本文流程
安装环境->yolo使用介绍->原理->标记训练
Miniconda的安装和使用
使用condamini可以创建一个虚拟环境,防止电脑上的python环境被扰乱(但不安装也行。),以后安装的库什么的都塞到这个虚拟环境里了。
Installing Miniconda - Anaconda
直接官网下载miniconda就行。(完整conda也行,但比较大占用空间)
下载完之后,按照链接中的文档安装。
安装完之后,进cmd输入conda会输出
C:\Windows\System32>conda
usage: conda-script.py -h -v --no-plugins -V COMMAND ...
conda is a tool for managing and deploying applications, environments and packages.
options:
-h, --help Show this help message and exit.
-v, --verbose Can be used multiple times. Once for detailed output, twice for INFO logging, thrice for DEBUG
logging, four times for TRACE logging.
--no-plugins Disable all plugins that are not built into conda.
-V, --version Show the conda version number and exit.
.........
我们只需要创建一个虚拟环境就行
conda create -n 名称 python=python版本号
例如:conda create -n yolo python=3.12
创建一个叫yolo的,python版本为3.12的虚拟环境。(基于2026年2月的情况,我推荐使用python3.12,因为这是后面库支持的最高版本,如果你是在27年或者更未来看到的话,建议根据后面的库的文档中建议的最高python版本创建)
创建完之后会报
C:\Windows\System32>conda create -n test python=3.12
3 channel Terms of Service accepted
Retrieving notices: done
WARNING: A directory already exists at the target location 'C:\Users\sansh\miniconda3\envs\test'
but it is not a conda environment.
Continue creating environment (y/n)?
后面你按着提示走就行,conda会自动下载并创建。
conda activate 名称
激活那个环境。
这时候命令行提示符前面会出现你之前创建的环境的名称。例如我的(yolo)
此时说明你接下来的python操作都是在这个环境里的。
输入python时,也可以看到版本信息,并且说明这个版本是anaconda创建的。
C:\Windows\System32>conda activate yolo
(yolo) C:\Windows\System32>python
Python 3.12.12 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 20:05:38) MSC v.1929 64 bit (AMD64) on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
这里列一些常用命令
conda create -n 环境名称 python=python版本号
conda activate 环境名称
conda deactivate
conda remove 环境名称
conda rename 环境名称
conda list
PyTorch的安装
yolo的推理和训练是以这个库为基础的,所以必须要安装这个库(事实上这个也是最常用的机器学习库)
可以访问这个链接进行安装。
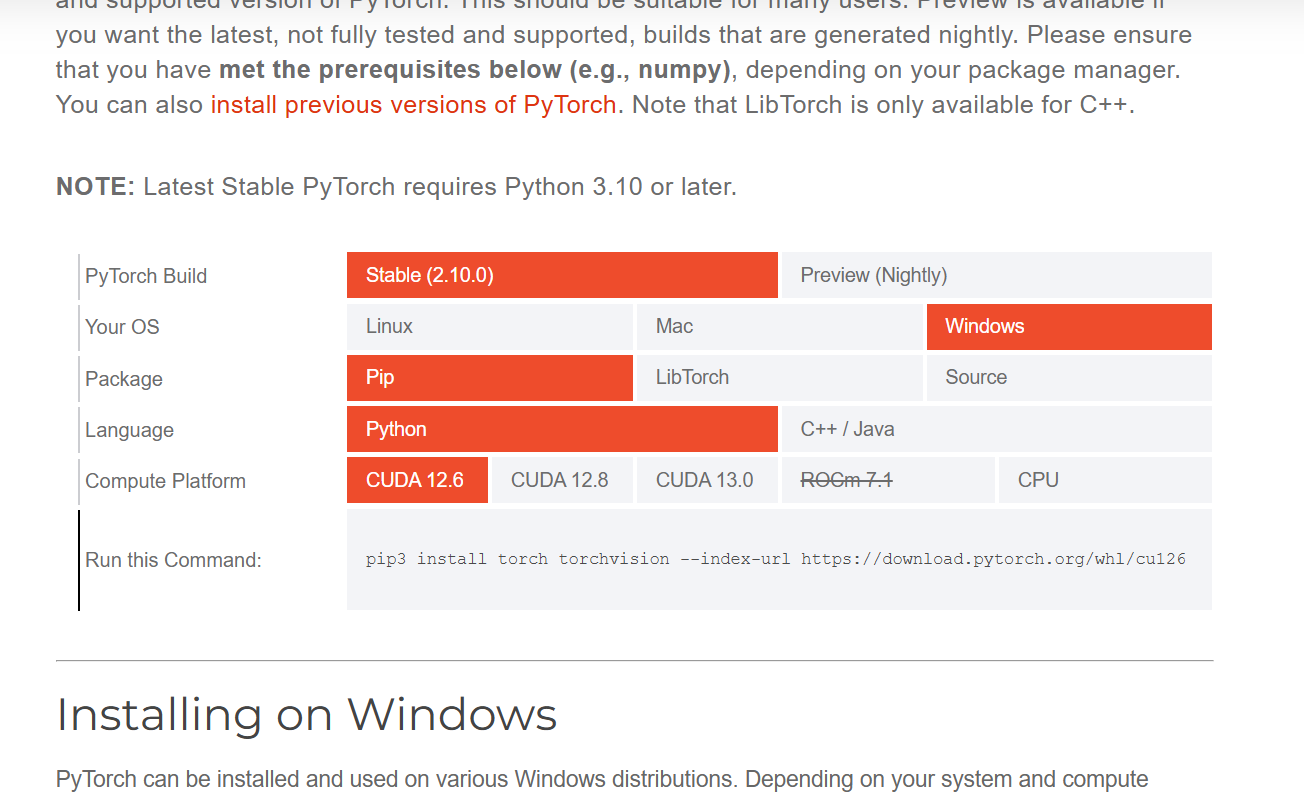
stable是稳定版,preview是实验版(更新快,东西新,有bug)
我们选择pip和python安装(可以看到这个要求版本高于python3.10)
根据你的显卡情况选择cuda版本,如果没有显卡就选择cpu(有显卡,显卡好的训练的快,或者懒得搞显卡驱动也可以cpu先用着)
(如果你是AMD的话,需要ROCm,不过我没安装过,就不多扯了)
这个版本要怎么看?
