LangChain 实践
内容:Model I/O、Prompt/OutputParser、自定义LLM/ChatModel、RAG全链路、多向量检索、Self-querying、MMR、结构化Agent、Function Call Agent
一、入门
项目1:个人知识库问答机器人(极简RAG)
知识点:文档加载器、文本分割、Embedding、FAISS向量库、基础检索、Prompt模板、OutputParser
功能
- 本地导入 PDF/笔记/Markdown 文档
- 自动切块、向量化、入库
- 自然语言提问,基于私有文档回答
重点
把 RAG 完整链路 加载→分割→嵌入→存储→检索→生成 跑通,是所有高级项目的基础。
项目2:自定义大模型封装+通用对话链
知识点:自定义LLM/ChatModel、Model I/O、PromptTemplate、LCEL链式调用、Token统计、缓存
功能
- 封装通义千问/本地开源模型为 LangChain 标准模型
- 实现对话、角色人设、调用缓存、记录Token消耗
重点
吃透「自定义LLM继承、_generate/_call、模型参数调优」。
二、进阶
项目3:增强版智能知识库(集成所有高级检索策略)
知识点:语义分块、MMR去重、上下文压缩、多向量检索(摘要/假设问题)、Self-querying元数据检索
功能
- 支持语义分割,不按字数硬切
- 检索结果 MMR 去重,避免重复内容
- 上下文压缩精简冗余文档
- 多向量:摘要检索、假设问题检索优化匹配
- Self-querying 自动解析时间/分类/评分等元数据过滤
价值
做完这个,RAG所有高级玩法全部吃透。
项目4:结构化输出问答器(Pydantic + 自定义OutputParser)
知识点:Pydantic结构化输出、自定义解析器、类NER信息抽取、RunnableLambda
功能
- 输入自然语言,自动抽取:天气/时间/地址/商品信息
- 强制固定JSON结构输出,失败自动校验重试
三、高阶
项目5:不依赖Function Call的结构化通用Agent
知识点:结构化Agent、Prompt工程、不支持Function Call模型适配、自定义工具
功能
- 自己写 Prompt 约束格式:
Action:xxx Action Input:xxx - 不用模型原生Function Call,纯提示词实现工具调用
- 接入:计算器、时间查询、本地文档检索工具
落地:结构化Agent不靠模型,靠Prompt实现Agent。
项目6:Function Call 智能工具助手
知识点:bind_tools、自定义工具、AgentExecutor、自定义解析器、Response伪装成格式工具
功能
- 多工具自动调度:查天气、查时间、知识库检索
- 最后强制调用Response输出结构化JSON
- 自定义parse解析终止流程
四、企业级项目
项目7:私人AI助手全站项目
整合所有知识点:Model I/O + 高级RAG + 多检索策略 + 结构化&Function双Agent + 缓存 + Token统计
功能
- 私有知识库问答
- 多工具智能决策
- 结构化信息抽取
- 对话记忆、缓存加速、Token消耗统计
做完直接可以放到 GitHub 当代表作。
项目1:极简个人知识库问答机器人
掌握本项目就等于掌握 RAG 全流程。
项目结构
personal-knowledge-qa-bot/
├── docs/ # 放你要读取的文档(.txt / .md)
├── main.py # 主程序第一步:安装依赖
python
pip install langchain pypdf faiss-cpu numpy第二步:完整代码
python
# ======================
# 项目1:极简RAG知识库问答
# 流程:加载文档 → 分割 → 向量化 → 存向量库 → 检索 → 回答
# ======================
# 文档加载器:读取本地 txt 文档
from langchain_community.document_loaders import TextLoader
# 文本分割器:把长文本切成小块
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 提示词模板:构造给大模型的提问格式
from langchain_core.prompts import ChatPromptTemplate
# 输出解析器:把模型返回结果转成字符串
from langchain_core.output_parsers import StrOutputParser
# FAISS 向量库:存储向量 + 快速相似度检索
from langchain_community.vectorstores import FAISS
