在前一篇SqlAlchemy基本功能介绍的文章中,介绍了SqlAlchemy的同步阻塞IO的使用方法,当时因为不了解python的asyncio运行机制,所以就没有介绍异步IO的使用方法,但如果在高并发场景下,使用阻塞IO的话,每一个连接,都需要一个线程的支持,无法解决C10K问题。异步IO,使用协程,在仅需一个线程的情况下就能支持高并发连接操作,这个知识点很重要,所以后面找时间补上了python的asyncio的知识点,然后把SqlAlchemy的异步IO官方文档读了一遍,把重要的知识点整理了一下。异步IO的知识点众多,没办法面面俱到的整理,如果想了解完整的实现细节,可以看一下SQLAlchemy异步IO官方文档
异步版本的API,基本都是使用代理模式对传统阻塞IO对应API的封装,依赖greenlet技术将阻塞IO包装为异步IO,所以在使用SqlAlchemy异步API时如果报错了,很多错误中都会出现greenlet的字样,出处就在这里。
既然python官方有原生的asyncio,功能很完善,为啥SqlAlchemy还要引入三方库来实现异步IO呢?
这是因为SqlAlchemy的核心代码是2005年写的,内部很复杂,如果使用python原生的asyncio对传统阻塞IO代码进行重写,工作量会很大,风险极高,所以官方就想出了这种折中的办法,不改动核心的阻塞IO逻辑,通过引入三方依赖greenlet来实现异步IO,当业务调用异步API时,通过greenlet将核心逻辑中的阻塞IO包装成可awaitable的代码,从而避免阻塞异步环境中的事件循环
文章目录
- 1、SQLAlchemy异步IO使用准备
- 2、SQLAlchemy异步IO使用案例
- 3、AsyncEngine
-
- 3.1、基本使用方法
- [3.2、AsyncEngine API](#3.2、AsyncEngine API)
- 4、AsyncSessionMaker
- 5、AsyncConnection
- 6、AsyncSession
- 7、ResultSetAPI
- 8、AsyncScopedSession
- 9、异步IO事件使用
- 10、异步IO使用注意事项
1、SQLAlchemy异步IO使用准备
1.1、安装依赖
上面提到,异步IO需要依赖greenlet,所以安装SQLAlchemy异步IO的相关依赖时,需要安装greenlet,以下安装方式会同步安装SQLAlchemy异步IO,greenlet以及其他依赖
python
# mac版本需要加个单引号,其他版本如果安装报错,可以去掉单引号
pip install 'sqlalchemy[asyncio]'1.2、使用对应的异步驱动
在使用异步IO操作数据库前,要注意安装对应数据库的异步版本驱动,比如:
mysql:asyncmy
pg:asyncpg
sqlite:aiosqlite
我只是举了3个例子,其他类型的数据库,也要注意找一下异步版本的驱动,否则运行会报错,比如:
python
sqlalchemy.exc.InvalidRequestError: The asyncio extension requires an async driver to be used. The loaded 'pymysql' is not async2、SQLAlchemy异步IO使用案例
SQLAlchemy的异步IO,操作类型和阻塞IO一样,也是分为Core方式和ORM方式
2.1、Core方式
使用AsyncConnection对象发起IO操作,就是Core方式,对应阻塞IO中Connection对象发起的IO操作
下面举了一个Core方式的例子,相比于阻塞IO,有5个变化。
(1)、方法级别的AsyncEngine,使用后需要手动关闭连AsyncEngine ,await engine.dispose()
(2)、方法体使用async修饰
(3)、在发生IO的地方,使用await修饰
(4)、with上下文块使用async with替代
(5)、最外层使用asyncio.run启动事件循环
python
meta = MetaData()
t1 = Table("t1", meta, Column("name", String(50), primary_key=True))
async def async_main() -> None:
engine = create_async_engine("sqlite+aiosqlite://", echo=True)
......