C:\Windows\System32>nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jul_16_20:06:48_Pacific_Daylight_Time_2025
Cuda compilation tools, release 13.0, V13.0.48
Build cuda_13.0.r13.0/compiler.36260728_0
输入nvidia-smi可以看到当前显卡驱动支持的CUDA最高版本(可以看到我这里支持的最高版本是cuda version 13.1)
C:\Windows\System32>nvidia-smi
Mon Feb 23 09:35:59 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 591.74 Driver Version: 591.74 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce GTX 1650 Ti WDDM | 00000000:01:00.0 Off | N/A |
| N/A 63C P8 5W / 50W | 175MiB / 4096MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 9252 C+G ...ram Files\Tencent\QQNT\QQ.exe N/A |
| 0 N/A N/A 12640 C+G ...ram Files\Tencent\QQNT\QQ.exe N/A |
+-----------------------------------------------------------------------------------------+
当然这两个是已安装完驱动和CUDA Toolkit后才会显示。
如果你用nvidia-smi看到连PyTorch的最低版本都不支持,有两种可能一种是你的显卡太老了,第二种是你的显卡驱动需要更新。
NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA
如果你是N卡,进这里,按照它给出的提示,自动或者手动安装你显卡支持的最新驱动。
安装完成后,进这里安装CUDA Toolkit
CUDA Toolkit Archive | NVIDIA Developer
这里选择的安装版本,要根据PyTorch支持的CUDA版本选择,并且不能超过你显卡驱动支持的最高版本。
因为我的最高支持版本是CUDA Version: 13.1,并且PyTorch的库的最高支持版本是13.0,所以这里我选择13.0版本安装。
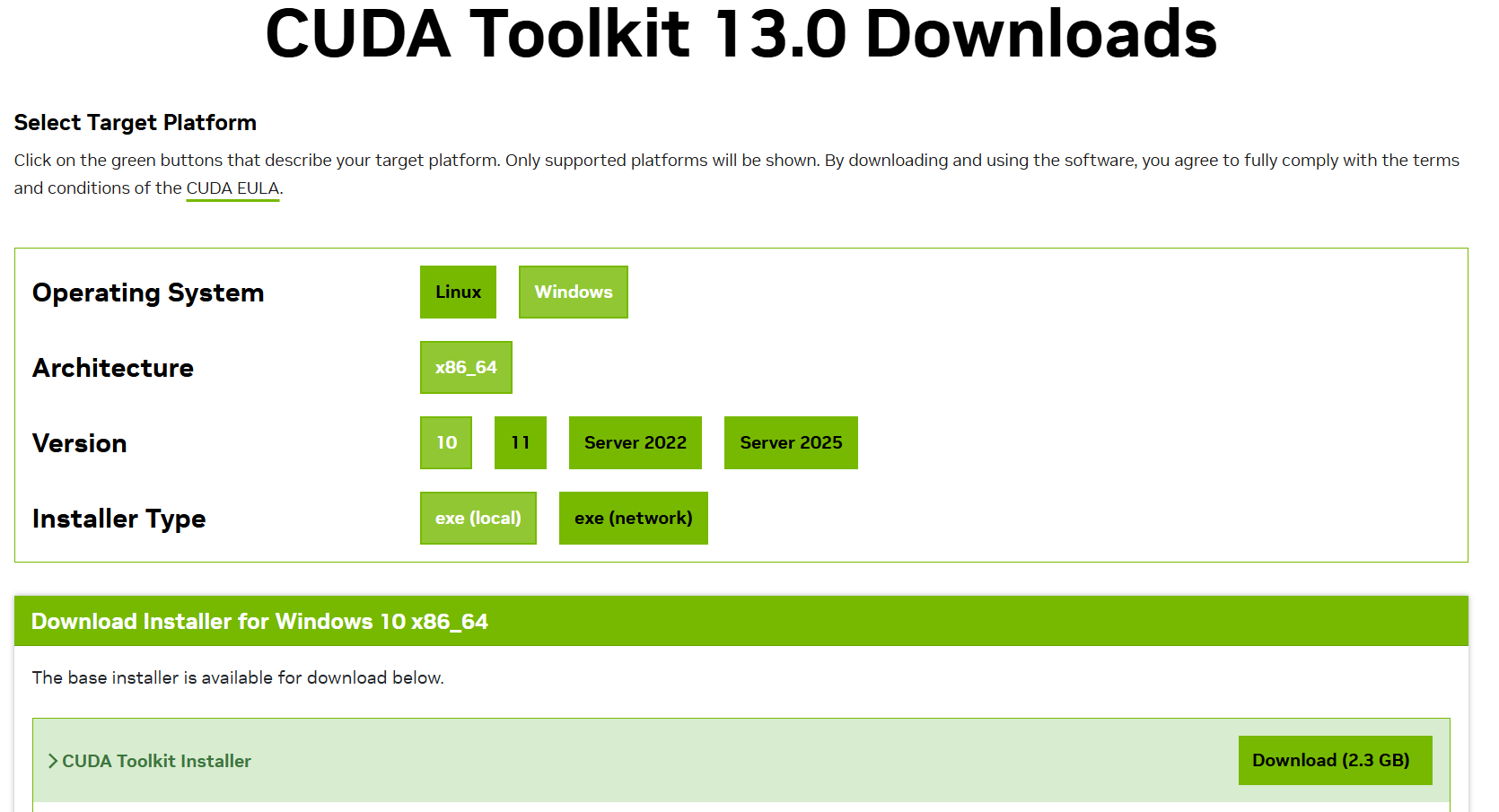
安装完成后输入nvcc --version就可以找到了
驱动装完了继续回到PyTorch,把Run this Command里的内容复制到终端运行,就会自动安装
(注意这些需要在你创建的虚拟环境里安装!别安装到外面了,可能你之前捣鼓cuda把这事忘了,这里提醒一下!)
(yolo) C:\Windows\System32>pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu126
