免费版Java学习笔记(28w字)链接:https://www.yuque.com/aoyouaoyou/sgcqr8
免费版Java面试题(20w字)链接:https://www.yuque.com/aoyouaoyou/wh3hto
完整版Java学习笔记200w字,附有代码实现,图解清楚,仅需9.9
完整版Java面试题,150w字,高频面试题,内容详细,仅需9.9
完整版链接:
https://www.xiaohongshu.com/user/profile/63c2d512000000002601232c
祝您新的一年事事马到成功,身体健康,阖家幸福,大展宏图!
一、BM算法介绍
1.1 定义与定位
BM算法是Boyer-Moore 的缩写,是一种极致高效的滑动式字符串匹配算法 ,也是工业界应用广泛的经典算法;它针对BF算法的低效、RK算法哈希设计的痛点做了针对性优化,通过智能滑动规则跳过无意义的匹配,大幅减少比对次数。
1.2 解决的问题
BF算法暴力逐位匹配导致最坏时间复杂度O(n×m),RK算法依赖哈希设计且难以适配任意字符,而BM算法通过倒序匹配+滑动规则,解决了前两种算法的痛点:
- 避免逐位暴力比对,利用规则让模式串一次性滑动多位,跳过肯定无法匹配的情况;
- 无需哈希计算,直接基于字符本身做匹配,适配任意字符类型,无哈希冲突/溢出风险;
- 实际场景中匹配效率远超BF和RK,甚至优于KMP算法。
1.3 设计理念
- 倒序匹配 :与BF/RK的正序匹配不同,BM算法从模式串的末尾向前倒着与主串比对,这种方式能快速定位不匹配的字符,为后续滑动提供依据;
- 滑动匹配 :当发现字符不匹配时,不只是向后滑动1位,而是通过特定规则计算滑动位数,一次性滑动多位,从根本上减少匹配轮次;
- 双规则驱动 :通过坏字符规则 和好后缀规则共同决定滑动位数,取两者中的最大值,既保证滑动的有效性,又避免漏匹配。
1.4 应用场景
BM算法因高效的匹配性能,是文本检索的算法选择之一,典型应用:
- 文本编辑器的查找/替换功能(如Notepad++、VS Code的字符串查找);
- 海量文本的关键字匹配、搜索引擎的基础字符串检索;
- 替代BF/RK的所有场景,尤其适合长主串+中短模式串的匹配场景。
二、BM算法规则(坏字符+好后缀)
BM算法的是两个滑动规则------坏字符规则 (基础)和好后缀规则(优化),两者结合使用,共同决定模式串的滑动位数。
2.1 坏字符规则(Bad Character Rule)
概念
在倒序匹配 过程中,首次发现的主串中不匹配的字符 ,称为坏字符(注意:坏字符是主串中的字符,不是模式串的)。
逻辑
- 倒序比对时,找到坏字符后,记录其在模式串中对应的下标si(即模式串中与坏字符对齐的那个字符的下标);
- 查找坏字符是否在模式串中存在:
-
- 若存在,记录坏字符在模式串中最后一次出现的下标xi;
