项目地址:https://github.com/thu-ml/SLA
项目下有SageSLA与sparse_linear_attention两个版本,SageSLA是基于SageAttention实现的版本,sparse_linear_attention是基于triton实现的版本。
根据SLA论文描述,可以将wan2.1 1.3b模型生成480p fps 16 时长5s的视频Flops从53T降低到2.73T,推理速度提升2倍左右。为此对实现代码进行分析,了解其实现流程与实测效果。在实际测试中SLA相比Flash_attn耗时可以降低70%左右(视频生成模型中 Attention(尤其是时空 Attention)通常占总耗时的 70%~85%,attention计算节省80%的耗时,故整体节省60%的耗时,整体提升2.2倍左右)
(行业主流:640×480 帧编码为 16×16=256 个视觉 Token,即每个 Token 对应 30×30 像素)
总 Token 长度 = 单帧 Token 数 × 总帧数 + 额外 Token = 256 × 80 + 32 = 20512 TokenSparseLinearAttention
SparseLinearAttention实现代码如下,可以发现是带参数的(proj_l 用于对线性稀疏注意力进行投影缩放)。
具体执行步骤为:
输入预处理 → 生成稀疏映射(get_block_map函数) → 稀疏注意力计算(o_s,基于triton kernel实现的_attention) → 线性注意力计算(o_l,calc_linear函数) → 投影融合(proj_l投影后相加) → 输出
py
import torch
import torch.nn as nn
import torch.nn.functional as F
from .kernel import _attention
from .utils import get_block_map
class SparseLinearAttention(nn.Module):
def __init__(self, head_dim, topk, feature_map='softmax', BLKQ=64, BLKK=64, use_bf16=True, tie_feature_map_qk=True):
R'''
Args:
head_dim: dimension of each head.
topk: ratio of keys selected for sparse attention, shared across all queries.
feature_map: feature map for linear attention, one of ['hedgehog', 'elu', 'relu', 'softmax'].
BLKQ: block size for query.
BLKK: block size for key.
use_bf16: whether to use bfloat16 (default) or float16 for computation. The conversion to bf16/fp16 is done inside the module.
tie_feature_map_qk: whether to use the same feature map for query and key.
'''
super().__init__()
self.dtype = torch.bfloat16 if use_bf16 else torch.float16
self.topk = topk
self.BLKQ = BLKQ
self.BLKK = BLKK
self.proj_l = nn.Linear(head_dim, head_dim, dtype=torch.float32)
if feature_map == 'elu':
def elu_feature_map(x):
return F.elu(x) + 1
self.feature_map_q = elu_feature_map
self.feature_map_k = elu_feature_map
elif feature_map == 'relu':
self.feature_map_q = nn.ReLU()
self.feature_map_k = nn.ReLU()
elif feature_map == 'softmax':
def softmax_feature_map(x):
return F.softmax(x, dim=-1)
self.feature_map_q = softmax_feature_map
self.feature_map_k = softmax_feature_map
else:
raise NotImplementedError(f'Not supported feature map {feature_map}.')
if tie_feature_map_qk:
self.feature_map_k = self.feature_map_q
self.init_weights_()
def init_weights_(self):
with torch.no_grad():
nn.init.zeros_(self.proj_l.weight)
nn.init.zeros_(self.proj_l.bias)
def forward(self, q, k, v, return_sparsity=False):
R'''
Args:
q: queries of shape (B, H, L, D).
k: keys of shape (B, H, L, D).
v: values of shape (B, H, L, D).
return_sparsity: whether to return the actual sparsity.