Looking in indexes: https://download.pytorch.org/whl/cu126
Requirement already satisfied: torch in c:\users\sansh\miniconda3\envs\yolo\lib\site-packages (2.10.0+cu130)
Requirement already satisfied: torchvision in c:\users\sansh\miniconda3\envs\yolo\lib\site-packages (0.25.0+cu130)
.........
当然,我这里都装过了,实际上安装大概需要半个小时左右。
安装完后可以输入pip show torch验证一下当前版本是cu130
(yolo) C:\Windows\System32>pip show torch
Name: torch
Version: 2.10.0+cu130
Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration
Home-page: https://pytorch.org
Author:
Author-email: PyTorch Team <packages@pytorch.org>
License: BSD-3-Clause
Location: C:\Users\sansh\miniconda3\envs\yolo\Lib\site-packages
Requires: filelock, fsspec, jinja2, networkx, setuptools, sympy, typing-extensions
Required-by: stable_baselines3, torchvision, ultralytics, ultralytics-thop
也可以用这种方式验证
(yolo) C:\Windows\System32>python
Python 3.12.12 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 20:05:38) MSC v.1929 64 bit (AMD64) on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torchvision
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.randn(1).cuda()
tensor(-0.1820, device='cuda:0')
YOLO的安装
有了上面的基础现在我们可以安装yolo了。
安装 Ultralytics - Ultralytics YOLO 文档
pip install -U ultralytics
找到这条命令,安装就行,也可以按照说明从github上安装最新的测试版。
安装完成之后,我们的环境就搭建成功了。
我们查看和阅读yolo的文档,这个是最新的yolo26,当然不同的版本有不同的特色,你可以询问AI这些版本都有哪些不同,选择哪个版本更好。但这里我先选择26作为演示。
