更加完整详细内容可查看【免费版Java学习笔记】和【免费版Java面试题】
免费版Java学习笔记(28w字)链接:https://www.yuque.com/aoyouaoyou/sgcqr8
免费版Java面试题(20w字)链接:https://www.yuque.com/aoyouaoyou/wh3hto
完整版Java学习笔记200w字,附有代码实现,图解清楚,仅需9.9
完整版Java面试题,150w字,高频面试题,内容详细,仅需9.9
完整版链接:
https://www.xiaohongshu.com/user/profile/63c2d512000000002601232c
祝您新的一年事事马到成功,身体健康,阖家幸福,大展宏图!
一、Trie树介绍
1.1 定义与定位
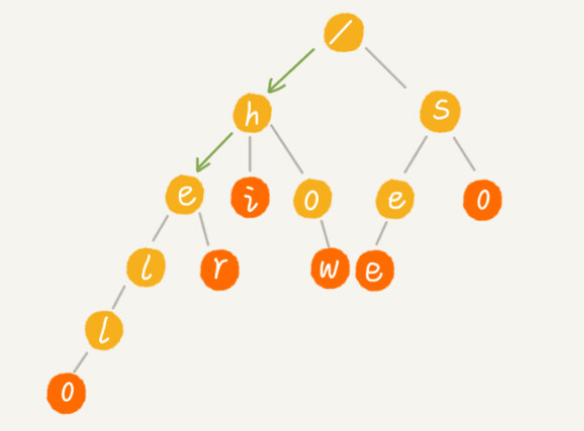
Trie树也叫字典树/前缀树 ,是一种专门为字符串匹配设计的树形数据结构 ,用于解决一组字符串集合中快速查找、匹配指定字符串 的问题,尤其擅长处理与公共前缀相关的字符串操作。
1.2 设计理念
Trie树的本质是利用字符串之间的公共前缀,将重复的前缀合并存储 ,通过树形结构消除字符串前缀的冗余存储,同时让匹配过程能沿着前缀路径快速遍历,从根本上提升字符串查找效率。
比如字符串集合aoyou、aocode、apple、app、so、see,其中ao、app是公共前缀,Trie树会将这些公共前缀只存储一次,所有含该前缀的字符串共享这部分路径。
1.3 结构特征
- 树形结构 :属于多叉树,根节点不存储任何有效字符,仅作为遍历的起点;
- 节点含义 :每个非根节点表示一个字符串中的单个字符;
- 路径表示字符串 :从根节点到标记为"结束"的节点的一条完整路径,对应一个完整的字符串;
- 结束标记 :节点包含一个布尔标识(如
isEndingChar),标记该节点是否为某个字符串的最后一个字符 (避免前缀匹配与完整匹配混淆,比如区分app和apple)。
1.4 与传统字符串匹配算法的差异
BF/RK/BM等算法适用于**"主串中找模式串"的单串匹配场景,而Trie树适用于"字符串集合中找指定串/前缀"**的多串匹配场景,差异如下:
|------|------------------|----------------|
| 对比维度 | 传统匹配算法(BF/RK/BM) | Trie树 |
| 适用场景 | 单主串中匹配单个/多个模式串 | 字符串集合中查找/前缀匹配 |
| 依赖 | 字符逐位比对/滑动规则 | 公共前缀合并存储 |
| 匹配依据 | 主串与模式串的字符比对 | 沿树形路径的字符遍历 |
| 优势场景 | 长单串的单次匹配 | 多字符串的频繁查找/前缀提示 |
二、Trie树的实现(基于26个小写字母)
Trie树的操作是插入 和查找 ,因主要处理字符串,通常基于字符与数组下标映射 实现多叉树的子节点存储(以纯小写字母为例,适配26进制映射),先定义的节点类,再实现树的插入和查找逻辑。
2.1 节点类设计
Trie树的每个节点包含字符值 、子节点数组 、结束标记三个属性,利用长度为26的数组存储子节点(对应a-z),通过ASCII码偏移快速定位子节点下标:
/**
* Trie树节点类(适配纯小写字母a-z)
* @author aoyou
*/
public class TrieNode {
public char data; // 节点存储的字符
// 子节点数组:下标0→a,1→b...25→z,null表示无对应子节点
public TrieNode[] children = new TrieNode[26];
public boolean isEndingChar = false; // 标记是否为某个字符串的结束字符
