Mysql数据库
Mysql数据库简介
MySQL 是一款开源的关系型数据库管理系统,即:
-
关系型: 数据以表的形式存储,表与表之间可以通过字段建立关联。
-
开源:核心版本免费使用,这也是它普及的关键原因。
-
跨平台:支持 Windows、Linux、macOS 等主流操作系统,适配性极强。
MySQL 的核心特点:
-
轻量高效:安装包小、资源占用低,启动快,适合从小型应用到大型系统的各种场景。
-
易用性强:SQL 语法标准且简单,新手容易上手,社区文档和教程丰富。
-
高可靠性:支持事务(ACID 特性)、备份恢复、主从复制(读写分离),保障数据安全和服务稳定。
-
兼容性好:支持多种编程语言(Python、Java、PHP、C# 等),几乎所有主流开发框架都能无缝对接。
-
生态完善:有大量配套工具(如 phpMyAdmin、Navicat、MySQL Workbench),且被 Oracle 官方维护,更新迭代稳定。
MySQL 与其他数据库的简单对比:
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| MySQL | 开源免费、轻量高效 | 中小型应用、网站、一般企业系统 |
| Oracle | 商用、功能强、高并发 | 大型金融、政企核心系统 |
| SQL Server | 微软出品、适配 Windows | .NET 开发、Windows 服务器环境 |
| SQLite | 嵌入式、无服务器 | 移动端 APP、本地小型应用 |
Mysql数据库的安装
下载安装包
-
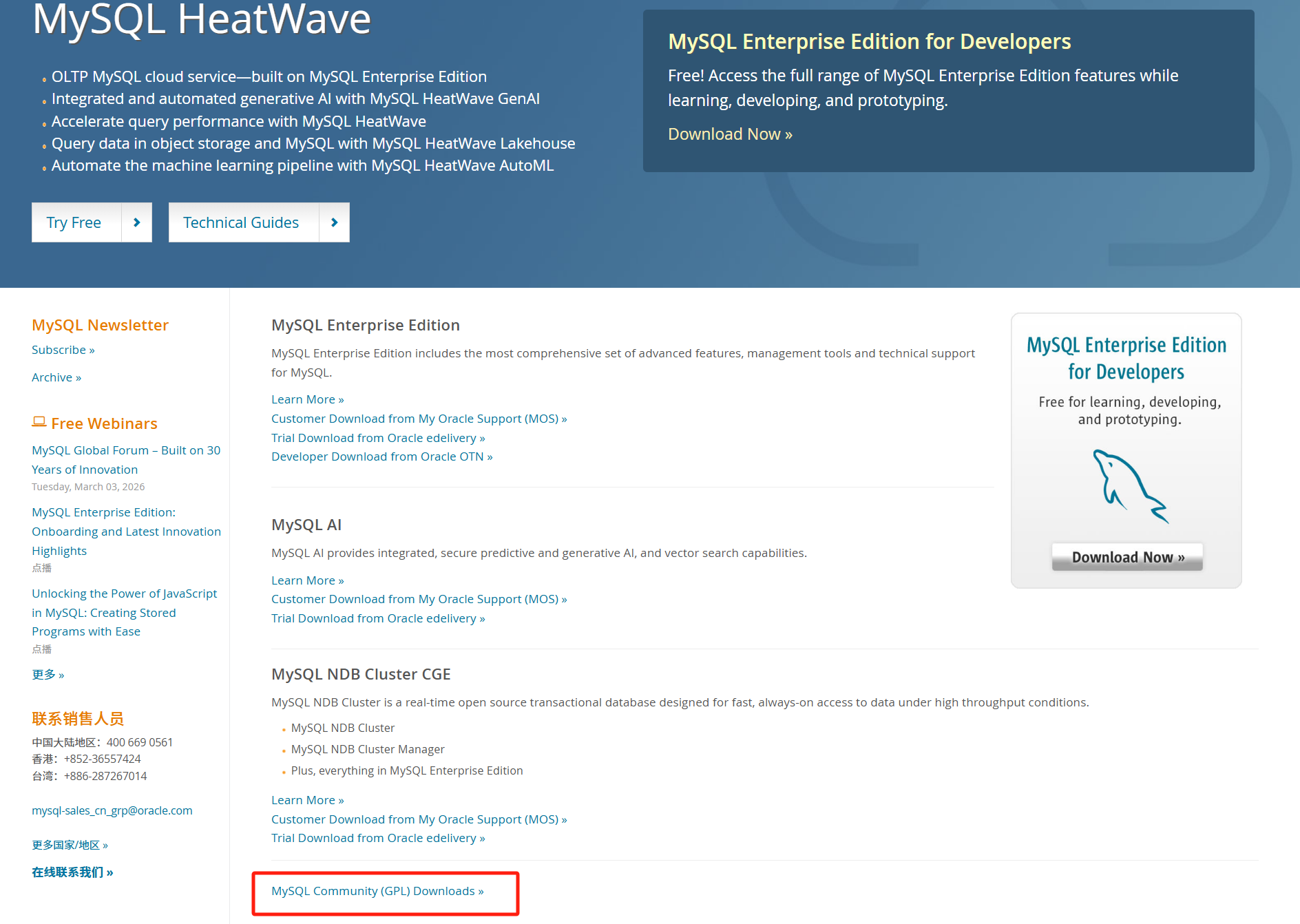