async with engine.connect() as conn:
# select a Result, which will be delivered with buffered
# results
result = await conn.execute(select(t1).where(t1.c.name == "some name 1"))
print(result.fetchall())
# for AsyncEngine created in function scope, close and
# clean-up pooled connections
await engine.dispose()
asyncio.run(async_main())2.2、ORM方式
使用AsyncSession对象发起IO操作,就是ORM方式,对应于阻塞IO的Session操作。
Session不能在多线程中共享,同样,AsyncSession对象也不能在并发多协程任务中共享,每个协程任务需要一个独立的AsyncSession对象
相比于阻塞IO中的Session,AsyncSession和AsyncConnection差不多,也需要用async修饰方法体,在发生IO的地方用await修饰
python
async def main():
async_engine=create_async_engine("mysql+asyncmy://root:111111@127.0.0.1:3337/async_sqlalchemy", echo=True)
AsyncSessionMaker = async_sessionmaker(async_engine,expire_after_commit=False)
async with AsyncSessionMaker() as session:
tb_a = await session.scalars(select(TBA).where(TBA.id > 0))
print(tb_a.all())
await async_engine.dispose()3、AsyncEngine
AsyncEngine也是对阻塞IO的Engine的一个封装,使用方式基本差不多
3.1、基本使用方法
python
from sqlalchemy.ext.asyncio import create_async_engine
engine = create_async_engine("postgresql+asyncpg://user:pass@host/dbname")
# 通过async_engine手动获取一个AsyncConnection对象,并开始事务。
# 除此之外也可以使用async_engine.connect()方法来获取AsyncConnection对象,但是手动管理事务
async with async_engine.begin() as conn:
await conn.execute(
text("insert into table (x, y, z) values (1, 2, 3)")
)
await conn.execute(text("my_special_procedure(5)"))3.2、AsyncEngine API
AsyncEngine有很多API,就不一一介绍了,具体可以看这个链接
其他API
4、AsyncSessionMaker
4.1、基本使用
python
# 构建async_session_maker
AsyncSession = async_sessionmaker(async_engine, expire_on_commit=False)
# 使用async_session_maker生产session
session = AsyncSession()和同步版本的session_maker作用是一样的,都是session工厂,根据传入的配置生产session
4.2、创建一个新Session并且自动开启事务
python
async def main():
Session = async_sessionmaker(some_engine)
async with Session.begin() as session:
session.add(some_object)
# commits transaction, closes session4.3、configure方法
创建好AsyncSessionMaker的情况下,通过configure可以重新配置AsyncSessionMaker
python
AsyncSession = async_sessionmaker(some_engine)
AsyncSession.configure(bind=create_async_engine("sqlite+aiosqlite://"))5、AsyncConnection
看着和Connection的使用方法差不多,只不过要使用异步版本而已,这一节介绍几个不好理解的API,其他的如果想了解,可以看下AsyncConnection官方文档
5.1、基本使用方法
python
from sqlalchemy.ext.asyncio import create_async_engine
engine = create_async_engine("postgresql+asyncpg://user:pass@host/dbname")
async with engine.connect() as conn:
result = await conn.execute(select(table))5.2、stream方法
流式查询使用方式
python
result = await conn.stream(stmt)
async for row in result:
print(f"{row}")这个方法的作用就是当我们机器的内存有限,但是表数据行很多时,可以考虑使用这个方法,这个API的实现方式是在服务端维护了一个游标,然后逐行从数据库拉取数据。所以即使你的表有上亿行数据,内存中实际在处理的也只有一行,很适合大数据量的处理,但是显而易见,表里有上亿行数据时,一行一行的拉取,势必会长时间的占用连接,这就是我们平时经常说的要避免的大事务场景,要注意这一点。
我没有使用过这个stream方法,感觉这种方式,还不如分页来的简单,并且也不是所有数据库都很好的支持这个流式查询,pg支持的很完整,mysql需要单独开一些配置才能使用,还有很多数据库不支持
目前不知道有啥场景用这个API比较好,发现了,再回来补充。
5.3、sync_connection方法
获取AsyncConnection代理的阻塞Connection对象
都已经用上异步IO了,为啥还提供了一个获取同步connection对象的方法呢?