# 本地开源向量模型(把文本转成向量)
from langchain_huggingface import HuggingFaceEmbeddings
# 通义千问大模型(生成最终回答)
from langchain_community.llms import Tongyi
# 操作系统底层工具库,此处读取环境变量
import os
# 加载 .env 文件中的密钥
from dotenv import load_dotenv
# ----------------------
# 加载环境变量(API KEY)
# ----------------------
load_dotenv() # 加载项目根目录下的 .env 文件
tongyi_api_key = os.getenv("TONGYI_API_KEY") # 读取通义KEY
print(tongyi_api_key)
# ======================
# 1. 初始化模型
# ======================
# 创建通义大模型实例
llm = Tongyi(api_key=tongyi_api_key)
# 本地 BGE 中文向量模型路径
embeddings_path = "H:\\AI\\Agent\\models\\bge-large-zh-v1.5"
# 创建向量模型实例
embeddings = HuggingFaceEmbeddings(model_name=embeddings_path)
# ======================
# 2. 加载本地文档
# ======================
# 知识库文件路径
DOC_PATH = "./docs/test.txt"
loader = TextLoader(DOC_PATH, encoding="utf-8")
# 读取全文
documents = loader.load()
# ======================
# 3. 文本分割
# ======================
splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # 每块大小:300 个字
chunk_overlap=50, # 重叠(重叠 50 个字)防止丢失上下文
)
# 切分后的文本块
chunks = splitter.split_documents(documents)
# ======================
# 4. 向量化 + 存入 FAISS 向量库
# ======================
# 把所有文本块 → 向量 → 存入 FAISS
db = FAISS.from_documents(chunks, embeddings)
# 构建检索器(获取最相似的3条)
retriever = db.as_retriever(search_kwargs={"k": 3})
# ======================
# 5. 提示词模板
# ======================
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个文档问答助手,只能根据提供的资料回答,不能编造。\n资料:{context}"),
("user", "问题:{question}")
])
# ======================
# 6. 输出解析器
# ======================
parser = StrOutputParser()
# ======================
# 7. RAG 核心链
# ======================
def rag_chain(question):
# 1. 根据用户问题,检索最相关的文档片段
docs = retriever.invoke(question)
context = "\n".join([d.page_content for d in docs])
# 2. 构造prompt: 把资料 + 问题 填入提示词模板
formatted_prompt = prompt.invoke({
"context": context,
"question": question
})
# 3. 大模型生成回答
response = llm.invoke(formatted_prompt)
# 4. 解析输出
return parser.invoke(response)
# ======================
# 8. 启动测试
# ======================
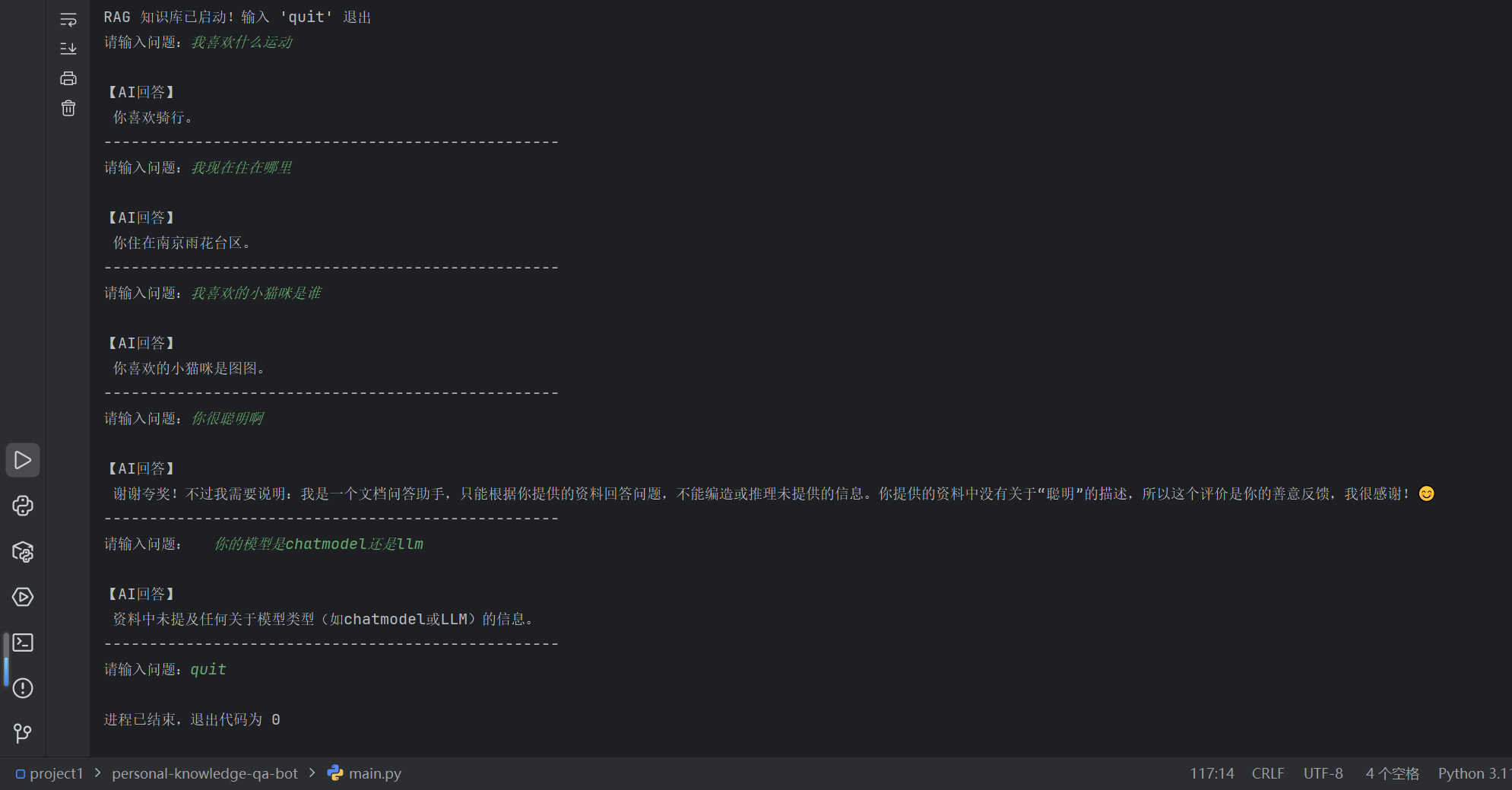
if __name__ == "__main__":
print("RAG 知识库已启动!输入 'quit' 退出")
while True:
question = input("请输入问题:")
