OLTP的三个范式
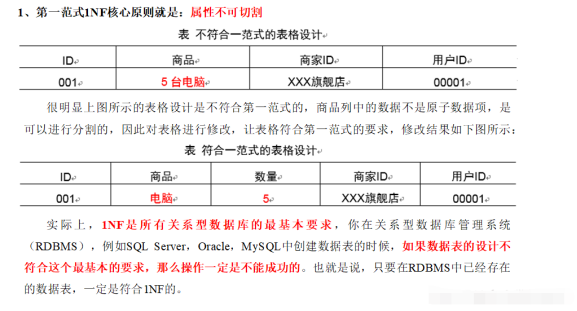
-1-第一范式 1NF 数据原子性(不可分割性)
-2-第二范式(2NF) "消除部分函数依赖"
它要求在第一范式(1NF,即数据原子性)的基础上,确保表中的所有非主属性(字段)必须完全依赖于整个主键(所有的主键),而不能只依赖于主键的一部分。
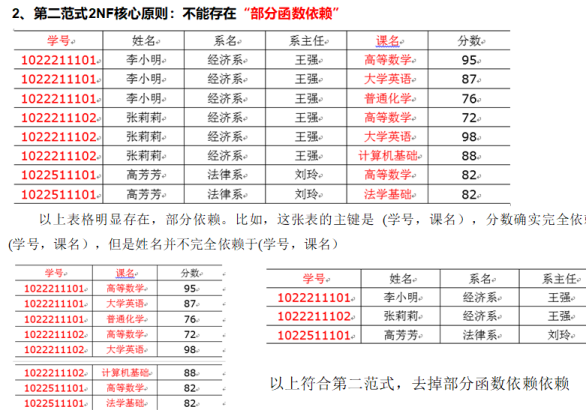
姓名以及 姓名、系名、系主任这个组合只依赖于学号这个主键,与课程名无关。毕竟,学生姓名不会因为选了什么课就跟着变吧?
因此把上面这一个表拆成两个表
-3-第三范式 不能存在传递函数依赖
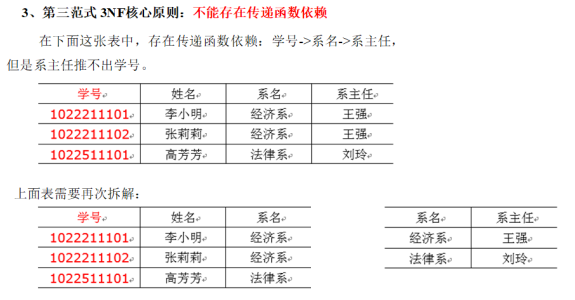
这里第一个table系名依赖于学号,但是系主任是直接依赖于系名,而不是依赖于学号的。存在学号->系名->系主任的传递性依赖,也就是说所以的非主键列,只能依赖于主键 学号,不能依赖于 主键 学号 之外的其他非主键列 如系名
官方定义
一个关系模式满足2NF,且所有非主属性都不传递依赖于任何候选键。
人话解释
-
表中的每一列都要直接依赖于主键,不能依赖于其他非主键列
比如在这里系主任这一列,依赖于系名这个非主键列。因为这样一种情况:学生学号不同,但是系主任的名字相同。这是因为系主任是谁,取决于系名是什么,而不是学号一变系主任就变了。
-
消除字段间的传递依赖关系
-
目标是:一个字段只描述一个实体的一种属性
第三范式广泛使用于OLTP事务型数据库,是因为以下几个理由
-
无数据冗余
------系主任这一列不需要在多个表上显示,只在系名-系主任这个table上显示。避免了系主任这一列重复记录在多个表上,减少了数据存储的浪费。
-
更新只需修改一处
------因为每个表内部的非主键都不存在依赖关系。比如系主任换了,只需要修改 系名-系主任 这一张表。
-
适合频繁增删改的OLTP系统
------增删改这些对数据进行 增 减 修改只动一个表,而不是多个表,速度更快。
缺点:
- 查询需要多表连接,性能差
------所以在OLAP数据库,为了减少多表连接,直接将常用的列拼在一起,组成一个大宽表
- 不适合分析型查询
OLTP的设计要点
减少每个表上的数据冗余,让每个表格上的列尽可能的少(第二范式,所有数据必须完全依赖于所有的主键,不依赖于所有主键的列全部移除;不依赖于主键的列 找到他们的主键,单独建表 ;第三范式:有传递性依赖的拿出去单独建表)
让增删改操作涉及的表尽可能的少,甚至只涉及一张表。从而提升增删改查的性能。
三、银行数仓:故意违反3NF!