这是因为,在异步IO的事件处理器里面,没有异步IO,使用的还是同步的IO代码,所以需要能够通过AsyncConnection获取到同步的Connection,详见第9章节
5.4、run_sync方法
有一些API,SQLAlchemy没有提供异步版本,此时这类API如果在异步环境中使用,就会阻塞事件循环。SQLAlchemy就提供了一个run_sync方法,来解决这个问题
比如下面的这个例子,获取元信息的inspector方法,是没有异步版本的,此时可以使用AsyncConnection的run_sync方法将inspector方法包裹起来即可。
python
import asyncio
from sqlalchemy import inspect
from sqlalchemy.ext.asyncio import create_async_engine
engine = create_async_engine("postgresql+asyncpg://scott:tiger@localhost/test")
def use_inspector(conn):
inspector = inspect(conn)
# use the inspector
print(inspector.get_view_names())
# return any value to the caller
return inspector.get_table_names()
async def async_main():
async with engine.connect() as conn:
tables = await conn.run_sync(use_inspector)
asyncio.run(async_main())run_sync方法的内部同样用到了greenlet技术,将同步操作await,防止阻塞事件循环。
源码是这样的
python
return await greenlet_spawn(
fn, self.sync_session, *arg, _require_await=False, **kw
)run_sync实现的功能和gevent事件驱动库实现的功能类似,区别点是:前者是内置的,后者需要引入三方库,另外在实现机制上也有区别,前者底层是事件循环,后者是用了python的猴子补丁技术,劫持IO操作,将同步操作转awaitable。
在介绍到run_sync这个方法时,文档中是专门提了一下,这个API是违背SQLAlchemy异步IO设计哲学的,为什么这么说呢?
run_sync方法相当于是将很多IO方法打包执行,而不是SQLAlchemy推荐的在每一个IO处进行await,所以说run_sync是违背异步IO设计哲学的。设计这个API,也是因为有一些API无法支持awaitable,历史原因。
run_sync方法最经典的使用场景如下,是创建表结构
python
# run metadata.create_all(conn) with a sync-style Connection,
# proxied into an awaitable
with async_engine.begin() as conn:
await conn.run_sync(metadata.create_all)另外有一个点需要特别注意下,不要啥都往run_sync方法中扔,如果是HTTP请求或者文件读写操作,不要用这个方法,因为在线程中发起HTTP请求或者文件读写操作,此时发生IO阻塞时,OS会将当前线程直接挂起,这个线程是整个事件循环共用的线程,如果被挂起,整个事件循环都会阻塞在这个调用处。此时要使用asyncio.to_thread() 或loop.run_in_executor()来执行HTTP请求或者文件读写操作,也就是多线程技术,遇到Http请求或者文件操作,新开一个线程处理,事件循环的线程立即返回,此时就不会发生阻塞。
这里提供的两种线程执行API,asyncio.to_thread()是3.9+使用,是基于对 loop.run_in_executor()的封装。前者用的更多一点
6、AsyncSession
AsyncSession是对Session的代理,底层操作还是基于Session,比如AsyncSession的commit操作,底层源码如下:
python
async def commit(self) -> None:
await greenlet_spawn(self.sync_session.commit)6.1、基本使用
python
async def main():
AsyncSessionMaker = async_sessionmaker(expire_after_commit=False)
async with AsyncSessionMaker() as session:
print(type(session))
pg_like = PGLike(id=1,
name='测试',
age=34)
session.add(pg_like)
await session.commit()6.2、get_bind方法
多库环境可以覆盖Session的get_bind方法来让业务侧无感切换数据库,比如下面的这个例子。
(1)、当操作对象类型是PGLike类型时,走other库
(2)、当操作类型是insert、update或者delete等写入操作时,走leader库
(3)、查询操作,随机走follower1库或者follower2库
python
import asyncio
from sqlalchemy import Update, Delete, select
from sqlalchemy.ext.asyncio import async_sessionmaker
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.orm import Session
from bean.user_bean import PGLike, TBA
# construct async engines w/ async drivers
engines = {
"other": create_async_engine("postgresql+asyncpg://postgres:123456@127.0.0.1:5432/sql_test"),
"leader": create_async_engine("mysql+asyncmy://root:111111@127.0.0.1:3337/async_sqlalchemy"),
"follower1": create_async_engine("sqlite+aiosqlite:////Users/abc/personal/sqllite/follower1.db"),
"follower2": create_async_engine("sqlite+aiosqlite:////Users/abc/personal/sqllite/follower2.db"),
}
class RoutingSession(Session):