'''
dtype = q.dtype
q = q.contiguous()
k = k.contiguous()
v = v.contiguous()
sparse_map, lut, real_topk = get_block_map(q, k, topk_ratio=self.topk, BLKQ=self.BLKQ, BLKK=self.BLKK)
q = q.to(self.dtype)
k = k.to(self.dtype)
v = v.to(self.dtype)
o_s = _attention.apply(q, k, v, sparse_map, lut, real_topk, self.BLKQ, self.BLKK)
q = self.feature_map_q(q).contiguous().to(self.dtype) # c_q
k = self.feature_map_k(k).contiguous().to(self.dtype) # c_k
def calc_linear(q, k, v):
kvsum = k.transpose(-1, -2) @ v
ksum = torch.sum(k, dim=-2, keepdim=True)
return (q @ kvsum) / (1e-5 + (q * ksum).sum(dim=-1, keepdim=True))
o_l = calc_linear(q, k, v)
with torch.amp.autocast('cuda', dtype=self.dtype):
o_l = self.proj_l(o_l)
o = (o_s + o_l).to(dtype)
if return_sparsity:
return o, real_topk / sparse_map.shape[-1]
else:
return oget_block_map实现
代码执行流程如下
输入q/k → k去中心化 → 分块均值池化(Triton加速) → 块级相似度计算 → TopK筛选Key块 → 生成稀疏映射/索引表
最终目的是为稀疏注意力模块(如你之前的 SparseLinearAttention)提供 "哪些 Key 块需要关注" 的映射关系,从而跳过无关 Key 块的计算,实现长序列注意力的高效计算。
py
import torch
import triton
import triton.language as tl
@triton.jit
def compress_kernel(
X, XM,
L: tl.constexpr,
D: tl.constexpr,
BLOCK_L: tl.constexpr,
):
idx_l = tl.program_id(0)
idx_bh = tl.program_id(1)
offs_l = idx_l * BLOCK_L + tl.arange(0, BLOCK_L)
offs_d = tl.arange(0, D)
x_offset = idx_bh * L * D
xm_offset = idx_bh * ((L + BLOCK_L - 1) // BLOCK_L) * D
x = tl.load(X + x_offset + offs_l[:, None] * D + offs_d[None, :], mask=offs_l[:, None] < L)
nx = min(BLOCK_L, L - idx_l * BLOCK_L)
x_mean = tl.sum(x, axis=0, dtype=tl.float32) / nx
tl.store(XM + xm_offset + idx_l * D + offs_d, x_mean.to(XM.dtype.element_ty))
def mean_pool(x, BLK):
assert x.is_contiguous()
B, H, L, D = x.shape
L_BLOCKS = (L + BLK - 1) // BLK
x_mean = torch.empty((B, H, L_BLOCKS, D), device=x.device, dtype=x.dtype)
grid = (L_BLOCKS, B * H)
compress_kernel[grid](x, x_mean, L, D, BLK)
return x_mean
def get_block_map(q, k, topk_ratio, BLKQ=64, BLKK=64):
arg_k = k - torch.mean(k, dim=-2, keepdim=True) # smooth-k technique in SageAttention
pooled_qblocks = mean_pool(q, BLKQ)
pooled_kblocks = mean_pool(arg_k, BLKK)
pooled_score = pooled_qblocks @ pooled_kblocks.transpose(-1, -2)
K = pooled_score.shape[-1]
topk = min(K, int(topk_ratio * K))
lut = torch.topk(pooled_score, topk, dim=-1, sorted=False).indices
sparse_map = torch.zeros_like(pooled_score, dtype=torch.int8)
sparse_map.scatter_(-1, lut, 1)
return sparse_map, lut, topkSLA与Flash_attn对比 (kernel级)
通过对比可以发现输入序列越长,SLA提速效果越明显
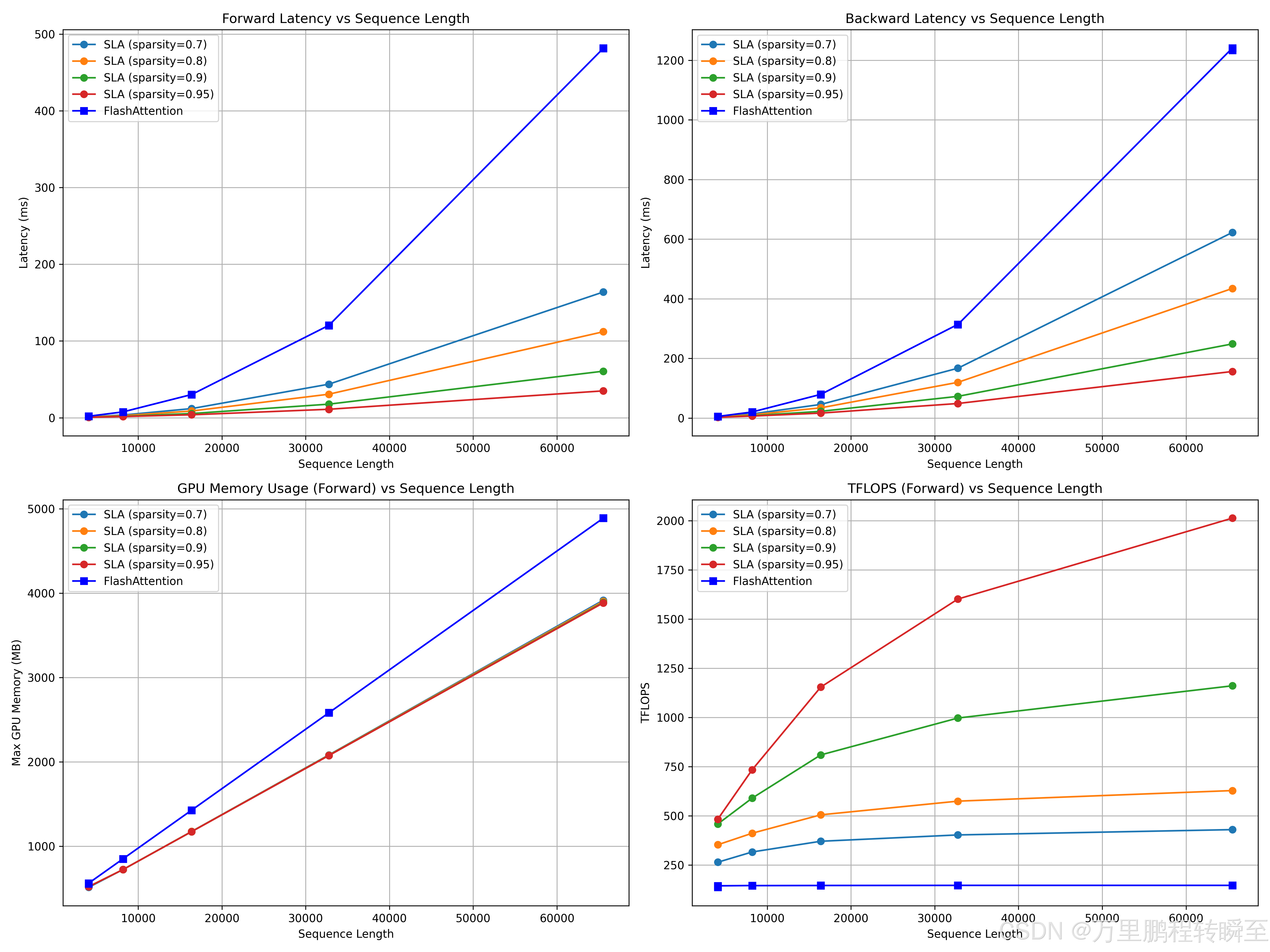
评测代码如下,输出是 o = o_s + o_l,对于线性注意力输出o_l没有进行按照论文进行投影缩放。
py
import torch
import triton
import psutil
import gc
from typing import Dict, List
import pandas as pd
# 解决flash_attn导入问题
try:
from flash_attn.flash_attn_interface import flash_attn_func
HAS_FLASH = True
except ImportError:
HAS_FLASH = False
print("Warning: flash_attn not found, only SLA will be tested")
# 导入SLA相关模块
from sparse_linear_attention.utils import get_block_map
from sparse_linear_attention.kernel import _attention
# 全局配置
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if DEVICE.type != "cuda":
raise RuntimeError("This benchmark requires CUDA device")
# 基础参数
BATCH = 2
N_HEADS = 16
HEAD_DIM = 128
