3.1 矩阵补充
3.1.1 基本思路
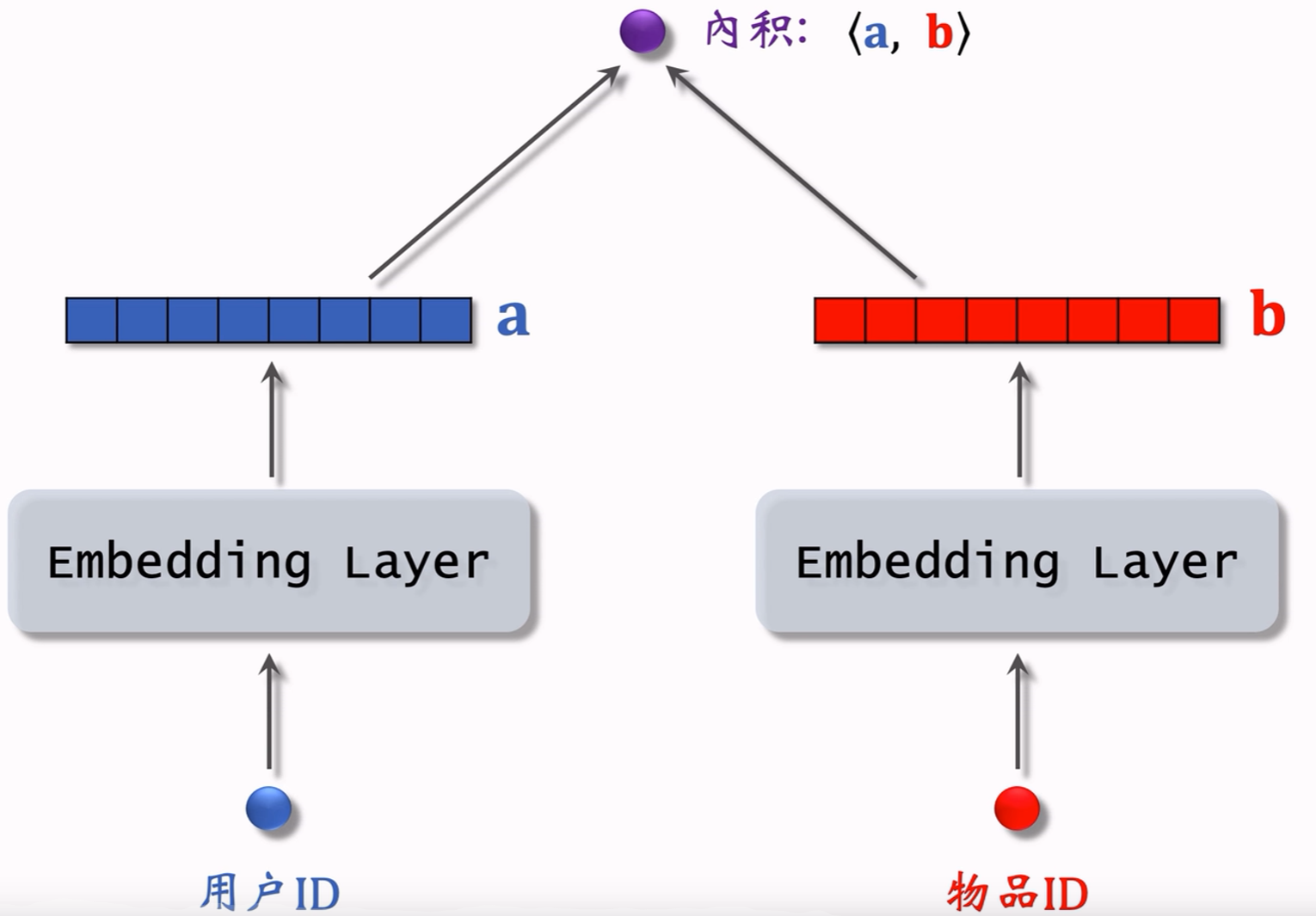
用户embedding参数矩阵记作 A A A,第 u u u号用户对应矩阵第 u u u列,记作向量 a u a_u au;
物品embedding参数矩阵记作 B B B,第 i i i号用户对应矩阵第 i i i列,记作向量 b i b_i bi;
内积 ⟨ a u , b i ⟩ \langle a_u,b_i\rangle ⟨au,bi⟩是第 u u u号用户对第 i i i号物品兴趣的预估值;
训练模型的目的是学习矩阵 A A A和 B B B,使得预估值拟合真实观测的兴趣分数。
3.1.2 数据集
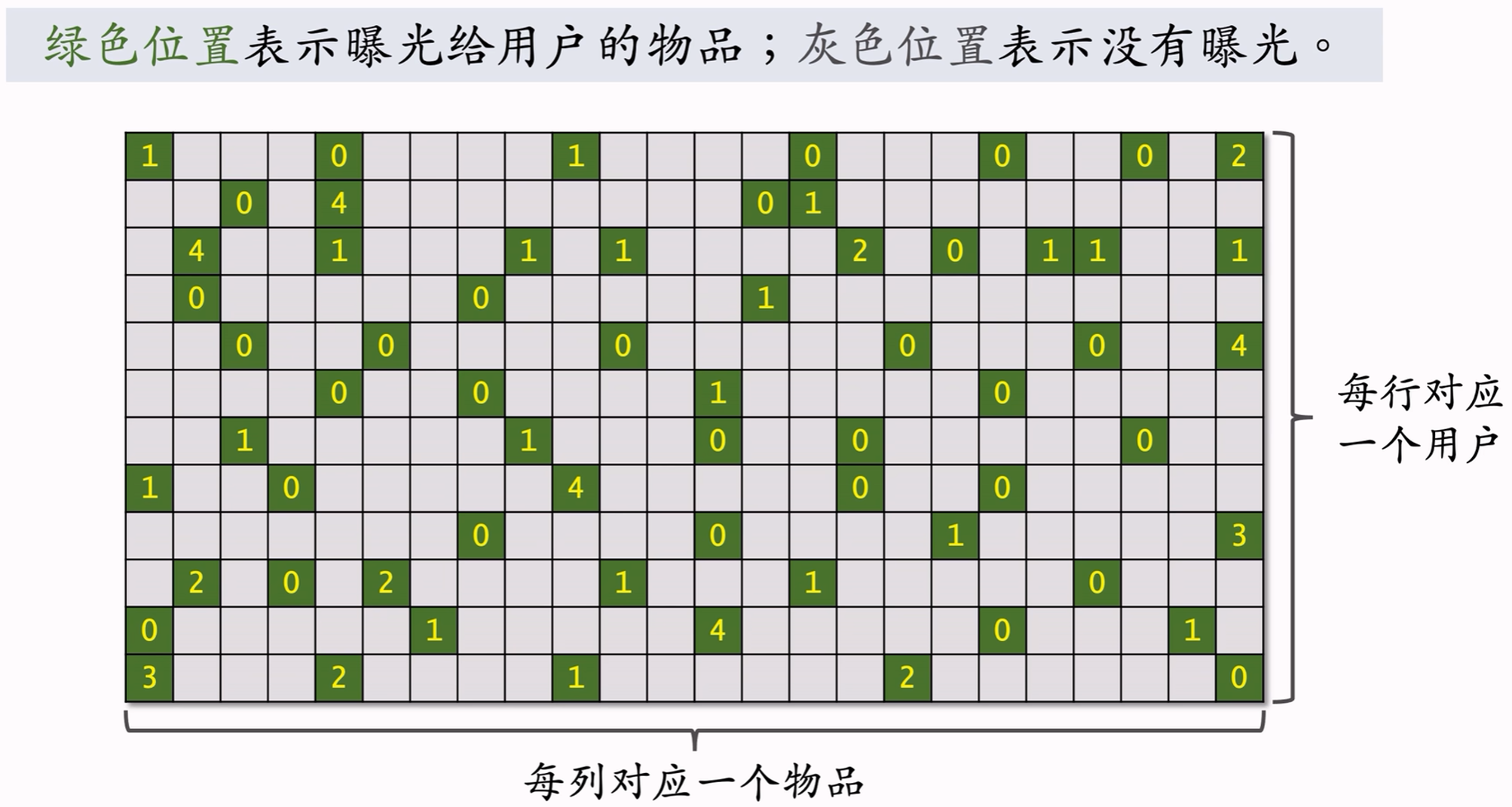
数据集:(用户ID,物品ID,兴趣分数)的集合,记作 Ω = { ( u , i , y ) } \Omega=\{(u,i,y)\} Ω={(u,i,y)}。
数据集中兴趣分数由系统记录,举例:
- 曝光但没点击:0分;
- 点击、点赞、收藏、转发:分别算1分;
- 分数最低0分,最高4分。
3.1.3 训练
把用户ID、物品ID映射成向量(第 u u u号用户→向量 a u a_u au,第 i i i号物品→向量 b i b_i bi)。
求解优化问题,得到参数 A A A和 B B B:
min A , B ∑ ( u , i , y ) ∈ Ω ( y − ⟨ a u , b i ⟩ ) 2 \min_{A,B} \sum_{(u,i,y)\in\Omega} (y-\langle a_u,b_i\rangle)^2 A,Bmin(u,i,y)∈Ω∑(y−⟨au,bi⟩)2
3.1.4 矩阵补充
3.1.5 缺点
工业界不会使用矩阵补充方法。
- 仅用ID embedding,没利用物品、用户属性。
- 负样本的选取方式不正确(曝光之后没有点击、交互作为负样本的方式不work)。
3.2 线上服务
3.2.1 背景
- 把用户ID作为key,查询key-value表,获取该用户的 a a a向量;
- 查找用户最可能感兴趣的 k k k个物品作为召回结果(返回内积 ⟨ a , b i ⟩ \langle a, b_i\rangle ⟨a,bi⟩最大的 k k k个物品)。
时间复杂度正比于物品数量,不可接受。
3.2.2 最近邻查找的标准
- 欧氏距离最小(L2距离)
- 向量内积最大(内积相似度)
- 向量夹角余弦最大(cosine相似度)
3.2.3 通过索引获取最近邻
考虑所有向量进行了归一化。
Step 1: 对向量空间进行区域划分;
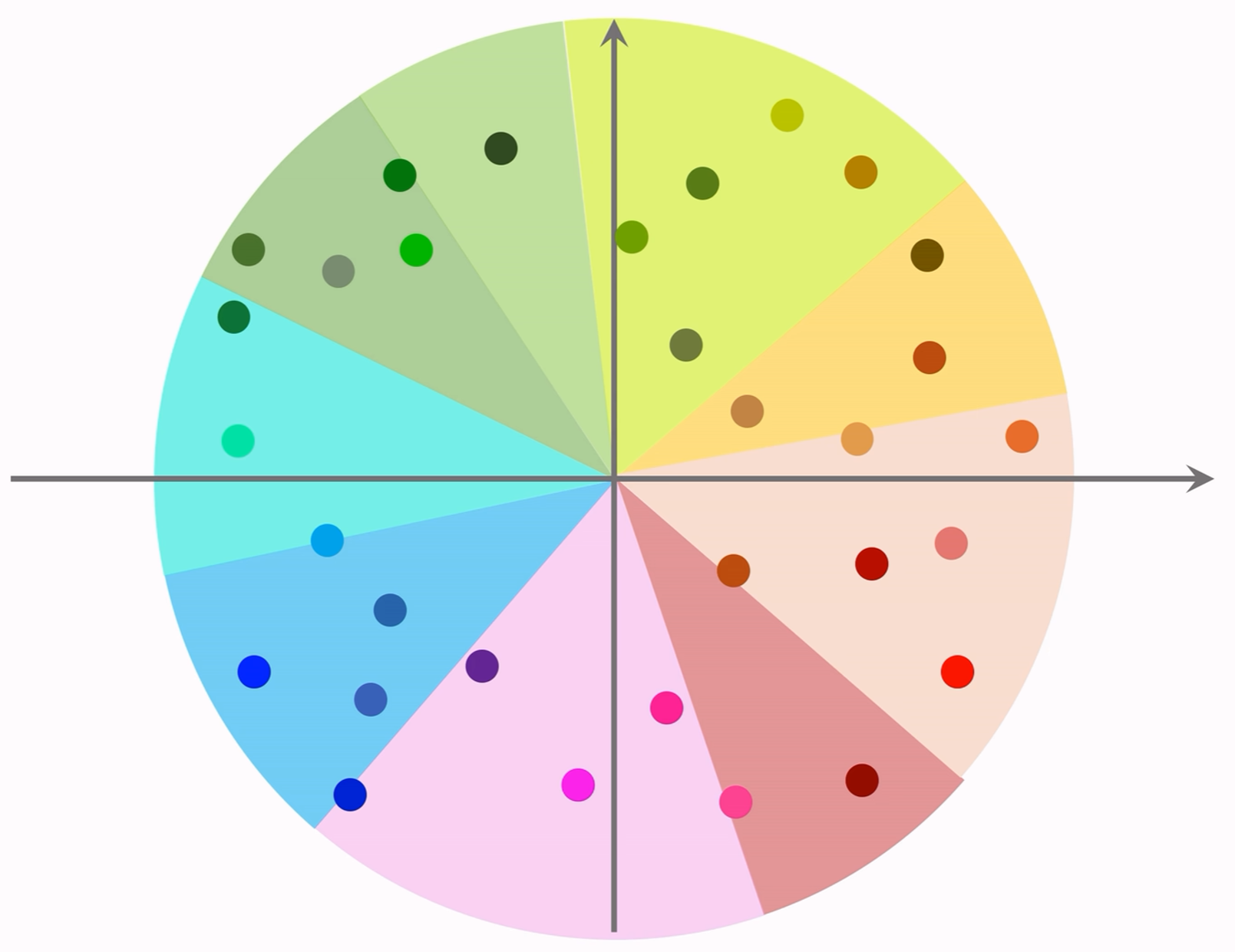
Step 2: 为每个区域建立索引向量(区域的中心向量),并建立索引向量→区域内所有向量 的映射;
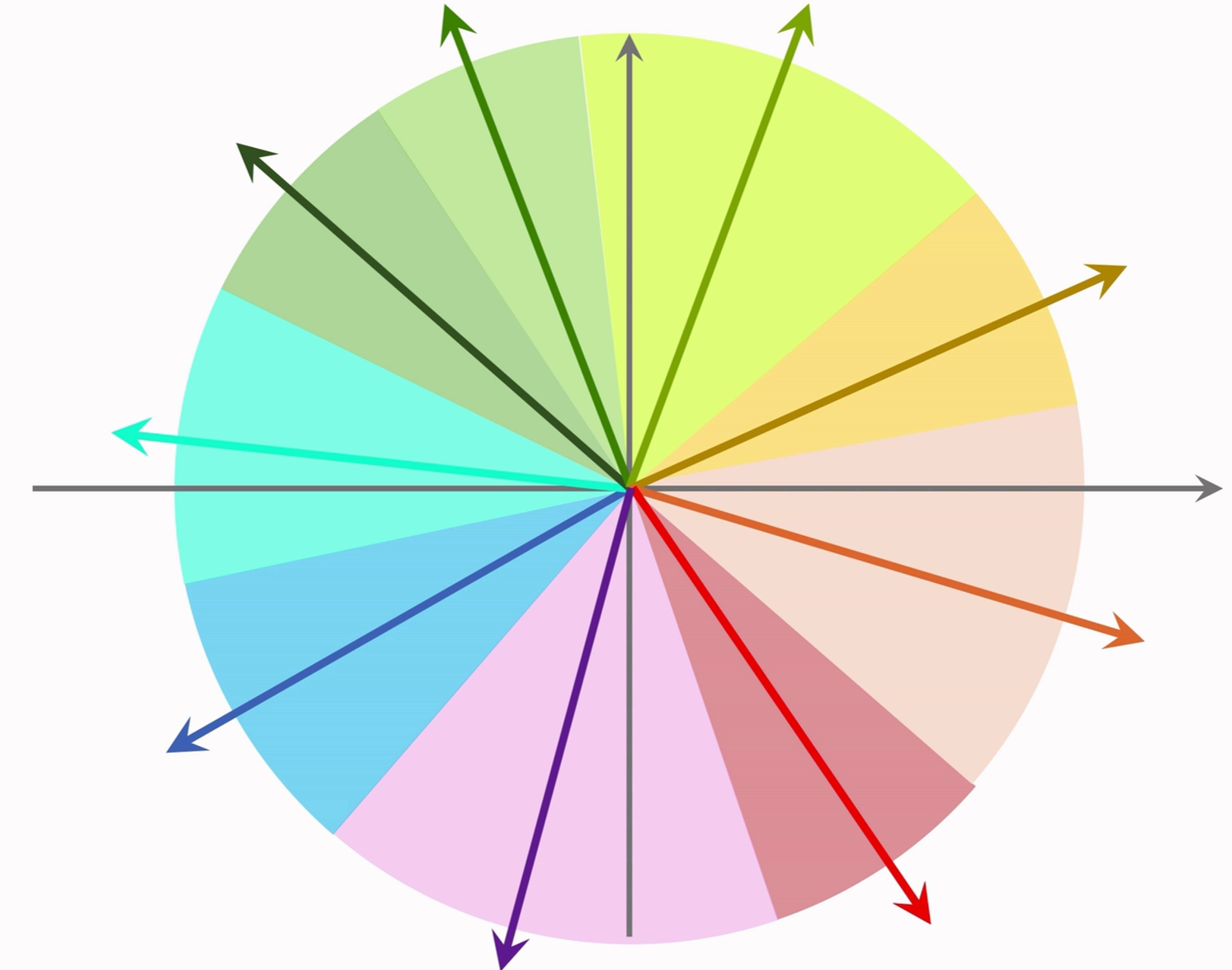
