一、理论基础:为什么基础向量检索不够好?
1.1 基础向量检索的核心痛点
第 4 天实现的基础向量检索(也叫单阶段检索)虽然简单易用,但存在三个致命缺陷,导致工业级场景下回答准确率通常只有 60%-70%:
缺陷 1:语义相似度≠相关性
向量检索计算的是文本之间的语义相似度,但语义相似不等于对用户问题有用。
- 示例:用户问 "如何安装 Python?"
- 向量检索可能会召回 "Python 是一种编程语言"、"Python 的历史" 等语义相似但完全不相关的内容
缺陷 2:分块粒度矛盾
基础检索面临无法调和的分块粒度矛盾:
- 分块太小:丢失上下文信息,检索到的片段无法独立回答问题
- 分块太大:包含太多无关信息,稀释核心内容,增加大模型处理成本
缺陷 3:用户查询表达不完整
用户的查询通常是口语化、不完整的,无法准确表达真实需求:
- "它怎么用?"(指代不明)
- "RAG 好吗?"(过于宽泛)
- "这个错误怎么解决?"(没有提供错误信息)
1.2 工业级解决方案:两阶段检索架构
为了解决上述问题,工业界普遍采用 **"粗召回 + 精排序" 的两阶段检索架构 **:
用户查询 → 粗召回(向量检索) → Top-K候选集(20-50个) → 精排序(重排序模型) → Top-N最终结果(3-5个) → 大模型生成
- 粗召回阶段:使用向量数据库快速召回大量语义相关的候选文档(追求高召回率)
- 精排序阶段:使用更强大的交叉编码器模型对候选集进行精确打分排序(追求高精度)
这种架构兼顾了速度 和精度:
- 向量检索速度快,可以在毫秒级从百万级数据中召回候选集
- 重排序模型虽然速度慢,但只需要处理几十条候选数据,整体延迟可控
1.3 检索效果评估指标
要量化检索效果,必须掌握三个核心指标:
| 指标 | 定义 | 计算公式 | 说明 |
|---|---|---|---|
| 召回率(Recall) | 检索到的相关文档占所有相关文档的比例 | 召回率 = 检索到的相关文档数 / 总相关文档数 | 衡量 "有没有漏掉有用的信息",越高越好 |
| 精确率(Precision) | 检索到的文档中相关文档的比例 | 精确率 = 检索到的相关文档数 / 检索到的总文档数 | 衡量 "有没有混入没用的信息",越高越好 |
| F1 分数 | 召回率和精确率的调和平均数 | F1 = 2 * (精确率 * 召回率) / (精确率 + 召回率) | 综合衡量检索效果,越高越好 |
基础向量检索的问题:召回率高但精确率低,通常召回率能达到 80%-90%,但精确率只有 30%-50%。
重排序的作用:在几乎不损失召回率的前提下,将精确率提升至 80%-90%。
二、核心技术 1:重排序(Reranking)
2.1 重排序的工作原理
重排序模型使用 ** 交叉编码器(Cross-Encoder)架构,与向量检索使用的双编码器(Bi-Encoder)** 架构有本质区别:
| 架构 | 工作方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 双编码器(Bi-Encoder) | 分别对查询和文档进行编码,然后计算相似度 | 速度极快,可预计算向量 | 精度较低 | 粗召回阶段 |
| 交叉编码器(Cross-Encoder) | 将查询和文档拼接在一起输入模型,直接输出相关性分数 | 精度极高 | 速度慢,无法预计算 | 精排序阶段 |
交叉编码器的优势:它可以同时看到查询和文档的完整上下文,能够捕捉到更细粒度的语义匹配关系,比如否定词、指代关系、逻辑关系等。
2.2 主流重排序模型对比
2026 年工业界最常用的中文重排序模型:
| 模型 | 开发者 | 参数量 | 中文效果 | 速度 | 适用场景 |
|---|---|---|---|---|---|
| bge-reranker-v2-m3 | 智源研究院 | 560M | ⭐⭐⭐⭐⭐ | 中等 | 通用场景(首选) |
| bge-reranker-v2-base | 智源研究院 | 110M | ⭐⭐⭐⭐ | 快 | 对速度要求高的场景 |
| bge-reranker-v2-large | 智源研究院 | 330M | ⭐⭐⭐⭐⭐ | 慢 | 对精度要求极高的场景 |
| m3e-reranker | MokaAI | 110M | ⭐⭐⭐⭐ | 快 | 轻量级场景 |
推荐使用 :bge-reranker-v2-m3,综合效果最好,是目前中文重排序的工业标准。
2.3 LangChain 2026 重排序 API 详解
LangChain 提供了统一的重排序接口CrossEncoderReranker,支持所有主流重排序模型。
基本用法
python
from langchain_huggingface import HuggingFaceCrossEncoder
from langchain_core.documents import Document
# 初始化重排序器(自动从HuggingFace下载模型)
reranker = HuggingFaceCrossEncoder(
model_name="BAAI/bge-reranker-v2-m3",
model_kwargs={"device": "cpu"}, # 有GPU改为"cuda"
max_length=512 # 最大输入长度
)
# 模拟检索到的候选文档
documents = [
Document(page_content="Python是一种解释型、面向对象的编程语言"),
Document(page_content="安装Python的步骤:1. 下载安装包;2. 运行安装程序;3. 配置环境变量"),
Document(page_content="Python的创始人是吉多·范罗苏姆"),
Document(page_content="Python支持多种编程范式,包括过程式、面向对象和函数式编程")
]
# 重排序
reranked_docs = reranker.compress_documents(
documents=documents,
query="如何安装Python?"