Ultralytics YOLO26 - Ultralytics YOLO 文档
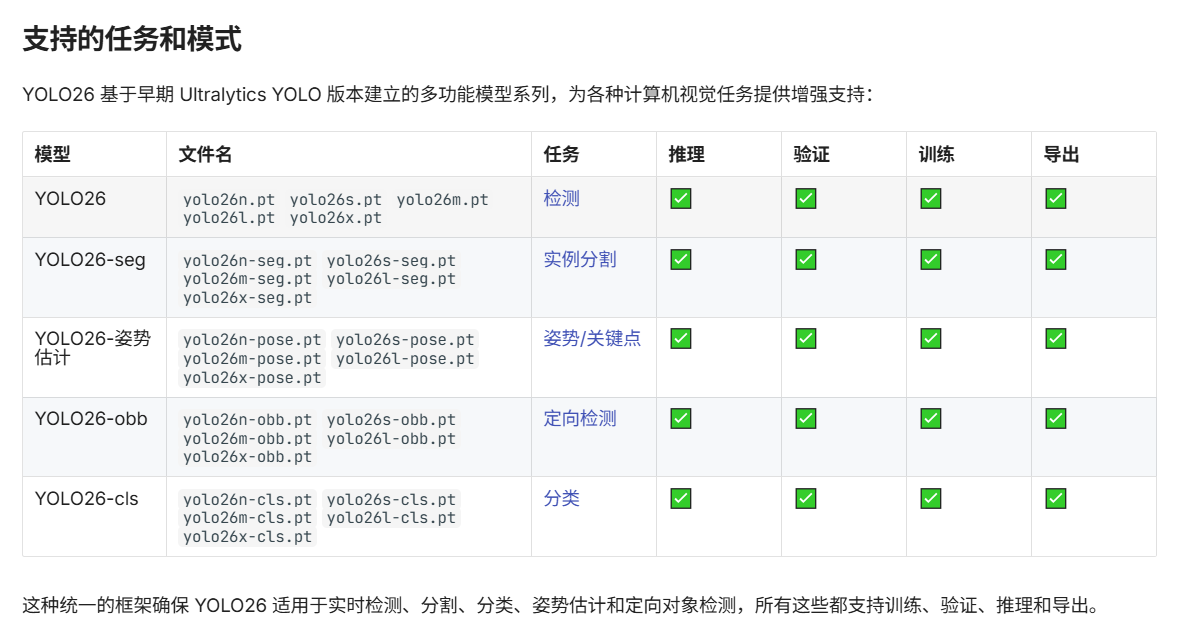
可以看到yolo支持这些任务和模式,根据你的实际情况选就行。
如果你需要识别某个物体是什么,在什么坐标位置,可以选yolo26
如果你希望能识别一些物体的轮廓使其和环境分隔开,就选择yolo26-seg
如果你希望识别某个物体的运动骨架什么的,就选择yolo26n-pose
等等,当然文字描述肯定并不准确,你可以在网上搜索不同模型的使用的视频。
其中不同模型都分成 n、s、m、l、x 不同的型号,简单来说就是模型大小的不同,模型越大,精确越高,速度越慢。
具体如何选择看使用场景。
YOLO初体验
我们用yolo26n.pt简单测试一下,如果识别个人什么的。(其实不用下载,你代码中使用到了内部会自动下载,很智能)
yolo26n.pt是yolo官方已经训练过的模型,我们可以以此为基础进行训练,但其默认自带了一些已经训练好的内容,例如识别一些简单的物品什么的。
我使用的环境是vscode。
创建一个文件夹作为实验场地,丢给vscode打开。

可能会提示是否信任作者,点信任就行。
另外没用过vscode写python的话,要先安装一个python环境。
安装完之后,我们选择一下之前在conda里创建的虚拟环境。
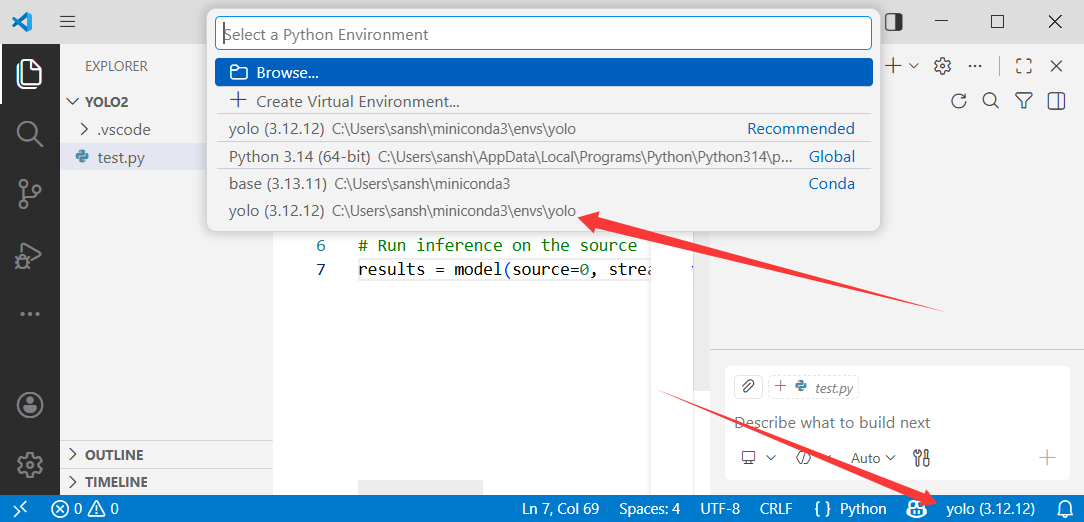
我们创建一个test.py,并在里面输入代码,识别图片中某些物品的位置。
python
from ultralytics import YOLO
# Load a pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Define path to the image file
source = "path/to/image.jpg"
# Run inference on the source
results = model(source) # list of Results objects我在网上随便找了一个图片,可以看到识别效果。
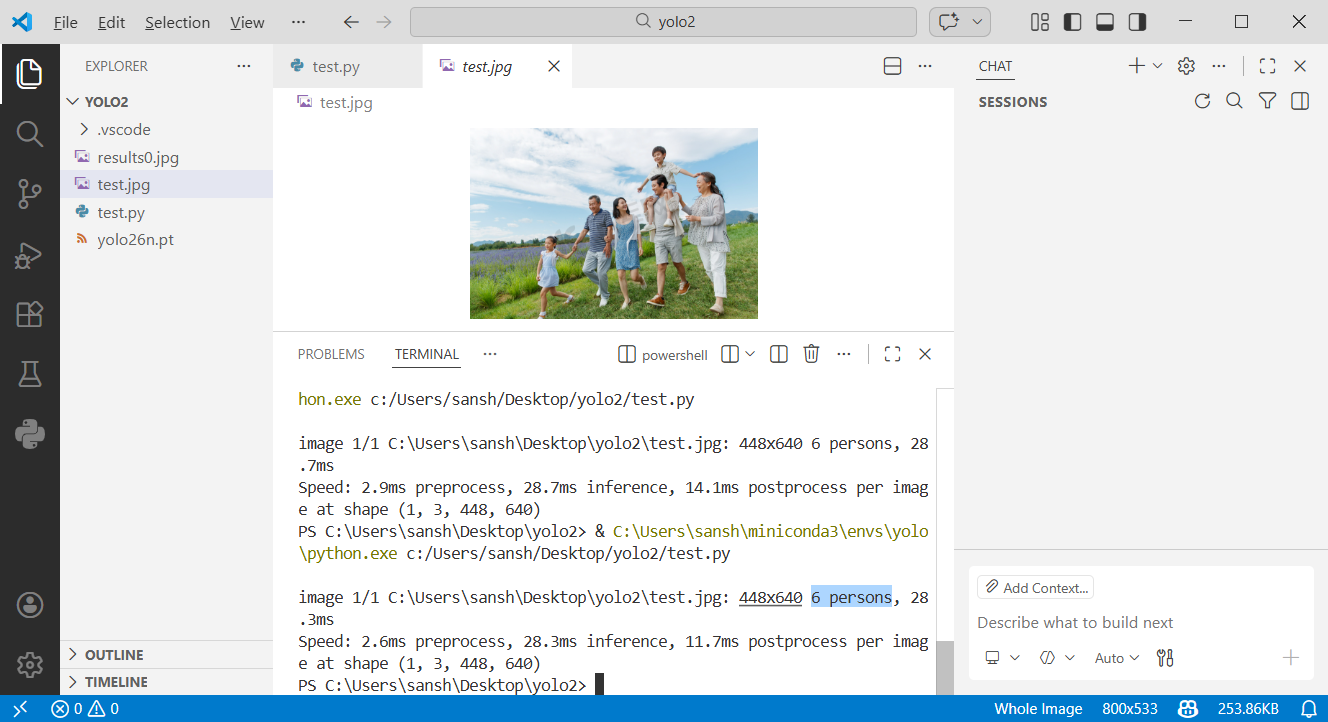
运行后,检测出有六个人。
如果你想让它显示出来,可以些代码如下。
python
from ultralytics import YOLO
# Load a pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Define path to the image file
source = "test.jpg"
# Run inference on the source
results = model(source) # list of Results objects
for result in results:
boxes = result.boxes # Boxes object for bounding box outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
result.save(filename="result.jpg") # save to disk运行之后,检测效果如下。