Step 3: 对于需要查找最近邻的向量,将其先与所有的索引向量进行相似度计算,找到目标区域;
Step 4: 借助Step 2中建立的映射,通过目标区域的索引向量获得目标区域内的向量,逐一进行相似度计算。
时间复杂度分析:
逐一暴力对比 O ( n ) O(n) O(n);本方法最优时间复杂度为 O ( n ) O(\sqrt{n}) O(n )。
3.3 双塔模型
3.3.1 用户和物品的表征
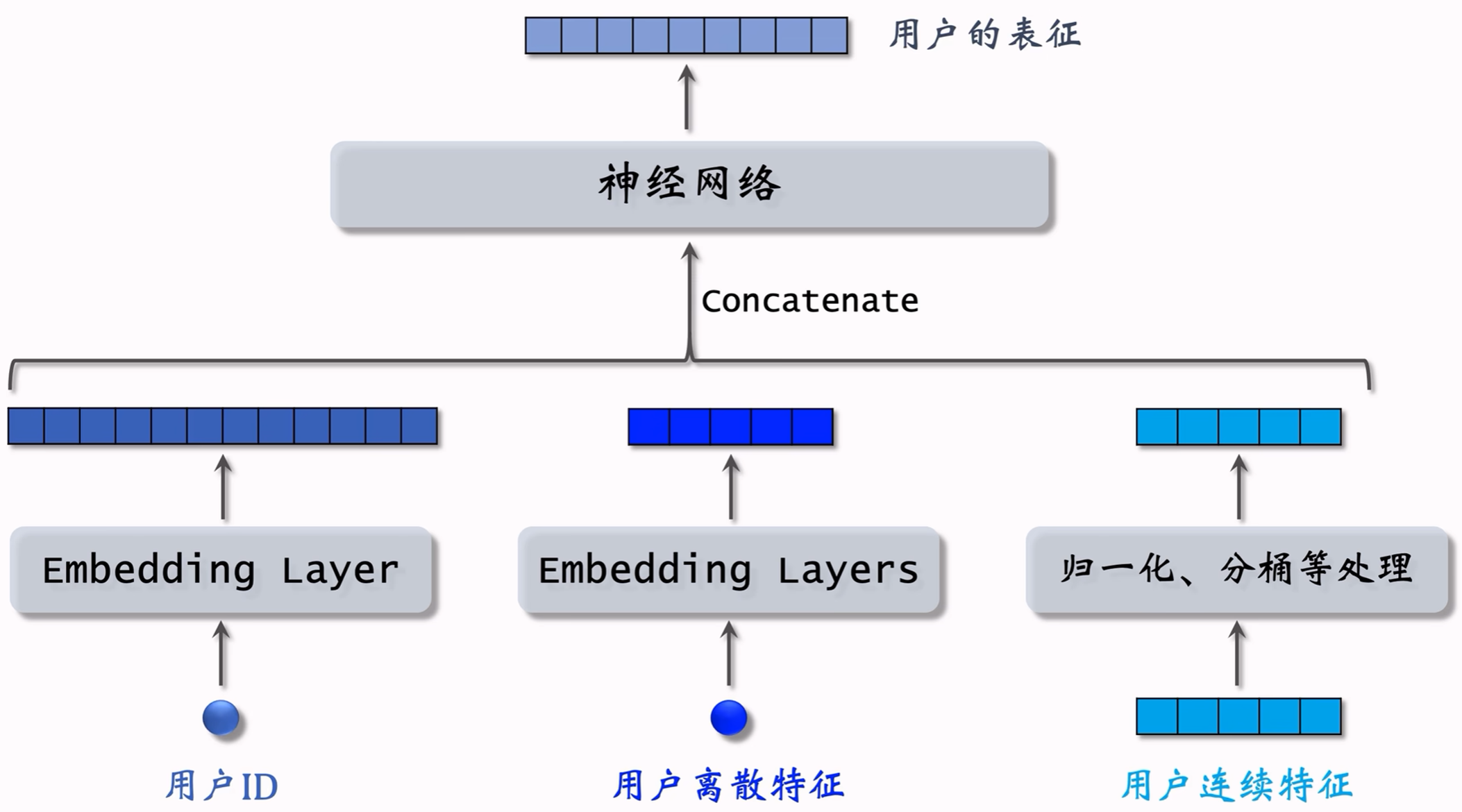
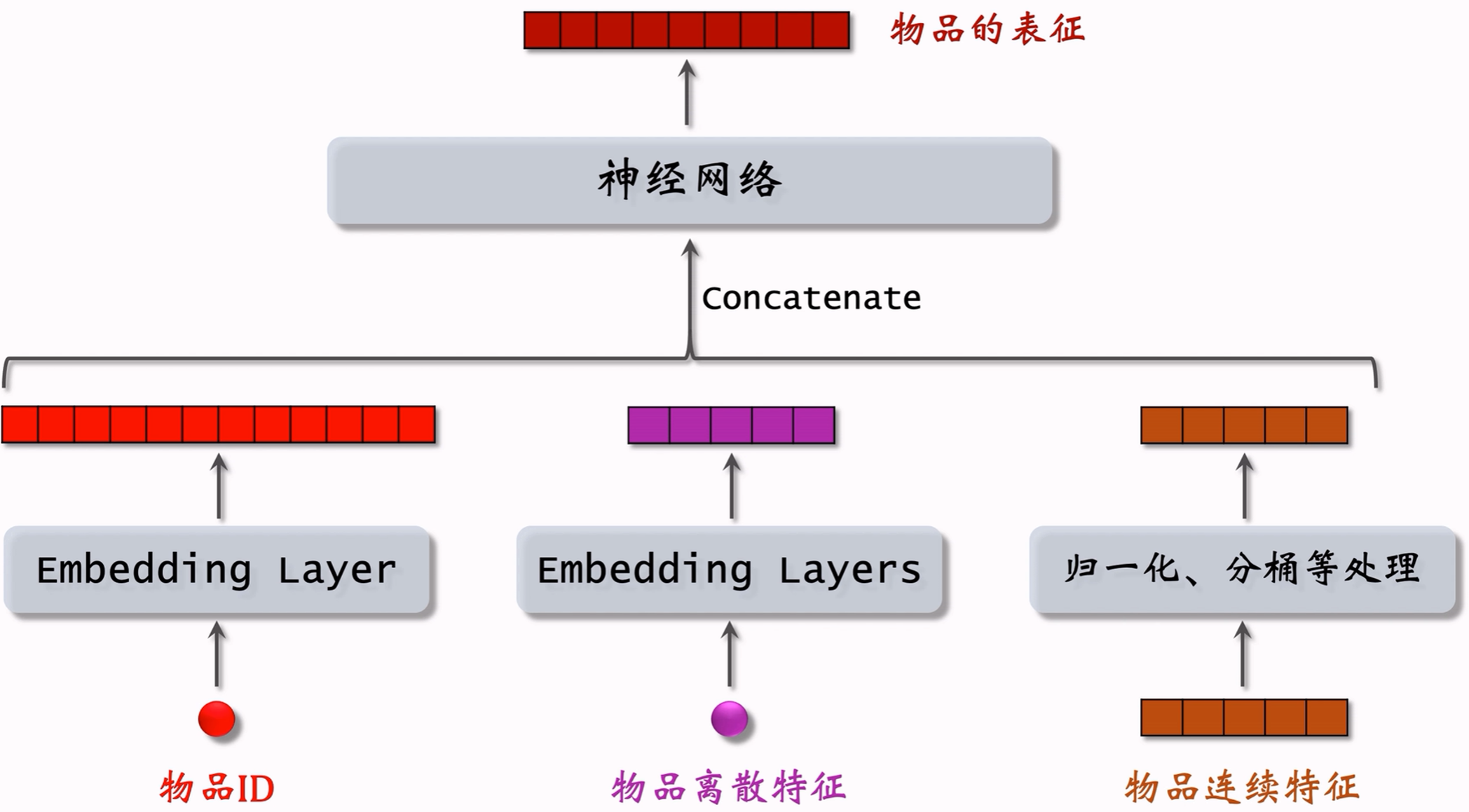
3.3.2 结构
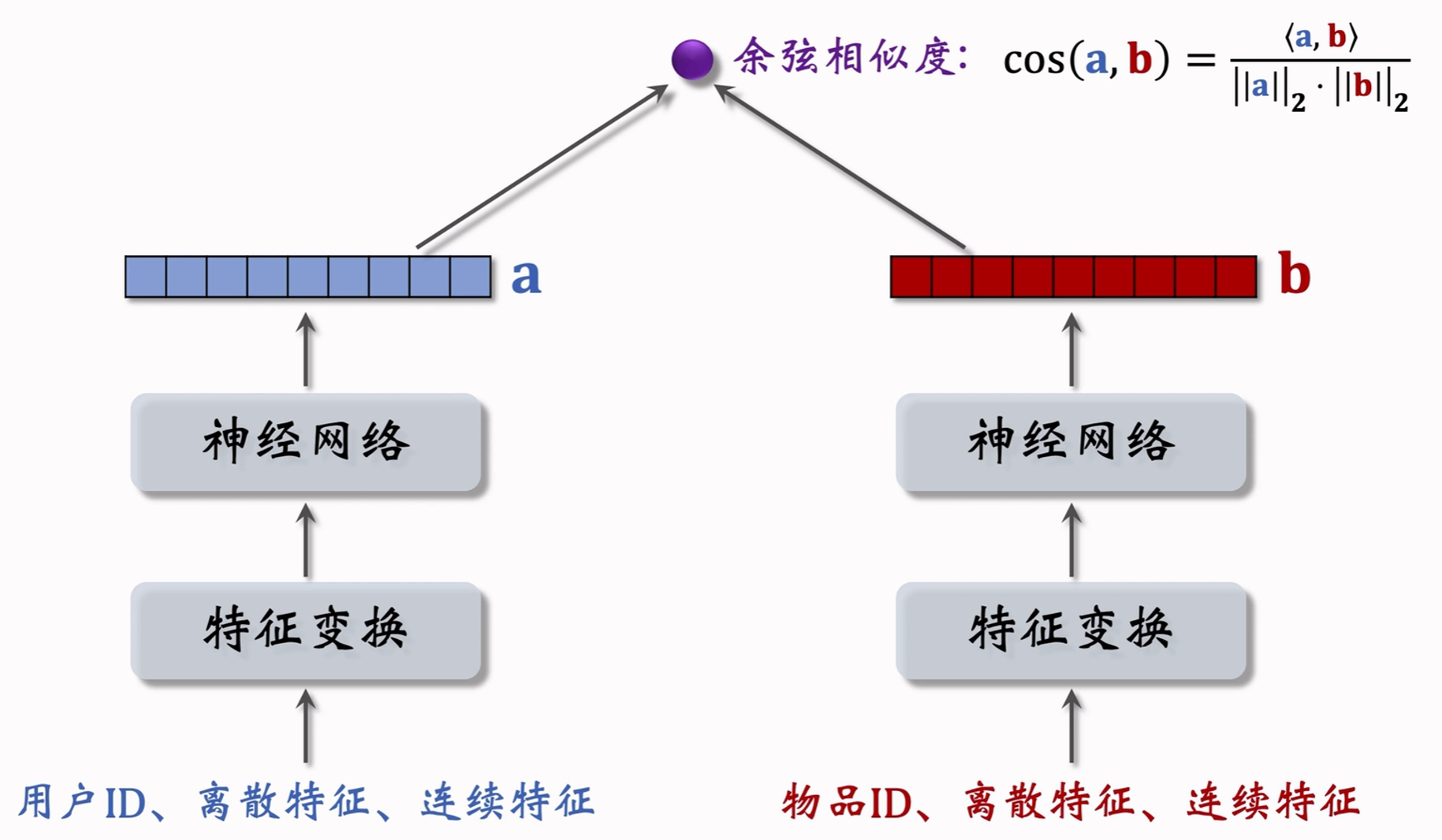
3.3.3 训练
- Pointwise:独立看待每个正样本、负样本,做简单二元分类;
- Pairwise:每次取一个正样本、一个负样本;
- Listwise:每次取一个正样本、多个负样本。
3.3.3.1 Pointwise训练
- 把召回看作二元分类任务;
- 对于正样本,鼓励 cos ( a , b ) \cos(a,b) cos(a,b)接近+1;
- 对于负样本,鼓励 cos ( a , b ) \cos(a,b) cos(a,b)接近-1;
- 控制正负样本数量为1:2或1:3(经验)。
3.3.3.2 Pairwise训练
