从一个小例子学习方程组求解超节点(supernodal)算法
矩阵分块分解
以 Cholesky 分解超节点方法举例说明,LULULU 和 LDLTLDL^TLDLT 类似。
考虑对称正定(SPD)线性方程组求解问题
x=b,A=AT,A≻0 x=b, \quad A=A^T, A \succ 0 x=b,A=AT,A≻0
Cholesky 分解法求解方程步骤分两段:
1.分解阶段:求下三角矩阵 L ,使得
A=LLT A=L L^T A=LLT
2.求解阶段:先解
Ly=b L y=b Ly=b
再解
LTx=y L^T x=y LTx=y
把 AAA 的对角部分成两块,左上部分和右下剩余部分,左下和右上部分形状顺应,
A=A11A12A21A22,A12=A21T A=\left\\begin{array}{ll} A_{11} \& A_{12} \\\\ A_{21} \& A_{22} \\end{array}\\right, \quad A_{12}=A_{21}^T A=A11A21A12A22,A12=A21T
假设 A11A_{11}A11 由 Cholesky 分解如下
A11=L11L11T A_{11}=L_{11} L_{11}^T A11=L11L11T
那么,我们思考,是否可以将 AAA 写成如下分解形式,
A=L110L21II00SL110L21IT=L11L11TL11L21TL21L11TL21L21T+S A = \left\\begin{array}{ll}L_{11} \& 0 \\\\ L_{21} \& I\\end{array}\\right\left\\begin{array}{ll} I \& 0 \\\\ 0 \& S \\end{array}\\right \left\\begin{array}{ll}L_{11} \& 0 \\\\ L_{21} \& I\\end{array}\\right^T= \left\\begin{array}{cc}L_{11} L_{11}\^T \& L_{11} L_{21}\^T \\\\ L_{21} L_{11}\^T \& L_{21} L_{21}\^T+S\\end{array}\\right A=L11L210II00SL11L210IT=L11L11TL21L11TL11L21TL21L21T+S
这里面的 L21L_{21}L21 和 SSS 是未知量。
将其与 A11A12A21A22\left\\begin{array}{ll}A_{11} \& A_{12} \\\\ A_{21} \& A_{22}\\end{array}\\rightA11A21A12A22 比对可得,
A21=L21L11T A_{21} = L_{21} L_{11}^T A21=L21L11T
A22=L21L21T+S A_{22} = L_{21} L_{21}^T+S A22=L21L21T+S
可得
L21=A21L11−T L_{21} = A_{21} L_{11}^{-T} L21=A21L11−T
S=A22−L21L21T=A22−A21L11−TL11−1A21T=A22−A21A11−1A21T S = A_{22} - L_{21} L_{21}^T = A_{22} - A_{21} L_{11}^{-T} L_{11}^{-1}A_{21} ^T = A_{22} - A_{21} A_{11}^{-1}A_{21} ^T S=A22−L21L21T=A22−A21L11−TL11−1A21T=A22−A21A11−1A21T