首先去官网下载Mysql的安装包,官网链接:https://www.mysql.com/cn/downloads/
-
点击下列红色链接进去:
-
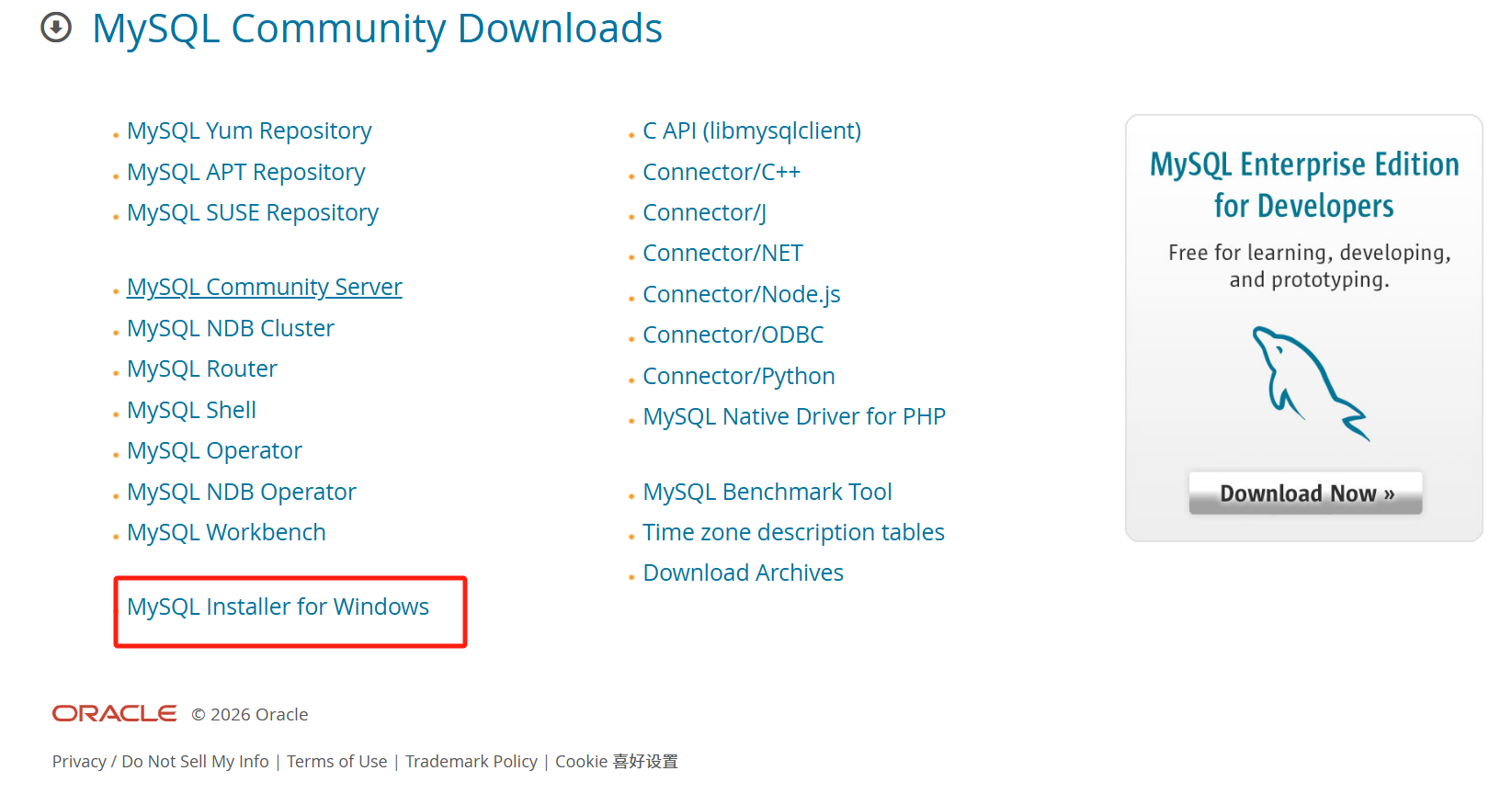
找到MySQL Installer for Windows并点击,如下所示:
-
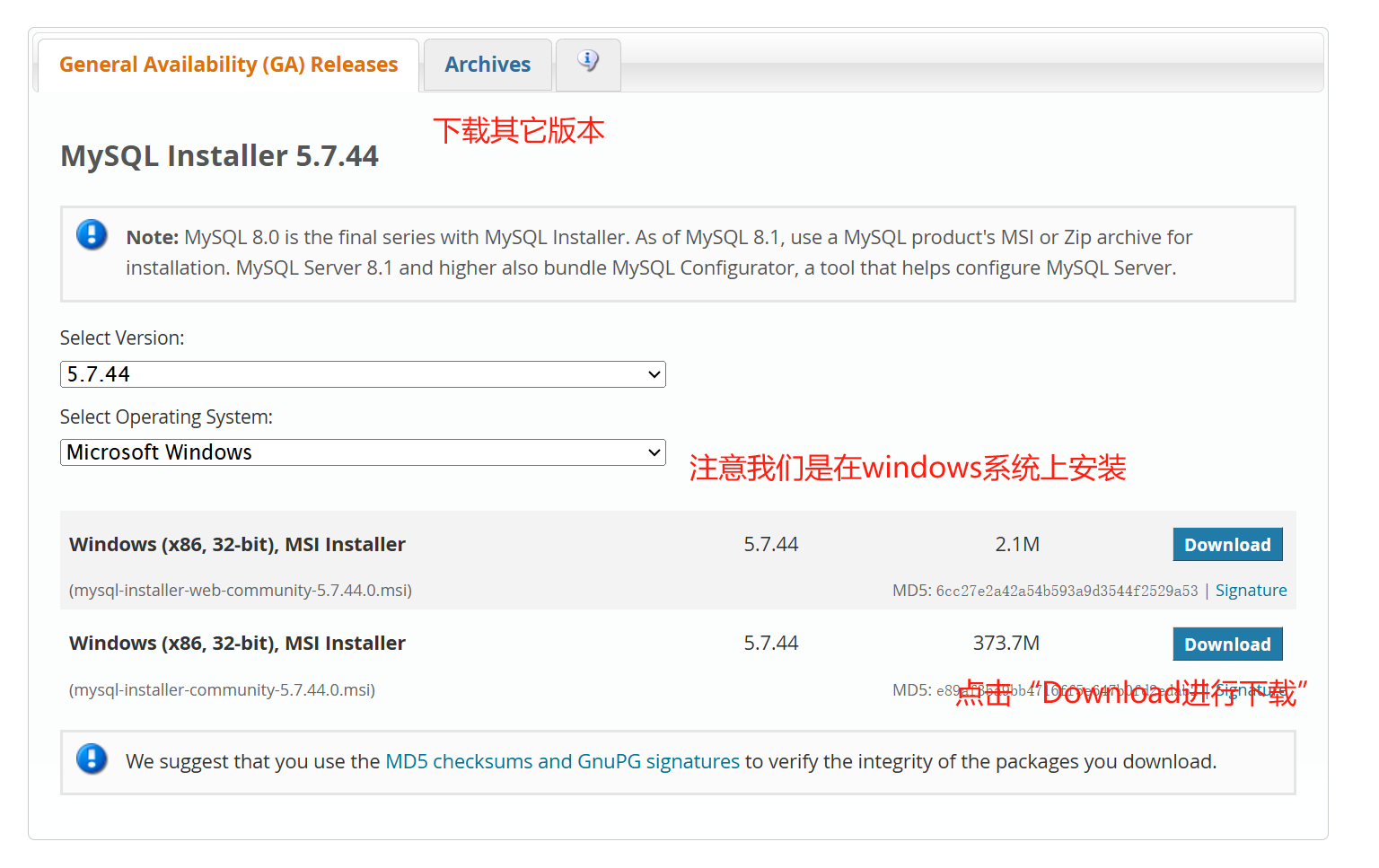
进入下一个页面后,我们可以选择下载最新的版本,当然也可以点击Archives 选择其它版本进行下载。这里我们下载5.7版本,点击下列第二个Download 即可,如下所示:
至此,我们的安装白已经下载完成,下面进行安装。
安装配置
-
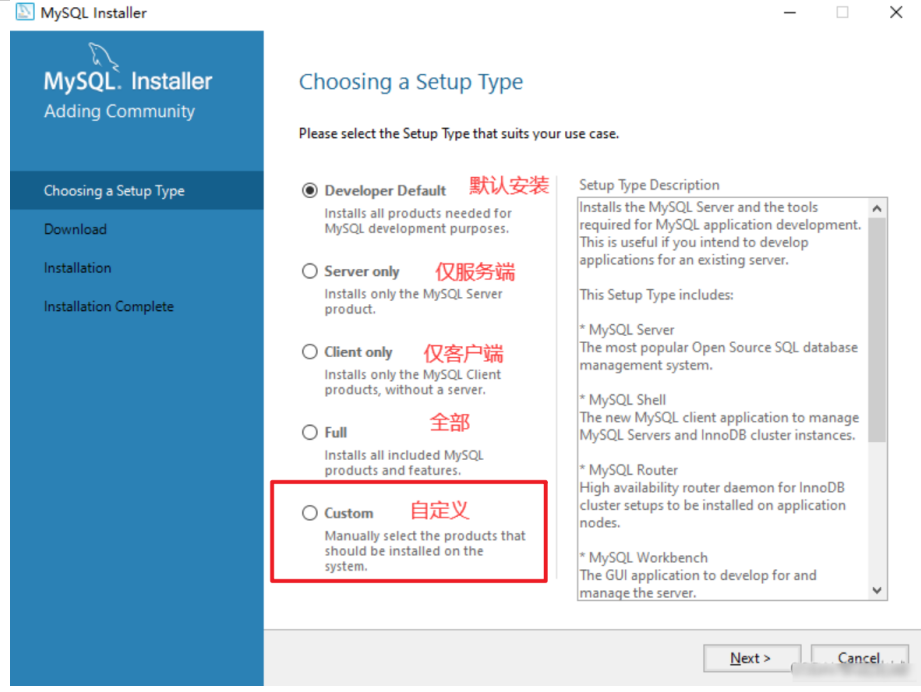
双击下载的文件启动安装流程。
-
进入下列页面后,选择"自定义安装"
-
选择与我们下载的数据库
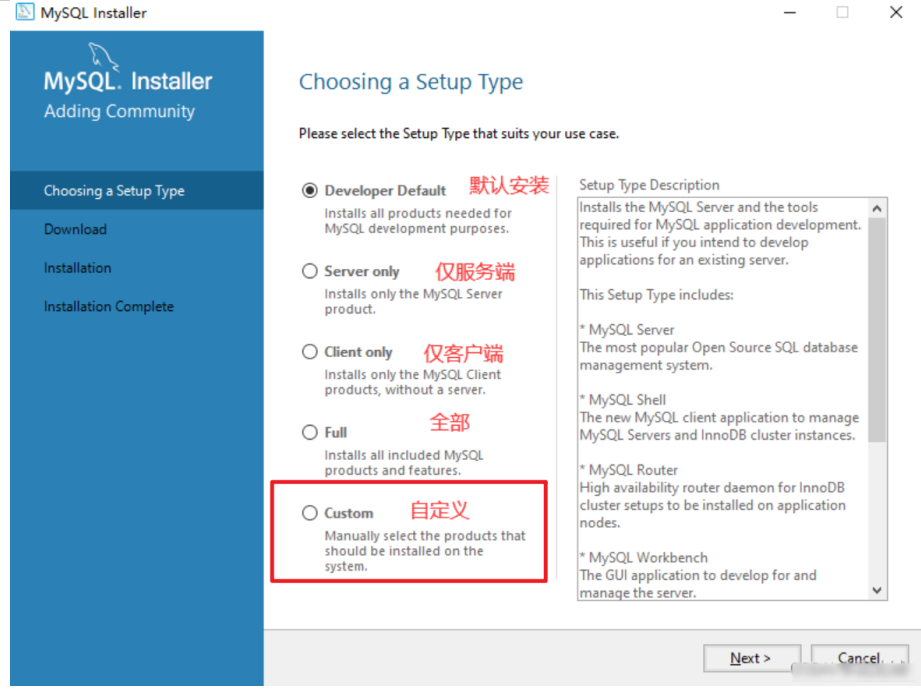
-
左边显示灰色,右边显示黑色时即可,如下:
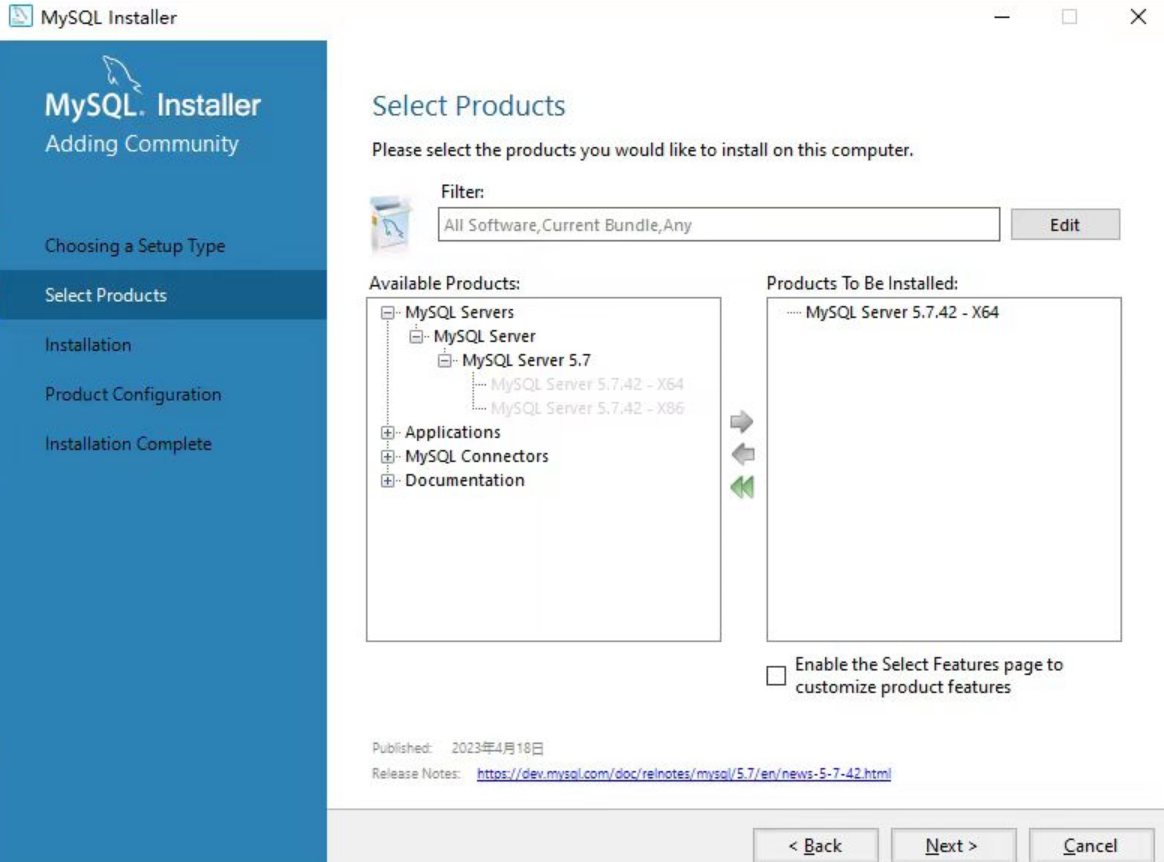
-
完上一步操作之后,会出现一个箭头所指的按钮,点击可切换MySQL的安装位置,如图所示:
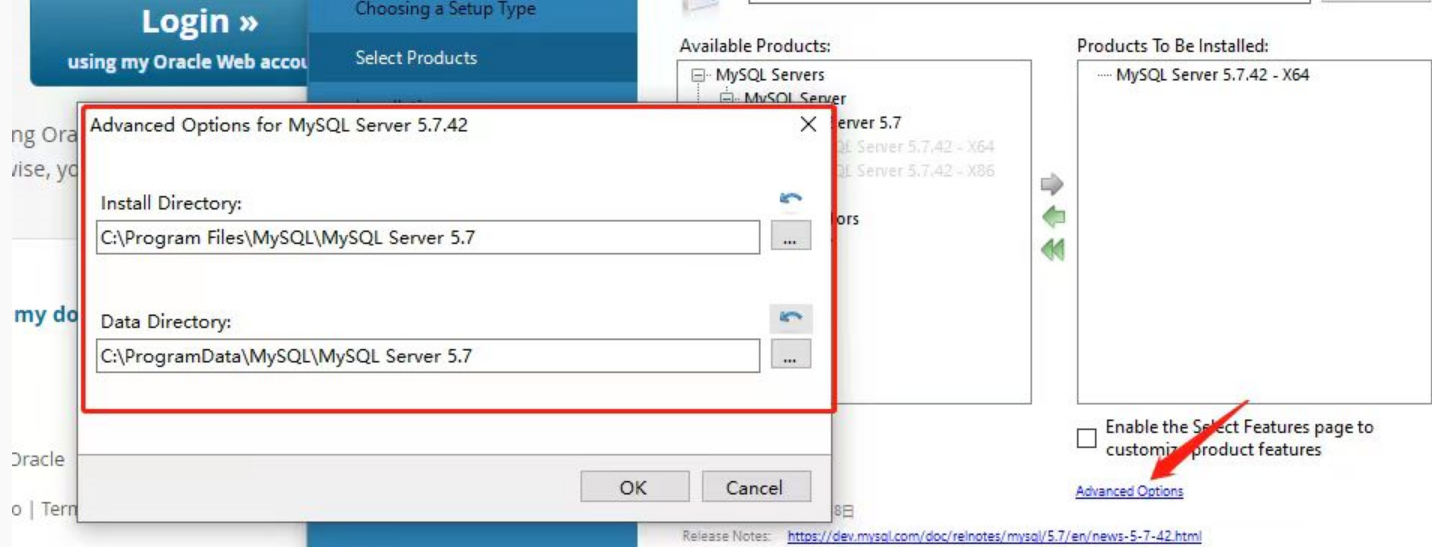
-
切换好位置之后,点击Execute执行安装即可,如下:
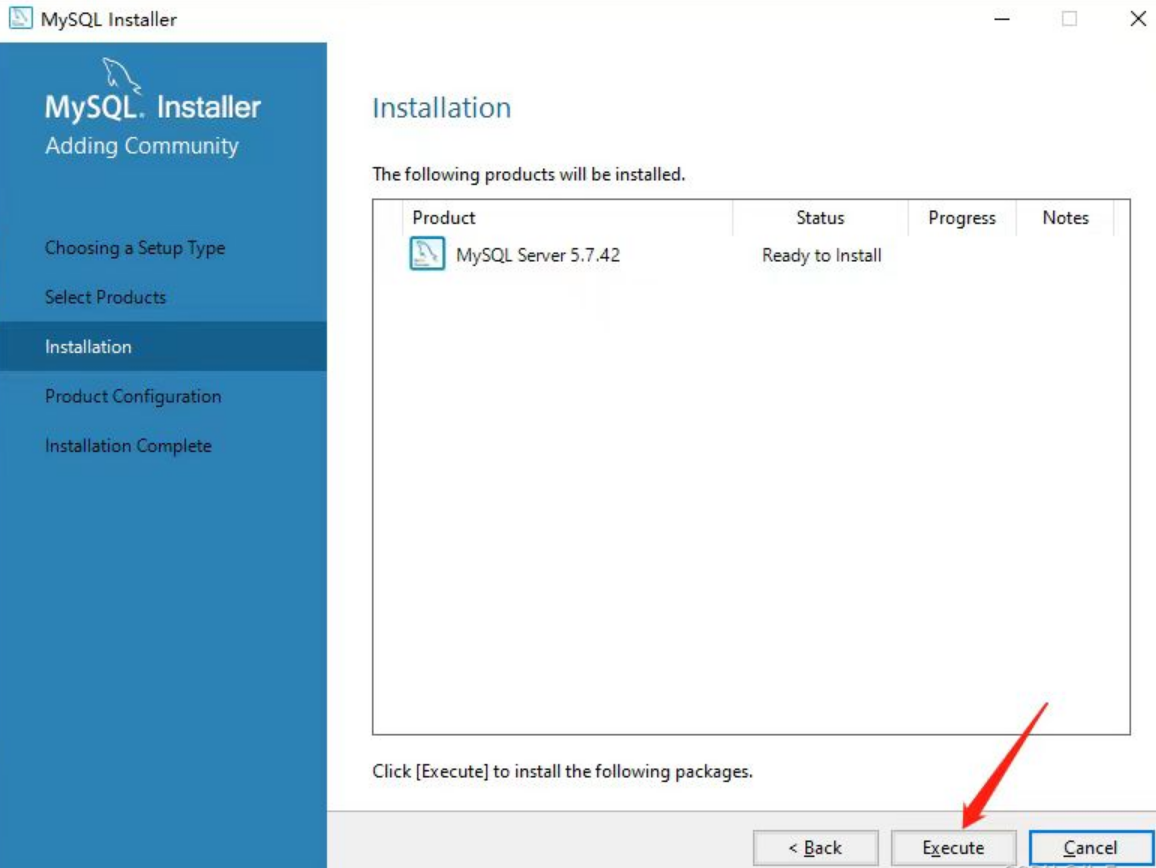
-
安装好后点击Next,如下即可:
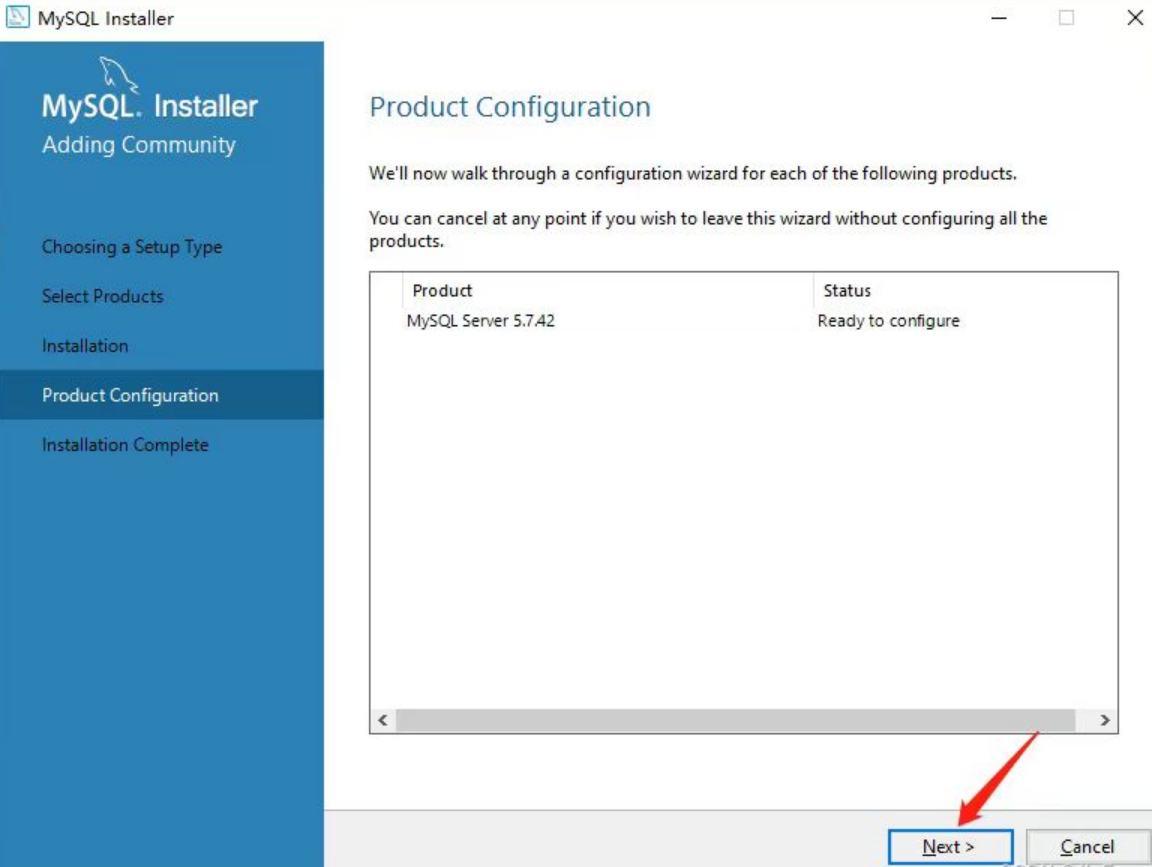
-
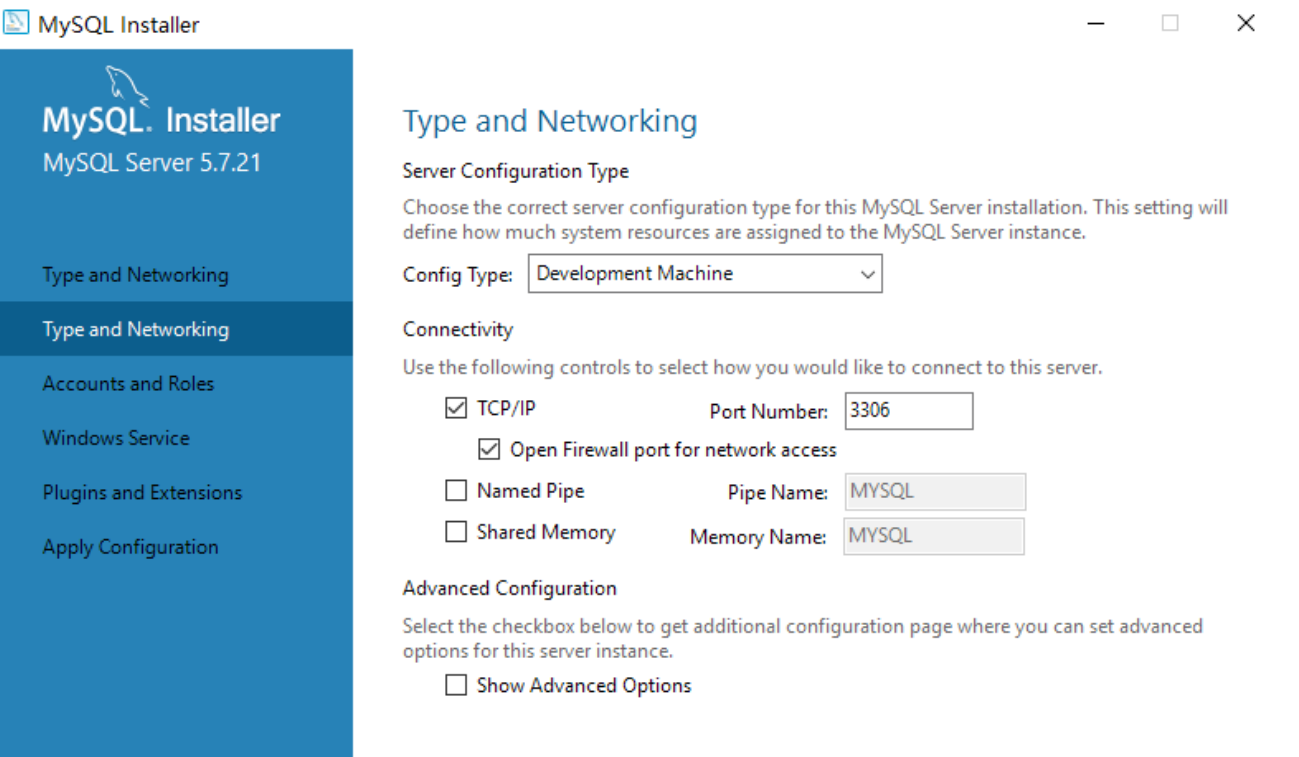