在数仓中,我们反其道而行之 ,使用维度建模,故意引入"冗余":
银行数仓的典型设计(星型模型)
sql
-- 事实表:交易事实(存储业务过程度量值)
CREATE TABLE fact_transactions (
tx_id BIGINT,
tx_date_key INT, -- 日期维度代理键
tx_time_key INT, -- 时间维度代理键
account_key INT, -- 账户维度代理键
branch_key INT, -- 支行维度代理键
customer_key INT, -- 客户维度代理键
product_key INT, -- 产品维度代理键
channel_key INT, -- 渠道维度代理键
-- 度量值(数值型)
amount DECIMAL(15,2),
fee DECIMAL(10,2),
balance_after DECIMAL(15,2),
-- 退化维度(为了减少连接)
tx_type VARCHAR(10), -- 直接冗余,避免连接维度表
tx_status VARCHAR(10)
) PARTITIONED BY (dt STRING);
-- 维度表:客户维度(违反3NF!包含大量冗余信息)
CREATE TABLE dim_customer (
customer_key INT PRIMARY KEY,
-- 自然键
cust_id VARCHAR(20),
-- 客户基本信息(层次关系,违反3NF)
cust_name VARCHAR(100),
cust_type VARCHAR(20), -- 个人/企业
-- 人口统计信息(可单独成表,但冗余在此)
age INT,
gender CHAR(1),
education VARCHAR(50),
occupation VARCHAR(50),
income_level VARCHAR(20),
-- 联系信息(可单独成表,但冗余在此)
mobile VARCHAR(11),
email VARCHAR(100),
address VARCHAR(200),
city VARCHAR(50),
province VARCHAR(50),
zip_code VARCHAR(10),
-- 风险信息
risk_level CHAR(1),
credit_score INT,
-- 时间信息
create_date DATE,
update_date DATE,
is_current BOOLEAN, -- SCD Type 2标记
start_date DATE,
end_date DATE
);
s
-- 维度表:支行维度(包含地理层级信息)
CREATE TABLE dim_branch (
branch_key INT PRIMARY KEY,
branch_code VARCHAR(10),
branch_name VARCHAR(100),
-- 地理层级(违反3NF!本应分开存储)
branch_level VARCHAR(20), -- 总行/分行/支行/网点
parent_branch VARCHAR(10), -- 上级机构代码
region VARCHAR(50), -- 大区
province VARCHAR(50),
city VARCHAR(50),
address VARCHAR(200),
manager VARCHAR(50),
-- 业绩属性
branch_type VARCHAR(20), -- 对公/对私/综合
employee_count INT,
aum_total DECIMAL(18,2) -- 管理资产总额
);四、为什么银行数仓要违反3NF?
核心原因:更新性能 vs 查询性能
| 考虑维度 | OLTP核心系统(3NF) | 数仓(反范式化) |
|---|---|---|
| 主要操作 | 大量INSERT/UPDATE/DELETE | 大量SELECT查询 |
| 性能关键 | 写性能、数据一致性 | 读性能、查询速度 |
| 数据规模 | GB~TB级,当前数据 | TB~PB级,历史数据 |
| 典型查询 | 按主键查询单条记录 | 多维度聚合、复杂连接 |
| 用户数量 | 数千银行柜员 | 数百分析师/决策者 |
sql
-- 场景:分析各支行2024年1月的交易情况
-- 3NF方式(需要5表连接)
SELECT
b.branch_name,
c.province,
EXTRACT(MONTH FROM t.tx_date) as month,
SUM(t.amount) as total_amount,
COUNT(*) as tx_count
FROM transactions t
JOIN accounts a ON t.account_no = a.account_no
JOIN branches b ON a.branch_code = b.branch_code
JOIN branch_hierarchy h ON b.branch_code = h.branch_code
JOIN cities c ON b.city_id = c.city_id
WHERE t.tx_date BETWEEN '2024-01-01' AND '2024-01-31'
GROUP BY b.branch_name, c.province, EXTRACT(MONTH FROM t.tx_date);
