3 与主流方法的对比结果深度解读
三种对比方法的检测结果如图8 所示,结合结果我们可以清晰看到传统方法在真实城市场景中的核心缺陷:
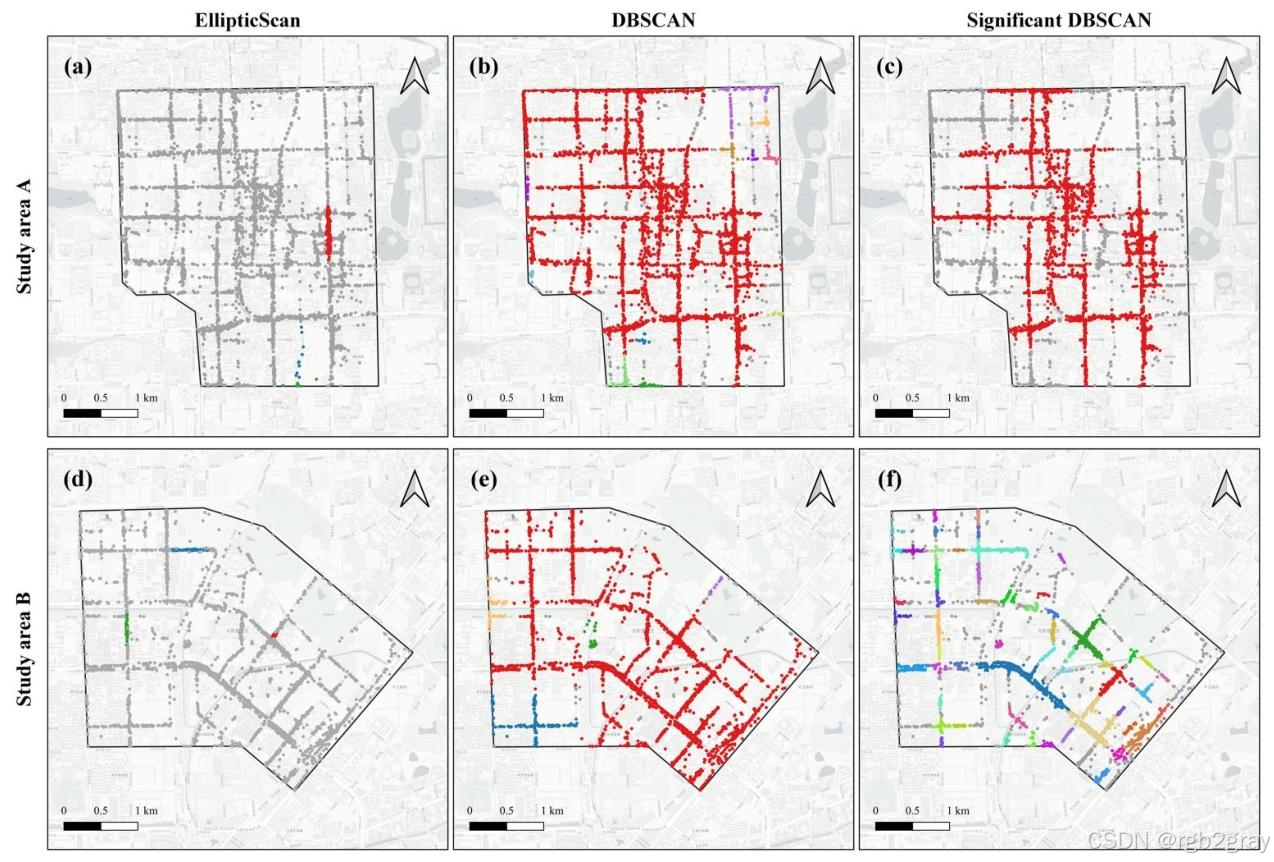
图8 对比方法的出租车热点检测结果
图注:上排为研究区域A,下排为研究区域B;列从左到右为EllipticScan、DBSCAN、Significant DBSCAN。
4.3.1 EllipticScan的核心缺陷
EllipticScan只能识别椭圆形态的聚集区,对于真实城市中沿道路分布的线性热点、地铁口的十字形热点,完全无法捕捉完整形态:
- 在研究区域A中,仅能识别西单北大街沿线的一小部分热点,完全无法覆盖两侧商业综合体的聚集区;
- 在研究区域B中,仅能识别太阳宫地铁站东北出口的一小部分热点,完全无法覆盖十字形的四个出口,严重低估了热点的范围;
- 对热点面积的估计,与真实场景偏差极大,研究区域A的核心热点面积仅估计为90321㎡,不到TWScan估计值的60%,完全无法反映热点的真实规模。
4.3.2 DBSCAN的核心缺陷
DBSCAN在真实场景中出现了严重的过度聚类与聚类不足问题:
- 过度聚类:将西单商业街和金融街两个空间独立、功能完全不同的热点,合并为一个大簇,完全无法区分不同的热点;将太阳宫地铁站、周边高校、住宅区合并为一个超大簇,丢失了热点的细节特征;
- 聚类不足:产生了大量零散的、无意义的小热点,结果杂乱无章,根本无法用于实际的交通管理决策;
- 无法输出热点的空间范围,也无法进行统计显著性检验,无法区分真实热点与随机聚集。
4.3.3 Significant DBSCAN的核心缺陷
Significant DBSCAN虽然通过显著性检验过滤了部分虚假热点,但依然无法解决密度聚类的固有缺陷:
- 在研究区域A中,依然将多个独立热点合并为一个大簇,无法区分西单商业街和金融街;
- 在研究区域B中,又将太阳宫地铁站的十字形完整热点,拆分为多个零散的小簇,完全无法识别热点的整体形态;
- 无法输出热点的面积与空间范围,无法为决策提供量化支撑。
4.4 案例研究结论
北京出租车数据的真实案例,充分验证了TWScan算法在真实世界复杂场景中的落地能力:
- TWScan可精准识别真实城市中沿道路、地铁口分布的不规则形态热点,完美贴合热点的真实形状,性能远超传统方法;
- TWScan可精准量化热点的空间范围,为城市交通管理、运力调度、公共设施优化提供了精准的量化数据;
- TWScan的参数鲁棒性强,无需针对不同城市场景反复调参,工程落地门槛极低;
- TWScan的结果具备严谨的统计显著性,可直接作为政务决策的科学依据,完全满足城市管理的合规性要求。
五、论文结论、创新价值与未来展望
5.1 论文核心结论
论文通过理论创新、模拟实验、真实案例验证,得出了四大核心结论:
- 本文提出的「收紧窗口」概念,彻底突破了传统空间扫描统计对预定义几何窗口的依赖,实现了任意形状热点的自适应匹配,从底层解决了不规则热点检测的世纪难题;
- 基于k近邻距离统计的收紧窗口面积估计方法,无需勾勒热点几何边界,即可完成精准的统计量计算,方法简洁、高效、无偏,具备极强的普适性;
- 本文提出的TWScan算法,在热点显著性检验、不规则形状识别、空间范围估计、参数鲁棒性四大维度,全面超越现有主流方法;
- TWScan算法在真实城市交通场景中,可精准识别地铁口、商业街等不规则形态的出行热点,可为城市交通管理、资源优化提供精准的决策支撑,具备极强的工程应用价值。
5.2 论文的核心创新价值
5.2.1 理论价值
论文提出的「收紧窗口」概念,是空间扫描统计领域近30年来的重要理论突破。它彻底改变了传统空间扫描统计「用窗口定义热点」的底层逻辑,开创了「用热点定义窗口」的全新范式,不仅可用于空间扫描统计,还可扩展到Ripley's K函数、核密度估计等所有基于扫描窗口的空间统计方法中,为空间统计学的发展提供了全新的思路。
5.2.2 应用价值
论文提出的TWScan算法,解决了现有热点检测方法的所有核心痛点,可直接落地到公共卫生、公共安全、城市交通、灾害监测等数十个领域:
- 公共卫生:可精准识别沿河流、社区分布的不规则疾病暴发热点,为疫情防控提供精准支撑;
- 公共安全:可精准识别城市中不规则的犯罪热点,指导警力精准部署;
- 灾害监测:可精准识别沿断裂带分布的地震聚集热点,为地震风险评估提供依据;
- 城市交通:可精准识别沿道路、地铁口分布的出行热点,优化交通运力调度。
5.3 论文的局限性与未来研究方向
论文中客观地分析了TWScan算法的局限性,并提出了明确的未来研究方向:
-
算法计算复杂度优化
局限性:多次扫描迭代与收紧窗口构建,带来了更高的计算复杂度,在超大规模数据集(如千万级以上的城市GPS点)上的运行效率有待提升。
未来方向:开发更高效的算法逻辑,结合空间索引、GPU加速等技术,提升大规模数据下的运行效率。
-
从欧氏空间到网络空间的扩展