接下来开始配置端口号,如果之前安装过其他版本的MySQL或者MariaDB,3306端口可能会被占用,我们可以设置其他的端口号,但这里建议端口号设置3306,如下所示:
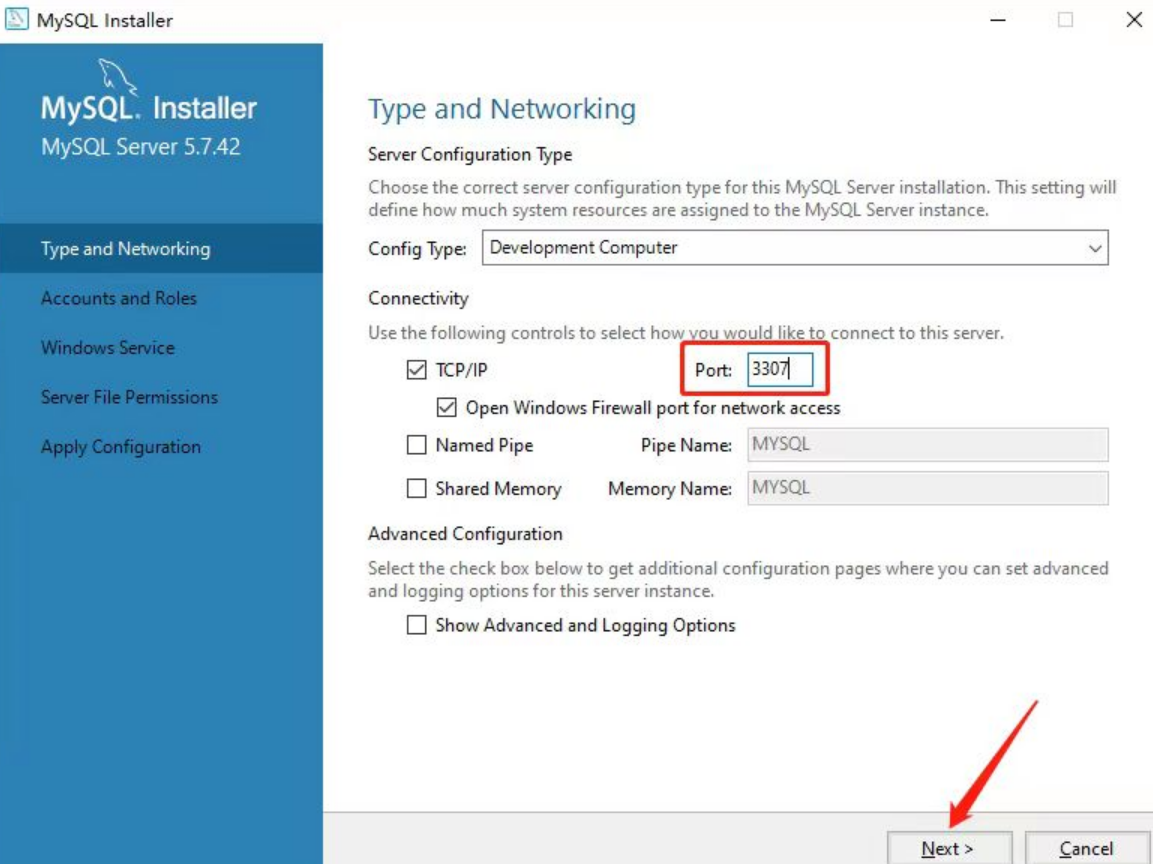
-
如下,开始设置MySQL的登录密码。(建议密码设置简单一点,后面使用都会用到)
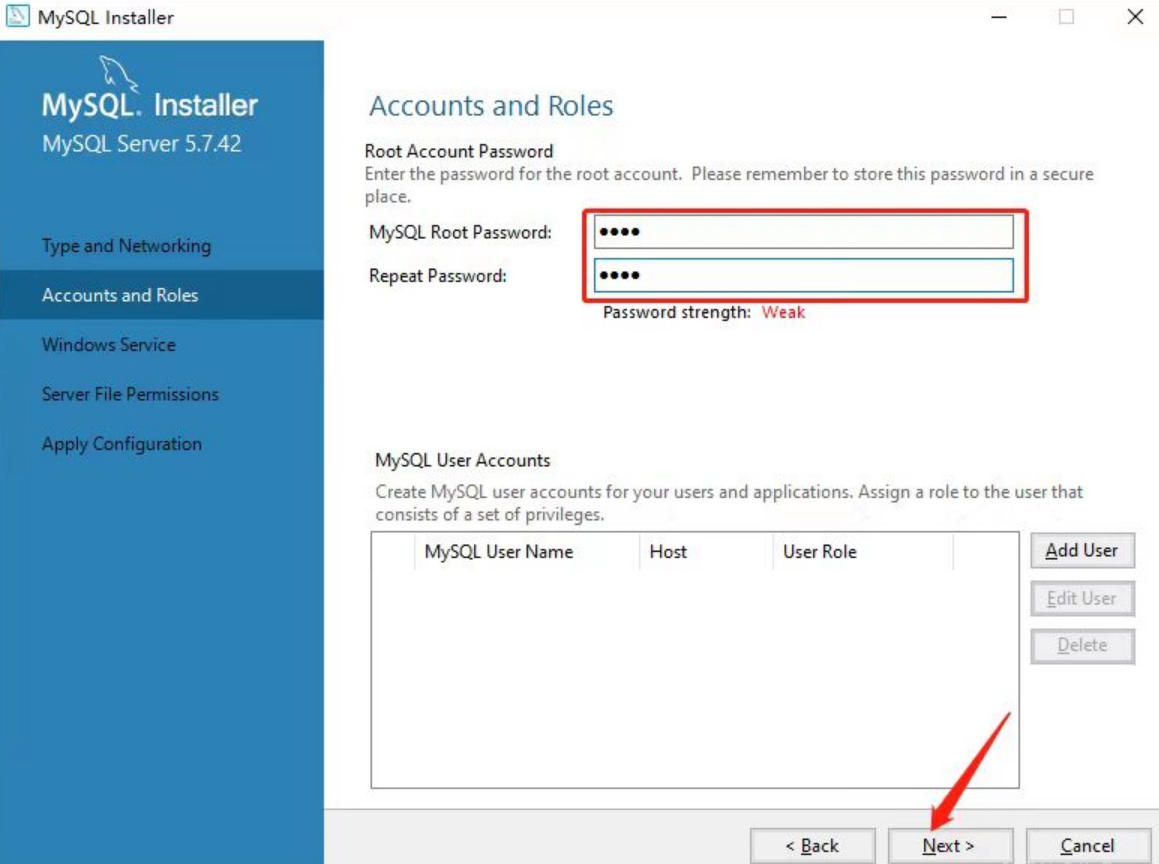
-
后面基本都是点击下一步,如下:
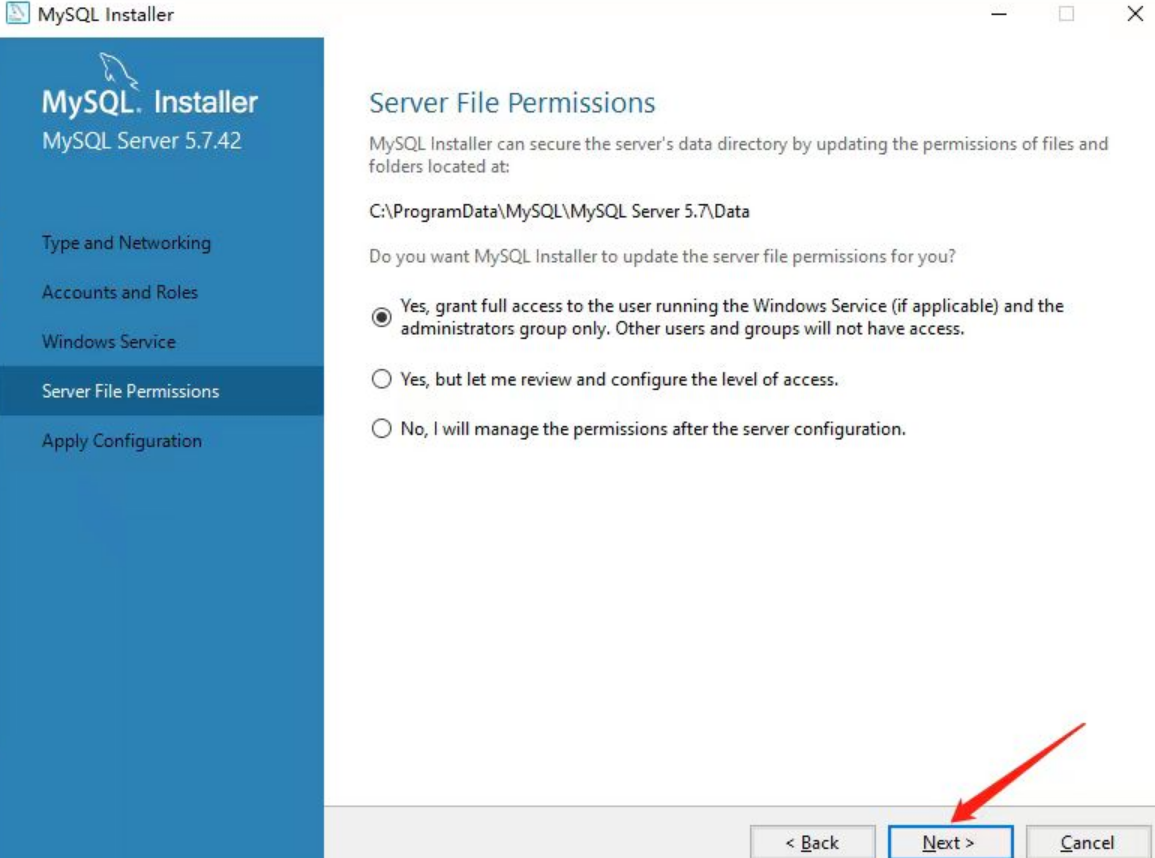
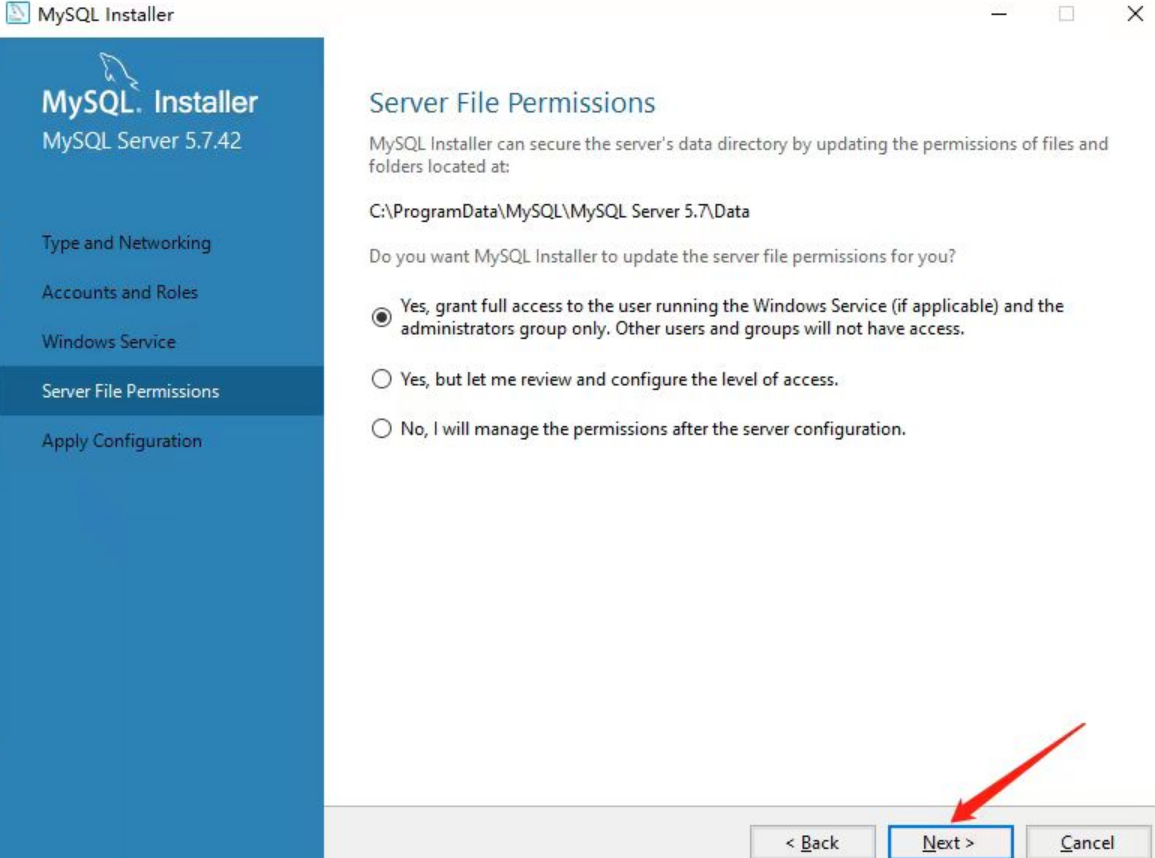
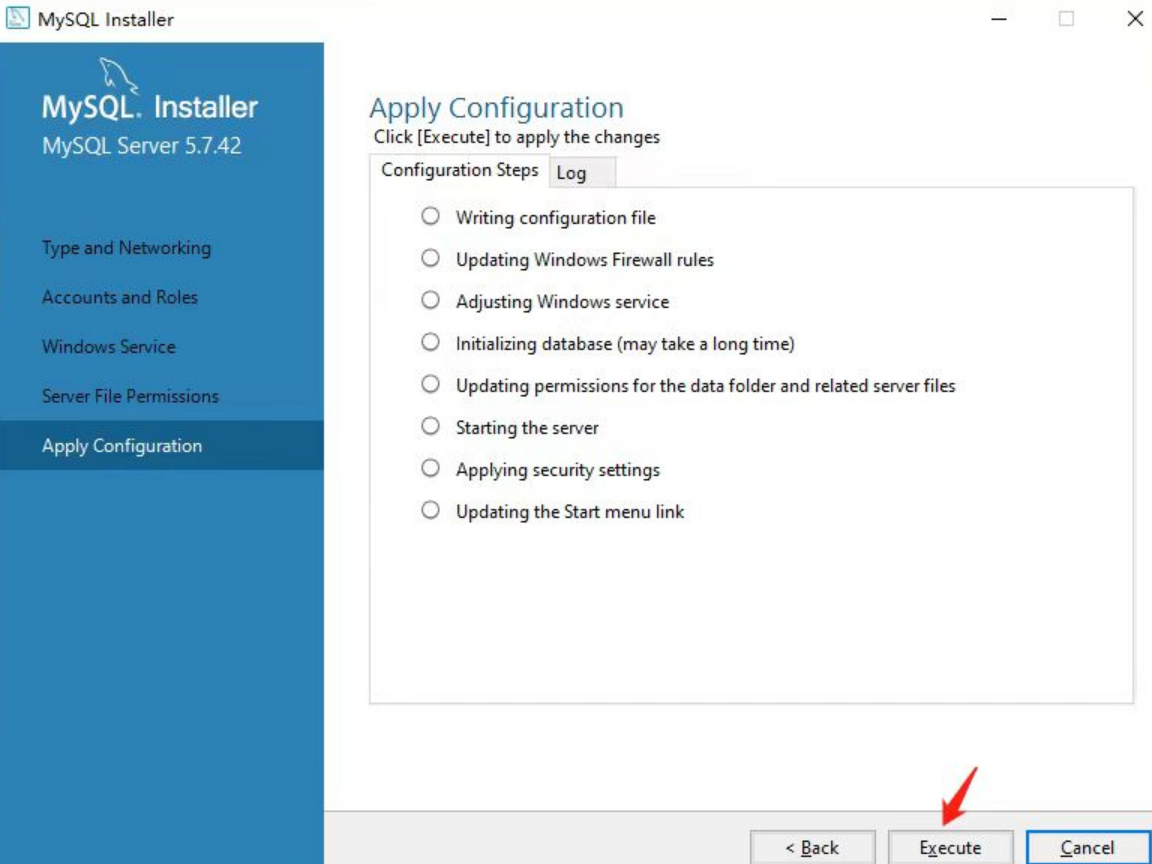
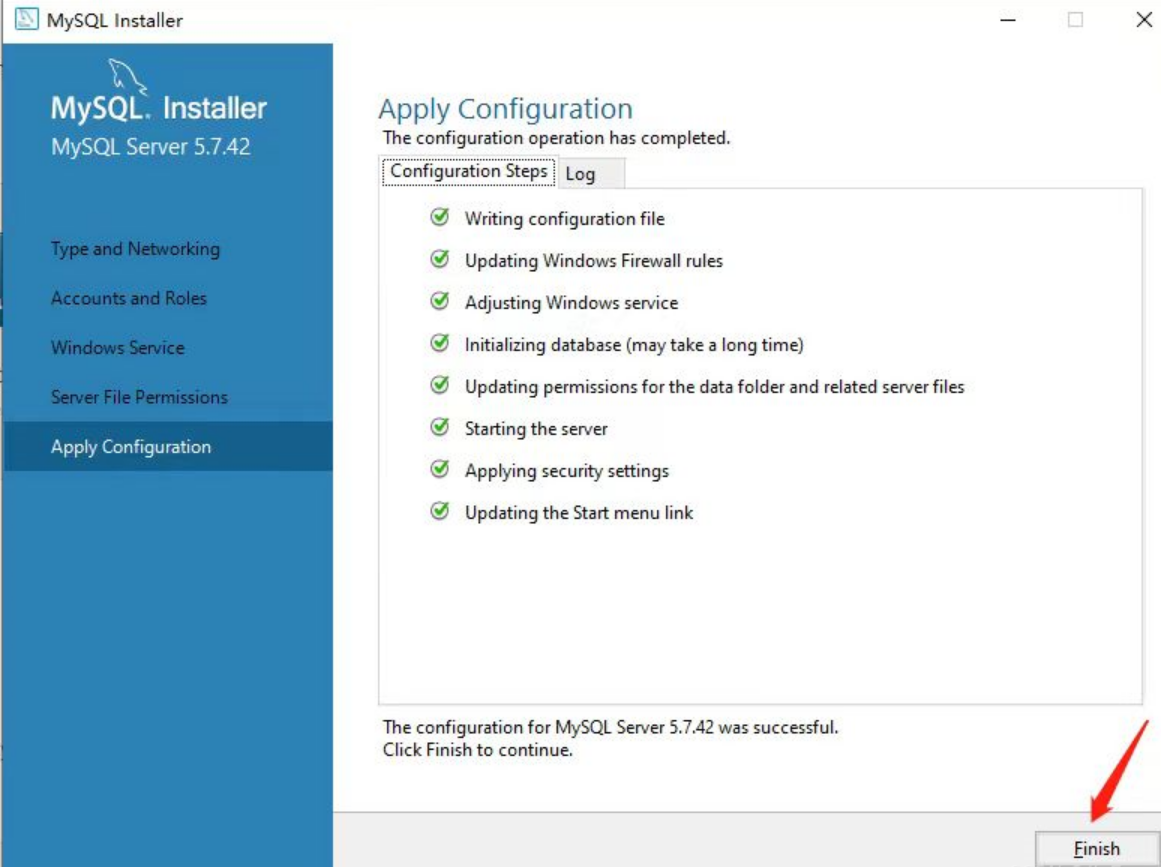
至此,MySQL5.7已经安装完毕。下面我们可以验证一下。
最后,使用刚刚安装时设置的密码登录,登陆后显示如下即登录成功!
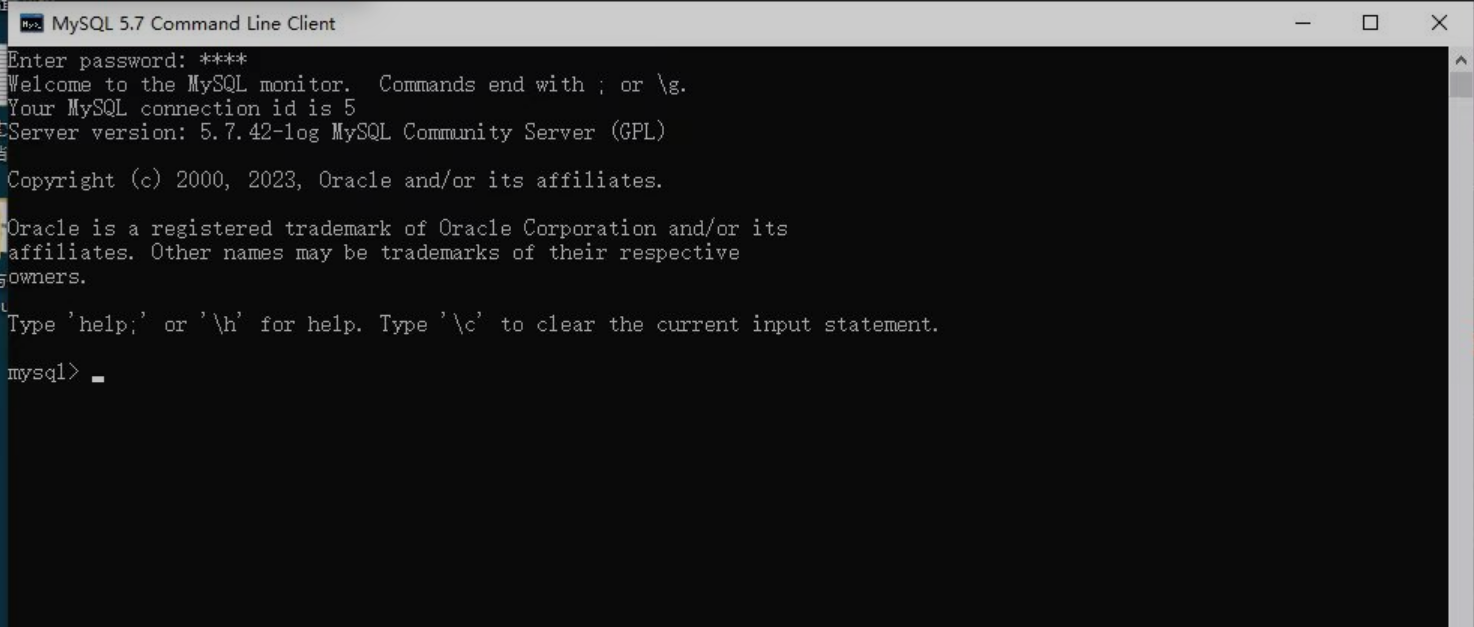
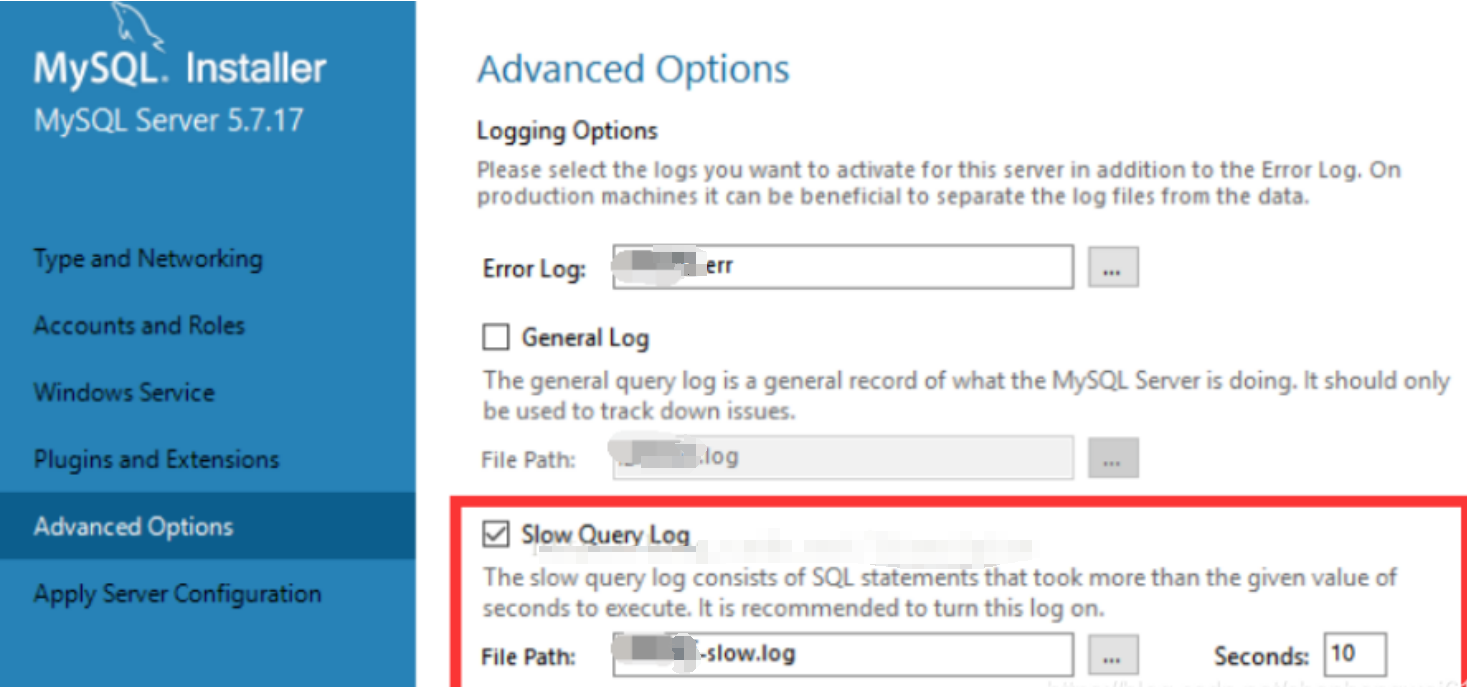
注意:如果一直卡在starting the server这个地方,大概率是由于你的路径中包含中文名字。因为我们安装时没有勾选show Advanced Options,即没有更改日志的文件,因此在安装过程中会自动生成包含计算机名称的日志文件,如果恰好计算机名称中包含中文,则是不行的。所以,我们要卸载并重新安装,勾选show Advanced Options选项,在接下来弹出的Advanced Options页面更改你的路径。,如下所示。
