大语言模型系统:【CMU 11-868】课程学习笔记06------Transformer学习(Transformer)
- 前言
- [一、实现Transformer,大语言模型的核心架构(Implementing Transformer, the backbone of LLMs)](#一、实现Transformer,大语言模型的核心架构(Implementing Transformer, the backbone of LLMs))
-
- [1.1 编码器-解码器架构(Encoder-decoder architecture)](#1.1 编码器-解码器架构(Encoder-decoder architecture))
- [1.2 词嵌入(Embedding)](#1.2 词嵌入(Embedding))
- [1.3 多头注意力和前馈网络,解码器自注意力(Multihead Attention and FFN, Decoder Self-Attention)](#1.3 多头注意力和前馈网络,解码器自注意力(Multihead Attention and FFN, Decoder Self-Attention))
- [二、Transformer的训练技术与性能(Training techniques and Performance of Transformer)](#二、Transformer的训练技术与性能(Training techniques and Performance of Transformer))
- [三、代码讲解(Code walkthrough)](#三、代码讲解(Code walkthrough))
-
- [3.1 第一部分:模型架构](#3.1 第一部分:模型架构)
-
- [3.1.1 编码器-解码器架构(Encoder and Decoder Stacks)](#3.1.1 编码器-解码器架构(Encoder and Decoder Stacks))
- [3.1.2 位置前馈网络(Position-wise Feed-Forward Networks)](#3.1.2 位置前馈网络(Position-wise Feed-Forward Networks))
- [3.1.3 嵌入层和 Softmax(Embeddings and Softmax)](#3.1.3 嵌入层和 Softmax(Embeddings and Softmax))