def get_bind(self, mapper=None, clause=None, **kw):
# within get_bind(), return sync engines
if mapper and issubclass(mapper.class_, PGLike):
return engines["other"].sync_engine
elif self._flushing or isinstance(clause, (Update, Delete)):
return engines["leader"].sync_engine
else:
return engines[
random.choice(["follower1", "follower2"])
].sync_engine
async def main():
# apply to AsyncSession using sync_session_class
AsyncSessionMaker = async_sessionmaker(sync_session_class=RoutingSession)
async with AsyncSessionMaker() as session:
print(type(session))
pg_like = PGLike(id=1,
name='测试',
age=34)
session.add(pg_like)
# PGLike数据类型,走other库
await session.commit()
# 查询操作,随机走follower1或者follower2库
tb_a = (await session.scalars(select(TBA).where(TBA.id == 1))).first()
# 更新操作,走leader库
tb_a.data = 'a500'
await session.commit()
if __name__ == '__main__':
asyncio.run(main())6.3、scalar、scalars、execute方法
这三个方法都是获取值的方法
总结来说,execute是返回ROW对象,这是一行值
scalar和scalars是返回某一行中某一列的数据,区别是前者只返回满足条件的其中一个值,后者返回符合条件的所有数据
python
async def main():
# apply to AsyncSession using sync_session_class
AsyncSessionMaker = async_sessionmaker(sync_session_class=RoutingSession)
async with AsyncSessionMaker() as session:
print(type(session))
# 单值:ROW对象。多值:ChunkedIteratorResult对象,使用.all方法获取全部数据
tb_a = (await session.execute(select(TBA.data).where(TBA.id == 1))).first()
print(tb_a)
# 使用scalar方式获取到第一个满足条件的数据,结果是一个单值
tb_a = (await session.scalar(select(TBA.data).where(TBA.id > 0)))
print(tb_a)
# 通过scalars获取到所有满足条件的数据,结果是ScalarResult对象,通过它的all方法获取到所有满足条件的数据
tb_a = await session.scalars(select(TBA.data).where(TBA.id > 0))
print(tb_a.all())7、ResultSetAPI
涉及到的ResultSetAPI有4种,AsyncResult、AsyncMappingResult、AsyncScalarResult、AsyncTupleResult
这个API是相对于Core方式来说的,也就是通过AsyncConnection对象查询数据,如下:
python
async def main():
async with async_engine.begin() as conn:
async with conn.stream(select(PGLike)) as result:
# 遍历result时,逐行从数据库获取数据
async for row in result:
print(row)这里的result对象就是上面提到的4种API中的一种,AsyncResult对象
例子里用到的stream方法就是我们上面提到的流式查询,当发起查询时,conn.stream会立即返回,当开始迭代result时,从数据库逐行获取
8、AsyncScopedSession
官方介绍AsyncScopedSession前,给了一段tips,如下:
SQLAlchemy generally does not recommend the "scoped" pattern for new development as it relies upon mutable global state that must also be explicitly torn down when work within the thread or task is complete. Particularly when using asyncio, it's likely a better idea to pass the AsyncSession directly to the awaitable functions that need it.
大致意思是:SQLAlchemy通常不推荐使用这种Scope类型的Session,因为它依赖可变全局状态,并且当使用完时必须要显示移除。
依赖可变全局状态,这说的是注册表机制,可以类比下java的ThreadLocal机制,我们将线程和数据进行绑定,从而实现线程本地变量,这就是注册表机制。
显式移除不用说了,就是使用完移除,否则会造成内存遗漏以及安全问题。
如果是新项目,尽量不要用这个ScopedSession,尤其是asyncio的场景,官方更推荐的方法是手动注入,如下:
python
async def get_db() -> AsyncGenerator[AsyncSession, None]:
async with AsyncSessionLocal() as db:
yield db
# 显式依赖注入
async def get_user(session: AsyncSession, user_id: int):
return await session.get(User, user_id)
# 在入口点(如 FastAPI 依赖)创建并传递,get_db是一个异步生成器,生成AsyncSession对象
async def endpoint(db: AsyncSession = Depends(get_db)):
# 来源清晰,生命周期可控
user = await get_user(db, 1) 这样看着虽然啰嗦,但是更清晰,出问题更好排查
问题来了,既然不推荐使用,那为啥还要搞这么个东西呢?
