jieba库三种模式
- 精确模式
bash
jieba.cut(s, cut_all=False) 或 jieba.lcut(s)- 全模式
bash
jieba.cut(s, cut_all=True) - 搜索引擎模式
bash
jieba.cut_for_search(s)假设我们对句子 "我来到北京清华大学" 进行分词,不同模式的结果如下:
精确模式:'我', '来到', '北京', '清华大学'
全模式:'我', '来到', '北京', '清华', '清华大学', '华大', '大学' (可以看到 "清华大学" 被重复切分出了 "清华" 和 "大学" 等词)
搜索引擎模式:'我', '来到', '北京', '清华', '华大', '大学', '清华大学' (它在精确模式的基础上,对 "清华大学" 这个长词进行了更细的切分)
分词结果处理
- len():计算一段文本被分成了多少个词
bash
len([1,2,3]) // 3- 切片:起始,结尾,步长
bash
words = ['我', '爱', '北京', '天安门', '广场']
print(words[1:4:2]) # 从索引1到3,步长为2 → 取索引1和3
# 输出:['爱', '天安门']
print(words[:3]) # 从开头取到索引2(不包含3)
# 输出:['我', '爱', '北京']
print(words[2:]) # 从索引2取到末尾
# 输出:['北京', '天安门', '广场']
print(words[:]) # 相当于 words[0:len(words)]
# 输出:['我', '爱', '北京', '天安门', '广场']
print(words[-3:-1]) # 从倒数第3个取到倒数第2个(不包含-1)
# 倒数第3个是'北京',倒数第2个是'天安门',结果:['北京', '天安门']
print(words[-4::2]) # 从倒数第4个取到末尾,步长2