局限性:目前算法基于欧氏距离构建,而城市中的出租车、交通事故、犯罪事件等,都是受路网约束的网络空间点事件,网络距离比欧氏距离更贴合实际场景。
未来方向:将TWScan算法扩展到网络空间,开发基于网络距离的收紧窗口扫描统计方法,进一步提升城市场景下的检测精度。
-
应用场景的拓展
局限性:目前论文仅在出租车出行数据中验证了算法的落地能力。
未来方向:将算法应用到传染病监测、犯罪分析、地震聚类等更多领域,验证算法的普适性;同时扩展到时-空间三维热点检测,实现时空聚集的动态监测。
python
# ====================== 1. 依赖库导入 ======================
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import poisson
from sklearn.neighbors import KDTree
from tqdm import tqdm
# ====================== 2. TWScan核心算法类 ======================
class TWScan:
def __init__(self, points, max_radius, sig_level=0.05, n_monte_carlo=999):
"""
TWScan算法初始化(对应论文2.1-2.2节核心逻辑)
:param points: 输入空间点数据,shape=(n, 2),numpy数组
:param max_radius: 原始圆形扫描窗口的最大半径
:param sig_level: 统计显著性水平,论文默认95%,即0.05
:param n_monte_carlo: 蒙特卡洛模拟次数,论文默认999次
"""
self.points = points
self.n_points = points.shape[0]
self.max_radius = max_radius
self.sig_level = sig_level
self.n_monte_carlo = n_monte_carlo
# 研究区域边界与总面积(对应论文公式2的背景密度计算)
self.x_min, self.x_max = points[:, 0].min(), points[:, 0].max()
self.y_min, self.y_max = points[:, 1].min(), points[:, 1].max()
self.area_total = (self.x_max - self.x_min) * (self.y_max - self.y_min)
# 全局背景点密度λ(对应论文公式2)
self.lambda_global = self.n_points / self.area_total
# 构建KDTree加速近邻搜索(对应论文2.2节k近邻计算)
self.kd_tree = KDTree(points)
# 结果存储
self.best_llr = -np.inf
self.best_window = None
self.hotspots = []
self.p_value = None
def _remove_noise_in_window(self, window_points):
"""
步骤1:原始窗口内噪声点去除(对应论文2.2节第一步,公式5)
:param window_points: 原始圆形窗口内的点集,shape=(n, 2)
:return: 剔除噪声后的密集点集
"""
n_window = window_points.shape[0]
if n_window < 3:
return window_points
# 论文中k值自适应设置:k = log10(n)
k = max(1, int(np.log10(n_window)))
# 窗口内构建KDTree,仅计算窗口内的k近邻(论文强调的局部化计算)
window_tree = KDTree(window_points)
distances, _ = window_tree.query(window_points, k=k+1)
# 取第k近邻距离(排除自身)
d_k = distances[:, k]
# 计算95%显著性水平下的距离阈值(对应论文公式5)
lambda_window = n_window / (np.pi * self.max_radius**2)
# 二分法求解阈值x,满足P(Dk >= x) = 0.05
def prob_fun(x):
lambda_pi_x2 = lambda_window * np.pi * (x ** 2)
prob_sum = 0
for m in range(k):
prob_sum += poisson.pmf(m, lambda_pi_x2)
return prob_sum - 0.05
# 二分法求解阈值
x_low, x_high = 0, self.max_radius
for _ in range(100):