-- 数仓星型模型(只需2表连接,且维度表小)
SELECT
b.branch_name,
b.province, -- 直接取自维度表,无需连接城市表
d.month,
SUM(f.amount) as total_amount,
COUNT(*) as tx_count
FROM fact_transactions f
JOIN dim_branch b ON f.branch_key = b.branch_key
JOIN dim_date d ON f.tx_date_key = d.date_key
WHERE d.year_month = '202401' -- 分区剪裁
GROUP BY b.branch_name, b.province, d.month;性能差异:
-
3NF查询:5次表连接,全表扫描,可能需要分钟级
-
数仓查询:2次连接,分区剪裁,秒级响应
二、详细技术原因分析
1. 连接数量大幅减少
-
3NF模型:需要5表连接
-
transactions → accounts → branches → branch_hierarchy → cities -
每个连接都是开销,复杂度O(n²)级别
-
-
星型模型:只需2表连接
-
fact_transactions → dim_branch和fact_transactions → dim_date -
连接路径简单直接
-
关系建模与维度建模
关系建模
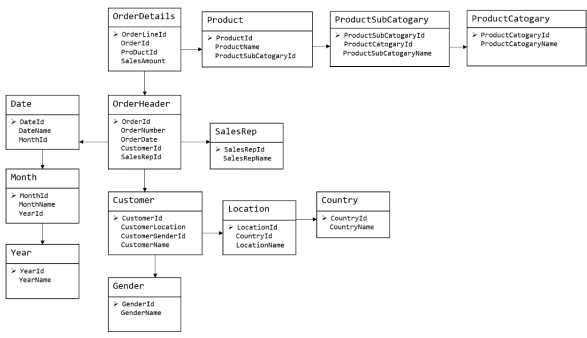
关系模型如图所示,严格遵循第三范式(3NF),从图中可以看出,较为松散、零碎,物理表数量多,而数据冗余程度低。由于数据分布于众多的表中,这些数据可以更为灵活地被应用,功能性较强。关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统(OLTP)的表都是遵循第三范式的。
你听到"关系建模"时,可以把它等同于ER建模/三范式建模。它的特点是大表拆小表,强调数据一致性,主要用于ODS层或传统数仓的核心层
维度建模
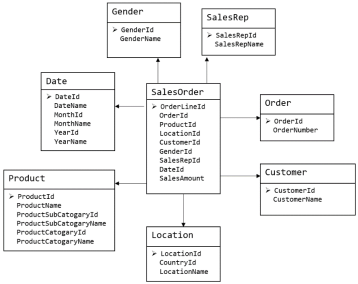
维度模型如图所示,主要应用于OLAP系统中,通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以通常我们采用维度模型建模,把相关各种表整理成两种:事实表 和维度表两种。
上图中
-
✅ 中间的表 = 事实表(Fact Table) :记录银行发生的业务过程/事件
-
✅ 周围的表 = 维度表(Dimension Table) :描述事实的上下文信息
交易业务的星型模型的具象化示例
sql
-- 事实表:交易事实(中间)
CREATE TABLE fact_transactions (
-- 代理键(主键)
transaction_sk BIGINT PRIMARY KEY,
-- 外键(指向各个维度表)
transaction_date_key INT, -- 指向 dim_date
transaction_time_key INT, -- 指向 dim_time
account_key INT, -- 指向 dim_account
customer_key INT, -- 指向 dim_customer
branch_key INT, -- 指向 dim_branch
product_key INT, -- 指向 dim_product
channel_key INT, -- 指向 dim_channel
counterparty_key INT, -- 指向 dim_counterparty
-- 度量值(数值型,可聚合)
amount DECIMAL(15,2), -- 交易金额
fee DECIMAL(10,2), -- 手续费
balance_after DECIMAL(15,2), -- 交易后余额
-- 退化维度(避免连接小型维度表)
transaction_type VARCHAR(10), -- 交易类型:存款/取款/转账
currency VARCHAR(3), -- 币种:CNY/USD
status VARCHAR(10) -- 状态:成功/失败/冲正
);
-- 维度表:账户维度(周围)
CREATE TABLE dim_account (
account_sk INT PRIMARY KEY, -- 代理键
account_no VARCHAR(20), -- 自然键(业务键)
account_name VARCHAR(100),
account_type VARCHAR(20), -- 储蓄/支票/信用卡
currency VARCHAR(3),
open_date DATE,
close_date DATE,
status VARCHAR(10), -- 正常/冻结/销户
-- 其他描述属性...
);
-- 维度表:客户维度(周围)
CREATE TABLE dim_customer (
customer_sk INT PRIMARY KEY,
cust_id VARCHAR(20),
cust_name VARCHAR(100),
cust_type VARCHAR(10), -- 个人/企业
risk_level CHAR(1),
credit_rating VARCHAR(10),
-- 其他描述属性...