自此,整个mysql的安装教材完成。
注意:由于navicate的下载过于简单,这里我将不再讲解navicate的下载教程,如有不会的读者,请网上参考其他笔记。
Mysql数据库学习
命令行链接数据库
cmd后进入命令行,输入mysql -u root -p连接数据库运行
sql
mysql -u root -p --连接数据库
show databases; --查看所有数据库
use school --切换某个数据库 use 数据库名
show tables --显示某个数据库中所有的表
describe student1; --查看数据库中所有表的信息
create database demo01; --创建一个名为demo01的数据库,create database 数据库名称
exit --退出连接命令
--为单行注释(SQL 的本来的注释)
/*hello
world
*/ sql的多行注释数据库xxx语言
DDL 定义
DML 操作语言
DQL 查询语言
DCL 控制语言
操作数据库
操作数据库 > 操作数据库中的表 > 操作数据库中表的数据
mysql关键字不区分大小写
- 创建数据库
手动创建数据时如下: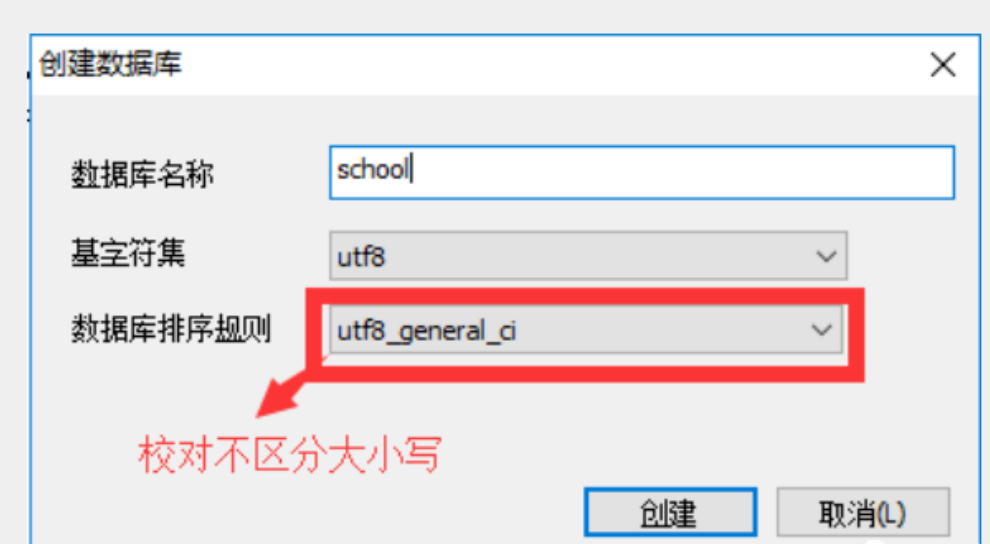
sql
crate Database if not exists demo02 -
删除数据库
sqlDrop database if exists demo02 -
使用数据库
sqluse `school` -
查看数据库
sqlshow databases; --查看所有数据库
学习思路:
- 对照navicat可视化历史记录查看sql
- 固定的语法和关键字必须要记住!