x_mid = (x_low + x_high) / 2
p = prob_fun(x_mid)
if p > 0:
x_low = x_mid
else:
x_high = x_mid
threshold = x_mid
# 剔除噪声,保留密集点
dense_points = window_points[d_k <= threshold]
return dense_points
def _estimate_dense_density(self, dense_points):
"""
步骤2:密集点的局部密度估计(对应论文2.2节第二步,公式6)
:param dense_points: 剔除噪声后的密集点集
:return: 密集点局部密度λ_d
"""
n_d = dense_points.shape[0]
if n_d < 3:
return self.lambda_global
# 自适应k值:k = log10(n_d)
k = max(1, int(np.log10(n_d)))
# 计算密集点的k近邻距离
dense_tree = KDTree(dense_points)
distances, _ = dense_tree.query(dense_points, k=k+1)
d_k_sq = distances[:, k] ** 2
# 论文公式6计算局部密度
lambda_d = (n_d * k) / (np.pi * np.sum(d_k_sq))
return lambda_d
def _calc_tightened_window_llr(self, dense_points, lambda_d):
"""
步骤3:计算收紧窗口面积与对数似然比LLR(对应论文2.2节第三步,公式7-8)
:param dense_points: 密集点集
:param lambda_d: 密集点局部密度
:return: 收紧窗口LLR值、收紧窗口面积S_TW、密集点数量n_d
"""
n_d = dense_points.shape[0]
if n_d == 0:
return 0, 0, 0
# 论文公式7:收紧窗口面积计算
s_tw = n_d / lambda_d
# 论文公式8:收紧窗口的对数似然比LLR计算
if n_d <= self.lambda_global * s_tw:
llr = 0
else:
term1 = n_d * np.log(n_d / (self.lambda_global * s_tw))
term2 = (self.n_points - n_d) * np.log((self.n_points - n_d) / (self.n_points - self.lambda_global * s_tw))
llr = term1 + term2
return llr, s_tw, n_d
def fit(self):
"""
TWScan主流程:遍历所有扫描窗口,寻找最优热点(对应论文2.1节扫描框架)
"""
print("====== 开始TWScan扫描计算 ======")
# 以每个点为中心,遍历不同半径的扫描窗口
radius_list = np.linspace(self.max_radius*0.1, self.max_radius, 20)
max_llr_list = []
for center in tqdm(self.points, desc="扫描窗口遍历"):
for radius in radius_list:
# 1. 获取当前圆形窗口内的所有点
idx = self.kd_tree.query_radius(center.reshape(1, -1), r=radius)[0]
window_points = self.points[idx]
n_window = window_points.shape[0]
if n_window < 5:
continue
# 2. 三步法构建收紧窗口
dense_points = self._remove_noise_in_window(window_points)
if dense_points.shape[0] < 3:
continue
lambda_d = self._estimate_dense_density(dense_points)
llr, s_tw, n_d = self._calc_tightened_window_llr(dense_points, lambda_d)
# 3. 更新全局最优LLR
max_llr_list.append(llr)
if llr > self.best_llr:
self.best_llr = llr
self.best_window = {
"center": center,
"radius": radius,
"dense_points": dense_points,
"s_tw": s_tw,
"n_d": n_d,