- [3.1.4 位置编码(Positional Encoding)](#3.1.4 位置编码(Positional Encoding))
- [3.1.5 完整模型(Full Model)](#3.1.5 完整模型(Full Model))
- [3.1.6 推理(Inference)](#3.1.6 推理(Inference))
- 推荐课外阅读资料
前言
【CMU 11-868】课程面向研究生开设,聚焦"从算法到工程"的大语言模型系统构建全过程。课程内容包括但不限于:
- GPU 编程与自动微分:掌握 CUDA kernel 调用、并行编程基础,以及深度学习框架设计原理
- 模型训练与分布式系统:学习高效的训练算法、通信优化(ZeRO、FlashAttention)、分布式训练框架(DDP、GPipe、Megatron-LM)。
- 模型压缩与加速:量化(GPTQ)、稀疏化(MoE)、编译技术(JAX、Triton)、以及推理时的服务化设计(vLLM、CacheGen)。
- 前沿技术与系统实践:涵盖检索增强生成(RAG)、多模态 LLM、RLHF 系统,以及端到端的在线维护和监控。
一、实现Transformer,大语言模型的核心架构(Implementing Transformer, the backbone of LLMs)
1.1 编码器-解码器架构(Encoder-decoder architecture)
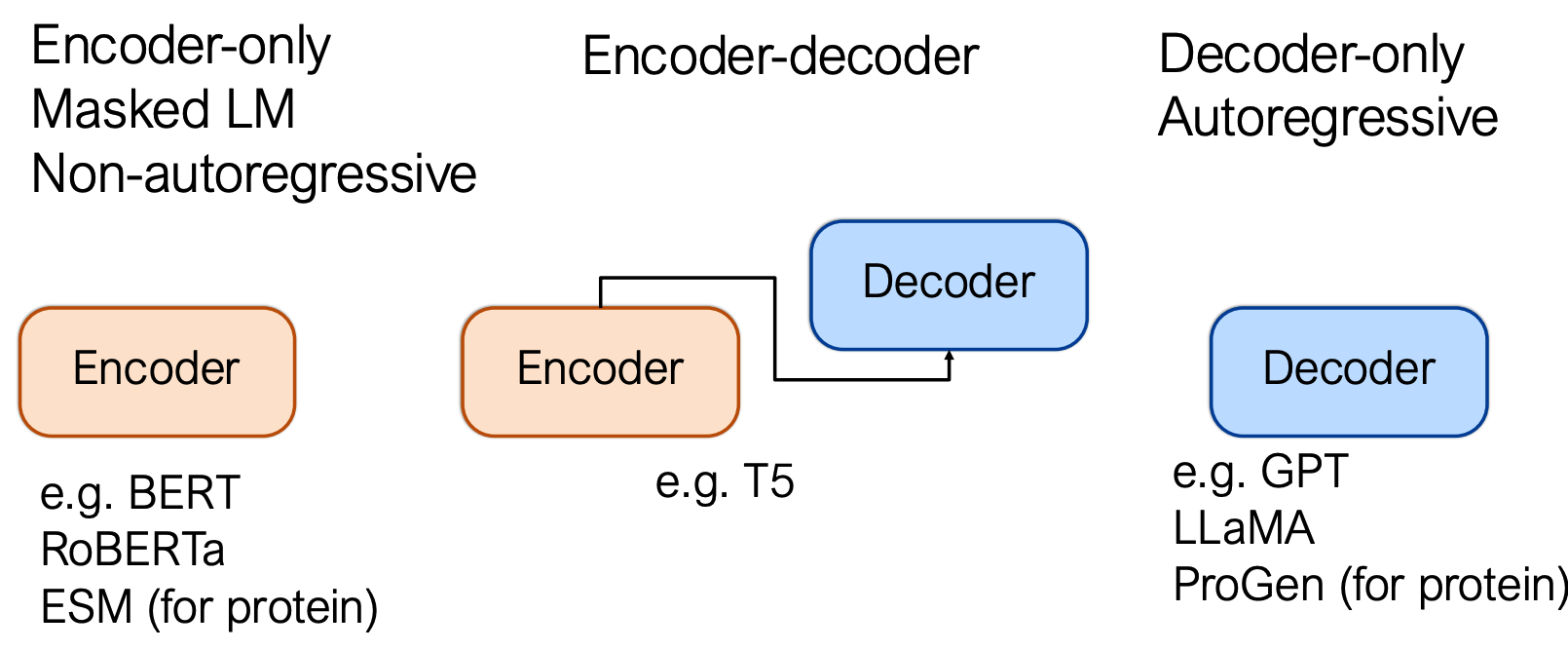
1️⃣ 语言模型类型(Type of Language Models)
语言模型包括仅编码器、编码器-解码器和仅解码器类型。
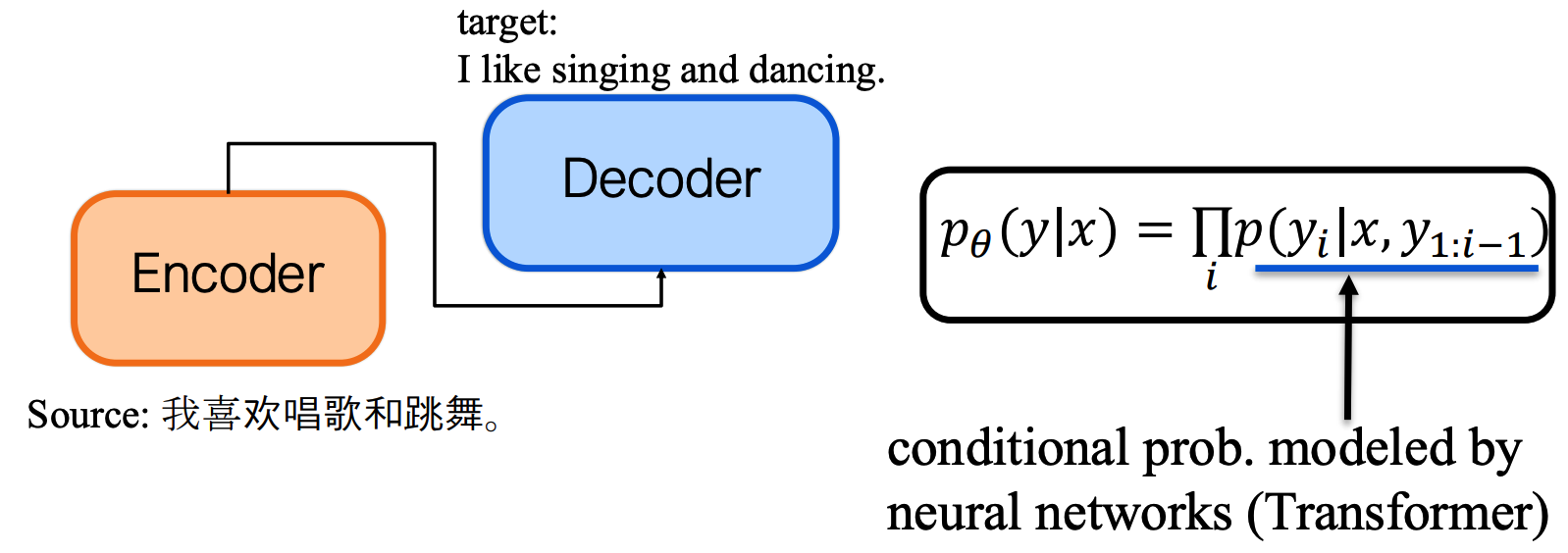
2️⃣ 编码器-解码器范式(Encoder-Decoder Paradigm)
核心任务:将源序列(如中文 "我喜欢唱歌和跳舞。")映射到目标序列(如英文 "I like singing and dancing.")。
条件概率建模: p θ ( y ∣ x ) = ∏ i p ( y i ∣ x , y 1 : i − 1 ) p_{\theta}(y|x) = \prod_{i} p(y_i|x, y_{1:i-1}) pθ(y∣x)=∏ip(yi∣x,y1:i−1),其中概率由 Transformer 神经网络建模。
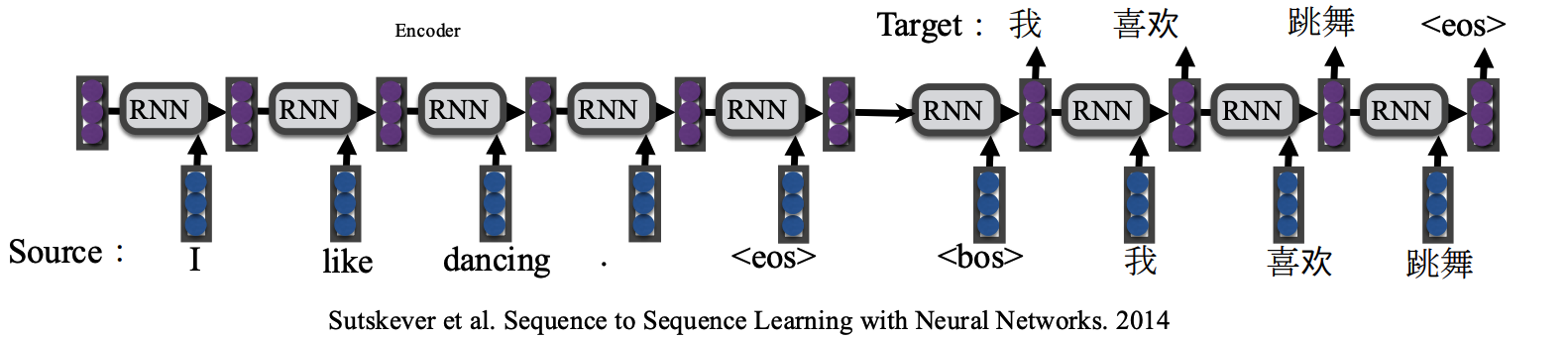