- 若不存在,令xi = -1;
- 计算模式串的滑动位数 = si - xi,将模式串向后滑动对应位数,再重新从末尾倒序匹配。
两个示例
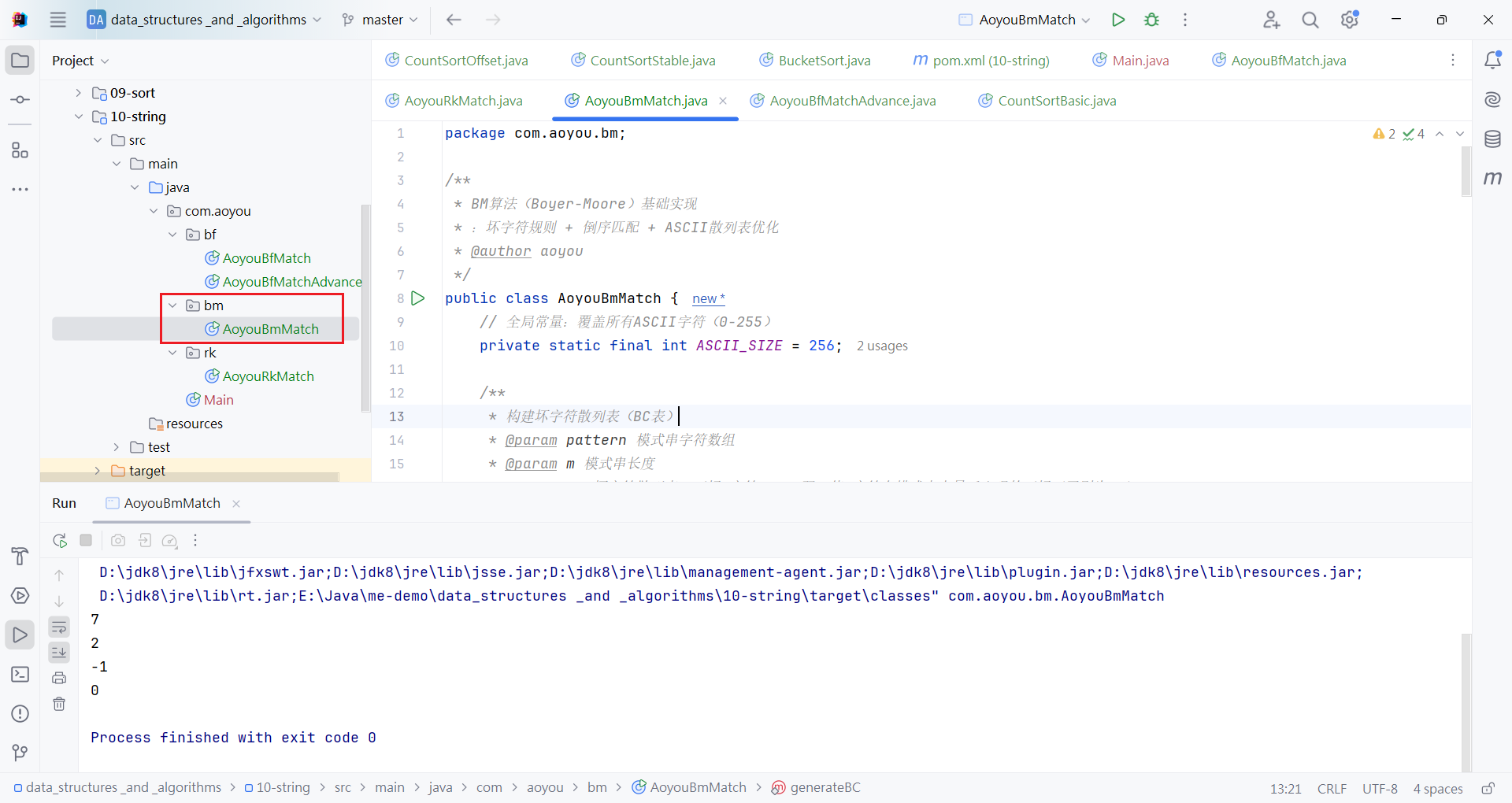
示例1:坏字符在模式串中不存在(以主串aoyouabcde、模式串abc为例)
- 倒序比对时,主串中的
y与模式串末尾的c不匹配,y是坏字符; y在模式串abc中无匹配,xi=-1,模式串中对应下标si=2;- 滑动位数=2 - (-1)=3,模式串直接向后滑动3位,跳过与
y重合的所有位置。
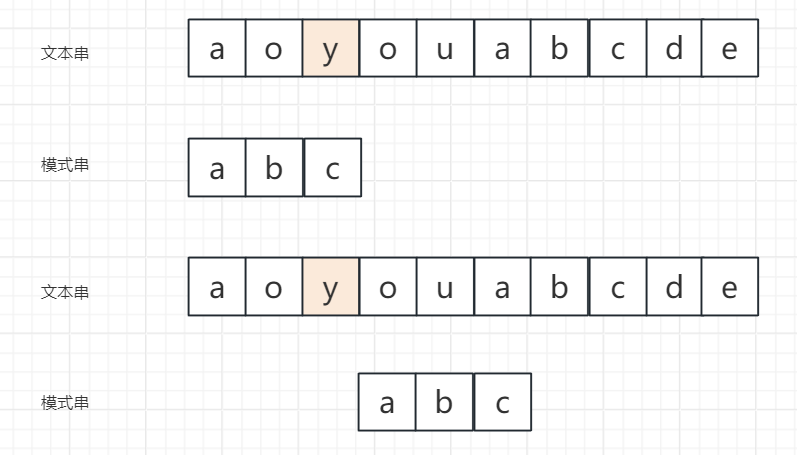
示例2:坏字符在模式串中存在(以主串aoaouabcde、模式串abc为例)
- 倒序比对时,主串中的
a与模式串的c不匹配,a是坏字符; a在模式串中最后出现的下标xi=0,模式串中对应下标si=2;- 滑动位数=2 - 0=2,模式串向后滑动2位,让主串和模式串的
a上下对齐,再重新匹配。
关键优化:散列表快速查找xi
若暴力遍历模式串查找坏字符的xi,会降低效率,因此采用ASCII散列表优化:
- 创建长度为256的数组(覆盖所有ASCII字符),数组下标对应字符的ASCII码,数组值对应字符在模式串中最后一次出现的下标;
- 模式串中不存在的字符,数组值初始化为-1;
- 查找坏字符的xi时,直接通过
数组[坏字符ASCII码]获取,时间复杂度(1)。
2.2 好后缀规则(Good Suffix Shift)
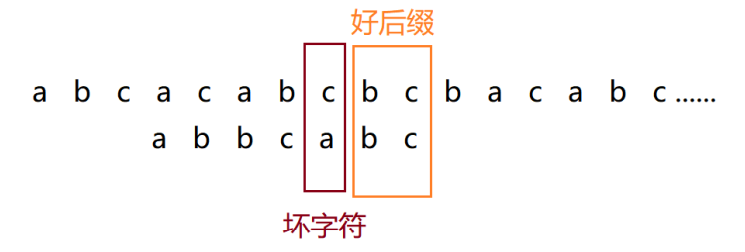
概念
倒序匹配时,坏字符之前已经匹配成功的模式串后缀子串 ,称为好后缀(记为{u});好后缀规则是为了利用已匹配的有效信息,进一步优化滑动位数,避免漏匹配。
逻辑
-
找到好后缀{u}后,在模式串的前缀部分 查找是否存在另一个与{u}完全匹配的子串{u'};
-
-
若存在,将模式串滑动到{u'}与主串中的{u}对齐的位置,重新匹配;
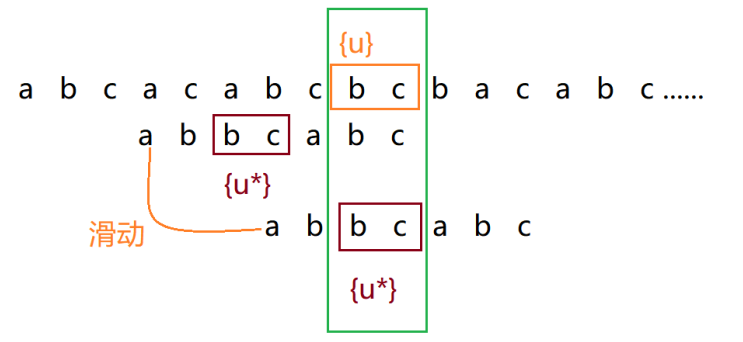
-
若不存在,继续检查好后缀的后缀子串(c) 是否与模式串的前缀子串(c) 匹配(避免过度滑动导致漏匹配);
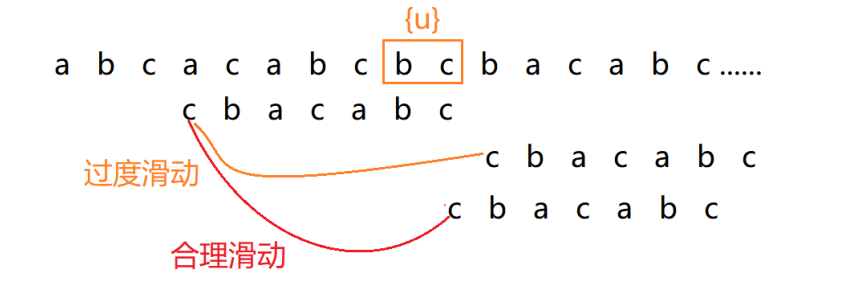
-
- 若上述情况均不满足,直接将模式串滑动到主串中{u}的后方,跳过所有与{u}重合的位置。
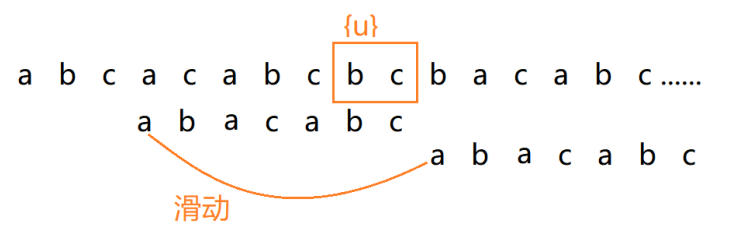
价值
弥补坏字符规则的不足:当模式串中存在大量重复字符时,坏字符规则的滑动位数可能很小,好后缀规则能基于已匹配的有效信息,让模式串滑动更多位,进一步提升效率。
2.3 滑动位数的最终选择