// 构造方法:初始化节点存储的字符
public TrieNode(char data) {
this.data = data;
}
}映射规则 :字符的ASCII码 - 小写字母a的ASCII码(97)= 子节点数组下标,比如a→0、o→14、y→24。
2.2 Trie树完整实现(插入+查找)
基于上述节点类,实现Trie树的插入字符串 和查找字符串功能:
/**
* Trie树(字典树)完整实现
* :插入字符串、查找字符串(适配纯小写字母a-z)
* @author aoyou
*/
public class AoyouTrie {
// 根节点:存储无意义字符(如'/'),作为遍历起点
private final TrieNode root = new TrieNode('/');
/**
* 向Trie树中插入一个字符串
* @param text 待插入的字符串字符数组(如"aoyou".toCharArray())
*/
public void insert(char[] text) {
TrieNode p = root; // 从根节点开始遍历
for (char c : text) {
// 计算字符对应的子节点数组下标(c - 'a' 等价于 c - 97)
int index = c - 'a';
// 若当前字符的子节点不存在,创建新节点并挂载
if (p.children[index] == null) {
p.children[index] = new TrieNode(c);
}
// 移动到子节点,继续遍历下一个字符
p = p.children[index];
}
// 遍历结束,将最后一个节点标记为结束字符(表示该路径对应一个完整字符串)
p.isEndingChar = true;
}
/**
* 在Trie树中查找指定字符串(完整匹配)
* @param pattern 待查找的字符串字符数组
* @return 找到则返回true,未找到/仅为前缀匹配返回false
*/
public boolean find(char[] pattern) {
TrieNode p = root; // 从根节点开始遍历
for (char c : pattern) {
int index = c - 'a';
// 若当前字符的子节点不存在,说明无该字符串,直接返回false
if (p.children[index] == null) {
return false;
}
// 移动到子节点,继续遍历
p = p.children[index];
}
// 注意:遍历完字符不代表匹配成功,需校验结束标记
// 比如树中有"apple",查找"app"时,遍历完但最后一个节点不是结束字符,返回false
return p.isEndingChar;
}
// 测试示例(包含aoyou相关用例,贴合要求)
public static void main(String[] args) {
AoyouTrie trie = new AoyouTrie();
// 插入测试字符串集合
trie.insert("aoyou".toCharArray());
trie.insert("aocode".toCharArray());
trie.insert("apple".toCharArray());
trie.insert("app".toCharArray());
trie.insert("so".toCharArray());
trie.insert("see".toCharArray());
// 测试查找:完整匹配
System.out.println(trie.find("aoyou".toCharArray())); // true(找到完整字符串)