3️⃣ 序列到序列学习(Sequence to Sequence Learning)
条件文本生成 :直接学习从源序列到目标序列的映射函数,概率公式:
p θ ( y ∣ x ) = ∏ t p ( y t ∣ x , y 1 : t − 1 ; θ ) p_{\theta}(y | x)=\prod_{t} p\left(y_{t} | x, y_{1: t-1} ; \theta\right) pθ(y∣x)=t∏p(yt∣x,y1:t−1;θ)
早期编码器/解码器:LSTM或GRU。
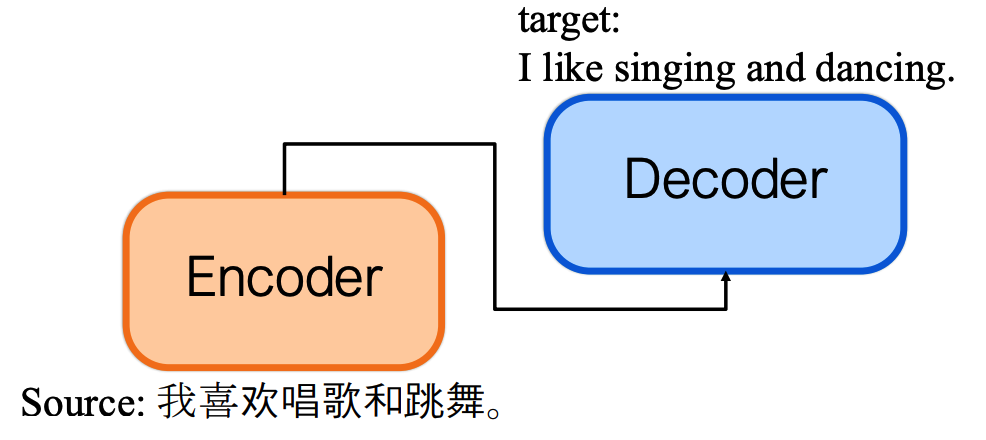
4️⃣ 新架构的动机(Motivation for a new Architecture)
- 传统 RNN 缺陷:无法并行计算,依赖序列顺序,上下文捕捉不充分。
- Transformer 改进:编码器和解码器均采用注意力机制(Attention)。
- 全上下文捕捉:注意力机制可同时关注输入序列所有位置。
- 并行编码:无循环结构,支持并发计算,提升效率。
完整语境与并行性:在编码器和解码器中均使用注意力机制。
无循环 ==> 并行编码。
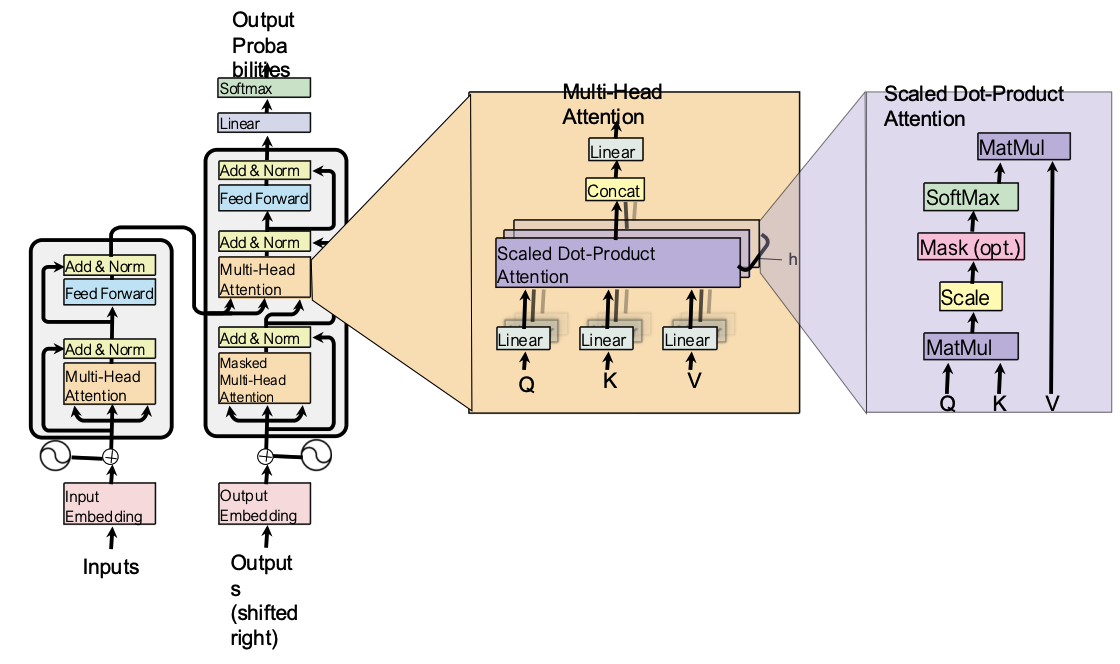
5️⃣ Transformer架构(Transformer)
- 输入:源序列(如中文 "我喜欢唱歌和跳舞。")+ 位置嵌入(pos emb)→ 编码器(Encoder)
- 编码器输出 + 目标序列(右移后)+ 位置嵌入 → 解码器(Decoder)
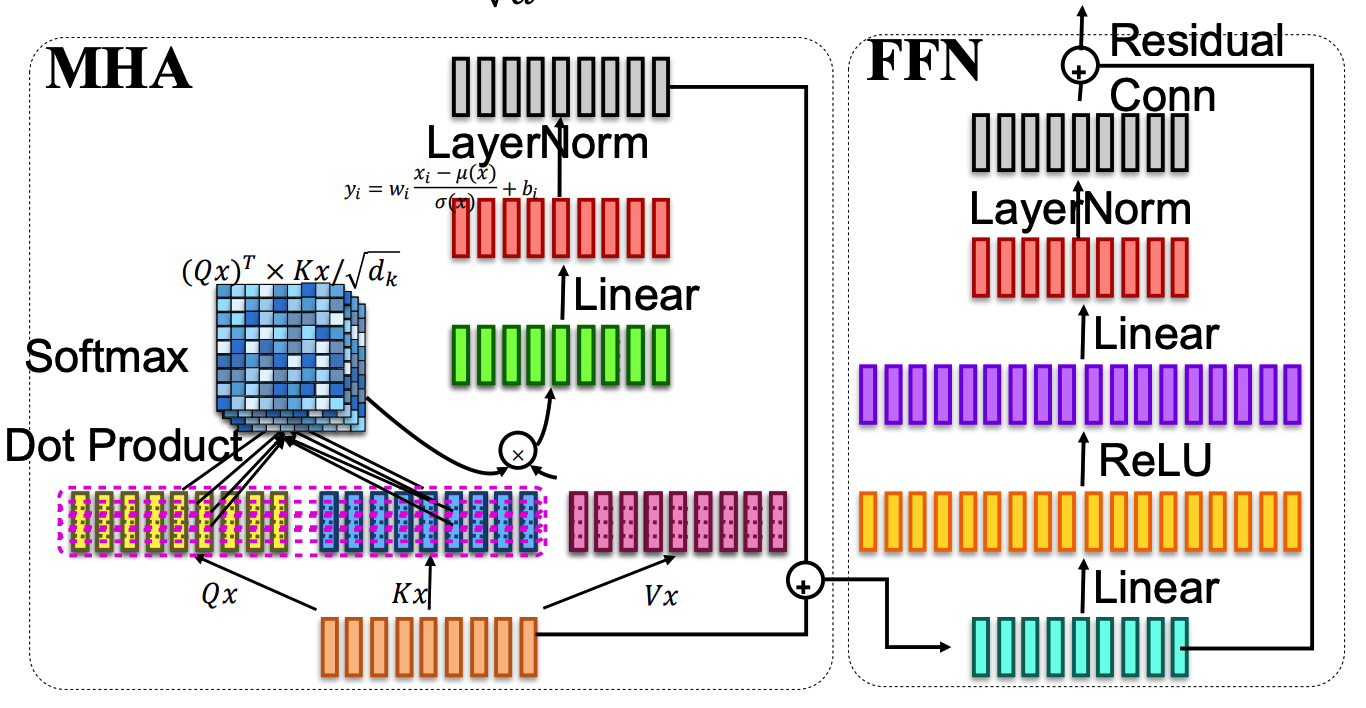
- 核心组件:令牌嵌入(Token Emb)、位置嵌入(Positional Emb)、多头注意力(MHA)、前馈网络(FFN)、残差连接(Residual Conn)、层归一化(LayerNorm)、Softmax
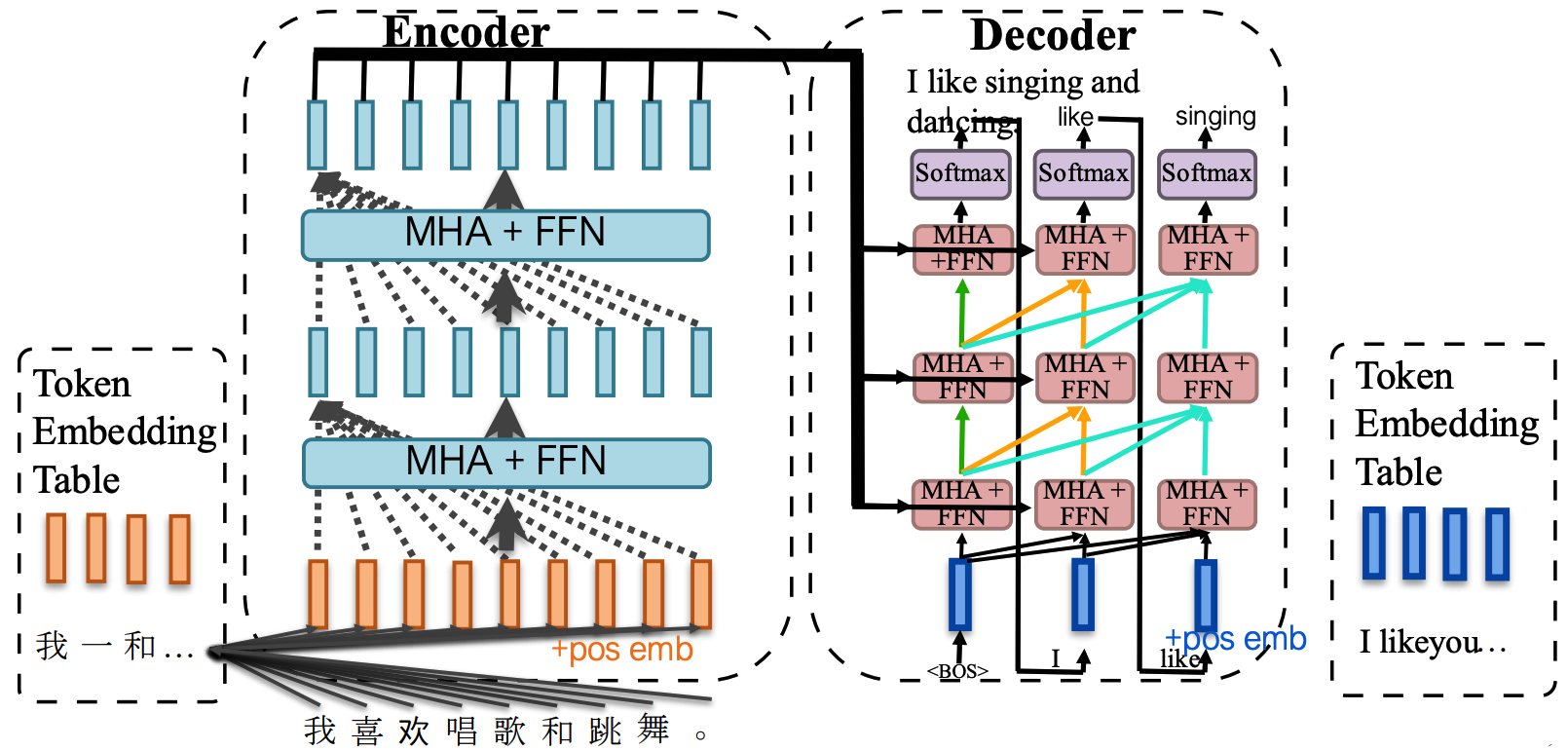
1.2 词嵌入(Embedding)
1️⃣ 令牌嵌入(Token Embedding)
核心:通过查找表实现输入与输出嵌入的共享(tied),tokenization将在后续课程讲解。
2️⃣ 位置嵌入(Positional Embedding)
区分不同位置的单词,弥补无循环结构导致的位置信息缺失。维度与令牌嵌入维度一致,对于第 t 个位置,第 i 个维度,计算公式如下:
P E t , 2 i = sin ( t 1000 2 i / d ) P E t , 2 i + 1 = cos ( t 1000 2 i / d ) P E_{t, 2 i}=\sin \left(\frac{t}{1000^{2 i / d}}\right) \\ P E_{t, 2 i+1}=\cos \left(\frac{t}{1000^{2 i / d}}\right) PEt,2i=sin(10002i/dt)PEt,2i+1=cos(10002i/dt)
1.3 多头注意力和前馈网络,解码器自注意力(Multihead Attention and FFN, Decoder Self-Attention)
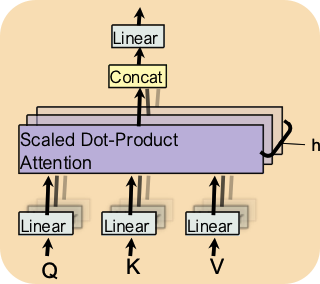
1️⃣ 多头注意力(Multi-head Attention)
核心思想:
- 不使用单个向量表示每个令牌,而是将其拆分到多个 "头"(head)。
- 每个头独立执行注意力计算,最终拼接结果并线性变换,捕捉多维度语义信息。
H e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) M u l t i H e a d ( Q , K , V ) = C o n c a t ( H e a d 1 , H e a d 2 , ... , H e a d h ) W o Head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) \\ MultiHead(Q,K,V)=Concat(Head_1,Head_2 ,...,Head_h)W_o Headi=Attention(QWiQ,KWiK,VWiV)MultiHead(Q,K,V)=Concat(Head1,Head2,...,Headh)Wo
X X X 是来自前一层的输入嵌入(num of token * dim)。缩放点积注意力(Scaled Dot-Product Attention)公式如下:
S o f t m a x ( Q × K T d k ) ⋅ V Softmax(\frac{Q \times K^T}{\sqrt{d_k}}) \cdot V Softmax(dk Q×KT)⋅V
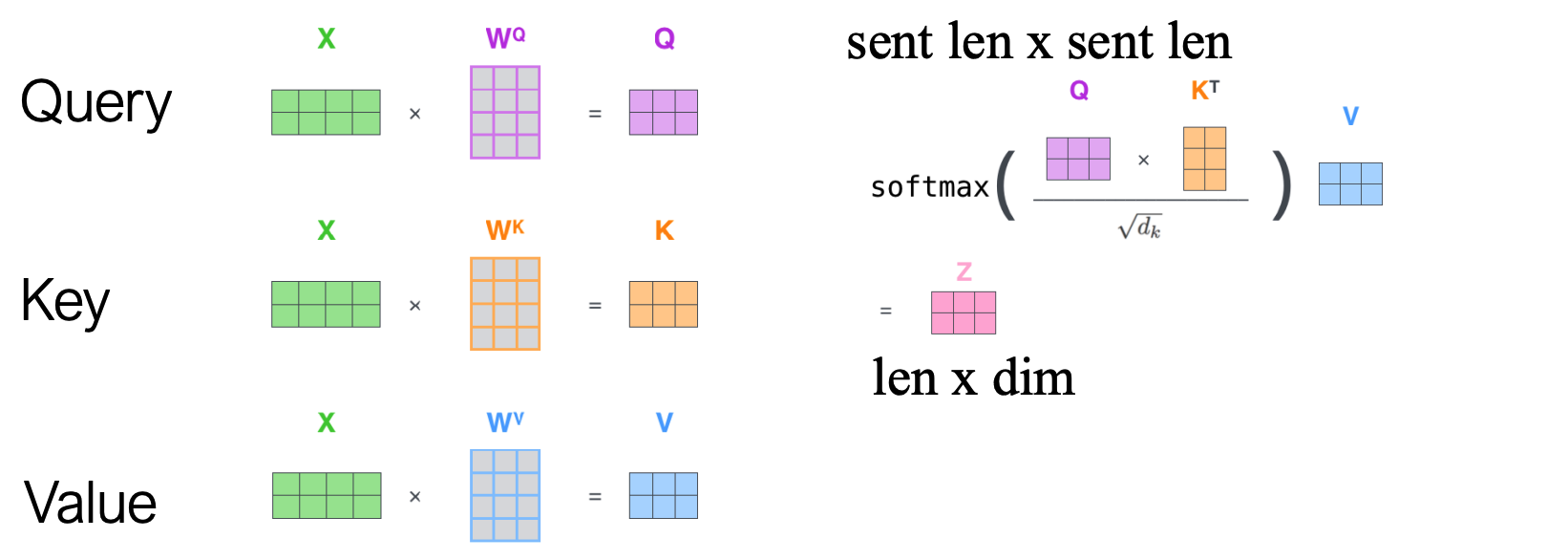
问题:为何除以 d k \sqrt{d_k} dk ?