if question.lower() == "quit":
break
answer = rag_chain(question)
print("\n【AI回答】\n", answer)
print("-"*50)第三步:使用方法
-
新建
docs文件夹 -
在里面放一个
test.txt,随便写一段内容,例如:我喜欢骑行,每周3次。
我最喜欢的小猫是图图。
我住在南京雨花台区。 -
运行
main.py -
提问:
我喜欢做什么运动?
运行输出
代码流程
python
开始
↓
【环境准备】加载.env → 获取通义千问API Key
↓
【模型初始化】
├─ 通义千问LLM(生成回答)
└─ BGE中文向量模型(文本转向量)
↓
【文档加载】读取本地txt文档 → 得到完整文档内容
↓
【文本分割】将长文本切分成小块(chunk_size=300,重叠50)
↓
【向量化 + 向量库存储】
文本块 → 向量模型 → 向量
向量 → 存入FAISS本地向量库
↓
【构建检索器】设置从向量库召回最相似的3条内容
↓
【提示词模板】定义系统提示(根据资料回答,不编造)
↓
【输出解析】将模型返回结果转为字符串
↓
【启动问答循环】等待用户输入问题
↓
┌───────────────────────────────────┐
│ RAG 核心问答链 │
│ 1. 用户问题 → 检索器 → 匹配相关文档 │
│ 2. 文档内容 + 问题 → 填入提示词 │
│ 3. 提示词 → 通义千问 → 生成回答 │
│ 4. 回答解析 → 输出给用户 │
└───────────────────────────────────┘
↓
循环问答,直到输入 quit → 结束项目知识点
✅ 文档加载
✅ 文本切块
✅ 向量库 FAISS
✅ 基础检索
✅ Prompt 模板
✅ 输出解析
✅ 完整 RAG 流水线
项目2:自定义大模型封装+通用对话链
考察内容
用到知识点:自定义LLM/ChatModel、Model I/O、PromptTemplate、LCEL链式调用、Token统计、缓存
功能
- 封装通义千问/本地开源模型为 LangChain 标准模型
- 实现对话、角色人设、调用缓存、记录Token消耗
适合练什么
吃透「自定义LLM继承、_generate/_call、模型参数调优」。
方案分析
有 3 种调用大模型的方案(从最简单 → 最底层)
-
方案 1:直接使用 LangChain 现成封装(项目 1 用的)
- 最简单 → 0 底层知识 → 开箱即用
from langchain_community.llms import Tongyi llm = Tongyi(api_key="...") llm.invoke("你好")- 原理
- 已经写好了整个 LLM 类,实现了 _call(),帮你发 HTTP, 帮你解析返回结果
- 你要做的内容:只调用(不关心底层)
-
方案2:自定义 LLM + 官方 SDK(中等难度)
- 自己写 LLM 类,但借用 SDK 发请求
- 原理
- 你要做的内容:继承 LangChain 的 LLM 基类,实现 call(), 在 _call () 里调用官方 SDK(dashscope)
- 不用自己写 HTTP
- 优点
- 学会自定义 LLM
- 不用处理复杂网络请求
-
方案3:自定义 LLM + 纯原生 HTTP(最底层 ✅️)
- 原理:自己写:请求头、请求体、POST、JSON解析、获取回答内容、处理异常(真正的从零封装大模型)
- 优点
- 彻底懂大模型调用原理
- 真正掌握 "封装"
- 任何模型都能接
方案3 自定义LLM + 原生HTTP调用
前置准备
安装依赖
python
pip install langchain-core requests python-dotenvpython-dotenv介绍
安装
python
pip install python-dotenv导入
python
from dotenv import load_dotenv
import os
# 加载项目根目录里的 .env 文件,把里面的密钥、配置读到环境变量里:
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY").env文件
已有通义千问API_KEY,存入.env文件
对话API
通义千问对话 API 地址:
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation
BaseLLM规范
必须继承
python
from langchain_core.language_models.llms import BaseLLM必须实现
- _llm_type()
- → 返回模型标识,框架识别用
- _generate()
- → 框架真正强制的核心方法,处理批量请求
_call() 是什么?