# 扩展测试的序列长度(覆盖不同尺寸)
TEST_SEQ_LENGTHS = [4096, 8192, 16384, 32760, 65536]
# 稀疏度配置(体现SLA的稀疏优势)
SPARSITY_RATIOS = [0.7, 0.8, 0.9, 0.95]
# 测试模式
MODES = ["fwd", "bwd"]
CAUSAL = False
# 显存监控工具函数
def get_gpu_memory_usage(device: torch.device) -> Dict[str, float]:
"""获取GPU显存使用情况(单位:MB)"""
if device.type != "cuda":
return {"used": 0.0, "max_allocated": 0.0}
torch.cuda.synchronize()
allocated = torch.cuda.memory_allocated(device) / 1024 / 1024
max_allocated = torch.cuda.max_memory_allocated(device) / 1024 / 1024
torch.cuda.reset_peak_memory_stats(device)
return {"used": allocated, "max_allocated": max_allocated}
def get_cpu_memory_usage() -> float:
"""获取CPU内存使用(单位:MB)"""
return psutil.Process().memory_info().rss / 1024 / 1024
# 性能测试核心函数
def benchmark_attention(
batch: int,
n_heads: int,
seq_len: int,
head_dim: int,
sparsity: float,
mode: str,
provider: str,
causal: bool = False
) -> Dict[str, float]:
"""
单组参数的性能测试,返回:
- 推理/反向耗时(ms)
- GPU显存占用(MB)
- TFLOPS
"""
assert mode in ["fwd", "bwd"], "Mode must be 'fwd' or 'bwd'"
assert provider in ["sla", "flash"] if HAS_FLASH else ["sla"], f"Invalid provider: {provider}"
# 清理显存
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats(DEVICE)
# 生成测试数据
dtype = torch.bfloat16
q = torch.randn((batch, n_heads, seq_len, head_dim), dtype=dtype, device=DEVICE, requires_grad=True).contiguous()
k = torch.randn((batch, n_heads, seq_len, head_dim), dtype=dtype, device=DEVICE, requires_grad=True).contiguous()
v = torch.randn((batch, n_heads, seq_len, head_dim), dtype=dtype, device=DEVICE, requires_grad=True).contiguous()
do = torch.randn_like(v)
# 基础计算量
flops_per_matmul = 2.0 * q.numel() * seq_len
total_flops = 2 * flops_per_matmul
if causal:
total_flops *= 0.5
if mode == "bwd":
total_flops *= 2.5 # 2.0(bwd) + 0.5(recompute)
# 定义测试函数
if provider == "flash":
# flash_attn要求维度为 [B, N_CTX, H, HEAD_DIM]
q_flash = q.transpose(1, 2).contiguous()
k_flash = k.transpose(1, 2).contiguous()
v_flash = v.transpose(1, 2).contiguous()
do_flash = do.transpose(1, 2).contiguous()
def forward_fn():
with torch.no_grad() if mode == "fwd" else torch.enable_grad():
return flash_attn_func(q_flash, k_flash, v_flash, causal=causal)
if mode == "bwd":
o = forward_fn()
def backward_fn():
o.backward(do_flash, retain_graph=True)
return o
test_fn = backward_fn
else:
test_fn = forward_fn
else: # SLA
# 获取稀疏映射
sparse_map, lut, real_topk = get_block_map(
q, k, topk_ratio=1 - sparsity, BLKQ=128, BLKK=64
)
# 线性注意力计算(SLA的线性部分)
def calc_linear(q_, k_, v_):
kvsum = k_.transpose(-1, -2) @ v_
ksum = torch.sum(k_, dim=-2, keepdim=True)
return (q_ @ kvsum) / (1e-5 + (q_ * ksum).sum(dim=-1, keepdim=True))
def forward_fn():
with torch.no_grad() if mode == "fwd" else torch.enable_grad():
o_s = _attention.apply(q, k, v, sparse_map, lut, real_topk, 128, 64)
o_l = calc_linear(q, k, v)
return o_s + o_l
if mode == "bwd":
o = forward_fn()
def backward_fn():
o.backward(do, retain_graph=True)
return o
test_fn = backward_fn
else:
test_fn = forward_fn
# 预热(避免首次运行开销)
for _ in range(5):
test_fn()
# 测试耗时
torch.cuda.synchronize()
ms = triton.testing.do_bench(test_fn, warmup=10, rep=50) # 增加测试次数提升稳定性
# 获取显存占用
gpu_mem = get_gpu_memory_usage(DEVICE)
cpu_mem = get_cpu_memory_usage()
# 计算TFLOPS
tflops = total_flops * 1e-12 / (ms * 1e-3)
return {