);具体怎么连接的?join起来
sql
-- 最常见的分析查询:连接事实表和维度表
SELECT
-- 从维度表获取描述性信息
da.account_no,
da.account_name,
da.account_type,
-- 从事实表获取度量值
SUM(ft.amount) AS total_amount,
COUNT(*) AS transaction_count
FROM fact_transactions ft
-- 关键连接:通过代理键关联
JOIN dim_account da ON ft.account_key = da.account_sk
WHERE ft.transaction_date_key BETWEEN 20240101 AND 20240131
GROUP BY da.account_no, da.account_name, da.account_type;- 连接的可视化表示
sql
事实表 (fact_transactions) 维度表 (dim_account)
+----------------------+ +----------------------+
| transaction_sk (PK) | | account_sk (PK) |
|----------------------| |----------------------|
| account_key (FK)----+---------->| account_sk |
| customer_key (FK) | | account_no (NK) |
| branch_key (FK) | | account_name |
| | | account_type |
| amount | | currency |
| fee | | open_date |
+----------------------+ +----------------------+
│ │
└───────── JOIN ON ──────────────┘
ft.account_key = da.account_sk维度建模的三种类型
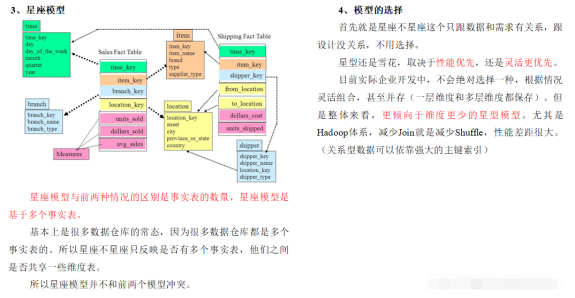
除了维度建模和ER建模,还有什么建模方法?
在银行和企业级数仓建设中,除了前两者,以下两种建模方法也非常重要(尤其是第一种):
A. Data Vault 建模(数据仓库建模的"集大成者")
这是目前在大银行、金融、保险等超大型企业中非常流行的一种建模方法,由 Dan Linstedt 提出。你可以把它理解为 ER建模 + 维度建模 的混合体。
- 核心思想:
- 它吸取了ER建模(3NF)的灵活性(应对业务变化)。
- 它吸取了维度建模的易用性 和历史追踪能力。
- 结构组成(三剑客):
- Hub(中心表): 只存业务主键(如客户号、账号)。相当于事物的"身份证"。
- Link(链接表): 记录关系(如客户和账户的关系)。相当于"关系网"。
- Satellite(卫星表): 记录描述性属性(如客户姓名、地址)。所有的历史变化都在这里保存,不覆盖。
- 为什么银行喜欢它?
- 银行业务经常变(改监管、改产品),Data Vault 不需要修改核心结构,只需要加新的 Satellite 表。
- 审计要求极高,Data Vault 完美记录了所有数据的历史变迁(谁在什么时候把余额从100改成了200)。
B. Anchor 建模(锚点建模)
这是一种比 Data Vault 更激进、更"极客"的高度规范化的建模方法,也是基于关系模型的,但规范到了第六范式(6NF)。
- 核心思想:
- 把数据拆解到极致。所有属性(如客户姓名、性别、电话)都会被拆成独立的表,甚至每个属性的历史变动都单独存一行。
- 只有"锚点"(主键)和"属性"(键值对)。
- 特点:
- 优点: 极其灵活,扩展性无敌,存储成本相对较低(因为稀疏数据少)。
- 缺点: 查询性能极差,需要Join几十张表才能拼出一个人,太复杂,一般只有极少数特殊场景使用。
C. Graph 建模(图建模)
这在银行反欺诈 和风控领域是必不可少的。
- 核心思想:
- 数据不是表,而是**"点"** (Node)和**"边"**(Edge)。
- 点:人、设备、手机号、银行卡。
- 边:转账、通话、共享设备。
- 应用场景:
- 不用来做报表,而是用来挖掘团伙。例如:"发现这3个人虽然看起来没关系,但他们都在同一个时间段使用了同一个IP地址登录,并且互相转过账"------这是ER表和维度表很难查出来的。
3. 总结:四大建模门派对比
为了帮你理清思路,我们将这四种主流方法放在一起对比:
| 建模方法 | 别名/核心 | 规范程度 | 核心特点 | 在银行数仓中的典型位置 |
|---|---|---|---|---|
| ER建模 | 关系建模、三范式 | 高 (3NF) | 数据高度一致,冗余低,表多关联多 | ODS层、传统数仓核心层 |
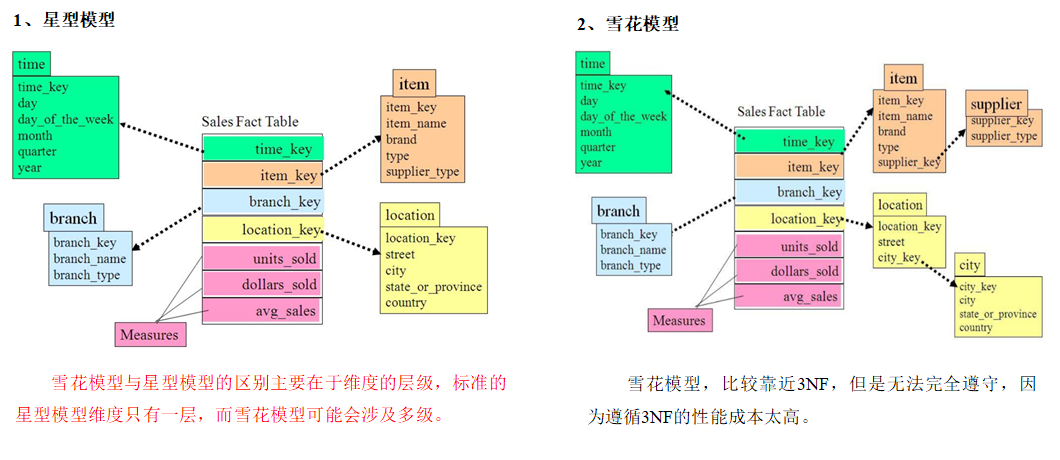
| 维度建模 | 星型/雪花模型 | 低 (反范式) | 查询快,易于理解,适合BI分析 | DWD/DWS/ADS层、现代数仓主流 |
| Data Vault | 数据金库 | 中高 (混合) | 可追踪历史,极强的业务适应性,Hub/Link/Sat结构 | 企业级EDW层(作为中间层,连接ODS和ADS) |
| Graph建模 | 图数据库 | N/A | 点和边,擅长查关系 | 风控/反欺诈专用库 |
4. 给你的建议
既然你在关注银行数仓:
- 基石: 必须精通 维度建模(Kimball),这是吃饭的家伙,90%的日常开发都是基于它。
- 理解: 必须懂 ER建模,因为它是源头系统的逻辑,不懂数据就无法清洗。
- 关注: 了解 Data Vault。如果你去的大型银行(特别是外资银行或正在做数字化转型的大行),他们可能会在EDW(企业数据仓库)层引入Data Vault来解决数据整合和历史审计的难题。
一句话总结:
关系建模就是ER建模;除了它们,还有Data Vault(专门解决历史和灵活性问题)和Graph建模(专门解决关联关系问题)。
银行典型的事实表类型
| 事实表类型 | 对应业务过程 | 粒度 | 示例度量值 |
|---|---|---|---|
| 交易事实表 | 每笔金融交易 | 单笔交易 | 金额、手续费、余额 |
| 余额快照事实表 | 每日账户余额 | 每个账户每天 | 余额、可用额度 |
| 流水事实表 | 账户变动流水 | 每次余额变动 | 变动金额、变动后余额 |
| 授信事实表 | 贷款发放 | 每笔贷款 | 贷款金额、利率、期限 |
| 还款事实表 | 贷款偿还 | 每次还款 | 还款金额、本金、利息 |
什么是缓慢变化维?(Slowly Changing Dimension, SCD)
缓慢变化维(Slowly Changing Dimension, SCD) 是数据仓库建模中的一个核心概念,用于处理维度表中属性随时间缓慢变化的问题。
在业务系统中,很多维度信息会随着时间推移而改变(比如客户地址、产品类别、员工部门等),但这些变化通常不是频繁发生的,因此称为"缓慢变化"。
而在数据仓库中,我们不仅关心当前状态,更需要保留历史变化信息(比如记录银行客户登录交易地的ip,查看客户是不是快速移动,做反欺诈预警),以支持准确的历史分析和趋势追踪。
举个例子 🌰
假设有一个客户维度表:
| customer_id | name | city |
|---|---|---|
| 101 | 张三 | 北京 |
2024年,张三从"北京"搬到了"上海"。
如果直接更新 city = '上海',那么之前所有与"北京"相关的销售记录在回溯时就会错误地关联到"上海"------历史事实被篡改了。
这就引出了 SCD 的不同处理策略。
SCD 的常见类型
✅ 类型1:覆盖(Overwrite / No History)
- 做法:直接用新值覆盖旧值。
- 特点:不保留历史,维度表始终只反映最新状态。
- 适用场景:不需要历史追溯的属性(如邮箱拼写错误修正;比如修改密码后,过去的旧密码旧没必要保存了)。
- 缺点:破坏历史准确性。
示例:
UPDATE dim_customer SET city='上海' WHERE customer_id=101;
✅ 类型2:新增行(Add New Row / Full History)
- 做法 :
- 保留旧行(标记为非当前);
- 插入一行新记录(标记为当前);
- 通常增加字段:
start_date,end_date,is_current或version。
- 特点:完整保留历史变化,支持任意时间点的准确查询。
- 适用场景:关键业务属性(如客户所属区域、产品分类)。