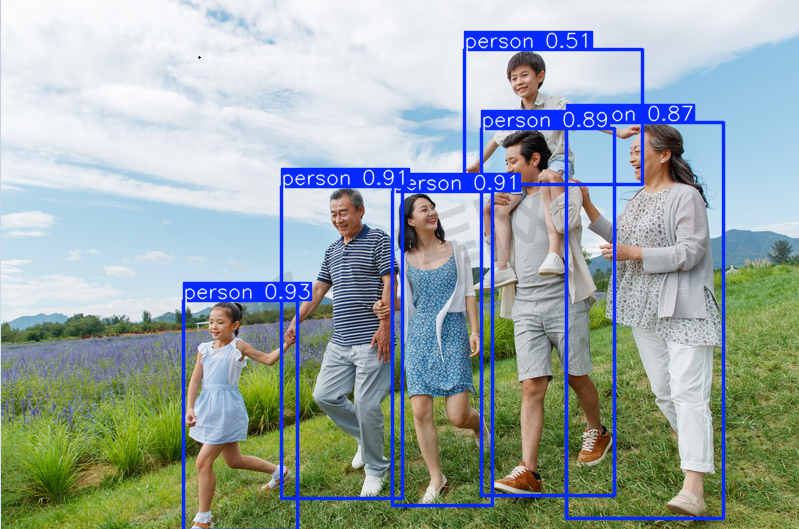
此外也可以使用摄像头功能,实时在控制台上输出检测信息
python
from ultralytics import YOLO
# Load a pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Run inference on the source
results = model(source=0, stream=True) # generator of Results objects
for result in results:
print(result.boxes.xyxy) # print boxes (xyxy format)更详细的使用,可参考
使用 Ultralytics YOLO 进行模型预测 - Ultralytics YOLO 文档
原理
整个过程就三步,标注,训练,推理。如果把这个过程比作教小学生看图识字:
- 标注: 老师拿红笔在书上把"苹果"圈出来,并在旁边写上"苹果",写一大堆案例。
- 训练: 学生(神经网络)看图,一开始乱指。老师根据指偏了多少、认错了多少打分(损失函数)。学生根据分数调整自己的观察方法(权重更新)。
- 推理: 考试了,给一张没见过的图。学生快速看一眼,圈出他认为的苹果,并在旁边写上苹果。
简单来说,我们接下来的活动就是,收集一些数据集,然后用标注软件标注信息(这里用label studio),标注完之后,丢该电脑训练,训练出来的结果就是xxxx.pt模型,然后你拿着模型,就像上面那样用就行。
为了便于学习、理解,笔者会用一个小项目作为演示。(你不必和我做的一样,你可以按照你的思路做你的游戏或者其他什么的)
这是一个我小时候经常玩的游戏,本质上就是炸弹人的一个变种。
根据我的预想,我希望检测三个目标,玩家,敌人,炸弹。
我希望能实时监测出来这三个目标的位置,并分类标注。
下面的内容将会以这个项目做演示。
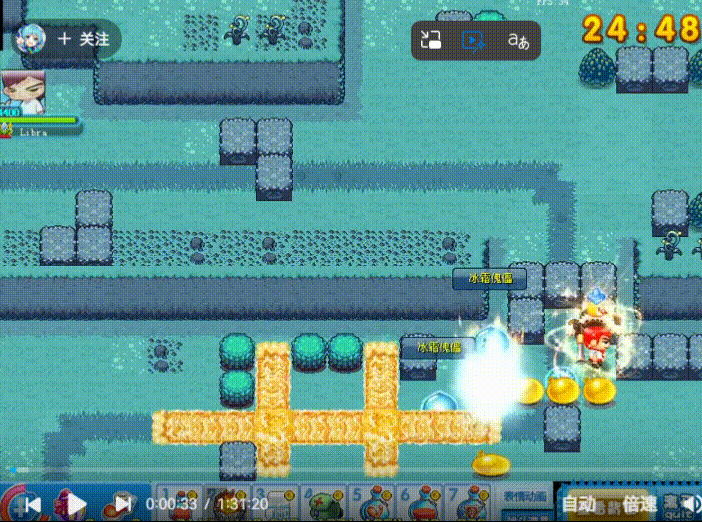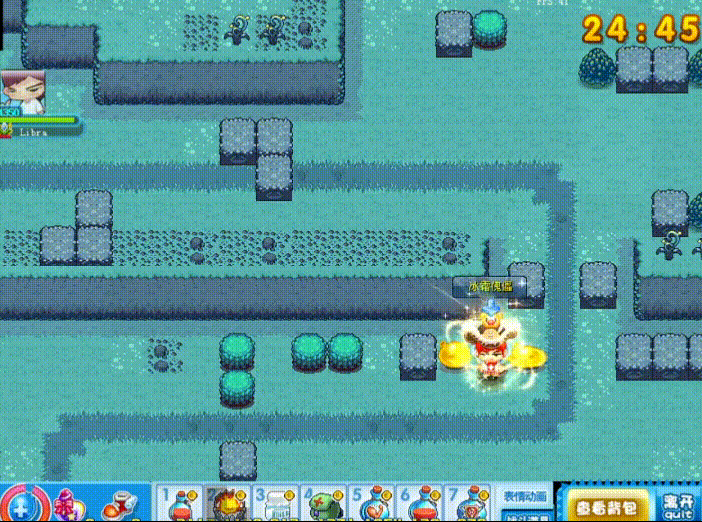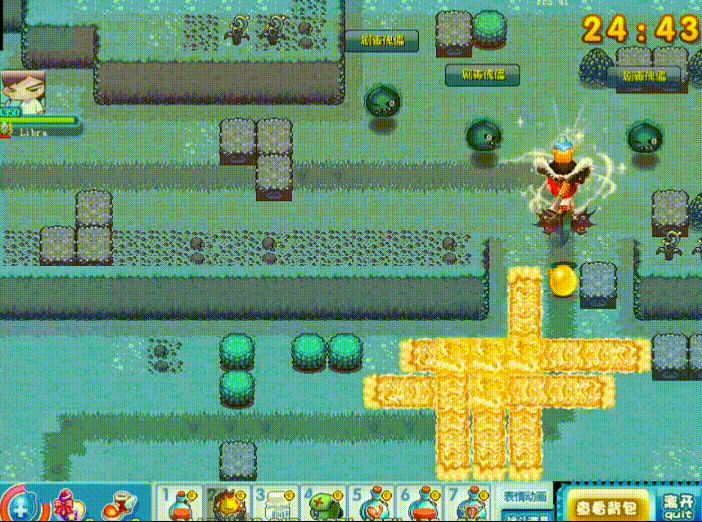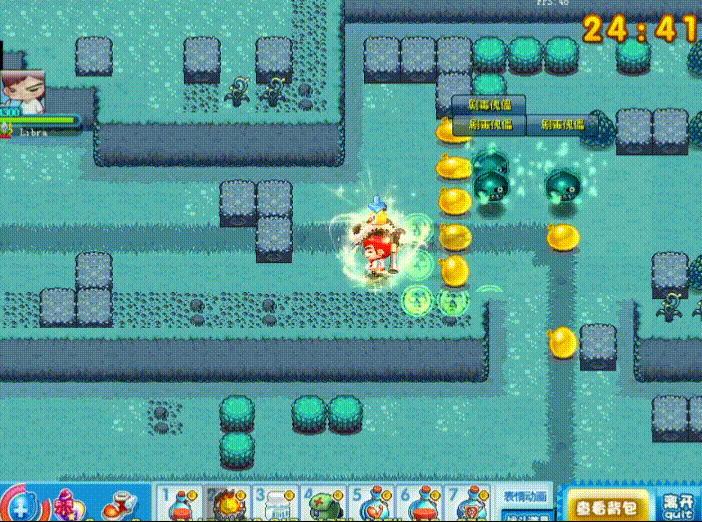
数据集的收集
要标注,总要告诉AI练什么吧,所以我们需要准备一些数据集。
为了实现这个目标,我使用obs,按每秒一帧的方式进行录制。
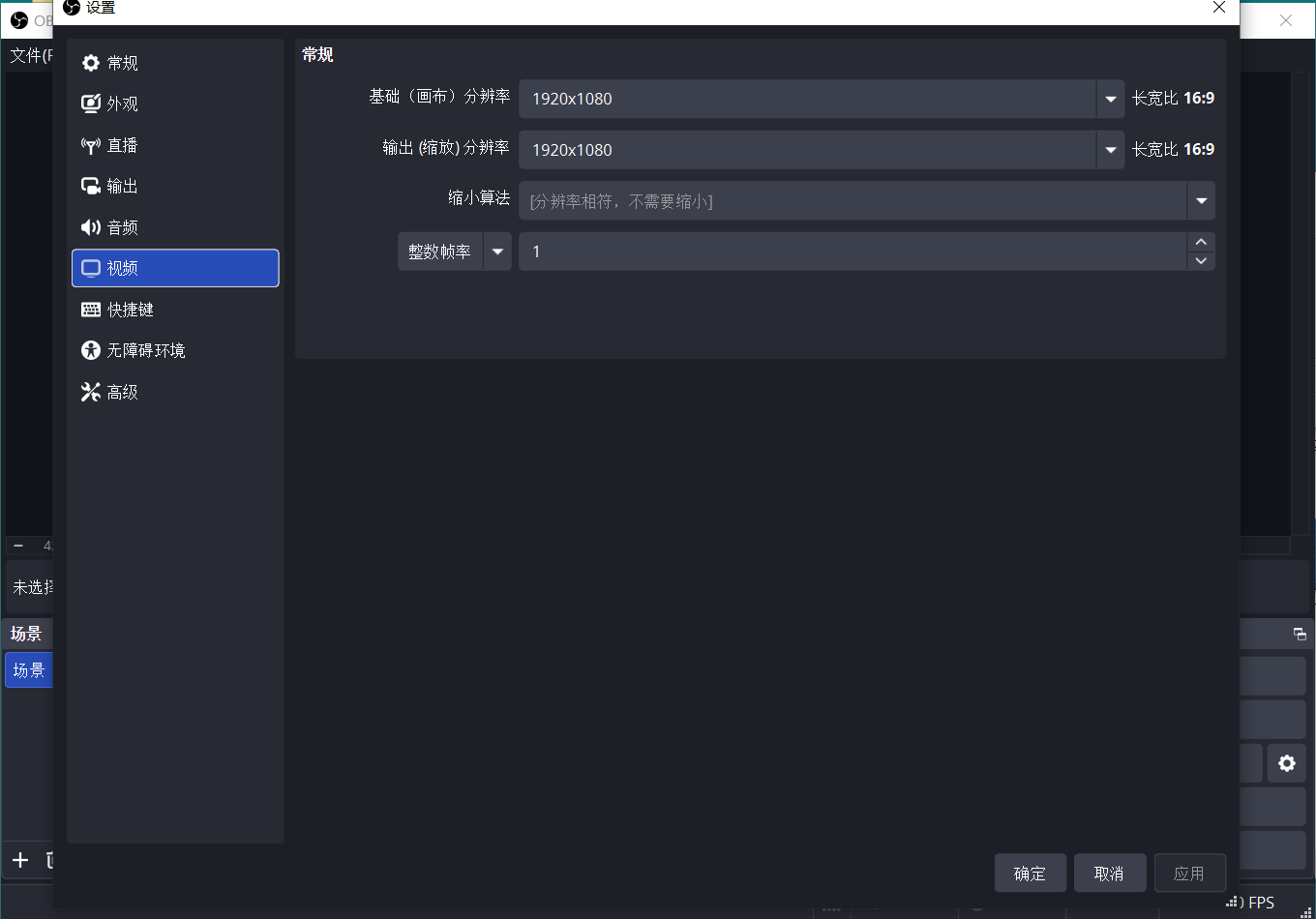
在经过几分钟的游戏之后,我结束了游戏的录制,并编写代码将录制好的mp4格式的视频分割成几百张图片。
python
import cv2 as cv
from ultralytics import YOLO
from time import sleep
rec = cv.VideoCapture('player.mp4')
# 设置从第14332帧开始读取
# rec.set(cv.CAP_PROP_POS_FRAMES, 5400)
i=1 #从上一个的最后一帧开始保存
while True:
r,f = rec.read()
if not r:
print("mei you geng duo zhen le.")