"seq_len": seq_len,
"sparsity": sparsity,
"mode": mode,
"provider": provider,
"latency_ms": ms,
"gpu_mem_used_mb": gpu_mem["used"],
"gpu_mem_max_mb": gpu_mem["max_allocated"],
"cpu_mem_used_mb": cpu_mem,
"tflops": tflops
}
# 批量测试与结果汇总
def run_benchmark_suite() -> pd.DataFrame:
"""运行完整的基准测试套件,返回结构化结果"""
results = []
providers = ["sla"] + (["flash"] if HAS_FLASH else [])
print(f"=== Starting Benchmark (Device: {DEVICE}) ===")
print(f"Test Config: BATCH={BATCH}, N_HEADS={N_HEADS}, HEAD_DIM={HEAD_DIM}")
print(f"Seq Lengths: {TEST_SEQ_LENGTHS} | Sparsity: {SPARSITY_RATIOS} | Modes: {MODES}")
for seq_len in TEST_SEQ_LENGTHS:
for sparsity in SPARSITY_RATIOS:
for mode in MODES:
for provider in providers:
# 跳过flash_attn的稀疏度无关测试(仅标记固定稀疏度0.0)
test_sparsity = sparsity if provider == "sla" else 0.0
print(f"\nTesting: {provider.upper()} | Seq: {seq_len} | Sparsity: {test_sparsity} | Mode: {mode}")
try:
res = benchmark_attention(
batch=BATCH,
n_heads=N_HEADS,
seq_len=seq_len,
head_dim=HEAD_DIM,
sparsity=test_sparsity,
mode=mode,
provider=provider,
causal=CAUSAL
)
results.append(res)
print(f"✅ Result: Latency={res['latency_ms']:.2f}ms | GPU Mem={res['gpu_mem_max_mb']:.2f}MB | TFLOPS={res['tflops']:.2f}")
except Exception as e:
print(f"❌ Failed: {str(e)}")
continue
# 转换为DataFrame方便分析
df = pd.DataFrame(results)
return df
# 结果可视化(可选)
def plot_benchmark_results(df: pd.DataFrame):
"""绘制性能对比图(需安装matplotlib)"""
try:
import matplotlib.pyplot as plt
plt.rcParams["font.size"] = 10
# 1. 不同序列长度的耗时对比
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# 子图1:前向耗时 vs 序列长度
ax1 = axes[0, 0]
for provider in df["provider"].unique():
data = df[df["provider"] == provider]
for sparsity in data["sparsity"].unique():
if provider == "sla":
plot_data = data[(data["sparsity"] == sparsity) & (data["mode"] == "fwd")]
ax1.plot(plot_data["seq_len"], plot_data["latency_ms"],
label=f"SLA (sparsity={sparsity})", marker="o")
else:
plot_data = data[(data["mode"] == "fwd")]
ax1.plot(plot_data["seq_len"], plot_data["latency_ms"],
label="FlashAttention", marker="s", color="blue")
ax1.set_title("Forward Latency vs Sequence Length")
ax1.set_xlabel("Sequence Length")
ax1.set_ylabel("Latency (ms)")
ax1.legend()
ax1.grid(True)
# 子图2:反向耗时 vs 序列长度
ax2 = axes[0, 1]
for provider in df["provider"].unique():
data = df[df["provider"] == provider]
for sparsity in data["sparsity"].unique():
if provider == "sla":
plot_data = data[(data["sparsity"] == sparsity) & (data["mode"] == "bwd")]
ax2.plot(plot_data["seq_len"], plot_data["latency_ms"],
label=f"SLA (sparsity={sparsity})", marker="o")
else:
plot_data = data[(data["mode"] == "bwd")]
ax2.plot(plot_data["seq_len"], plot_data["latency_ms"],
label="FlashAttention", marker="s", color="blue")
ax2.set_title("Backward Latency vs Sequence Length")
ax2.set_xlabel("Sequence Length")
ax2.set_ylabel("Latency (ms)")
ax2.legend()
ax2.grid(True)
# 子图3:GPU显存占用 vs 序列长度
ax3 = axes[1, 0]
for provider in df["provider"].unique():
data = df[df["provider"] == provider]
for sparsity in data["sparsity"].unique():
if provider == "sla":
plot_data = data[(data["sparsity"] == sparsity) & (data["mode"] == "fwd")]
ax3.plot(plot_data["seq_len"], plot_data["gpu_mem_max_mb"],
label=f"SLA (sparsity={sparsity})", marker="o")