这里的 SSS 大家喜欢叫 Schur 补(块高斯消元的补的部分),事实上,SSS 也是 SPD 的,对称性由表达式可看出。对于正定性,可利用定义进行证明。
任取非零向量 yyy ,令
x=−A11−1A12yy≠0 x=\left\\begin{array}{c} -A_{11}\^{-1} A_{12} y \\\\ y \\end{array}\\right \neq 0 x=−A11−1A12yy=0
那么,
xTAx=yT(A22−A21A11−1A12)y=yTSy>0x^T A x=y^T\left(A_{22}-A_{21} A_{11}^{-1} A_{12}\right) y=y^T S y >0xTAx=yT(A22−A21A11−1A12)y=yTSy>0
证毕。
进一步,假如 SSS 有 Cholesky 分解
S=L22L22TS = L_{22}L_{22}^TS=L22L22T
那么,可以得到 AAA 的 Cholesky 分解
A=L110L21II00SL110L21IT=L110L21II00L22I00L22TL110L21IT=L110L21L22L110L21L22T=LLT A=\left\\begin{array}{ll} L_{11} \& 0 \\\\ L_{21} \& I \\end{array}\\right\left\\begin{array}{ll} I \& 0 \\\\ 0 \& S \\end{array}\\right\left\\begin{array}{ll} L_{11} \& 0 \\\\ L_{21} \& I \\end{array}\\right^T =\left\\begin{array}{ll} L_{11} \& 0 \\\\ L_{21} \& I \\end{array}\\right \left\\begin{array}{ll} I \& 0 \\\\ 0 \& L_{22} \\end{array} \\right \left\\begin{array}{ll} I \& 0 \\\\ 0 \& L_{22}\^T \\end{array} \\right \left\\begin{array}{ll} L_{11} \& 0 \\\\ L_{21} \& I \\end{array}\\right^T=\left\\begin{array}{ll} L_{11} \& 0 \\\\ L_{21} \& L_{22} \\end{array}\\right\left\\begin{array}{ll} L_{11} \& 0 \\\\ L_{21} \& L_{22} \\end{array}\\right^T=LL^T A=L11L210II00SL11L210IT=L11L210II00L22I00L22TL11L210IT=L11L210L22L11L210L22T=LLT
一言以蔽之,AAA Cholesky 分解的下三角矩阵 LLL 写法如下。
左上角 L11L_{11}L11 为左上角的 Cholesky 分解:
L11L_{11}L11
左下角 L21L_{21}L21 为原右下角右乘左上角的逆转置(解个下三角方程组):
L21=A21L11−T L_{21} = A_{21} L_{11}^{-T} L21=A21L11−T