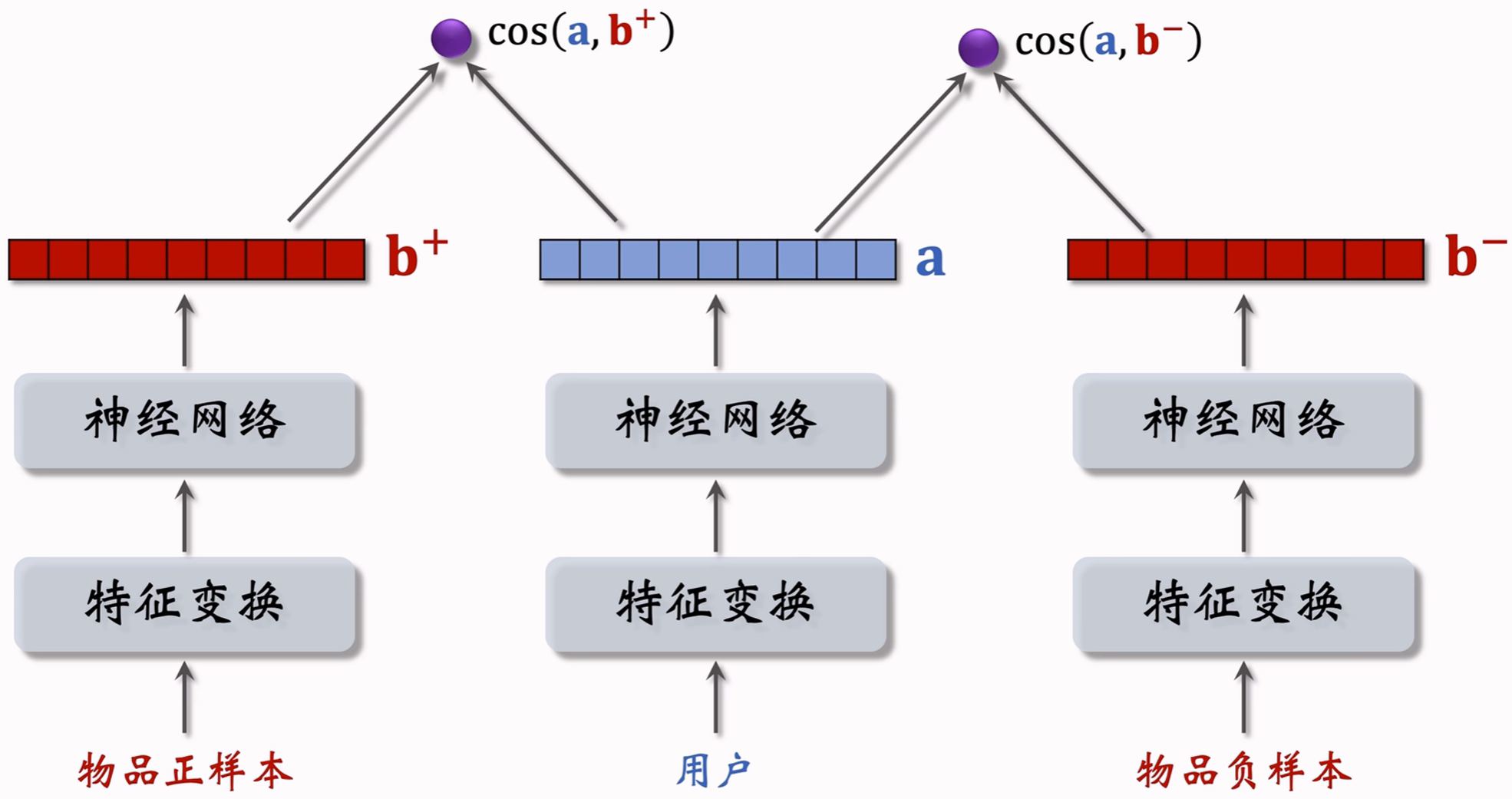
做法:鼓励 cos ( a , b + ) \cos(a,b^+) cos(a,b+)大于 cos ( a , b − ) \cos(a,b^-) cos(a,b−),至少大于 m m m。
若 cos ( a , b + ) \cos(a,b^+) cos(a,b+)大于 cos ( a , b − ) + m \cos(a,b^-)+m cos(a,b−)+m,则损失为0;
否则,损失为 cos ( a , b − ) + m − cos ( a , b + ) \cos(a,b^-)+m-\cos(a,b^+) cos(a,b−)+m−cos(a,b+)。
因此得到Triplet hinge loss:
L ( a , b + , b − ) = max { 0 , cos ( a , b − ) + m − cos ( a , b + ) } L(a,b^+,b^-)=\max\{0,\cos(a,b^-)+m-\cos(a,b^+)\} L(a,b+,b−)=max{0,cos(a,b−)+m−cos(a,b+)}
Triplet logistic loss:
L ( a , b + , b − ) = log ( 1 + exp σ ⋅ ( cos ( a , b − ) − cos ( a , b + ) ) ) L(a,b^+,b^-)=\log(1+\exp\\sigma\\cdot(\\cos(a,b\^-)-\\cos(a,b\^+))) L(a,b+,b−)=log(1+expσ⋅(cos(a,b−)−cos(a,b+)))