- 缺点:维度表膨胀,ETL 逻辑复杂。
sql
customer_id | name | city | start_date | end_date | is_current
101 | 张三 | 北京 | 2020-01-01 | 2024-06-30 | N
101 | 张三 | 上海 | 2024-07-01 | 9999-12-31 | Y✅ 类型3:新增列(Add New Column / Limited History)
- 做法 :
- 在同一行中增加"旧值"列(如
city_old); - 当前值存在
city,上一次值存在city_old。
- 在同一行中增加"旧值"列(如
- 特点:仅保留最近两次状态,节省空间。
- 缺点:无法追踪多次变化,扩展性差。
- 适用场景:极少变化且只需对比最近两次的场景。
sql
customer_id | name | city | city_previous | change_date
101 | 张三 | 上海 | 北京 | 2024-07-01其他变体(高级用法)
- 类型4:使用微型维度(Mini-dimension)
将频繁变化的属性拆到单独的小维度表中,主维度保持稳定。 - 类型6:混合模式(Combination of Type 1+2+3)
同时支持当前值、历史行、以及快速查询字段。
如何选择 SCD 类型
| 需求 | 推荐类型 |
|---|---|
| 不需要历史 | Type 1 |
| 必须完整保留历史 | Type 2(最常用) |
| 只需对比最近一次变化 | Type 3 |
| 属性变化非常频繁 | Type 4(微型维度) |
总结
缓慢变化维(SCD)的本质是:在数据仓库中如何优雅地处理维度属性的历史变化,以平衡"数据准确性"、"查询性能"和"存储成本"。
在实际项目中,Type 2 是最主流的选择,尤其在金融、零售等对历史追溯要求高的行业。现代数据仓库工具(如 dbt、Informatica、DataStage)都内置了 SCD Type 2 的自动化处理逻辑。
什么是ER建模?
在银行数据仓库的建设过程中,ER建模(Entity-Relationship Modeling,实体关系建模)是一种从业务视角出发,对数据进行高度抽象和结构化设计的方法论。
简单来说,ER建模就是用图形化的方式描述银行内部业务对象(如"客户"、"账户"、"交易")之间是如何关联的。它通常遵循三范式(3NF)的原则,旨在消除数据冗余,保证数据的一致性和准确性。
以下是关于银行数仓中ER建模的详细解析:
1. 核心概念:三个基本要素
ER模型主要由三个部分组成,这三个部分在银行业务中都有具体的对应:
实体 : 客观存在的对象。
*银行例子:* 客户、个人、对公客户、银行卡、信贷账户、理财产品、网点、柜员。
属性 : 实体所具有的特征。
*银行例子:* 客户实体的属性包括"客户号"、"姓名"、"身份证号"、"信用评级"。
关系 : 实体之间的联系。
*银行例子:* 客户与账户之间是"持有"关系(1:N);客户与产品之间是"购买"关系;主卡与附属卡之间是"归属"关系。
2. 银行为什么要用ER建模? (价值与意义)
在数仓建设(尤其是贴源层ODS或明细数据层DWD)中,ER建模至关重要,原因如下:
复杂数据关系的梳理: 银行业务极其复杂,涉及存贷汇、理财、风控等多个条线。ER模型能理清像"一个客户持有多个账户,一个账户下有多笔交易"这种网状关系。
数据一致性保障(消除冗余): 遵循三范式设计,确保"客户姓名"只在一个地方存储,避免了数据更新时出现"张三"和"李四"并存的不一致情况。
应对业务变更的灵活性: 银行业务经常调整(如推出新卡种、新的计息规则)。结构良好的ER模型(解耦的设计)使得底层表结构更容易扩展,而不需要重写上层应用。
数据资产的沉淀: ER建模构建的是企业级的数据模型,它不局限于某一个具体的报表,而是将数据作为一种长期的资产沉淀下来。
3. ER建模在数仓架构中的位置
在现代银行数据仓库的分层架构中,ER建模主要应用于底层:
ODS层 (操作数据存储层): 几乎是对源系统业务表结构的镜像,本身就是高度规范化的ER模型。
DWD层 (明细数据层): ++在这一层,通常会基于ER建模的理念,进行微调、整合和清洗++ ,形成企业级的主题域模型。例如,将核心系统、信贷系统、信用卡系统中的"客户"数据整合成一张统一的客户表。(具体是怎么做的ER模型?)
