开源 C++ 语音对话系统 E2E Voice 更新:模块化 + 全双工 + Kokoro 多音色
项目介绍
E2E Voice 是一个 C++17 端到端智能语音对话系统。简单来说,它能让你对着麦克风说话,AI 实时语音回复你------就像和一个真人聊天一样。
整个系统集成了完整的语音对话链路:
- ASR(语音识别):SenseVoice,支持中/英/日/韩/粤多语言
- LLM(大语言模型):Ollama 本地推理或 OpenAI 兼容的云端 API
- TTS(语音合成):Matcha-TTS(中/英/中英混合)+ Kokoro(多音色)
- VAD(语音活动检测):Silero VAD
- AEC(回声消除):WebRTC 全双工回声消除
架构流程:
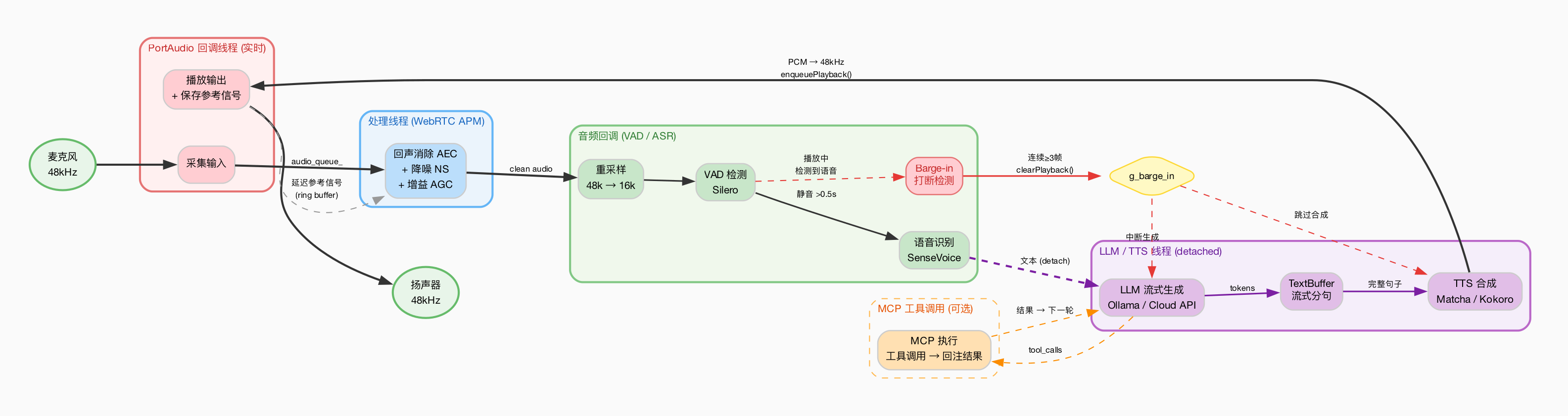
整个流程跑在 C++ 上,延迟低,资源占用小,适合边缘设备和本地部署场景。
为什么要重构
之前的 master 分支是项目早期的单体架构,虽然功能完整,但随着迭代暴露出不少问题:
- 仓库臃肿 :cppjieba(中文分词)、cpp-pinyin(拼音转换)等第三方库的源码直接内嵌在
third_party/里,几十万行代码堆在一个仓库 - 模块耦合:想单独用 TTS 做个语音合成工具?做不到,必须拉整个项目
- 维护困难:改一个模块的代码,要在一个巨大的仓库里翻来翻去
- 半双工限制:AI 说话的时候你只能等,不能打断
这些痛点最终推动了这次重构。
重构后的三大亮点
1. 模块化架构 --- 维护更简单了
这次重构最核心的改动:把 6 个核心模块拆成了独立的 Git 仓库(通过 git submodule 管理)。
| 模块 | 功能 | 独立仓库 |
|---|---|---|
| audio | 音频采集 / 播放 / 全双工 / 重采样 | evo_audio |
| stt | SenseVoice 语音识别 | evo_stt |
| tts | Matcha / Kokoro 语音合成 | evo_tts |
| vad | Silero 语音活动检测 | evo_vad |
| llm | Ollama / OpenAI 兼容 API 客户端 | evo_llm |
| mcp | MCP 工具调用 SDK | evo_mcp |
这样带来的好处很直观:
- 想单独用某个模块? 直接引入对应仓库就行。比如只需要语音合成,引入 evo_tts 即可,不用拉整个项目
- 每个模块独立开发、测试、发版,互不影响
- 每个模块提供统一的 API 头文件(
*_api.hpp)和文档(API.md),接口清晰 - 主仓库净减约 136 万行代码,原来内嵌的第三方库全部改为 CMake FetchContent 按需拉取
此外,audio / stt / tts / vad 四个模块还提供了 pybind11 Python 绑定,pip install -e . 即可使用。
2. 全双工 AEC 回声消除 --- 可以打断了
这是体验上提升最大的一个功能。
之前是半双工模式:AI 说话的时候,你必须等它说完才能开始下一轮对话。这在实际使用中很不自然------真人对话哪有人会乖乖等对方说完?
