数据导入
python
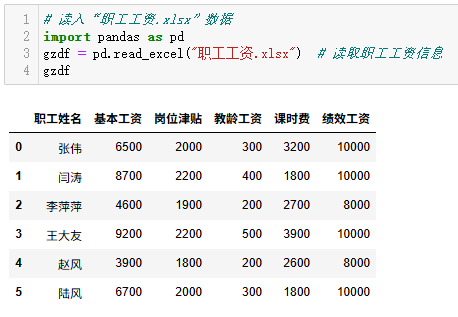
# 读入"职工工资.xlsx"数据
import pandas as pd
gzdf = pd.read_excel("职工工资.xlsx") # 读取职工工资信息
gzdf拼接contact
axis=0 为默认按照行拼接(上下拼接)
axis=1(左右拼接)
python
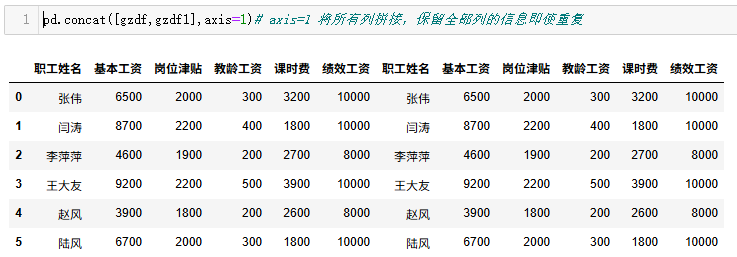
gzdf1=gzdf
pd.concat([gzdf,gzdf1],axis=1)# axis=1 将所有列拼接,保留全部列的信息即使重复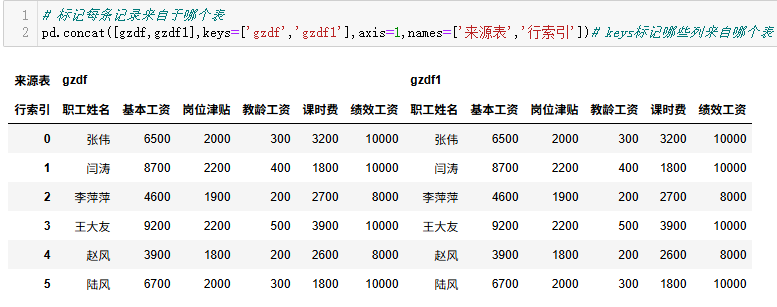
python
# 标记每条记录来自于哪个表
pd.concat([gzdf,gzdf1],keys=['gzdf','gzdf1'],axis=1,names=['来源表','行索引'])# keys标记哪些列来自哪个表lambda函数
python
mySum = lambda a,b:a+b # 定义匿名函数,并将其赋值给变量mySum
print(mySum(10,20)) # 通过mySum调用匿名函数,并给匿名函数传入参数10和20
print(mySum(100,20)) # 通过mySum调用匿名函数,并给匿名函数传入参数100和200apply
python
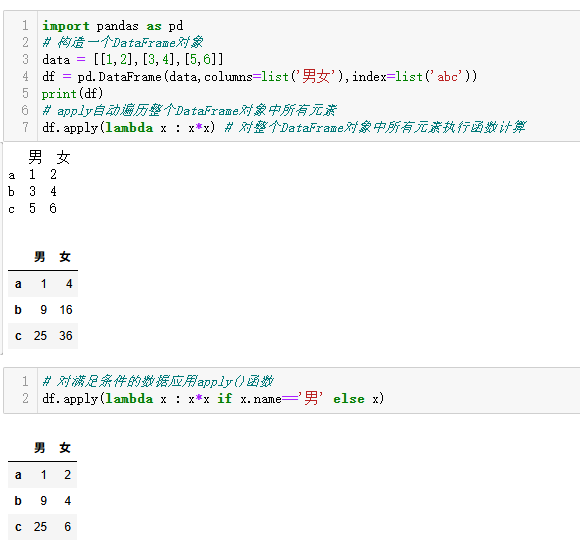
import pandas as pd
# 构造一个DataFrame对象
data = [[1,2],[3,4],[5,6]]
df = pd.DataFrame(data,columns=list('男女'),index=list('abc'))
print(df)
# apply自动遍历整个DataFrame对象中所有元素
df.apply(lambda x : x*x) # 对整个DataFrame对象中所有元素执行函数计算
python
# 对满足条件的数据应用apply()函数
df.apply(lambda x : x*x if x.name=='男' else x)还可以axis=1按行,=0默认按列

python
df.apply(lambda x:x.sum(),axis=1)# 按行求和
python
df.apply(lambda x:x.sum())# 默认按列求和Series也可以使用功能
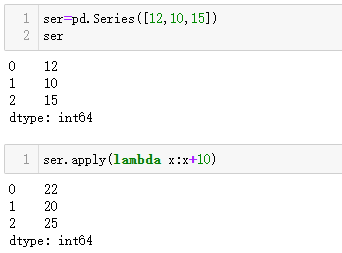
进阶
python
student['新成绩']=student['成绩'].apply( lambda x:"缺考" if pd.isna(x)==True
else ("不及格" if x<60
else "及格"))删除列drop
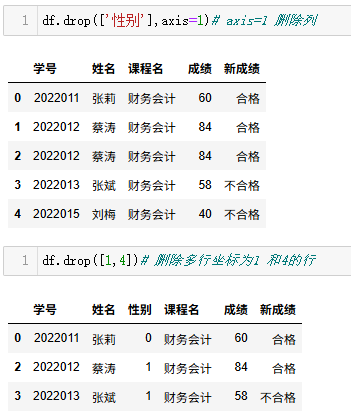
python
df.drop(['性别'],axis=1)# axis=1 删除列
df.drop([1,4])# 删除多行坐标为1 和4的行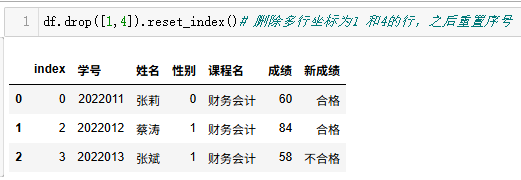
df.drop(1,4).reset_index()# 删除多行坐标为1 和4的行,之后重置序号
替换replace
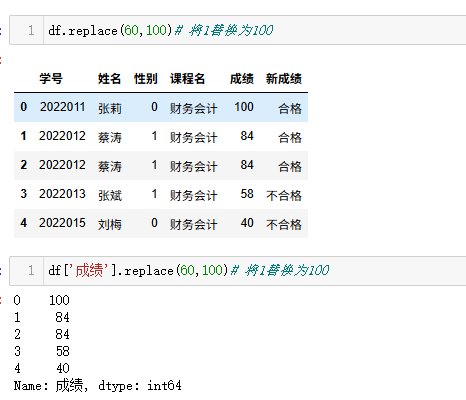
进阶
对客户数据信息进行合理转换
按照通话时长将用户划分为三种:通话时长>平均通话时长 为 较多时间;< 为较少时间;空为未使用
python
# 获取"通话时长"列的平均值
meanValue = df["通话时长"].mean()
meanValue
# 为"通话使用情况"列赋值
df["通话使用情况"] = df["通话时长"].\
apply(lambda x: "未使用" if (pd.isna(x)==True) \
else ("较少时间" if x < meanValue \
else "较多时间" ))
df.head() # 限于篇幅,显示前五行