4. 银行ER建模的经典案例(主题划分)
银行在进行ER建模时,通常会将庞大的业务拆分为若干个主题域。以下是典型的银行ER模型主题划分:
当事人主题: 涉及个人、对公客户、客户关系、员工等。
*关键实体:* 客户、客户地址、职业信息。
产品主题: 银行销售的东西。
*关键实体:* 存款产品、贷款产品、基金产品、费率信息。
协议/事件主题: 客户与银行达成的契约及产生的动作。
*关键实体:* 账户、借贷合同、存取款交易记录、转账流水。
渠道主题: 业务发生的场所。
*关键实体:* 网点、ATM机、手机银行App、柜员。
地理/公共主题: 外部参考数据。
*关键实体:* 行政区划、行业分类代码。
5. ER建模 vs. 维度建模
理解ER建模,必须将其与维度建模进行对比。在银行数仓中,两者通常是结合使用的:
| 特性 | ER建模 (实体关系) | 维度建模 (Dimensional) |
|---|---|---|
| 核心原则 | 三范式 (3NF),高度规范化,消除冗余 | 星型模型/雪花模型,反规范化,允许冗余 |
| 关注点 | 数据的产生源头,业务逻辑的完整性,数据质量 | 数据的分析应用,查询性能,用户理解便利性 |
| 主要位置 | 数仓底层 (ODS/DWD) | 数仓上层 (DWS/ADS) |
| 优缺点 | 优点: 数据一致性好,冗余低; 缺点: 查询慢,需要大量Join,分析师看不懂。 | 优点: 查询极快,适合BI报表; 缺点: 数据冗余大,存储成本相对高。 |
| 比喻 | 零件仓库:螺丝、螺母分类摆放,整齐严谨。 | 组装好的工具包:为了方便使用,把常用的螺丝和螺丝刀打包在一起。 |
- 总结
在银行数仓建设中,ER建模是地基。
它通过三范式的方法,将银行业务中错综复杂的"客户、产品、账户、交易"关系梳理得井井有条,确保了底层数据的准确性、一致性和可扩展性。虽然终端分析师直接使用的是基于维度建模的报表,但这些报表的数据质量完全依赖于底层ER建模的扎实程度。
请具体举例说明以下DWD层是如何用ER建模来组织的?
明确回答:
在银行数仓的DWD层,主要采用的方法论是"维度建模",而不是ER建模。
虽然ER建模(三范式)在理解业务逻辑时不可或缺,但在现代银行数仓(尤其是基于Hadoop/Spark/MPP等大数据平台)的物理落地中,DWD层几乎全部是按照维度建模的思想来构建的 ,即构建**"事实表"** 和**"维度表"**。
1. 为什么DWD层主要用"维度建模"?
早期的传统银行数仓(基于Oracle/Teradata一体机)常常在DWD层使用ER建模(三范式),但在大数据时代,这种做法被淘汰了,原因有三:
-
查询性能(核心原因):
- ER模型 关联关系极其复杂(如一个交易可能要关联10张表才能查全信息)。在大数据平台上进行大量的
Join操作会严重拖慢计算速度,甚至导致任务超时。 - 维度模型(如星型模型)通过构建"大宽表"或减少关联层级,大大提升了DWD层到DWS/ADS层的计算效率。
- ER模型 关联关系极其复杂(如一个交易可能要关联10张表才能查全信息)。在大数据平台上进行大量的
-
易用性:
- 数据开发人员(ETL工程师)和分析师更习惯看"事实"(发生了什么)和"维度"(谁、何时、何地),而不是复杂的抽象实体关系网。
-
OneData理论体系:
- 目前国内银行(如建行、工行、招行及各大农商行)在建数仓时,普遍参考阿里巴巴的OneData 体系。该体系明确规定:DWD层是以"业务过程"为构建核心,构建原子事实表。