分别通过坏字符规则和好后缀规则计算出两个滑动位数,取两者中的最大值作为模式串最终的滑动位数:
- 原因:保证滑动的有效性,既不会因滑动位数太小导致无意义匹配,也不会因滑动位数太大导致漏匹配。
三、BM算法代码实现
3.1 基础实现:坏字符规则(基础)
基于ASCII散列表实现坏字符规则,是BM算法的基础版本,代码简洁且能体现思路,适配所有ASCII字符匹配,返回主串中模式串首次匹配的起始下标(无匹配返回-1):
/**
* BM算法(Boyer-Moore)基础实现
* :坏字符规则 + 倒序匹配 + ASCII散列表优化
* @author aoyou
*/
public class AoyouBmMatch {
// 全局常量:覆盖所有ASCII字符(0-255)
private static final int ASCII_SIZE = 256;
/**
* 构建坏字符散列表(BC表)
* @param pattern 模式串字符数组
* @param m 模式串长度
* @param bc 坏字符散列表:下标=字符ASCII码,值=字符在模式串中最后出现的下标(无则为-1)
*/
private static void generateBC(char[] pattern, int m, int[] bc) {
// 1. 初始化散列表:所有字符默认值-1(表示模式串中无该字符)
for (int i = 0; i < ASCII_SIZE; i++) {
bc[i] = -1;
}
// 2. 遍历模式串,更新散列表:重复字符覆盖为最后一次出现的下标
for (int i = 0; i < m; i++) {
int asciiCode = (int) pattern[i]; // 获取字符的ASCII码
bc[asciiCode] = i; // 记录字符最后出现的下标
}
}
/**
* BM算法匹配方法(坏字符规则版)
* @param main 主串
* @param pattern 模式串
* @return 主串中模式串首次匹配的起始下标,无匹配返回-1
*/
public static int bmMatchByBadChar(String main, String pattern) {
// 边界校验:空值、模式串更长,直接返回-1
if (main == null || pattern == null || pattern.length() > main.length()) {
return -1;
}
char[] mainArr = main.toCharArray();
char[] patternArr = pattern.toCharArray();
int n = mainArr.length; // 主串长度
int m = patternArr.length; // 模式串长度
// 1. 构建坏字符散列表