System.out.println(trie.find("so".toCharArray())); // true
// 测试查找:仅前缀匹配(无完整字符串)
System.out.println(trie.find("ao".toCharArray())); // false(ao只是前缀,非独立字符串)
System.out.println(trie.find("app".toCharArray())); // true(app是独立插入的字符串)
// 测试查找:不存在的字符串
System.out.println(trie.find("java".toCharArray())); // false
System.out.println(trie.find("aoy".toCharArray())); // false(仅为aoyou的前缀)
}
}运行结果:
true
true
false
true
false
false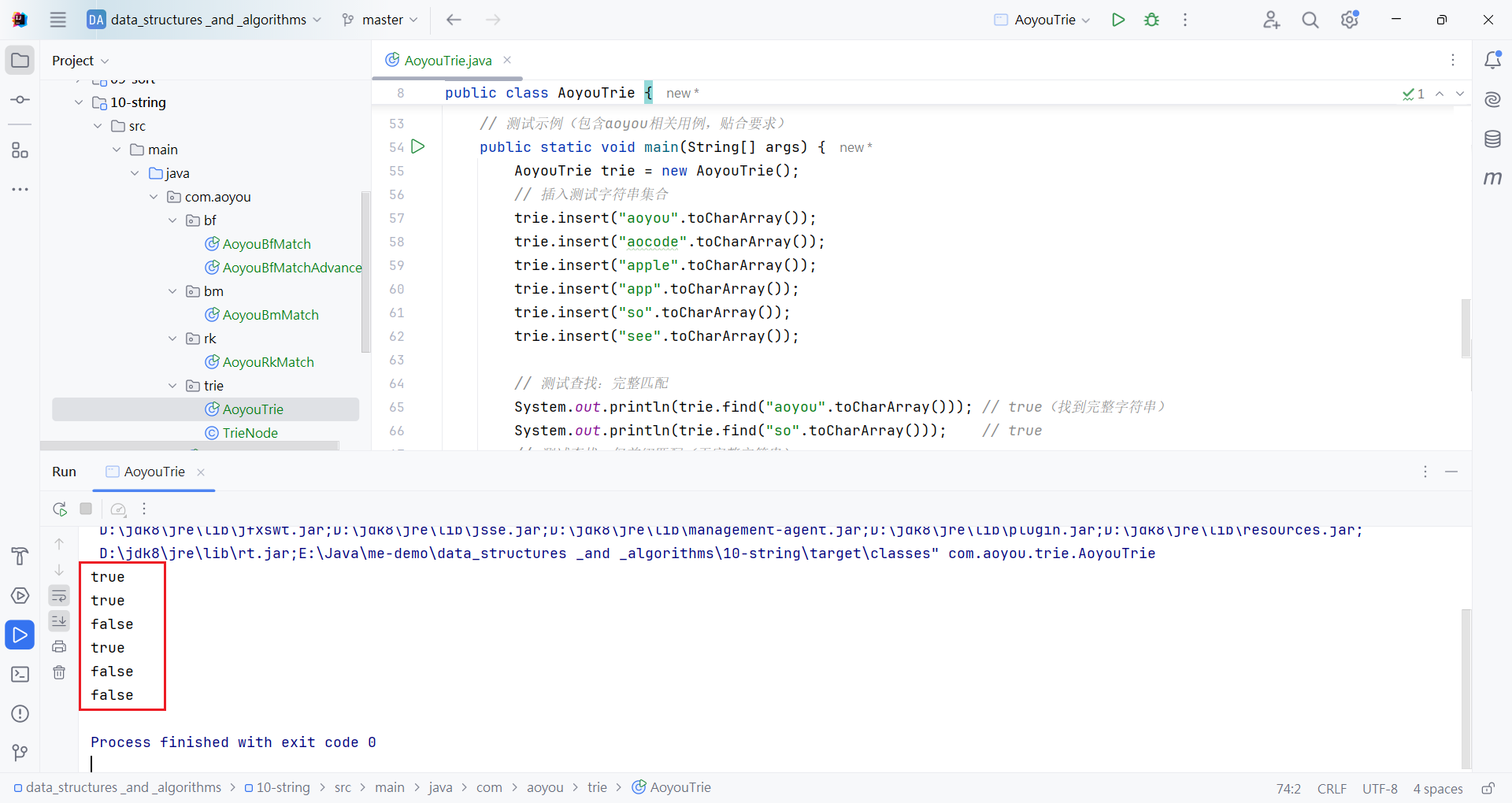
2.3 操作执行流程
插入"aoyou"的流程
- 从根节点出发,取第一个字符
a,计算下标0,根节点子节点0位为null,创建a节点并挂载,移动到a节点; - 取第二个字符
o,计算下标14,a节点子节点14位为null,创建o节点并挂载,移动到o节点; - 依次处理
y(24)、o(14)、u(20),逐个创建并挂载节点,最终移动到u节点; - 将
u节点的isEndingChar设为true,完成插入。
查找"aoyou"的流程
- 从根节点出发,依次遍历
a(0)、o(14)、y(24)、o(14)、u(20),每一步都能找到对应子节点; - 遍历结束后,检查最后一个
u节点的isEndingChar为true,判定为完整匹配 ,返回true。
查找"aoy"的流程
- 遍历
a(0)、o(14)、y(24),能找到对应子节点,但最后一个y节点的isEndingChar为false; - 判定为仅前缀匹配 ,返回
false(树中无独立的"aoy"字符串)。
三、时间复杂度分析
Trie树的时间复杂度分为构建阶段(插入所有字符串) 和 查询阶段(单次查找) ,优势是查询效率与字符串集合的规模无关,仅与待查字符串的长度相关:
3.1 构建阶段时间复杂度:O(n)
- 表示所有插入字符串的字符总长度;
- 插入每个字符串时,需遍历其所有字符,每个字符仅执行一次节点判断/创建操作,无嵌套循环,总操作次数等于所有字符的总数,因此时间复杂度 O(n)。
3.2 查询阶段时间复杂度:O(k)
- k表示待查找字符串的长度;
- 查找时仅需沿树形路径遍历k 个节点,每个节点的子节点查找是 O(1)的数组下标操作,与字符串集合的个数 和总长度无关,因此单次查询时间复杂度为O(k) 。
3.3 空间复杂度
Trie树的空间复杂度为O(n * 26)(n为所有字符总长度),本质是以空间换时间:
- 每个节点都需要一个长度为26的数组存储子节点,即使大部分位置为null,也会占用固定空间;
- 字符串的公共前缀越多,空间利用率越高;若字符串无公共前缀,空间开销会较大(这是Trie树的局限)。
四、应用场景
Trie树因前缀匹配高效、频繁查询成本低的特点,是处理字符串场景的常用数据结构,典型应用如下:
4.1 搜索引擎/输入框的关键词前缀提示
这是Trie树最经典的应用,比如百度、微信输入框的"联想词提示":
- 将用户热门搜索关键词(如aoyou、aocode、apple、so等)构建成Trie树;
- 当用户输入
a时,遍历Trie树中以a为前缀的所有路径,提取完整字符串(aoyou、aocode、apple、app)展示为提示; - 当用户继续输入