- 是辅助方法,方便写单条调用逻辑
- 不是必须,但写了会让代码更干净
- 会被 _generate 内部调用
HTTP 调用格式
针对通义千问模型的调用格式如下。
请求头
python
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}请求体
python
body = {
"model": self.model_name,
"input": {
"messages": [
{"role": "system", "content": "你是智能助手"},
{"role": "user", "content": prompt}
]
},
"parameters": {
"result_format": "message",
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
}基础自定义LLM
2-langchain-model-customize/SelfTongyiLLM.py
python
from langchain_core.language_models.llms import BaseLLM
from typing import Optional, List, Any
from langchain_core.callbacks import CallbackManagerForLLMRun
import requests
from langchain_core.outputs import LLMResult, Generation
class SelfTongyiLLM(BaseLLM):
# 自定义可配置参数
api_key: Optional[str] = None
model_name: str = "qwen-turbo"
temperature: float = 0.7
max_tokens: int = 1024
base_url: str = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 1:模型标识
@property
def _llm_type(self) -> str:
return "self_define_tongyi_http"
# 2. 核心调用方法(重点写这里)
def _generate(
self,
prompts: List[str],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> LLMResult:
# 直接取第一个提问,日常invoke只会传一个
prompt = prompts[0]
# 1. 拼接headers请求头
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# 2. 组装messages对话结构