数据库的数据类型
1.数值类型
| 类型 | 字节 | 用途 & 典型场景 |
|---|---|---|
| TINYINT | 1 | 小整数(范围 - 128~127),适合状态值(0/1)、年龄、性别标识等 |
| SMALLINT | 2 | 较小整数(-32768~32767),适合少量数据的计数(如商品库存、评论数) |
| mediumint | 3 | |
| INT | 4 | 常用整数(-21 亿~21 亿),适合用户 ID、订单编号、自增主键等核心标识 |
| BIGINT | 8 | 大整数(-9e18~9e18),适合海量数据的 ID(如大数据量的订单、日志主键) |
| FLOAT | 4 | 单精度浮点数(精度约 6-7 位),适合非精准计算(如温度、评分) |
| DOUBLE | 8 | 双精度浮点数(精度约 15 位),适合普通小数计算(如身高、体重) |
| DECIMAL(M,D) | 可变 | 定点数(精准),M = 总长度,D = 小数位数,适合金额、税率(如 DECIMAL (10,2) 存价格) |
2.字符串类型
| 类型 | 特点 & 字节 | 用途 & 典型场景 |
|---|---|---|
| CHAR(n) | 定长 | n 为固定长度(1~255),占用 n 字节,适合固定长度文本(手机号、身份证号、邮编) |
| VARCHAR(n) | 变长 | n 为最大长度(1~65535),仅占实际字符 + 1/2 字节,适合可变长度文本(姓名、地址) |
| TINYTEXT | 最大 255 字符 | 短文本,适合简短备注、标签 |
| TEXT | 最大 65535 字符 | 普通长文本,适合文章内容、商品描述 |
| MEDIUMTEXT | 最大 16M 字符 | 中等长度文本,适合长文、日志内容 |
| LONGTEXT | 最大 4G 字符 | 超长文本,适合超大内容(如备份数据、大型文档) |
| ENUM | 1/2 字节 | 枚举类型(只能选其一),适合性别(男 / 女)、订单状态(待付款 / 已发货) |
| SET | 1-8 字节 | 集合类型(可多选),适合用户兴趣(阅读 / 运动 / 音乐)、商品标签 |
3.时间日期
| 类型 | 字节 | 格式 & 范围 | 用途 & 典型场景 |
|---|---|---|---|
| DATE | 3 | YYYY-MM-DD(1000~9999) | 仅存日期,适合生日、订单日期、注册日期 |
| TIME | 3 | HH:MM:SS(-838:59:59~838:59:59) | 仅存时间,适合打卡时间、活动时长 |
| DATETIME | 8 | YYYY-MM-DD HH:MM:SS | 日期 + 时间,适合创建时间、更新时间(无时区影响) |
| TIMESTAMP | 4 | 1970~至今的毫秒数(秒级时间戳) | 自动更新时间(如数据修改时间),支持时区转换 |
| YEAR | 1 | YYYY(1901~2155) | 仅存年份,适合年份统计、毕业年份 |
4.null类型
没有值、未知,但要注意不要使用null进行计算,即使进行了计算结果也为null。
数据库的字段属性
Unsigned:
-
无符号整数
-
声明了该列不能为负数
zerofill:
-
0填充的
-
不足的位数,前边使用0来填充,如 int(3), 1-->003
自增:
-
通常理解为自增,自动在上一条记录的基础上+1(默认)
-
通常用来设计唯一的主键 ~index,必须是整数类型
-
可以自定义设计主键自增的起始值和步长
非空 Null not null
-
假设设置为not null ,如果不给它赋值,就会报错!
-
Null,如果不填写值,默认就是null!
创建数据库表
sql
-- 学号int 登录密码varchar(20) 姓名,性别varchar(2),出生日期(datatime),家庭住址,email
-- 注意点,使用英文(),表的名称 和 字段 尽量使用 ``括起来
-- AUTO_INCREMENT 自增
--字符串使用单引号括起来!
--所有的语句后面加,(英文的),最后一个不用加
create TABLE if not EXISTS `student`(
`id` int(4) not null AUto_increment COMMENT '学号',
`name` VARCHAR(30) not null DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(20) not null DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(50) not NULL DEFAULT '女' COMMENT '名别',
`birthday` datetime DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭地址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY(`id`)
)ENGINE =INNODB DEFAULT CHARSET=utf8格式
create table [if not exits] `表名`(
'字段名' 列类型 [属性] [索引] [注释],
'字段名' 列类型 [属性] [索引] [注释],
....
'字段名' 列类型 [属性] [索引] [注释],
)[表类型][字符集设置][注释]排错方式:一行一行排
常用命令
SHOW CREATE DATABASE school --查看创建数据库的语句
SHOW CREATE TABLE student --查看student 数据表的定义语句
DESC student --显示表的结构数据表的类型
| 存储引擎 | 核心特点 | 适用场景 | 关键注意点 |
|---|---|---|---|
| InnoDB | 1. 支持事务(ACID)、行级锁、外键约束 2. 崩溃恢复能力强,数据安全性高 3. 读写性能均衡,适合高并发 | 绝大多数业务场景: 用户表、订单表、支付表、财务表等核心业务表 | 1. MySQL 5.5+ 默认引擎 2. 占用磁盘空间略大 3. 需合理设置索引提升性能 |
| MyISAM | 1. 不支持事务、外键,仅表级锁 2. 查询速度极快,插入 / 更新效率低 3. 占用空间小,支持全文索引 | 只读 / 少写的场景: 日志表、统计报表、静态数据字典、博客文章表 | 1. 崩溃后数据易损坏,无恢复能力 2. 不适合高并发写入场景 |
| MEMORY | 1. 数据存储在内存中,读写速度极快 2. 重启 MySQL 后数据全部丢失 3. 支持哈希索引,仅表级锁 | 临时数据 / 缓存场景: 临时计算结果、会话数据、高频访问的临时表 | 1. 受内存大小限制 2. 不支持 BLOB/TEXT 类型 |
| CSV | 1. 数据以 CSV 文件形式存储,可直接用 Excel 打开 2. 不支持索引、事务,仅适合简单读写 | 数据导入 / 导出场景: 批量数据迁移、报表导出、与其他系统交互 | 1. 性能极低,仅用于小众场景 2. 每行数据对应 CSV 文件一行 |
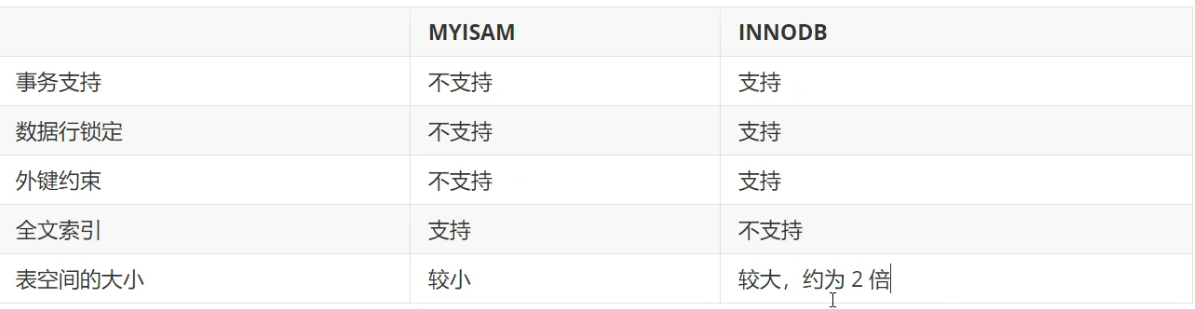
适用场景 :
- 适用 MyISAM : 节约空间及相应速度
- 适用 InnoDB : 安全性高 , 事务处理及多用户操作数据表,多表多用户操作
数据表的存储位置
所有的数据库文件都存在 data目录下,因此数据库的存储本质还是文件的存储!
MySQL 引擎在物理文件上的区别:
-
InnoDB类型在数据库表中只有一个 *.frm文件 , 以及上一级目录的ibdata1文件
-
MyISAM类型数据表对应三个文件 :
设置数据库表的字符集编码
sql
charset=utf8注意,不设置的话,会使用MySQL的默认字符集编码(不支持中文!)
也可以更改my.ini中的配置默认的编码(不建议)
charset-set-server = utf8修改删除表
修改表
sql
--修改表名 ALTER TABLE 旧表名 rename AS 新表名
ALTER TABLE student rename AS student1
--增加表的字段
ALTER TABLE student1 add age INT(11)
--修改表的字段(两种:重命名,修改约束!)
ALTER TABLE student1 MODIFY age VARCHAR(11) --修改约束
ALTER TABLE student1 CHANGE age age1 int(11) --字段重命名
--删除表的字段
ALTER TABLE student1 DROP age1删除表
sql
--删除表
DROP TABLE IF EXISTS student1所有的创建和删除操作尽量加上判断,以免出现报错!
注意点:
- `` 字段名 使用这个包裹!
- 注释 - - /**/
- sql 关键字大小写不敏感,建议大家写小写
- 所有的符号全部用英文!
Mysql的数据管理
外键
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表 ,具有此外键的表被称为主表的从表。
外键作用
保持数据一致性 ,完整性 ,主要目的是控制存储在外键表中的数据,约束。使两张表形成关联,外键只能引用外表中的列的值或使用空值。
创建外键表
sql
--创建年级表
CREATE TABLE `grade`(
`gradeid` INT(10) NOT NULL auto_increment COMMENT '年纪id',
`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY(`gradeid`)
)ENGINE =INNODB DEFAULT CHARSET=utf8
--学生表的gradeid字段要去引用年纪表的gradeid
--定义外键key
--给这个外键添加约束(执行引用) REFERENCES引用
create TABLE if not EXISTS `student`(
`id` int(4) not null AUto_increment COMMENT '学号',
`name` VARCHAR(30) not null DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(20) not null DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(50) not NULL DEFAULT '女' COMMENT '名别',
`birthday` datetime DEFAULT NULL COMMENT '出生日期',
`gradeid` INT(10) not NULL COMMENT '学生年纪',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭地址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY(`id`),
key `FK_gradeid`(`gradeid`),
CONSTRAINT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade`(`gradeid`)
)ENGINE =INNODB DEFAULT CHARSET=utf8创建外键方式二 : 创建子表完毕后,修改子表添加外键
sql
--创建表时没有外键关系
ALTER table `student`
add CONSTRAINT `Fk_gradeid` FOREIGN KEY(`gradeid`) REFERENCES `grade`(`gradeid`)
--公式: ALTER table `表` add CONSTRAINT `约束名` FOREIGN KEY(`作为外键的列`) REFERENCES `参考的表`(`表中哪个字段`)以上的操作都是物理外键,数据库级别的外键,不建议使用,因为过于繁琐,操作表时关联性过大! (避免数据库过多造成困扰)
最佳实践
-
数据库就是单纯的表,只用来存数据,只有行(数据)和列(字段)
-
我们想使用多张表的娄收据,想使用外键(程序去实现)
DML语言
DML语言包括:
Insert添加语句
语法:INSERT INTO 表名 (字段1,字段2,字段3) values('值1'(,('值2'), ('值3'),(...)
注意事项:
-
字段和字段之间需要用逗号隔开
-
字段是可以省略的,但是后边的值必须是一一对应,不能省略
-
可以同事插入多条数据
sql
--插入语句
--INSERT INTO 表名 ([字段1,字段2,字段3]) values('值1'(,('值2'), ('值3'),(...)