ao时,仅展示以ao为前缀的字符串(aoyou、aocode),实现精准的前缀联想。
4.2 字符串集合的快速去重与查找
比如在海量用户昵称、关键词库中,快速判断某个字符串是否已存在,或对字符串集合去重:
- 插入所有字符串到Trie树中,因公共前缀合并,天然实现前缀层面的冗余消除;
- 查找时 复杂度,远快于用HashSet(虽HashSet平均也是 ,但Trie树支持前缀匹配,HashSet不支持)。
4.3 词典/拼写检查
比如英文词典的单词查询、输入法的拼写错误检查:
- 将词典所有单词构建成Trie树;
- 用户输入单词时,沿Trie树遍历,若中途子节点不存在,判定为拼写错误;
- 若遍历完成但未标记为结束字符,可给出前缀相关的正确单词提示。
4.4 IP路由的最长前缀匹配
网络通信中,IP路由表的匹配规则是最长前缀匹配,Trie树可高效实现该逻辑:
- 将所有IP段的前缀构建成Trie树(按二进制位存储);
- 匹配时沿二进制位遍历Trie树,找到最长的匹配前缀,对应最优的路由路径。
五、特点与优化方向
5.1 优点
- 查询效率极高:构建后单次查询仅 ,与字符串集合规模无关,频繁查询时优势显著;
- 前缀匹配天然支持:无需额外逻辑,即可实现前缀联想、最长前缀匹配等场景,是其他数据结构(HashSet、红黑树)难以替代的;
- 公共前缀冗余消除:相同前缀仅存储一次,节省字符串集合的存储空间(公共前缀越多,效果越明显);
- 实现逻辑清晰:仅插入和查找操作,基于数组下标映射,代码简洁易懂。
5.2 局限性
- 空间开销大:每个节点需维护固定长度的子节点数组(如26、62),大量null值造成空间浪费,无公共前缀时空间复杂度极高;
- 字符类型受限:基础实现仅适配固定字符集(如a-z),若需支持大小写字母+数字(62)、中文、特殊符号,需扩大数组或修改存储结构;
- 不支持反向匹配 :仅能从前缀开始匹配,无法实现后缀匹配、模糊匹配(如含通配符
*); - 插入删除效率一般:删除字符串时需遍历路径并判断节点是否为公共节点,逻辑较繁琐,不如HashSet灵活。
5.3 常见优化方向
针对Trie树的局限性,工业界有多种经典优化方案,可根据业务场景选择:
- 压缩Trie树(Compact Trie):将连续的单孩子节点合并为一个节点,减少节点数量,降低空间开销;
- 双数组Trie树(Double-Array Trie):用两个数组(base数组和check数组)替代子节点数组,大幅提升空间利用率,是工业界主流优化方案;
- 后缀Trie树:将字符串反转后插入Trie树,实现后缀匹配功能,适配反向查找场景;
- 改用哈希表存储子节点:将固定长度的数组替换为HashMap<Character, TrieNode>,仅存储存在的子节点,节省空间(牺牲少量查询效率,换空间灵活性);
- 扩展字符集:将数组长度改为62(大小写字母+数字)、65536(Unicode基本平面),适配更多字符类型。
六、总结
- Trie树(字典树)是专为字符串匹配设计的多叉树 ,理念是合并公共前缀,根节点无有效字符,路径表示完整字符串,节点结束标记区分前缀和完整串;
- 基础实现基于字符-数组下标映射 (如a-z→0-25),操作是插入 和查找,插入遍历字符创建节点,查找遍历字符校验结束标记;
- 时间复杂度:构建阶段 ( 为所有字符总长度),查询阶段 ( 为待查字符串长度),是以空间换时间的典型数据结构;
- Trie树的优势是天然支持前缀匹配,经典应用为搜索引擎前缀提示、字符串快速查找、拼写检查等,是其他字符串匹配算法/数据结构难以替代的;
- 基础Trie树存在空间开销大、字符类型受限 的局限,工业界常用双数组Trie树、压缩Trie树优化,也可改用HashMap存储子节点提升灵活性。