break
if cv.waitKey(1) == ord('q'):
print("exit")
break
i += 1
if i % 1 == 0: #每隔n帧保存一次
cv.imwrite(f'./player_jpg/{i}.jpg',f)
rec.release()
cv.destroyAllWindows()从这些视频中抽选出200张有代表性的,(如果你的场景越复杂,就多搞点数据,当然训练的也就越慢)
为了能让AI学习到特征,需要在不同的背景上,玩家,敌人,炸弹,三个角色在不同的位置出现。
并测试玩家在被遮挡一半,敌人被遮挡一半,两者重叠等多种情况。以便AI能从一部分中理解这一现象,并识别出目标。
当数据集准备完毕之后,我们进行label studio软件的安装。
label studio的安装和使用
我们如果需要训练自己的模型,肯定要训练数据集进行标记。
label studio是一个开源的数据标注软件,由于可以网络部署多人协作,所以用的比较多。
Label Studio Documentation --- Quick start guide for Label Studio
这里演示label studio的安装(其实执行下面一条命令就安装了)
(yolo) C:\Windows\System32>pip install label-studio
然后
(yolo) C:\Windows\System32>label-studio
就能启动
在浏览器里输入 http://localhost:8080/ 就能访问
然后注册一个账号。
登录进去,理论上里面是没有东西的,当然我这里有几个遗留的测试项目。
点击创建一个项目,这里会让你输入项目名称,以及项目的描述
这里可以导入数据,使用URL或者直接上传文件的方式。
注意如果你的数据量达到上千张图片之类的话,不应该从这里导入,会报错,大数据导入后面我会介绍。
不过如果你只是测试,导入百来张图片的话,就无甚大碍了。
我们将准备好的数据集传进去。
下一步,到这里我们看到有很多模板,例如第一个是几何形式分割识别对应yolo26-seg,第二个是以位图的形式分割识别,这个也对应yolo26-seg。
我们只需要识别类型和位置就行,所以使用第三个。
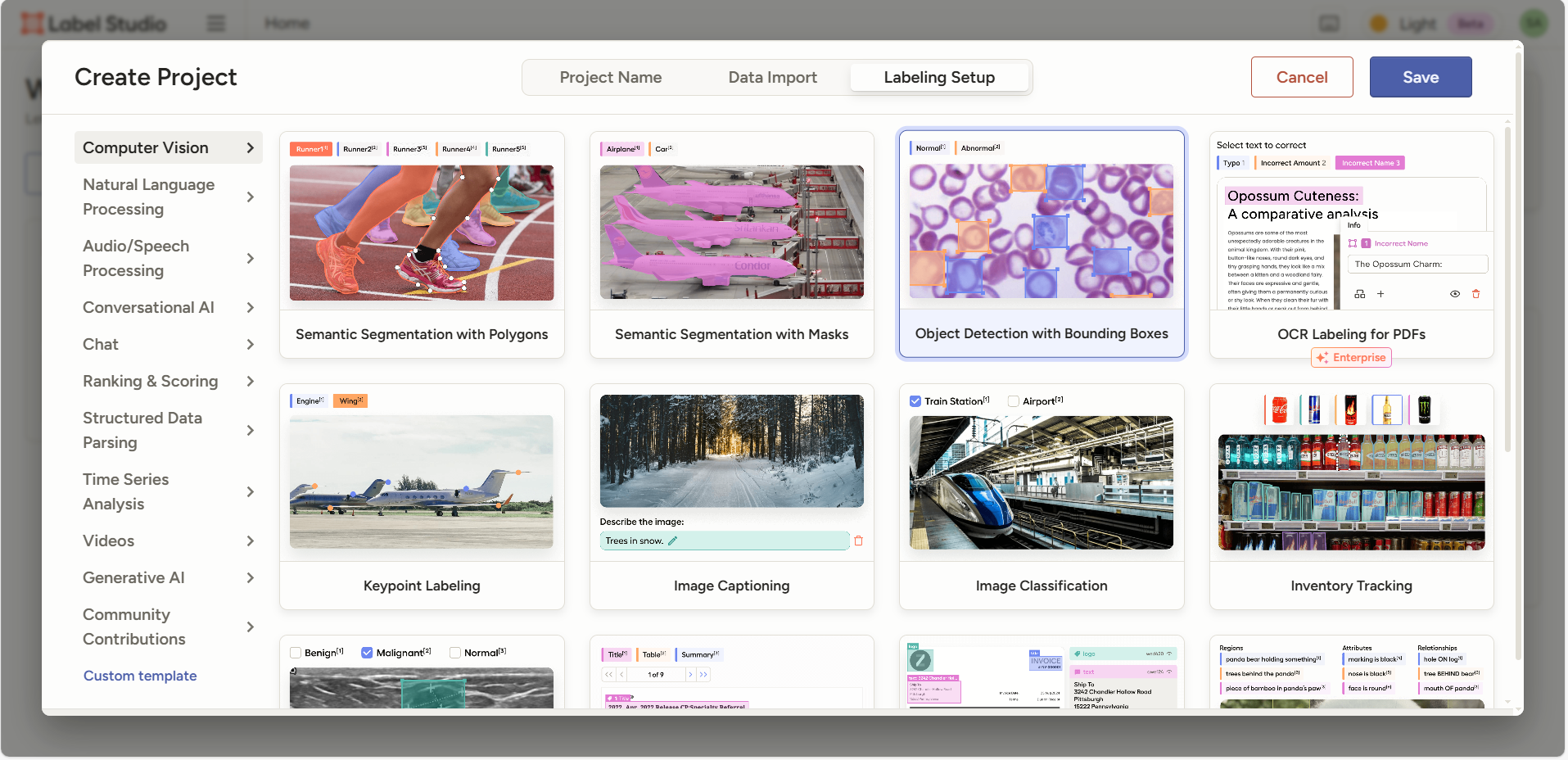
点中之后,会让你填写标签,它默认的示例是车辆和飞机,以及一张测试图片,你可以在右侧拉框框测试颜色。
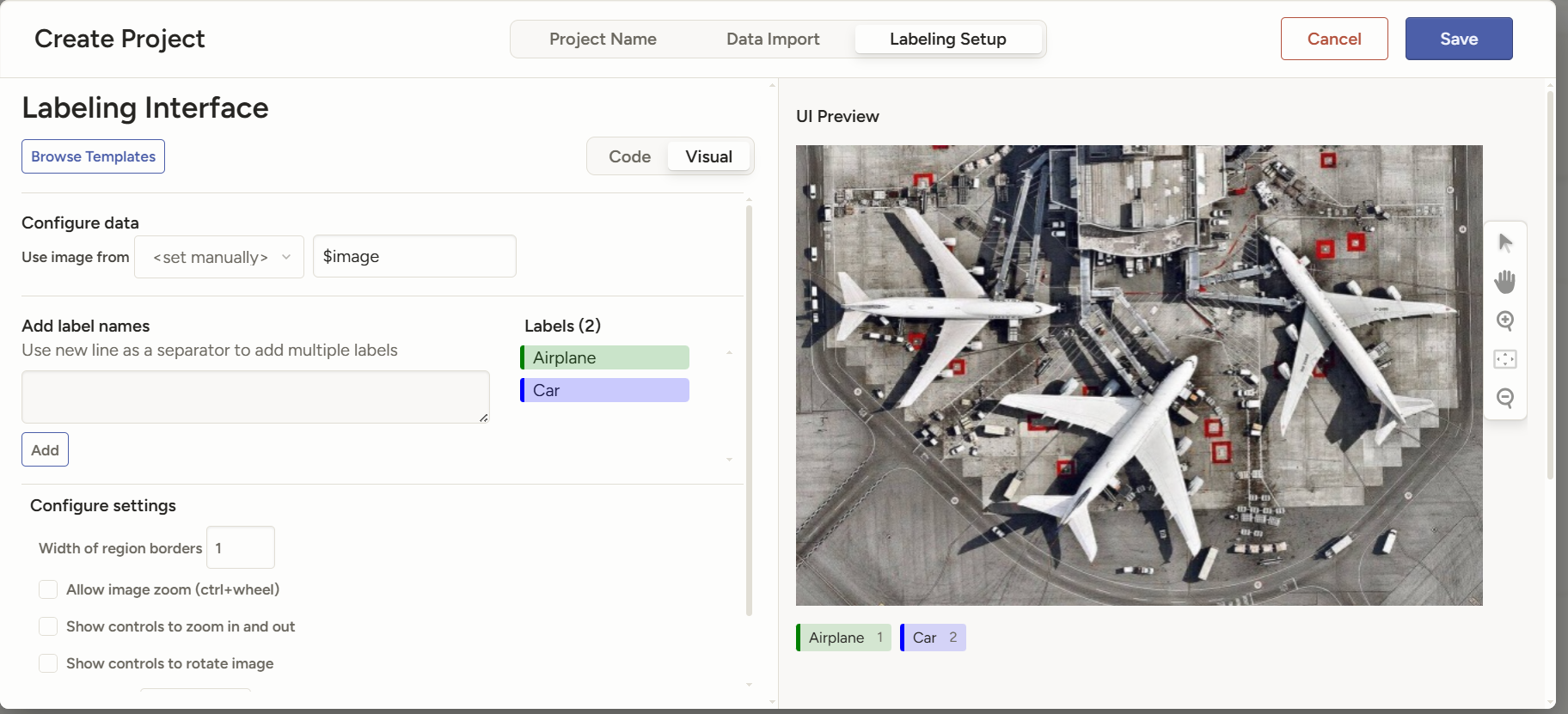
我们将默认标签删掉,然后填上我们自己需要的标签,就像这样。
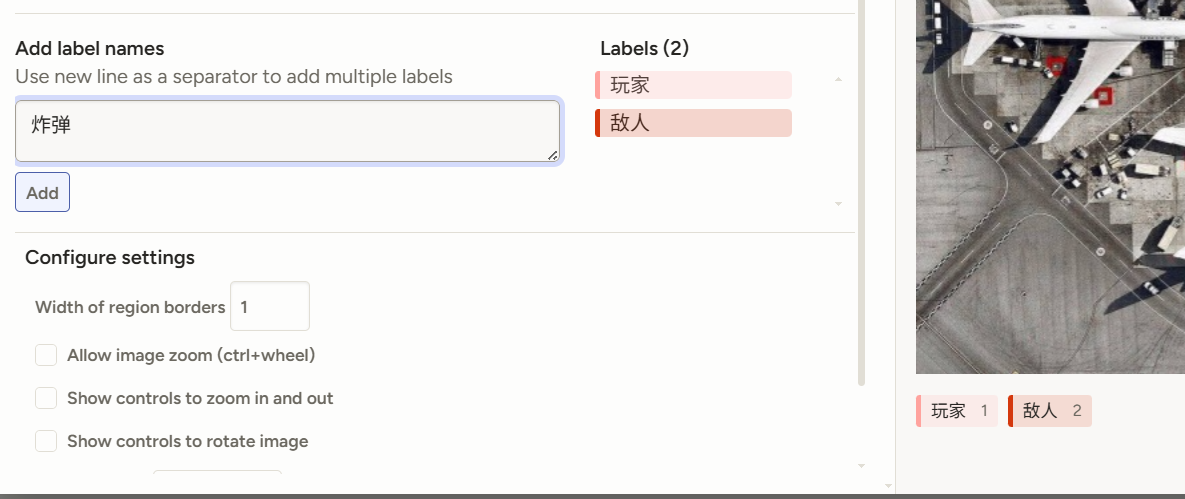
可以在左边拉框框测试,或者改标签的颜色。
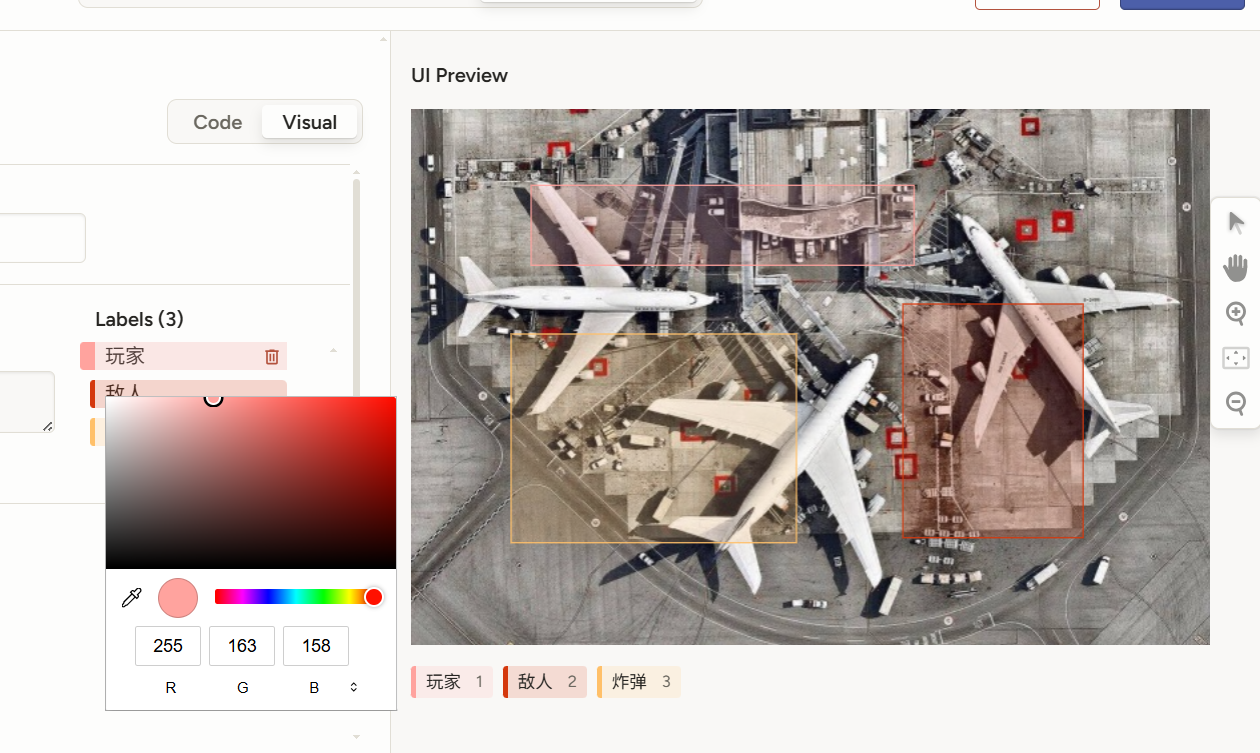
这里不用担心标签打错了,少打了,或者颜色不对什么的,如果后面你想添加新的标签可以随时添加,已有的标签改变颜色,已经标的框框都会变,所以不必担心。
一切搞定我们点击save完成。
p.s. 下面这部分是写给几千几万几十万图片需要导入的用户的,如果不需要可以略过