σ \sigma σ是超参数,需要人为设置。
3.3.3.3 Listwise训练
一条数据包含:
- 一个用户,特征向量 a a a;
- 一个正样本,特征向量记作 b + b^+ b+;
- 多个负样本,特征向量记作 b 1 − , ⋯ , b n − b_1^-,\cdots,b_n^- b1−,⋯,bn−。
训练目标:鼓励 cos ( a , b + ) \cos(a,b^+) cos(a,b+)尽量大,鼓励所有 cos ( a , b − ) \cos(a,b^-) cos(a,b−)尽量小。
训练方式:
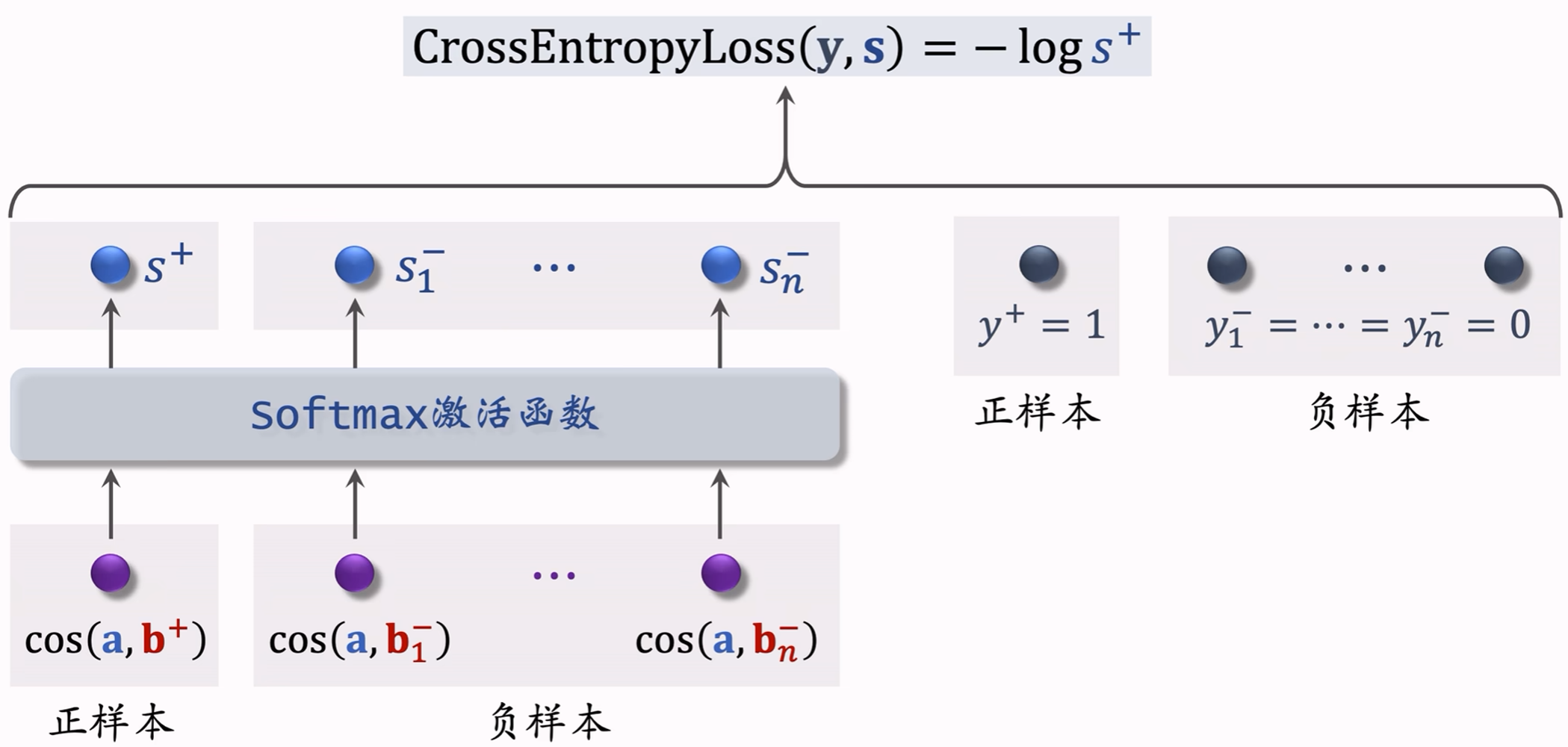
3.3.4 正样本
正样本的选取:曝光且有点击的用户-物品二元组。(用户对物品感兴趣)
问题:少部分物品占据大部分点击,导致正样本大多是热门物品。
解决方案:过采样冷门物品,降采样热门物品。
3.3.5 负样本
负样本的选取:在推荐系统链路上,召回、粗排、精排的过程中没有被选中的样本。
有曝光但没有被用户点击的样本不用于召回。
3.3.5.1 简单负样本
未被召回的物品,大概率是用户不感兴趣的,从数量上约等于全体物品。
因此将全体物品作为简单负样本。
采取均匀抽样的缺点:
- 正样本大多是热门物品;
- 负样本从全体物品中抽取,大多是冷门物品;
- 训练后,会导致热门物品更热门,冷门物品更冷门。
因此采取非均匀抽样:
- 负样本抽样概率与热门程度(点击次数 t t t)正相关;
- 抽样概率 p ∝ t 0.75 p\propto t^{0.75} p∝t0.75,0.75是经验值。
Batch内负样本:
- 一个batch内有 n n n个正样本,每个正样本中用户与物品一一对应。
- 对于每个用户,都能与其他正样本中的物品组成负样本,共 n ( n − 1 ) n(n-1) n(n−1)对负样本。
- 这 n ( n − 1 ) n(n-1) n(n−1)对负样本都是简单负样本。
Batch内负样本的问题:
- 一个物品出现在batch内的概率 p ∝ t p\propto t p∝t;
- 物品成为负样本的概率应当是 p ∝ t 0.75 p\propto t^{0.75} p∝t0.75,但这里是 p ∝ t p\propto t p∝t;
- batch内用户点击的大概率是热门物品,如果 p ∝ t p\propto t p∝t,则对热门物品打压程度过大。
- 解决方案:训练时将 cos ( a , b i ) \cos(a,b_i) cos(a,bi)调整为 cos ( a , b i ) − log p i \cos(a,b_i)-\log p_i cos(a,bi)−logpi。线上召回时无需调整。