# 倒数第4个是'爱',然后跳一个取'天安门',结果:['爱', '天安门']
print(words[::-1]) # 从右向左每步取一个,相当于反转列表
# 输出:['广场', '天安门', '北京', '爱', '我']
bash
#逆序 ls[::-1]- 去重复
bash
import jieba
txt = input()
words = jieba.lcut(txt)
unique = []
for w in words:
if w not in unique: # 考点:去重
unique.append(w)
print(' '.join(unique))
bash
import jieba
with open('data.txt', 'r', encoding='utf-8') as f:
text = f.read()
words = jieba.lcut(text)
unique_words = []
for w in words:
# 考点:筛选长度≥3 且 去重
if len(w) >= 3 and w not in unique_words:
unique_words.append(w)数组转字符串:.join()
bash
import jieba
words = jieba.lcut("我爱北京天安门")
result = ' '.join(words) # 用空格做分隔符
print(result) # 输出:我 爱 北京 天安门真题举例:
进阶题4:

进阶题5:

bash
print(words[3:1:-1]) # 从索引3取到索引2(不包含1),步长-1
# 索引3='天安门',索引2='北京' → 结果:['天安门', '北京']
bash
print(words[:2:-1]) # 从末尾取到索引3(不包含2)?需要仔细理解
# 起始省略时,默认从末尾开始(因为步长为负,起始默认为-1)
# 结束索引为2(正向索引),取到索引2之前(即索引3和4)
# 结果:['广场', '天安门'](索引4和3)
bash