int[] bc = new int[ASCII_SIZE];
generateBC(patternArr, m, bc);
int i = 0; // i:主串与模式串对齐的起始下标(滑动变量)
// 循环条件:模式串与主串有重合部分
while (i <= n - m) {
int j;
// 2. 倒序匹配:从模式串末尾向前比对(j从m-1到0)
for (j = m - 1; j >= 0; j--) {
// 主串当前字符:mainArr[i+j],模式串当前字符:patternArr[j]
if (mainArr[i + j] != patternArr[j]) {
break; // 找到坏字符,退出比对,j为坏字符在模式串中的下标si
}
}
// 3. 匹配成功:j<0表示所有字符都匹配
if (j < 0) {
return i;
}
// 4. 计算滑动位数,更新i:滑动位数 = si - xi(xi是坏字符在模式串中的最后下标)
int badCharAscii = (int) mainArr[i + j]; // 坏字符的ASCII码
i = i + (j - bc[badCharAscii]);
}
// 无匹配,返回-1
return -1;
}
// 测试示例
public static void main(String[] args) {
// 测试用例1:正常匹配(主串含aoyou,模式串为aoyou)
String main1 = "java123aoyoupython456";
String pattern1 = "aoyou";
System.out.println(bmMatchByBadChar(main1, pattern1)); // 输出7(aoyou的起始下标)
// 测试用例2:原示例用例(主串abcabcabc,模式串cab)
String main2 = "abcabcabc";
String pattern2 = "cab";
System.out.println(bmMatchByBadChar(main2, pattern2)); // 输出1
// 测试用例3:无匹配
String main3 = "bmalgorithm123";
String pattern3 = "test";
System.out.println(bmMatchByBadChar(main3, pattern3)); // 输出-1
// 测试用例4:模式串与主串完全一致
String main4 = "aoyou";
String pattern4 = "aoyou";
System.out.println(bmMatchByBadChar(main4, pattern4)); // 输出0
}
}
3.2 扩展:好后缀规则的补充说明