)
# 输出结果
print("重排序后的结果:")
for i, doc in enumerate(reranked_docs):
print(f"{i+1}. 分数:{doc.metadata['relevance_score']:.4f},内容:{doc.page_content}")带阈值过滤的重排序
python
def rerank_with_threshold(reranker, documents, query, threshold=0.5):
"""重排序并过滤掉分数低于阈值的文档"""
reranked_docs = reranker.compress_documents(documents, query)
# 过滤低分数文档
filtered_docs = [
doc for doc in reranked_docs
if doc.metadata["relevance_score"] >= threshold
]
return filtered_docs三、核心技术 2:高级检索策略
重排序解决了精确率的问题,而高级检索策略则解决了分块粒度矛盾和用户查询表达不完整的问题。
3.1 策略 1:多查询生成(Multi-Query Generation)
原理
将用户的单个查询生成 3-5 个不同角度、不同表达方式的查询,分别进行检索,然后合并所有结果并去重。
解决的问题:用户查询表达不清晰、不完整、有歧义。
实现示例
python
from langchain_core.prompts import ChatPromptTemplate
from core.llm_factory import LLMFactory
# 多查询生成提示模板
multi_query_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个AI助手,你的任务是根据用户的原始查询,生成3个不同角度的查询语句。
要求:
1. 每个查询都要表达原始查询的核心需求
2. 从不同的角度和表达方式生成
3. 只输出查询语句,不要添加任何其他内容
4. 每个查询占一行"""),
("human", "原始查询:{query}\n生成的查询:")
])
# 创建链
llm = LLMFactory.get_llm()
multi_query_chain = multi_query_prompt | llm
# 生成多查询
query = "RAG好吗?"
response = multi_query_chain.invoke({"query": query})
queries = [line.strip() for line in response.content.split("\n") if line.strip()]
print("原始查询:", query)
print("生成的查询:", queries)输出示例:
原始查询: RAG好吗?
生成的查询: 'RAG技术有哪些优势?', 'RAG技术的缺点是什么?', 'RAG技术适合哪些场景?'
检索流程
python
def multi_query_retrieval(retriever, query, top_k=3):
"""多查询检索"""
# 1. 生成多查询
response = multi_query_chain.invoke({"query": query})
queries = [line.strip() for line in response.content.split("\n") if line.strip()]
queries.append(query) # 保留原始查询
# 2. 分别检索
all_docs = []
for q in queries:
docs = retriever.retrieve(q, top_k=top_k)
all_docs.extend(docs)
# 3. 去重
seen_ids = set()
unique_docs = []
for doc in all_docs:
doc_id = doc.metadata.get("chunk_id", doc.page_content)
if doc_id not in seen_ids:
seen_ids.add(doc_id)
unique_docs.append(doc)
return unique_docs3.2 策略 2:查询重写(Query Rewriting)
原理
将用户的口语化、不完整、有歧义的查询重写为清晰、准确、适合检索的专业查询。
解决的问题:用户查询口语化、指代不明、过于简短。
实现示例
python
# 查询重写提示模板
rewrite_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个查询优化专家,将用户的原始查询重写为更适合搜索引擎的查询语句。
要求:
1. 保留原始查询的所有核心信息
2. 补充缺失的上下文,明确指代关系
3. 使用更规范、更专业的术语
4. 只输出重写后的查询,不要添加任何其他内容"""),
("human", "原始查询:{query}\n重写后的查询:")
])
rewrite_chain = rewrite_prompt | llm
# 测试
query = "它怎么用?"