messages = [
{"role": "system", "content": "你是一个智能聊天助手"},
{"role": "user", "content": prompt}
]
# 3. 构造完整请求体body
body = {
"model": self.model_name,
"input": { "messages": messages },
"parameters": {
"result_format": "message",
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
}
# 4. 发起请求 + 异常捕获
try:
response = requests.post(
url=self.base_url,
headers=headers,
json=body,
)
# 接口报错时抛出异常
response.raise_for_status()
# 6 解析响应json,提取回答文本
result = response.json()
# 7. 返回最终字符串结果
answer = result["output"]["choices"][0]["message"]["content"]
except Exception as e:
# 5 捕获异常
answer = f"调用失败:{str(e)}"
# 按框架固定格式返回结果
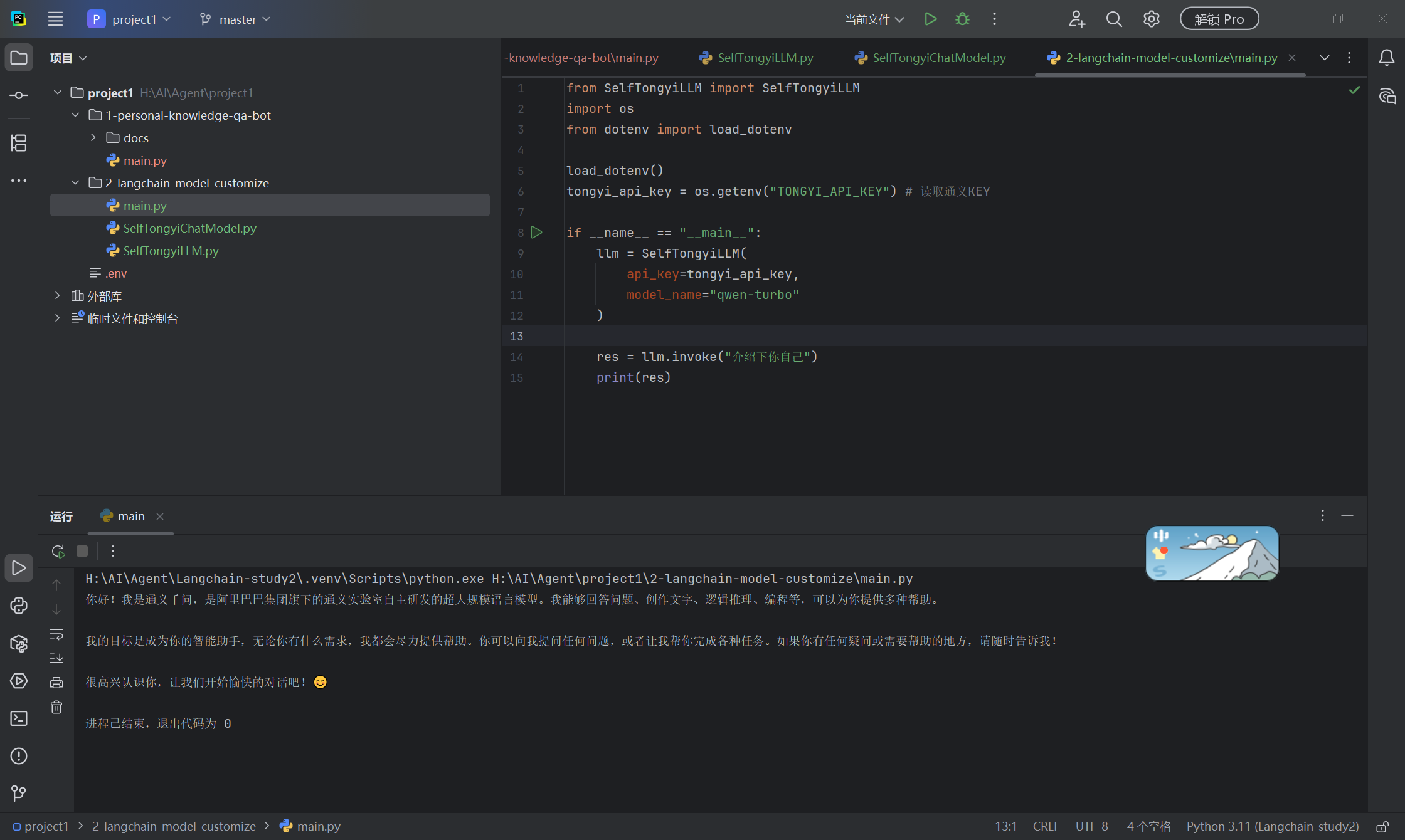
return LLMResult(generations=[[Generation(text=answer)]])2-langchain-model-customize/main.py
python
from SelfTongyiLLM import SelfTongyiLLM
import os
from dotenv import load_dotenv
load_dotenv()
tongyi_api_key = os.getenv("TONGYI_API_KEY") # 读取通义KEY
if __name__ == "__main__":
llm = SelfTongyiLLM(
api_key=tongyi_api_key,
model_name="qwen-turbo"
)
res = llm.invoke("介绍下你自己")
print(res)运行 main.py 结果
自定义ChatModel
LLM 与 ChatModel的区别
- BaseLLM:只接收纯文本字符串,适合单轮短句问答
- BaseChatModel:接收结构化消息对象(System/Human/AI),天生支持多轮对话、人设角色
项目做对话模型,优先继承 BaseChatModel,淘汰旧的 BaseLLM.