USE school1
INSERT INTO `grade`(`gradename`) VALUES('大一')
--由于主键自增我们可以省略(如果不写字段,默认会一一匹配),一般写字段要将字段和数据一一对应
INSERT INTO `grade` VALUES ('大二')
--插入多个字段,注意如果其它数据库中有grade这个表时要加上(use 数据库名)
USE school1
INSERT INTO `grade`(`gradename`) VALUES ('大二'), ('大三')
--插入多条数据
USE school1
INSERT INTO `student1`(`name`,`pwd`,`sex`)
VALUES ('张三', 'aaaaaa','男'),
('李四', 'bbbbbb','男')Update修改语句
语法:--UPDATE 表名 SET 列名1='值1',列名2 = '值2' WHERE 条件
sql
--修改语句
--修改学员名字
UPDATE `student1` SET `name` = '小明' WHERE id BETWEEN 2 AND 5
--修改多个属性,逗号隔开
UPDATE `student1` SET `name` = '小红', `email` = '12345678@qq.com' WHERE id=2
--不指定条件的情况下将会更改所有表
--语法
--UPDATE 表名 SET COLUMN_name=VALUE WHERE [条件]
--通过多个条件定位数据
UPDATE `student1` SET `name`='长江七号' WHERE `name`='小明'and`sex` = '男'注意事项:
-
字段尽量带上票
-
where筛选的条件如果没有指定,则会修改所有的列
-
值是一个具体的值,也可以是一个变量
delete修改语句
truncate命令与delete的区别:
-
相同点:都能删除数据且不会删除表结构
-
不同:
-
truncate 重新设置 自增列 计数器会归零
-
truncate 不会影响事务
-
sql
--删除数据
--删除所有数据
delete FROM `student1`
--清空某个表
TRUNCATE `student`
--测试delete和truncate的区别
CREATE TABLE `test`(
`id` INT(4) not NULL auto_increment,
`coll` VARCHAR(20) not NULL,
PRIMARY KEY(`id`)
)ENGINE= INNODB CHARSET=utf8
INSERT INTO `test`(`coll`) VALUES('1'),('2'),('3')
DELETE FROM `test` --不会影响自增
TRUNCATE TABLE `test` --自增会归0注意:delete 删除的问题,重启数据库现象
-
InnoDB 自增列会从1开始(是存储在内存中的,断电即失)
-
MyISAM 继续从上一个自增量开始(存储在文件中的,不会丢失)
select查询语句
DQL数据查询语言:所有的查询操作都用该语言,使用频率最高的语言,数据库中最核心的语言
创建数据库:
sql
CREATE DATABASE IF NOT EXISTS `school`;
-- 创建一个school数据库
USE `school`;-- 创建学生表
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student`(
`studentno` INT(4) NOT NULL COMMENT '学号',
`loginpwd` VARCHAR(20) DEFAULT NULL,
`studentname` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名',
`sex` TINYINT(1) DEFAULT NULL COMMENT '性别,0或1',
`gradeid` INT(11) DEFAULT NULL COMMENT '年级编号',
`phone` VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空',
`address` VARCHAR(255) NOT NULL COMMENT '地址,允许为空',
`borndate` DATETIME DEFAULT NULL COMMENT '出生时间',
`email` VARCHAR (50) NOT NULL COMMENT '邮箱账号允许为空',
`identitycard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号',
PRIMARY KEY (`studentno`),
UNIQUE KEY `identitycard`(`identitycard`),
KEY `email` (`email`)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
-- 创建年级表
DROP TABLE IF EXISTS `grade`;
CREATE TABLE `grade`(
`gradeid` INT(11) NOT NULL AUTO_INCREMENT COMMENT '年级编号',
`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY (`gradeid`)
) ENGINE=INNODB AUTO_INCREMENT = 6 DEFAULT CHARSET = utf8;
-- 创建科目表
DROP TABLE IF EXISTS `subject`;
CREATE TABLE `subject`(
`subjectno`INT(11) NOT NULL AUTO_INCREMENT COMMENT '课程编号',
`subjectname` VARCHAR(50) DEFAULT NULL COMMENT '课程名称',
`classhour` INT(4) DEFAULT NULL COMMENT '学时',
`gradeid` INT(4) DEFAULT NULL COMMENT '年级编号',
PRIMARY KEY (`subjectno`)
)ENGINE = INNODB AUTO_INCREMENT = 19 DEFAULT CHARSET = utf8;
-- 创建成绩表
DROP TABLE IF EXISTS `result`;
CREATE TABLE `result`(
`studentno` INT(4) NOT NULL COMMENT '学号',
`subjectno` INT(4) NOT NULL COMMENT '课程编号',
`examdate` DATETIME NOT NULL COMMENT '考试日期',
`studentresult` INT (4) NOT NULL COMMENT '考试成绩',
KEY `subjectno` (`subjectno`)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入学生数据 其余自行添加 这里只添加了2行
INSERT INTO `student` (`studentno`,`loginpwd`,`studentname`,`sex`,`gradeid`,`phone`,`address`,`borndate`,`email`,`identitycard`)
VALUES
(1000,'123456','张伟',0,2,'13800001234','北京朝阳','1980-1-1','text123@qq.com','123456198001011234'),
(1001,'123456','赵强',1,3,'13800002222','广东深圳','1990-1-1','text111@qq.com','123456199001011233');
-- 插入成绩数据 这里仅插入了一组,其余自行添加
INSERT INTO `result`(`studentno`,`subjectno`,`examdate`,`studentresult`)
VALUES
(1000,1,'2013-11-11 16:00:00',85),
(1000,2,'2013-11-12 16:00:00',70),
(1000,3,'2013-11-11 09:00:00',68),
(1000,4,'2013-11-13 16:00:00',98),
(1000,5,'2013-11-14 16:00:00',58);
-- 插入年级数据
INSERT INTO `grade` (`gradeid`,`gradename`) VALUES(1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'),(5,'预科班');
-- 插入科目数据
INSERT INTO `subject`(`subjectno`,`subjectname`,`classhour`,`gradeid`)VALUES
(1,'高等数学-1',110,1),
(2,'高等数学-2',110,2),
(3,'高等数学-3',100,3),
(4,'高等数学-4',130,4),
(5,'C语言-1',110,1),
(6,'C语言-2',110,2),
(7,'C语言-3',100,3),
(8,'C语言-4',130,4),
(9,'Java程序设计-1',110,1),
(10,'Java程序设计-2',110,2),
(11,'Java程序设计-3',100,3),
(12,'Java程序设计-4',130,4),
(13,'数据库结构-1',110,1),
(14,'数据库结构-2',110,2),
(15,'数据库结构-3',100,3),
(16,'数据库结构-4',130,4),
(17,'C#基础',130,1);select的语法:
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条查询简单练习:
sql
--查询所有学生,SELECT 字段 FROM 表
SELECT * FROM student
--查询指定字段
SELECT `StudentNo`,`StudentName` from student
--别名,给结果起一个名字 用AS 也可以给字段起别名,也可以给表起别名
SELECT `StudentNo`AS 学号,`StudentName` AS 学生姓名 from student as s
--函数concat(a,b)
SELECT CONCAT('姓名',StudentName)AS 新名字 FROM student去重
sql
--去重
--查询有哪些学生参加了考试,成绩
SELECT * FROM result --查询全部的考试成绩
SELECT `StudentNo` FROM result --查询有哪些同学参加了考试
SELECT DISTINCT `StudentNo` FROM result --发现重复数据,去重
SELECT VERSION() --查询系统版本号
SELECT 100*3 - AS 计算结果
--学员考试成绩+1分查看
SELECT `StudentNo`,`StudentREsult`+1 AS `提分后` FROM resultwhere条件子句
作用:检索数据中符合条件的值
逻辑运算符如下: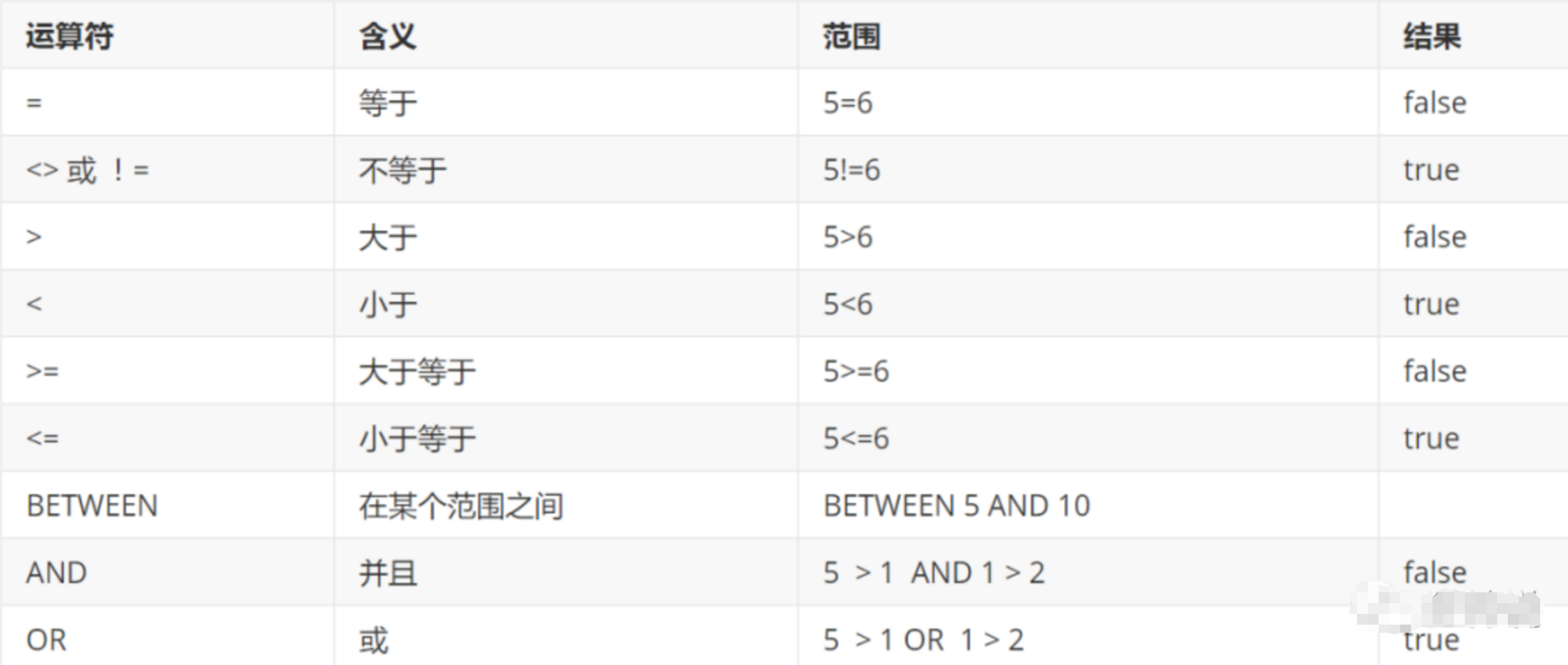
sql
--WHERE条件子句
SELECT `StudentNo`,`StudentResult` FROM result
WHERE studentresult>=95 AND studentresult<=100
--and ==&&
SELECT `StudentNo`,`StudentResult` FROM result
WHERE studentresult>=95 && studentresult<=100
--模糊查询
--WHERE条件子句
SELECT `StudentNo`,`StudentResult` FROM result
WHERE studentresult BETWEEN 95 AND 100模糊查询:本质是比较运算符
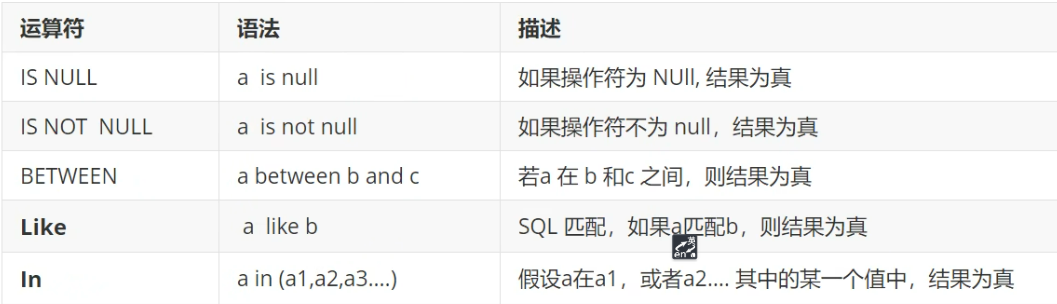
示例练习
sql
--模糊查询
--WHERE条件子句
SELECT `StudentNo`,`StudentResult` FROM result
WHERE studentresult BETWEEN 95 AND 100
--模糊查询
--查询姓刘的同学
--LIKE结合 %(代表0到任意个字符) ,_(代表一个字符)
SELECT `studentno` ,`studentname` FROM `student`
WHERE studentname LIKE '刘%'
--查询姓刘的同学,名字只有一个字的
SELECT `studentno` ,`studentname` FROM `student`
WHERE studentname LIKE '刘_'
--查询姓刘的同学,名字只有两个字的
SELECT `studentno` ,`studentname` FROM `student`
WHERE studentname LIKE '刘__'
--查询名字有嘉字的同学
SELECT `studentno` ,`studentname` FROM `student`
WHERE studentname LIKE '%嘉%'
--IN,具体的一个或多个值
--查询1001,1002,1003号学员
SELECT `studentno` ,`studentname` FROM `student`
WHERE studentno IN(1001,1002,1003)
--查询在北京的学生
SELECT `studentno` ,`studentname` FROM `student`
WHERE `address` in ('北京')
--查询地址为空的学生
SELECT `studentno` ,`studentname` FROM `student`