缓解点积结果随维度增长而过大的问题,保证 Softmax 输出稳定。
2️⃣ 多头注意力和前馈网络(Multihead Attention and FFN)
A t t e n t i o n ( 𝑄 , 𝐾 , 𝑉 , 𝑥 ) = S o f t m a x ( ( 𝑄 𝑥 ) 𝑇 𝐾 𝑥 d ) ⋅ ( 𝑉 𝑥 ) 𝑇 F F N ( 𝑥 ) = 𝑚 𝑎 𝑥 ( 0 , 𝑥 ⋅ 𝑊 1 + 𝑏 1 ) ⋅ 𝑊 2 + 𝑏 2 Attention(𝑄, 𝐾, 𝑉, 𝑥) = Softmax(\frac{(𝑄𝑥)^𝑇𝐾𝑥}{\sqrt{d}} ) ⋅(𝑉𝑥)^𝑇 \\ FFN(𝑥) = 𝑚𝑎𝑥(0, 𝑥⋅𝑊1 + 𝑏1) ⋅𝑊2 + 𝑏2 Attention(Q,K,V,x)=Softmax(d (Qx)TKx)⋅(Vx)TFFN(x)=max(0,x⋅W1+b1)⋅W2+b2
FFN结构:两层线性变换 + ReLU 激活函数(第一层升维,第二层降维)。
3️⃣ 解码器自注意力(Decoder Self-Attention)
在softmax前屏蔽右侧(负无穷)。
4️⃣ 残差连接和层归一化(Residual Connection and Layer Normalization)
- 残差连接;
- 在层内使其具有零均值和单位方差;
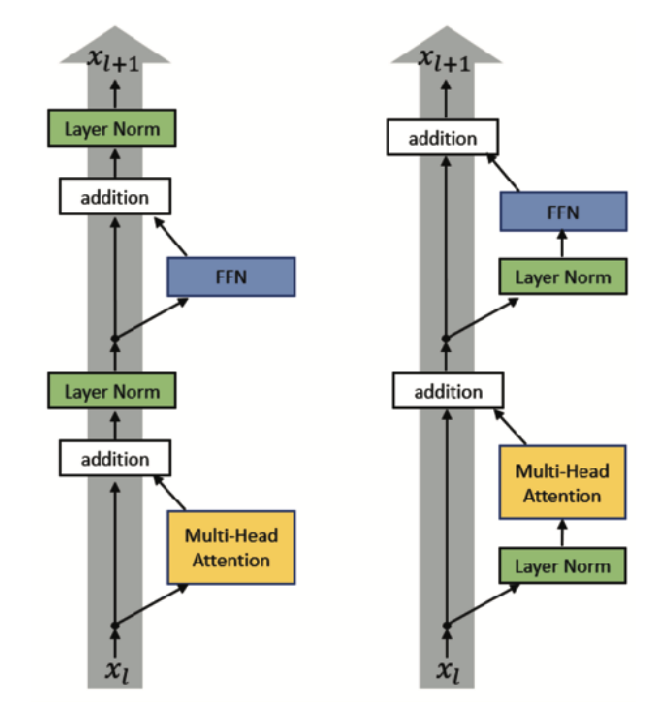
- 后归一化(Post-norm);
- 前归一化(Pre-norm);
二、Transformer的训练技术与性能(Training techniques and Performance of Transformer)
1️⃣ 原始论文中的Transformer(Transformer in Original Paper)
- 编码器层数(C):6 层
- 解码器层数(D):6 层
- 令牌嵌入维度:基础模型(base)512,大型模型(large)1024
- FFN 隐藏层维度:2048
- 输入:源序列
- 输出:目标序列概率分布(经 Softmax 得到)
2️⃣ 训练Transformer(Training Transformer)
损失函数:交叉熵损失(Cross-Entropy):
l = − ∑ n ∑ t l o g f θ ( x n , y n , 1 , . . . , y n , t − 1 ) l=-\sum_{n} \sum_{t} log f_{\theta}\left(x_{n}, y_{n, 1}, ..., y_{n, t-1}\right) l=−n∑t∑logfθ(xn,yn,1,...,yn,t−1)
其中 f θ f_{\theta} fθ 为模型预测函数, x n x_n xn 为第 n 个样本的源序列, y n , 1 : t − 1 y_{n,1:t-1} yn,1:t−1 为目标序列的前缀。
训练时教师强制(Teacher-forcing):训练时,解码器的输入使用真实目标序列的前缀(而非模型预测的前缀),加速收敛。
3️⃣ 训练Transformer用于机器翻译(Training Transformer for MT)
Dropout 正则化:应用位置:残差连接前、嵌入层、位置嵌入层。丢弃概率(p):0.1~0.3。
标签平滑(Label Smoothing):分配给非真实情况的概率为0.1。
词汇(Vocabulary):En-De:使用BPE中的37K数量的数据。英-法:32k数量的数据(类似于BPE)。
4️⃣ 标签平滑(Label Smoothing)
动机:缓解 one-hot 标签的过拟合问题,降低模型对 "正确标签" 的过度自信。
原始 one-hot 标签: y i = { 1 属于第 i 类 0 其他情况 y_i=\begin{cases}1 & 属于第 i 类 \\ 0 & 其他情况 \end{cases} yi={10属于第i类其他情况;
平滑后标签: y i = { 1 − ϵ 属于第 i 类 ϵ / ( n − 1 ) 其他情况 y_i=\begin{cases}1-\epsilon & 属于第 i 类 \\ \epsilon/(n-1) & 其他情况 \end{cases} yi={1−ϵϵ/(n−1)属于第i类其他情况(n 为类别数)。常用 ϵ = 0.1 \epsilon=0.1 ϵ=0.1。
5️⃣ 训练(Training)
批量处理(Batch):
- 策略:按句子长度近似分组(减少 padding 带来的计算浪费)。
- 要求:训练前需打乱数据。
Adam优化器:
- 学习率调度:热身阶段(warmup)提升学习率,之后随步数下降;
- η = 1 d m i n ( 1 t , t t 0 3 ) \eta=\frac{1}{\sqrt{d}} min \left(\frac{1}{\sqrt{t}}, \frac{t}{\sqrt{t_{0}^{3}}}\right) η=d 1min(t 1,t03 t)。
6️⃣ Adam优化器(ADAM)
参数更新公式:
m t + 1 = β 1 m t + ( 1 − β 1 ) ∇ ℓ ( x t ) v t + 1 = β 2 v t + ( 1 − β 2 ) ( ∇ ℓ ( x t ) ) 2 m ^ t + 1 = m t + 1 1 − β 1 t + 1 v ^ t + 1 = v t + 1 1 − β 2 t + 1 x t + 1 = x t − η v ^ t + 1 + ϵ m ^ t + 1 m_{t+1}=\beta {1}m{t}+(1-\beta {1})\nabla \ell (x{t}) \\ \space \\ v_{t+1}=\beta {2}v{t}+(1-\beta {2})(\nabla \ell (x{t}))^{2} \\ \space \\ \hat{m}{t+1}=\frac{m{t+1}}{1-\beta_{1}^{t+1}} \\ \space \\ \hat{v}{t+1}=\frac{v{t+1}}{1-\beta_{2}^{t+1}} \\ \space \\ x_{t+1}=x_{t}-\frac{\eta}{\sqrt{\hat{v}{t+1}}+\epsilon} \hat{m}{t+1} mt+1=β1mt+(1−β1)∇ℓ(xt) vt+1=β2vt+(1−β2)(∇ℓ(xt))2 m^t+1=1−β1t+1mt+1 v^t+1=1−β2t+1vt+1 xt+1=xt−v^t+1 +ϵηm^t+1