右下角 L22L_{22}L22 为 Schur 补的 Cholesky 分解:
S=A22−A21A11−1A21T=L22L22TS = A_{22} - A_{21} A_{11}^{-1}A_{21} ^T = L_{22}L_{22}^TS=A22−A21A11−1A21T=L22L22T
考虑求 SSS 的 Cholesky 分解,如果对 SSS 继续分块,可以将 SSS 视为原来的 AAA,继续相似过程,以此类推。这刚好对应了 AAA 对角多分块的情形。
其实,在后续的过程中,左上角 L11L_{11}L11 和 左下角 L21L_{21}L21(蕴含了右上角),就已经固定下来了,不会再变了。A11A_{11}A11 对应的行列处理完了,我们一般就说消去了 A11A_{11}A11 对应的未知量。
事实上,上述过程表述的是给定矩阵的 Cholesky 分解的下三角的分裂式表达,这里面就蕴含着超节点(supernodal)思想核心,即"把若干列打包一起做"。真正的 supernodal 方法会把结构相似的列组成一个"超节点",然后用密集块运算(BLAS3)加速。
写一个 MATLAB 程序来验证。
clear; clc;
n = 200;
rng(1);
R = sprandsym(n, 0.03, 0.1, 1); % 稀疏对称矩阵
A = R'*R + n*speye(n); % 保证SPD
A = full(A); % 教学代码中用full方便演示
b = randn(n,1);
blockSize = 16;
[x_sn, L] = supernode_cholesky_solve(A, b, blockSize);
x_matlab = A \ b;
err = norm(x_sn - x_matlab)
function [x, L] = supernode_cholesky_solve(A, b, blockSize)
%SUPERNODE_CHOLESKY_SOLVE 用"超节点/分块Cholesky"方法求解 Ax=b
%
% 输入:
% A - n×n 对称正定矩阵(SPD)
% b - n×1 右端向量
% blockSize - 超节点大小(块大小)
%
% 输出:
% x - 解向量
% L - Cholesky下三角因子,使 A = L*L'
%
% 说明:
% 这是教学版"超节点方法"实现,本质是分块(blocked)Cholesky,
% 可看作固定大小超节点的简化版本。
[n, m] = size(A);
% 工作矩阵(右看分块Cholesky)
S = A;
L = zeros(n, n);
for k = 1:blockSize:n
ke = min(k + blockSize - 1, n);
J = k:ke;
% 当前对角块
Sjj = S(J, J);
% 对角块 Cholesky 分解
[Ljj, p] = chol(Sjj, 'lower');
L(J, J) = Ljj;
% 更新下面的块
if ke < n
I = (ke+1):n;
% Lik * Ljj' = S(I,J) => Lik = S(I,J) / Ljj'
Lik = S(I, J) / Ljj';
L(I, J) = Lik;
% Schur补更新: S(I,I) = S(I,I) - Lik*Lik'
S(I, I) = S(I, I) - Lik * Lik';
end
end
% 前代 + 回代
y = forward_substitution(L, b);