else:
plot_data = data[(data["mode"] == "fwd")]
ax3.plot(plot_data["seq_len"], plot_data["gpu_mem_max_mb"],
label="FlashAttention", marker="s", color="blue")
ax3.set_title("GPU Memory Usage (Forward) vs Sequence Length")
ax3.set_xlabel("Sequence Length")
ax3.set_ylabel("Max GPU Memory (MB)")
ax3.legend()
ax3.grid(True)
# 子图4:TFLOPS vs 序列长度
ax4 = axes[1, 1]
for provider in df["provider"].unique():
data = df[df["provider"] == provider]
for sparsity in data["sparsity"].unique():
if provider == "sla":
plot_data = data[(data["sparsity"] == sparsity) & (data["mode"] == "fwd")]
ax4.plot(plot_data["seq_len"], plot_data["tflops"],
label=f"SLA (sparsity={sparsity})", marker="o")
else:
plot_data = data[(data["mode"] == "fwd")]
ax4.plot(plot_data["seq_len"], plot_data["tflops"],
label="FlashAttention", marker="s", color="blue")
ax4.set_title("TFLOPS (Forward) vs Sequence Length")
ax4.set_xlabel("Sequence Length")
ax4.set_ylabel("TFLOPS")
ax4.legend()
ax4.grid(True)
plt.tight_layout()
plt.savefig("sla_vs_flash_benchmark.png", dpi=300)
#plt.show()
except ImportError:
print("Warning: matplotlib not installed, skip plotting")
if __name__ == "__main__":
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# 运行基准测试
results_df = run_benchmark_suite()
# 保存结果到CSV
results_df.to_csv("sla_vs_flash_benchmark_results.csv", index=False)
print("\n=== Benchmark Complete ===")
print("Results saved to: sla_vs_flash_benchmark_results.csv")
# 打印汇总表格
print("\n=== Summary Table ===")
print(results_df.pivot_table(
index=["seq_len", "sparsity", "mode"],
columns="provider",
values=["latency_ms", "gpu_mem_max_mb", "tflops"],
aggfunc="mean"
))
# 绘制可视化图表
plot_benchmark_results(results_df)SLA与Flash_attn对比 (应用级别)
直接对比应用层代码SparseLinearAttention与flash_attn_qkvpacked_func 的差异,可以发现只有在序列长度达到4096 及以上时才存在速度提升。同时,基于基于SLA方式,在显存消耗上较高。SLA的输出与Flash_attn的输出并不等价,这表明attention替换为SLA方式后,需要重新训练模型。 根据SLA论文中描述,大约2000个iter微调后,性能可以恢复。

txt
===== 1024 序列长度下的 汇总结果(精准指标) =====
稀疏度 SparseTime(ms) FlashTime(ms) SparseMem(MB) FlashMem(MB) MSE CosSim
0.99 0.51 0.27 84.79 24.38 nan nan
0.95 0.42 0.25 84.79 12.38 nan nan
0.90 0.51 0.24 84.80 12.38 0.960938 0.0732
0.80 0.50 0.24 84.82 12.38 0.933594 0.1396
0.70 0.45 0.24 84.83 12.38 0.929688 0.1621
0.50 0.52 0.24 84.88 12.38 0.921875 0.2314
0.30 0.52 0.24 84.91 12.38 0.921875 0.2734
0.00 0.50 0.24 84.97 12.38 0.921875 0.3242
===== 2048 序列长度下的 汇总结果(精准指标) =====
稀疏度 SparseTime(ms) FlashTime(ms) SparseMem(MB) FlashMem(MB) MSE CosSim
0.99 1.13 0.90 160.86 48.75 nan nan
0.95 1.23 0.93 160.88 24.75 0.968750 0.0430
0.90 0.86 1.39 160.93 24.75 0.941406 0.0845
0.80 1.11 0.89 161.00 24.75 0.933594 0.1230
0.70 0.92 0.87 161.07 24.75 0.929688 0.1514
0.50 1.04 0.86 161.23 24.75 0.929688 0.2012
0.30 1.21 0.88 161.37 24.75 0.925781 0.2344
0.00 1.54 0.87 161.61 24.75 0.925781 0.2793
===== 4096 序列长度下的 汇总结果(精准指标) =====
稀疏度 SparseTime(ms) FlashTime(ms) SparseMem(MB) FlashMem(MB) MSE CosSim
0.99 1.55 3.32 288.38 97.50 nan nan
0.95 1.73 3.14 288.52 49.50 0.945312 0.0503
0.90 1.86 3.14 288.66 49.50 0.937500 0.0747
0.80 2.20 3.14 288.94 49.50 0.933594 0.1064
0.70 2.61 3.14 289.27 49.50 0.933594 0.1338
0.50 3.43 3.14 289.88 49.50 0.933594 0.1729
0.30 4.07 3.14 290.44 49.50 0.933594 0.2012