实现
python
from langchain_core.language_models.chat_models import BaseChatModel
from typing import Optional, List, Any, Dict
from langchain_core.callbacks import CallbackManagerForLLMRun
import requests
from langchain_core.outputs import ChatResult, ChatGeneration
from langchain_core.messages import BaseMessage, AIMessage, SystemMessage, HumanMessage
class SelfTongyiChatModel(BaseChatModel):
# 模型配置参数
api_key: Optional[str] = None
model_name: str = "qwen-turbo"
temperature: float = 0.7
max_tokens: int = 1024
base_url: str = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
# 固定必填:声明模型类型
@property
def _llm_type(self) -> str:
return "custom_tongyi_chat_model"
# 核心必填方法:预留_generate空实现
def _generate(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any
) -> ChatResult:
# 1. 转换消息格式
api_messages = self._convert_langchain_msg_to_api(messages)
# 2. 请求头
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# 3. 构造完整请求体body
body = {
"model": self.model_name,
"input": { "messages": api_messages },
"parameters": {
"result_format": "message",
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
}
# 4. 发起请求 + 异常捕获
try:
response = requests.post(
url=self.base_url,
headers=headers,
json=body,
)
# 接口报错时抛出异常
response.raise_for_status()
# 6 解析响应json,提取回答文本
result = response.json()
# 7. 返回最终字符串结果
answer = result["output"]["choices"][0]["message"]["content"]
except Exception as e:
# 5 捕获异常
answer = f"调用失败:{str(e)}"
# 封装成LangChain标准返回格式
return ChatResult(
generations=[ChatGeneration(message=AIMessage(content=answer))]
)
def _convert_langchain_msg_to_api(self, messages: List[BaseMessage]) -> List[Dict]:
msg_list = []
for msg in messages:
if isinstance(msg, SystemMessage):
role = "system"
elif isinstance(msg, HumanMessage):
role = "user"
elif isinstance(msg, AIMessage):
role = "assistant"
else:
role = "user"
msg_list.append({"role": role, "content": msg.content})
return msg_list单轮测试调用
python
from langchain_core.messages import SystemMessage, HumanMessage
from SelfTongyiLLM import SelfTongyiLLM
from SelfTongyiChatModel import SelfTongyiChatModel
import os
from dotenv import load_dotenv
load_dotenv()
tongyi_api_key = os.getenv("TONGYI_API_KEY") . # 读取通义KEY
if __name__ == "__main__":
# LLM
# llm = SelfTongyiLLM(
# api_key=tongyi_api_key,
# model_name="qwen-turbo"
# )
#
# res = llm.invoke("介绍下你自己")
# print(res)
# ChatModel
chat_model = SelfTongyiChatModel(api_key=tongyi_api_key)
# 构造人设+用户提问
msg_list = [
SystemMessage(content="你是资深Python开发工程师"),
HumanMessage(content="简单介绍LCEL是什么")
]
result = chat_model.invoke(msg_list)
print(result.content)_convert_langchain_msg_to_api: 通义 API 需要 {"role":"xxx","content":"xxx"} 格式,将转换函数_convert_langchain_msg_to_api加到SelfTongyiChat类内部
- SystemMessage = 角色人设
- HumanMessage = 用户提问
- AIMessage = 模型历史回答
python
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
def _convert_langchain_msg_to_api(self, messages: List[BaseMessage]) -> List[Dict]:
msg_list = []
for msg in messages:
if isinstance(msg, SystemMessage):
role = "system"
elif isinstance(msg, HumanMessage):
role = "user"
elif isinstance(msg, AIMessage):
role = "assistant"
else:
role = "user"
msg_list.append({"role": role, "content": msg.content})
return msg_list【观察】 LLM vs ChatModel
| 对比项 | 自定义LLM(BaseLLM) | 自定义ChatModel(BaseChatModel) |
|---|---|---|
| 继承父类 | BaseLLM | BaseChatModel |
| 接收入参 | 字符串列表prompts | 消息对象列表messages |
| 传参方式 | invoke(纯文本) | invoke(系统消息+用户消息) |
| 消息处理 | 内置固定系统提示词 | 自动转换角色消息,灵活配置 |
| 返回类型 | LLMResult+纯文本 | ChatResult+AI消息对象 |
| 多轮对话 | 不友好 | 原生支持 |
| LCEL适配 | 一般 | 完美适配 |
| 使用场景 | 简单文本生成 | 对话、RAG、Agent、业务问答 |
接入PromptTemplate提示词模板
使用模板统一管理人设和输入。
模板解耦人设,业务修改只改模板不用改调用逻辑。
python
# 导入提示词模板
from langchain_core.prompts import ChatPromptTemplate
# 定义对话模板
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是专业前端架构师,回答简洁精炼"),