其中 m t m_t mt 为一阶动量, v t v_t vt 为二阶动量, ϵ \epsilon ϵ 为防止分母为 0 的微小值。
7️⃣ 模型平均(Model Average)
方法:对最后 5 个检查点(checkpoint,每 10 分钟保存一次)的模型参数取平均。
作用:提升模型稳定性和泛化能力。
解码长度:源序列长度 + 50(避免输出过短或过长)。
注:解码细节将在后续课程讲解。
三、代码讲解(Code walkthrough)
参考资料:https://nlp.seas.harvard.edu/annotated-transformer/。
3.1 第一部分:模型架构
3.1.1 编码器-解码器架构(Encoder and Decoder Stacks)
大多数神经序列转导模型都具有编码器-解码器 (Encoder-Decoder) 结构。编码器将输入符号序列 ( x 1 , ... , x n ) (x_1, \dots, x_n) (x1,...,xn) 映射到一个连续表示序列 z = ( z 1 , ... , z n ) z = (z_1, \dots, z_n) z=(z1,...,zn)。给定 z z z 后,解码器再生成一个输出符号序列 ( y 1 , ... , y m ) (y_1, \dots, y_m) (y1,...,ym),每次生成一个元素。在每一步中,模型都是自回归的(Auto-regressive),即在生成下一个符号时,会将之前生成的符号作为额外的输入。
python
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
python
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)Transformer 遵循这种整体架构,编码器和解码器分别采用堆叠式自注意力层和逐点全连接层,如下图的左半部分和右半部分所示。
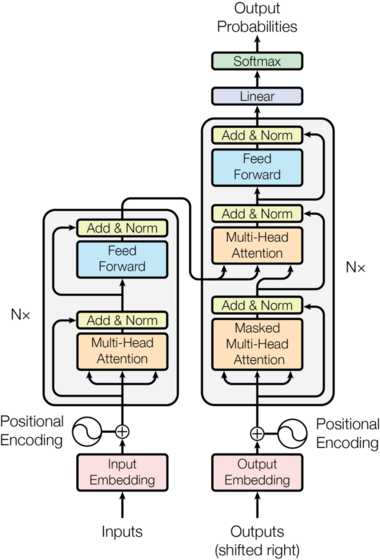
1️⃣ 编码器(Encoder)
编码器由 N = 6 N=6 N=6 个完全相同的层堆叠而成。
python
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
python
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)我们在两个子层之间采用残差连接,然后进行层归一化。
python
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2也就是说,每个子层的输出为: LayerNorm ( x + Sublayer ( x ) ) \text{LayerNorm}(x + \text{Sublayer}(x)) LayerNorm(x+Sublayer(x))。其中, Sublayer ( x ) \text{Sublayer}(x) Sublayer(x) 是子层本身实现的函数(如自注意力机制或前馈网络)。在将子层的输出与输入 x x x 相加并进行归一化之前,我们会先对该输出应用 Dropout。
为了便于实现这些残差连接,模型中的所有子层以及嵌入层(embedding layers)所产生的输出维度均固定为 d model = 512 d_{\text{model}} = 512 dmodel=512。
python
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))每一层都有两个子层。第一层是多头自注意力机制,第二层是一个简单的、按位置全连接的前馈网络。
python
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
2️⃣ 解码器(Decoder)
解码器也由一个堆栈组成 N = 6 N=6 N=6 相同的层。
python
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)除了每个编码器层中的两个子层之外,解码器还插入了第三个子层,该子层对编码器堆栈的输出执行多头注意力机制。与编码器类似,我们在每个子层周围都使用了残差连接,然后进行层归一化。
python
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
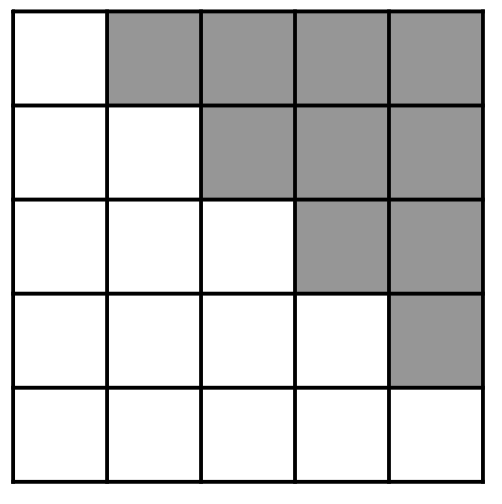
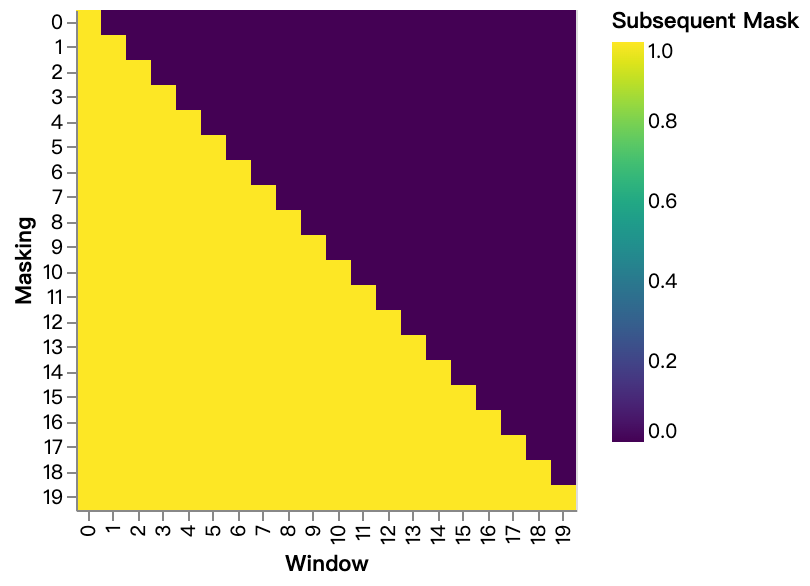
return self.sublayer[2](x, self.feed_forward)我们还修改了解码器堆栈中的自注意力子层,以防止当前位置关注到其后的位置。这种掩码(Masking)处理,结合"输出嵌入向后偏移一个位置"这一事实,确保了对位置 i i i 的预测只能依赖于小于 i i i 的已知位置的输出。
python
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0下方的注意力掩码展示了每个目标词(行)允许关注的位置(列)。在训练过程中,系统会屏蔽单词对后续"未来"单词的注意力。
3️⃣ 注意力(Attention)
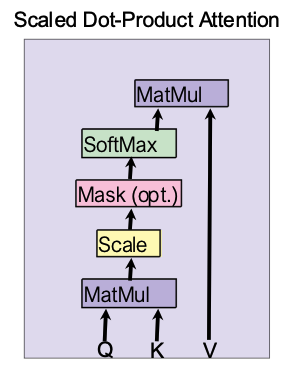
注意力函数可以被描述为将一个查询和一组键值对映射到一个输出的过程,其中查询、键、值以及输出均为向量。输出是通过对值进行加权求和计算得到的,而分配给每个值的权重则是通过计算查询与对应键的相容性函数得出的。