WHERE address='' or address is NULL
--查询有出生日期的学生
SELECT `studentno` ,`studentname` FROM `student`
WHERE borndate is NOT NULL 联表查询
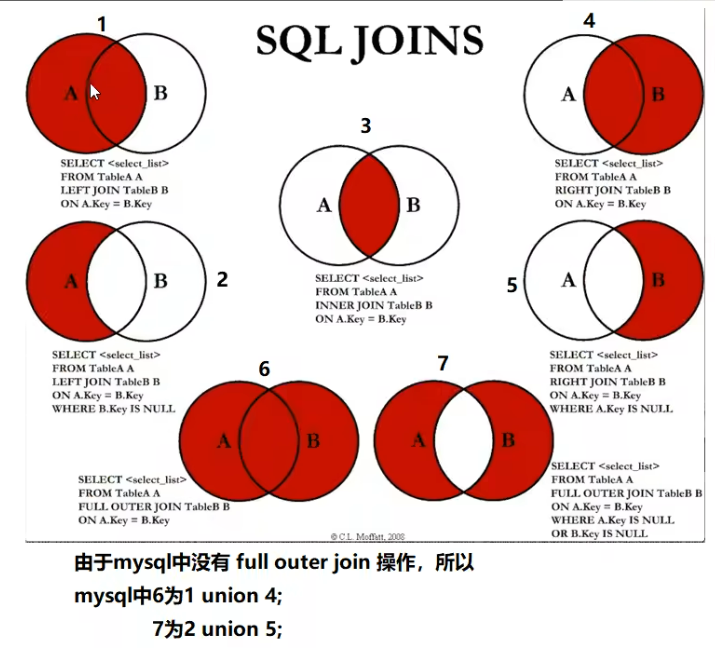
代码练习
sql
--====联表查询====
--查询参加考试的同学(学号,姓名,科目编号,分数)
/*
思路:
1.分析需求,分析查询的字段来自那些表
2.确定使用哪种连接查询?7种
确定交叉点(这两个表中的那个数据是相同的)
判断条件:学生表中的studentno=成绩表studentno
*/
--INNER JOIN练习
SELECT s.studentno,studentname subjectno,studentresult
FROM student AS s
INNER JOIN result AS r
WHERE s.studentno =r.studentno
--RIGHT JOIN使用
SELECT s.studentno,studentname subjectno,studentresult
FROM student AS s
RIGHT JOIN result AS r
ON s.studentno =r.studentno
--ELFT JOIN使用
SELECT s.studentno,studentname subjectno,studentresult
FROM student AS s
RIGHT JOIN result AS r
ON s.studentno =r.studentno
--查询缺考的同学
SELECT s.studentno,studentname subjectno,studentresult
FROM student AS s
RIGHT JOIN result AS r
ON s.studentno =r.studentno
WHERE studentresult IS NULL
--查询参加考试的同学信息(学号,姓名,科目名,分数)
/*
思路:
1.分析需求,分析查询的字段来自那些表,student,result,`subject`(连接查询)
2.确定使用哪种连接查询?7种
确定交叉点(这两个表中的那个数据是相同的)
判断条件:学生表中的studentno=成绩表studentno
*/
SELECT s.studentno, studentname,subjectname,studentresult
FROM student s
RIGHT JOIN result r
ON s.studentno =r.studentno
INNER JOIN `subject`sub
ON r.subjectno = sub.subjectno
--思路:
1.要查询那些数据 SELECT
2.从哪几个表中查 FROM 表 xxx JOIN 连接的表 ON 交叉条件
3.假设存在一种多张表查询,先查询两张表,然后再慢慢增加
自连接
自己的表和自己的表连接,核心:一张表拆为两张一样的表即可
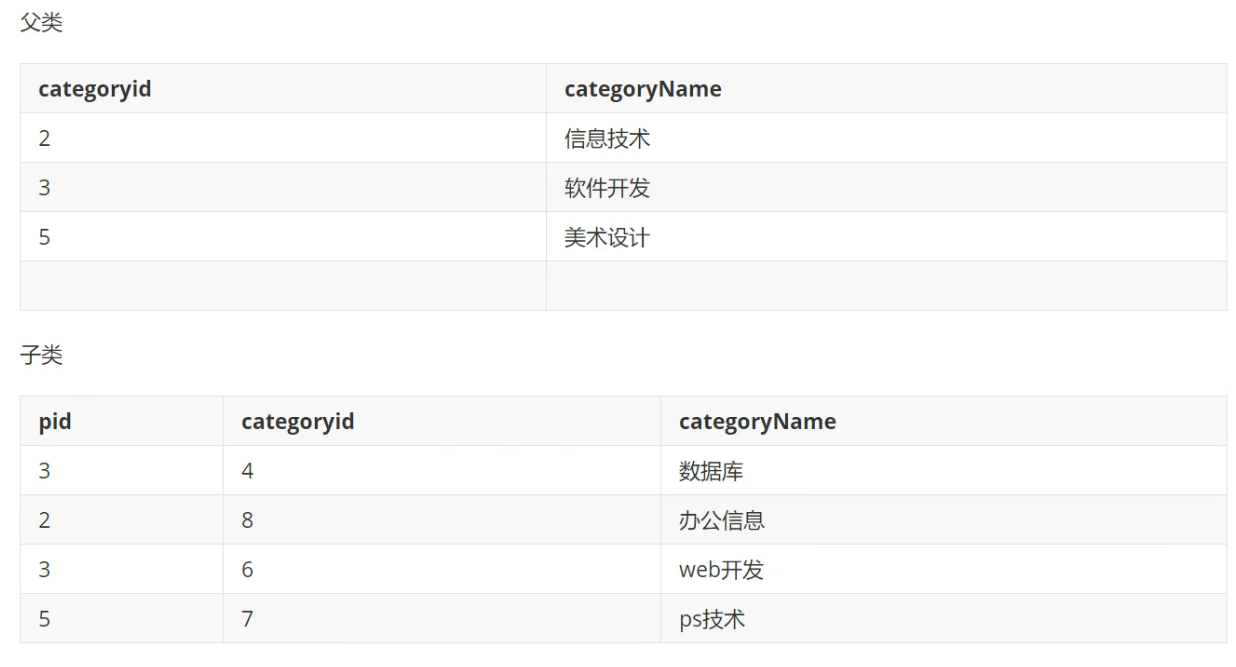
操作:查询父类对应的字类关系
sql
--===================自连接==============
/*
自连接
数据表与自身进行连接
需求:从一个包含栏目ID , 栏目名称和父栏目ID的表中
查询父栏目名称和其他子栏目名称
*/
-- 创建一个表
CREATE TABLE `category` (
`categoryid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主题id',
`pid` INT(10) NOT NULL COMMENT '父id',
`categoryName` VARCHAR(50) NOT NULL COMMENT '主题名字',
PRIMARY KEY (`categoryid`)
) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
-- 插入数据
INSERT INTO `category` (`categoryid`, `pid`, `categoryName`)
VALUES('2','1','信息技术'),
('3','1','软件开发'),
('4','3','数据库'),
('5','1','美术设计'),
('6','3','web开发'),
('7','5','ps技术'),
('8','2','办公信息');
-- 编写SQL语句,将栏目的父子关系呈现出来 (父栏目名称,子栏目名称)
-- 核心思想:把一张表看成两张一模一样的表,然后将这两张表连接查询(自连接)
--查询父子信息
SELECT a.categoryName AS '父栏目',b.categoryName AS '子栏目'
FROM category AS a,category AS b
WHERE a.`categoryid`=b.`pid`
--查询学员所属的年纪(学号、学生的姓名,年纪名称)
SELECT studentno,studentname,`gradename`
FROM student s
INNER JOIN `grade` g
WHERE s.`gradeid`=g.`gradeid`
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON sub.subjectno = r.subjectno
-- 查询科目及所属的年级(科目名称,年级名称)
SELECT subjectname AS 科目名称,gradename AS 年级名称
FROM SUBJECT sub
INNER JOIN grade g
ON sub.gradeid = g.gradeid
-- 查询 数据库结构-1 的所有考试结果(学号 学生姓名 科目名称 成绩)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'排序和分页
排序
sql
--===== 分页 LIMIT 和排序 order by=====
--排序:升序 ASC,降序DESC
--查询的结果根据成绩降序排列
-- ORDER BY 通过哪个字段进行排序
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
ORDER BY studentresult ASC分页
语法:LIMIT 起始值,页面
sql
--为什么要分页?
--缓解数据库压力,给人的体验更好,瀑布流
-- 分页,煤业只显示五条数据
--语法:LIMIT 起始值,页面的大小
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
ORDER BY studentresult ASC
LIMIT 0,5嵌套子查询
什么是子查询?
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句 嵌套查询可由多个子查询组成,求解的方式是由里及外; 子查询返回的结果一般都是集合,故而建议使用IN关键字
sql
--子查询和嵌套查询
--思考:
--查询java第一学年课程成绩排名前十的学生并且分数要大于80的学生信息(学号,姓名,课程名称,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
ORDER BY StudentResult DESC
LIMIT 0,10
--1、查询"数据库结构-1"的所有考试结果(学号、科目编号,成绩),降序排列
--方式一:使用连接查询
SELECT studentno,r.`subjectno`,StudentResult
FROM result r
INNER JOIN `subject`sub
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
ORDER BY StudentResult DESC
--方式二:使用子查询(由里及外)
SELECT studentno,`subjectno`,StudentResult
FROM result
WHERE studentno=(
SELECT `subjectno` FROM `subject` WHERE subjectname = '数据库结构-1'
)
--分数不小于80分的学生的学号和姓名
SELECT DISTINCT s.`studentname`,`studentname`
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
WHERE `studentresult` >=80
--在上面这个基础上增加一个科目,高等数学-2
SELECT DISTINCT s.`studentname`,`studentname`
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
WHERE `studentresult` >=80 AND `subjectno`=
(SELECT subjectNO FROM `subject`WHERE
`subjectname` = '高等数学-2')
--查询课程为高等数学-2 且分数不小于80分的同学的学号和姓名
SELECT DISTINCT s.`studentno`,`studentname`
FROM student s
INNER JOIN result r
ON s.studentno =r.studentno
INNER JOIN `subject` sub
on r.`subjectno`=sub.`subjectno`
WHERE `subjectname` = '高等数学-2' AND studentresult>=80
--方式三
SELECT studentno,studentname FROM student WHERE studentno IN(
SELECT studentno FROM result WHERE StudentResult>=80 AND subjectno=(
SELECT subjectno FROM `subject` WHERE subjectname = '高等数学-2'
)
)MySQL的常用函数
常用函数
sql
--常用函数
--数学运算
SELECT ABS(-8) --绝对值
SELECT CEILING(9.4) --向上取整
SELECT FLOOR(9.4) --向下取整
SELECT RAND() -- 返回一个0·1之间的随机数
SELECT SIGN(10) --判断一个数的符号0-0 负数返回-1.正数返回1
--字符串函数
SELECT CHAR_LENGTH('你好世界QQQ') --字符串长度
SELECT CONCAT('我','爱','你') --拼接字符串
SELECT INSERT ('我爱编程helloworld',1,2,'超级喜欢') --查询,替换
SELECT LOWER('HELLO') --转小写
SELECT UPPER('hello') --转大写
SELECT INSTR('hello','h') --返回第一次出现的字串的索引
SELECT REPLACE('坚持就能成功','坚持','努力') --替换出现的指定字符串
SELECT SUBSTR('坚持就能成功',4,2) -返回指定的子字符串(源字符串,截取的位置,截取的长度)
SELECT REVERSE('坚持就能成功') --反转字符串
--查询姓周的同学
SELECT REPLACE(studentname,'周','邹') FROM student
WHERE studentname LIKE '周%'
--时间和日期函数
SELECT CURRENT_DATE() -- 获取当前日期
SELECT CURDATE() -- 获取当前日期
SELECT NOW() --获取当前时间
SELECT LOCALTIME() --获取本地时间
SELECT SYSDATE() --获取系统时间
SELECT YEAR(NOW())
SELECT MONTH(NOW())
SELECT DAY(NOW())
SELECT HOUR(NOW())
SELECT MINUTE(NOW())
SELECT SECOND(NOW())
--系统
SELECT SYSTEM_USER()
SELECT USER()
SELECT VERSION()聚合函数
sql
--聚合函数
--都能进行统计表中的数据(想查询一个表中有多少个记录,就使用这个count())
SELECT count(studentname) FROM student --count(指定列),会忽略所有的null值
SELECT count(*) FROM student --count(指定列) --count(*),不会忽略null值,本质计算行数
SELECT count(1) FROM student --count(指定列) --count(*),不会忽略所有的null值,本质计算列数
SELECT sum(`studentresult`) as '总和' FROM result
SELECT avg(`studentresult`) AS '平均分' FROM result
SELECT MAX(`studentresult`) AS '最高分' FROM result
SELECT Min(`studentresult`) AS '最低分' FROM result
--查询不同课程的平均分,最高分,最低分
--核心:(根据不同道课程分组)
SELECT `subjectNAME`,avg(studentresult) AS '平均分',max(studentresult),min(studentresult)
FROM result r
INNER JOIN `subject` sub
ON r.`subjectno` = sub.`subjectno`
GROUP BY r.`subjectno` --通过该字段进行分组
HAVING '平均分'>80 --having是分组后进行过滤数据库级别的MD5加密
什么是MD5?