"llr": llr
}
# 蒙特卡洛模拟计算p值(对应论文2.1节公式4)
print("====== 开始蒙特卡洛显著性检验 ======")
mc_max_llr = []
for _ in tqdm(range(self.n_monte_carlo), desc="蒙特卡洛模拟"):
# 原假设下生成随机均匀分布的点
rand_points = np.random.uniform(
low=[self.x_min, self.y_min],
high=[self.x_max, self.y_max],
size=(self.n_points, 2)
)
rand_tree = KDTree(rand_points)
current_max_llr = 0
# 随机数据的扫描计算
for center in rand_points[::10]: # 采样加速,完整计算可去掉步长
for radius in radius_list:
idx = rand_tree.query_radius(center.reshape(1, -1), r=radius)[0]
window_points = rand_points[idx]
n_window = window_points.shape[0]
if n_window < 5:
continue
# 简化版三步法加速蒙特卡洛
dense_points = self._remove_noise_in_window(window_points)
if dense_points.shape[0] < 3:
continue
lambda_d = self._estimate_dense_density(dense_points)
llr, _, _ = self._calc_tightened_window_llr(dense_points, lambda_d)
if llr > current_max_llr:
current_max_llr = llr
mc_max_llr.append(current_max_llr)
# 计算p值(论文公式4)
n_extreme = len([llr for llr in mc_max_llr if llr > self.best_llr])
self.p_value = (n_extreme + 1) / (self.n_monte_carlo + 1)
# 输出结果
if self.p_value < self.sig_level:
self.hotspots.append(self.best_window)
print(f"====== 检测到显著热点 ======")
print(f"最大LLR值: {self.best_llr:.2f}")
print(f"p值: {self.p_value:.4f} (显著水平: {self.sig_level})")
print(f"热点真实点数: {self.best_window['n_d']}")
print(f"收紧窗口估计面积: {self.best_window['s_tw']:.6f}")
else:
print("未检测到统计显著的热点")
return self.hotspots
# ====================== 3. 模拟数据生成(对应论文3.1节) ======================
def generate_simulated_data(case="ring", n_hotspot=700, n_noise=300):
"""
生成论文中的模拟数据集,支持环形、I型、矩形热点
:param case: 热点类型,可选"ring"/"I"/"rectangle"
:param n_hotspot: 热点点数
:param n_noise: 背景噪声点数
:return: 合并后的点集shape=(n,2),真实热点标签shape=(n,)
"""
np.random.seed(42) # 固定随机种子保证可复现
hotspot_points = []
labels = []
if case == "ring":
# 论文Case1:环形热点
r_inner, r_outer = 0.2, 0.3
for _ in range(n_hotspot):
theta = np.random.uniform(0, 2*np.pi)
r = np.random.uniform(r_inner, r_outer)
x = 0.5 + r * np.cos(theta)
y = 0.5 + r * np.sin(theta)
hotspot_points.append([x, y])
labels.append(1)
elif case == "I":
# 论文Case3:I型热点
# 上横条
for _ in range(n_hotspot//3):
x = np.random.uniform(0.3, 0.7)