3.3.5.2 困难负样本
困难负样本:
- 被粗排淘汰的物品(比较困难);
- 精排分数靠后的物品(非常困难)。
对正负样本做二元分类:
- 全体物品(简单)分类准确率高;
- 被粗排淘汰的物品(比较困难)容易分错;
- 精排分数靠后的物品(非常困难)更容易分错。
3.3.5.3 选择负样本的原理
召回的目标:快速找到用户可能感兴趣的物品。
- 全体物品(简单):绝大多数是用户不感兴趣的;
- 被排序淘汰(困难):用户可能感兴趣,但是不够感兴趣;
- 有曝光但没点击(没用):用户感兴趣,可能碰巧没点击,适用于排序的负样本。
3.3.6 训练数据的组合
- 混合几种负样本;
- 50%的负样本是全体物品(简单负样本);
- 50%的负样本是没通过排序的物品(困难负样本)。
3.3.7 召回流程
3.3.7.1 离线存储
用双塔模型提取物品的特征向量 b b b,存入向量数据库中。
- 完成训练后,用物品塔计算每个物品的特征向量 b b b;
- 把几亿个 b b b存入向量数据库(如Milvus, Faiss, HnswLib);
- 向量数据库建立索引,加速最近邻查找(3.2.3节)。
3.3.7.2 线上召回
- 给定用户ID和画像,线上用神经网络计算用户向量 a a a;
- 把向量 a a a作为query,调用向量数据库做最近邻查找(3.2.3节);
- 返回余弦相似度最大的 k k k个物品,作为召回结果。
为什么不事先存储用户向量 a a a?