0.00 5.32 3.15 291.38 49.50 0.933594 0.2373
===== 8192 序列长度下的 汇总结果(精准指标) =====
稀疏度 SparseTime(ms) FlashTime(ms) SparseMem(MB) FlashMem(MB) MSE CosSim
0.99 3.70 12.50 577.59 195.00 0.972656 0.0142
0.95 4.11 12.38 578.06 99.00 0.941406 0.0447
0.90 4.75 11.70 578.62 99.00 0.937500 0.0645
0.80 6.19 11.68 579.84 99.00 0.933594 0.0938
0.70 7.64 11.70 582.00 99.00 0.933594 0.1143
0.50 10.61 11.69 583.50 99.00 0.933594 0.1475
0.30 13.23 11.80 585.84 99.00 0.933594 0.1709
0.00 17.86 11.72 589.50 99.00 0.933594 0.2002
===== 16384 序列长度下的 汇总结果(精准指标) =====
稀疏度 SparseTime(ms) FlashTime(ms) SparseMem(MB) FlashMem(MB) MSE CosSim
0.99 7.69 46.64 1158.38 390.00 0.953125 0.0140
0.95 9.34 46.49 1160.25 198.00 0.937500 0.0393
0.90 12.22 46.57 1162.83 198.00 0.933594 0.0576
0.80 17.90 46.52 1167.56 198.00 0.933594 0.0811
0.70 23.40 46.64 1172.25 198.00 0.933594 0.0981
0.50 35.43 46.62 1182.00 198.00 0.933594 0.1260
0.30 46.18 46.66 1191.56 198.00 0.933594 0.1465
0.00 64.27 46.67 1206.00 198.00 0.933594 0.1709
===== 32768 序列长度下的 汇总结果(精准指标) =====
稀疏度 SparseTime(ms) FlashTime(ms) SparseMem(MB) FlashMem(MB) MSE CosSim
0.99 16.51 186.07 2329.88 780.00 0.941406 0.0150
0.95 24.43 185.81 2337.38 396.00 0.933594 0.0356
0.90 36.90 186.14 2347.12 396.00 0.933594 0.0510
0.80 58.44 185.83 2366.25 396.00 0.933594 0.0708
0.70 80.95 185.79 2385.38 396.00 0.933594 0.0859
0.50 129.13 186.36 2424.00 396.00 0.933594 0.1084
0.30 172.09 185.88 2462.25 396.00 0.933594 0.1270
0.00 245.14 185.96 2520.00 396.00 0.933594 0.1475 通过以上实测,可以发现在长序列情况下,SLA可以节省70~80的耗时。并根据论文中的数据,可以发现可以将模型的FLOPs降低20倍左右。
对比代码
py
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
import psutil
import numpy as np
from typing import Dict, List, Tuple
from flash_attn import flash_attn_qkvpacked_func # FlashAttention 核心函数
from scipy.spatial.distance import cosine
import matplotlib.pyplot as plt
from sparse_linear_attention.utils import get_block_map
from sparse_linear_attention.kernel import _attention
from sparse_linear_attention.core import SparseLinearAttention
# ==============================================
# 精准显存监控函数(核心替换)
# ==============================================
def reset_gpu_memory_stats():
"""重置GPU显存统计,确保每次测试独立"""
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
def get_gpu_peak_memory_mb() -> float:
"""获取从上次reset后的GPU峰值显存(MB)"""
if not torch.cuda.is_available():
return 0.0
return torch.cuda.max_memory_allocated() / (1024 * 1024)
def get_gpu_current_memory_mb() -> float:
"""获取当前GPU已分配显存(MB),用于基线校准"""
if not torch.cuda.is_available():
return 0.0
return torch.cuda.memory_allocated() / (1024 * 1024)
# ==============================================
# 其他工具函数(保留并优化)
# ==============================================
def compute_mse(output1: torch.Tensor, output2: torch.Tensor) -> float:
assert output1.shape == output2.shape, f"维度不匹配!output1: {output1.shape}, output2: {output2.shape}"
return F.mse_loss(output1, output2).item()
def compute_cosine_similarity(output1: torch.Tensor, output2: torch.Tensor) -> float:
assert output1.shape == output2.shape, f"维度不匹配!output1: {output1.shape}, output2: {output2.shape}"
output1_flat = output1.detach().cpu().flatten()
output2_flat = output2.detach().cpu().flatten()
dot_product = torch.dot(output1_flat, output2_flat)