是因为有一些历史的阻塞IO代码,最开始研发的时候,就用了ScopedSession,在迁移到异步IO版本时,如果没有对等的Async版本,那团队将代码迁移到异步IO时,就要重写大量的代码,迁移风险很高,所以官方才说,如果你是新项目,那就别用了,潜台词就是:旧项目,如果必要的话可以用,但是要注意管理好AsyncScopedSession的生命周期。在使用完AsyncScopedSession后,注意将其移除,防止内存泄漏
python
async def some_function(some_async_session, some_object):
# use the AsyncSession directly
some_async_session.add(some_object)
# use the AsyncSession via the context-local proxy
await AsyncScopedSession.commit()
# "remove" the current proxied AsyncSession for the local context
await AsyncScopedSession.remove()在构建AsyncScopedSession时,有另外一个比较重要的参数要了解下,scopefunc。
scopefunc就是类似于Map结构里的key一样,通过这个scopefunc来找到对应的ScopedSession,官方给的这个例子里,用的是current_task本身
python
from asyncio import current_task
from sqlalchemy.ext.asyncio import (
async_scoped_session,
async_sessionmaker,
)
async_session_factory = async_sessionmaker(
some_async_engine,
expire_on_commit=False,
)
AsyncScopedSession = async_scoped_session(
async_session_factory,
scopefunc=current_task,
)
some_async_session = AsyncScopedSession()scopefunc函数,应该是幂等的,并且是无状态的,多次调用,行为是一致的
9、异步IO事件使用
SqlAlchemy的IO操作,允许我们监听操作节点,比如:
python
import asyncio
from sqlalchemy import event
from sqlalchemy import text
from sqlalchemy.engine import Engine
from sqlalchemy.ext.asyncio import create_async_engine, async_sessionmaker
engine = create_async_engine("mysql+asyncmy://root:111111@127.0.0.1:3337/async_sqlalchemy")
# connect event on instance of Engine
@event.listens_for(engine.sync_engine, "connect")
def my_on_connect(dbapi_con, connection_record):
print("New DBAPI connection:", dbapi_con)
cursor = dbapi_con.cursor()
# sync style API use for adapted DBAPI connection / cursor
cursor.execute("select 'execute from event'")
print(cursor.fetchone()[0])以上代码,当发生数据库连接时,my_on_connect方法会执行,在这里,我们将my_on_connect称作是事件处理器
根据官方的描述,截止目前,并没有异步版本的事件API
python
The SQLAlchemy event system is not directly exposed by the asyncio extension, meaning there is not yet an "async" version of a SQLAlchemy event handler.异步环境下的事件处理器代码看着和阻塞IO的是一样的,如下:
python
import asyncio
from sqlalchemy import event
from sqlalchemy import text
from sqlalchemy.engine import Engine
from sqlalchemy.ext.asyncio import create_async_engine
engine = create_async_engine("postgresql+asyncpg://scott:tiger@localhost:5432/test")
# connect event on instance of Engine
@event.listens_for(engine.sync_engine, "connect")
def my_on_connect(dbapi_con, connection_record):
print("New DBAPI connection:", dbapi_con)
cursor = dbapi_con.cursor()
# sync style API use for adapted DBAPI connection / cursor
cursor.execute("select 'execute from event'")
print(cursor.fetchone()[0])
# before_execute event on all Engine instances
@event.listens_for(Engine, "before_execute")
def my_before_execute(
conn,
clauseelement,
multiparams,
params,
execution_options,
):
print("before execute!")
async def go():
async with engine.connect() as conn:
await conn.execute(text("select 1"))
await engine.dispose()
asyncio.run(go())我们知道,在异步环境下的IO操作需要被await修饰,否则会报错。那事件处理器里的数据库操作是同步阻塞操作,并没有报错,这是怎么实现的呢?