上述代码仅实现了坏字符规则(工业界基础场景已足够用),好后缀规则是对坏字符规则的优化,实现相对复杂(需构建好后缀规则表),补充点:
- 好后缀规则实现步骤:
-
- 预处理模式串,构建好后缀规则表(suffix数组+prefix数组),记录好后缀的匹配位置和前缀匹配情况;
- 倒序匹配找到好后缀后,通过规则表计算滑动位数;
- 最终滑动位数计算 :
最终滑动位数 = Math.max(坏字符滑动位数, 好后缀滑动位数); - 实现价值:在模式串含大量重复字符时,好后缀规则能让滑动位数更大,匹配效率更高,避免坏字符规则的低效情况。
四、BM算法特点
4.1 优点
- 效率极致:平均时间复杂度O(n/m),是所有基础字符串匹配算法中效率最高的,长主串场景下优势尤为明显;
- 适配性强:无需哈希计算,直接基于字符ASCII码匹配,支持任意ASCII字符,无哈希冲突/溢出风险;
- 空间开销小:仅需固定大小的散列表,空间复杂度O(1),适合嵌入式、低内存场景;
- 规则实用:坏字符规则实现简单且能覆盖90%以上的业务场景,无需实现复杂的好后缀规则。
4.2 局限性
- 最坏情况效率退化:模式串和主串含大量重复字符时,滑动位数为1,退化为,但实际场景极少出现;
- 好后缀规则实现复杂:好后缀规则的预处理(构建suffix/prefix数组)逻辑较繁琐,增加开发和调试成本;
- 仅支持单模式串匹配:无法直接支持多模式串的批量匹配,多模式串场景需使用AC自动机等算法。
4.3 建议
- 优先实现坏字符规则 :工业界绝大多数业务场景中,仅实现坏字符规则的BM算法已足够用,既能保证高效,又能降低实现复杂度;
- 边界校验必须做:匹配前需校验主串/模式串是否为空、模式串是否比主串长,避免数组越界和无意义循环;
- 适配非ASCII字符 :若需匹配中文、特殊符号等非ASCII字符,可将散列表的大小从256改为65536(覆盖Unicode基本平面),其余逻辑不变;
- 替换BF/RK算法:所有BF/RK的应用场景,均可替换为BM算法(坏字符版),实现成本略高但性能提升显著;
- 文本检索首选:开发文本编辑器、日志检索、关键字匹配等功能时,优先使用BM算法,契合工业界主流实现。
五、总结
- BM算法是高效的滑动式字符串匹配算法 ,为倒序匹配+智能滑动规则,应用广泛(如文本编辑器查找功能);
- BM算法由坏字符规则 (基础)和好后缀规则(优化)组成,滑动位数取两者的最大值,坏字符规则实现简单且适配大部分场景;
- 坏字符规则的是ASCII散列表优化 ,通过散列表查找坏字符在模式串中的最后下标,滑动位数公式为
si - xi(si为坏字符在模式串的对应下标,xi为坏字符在模式串的最后下标); - BM算法平均时间复杂度(效率极致),最坏时间复杂度(极少出现),空间复杂度;
- 生产环境中优先实现坏字符规则版BM算法,无需实现复杂的好后缀规则,即可满足绝大多数业务场景的性能需求。