# 假设上下文是之前的对话:"什么是RAG技术?"
context = "之前的对话:用户问了什么是RAG技术"
response = rewrite_chain.invoke({"query": query + "\n上下文:" + context})
print("原始查询:", query)
print("重写后的查询:", response.content)输出示例:
原始查询: 它怎么用?
重写后的查询: RAG技术的使用方法是什么?
3.3 策略 3:句子窗口检索(Sentence Window Retrieval)
原理
将文档按句子分块进行检索,检索到最相关的句子后,扩展该句子前后 N 个句子的上下文,然后将扩展后的上下文喂给大模型。
解决的问题:分块太小丢失上下文信息。
实现示例
python
def sentence_window_retrieval(retriever, query, window_size=2):
"""句子窗口检索"""
# 1. 按句子分块检索
sentence_chunks = retriever.retrieve(query, top_k=3)
# 2. 扩展上下文
expanded_docs = []
for sentence_chunk in sentence_chunks:
# 获取该句子在原始文档中的位置
chunk_index = sentence_chunk.metadata["chunk_index"]
total_chunks = sentence_chunk.metadata["total_chunks"]
# 计算窗口范围
start = max(0, chunk_index - window_size)
end = min(total_chunks, chunk_index + window_size + 1)
# 加载该文档的所有句子分块
# (实际项目中需要从数据库或缓存中加载)
all_sentences = load_all_sentences(sentence_chunk.metadata["source"])
# 拼接上下文
expanded_content = " ".join([all_sentences[i].page_content for i in range(start, end)])
# 创建扩展后的文档
expanded_doc = Document(
page_content=expanded_content,
metadata={
**sentence_chunk.metadata,
"window_start": start,
"window_end": end,
"original_sentence": sentence_chunk.page_content
}
)
expanded_docs.append(expanded_doc)
return expanded_docs3.4 策略 4:父子分块检索(Parent-Document Retrieval)
原理
将文档分成两种粒度的分块:
- 子分块:小粒度(100-200 字符),用于检索,保证检索精度
- 父分块:大粒度(500-1000 字符),包含多个子分块,用于生成,保证上下文完整
检索时先找到最相关的子分块,然后返回对应的父分块给大模型。
解决的问题:分块粒度矛盾,兼顾检索精度和上下文完整性。
实现示例
python
def create_parent_child_chunks(documents, child_chunk_size=150, parent_chunk_size=600):
"""创建父子分块"""
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=parent_chunk_size, chunk_overlap=50)
child_splitter = RecursiveCharacterTextSplitter(chunk_size=child_chunk_size, chunk_overlap=20)
all_child_chunks = []
for parent_doc in parent_splitter.split_documents(documents):
# 生成父分块ID
parent_id = f"parent_{hash(parent_doc.page_content)}"
parent_doc.metadata["parent_id"] = parent_id
# 生成子分块
child_chunks = child_splitter.split_documents([parent_doc])
for child_chunk in child_chunks:
child_chunk.metadata["parent_id"] = parent_id
child_chunk.metadata["parent_content"] = parent_doc.page_content
all_child_chunks.append(child_chunk)
return all_child_chunks
def parent_child_retrieval(retriever, query, top_k=3):
"""父子分块检索"""
# 1. 检索子分块
child_chunks = retriever.retrieve(query, top_k=top_k)
# 2. 返回对应的父分块
parent_docs = []
seen_parent_ids = set()
for child_chunk in child_chunks:
parent_id = child_chunk.metadata["parent_id"]
if parent_id not in seen_parent_ids:
seen_parent_ids.add(parent_id)
parent_doc = Document(
page_content=child_chunk.metadata["parent_content"],
metadata=child_chunk.metadata
)
parent_docs.append(parent_doc)
return parent_docs四、项目代码应用
4.1 本地重排序器 core/reranker.py
完全本地、不走 HuggingFace 下载