官方文档给了一个异步IO的执行流,介绍了在异步环境下,事件处理器的执行节点,也就是异步环境下,事件处理的内部实现方式
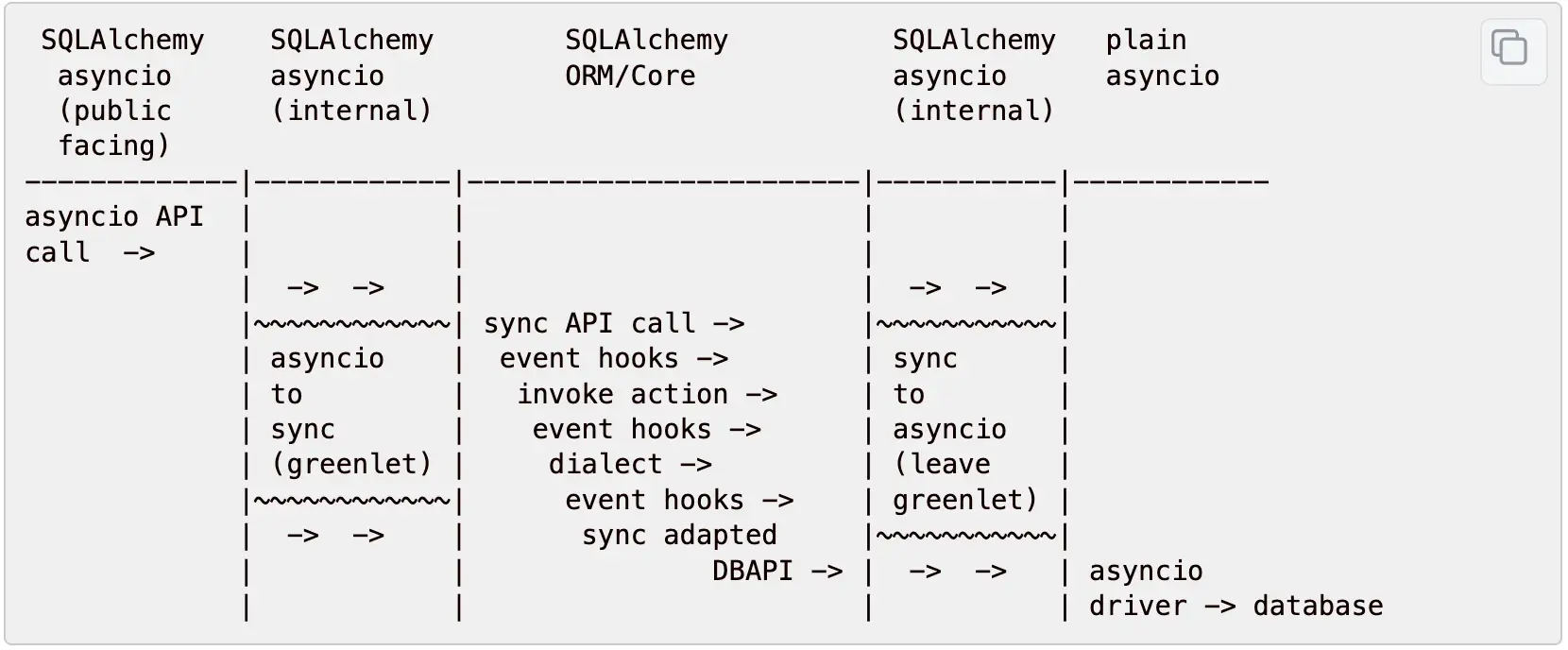
一共5列,我们分别说下。
第一列:业务执行异步asyncio代码
第二列:SQLAlchemy异步IO的内部,asyncio使用greenlet技术手动将asyncio代码转换成同步代码
第三列:SQLAlchemy核心流程,开始执行同步代码,就好像在阻塞IO环境下一样
第四列:通过greenlet技术,将同步再切回到异步asyncio环境
第五列:通过异步驱动和数据库进行交互
简单理解就是,虽然我们写的处理器代码是同步的,但是SQLAlchemy在内部通过greenlet技术将同步代码转换成了异步执行。
利用greenlet将同步代码转成了异步,解决了异步环境中执行同步代码的问题,但是如果我们在事件处理器中执行的方法,不能用同步方式,只能用awaitable的方式执行,此时该怎么办呢?
官方举了一个例子,asyncpg驱动库里的.set_type_codec()方法,只提供了await的调用方式。
如果对上面的内容还有印象,此时就会想到run_sync方法了,没错,就是使用这个方法。看下面的例子:
此处是用到了dbapi_connection对象的run_sync方法,dbapi_connection是AdaptedConnection类型,它的run_async方法接收一个lambda入参,lambda返回一个awaitable方法,然后run_sync会执行
python
from sqlalchemy import event
from sqlalchemy.ext.asyncio import create_async_engine
engine = create_async_engine(...)
@event.listens_for(engine.sync_engine, "connect")
def register_custom_types(dbapi_connection, *args):
dbapi_connection.run_async(
lambda connection: connection.set_type_codec(
"MyCustomType",
encoder,
decoder, # ...
)
)10、异步IO使用注意事项
整理了2个使用异步IO时的注意事项
(1)、避免使用隐式IO。显示查询数据,就像python之禅中所说:显式好于隐式
(2)、多事件循环,不要共享AsyncEngine
10.1、避免隐式IO
10.1.1、显示查询数据
SqlAlchemy默认是懒加载的
如这个实例,A类持有一个bs的集合引用,引用类型是B
当查询A时,默认是不查询B的,只有当访问A.bs时才发起真正的查询,这就是SqlAlchemy的懒加载机制
python
result = session.execute(select(A).order_by(A.id).limit(1))
......