- 每次查询只计算一次用户向量,计算开销不大;
- 用户的兴趣是动态变化的,而物品特征相对稳定。
3.3.8 模型更新
3.3.8.1 全量更新
每天凌晨,用上一天全天的数据训练模型。
- 在上一天模型参数的基础上做训练(不是随机初始化);
- 用上一天的数据,训练1个epoch;
- 发布新的用户塔神经网络和物品向量,供线上召回使用;
- 全量更新对数据流、系统的要求比较低。
3.3.8.2 增量更新
做online learning更新模型参数。
- 用户兴趣会随时发生变化;
- 实时收集线上数据,做流式处理,生成TFRecord文件;
- 对模型做online learning,增量更新ID Embedding参数(不更新其他部分的参数);
- 发布用户ID Embedding,供用户塔在线上计算用户向量。
3.3.8.3 模型更新流程
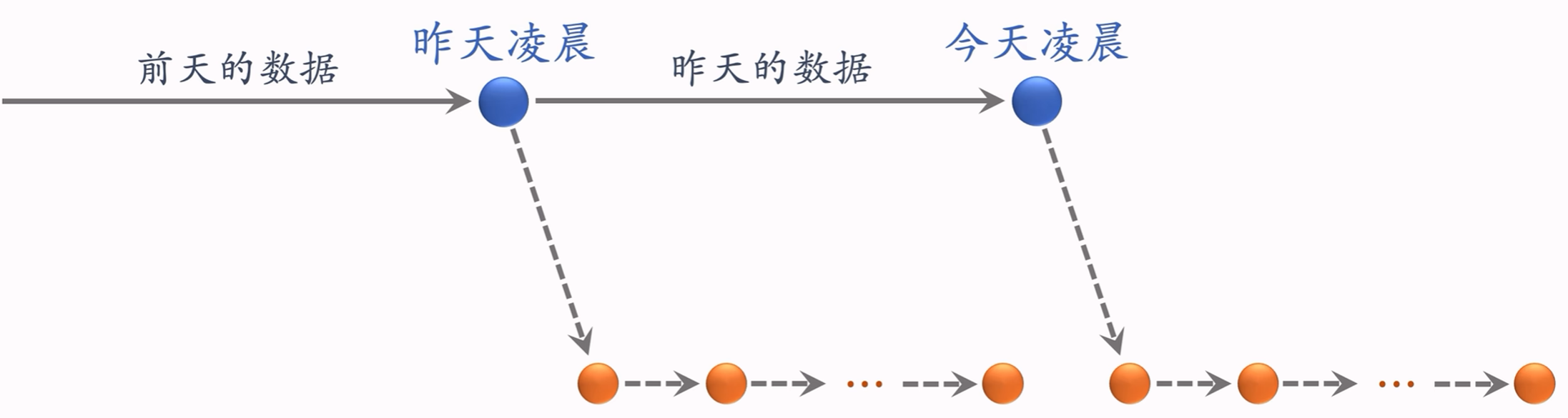
全量更新时,当日增量更新的内容会被舍弃。
为什么不能只做增量更新:
- 小时级数据有偏,分钟级偏差更大;
- 全量会对数据做随机,而增量是按照时间顺序训练,随机优于顺序,因此全量训练优于增量训练。
3.3.9 自监督学习
- 推荐系统头部效应严重(少部分物品占用大部分点击,大部分物品点击次数少)
- 高点击物品表征学的好,长尾物品表征学的不好;
- 用自监督学习:做data augmentation,更好地学习长尾物品的向量表征。
3.3.9.1 目标
有两个不同的物品 i i i和 j j j,有两个不同的变换(变换1和变换2)。
i i i通过变换1得到特征 i ′ i' i′,通过变换2得到特征 i ′ ′ i'' i′′; j j j通过变换1得到特征 j ′ j' j′,通过变换2得到特征 j ′ ′ j'' j′′。
这四个特征通过物品塔分别得到 b i ′ , b i ′ ′ , b j ′ , b j ′ ′ b_i',b_i'',b_j',b_j'' bi′,bi′′,bj′,bj′′。
- 物品 i i i的两个向量表征 b i ′ , b i ′ ′ b_i',b_i'' bi′,bi′′应有较高的相似度,尽管使用的变换不同;
- 物品 i i i和物品 j j j的任意向量表征之间应有较低的相似度。
3.3.9.2 特征变换
- Random Mask: 随机选一些离散特征(如类目),将其遮住。eg. 类目特征{数码,摄影}→{default},然后送入物品塔;
- Dropout:仅对多值离散特征生效,随机丢弃特征中50%的值。eg. 类目特征{数码,摄影}→{数码};
- 互补特征 (complementary):将物品已有 n n n个特征随机分为2组,对于每一组,缺失特征用default填充,得到2个物品表征。eg. 特征{ID,关键词,类目,城市},分为两组:{ID,类目}和{关键词,城市},然后得到两个物品表征:{ID,default,类目,default}和{default,关键词,default,城市},然后一起送入物品塔;
- Mask一组关联的特征:特征之间会有关联,如数码类目的受众性别为男性(3.3.9.3节)。
3.3.9.3 Mask一组关联的特征
特征之间会有关联。令 p ( u ) p(u) p(u)为某特征取值为 u u u的概率; p ( u , v ) p(u,v) p(u,v)为某特征取值为 u u u,另一个特征取值为 v v v,同时发生的概率。
离线计算特征两两之间的关联,用互信息(mutual information)衡量:
M I ( U , V ) = ∑ u ∈ U ∑ v ∈ V p ( u , v ) ⋅ log p ( u , v ) p ( u ) ⋅ p ( v ) MI(U,V)=\sum_{u\in U}\sum_{v\in V} p(u,v)\cdot\log\frac{p(u,v)}{p(u)\cdot p(v)} MI(U,V)=u∈U∑v∈V∑p(u,v)⋅logp(u)⋅p(v)p(u,v)
做法:
- 设共 k k k个特征,离线计算特征两两之间的MI,得到 k × k k\times k k×k的矩阵;
- 随机选一个特征作为种子,找到种子最相关的 k 2 \frac{k}{2} 2k种特征;
- Mask种子及其相关的 k 2 \frac{k}{2} 2k种特征,保留其余的 k 2 \frac{k}{2} 2k种特征。
好处:效果更好;
坏处:方法复杂,实现难度大,不容易维护。
3.3.9.4 自监督损失函数
第 i i i个物品的损失函数为:
L self i = − log ( exp ( cos ( b i ′ , b i ′ ′ ) ) ∑ j = 1 m exp ( cos ( b i ′ , b j ′ ′ ) ) ) L_\text{self}i=-\log(\frac{\exp(\cos(b_i',b_i''))}{\sum_{j=1}^m\exp(\cos(b_i',b_j''))}) Lselfi=−log(∑j=1mexp(cos(bi′,bj′′))exp(cos(bi′,bi′′)))
做梯度下降,减小自监督学习的损失:
1 m ∑ i = 1 m L self i \frac{1}{m}\sum_{i=1}^m L_\text{self}i m1i=1∑mLselfi
3.3.9.5 双塔+自监督训练
- 对点击做随机抽样,得到 n n n对用户-物品二元组,作为一个batch;
- 从全体物品种均匀抽样,得到 m m m个物品,作为一个batch;
- 做梯度下降,使得损失减小。
损失函数:
1 n ∑ i = 1 n L main i + α ⋅ 1 m ∑ j = 1 m L self j \frac{1}{n}\sum_{i=1}^n L_\text{main}i+\alpha\cdot\frac{1}{m}\sum_{j=1}^m L_\text{self}j n1i=1∑nLmaini+α⋅m1j=1∑mLselfj