x = backward_substitution(L', y);
end
function y = forward_substitution(L, b)
% 求解 Ly = b,其中 L 为下三角矩阵
n = length(b);
y = zeros(n,1);
for i = 1:n
y(i) = (b(i) - L(i,1:i-1)*y(1:i-1)) / L(i,i);
end
end
function x = backward_substitution(U, y)
% 求解 Ux = y,其中 U 为上三角矩阵
n = length(y);
x = zeros(n,1);
for i = n:-1:1
x(i) = (y(i) - U(i,i+1:n)*x(i+1:n)) / U(i,i);
end
end概念引入
上述过程有几个遗留问题,比如
1、矩阵 AAA 应该如何分块,才可以使分解过程又快又准?比如令单个块的分解缓存友好。
2、矩阵 AAA 行列变换会对求解过程有什么影响?
3、原始系统可以做哪些操作,改善矩阵性质,提高分解速度。
这个过程会涉及到若干知识点
- 消去树(elimination tree)
- 列合并/超节点识别
- 稀疏结构重排(如 AMD)
- 稀疏 BLAS 优化
- fill-in 填充
- 分析、符号分解、数值分解、面板、左看右看、最大权匹配
- ......
消去树(elimination tree)决定"依赖关系和传播路径",超节点(supernode)决定"把哪些列合并成一个密集块一起算"。最大权匹配(maximum weighted matching),可显著改善原始系统的对角占优性。
要讲清楚这些概念,直至可以工程实现,需要比较大的篇幅,下面只做一些抛砖引玉的概念点题,管中窥豹,可见一斑。
本质上,整个 surpernodal 方法是这样一个过程:
先换座位(重排)→ 看关系图(分析)→ 预测施工影响(符号)→ 分组施工(超节点)→ 机器高效施工(BLAS)
超节点方法
超节点法的核心:利用列之间模式相同的部分组成超节点,用 BLAS-3(矩阵-矩阵运算)提高效率。
对稀疏 SPD 矩阵 AAA ,如果你做 Cholesky:
A=LLT A=L L^T A=LLT
虽然 AAA 稀疏,但在消元过程中会产生填充(fill-in):原来是 0 的位置在 LLL 中变成非零。
如果按"逐列"处理(列 Cholesky):
- 每列都有很多零散更新
- 运算像 Level-1/Level-2 BLAS(小向量、小矩阵)
- 内存访问碎片化
- CPU 缓存和矩阵乘法性能发挥不出来
supernodal 的想法就是:
- 找出若干"结构相似、非零模式连续"的列
- 按结构自动识别,合成一个"超节点"
- 把很多零散更新改成小块密集矩阵运算(BLAS3)
从而加速运算。打个比方,像做饭:
- 一根根切菜(单列)很慢
- 把同类菜堆一起切(超节点)效率高,还更适合用大刀(BLAS)
怎么定义超节点呢?超节点就是一段连续的列,这些列在 LLL 里满足
- 这些列长得几乎一样(下面的非零结构一样)
- 所以可以把它们当成一个小稠密块一起算
- 而且这串列已经是能并的最大范围(不能再扩了)
给个简单的矩阵表视图如下,一目了然,sss 到 s′s's′ 列就是个超节点

supernodal 高效的根本原因:可以调用 dense BLAS。它可以显著提高缓存命中、更容易利用多核并行和减少调度和索引开销。在超节点方法中,消去树主要用来做 4 件事:
- 描述依赖关系:哪一列(或哪一组列)必须等谁算完
- 做符号分析:预测每列/每超节点会出现哪些非零(结构传播路径)
- 识别超节点:看哪些连续列结构相似、依赖关系连在一起,适合合并
- 调度与并行:不同子树可以并行算,父节点等孩子更新完再算
理论上"最干净"的超节点不一定最快,工程上会适当"凑块"。
- 不要求完全严格匹配
- 允许一些小树枝/小差异合并进来
- 目标是增大块大小、提升 BLAS3 比例
这便是所谓的松弛超节点。
图和填充(fill-in)
不妨考虑对称矩阵比如
A={aij}=∗∗∗000∗∗∗000∗∗∗∗∗000∗∗∗∗00∗∗∗∗000∗∗∗ A=\{a_{ij}\}= \begin{bmatrix} \ast & \ast & \ast & 0 & 0 & 0 \\ \ast & \ast & \ast & 0 & 0 & 0 \\ \ast & \ast & \ast & \ast & \ast & 0 \\ 0 & 0 & \ast & \ast & \ast & \ast \\ 0 & 0 & \ast & \ast & \ast & \ast \\ 0 & 0 & 0 & \ast & \ast & \ast \end{bmatrix} A={aij}= ∗∗∗000∗∗∗000∗∗∗∗∗000∗∗∗∗00∗∗∗∗000∗∗∗
我们先只关心"非零结构"(* 表示非零,0 表示零)。可以把每一行/列看成一个点 1~6,如果 Aij≠0A_{i j} \neq 0Aij=0(且 i≠ji \neq ji=j ),就连一条边。那么,上述矩阵的非零元位置和关系,事实上可以用一张图来表示,
1 ----- 2
\ /
\ /
3 ----- 4
\ / \
\ / \
5 ----- 6这就建立了"非零结构"和图(顶点和边)的关系,非零元位置就表示了边关系。
在高斯消元的过程中,因为变换是整行整行去做的,所以难免会让一些原来矩阵中是 0 的位置,变成了非零,在图上体现一些节点之间原来没有边,现在有了边,这就是填充(fill-in)。
那每次消元会产生哪些填充呢?不妨以先处理第一列举例,先把第 1 个变量从后续方程里消掉。考虑第 iii 行第 jjj 列的元素,对于原来的 aij=0a_{ij} = 0aij=0,如果两个剩余变量 i,ji, ji,j 都和 1 节点相连(即 ai1≠0,aj1≠0a_{i 1} \neq 0, a_{j 1} \neq 0ai1=0,aj1=0 ),那更新 AAA 里的 (i,j)(i, j)(i,j) 项就会得到:
−ai1aj1a11 -\frac{a_{i 1} a_{j 1}}{a_{11}} −a11ai1aj1
用矩阵的语言描述,如果 ai1≠0,aj1≠0a_{i 1} \neq 0, a_{j 1} \neq 0ai1=0,aj1=0,那么高斯消元后,aija_{ij}aij 一定不等于 0。
用图的语言描述,如果节点 1 和节点 iii 和 jjj 都相连,那么消除节点 1 后,节点 iii 和 jjj 一定相连。
推广到一般的情形,在稀疏分解中,消去一个变量时,它的"邻居们"两两相连,往往会被连成团(clique),原来邻居之间可能没边,消去后需要补边(对应 fill-in)。
同一个矩阵,消元顺序会导致 fill-in 差很多,所以就有了重排,重排其实就是改变消元的顺序,使得填充尽可能少。
消去树(Elimination Tree):谁依赖谁的"家谱图"