# 访问a1的bs属性,此时发起对bs属性的访问,触发隐式IO
for b1 in a1.bs:
print(b1, b1.data)在异步IO环境中,发生IO的地方就需要使用await修饰,但是a1.bs是无法直接被await修饰的。关于这个问题,SqlALchemy提供了三种解决方案,都是使用显示查询的方式,如下:
(1)、就是例子中给出的,借助awaitable_attrs来实现,Base类需要继承一个AsyncAttrs混入类,然后再访问属性即可。
python
class Base(AsyncAttrs, DeclarativeBase):
pass
class B(Base):
__tablename__ = "b"
......
class A(Base):
__tablename__ = "a"
......
bs: Mapped[List[B]] = relationship()
# 需要依赖事件循环执行这个方法
async def select_and_update_objects(
async_session: async_sessionmaker[AsyncSession],
) -> None:
async with async_session() as session:
result = await session.execute(select(A).order_by(A.id).limit(1))
a1 = result.scalars().one()
for b1 in await a1.awaitable_attrs.bs:
print(b1, b1.data)(2)、加载A时,同步把bs属性一起加载出来,从而避免隐式IO,这里用到了selectinload属性
python
stmt = select(A).order_by(A.id).options(selectinload(A.bs))(3)、使用session.refresh方法显示的加载bs属性
python
# assume a_obj is an A that has lazy loaded A.bs collection
a_obj = await async_session.get(A, [1])
# force the collection to load by naming it in attribute_names
await async_session.refresh(a_obj, ["bs"])
# collection is present
print(f"bs collection: {a_obj.bs}")10.1.2、禁止使用cascade="all"
如下示例
python
class A(Base):
bs: Mapped[List[B]] = relationship(cascade="all")使用A
python
# 父对象a已刷新,但关联对象a.bs只是被过期,不会主动刷新
await session.refresh(a)
# 尝试访问子对象时,触发隐式IO。此时会报错: MissingGreenlet,异步中禁止隐式IO
print(a.bs[0].data)在阻塞IO中,我们可能会使用cascade="all",来让SqlAlchemy自动管理父子对象的关联关系,但是在异步IO场景,不能直接写All,主要是为了排除refresh-expire行为,官方文档对refresh-expire的描述是这样的:
refresh-expire is an uncommon option, indicating that the Session.expire() operation should be propagated from a parent down to referred objects. When using Session.refresh(), the referred objects are expired only, but not actually refreshed.
expire父对象时,会同步expire父对象关联的子对象
但是,refresh父对象时,不会同步refresh父对象的关联对象,当访问关联对象时,会重新加载,这就又涉及到了隐式IO,所以要显示排除refresh-expire。
除了refresh-expire,cascade的其他参数参见cascade文档
10.1.3、eager_defaults属性
python
If using asyncio with a database that does not support RETURNING, such as MySQL 8, server default values such as generated timestamps will not be available on newly flushed objects unless theMapper.eager_defaults option is used. In SQLAlchemy 2.0, this behavior is applied automatically to backends like PostgreSQL, SQLite and MariaDB which use RETURNING to fetch new values when rows are INSERTed.大概意思是:如果要在insert数据后,从实体中获取数据,但如果数据库不支持RETURNING( 比如:mysql),此时可以配置eager_defaults属性来做到新增数据后,强制发起一次select查询,查询最新的时间戳数据,这也是一次隐式IO,异步场景下,我们要知道,这是一个隐藏的点
python
class User(Base):
__tablename__ = "user"
__mapper_args__ = {"eager_defaults": True} # 强制 INSERT 后 SELECT 回默认值
id: Mapped[int] = mapped_column(primary_key=True)
created_at: Mapped[datetime] = mapped_column(server_default=text("CURRENT_TIMESTAMP"))10.2、多事件循环使用注意事项
1)、当使用默认的连接池实现QueuePool时,不要在多个异步循环间共享AsyncEngine对象,否则会报错:RuntimeError,Task
python
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.pool import NullPool
engine = create_async_engine(
"postgresql+asyncpg://user:pass@host/dbname",
poolclass=NullPool,
)