python
from typing import List
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from langchain_core.documents import Document
from config.settings import settings
from utils.logger import logger
from utils.exceptions import RerankerError
class Reranker:
"""本地 bge-reranker-v2-m3 重排序(适配 settings)"""
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._init_reranker()
return cls._instance
def _init_reranker(self):
"""从 settings 读取本地路径"""
self.enabled = getattr(settings, "reranker_enabled", True)
self.model_path = settings.reranker_model_path
self.device = settings.embedding_device
if not self.enabled:
logger.info("重排序已关闭")
self.tokenizer = None
self.model = None
return
try:
logger.info(f"加载本地重排序:{self.model_path}")
self.tokenizer = AutoTokenizer.from_pretrained(self.model_path)
self.model = AutoModelForSequenceClassification.from_pretrained(self.model_path)
self.model.eval().to(self.device)
logger.info("✅ 本地重排序加载成功")
except Exception as e:
logger.error(f"重排序加载失败:{e}")
self.enabled = False
def score(self, query: str, text: str) -> float:
"""计算相似度分数 0~1"""
if not self.enabled:
return 0.5
try:
inputs = self.tokenizer(
[[query, text]],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
).to(self.device)
with torch.no_grad():
logits = self.model(**inputs).logits
score = torch.sigmoid(logits[0][0]).item()
return score
except:
return 0.5
def rerank(self, query: str, docs: List[Document] = None, top_n: int = 3, threshold: float = 0.4, documents: List[Document] = None) -> List[Document]:
"""重排序 + 过滤"""
if not self.enabled or not docs:
return docs[:top_n]
scored = []
for doc in docs:
s = self.score(query, doc.page_content)
doc.metadata["rerank_score"] = s
scored.append((doc, s))
# 排序、过滤、取前N
scored.sort(key=lambda x: x[1], reverse=True)
filtered = [d for d, s in scored if s >= threshold]
return filtered[:top_n]4.2 高级检索策略 core/rag_retriever.py
python
from typing import List, Optional
from langchain_core.documents import Document
from langchain_core.vectorstores import VectorStore
from core.vector_store_factory import VectorStoreFactory
from core.document_processor import DocumentProcessor
from config.settings import settings
from utils.logger import logger
from utils.exceptions import RetrievalError
from core.reranker import Reranker
from core.llm_factory import LLMFactory
from langchain_core.prompts import ChatPromptTemplate
class RAGRetriever:
"""RAG检索器,封装文档处理、向量检索、查询重写、多查询生成、本地重排序"""
def __init__(
self,
vector_store: Optional[VectorStore] = None,
document_processor: Optional[DocumentProcessor] = None
):
self.vector_store = vector_store or VectorStoreFactory.get_vector_store()
self.document_processor = document_processor or DocumentProcessor()
self.reranker = Reranker()
self.llm = LLMFactory.get_llm()
logger.info("✅ RAG检索器初始化完成")