norm1 = torch.norm(output1_flat)
norm2 = torch.norm(output2_flat)
eps = 1e-8
cos_sim = dot_product / (norm1 * norm2 + eps)
return cos_sim.item()
# ==============================================
# 核心对比测试函数(含精准显存监控)
# ==============================================
def compare_attention_methods(
head_dim: int = 64,
batch_size: int = 8,
num_heads: int = 12,
seq_len: int = 1024,
topk_ratios: List[float] = [0.1, 0.2, 0.3, 0.5, 0.7, 1.0],
feature_map: str = 'softmax',
dtype: torch.dtype = torch.bfloat16
) -> Dict[str, List[float]]:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if not torch.cuda.is_available():
raise RuntimeError("需要CUDA环境运行FlashAttention和稀疏注意力")
if dtype not in [torch.float16, torch.bfloat16]:
raise ValueError("FlashAttention仅支持torch.float16或torch.bfloat16")
results = {
'topk_ratio': [],
'sparse_time': [],
'flash_time': [],
'sparse_peak_memory': [], # 改为峰值显存
'flash_peak_memory': [],
'mse': [],
'cosine_sim': []
}
# 生成测试数据
torch.manual_seed(42)
q = torch.randn(batch_size, num_heads, seq_len, head_dim, device=device, dtype=dtype)
k = torch.randn(batch_size, num_heads, seq_len, head_dim, device=device, dtype=dtype)
v = torch.randn(batch_size, num_heads, seq_len, head_dim, device=device, dtype=dtype)
# 处理FlashAttention输入
q_ = q.permute(0, 2, 1, 3).contiguous()
k_ = k.permute(0, 2, 1, 3).contiguous()
v_ = v.permute(0, 2, 1, 3).contiguous()
qkv = torch.stack([q_, k_, v_], dim=2).contiguous()
# 预热
_ = flash_attn_qkvpacked_func(qkv, causal=False, softmax_scale=(head_dim**0.5))
sparse_model = SparseLinearAttention(head_dim=head_dim, topk=1.0, feature_map=feature_map, use_bf16=(dtype == torch.bfloat16)).to(device)
_ = sparse_model(q, k, v)
torch.cuda.synchronize()
# 遍历测试
for topk_ratio in topk_ratios:
#print(f"\n测试稀疏度比例: {topk_ratio}")
results['topk_ratio'].append(topk_ratio)
# --------------------------
# 1. 测试SparseLinearAttention(精准显存监控)
# --------------------------
sparse_model = SparseLinearAttention(
head_dim=head_dim, topk=topk_ratio, feature_map=feature_map, use_bf16=(dtype == torch.bfloat16)
).to(device)
reset_gpu_memory_stats() # 重置显存统计
baseline_mem = get_gpu_current_memory_mb() # 记录测试前基线(数据+模型参数)
sparse_output = sparse_model(q, k, v)
# 计时+运行
start_time = time.time()
sparse_output = None
for _ in range(5):
sparse_output = sparse_model(q, k, v)
torch.cuda.synchronize()
end_time = time.time()
# 计算指标
sparse_time = (end_time - start_time) * 1000 / 5
peak_mem = get_gpu_peak_memory_mb()
sparse_memory = peak_mem - baseline_mem # 仅保留模型运行的增量峰值
results['sparse_time'].append(sparse_time)
results['sparse_peak_memory'].append(sparse_memory)
# --------------------------
# 2. 测试FlashAttention(精准显存监控)
# --------------------------
reset_gpu_memory_stats() # 重置显存统计
baseline_mem = get_gpu_current_memory_mb() # 重新校准基线
# 计时+运行
start_time = time.time()
flash_output = None
for _ in range(5):
flash_output = flash_attn_qkvpacked_func(qkv, causal=False, softmax_scale=(head_dim**0.5))
flash_output = flash_output.permute(0, 2, 1, 3).contiguous()
torch.cuda.synchronize()
end_time = time.time()
# 计算指标
flash_time = (end_time - start_time) * 1000 / 5
peak_mem = get_gpu_peak_memory_mb()
flash_memory = peak_mem - baseline_mem
results['flash_time'].append(flash_time)