消去树揭示了并发性信息。进一步地,它还有助于确定填充,可以帮助完成超节点的建立。它表示列与列之间在分解中的数据依赖结构(由稀疏模式决定,不看具体数值)。
消去树是一种树结构,描述非零元素依赖关系的树状结构。通常,节点 jjj 的父节点为 L 的第 jjj 列中,主对角线以下非零行索引里最小的那个行号 。它表示列 jjj 在后续计算中,最先会被需要到哪一列(更大的列)。父节点 = 第一个需要我(子节点)提供数据的"上级"。
消去树看的只是 LLL 非零元 Pattern,而不需要将 LLL 真正算出来,所以消去树是可以通过原始矩阵 AAA,及其对应的消元过程得到。
给个一目了然的示意图如下,
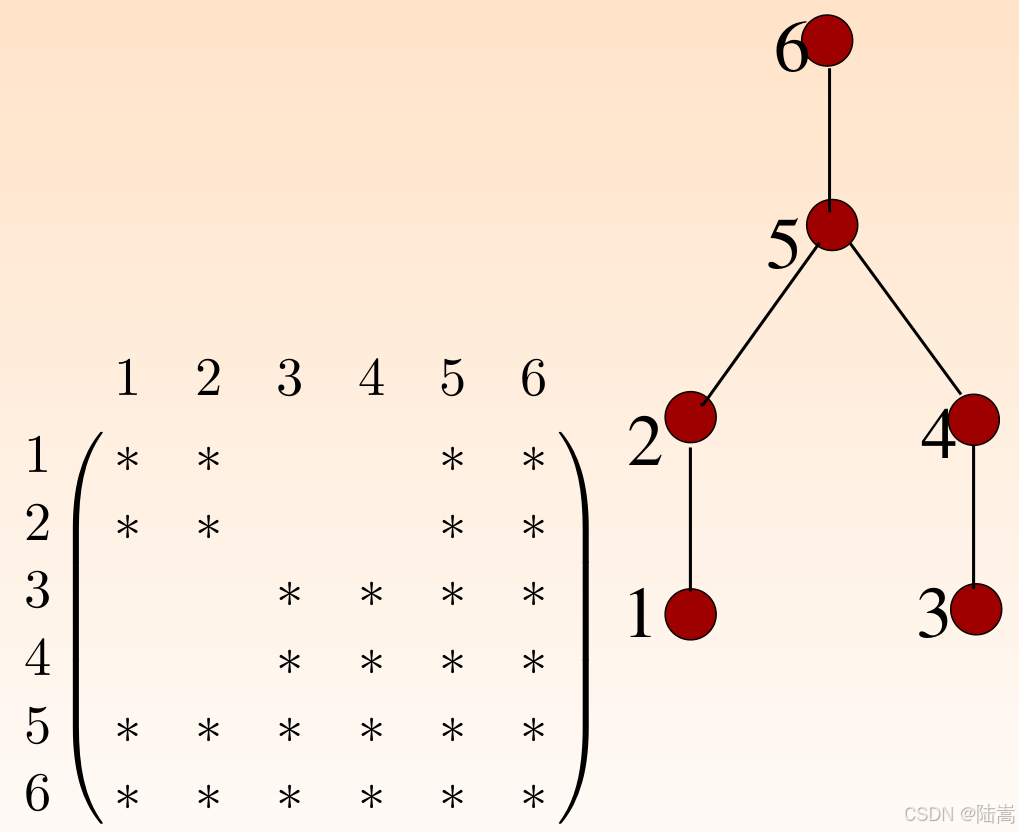
上图揭示了 1 的计算结果给到 2,3 的计算结果给到 4,2 和 4 的计算结果给到 5,5 的计算结果给到 6。那么 1->2 和 3->4 可以同时并行地计算。
树上的关系告诉你:
- 哪些任务可以并行(不同子树)
- 哪些任务必须等前置完成(祖先依赖)
消去树不是事后拍脑袋画的,它是从 LLL 的结构(而 LLL 的结构由 AAA+顺序决定)提炼出来的。
举个简单的例子:
求解稀疏线性方程组 Ax=bA x=bAx=b,其中
A=2000102001002010002111115,b=11112 A=\left\\begin{array}{lllll} 2 \& 0 \& 0 \& 0 \& 1 \\\\ 0 \& 2 \& 0 \& 0 \& 1 \\\\ 0 \& 0 \& 2 \& 0 \& 1 \\\\ 0 \& 0 \& 0 \& 2 \& 1 \\\\ 1 \& 1 \& 1 \& 1 \& 5 \\end{array}\\right, \quad b=\left\\begin{array}{l} 1 \\\\ 1 \\\\ 1 \\\\ 1 \\\\ 2 \\end{array}\\right A= 2000102001002010002111115 ,b= 11112
从高斯消元的过程可以看出,因为没有 fill-in,LLL 的结构基本就是 AAA 的下三角结构(含对角),那么由消去树的定义,可以得到消去树
1 2 3 4
\ | | /
\| |/
5这意味这, 1 2 3 4 的结果给到 5。换言之,本来高斯消元是强依赖前序步骤的方法,但是因为矩阵的高度稀疏,某一些计算就没有依赖关系了。1 2 3 4 列(行)的高斯消元过程可以同时完成,他们的计算不会相互影响,最后把结果汇聚到 5 列(行)即可。
对于超节点中的块运算来说,也是一样,因为矩阵稀疏性,分解计算过程中的某一些 Schur 补,不一定会受到前序某些分解步骤的影响。
消去树计算算法:

路径压缩 (Path Compression): 算法中通过 aia_iai 快速跳过已经处理过的节点,使得算法的时间复杂度接近线性,这是处理大型稀疏矩阵的关键。
重排序
对于大型稀疏矩阵,决定计算时间的关键因素之一是分解过程中产生的填充量。为降低复杂度,存在许多主要是对称的重排序技术,它们以启发式方式尝试减少填充。AMD 重排就是想办法挑一个顺序,让每次消去时邻居团尽量小,少补边。
为啥重排能减少填充?为了方便理解,我在 MATLAB 里对一个稀疏 SPD 矩阵做:
-
symamd(A)重排序 -
chol 分解
-
画
spy(A)和spy(L) -
再比较重排序前后
nnz(L)clear; clc; close all; rng(1)