# ---------- 查询重写 ----------
def rewrite_query(self, query: str) -> str:
"""查询重写:把用户口语化查询改写成适合检索的正式查询"""
prompt = ChatPromptTemplate.from_messages([
("system", "你是查询改写助手。用户给你一个查询,请直接输出改写后的查询,不要追问,不要解释,只输出查询结果。"),
("human", "原始查询:{query}")
])
chain = prompt | self.llm
return chain.invoke({"query": query}).content.strip()
# ---------- 多查询生成 ----------
def generate_multi_queries(self, query: str) -> List[str]:
"""多查询生成:生成3个角度不同、语义相关的查询"""
prompt = ChatPromptTemplate.from_messages([
("system", "你是查询生成助手。根据原始查询生成3个语义相近、角度不同的查询,每行一个,不要追问,不要解释。"),
("human", "原始查询:{query}")
])
chain = prompt | self.llm
res = chain.invoke({"query": query}).content.strip()
return [q.strip() for q in res.splitlines() if q.strip()] + [query]
def add_document(self, file_path: str) -> int:
"""
添加单个文档到向量数据库
:param file_path: 文档路径
:return: 添加的分块数量
"""
try:
logger.info(f"添加文档到知识库:{file_path}")
# 处理文档
chunks = self.document_processor.process_file(file_path)
if not chunks:
logger.warning(f"文档{file_path}没有有效内容")
return 0
# 添加到向量数据库
self.vector_store.add_documents(chunks)
logger.info(f"✅ 文档添加成功,共添加{len(chunks)}个分块")
# 如果是FAISS,保存索引
if settings.vector_store_type == "faiss":
VectorStoreFactory.save_faiss_index(self.vector_store)
return len(chunks)
except Exception as e:
raise RetrievalError(f"添加文档失败:{str(e)}") from e
def add_directory(self, dir_path: str, recursive: bool = False) -> int:
"""
批量添加目录下的所有文档
:param dir_path: 目录路径
:param recursive: 是否递归处理子目录
:return: 添加的总分块数量
"""
try:
logger.info(f"批量添加目录到知识库:{dir_path}")
chunks = self.document_processor.process_directory(dir_path, recursive)
if not chunks:
logger.warning(f"目录{dir_path}没有有效文档")
return 0
# 批量添加到向量数据库
self.vector_store.add_documents(chunks)
logger.info(f"✅ 批量添加成功,共添加{len(chunks)}个分块")
# 如果是FAISS,保存索引
if settings.vector_store_type == "faiss":
VectorStoreFactory.save_faiss_index(self.vector_store)
return len(chunks)
except Exception as e:
raise RetrievalError(f"批量添加文档失败:{str(e)}") from e
def retrieve(
self,
query: str,
top_k: int = None,
similarity_threshold: float = None,
filter: dict = None
) -> List[Document]:
"""
检索相关文档: 高级版检索:查询重写 → 多查询 → 向量召回 → 过滤 → 本地重排序
:param query: 用户查询
:param top_k: 返回结果数量,默认使用settings配置
:param similarity_threshold: 相似度阈值,默认使用settings配置
:param filter: 元数据过滤条件
:return: 相关文档列表
"""
try:
top_k = top_k or settings.retrieval_top_k
similarity_threshold = similarity_threshold or settings.retrieval_similarity_threshold
# ===================== 查询重写 =====================
rewritten_query = self.rewrite_query(query)
logger.info(f"查询重写:{query} → {rewritten_query}")
# ===================== 多查询生成 =====================
queries = self.generate_multi_queries(rewritten_query)
logger.debug(f"生成多查询:{queries}")
# ===================== 向量粗召回(从每个查询召回10条) =====================
all_docs = []