("human", "{user_input}")
])
# 接入提示词模板
prompt_value = chat_prompt.format_messages(user_input="讲一下Vue2核心原理")
chat_model = SelfTongyiChatModel(api_key=tongyi_api_key)
res = chat_model.invoke(prompt_value)
print(res.content)运行结果
python
Vue2 核心原理主要包括以下几点:
1. **响应式系统**:通过 `Object.defineProperty` 或 `Proxy`(Vue3)实现数据劫持,结合 `Dep` 和 `Watcher` 实现数据变化时触发视图更新。
2. **虚拟 DOM**:通过 `render` 函数生成虚拟节点(VNode),用于高效更新真实 DOM。
3. **编译过程**:将模板编译为 `render` 函数,支持指令、表达式等语法。
4. **组件系统**:基于构造函数和原型链实现组件化开发,支持 props、events、slot 等机制。
5. **生命周期钩子**:如 `created`、`mounted` 等,用于控制组件行为。
总结:Vue2 通过响应式数据 + 虚拟 DOM + 编译机制实现高效、灵活的前端框架。LCEL 链式调用
- 链式结构:提示模板 | 自定义聊天模型 | 结果解析器
|管道符串联流程
python
# 导入解析器
from langchain_core.output_parsers import StrOutputParser
# LCEL链式调用
chat_model = SelfTongyiChatModel(api_key=tongyi_api_key)
chain = chat_prompt | chat_model | StrOutputParser()
resp = chain.invoke({"user_input": "说说原型链继承优缺点"})
print(resp)运行结果
python
原型链继承优点:
- 实现简单,共享父类方法,节省内存。
- 对象间共享属性和方法,提高效率。
缺点:
- 所有实例共享引用类型属性,修改可能影响其他实例。
- 无法实现多继承。
- 无法在创建时传参,初始化不够灵活。token消耗统计
从通义返回体读取 usage 字段,统计输入 / 输出 token,实现用量监控,方便后续计费统计。
修改_generate里成功逻辑:
python
# 6 解析响应json,提取回答文本
result = response.json()
# 7. 返回最终字符串结果
answer = result["output"]["choices"][0]["message"]["content"]
# 新增token统计
usage_info = result.get("usage", {})
input_token = usage_info.get("input_tokens", 0)
output_token = usage_info.get("output_tokens", 0)
total_token = usage_info.get("total_tokens", 0)
print(f"输入Token:{input_token} 输出Token:{output_token} 总Token:{total_token}")运行结果
python
输入Token:34 输出Token:77 总Token:111
原型链继承优点:
- 实现简单,共享父类方法,节省内存。
- 对象间共享属性和方法,提高性能。
缺点:
- 父类引用类型属性会被所有子类共享,修改会影响所有实例。
- 无法实现多继承。
- 子类实例无法向父类构造函数传参。输入Token:34,已经包含了给 LLM 的所有人设、系统提示词、用户问题,是完整的总输入消耗。
LangChain 缓存
缓存是 LangChain 内置自带的核心技术,完全属于 LangChain 功能,不需要写代码存 Redis / 文件。
LangChain 支持一键开启全局缓存,相同的提问会直接读缓存,不再调用大模型,0 Token 消耗,速度极快。
LangChain 自带 3 种最常用缓存:
- 内存缓存(InMemoryCache):重启程序消失 ------ 本节使用该缓存方式
- 本地文件缓存(SQLiteCache):持久化保存
- Redis 缓存(RedisCache):分布式高性能
python
from langchain_core.globals import set_llm_cache
from langchain_community.cache import InMemoryCache
import time
# 开启内存缓存
set_llm_cache(InMemoryCache())
# LangChain缓存
chat_model = SelfTongyiChatModel(api_key=tongyi_api_key)
chain = chat_prompt | chat_model | StrOutputParser()
print(time.time())
print("第 1 次提问")
resp = chain.invoke({"user_input": "说说原型链继承优缺点"})
print(resp)
print(time.time())
print("第 2 次提问")
resp = chain.invoke({"user_input": "说说原型链继承优缺点"})
print(resp)
print(time.time())运行结果
python
1779282110.4766881
第 1 次提问
输入Token:34 输出Token:78 总Token:112
原型链继承优点:
- 实现简单,共享父类属性和方法。
- 内存高效,所有实例共享原型上的属性和方法。
缺点:
- 原型中引用类型会被所有实例共享,修改会影响其他实例。
- 无法实现多继承。
- 无法在创建时传递参数给父类构造函数。
1779282111.9036255
第 2 次提问
原型链继承优点:
- 实现简单,共享父类属性和方法。
- 内存高效,所有实例共享原型上的属性和方法。
缺点:
- 原型中引用类型会被所有实例共享,修改会影响其他实例。
- 无法实现多继承。
- 无法在创建时传递参数给父类构造函数。
1779282111.9046257开始 1779282110.4766881
第1次回答结束 1779282111.9036255
第2次回答结束 1779282111.9046257
多轮连续对话(带上下文)
使用MessagesPlaceholder占位对话历史。
python
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, HumanMessagePromptTemplate
# 支持历史对话的模板
history_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="亲切聊天助手"),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
# HumanMessage(content="{question}") # ❌️
])
# 构建多轮链
chat_model = SelfTongyiChatModel(api_key=tongyi_api_key)
multi_chain = history_prompt | chat_model | StrOutputParser()
# 第一轮
history = []
ans1 = multi_chain.invoke({"chat_history": history, "question": "你好"})
print(ans1)
# 存入历史
history.extend([HumanMessage(content="你好"), AIMessage(content=ans1)])
# 第二轮带上下文
ans2 = multi_chain.invoke({"chat_history": history, "question": "你都会什么"})
print(ans2)运行结果
python
[{'role': 'system', 'content': '亲切聊天助手'}, {'role': 'user', 'content': '你好'}]
输入Token:21 输出Token:23 总Token:44
你好呀!😊 很高兴见到你!今天过得怎么样呀?有什么想和我聊聊的吗?