n = 300; d = 0.01;
M = sprandn(n,n,d);
A = (M'M + 1e-1speye(n));
A = (A + A')/2;
L0 = chol(A,'lower');
p = symamd(A);
Lp = chol(A(p,p),'lower');
fprintf('nnz(L) = %d\n', nnz(L0));
fprintf('nnz(Lp) = %d\n', nnz(Lp));
figure
subplot(2,2,1), spy(A), title('A')
subplot(2,2,2), spy(L0), title('L')
subplot(2,2,3), spy(A(p,p)), title('A(p,p)')
subplot(2,2,4), spy(Lp), title('Lp')
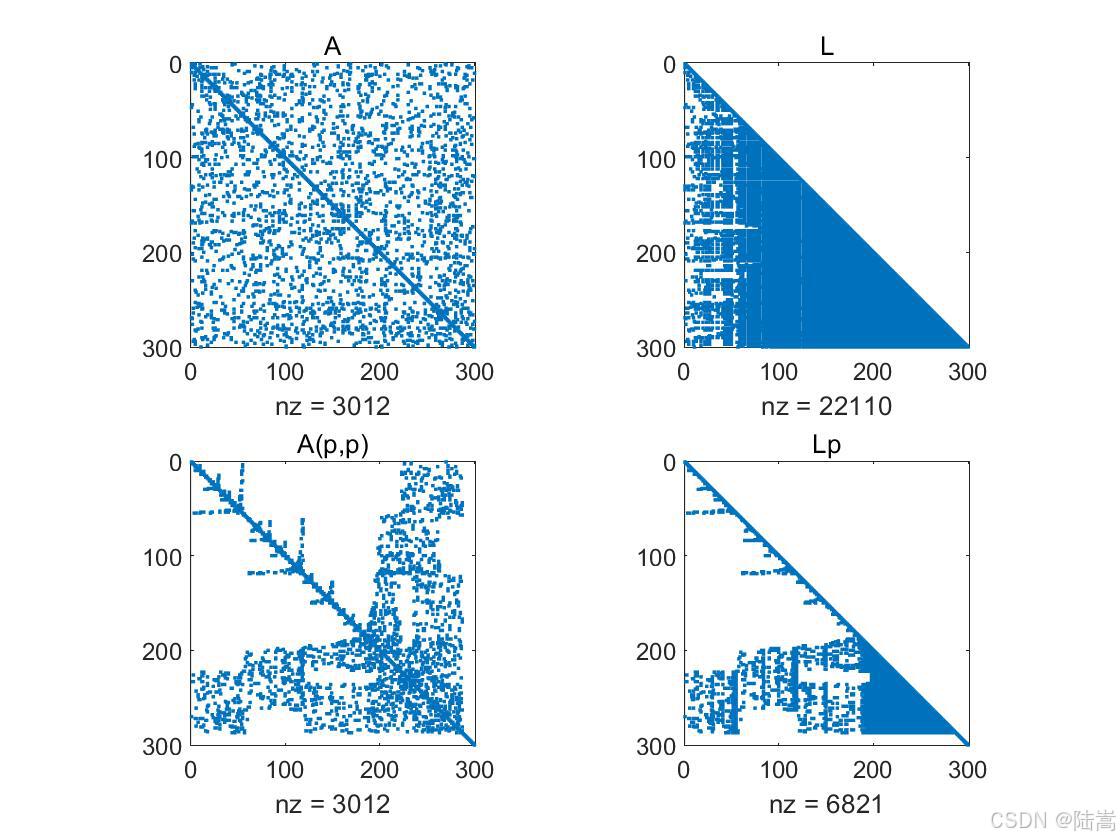
直观看到:
- fill-in 大小变化
- 列模式相似的"块状坚条"(这就是超节点的视觉线索)
- 重排序对于分解后的非零元填充有很大的影响。
以 LU 分解举例,所谓的重拍,就是对于矩阵 AAA,寻找一个置换矩阵 PPP,使得矩阵重排后分解的非零填充最少:
minpnnz(L+U) s.t. P 是置换矩阵P⊤AP=LU \begin{array}{ll} \min _p & \operatorname{nnz}(L+U) \\ \text { s.t. } & P \space 是置换矩阵 \\ & P^{\top} A P=L U \end{array} minp s.t. nnz(L+U)P 是置换矩阵P⊤AP=LU
为什么 fill-in 很重要?因为 fill-in 会导致:
- 内存变大(要存更多非零)
- 计算变慢(算更多乘加)
- 稀疏问题逐渐变"稠密化"
所以整个稀疏线性代数都在想办法:"怎么安排消去顺序,才能少长 fill-in?"这就引出了 重排(AMD、ND 和 RCM 等等)。一个直觉例子:
- 先消"度数很大"的点(连接很多邻居),容易让一大群邻居彼此补边,fill-in 爆炸
- 先消"度数较小"的点,补边通常少一些
AMD (pproximate Minimum Degree,近似最小度)重排就是干这么一件事情。
总结重排序的主要作用:
- 减少 fill-in(填充)
- 改善并行性(让消去树更"胖")
- 提高数值稳定性(LU 中尤其重要)
其他概念
分析(Analysis)
看结构(哪些位置非零,不看数值)、定策略(顺序、树、超节点、内存计划)
消去树在分析阶段能帮你做很多事:
- 预测列模式(symbolic)
- 确定计算顺序和依赖
- 内存分配估计
- 并行调度
- 超节点识别(相邻列是否结构相似,常常和树结构有关)
符号分解(Symbolic factorization)
以 LU 分解为例,预测分解后 L/U 的非零位置。为啥要搞个符号分解?
因为在很多应用计算里,矩阵结构不变(稀疏模式一样),但数值会反复变化(比如非线性迭代、时步推进),这时你可以:分析 + 符号分解做一次,数值分解重复做很多次,这样省很多时间。
数值分解
真正计算数值(L/U/LDLᵀ 的具体的数)。
最大权匹配
pivoting 相关预处理:提高稳定性/减少零主元问题。LU 分解中常见。尽量把"大而可靠"的元素安排到对角线上(通过置换)这样之后 LU 分解更稳定、更不容易遇到零主元。