for q in queries:
results_with_scores = self.vector_store.similarity_search_with_score(
query=q,
k=10,
filter=filter
)
for doc, score in results_with_scores:
similarity = max(0.0, 1.0 - score / 2.0)
doc.metadata["similarity_score"] = similarity
all_docs.append(doc)
# ===================== 去重 =====================
unique_docs = []
seen_content = set()
for doc in all_docs:
key = doc.page_content.strip()[:150]
if key not in seen_content:
seen_content.add(key)
unique_docs.append(doc)
# ===================== 基础阈值过滤 =====================
filtered = [d for d in unique_docs if d.metadata["similarity_score"] >= similarity_threshold]
# ===================== 第5天:本地重排序(核心升级) =====================
# 如果过滤后没有文档,直接使用去重后的文档
docs_to_rerank = filtered if filtered else unique_docs
final_docs = self.reranker.rerank(
query=rewritten_query,
docs=docs_to_rerank,
top_n=top_k,
threshold=0.3 # 降低阈值
)
logger.info(f"检索完成:原始={len(all_docs)} → 去重={len(unique_docs)} → 过滤={len(filtered)} → 最终={len(final_docs)}")
return final_docs
except Exception as e:
raise RetrievalError(f"检索失败:{str(e)}") from e
def get_document_count(self) -> int:
"""获取向量数据库中的文档数量"""
try:
return self.vector_store._collection.count()
except:
# FAISS不支持直接获取数量,返回-1
return -1
def clear_knowledge_base(self):
"""清空知识库"""
try:
VectorStoreFactory.delete_collection()
# 重新初始化向量存储
self.vector_store = VectorStoreFactory.get_vector_store()
logger.info("✅ 知识库已清空")
except Exception as e:
raise RetrievalError(f"清空知识库失败:{str(e)}") from e4.3 测试
python
from dotenv import load_dotenv
load_dotenv()
from core.rag_service import RAGService
from core.document_processor import DocumentProcessor
from core.vector_store_factory import VectorStoreFactory
import os
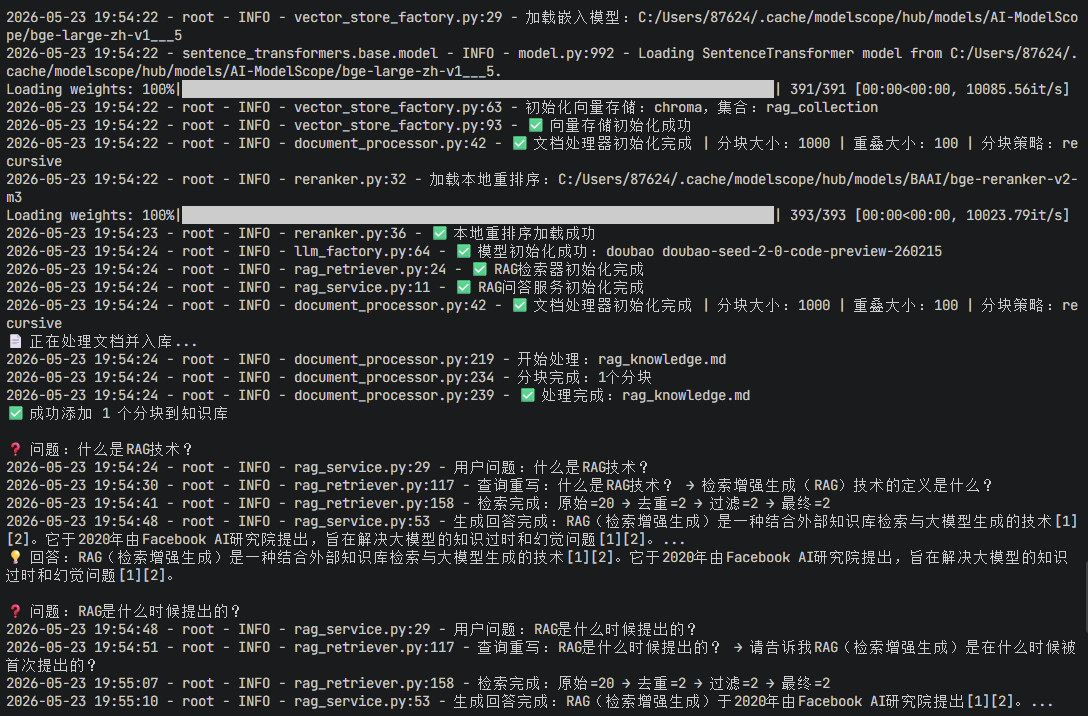
def test_day5_advanced_rag():
print("🚀 第5天:本地重排序 + 高级检索测试\n")
# 初始化服务
rag = RAGService()
proc = DocumentProcessor()
vs = VectorStoreFactory.get_vector_store()
# 准备测试文档(存到 data 目录)
doc_text = """
RAG(检索增强生成)是一种结合外部知识库检索与大模型生成的技术。
2020年由Facebook AI研究院提出,旨在解决大模型的知识过时和幻觉问题。
RAG系统的工作流程分为三个核心步骤:
1. 文档处理:将原始文档切割成小块,转换为向量存储到向量数据库
2. 检索:根据用户查询,从向量数据库中检索最相关的文档片段
3. 生成:将检索到的文档片段和用户查询一起喂给大模型,生成回答
RAG的核心优势:
- 知识实时更新:不需要重新训练模型,只需更新知识库
- 减少幻觉:回答基于真实的文档内容
- 可解释性:可以追溯回答的来源
- 成本低:比微调大模型便宜很多
"""
# 保存测试文档
os.makedirs("data", exist_ok=True)
test_file_path = os.path.join("data", "rag_knowledge.md")
with open(test_file_path, "w", encoding="utf-8") as f:
f.write(doc_text)
# 处理并添加到知识库
print("📄 正在处理文档并入库...")
chunks = proc.process_file(test_file_path)
vs.add_documents(chunks)
print(f"✅ 成功添加 {len(chunks)} 个分块到知识库\n")
# 测试问答
test_questions = [
"什么是RAG技术?",
"RAG是什么时候提出的?",
"RAG的工作流程是什么?",
"RAG有哪些优势?"
]
for q in test_questions:
print(f"❓ 问题:{q}")
answer = rag.query(q)
print(f"💡 回答:{answer}\n")
if __name__ == "__main__":
test_day5_advanced_rag()