print(words[2::-1]) # 从索引2开始向左取到开头
# 索引2='北京',然后向左取索引1='爱',索引0='我' → 结果:['北京', '爱', '我']
print(words[1:10]) # 结束索引10超出,取到末尾
# 输出:['爱', '北京', '天安门', '广场']
print(words[-10:3]) # 起始索引-10超出,从开头取到索引2
# 输出:['我', '爱', '北京']
s = "我爱北京天安门"
print(s[2:4]) # 输出:北京
print(s[::-1]) # 输出:门安天京爱我真题1答案:
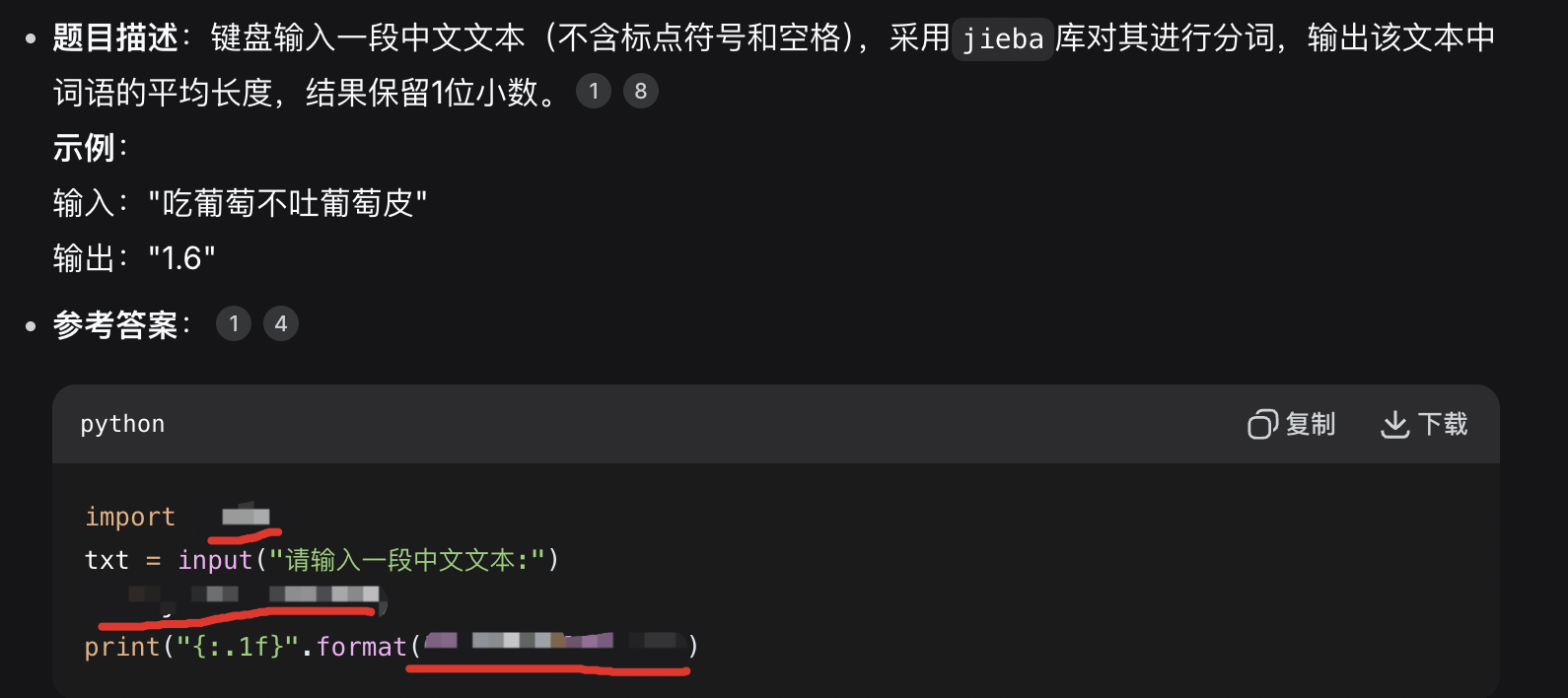
bash
import jieba
txt = input("请输入一段中文文本:")
ls = jieba.lcut(txt)
print("{:.1f}".format(len(txt)/len(ls)))真题2答案:
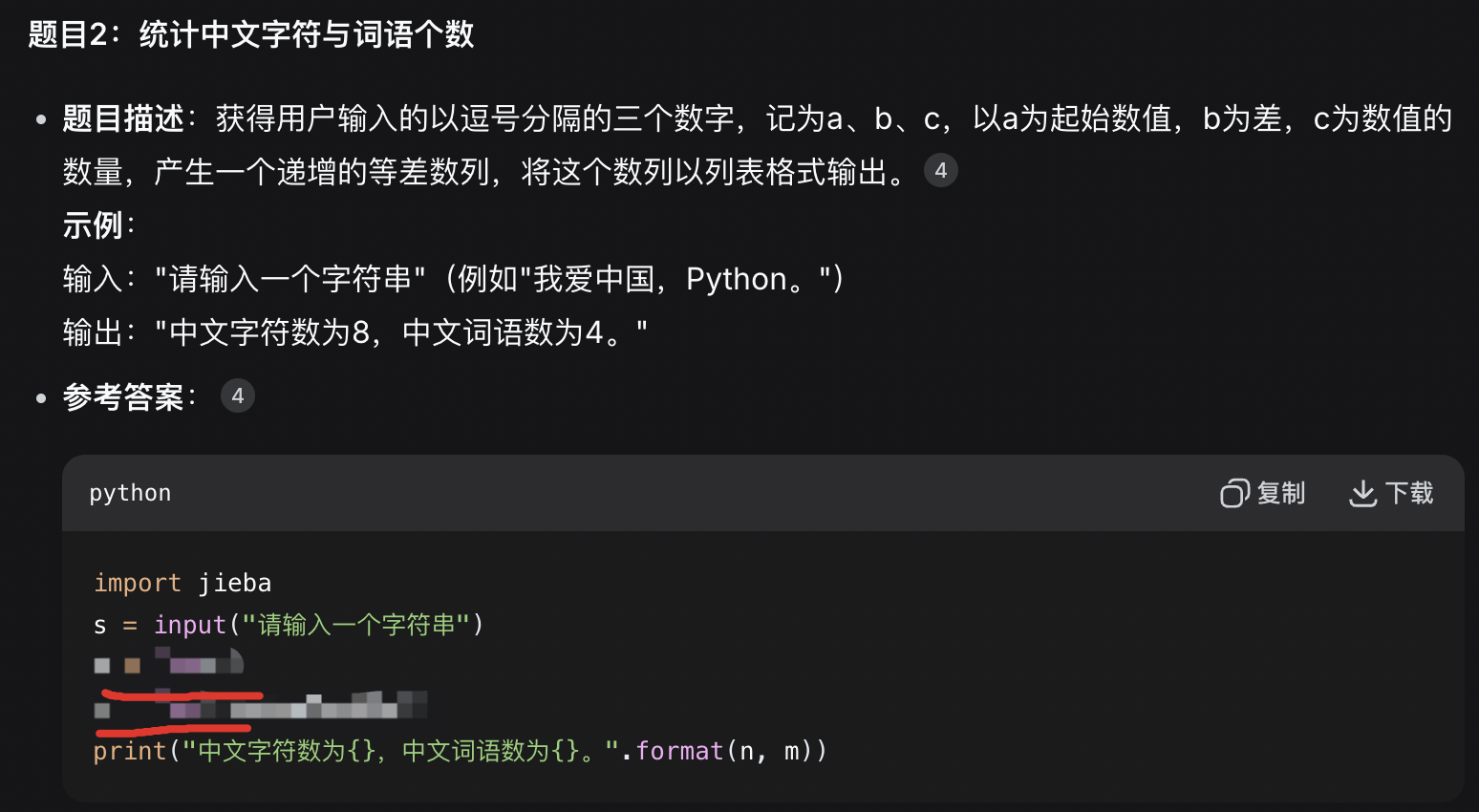
bash
import jieba
s = input("请输入一个字符串")
n = len(s)
m = len(jieba.lcut(s))
print("中文字符数为{},中文词语数为{}。".format(n, m))真题3答案:
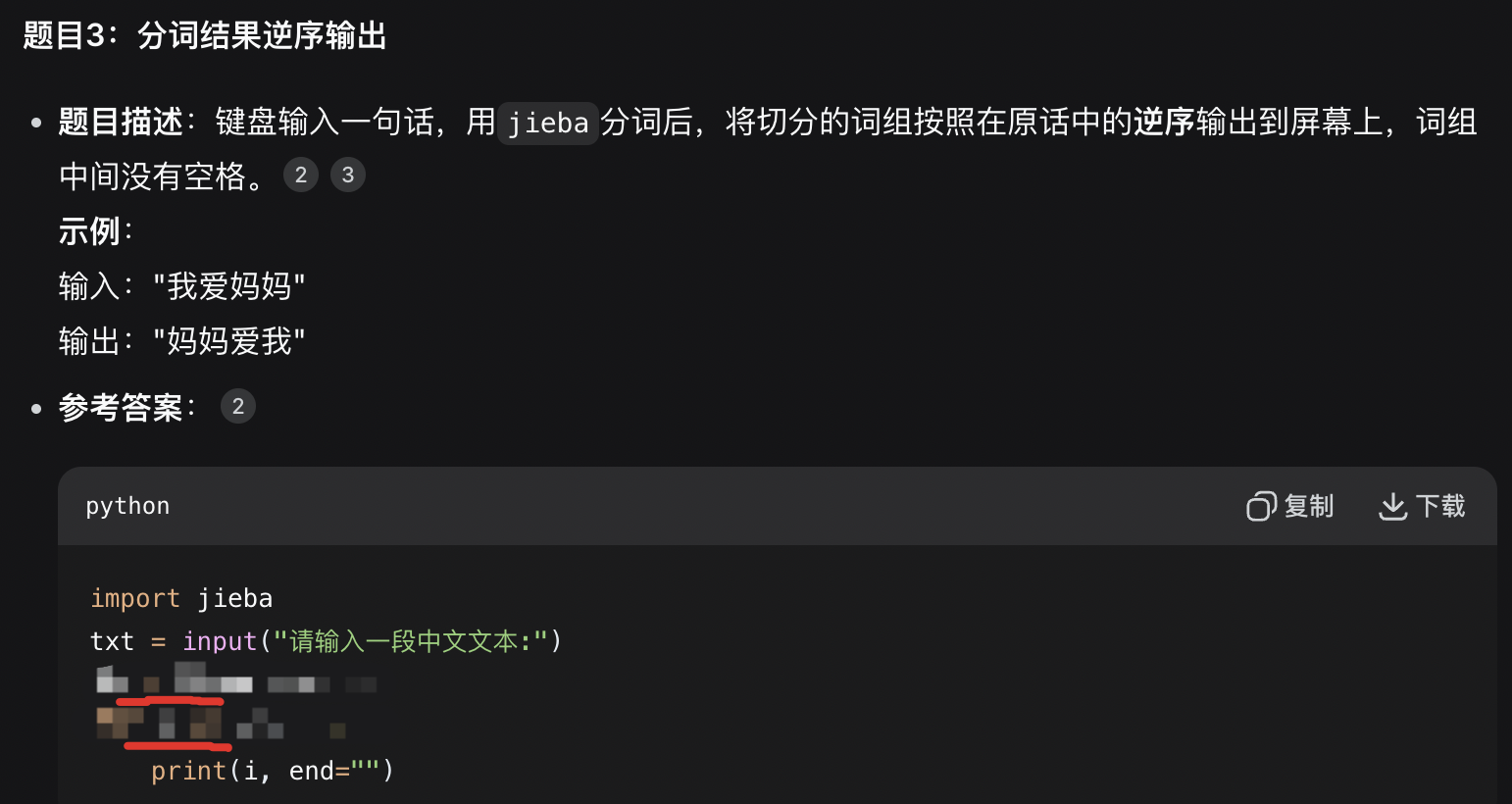
bash
import jieba
txt = input("请输入一段中文文本:")
ls = jieba.lcut(txt)
for i in ls[::-1]:
print(i, end="")进阶题4答案:
bash
import jieba
fi = open("clean.txt","r", encoding='utf-8')
data = fi.read()
fi.close()
ls = jieba.lcut(data)
d = {}
for i in ls:
if len(i) >= 3:
d[i] = d.get(i, 0) + 1
lt = list(d.items())
lt.sort(key=lambda x:x[1], reverse=True)
s = ""
for l in lt[:10]:
s += "{}:{},".format(l[0], l[1])
print(s.rstrip(","))进阶题5答案:
bash
# 问题1:提取不重复关键词
import jieba
f = open('data.txt','r')
lines = f.readlines()
f.close()
D = []
for line in lines:
wordList = jieba.lcut(line)
for word in wordList:
if len(word) >= 3 and word not in D:
D.append(word)
f = open('out1.txt','w')
f.write('\n'.join(D))
f.close()
# 问题2:统计词频并排序
import jieba
f = open("data.txt","r")
lines = f.readlines()
f.close()
d = {}
for line in lines:
wordList = jieba.lcut(line)
for word in wordList:
if len(word) >= 3:
d[word] = d.get(word, 0) + 1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True)
f = open('out2.txt','w')
for i in ls:
f.write('{}:{}\n'.format(i[0], i[1]))
f.close()