results['flash_peak_memory'].append(flash_memory)
# --------------------------
# 3. 精度指标
# --------------------------
#print(f" 维度检查 - Sparse: {sparse_output.shape}, Flash: {flash_output.shape}")
mse = compute_mse(sparse_output, flash_output)
cos_sim = compute_cosine_similarity(sparse_output, flash_output)
results['mse'].append(mse)
results['cosine_sim'].append(cos_sim)
# # 打印结果
# print(f" SparseLinearAttention - 耗时: {sparse_time:.2f}ms, 增量峰值显存: {sparse_memory:.2f}MB")
# print(f" FlashAttn - 耗时: {flash_time:.2f}ms, 增量峰值显存: {flash_memory:.2f}MB")
# print(f" 精度 - MSE: {mse:.6f}, 余弦相似度: {cos_sim:.4f}")
return results
# ==============================================
# 可视化+主函数(适配新的显存字段)
# ==============================================
def plot_results(results: Dict[str, List[float]], save_tag="attention_comparison_precise"):
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('SparseLinearAttention vs FlashAttn Comparison (Precise Metrics)', fontsize=16)
# 1. 耗时对比
axes[0,0].plot(results['topk_ratio'], results['sparse_time'], 'o-', label='SparseLinearAttention')
axes[0,0].plot(results['topk_ratio'], results['flash_time'], 's-', label='FlashAttn')
axes[0,0].set_xlabel('TopK Ratio (Sparsity)')
axes[0,0].set_ylabel('Time (ms)')
axes[0,0].set_title('Inference Time Comparison')
axes[0,0].legend()
axes[0,0].grid(True)
# 2. 峰值显存对比(核心修改)
axes[0,1].plot(results['topk_ratio'], results['sparse_peak_memory'], 'o-', label='SparseLinearAttention')
axes[0,1].plot(results['topk_ratio'], results['flash_peak_memory'], 's-', label='FlashAttn')
axes[0,1].set_xlabel('TopK Ratio (Sparsity)')
axes[0,1].set_ylabel('Peak Memory (MB)')
axes[0,1].set_title('Peak Memory Usage (Incremental)')
axes[0,1].legend()
axes[0,1].grid(True)
# 3. MSE对比
axes[1,0].plot(results['topk_ratio'], results['mse'], 'o-', color='red')
axes[1,0].set_xlabel('TopK Ratio (Sparsity)')
axes[1,0].set_ylabel('MSE')
axes[1,0].set_title('Output MSE (Lower is Better)')
axes[1,0].grid(True)
# 4. 余弦相似度对比
axes[1,1].plot(results['topk_ratio'], results['cosine_sim'], 'o-', color='green')
axes[1,1].set_xlabel('TopK Ratio (Sparsity)')
axes[1,1].set_ylabel('Cosine Similarity')
axes[1,1].set_title('Output Cosine Similarity (Higher is Better)')
axes[1,1].grid(True)
axes[1,1].set_ylim(0, 1.0)
plt.tight_layout()
plt.savefig(f'{save_tag}.png', dpi=300)
plt.show()
if __name__ == "__main__":
seq_len=[1024,2048,4096,8192,16384,32768]
for seq in seq_len:
test_results = compare_attention_methods(
head_dim=64,
batch_size=8,
num_heads=12,
seq_len=seq,
topk_ratios=[0.01, 0.05, 0.1, 0.2, 0.3, 0.5, 0.7, 1.0],
feature_map='softmax',
dtype=torch.bfloat16
)
plot_results(test_results, save_tag=f"sla_vs_flash_comparison_precise_seq_{seq}")
# 打印汇总表格
print(f"\n===== {seq} 序列长度下的 汇总结果(精准指标) =====")
print(f"{'稀疏度':<6} {'SparseTime(ms)':<15} {'FlashTime(ms)':<15} {'SparseMem(MB)':<15} {'FlashMem(MB)':<15} {'MSE':<10} {'CosSim':<10}")
for i, ratio in enumerate(test_results['topk_ratio']):
print(f"{1-ratio:<6.2f} {test_results['sparse_time'][i]:<15.2f} {test_results['flash_time'][i]:<15.2f} "
f"{test_results['sparse_peak_memory'][i]:<15.2f} {test_results['flash_peak_memory'][i]:<15.2f} "
f"{test_results['mse'][i]:<10.6f} {test_results['cosine_sim'][i]:<10.4f}")