2. DWD层的维度建模具体长什么样?
在维度建模视角下,DWD层不再是零散的"实体表",而是组织为事实表 和维度表。
① 原子事实表
DWD层的核心是原子事实表。它记录业务过程的最细粒度行为。
- 定义原则: 每一行对应一个具体的业务动作,且不可再分。
- 银行例子:
DWD_F_ACCT_TRANS(账户转账事实表)DWD_F_LOAN_APPLY(贷款申请事实表)DWD_F_CUST_LOGIN(手机银行登录事实表)
② 维度表
维度表是事实表的"环境说明"。在DWD层,维度表通常被拆分出来单独维护,以供复用。
- 银行例子:
DWD_DIM_CUSTOMER(客户维度表)DWD_DIM_ORG(机构/网点维度表)DWD_DIM_DATE(日期维度表)
3. 既然用维度建模,那ER建模在DWD阶段就没用了吗?
有用,但位置变了。
ER建模在DWD阶段并没有消失,它隐含在两个地方:
-
逻辑设计阶段(画图):
在建DWD表之前,架构师依然会用ER图来梳理业务关系(比如:必须先理解"客户"和"账户"是1对多关系,才能设计出事实表里的外键)。ER图是用来理清思路的,但落地的物理表结构是维度模型。
-
维度表内部(雪花模型):
在DWD层的维度表中,有时为了节省存储或保持数据一致性,依然会保留部分三范式(ER)结构。
- 例子:
DWD_DIM_CUSTOMER(客户表)里可能不会直接存"所属网点名称",而是存ORG_ID(机构ID)。当你需要"网点名称"时,再去关联DWD_DIM_ORG。这种"大圈套小圈"的雪花模型,本质上就是ER建模思想在维度表里的残留。
- 例子:
4. 总结对比:银行DWD层的两种建模风格
为了让你彻底明白,我们对比一下"传统派"和"现代派"在DWD层的做法:
| 特性 | 传统银行数仓 (Teradata/Oracle 旧架构) | 现代银行数仓 (Hadoop/MaxCompute 新架构 - 主流) |
|---|---|---|
| DWD建模方法 | ER建模 (三范式) | 维度建模 (星型/雪花模型) |
| 表结构特征 | 高度拆分,几十张关联表 | 事实表 + 独立维度表 (部分大宽表) |
| 数据冗余 | 极低,无冗余 | 适当冗余 (为了性能,如日期维度重复存储) |
| 开发难度 | SQL写起来很痛苦,大量Join | 相对简单,便于聚合统计 |
| 典型命名 | E_CUSTOMER, R_ACCT_CUST (实体/关系) |
DWD_F_TRANS_LOG, DWD_DIM_CUST (事实/维度) |
结论
在今天的银行数仓面试或实际工作中,如果问到DWD层:
- 它主要做什么? 数据清洗、规范化、构建一致性维度 、构建原子事实表。
- 用什么建模? 维度建模。
- ER建模在哪? 在ODS层(贴源层)作为镜像存在,或者在DWD层的逻辑设计阶段作为分析工具存在,但DWD层的物理实现是基于维度建模的。
什么是维度表?什么是事实表?
维度表 :一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
维表的特征:
- 维表的范围很宽(具有多个属性、列比较多)
- 跟事实表相比,行数相对较小:通常< 10万条
- 内容相对固定:编码表
时间维度表:
|------------|-------------|-------------|----|-----|
| 日期ID | day of week | day of year | 季度 | 节假日 |
| 2020-01-01 | 2 | 1 | 1 | 元旦 |
| 2020-01-02 | 3 | 2 | 1 | 无 |
| 2020-01-03 | 4 | 3 | 1 | 无 |
| 2020-01-04 | 5 | 4 | 1 | 无 |
| 2020-01-05 | 6 | 5 | 1 | 无 |
事实表中的 每行数据代表一个业务事件 ( 下单、支付、退款、评价 等) 。"事实"这个术语表示的是业务事件的度量值( 可统计次数、个数、件数、金额 等),例如,订单事件中的下单金额。
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键、通常具有两个和两个以上的外键、外键之间表示维表之间多对多的关系。
事实表的特征:
- 非常的大
- 内容相对的窄:列数较少
经常发生变化,每天会新增加很多。
1)事务型事实表
以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量。
2)周期型快照事实表
周期型快照事实表中不会保留所有数据 ,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。
3)累积型快照事实表
累计快照事实表用于 跟踪业务事实的变化 ****。****例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。
数据仓库为什么要分层?