y = np.random.uniform(0.75, 0.8)
hotspot_points.append([x, y])
labels.append(1)
# 中竖条
for _ in range(n_hotspot//3):
x = np.random.uniform(0.475, 0.525)
y = np.random.uniform(0.2, 0.75)
hotspot_points.append([x, y])
labels.append(1)
# 下横条
for _ in range(n_hotspot//3):
x = np.random.uniform(0.3, 0.7)
y = np.random.uniform(0.15, 0.2)
hotspot_points.append([x, y])
labels.append(1)
elif case == "rectangle":
# 论文Case2:矩形热点
for _ in range(n_hotspot):
x = np.random.uniform(0.3, 0.7)
y = np.random.uniform(0.3, 0.5)
hotspot_points.append([x, y])
labels.append(1)
# 生成背景噪声点
noise_points = np.random.uniform(low=0, high=1, size=(n_noise, 2))
noise_labels = np.zeros(n_noise)
# 合并数据
all_points = np.vstack([np.array(hotspot_points), noise_points])
all_labels = np.hstack([np.array(labels), noise_labels])
return all_points, all_labels
# ====================== 4. 算法运行与结果可视化 ======================
if __name__ == "__main__":
# 1. 生成模拟数据(论文Case3:I型不规则热点)
points, true_labels = generate_simulated_data(case="I", n_hotspot=700, n_noise=300)
# 2. 初始化并运行TWScan算法
twscan = TWScan(
points=points,
max_radius=0.4, # 对应论文模拟实验的0.25最大半径比例
sig_level=0.05,
n_monte_carlo=999
)
hotspots = twscan.fit()
# 3. 结果可视化
plt.figure(figsize=(12, 5), dpi=100)
# 子图1:真实热点分布
plt.subplot(1, 2, 1)
plt.scatter(points[true_labels==0, 0], points[true_labels==0, 1], c="gray", s=5, label="背景噪声")
plt.scatter(points[true_labels==1, 0], points[true_labels==1, 1], c="green", s=8, label="真实热点")
plt.title("真实热点分布", fontsize=12)
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.legend()
plt.axis("equal")
# 子图2:TWScan检测结果
plt.subplot(1, 2, 2)
plt.scatter(points[:, 0], points[:, 1], c="gray", s=5, label="背景点")
if hotspots:
hotspot_pts = hotspots[0]["dense_points"]
plt.scatter(hotspot_pts[:, 0], hotspot_pts[:, 1], c="red", s=8, label="TWScan识别热点")
# 绘制原始扫描窗口
circle = plt.Circle(
hotspots[0]["center"], hotspots[0]["radius"],
color="blue", fill=False, linestyle="--", linewidth=1.5, label="原始扫描窗口"
)
plt.gca().add_patch(circle)
plt.title(f"TWScan检测结果 (p值={twscan.p_value:.4f})", fontsize=12)
plt.xlim(0, 1)
plt.ylim(0, 1)
plt.legend()
plt.axis("equal")
plt.tight_layout()
plt.show()