我们称我们这种特定的注意力机制为"缩放点积注意力"。输入由维度为 d k d_k dk 的查询和键以及维度为 d v d_v dv 的值组成。我们计算查询与所有键的点积,将每个结果除以 d k \sqrt{d_k} dk ,并应用 softmax 函数以获得分配在值上的权重。
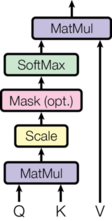
在实践中,我们同时对一组查询计算注意力函数,并将其打包成矩阵 Q Q Q。键和值也被分别打包成矩阵 K K K 和 V V V。我们按下式计算输出矩阵:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
python
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn两种最常用的注意力函数是加法注意力(additive attention)和点积(乘法)注意力。除了缩放因子 1 / d k 1/\sqrt{d_k} 1/dk 之外,点积注意力与我们的算法完全相同。加法注意力使用具有单个隐藏层的前馈网络来计算兼容性函数。虽然两者在理论复杂度上相似,但在实际应用中,点积注意力速度更快且更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
加法注意力:Neural Machine Translation by Jointly Learning to Align and Translate。
虽然对于较小的 d k d_k dk 值,两种机制的表现相似,但对于较大的 d k d_k dk 值,如果不进行缩放,加法注意力的表现优于点积注意力(cite)。我们推测,对于较大的 d k d_k dk 值,点积的量级会增大,从而将 softmax 函数推向梯度极小的区域。(为了说明点积为何变大,假设 q q q 和 k k k 的分量是均值为 0 0 0、方差为 1 1 1 的独立随机变量。那么它们的点积 q ⋅ k = ∑ i = 1 d k q i k i q \cdot k = \sum_{i=1}^{d_k} q_i k_i q⋅k=∑i=1dkqiki 的均值为 0 0 0,方差为 d k d_k dk。)为了抵消这种影响,我们使用 1 / d k 1/\sqrt{d_k} 1/dk 对点积进行缩放。
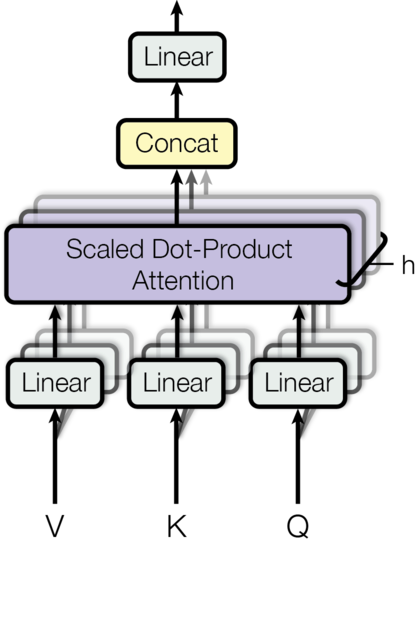
多头注意力机制允许模型同时关注来自不同表征子空间、位于不同位置的信息。而单头注意力机制则会通过平均来抑制这种能力。 M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , ... , h e a d h ) W O While h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) MultiHead(Q, K, V) = Concat(head_1, \dots, head_h)W^O \\ \text{While} \space head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,...,headh)WOWhile headi=Attention(QWiQ,KWiK,VWiV)
这里的投影是参数矩阵 W i Q ∈ R d m o d e l × d k W_i^Q \in \mathbb{R}^{d_{model} \times d_k} WiQ∈Rdmodel×dk, W i K ∈ R d m o d e l × d k W_i^K \in \mathbb{R}^{d_{model} \times d_k} WiK∈Rdmodel×dk, W i V ∈ R d m o d e l × d v W_i^V \in \mathbb{R}^{d_{model} \times d_v} WiV∈Rdmodel×dv 以及 W O ∈ R h d v × d m o d e l W^O \in \mathbb{R}^{hd_v \times d_{model}} WO∈Rhdv×dmodel。
在这项工作中,我们采用了 h = 8 h=8 h=8 个并行的注意力层,即"头"。对于每一个头,我们使用 d k = d v = d m o d e l / h = 64 d_k = d_v = d_{model}/h = 64 dk=dv=dmodel/h=64。由于每个头的维度降低了,其总计算成本与具有全维度的单头注意力相似。
python
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)注意力机制在我们模型中的应用
Transformer模型以三种不同的方式使用多头注意力机制:
1)在"编码器-解码器注意力"层中,查询来自前一个解码器层,记忆键和值来自编码器的输出。这使得解码器中的每个位置都能关注输入序列中的所有位置。这模拟了序列到序列模型中典型的编码器-解码器注意力机制。
2)编码器包含自注意力层。在自注意力层中,所有键、值和查询都来自同一位置,在本例中,即编码器前一层的输出。编码器中的每个位置都可以关注其前一层中的所有位置。
3)类似地,解码器中的自注意力层允许解码器中的每个位置关注解码器中直至该位置的所有位置。我们需要阻止解码器中信息的左向流动,以保持自回归特性。我们在缩放点积注意力机制中通过屏蔽softmax 输入中所有对应于非法连接的值(设置为负无穷)来实现这一点。
3.1.2 位置前馈网络(Position-wise Feed-Forward Networks)
除了注意力子层外,我们的编码器和解码器中的每一层都包含一个全连接的前馈网络,该网络分别且相同地应用于每个位置。它由两个线性变换组成,中间夹有一个 ReLU 激活函数: F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