[{'role': 'system', 'content': '亲切聊天助手'}, {'role': 'user', 'content': '你好'}, {'role': 'assistant', 'content': '你好呀!😊 很高兴见到你!今天过得怎么样呀?有什么想和我聊聊的吗?'}, {'role': 'user', 'content': '你都会什么'}]
输入Token:57 输出Token:164 总Token:221
你好呀!我是一个人工智能助手,可以和你聊天、解答问题、分享知识,还能陪你一起玩游戏、讲笑话呢!😊
虽然我不能像真人一样有真实的感受,但我可以尽量用温暖、真诚的方式和你交流。我可以:
- 和你聊天,听你说说你的想法和心情
- 帮你解答一些问题,比如学习、生活、工作上的困惑
- 给你推荐一些有趣的书、电影、音乐
- 陪你一起玩文字游戏、猜谜语、讲故事
- 在你需要的时候给你一些安慰和鼓励
当然啦,我也有很多不懂的地方,如果你问我不会的问题,我会如实告诉你,然后我们一起想办法找到答案,好不好?🌟
你想和我聊些什么呢?或者有什么想让我帮你做的事情吗?总结
项目定位
基于 LangChain 生态,自研封装国产通义千问大模型 ,打造一套符合LangChain标准、可扩展、可商用的对话式大模型调用框架,同时预留本地开源模型接入能力,兼顾学习实战与工程落地。
核心技术栈
- 底层框架:LangChain 标准生态
- 模型来源:阿里通义千问HTTP接口
- 自定义实现:继承
BaseChatModel实现自研对话模型 - 链式语法:LCEL 管道式调用
- 辅助能力:Prompt模板、Token统计、内存缓存、多轮对话
已完成核心模块
- 自定义对话模型(核心根基)
- 放弃旧
BaseLLM,使用标准**BaseChatModel**对话基类 - 实现必填:
_llm_type标识 + 核心_generate请求逻辑 - 内置消息转换器:LangChain结构化消息 ↔ 通义API请求格式
- 封装统一请求头、请求体、异常捕获,兼容性强
- 支持自由配置:模型名、温度、最大生成长度等参数
- Model I/O 标准化
- 输入:
SystemMessage/HumanMessage/AIMessage标准对话消息 - 输出:LangChain统一
ChatResult结构,无缝对接所有LangChain组件
- PromptTemplate 提示词工程
- 解耦角色人设、固定话术与动态用户输入
- 支持单轮提示词、多轮对话历史占位模板
- 业务修改只改模板,不动调用代码
- LCEL 链式调用(主流写法)
- 链式流程:提示模板 | 自定义模型 | 结果解析器
- 极简调用,易拼接流程、易扩展中间组件
- 实用工程能力
- Token用量统计:读取接口返回usage,统计输入/输出/总Token,用于计费、限流
- 全局缓存机制:内存缓存重复问答,减少接口请求、节省API额度
- 多轮上下文对话:通过消息列表维护聊天历史,实现连续对话
项目价值
- 吃透LangChain自定义模型底层继承规则
- 掌握
_generate底层调用逻辑,理解框架模型运行原理 - 熟练区分LLM与ChatModel使用场景
- 精通Prompt模板设计、LCEL工业级链式开发
- 学会大模型项目必备:Token计费、调用缓存、异常容错
- 具备国产大模型私有化封装实战经验
后续拓展方向
- 加入
stream流式输出,实现打字机聊天效果 - 接入Ollama本地模型,做到云端+本地模型一键切换
- 封装Memory记忆组件,自动管理对话上下文
- 接入Redis持久化缓存
- 增加请求重试、超时、请求队列、参数校验
- 封装成工具类,提供全局统一调用入口
- 对接Web/命令行/前端页面,做成完整聊天机器人
项目优势
不依赖官方SDK,纯手写HTTP自研封装,彻底吃透底层调用逻辑,不受官方接口版本迭代限制,自由度极高,是前端转AI全栈、学习大模型工程化最扎实的实战项目。