重构后加入了 WebRTC AEC(Acoustic Echo Cancellation) 回声消除,实现了全双工对话:
- AI 在播放语音的同时,麦克风也在持续采集
- AEC 会从麦克风信号中消除掉扬声器的回声
- 你随时可以打断(Barge-in)AI 的发言,系统会立即停止当前播放,转而处理你的新输入
效果就是:对话体验接近真人,想说就说,不用等。
3. Kokoro TTS --- 更多音色选择
之前只有 Matcha-TTS 一种合成后端(支持中文、英文、中英混合)。这次新增了 Kokoro TTS 后端,带来更多音色选择。
切换只需一个参数:
bash
./build/bin/voice_chat_aec --tts kokoro # 默认音色
./build/bin/voice_chat_aec --tts kokoro:xiaoxiao # 指定音色快速体验
bash
# 克隆(包含子模块)
git clone --recursive -b refactor https://github.com/muggle-stack/e2e_Voice.git
cd e2e_Voice
# 编译
mkdir -p build && cd build
cmake .. && make -j$(nproc 2>/dev/null || sysctl -n hw.ncpu) && cd ..
# 运行(确保 Ollama 已启动并拉取模型)
./build/bin/voice_chat_aec --tts matcha:zh-en
# 使用 OpenAI API 兼容 LLM 后端服务(ip 为服务器 ip,port 为启动 LLM 以后的服务器端口)
./build/bin/voice_chat_aec --tts matcha:zh-en --llm-url http://ip:port
# 使用 MCP 工具(默认有计算器、获取系统状态、获取系统时间三个工具,可选)
# 启动 MCP 服务器
# 安装依赖
pip install mcp starlette uvicorn psutil flask
./modules/mcp/examples/start_all_services.sh
./build/bin/voice_chat_aec --mcp-config modules/mcp/examples/config_registry.json --tts matcha:zh-en --llm-url http://ip:port依赖安装和更多选项详见 README。
MCP 工具调用
除了基础对话,系统还支持通过 MCP(Model Context Protocol) 让 LLM 调用外部工具。比如查天气、做计算、获取系统信息等------只要有对应的 MCP 服务,LLM 就能自动调用。
项目内置了注册中心和示例服务,一键启动即可体验:
bash
pip install mcp starlette uvicorn psutil flask
cd modules/mcp/examples && bash start_all_services.sh
./build/bin/voice_chat_aec --mcp-config modules/mcp/examples/config_registry.json你也可以编写自己的 MCP 服务注册到注册中心,voice_chat_aec 会自动发现新工具,无需重启。
总结
| master(旧) | refactor(新) | |
|---|---|---|
| 架构 | 单体,代码耦合 | 模块化,6 个独立子仓库 |
| 仓库体积 | ~140 万行(含内嵌第三方) | ~4000 行(第三方按需拉取) |
| 对话模式 | 半双工 | 全双工(AEC + Barge-in) |
| TTS 后端 | Matcha-TTS | Matcha-TTS + Kokoro |
| 工具调用 | 无 | MCP(stdio / socket / HTTP) |
| Python 支持 | 无 | audio / stt / tts / vad 提供绑定 |
参与共建
项目是我一个人在维护,难免有考虑不周的地方。如果您在使用中遇到问题或者发现了 bug,欢迎直接提 Issue,也可以发邮件给我:promuggle@gmail.com。
每个子模块都是独立仓库,如果你适配了新的 ASR / TTS / LLM 后端,或者有任何改进,非常欢迎提 PR。希望能和大家一起把端侧语音对话的生态做起来,让对话质量越来越好。
后续计划
- KWS 关键词唤醒 --- 语音唤醒,免按键触发对话
- 声纹识别 --- 说话人验证,区分不同用户
- 声源定位 --- 麦克风阵列方向估计
- 持续优化对话质量和端到端延迟
仓库地址 :https://github.com/muggle-stack/e2e_Voice(默认 refactor 分支)
欢迎 Star ⭐、Issue 和 PR!