尽管不同位置上的线性变换是相同的,但在层与层之间它们使用不同的参数。另一种描述方式是将其视为两个卷积核大小为 1 1 1 的卷积。输入和输出的维度为 d m o d e l = 512 d_{model} = 512 dmodel=512,内部层的维度为 d f f = 2048 d_{ff} = 2048 dff=2048。
python
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))
3.1.3 嵌入层和 Softmax(Embeddings and Softmax)
与其他序列转导模型类似,我们使用学习到的嵌入将输入标记和输出标记转换为维度为 d m o d e l d_{model} dmodel 的向量。我们还使用通常的学习线性变换和 softmax 函数,将解码器输出转换为预测的下一个标记概率。在我们的模型中,我们在两个嵌入层和 softmax 前的线性变换之间共享相同的权重矩阵。在嵌入层中,我们将这些权重乘以 d m o d e l \sqrt{d_{model}} dmodel 。
python
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
3.1.4 位置编码(Positional Encoding)
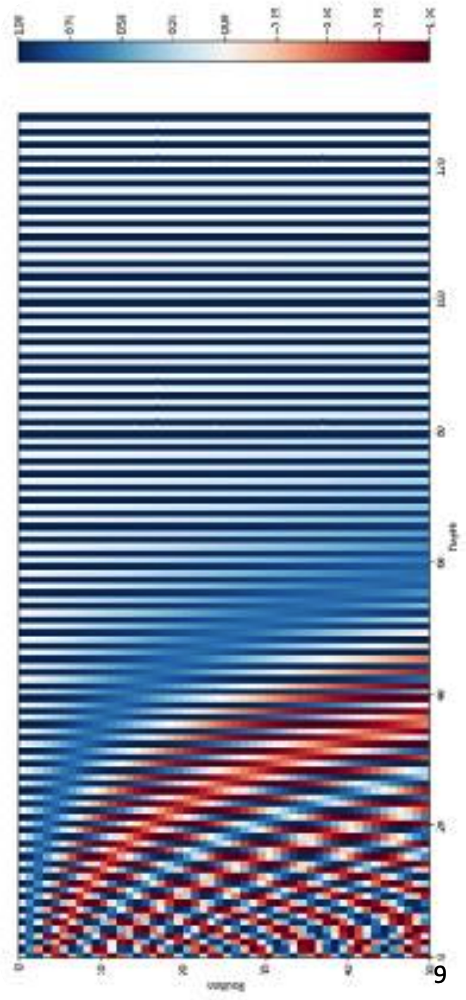
由于我们的模型不包含循环和卷积,为了使模型能够利用序列的顺序,我们必须注入一些关于序列中标记(token)相对或绝对位置的信息。为此,我们在编码器和解码器堆栈底部的输入嵌入中添加了"位置编码"。位置编码与嵌入具有相同的维度 d m o d e l d_{model} dmodel,因此两者可以相加。位置编码有多种选择,包括学习得出的和固定生成的。
在这项工作中,我们使用不同频率的正弦和余弦函数: P E ( p o s , 2 i ) = sin ( p o s / 10000 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s / 10000 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{model}})\\PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 p o s pos pos 是位置, i i i 是维度。也就是说,位置编码的每个维度都对应一个正弦曲线。波长形成从 2 π 2\pi 2π 到 10000 ⋅ 2 π 10000 \cdot 2\pi 10000⋅2π 的几何级数。我们选择这个函数是因为我们假设它能让模型轻松地通过相对位置来学习注意力,因为对于任何固定的偏移量 k k k, P E p o s + k PE_{pos+k} PEpos+k 都可以表示为 P E p o s PE_{pos} PEpos 的线性函数。
此外,我们在编码器和解码器堆栈中,对嵌入与位置编码之和应用了 dropout。对于基础模型,我们使用的比率为 P d r o p = 0.1 P_{drop} = 0.1 Pdrop=0.1。
python
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)在位置编码下方,会根据位置添加一个正弦波。每个维度的波形频率和偏移量都不同。
我们还尝试使用学习到的位置嵌入,发现两种方法得到的结果几乎相同。我们选择正弦嵌入是因为它可以让模型外推到比训练过程中遇到的序列长度更长的序列。
3.1.5 完整模型(Full Model)
在这里,我们定义了一个从超参数到完整模型的函数。
python
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
3.1.6 推理(Inference)
在这里,我们进行一次前向迭代,生成模型的预测结果。我们尝试使用 Transformer 来记忆输入。正如你所看到的,由于模型尚未训练,输出是随机生成的。在下一个教程中,我们将构建训练函数,并尝试训练模型来记忆 1 到 10 之间的数字。
python
def inference_test():
test_model = make_model(11, 11, 2)
test_model.eval()
src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])
src_mask = torch.ones(1, 1, 10)
memory = test_model.encode(src, src_mask)
ys = torch.zeros(1, 1).type_as(src)
for i in range(9):
out = test_model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = test_model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
print("Example Untrained Model Prediction:", ys)
def run_tests():
for _ in range(10):
inference_test()
show_example(run_tests)
其他部分暂时省略。
推荐课外阅读资料
Transformer论文:https://arxiv.org/abs/1706.03762。
Neural Machine Translation of Rare Words with Subword Units. Sennrich et al. 2016.
SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. Kudo and Richardson. 2018.