信息摘要算法,不可逆,简单说,就是把任意长度的文本 / 数据,通过固定算法转换成一个128 位的二进制串 ,通常表现为32 位的十六进制字符串
sql
--测试md5加密
CREATE TABLE `testmd5` (
`id` INT(4) NOT NULL,
`name` VARCHAR(20) NOT NULL,
`pwd` VARCHAR(50) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
--明文密码
INSERT INTO testmd5 VALUES(1,'张三','123456'),(2,'李四','456789'),(3,'王五','891230')
--加密
UPDATE testmd SET pwd = MD5(pwd) WHERE id=1
UPDATE testmd SET pwd = MD5(pwd) --加密全部密码
--插入的时候加密
INSERT INTO testmd5 VALUES(4,'小明',MD5('123456'))
--如何校验:将用户传递进来的密码。进行md5加密,然后比对加密后的值
SELECT * FROM testmd5 WHERE `name`='小明' AND pwd=MD5('123456')小结:
sql
-- ================ 内置函数 ================
-- 数值函数
abs(x) -- 绝对值 abs(-10.9) = 10
format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46
ceil(x) -- 向上取整 ceil(10.1) = 11
floor(x) -- 向下取整 floor (10.1) = 10
round(x) -- 四舍五入去整
mod(m, n) -- m%n m mod n 求余 10%3=1
pi() -- 获得圆周率
pow(m, n) -- m^n
sqrt(x) -- 算术平方根
rand() -- 随机数
truncate(x, d) -- 截取d位小数
-- 时间日期函数
now(), current_timestamp(); -- 当前日期时间
current_date(); -- 当前日期
current_time(); -- 当前时间
date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分
time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分
date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间
unix_timestamp(); -- 获得unix时间戳
from_unixtime(); -- 从时间戳获得时间
-- 字符串函数
length(string) -- string长度,字节
char_length(string) -- string的字符个数
substring(str, position [,length]) -- 从str的position开始,取length个字符
replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str
instr(string ,substring) -- 返回substring首次在string中出现的位置
concat(string [,...]) -- 连接字串
charset(str) -- 返回字串字符集
lcase(string) -- 转换成小写
left(string, length) -- 从string2中的左边起取length个字符
load_file(file_name) -- 从文件读取内容
locate(substring, string [,start_position]) -- 同instr,但可指定开始位置
lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length
ltrim(string) -- 去除前端空格
repeat(string, count) -- 重复count次
rpad(string, length, pad) --在str后用pad补充,直到长度为length
rtrim(string) -- 去除后端空格
strcmp(string1 ,string2) -- 逐字符比较两字串大小
-- 聚合函数
count()
sum();
max();
min();
avg();
group_concat()
-- 其他常用函数
md5();
default();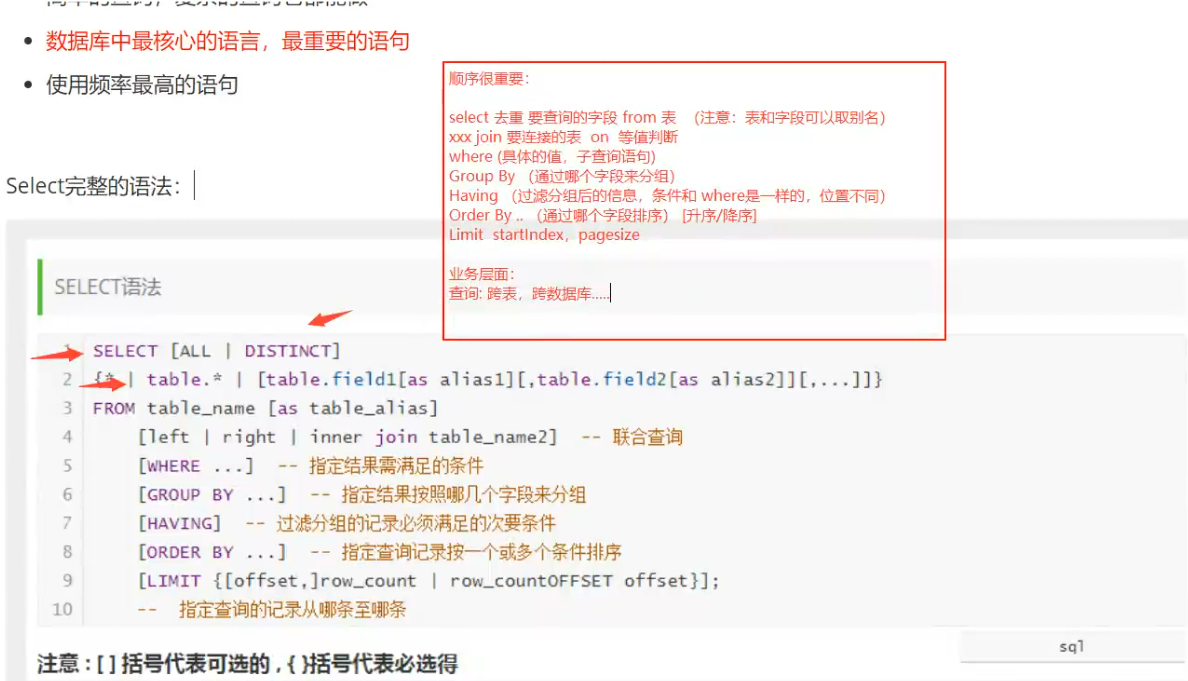
事务
什么是事务?
本质是一组不可分割的数据库操作集合 ------ 这组操作要么全部成功执行 ,要么全部失败回滚,就像 "一荣俱荣,一损俱损",保证数据在多步操作下的一致性。
核心特性(ACID原则)
| 特性 | 英文 | 通俗解释 |
|---|---|---|
| 原子性 | Atomicity | 事务是 "最小单位",要么全做,要么全不做(比如转账的两步操作不能只做一步)。 |
| 一致性 | Consistency | 事务执行前后,数据库的 "数据规则" 不变(比如转账前后,两人总余额不变,不是过程一致性)。 |
| 隔离性 | Isolation | 多个事务同时执行时,互相隔离、互不干扰(比如你转账的同时,朋友查余额不会看到 "只加了钱没扣钱" 的中间状态)。 |
| 持久性 | Durability | 事务一旦执行成功(提交),结果永久保存到数据库,即使数据库崩溃也不会丢失。 |
隔离性可能导致下列问题:
-
脏读:一个事务读取到了另一个事务还未提交的修改数据,而这个数据最终可能会被回滚(撤销),相当于读到了 "脏数据"。
-
不可重复读:在同一个事务 中,多次读取同一批数据,结果却不一致 ------ 因为期间有另一个事务提交了修改,导致前后读取结果不同。
基本语法:
sql
---事务
--mysql是默认开启事务自动提交的
SET autocommit = 0 /*关闭*/
SET autocommit = 1 /*开启(默认)*/
--手动处理事务
SET autocommit = 0 /*关闭*/
--事务开启
START TRANSACTION /*标记一个事务的开始,从这个之后的sql都在一个事务内*/
INSERT xxx
INSERT xxx
--提交:持久化(成功!)
COMMIT
--回滚:回到原来的样子(失败)
ROLLBACK
--事务结束
SET autocommit = 1 /*开启自动提交*/
--设置一个保存点
SAVEPOINT 保持点名字 --事务的保存点
ROLLBACK TO SAVEPOINT 保存点 --回滚到保存点
RELEASE SAVEPOINT 保存点 --删除保存点测试
sql
-- 事务测试
/*
A在线买一款价格为500元商品,网上银行转账.
A的银行卡余额为2000,然后给商家B支付500.
商家B一开始的银行卡余额为10000
创建数据库shop和创建表account并插入2条数据
*/
CREATE DATABASE `shop`CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `shop`;
CREATE TABLE `account` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(32) NOT NULL,
`cash` DECIMAL(9,2) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO account (`name`,`cash`)
VALUES('A',2000.00),('B',10000.00)
-- 转账实现
SET autocommit = 0; -- 关闭自动提交
START TRANSACTION; -- 开始一个事务,标记事务的起始点
UPDATE account SET cash=cash-500 WHERE `name`='A';
UPDATE account SET cash=cash+500 WHERE `name`='B';
COMMIT; -- 提交事务,一旦被提交,就会被持久化,回滚也不会其作用
rollback;
SET autocommit = 1; -- 恢复自动提交索引
索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的分类
在一个表中,主键索引只能有一个,唯一索引可以有多个
-
主键索引
- 唯一标识,主键不可重复,只能有一个列作为主键
-
唯一索引
- 避免重复 的列出现,可重复,多个列都可以标识唯一索引
-
常规索引
- 默认的,可通过index,key关键字来设置
-
全文索引
sql
-- 索引的使用
-- 在创建表的时候给字段增加索引或者创建完毕后,增加索引
-- 显示所有索引信息
SHOW INDEX FROM student
-- 增加一个全文索引,列名
ALTER TABLE student ADD FULLTEXT INDEX `studentname`(`studentname`)
-- EXPLAIN 分析sql的执行状况
EXPLAIN SELECT * FROM student --非全文索引
SELECT * FROM student WHERE MATCH(studentname)AGAINST('王')索引测试
sql
-- 测试索引
-- 创建app_user
CREATE TABLE `app_user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT '' COMMENT '用户昵称',
`email` varchar(50) NOT NULL COMMENT '用户邮箱',
`phone` varchar(20) DEFAULT '' COMMENT '手机号',
`gender` tinyint(4) unsigned DEFAULT '0' COMMENT '性别(0:男;1:女)',
`password` varchar(100) NOT NULL COMMENT '密码',
`age` tinyint(4) DEFAULT '0' COMMENT '年龄',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='app用户表'
--插入1000条数据
-- 方式一
DROP FUNCTION IF EXISTS mock_data;
delimiter $$ -- 写函数之前必须加上,这是函数的标识
CREATE FUNCTION mock_data()
RETURNs INT
BEGIN
DECLARE num INT DEFAULT 2000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO app_user(`name`,`email`,`phone`,`gender`,`PASSWORD`,`age`)
VALUES(CONCAT('用户',i),'123456789@qq.com',CONCAT('18',FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*2),UUID(),FLOOR(RAND()*10));
SET i = i+1;
END WHILE;
RETURN i;
END;
-- 4. 恢复语句结束符为;
DELIMITER ;
-- ================
-- 方式二
--插入1000条数据
-- 1. 先删除同名存储过程(避免重复创建报错)
DROP PROCEDURE IF EXISTS insert_batch_user;
-- 2. 创建存储过程
DELIMITER // -- 临时修改语句结束符为//(避免和存储过程内的;冲突)
CREATE PROCEDURE insert_batch_user()
BEGIN
DECLARE i INT DEFAULT 1; -- 定义循环变量,初始值1
WHILE i <= 100 DO -- 循环100次
INSERT INTO app_user(
`name`,
`email`,
`phone`,
`gender`,
`PASSWORD`,
`age`
)
VALUES(
CONCAT('用户', i),
CONCAT(FLOOR(RAND()*100000000), '@qq.com'),
CONCAT('18', FLOOR(RAND()*900000000 + 100000000)),
FLOOR(RAND()*2),
MD5(UUID()),
FLOOR(RAND()*50 + 18)
);
SET i = i + 1; -- 变量自增
END WHILE;
END //
DELIMITER ; -- 恢复语句结束符为;
-- 3. 调用存储过程(执行批量插入)
CALL insert_batch_user();
-- 4. 验证结果(可选)
SELECT COUNT(*) FROM app_user; -- 查看插入的总条数
--查询测试
SELECT * FROM app_user WHERE `name` = '用户9999'
--查询
SELECT * FROM app_user WHERE `name` = '用户9999'
SELECT * FROM student
-- id------表名------字段名
CREATE INDEX id_app_user_name ON app_user(`name`)
SELECT * FROM app_user WHERE `name` = '用户9999'
EXPLAIN SELECT * FROM app_user WHERE `name` = '用户9999'注意:索引在小数据量的时候,作用不大,但是在大数据的时候,区别十分明显。
索引原则
-
索引不是越多越好
-
不要对进程变动数据加索引
-
小数据量的表不需要加索引
-
索引一般加在常用来查询的字段上
用户管理
可视化管理
sql命令创建用户
sql
-- 用户管理==============
-- sql命令创建用户
-- 创建用户
-- 语法:CREATE USER 用户名 IDENTIFIED by 密码
CREATE USER zhangsan IDENTIFIED by '123456'
-- 修改当前用户密码
SET PASSWORD('1111111')
--重命名 RENAME USER 原来的名字 to 新名字
RENAME USER zhangsan to zhangsan2
-- 用户权限 ,ALL PRIVILEGES除了给别人授权,其他都能做
GRANT ALL PRIVILEGES ON *.* TO 'zhangsan2'
-- 查看权限
SHOW GRANT FOR zhangsan2 -- 查看指定用户的权限
-- 撤销权限 REVOKE 哪些权限,在哪个库撤销,给谁撤销
REVOKE ALL PRIVILEGES *.* FROM '张三'Mysql备份
为什么要备份:
-
保证重要的数据不丢失
-
数据转移
MySQL数据库备份的方式
-
直接拷贝物理文件
-
通过可视化软件
-
使用命令行导出:mysqldump 命令
导出命令
sql-- 导出 -- cdm中导出命令如下:mysqldump -h主机 -u用户名 -p密码 数据库 表名 >物理磁盘位置 mysqldump -hlocalhost -uroot -p123456 school1 student >D:/a.sql --导出多张表:cdm中导出命令如下:mysqldump -h主机 -u用户名 -p密码 数据库 表1 表2 表三 >物理磁盘位置 mysqldump -uroot -p123456 school student result >D:/a.sql -- 导入 在登录mysql的情况下:-- source D:/a.sql source 备份文件 在不登录的情况下 mysql -u用户名 -p密码 库名 < 备份文件
规范设计数据库
为什么需要设计?
当数据库比较复杂的时候,我们需要设计数据库
糟糕的数据库设计:
-
数据冗余,浪费空间
-
数据库插入和删除都会非常麻烦、异常
-
程序的性能差
良好的数据库设计:
-
节省内存空间
-
保证数据库的完整性
-
方便我们开发系统
软件开发中,关于数据库的设计
-
分析需求:分析业务和需要处理的数据库的需求
-
概要设计:设计关系E-R图
数据库的设计步骤
-
需求分析
-
概念设计
-
逻辑设计
-
物理设计
-
优化评审
三大范式
-
第一范式:字段原子化,不可再分
- 第一范式的目标是确保每列的原子性,如果每列都是不可再分的最小数据单元,则满足第一范式
-
第二范式:满足第一范式的基础上,消除部分依赖,必须有主键
- 在满足 1NF 的基础上,非主键字段必须完全依赖于主键,不能只依赖主键的一部分(仅针对 "复合主键" 生效)。
-
第三范式:满足第二范式的基础上,消除传递依赖
- 在满足 2NF 的基础上,非主键字段不能依赖于其他非主键字段
规范化和性能的关系(规范数据库的设计,成为相反关系)
-
关联查询的表不得超过三张表
-
为满足某种商业目标 , 数据库性能比规范化数据库更重要
-
在数据规范化的同时 , 要综合考虑数据库的性能
-
通过在给定的表中添加额外的字段,以大量减少需要从中搜索信息所需的时间
-
通过在给定的表中插入计算列,以方便查询
SQL注入问题
SQL注入是什么?
1.SQL 注入是**黑客通过构造恶意 SQL 语句,插入到应用程序的输入框 / 参数中**,让数据库执行非预期的 SQL 操作,从而窃取、篡改甚至删除数据库数据的攻击方式。
2.SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。例如:登录时,正常业务逻辑是:用户输入账号 / 密码,程序拼接 SQL 查询
sql
-- 预期的正常SQL(用户输入:账号=小明,密码=123456)
SELECT * FROM user WHERE username='小明' AND password='123456';黑客恶意输入:在账号输入框填 小明' OR '1'='1,密码随便填,拼接后的 SQL 变成:
sql
-- 恶意SQL(OR '1'='1'永远为真,绕过密码验证)
SELECT * FROM user WHERE username='小明' OR '1'='1' AND password='任意值';结果是无需正确密码,直接可登录成功!
SQL注入的危害性:
-
数据泄露:窃取用户手机号、密码、身份证、订单等敏感数据
-
越权操作:绕过登录验证,登录管理员账号,篡改用户信息、订单状态;
-
数据破坏:删除 / 修改数据库表、清空数据,导致业务无法运行;
-
服务器控制:通过注入获取数据库服务器权限,进而控制整个服务器
如何防止SQL注入?
使用预编译语句:把 SQL 语句的 "结构" 和 "参数" 分开,参数部分由数据库自动转义,杜绝拼接风险。
例如在Java中
java
// 错误写法(直接拼接,易注入)
String sql = "SELECT * FROM user WHERE username='" + username + "' AND password='" + password + "'";
Statement stmt = conn.createStatement();
stmt.executeQuery(sql);
// 正确写法(预编译,参数化)
String sql = "SELECT * FROM user WHERE username=? AND password=?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, username); // 参数1:用户名
pstmt.setString(2, password); // 参数2:密码
// 参数2:密码
pstmt.executeQuery();