首先你需要先把lable studio的服务关掉,设置环境变量然后再启动。
C:\Windows\System32>set LABEL_STUDIO_LOCAL_FILES_SERVING_ENABLED=true
C:\Windows\System32>set LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT=C:\\date\\media
C:\Windows\System32>label-studio
注意那个C:\\date\\media替换成你的数据集的上一级目录(因为为了安全考虑,这个不能直接写主目录),我这里懒得搞就直接上一级目录了。
在终端执行:
点击setting
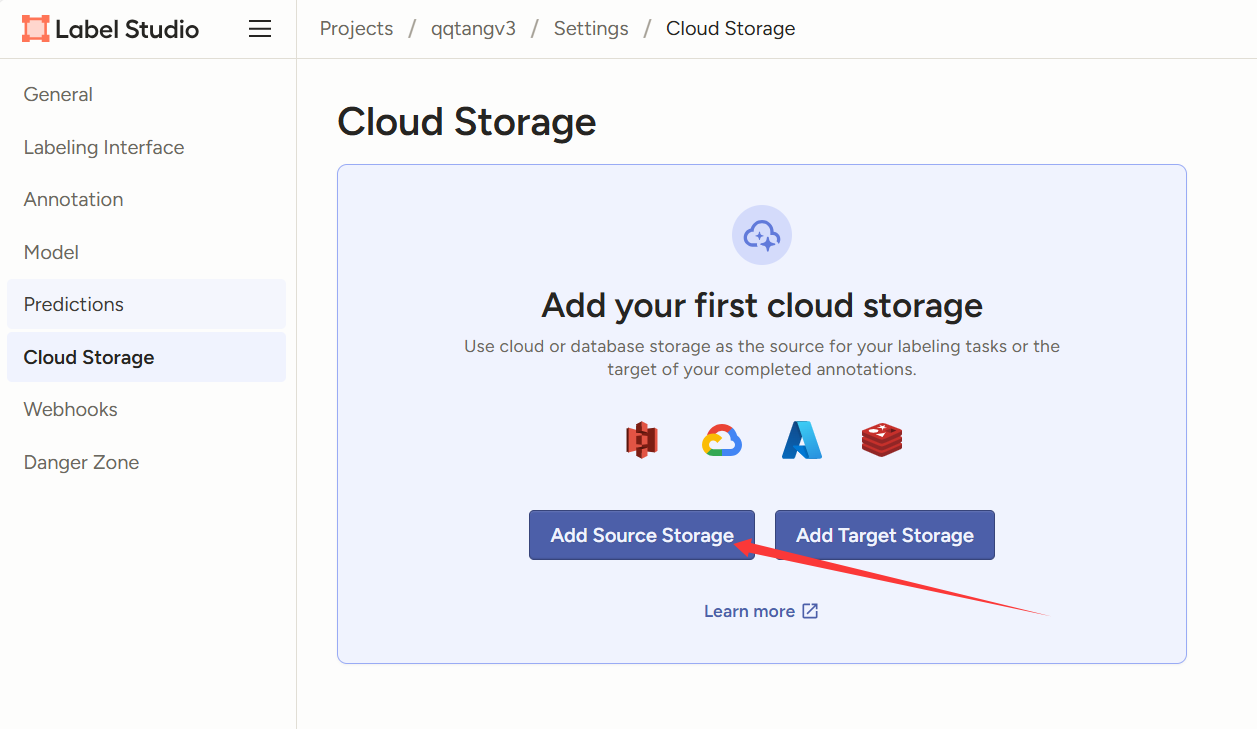
点击add source storage(此处从本地导入,如果是从云库导入的话,可以看它的帮助文档)
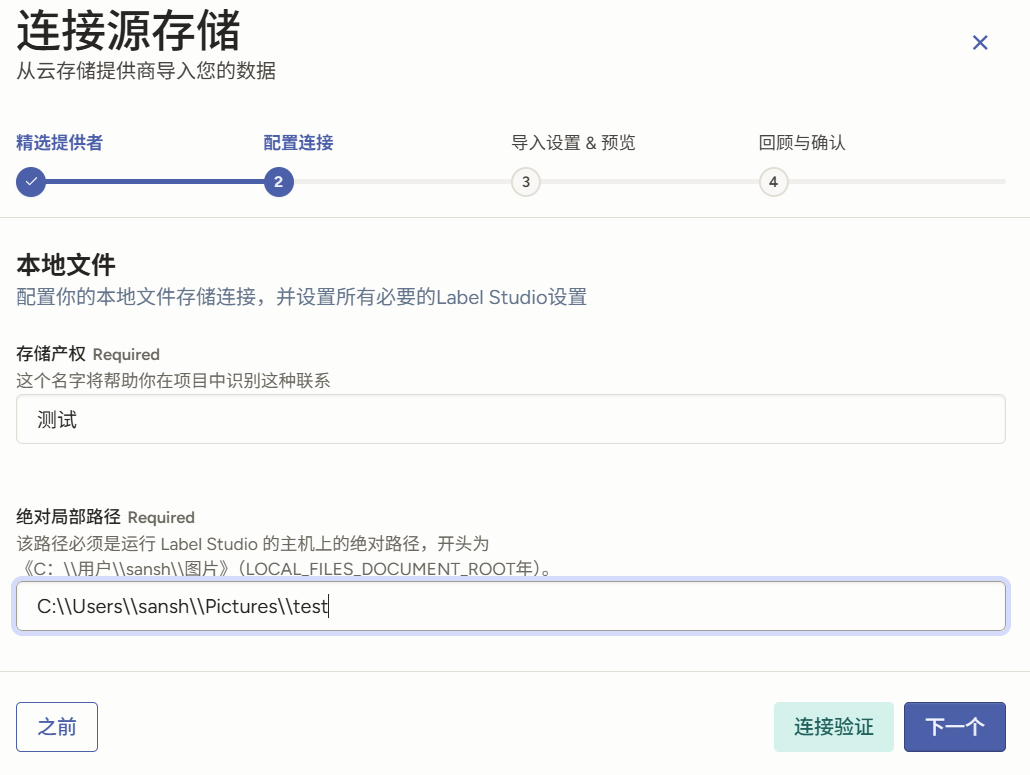
然后在这里填入你数据集的目录,然后点击测试,测试通过的话,就点next。(如果环境变量没有设置好的话,你会看到一个红框,并提示你去设置。)
为了便于理解,我这里翻译了一下。
然后按红表的标记选,选中files,然后文件名用正则筛出所有的图片,下面链接有写好的正则,点一下就自动填上去的。然后点击加载,就把图片都加载进去了,当然我这里只是演示,所以随便塞了几个gif上去。
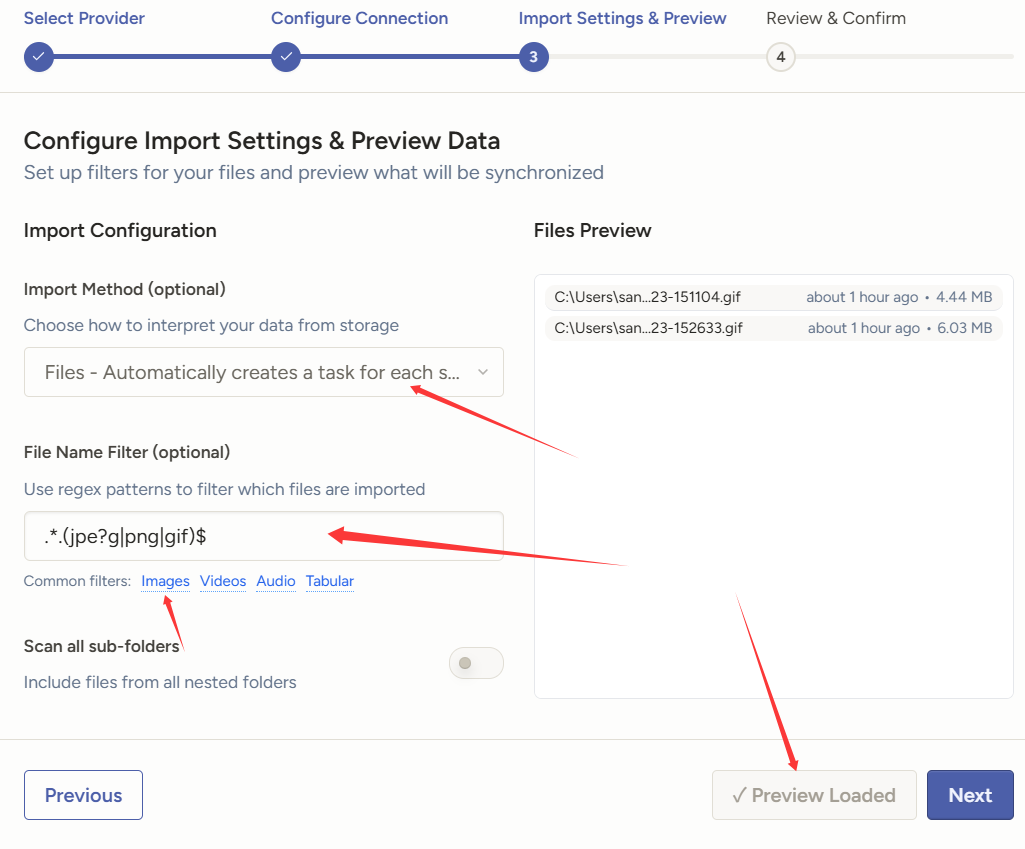
整完之后,保存同步,或者先保存,以后再同步。
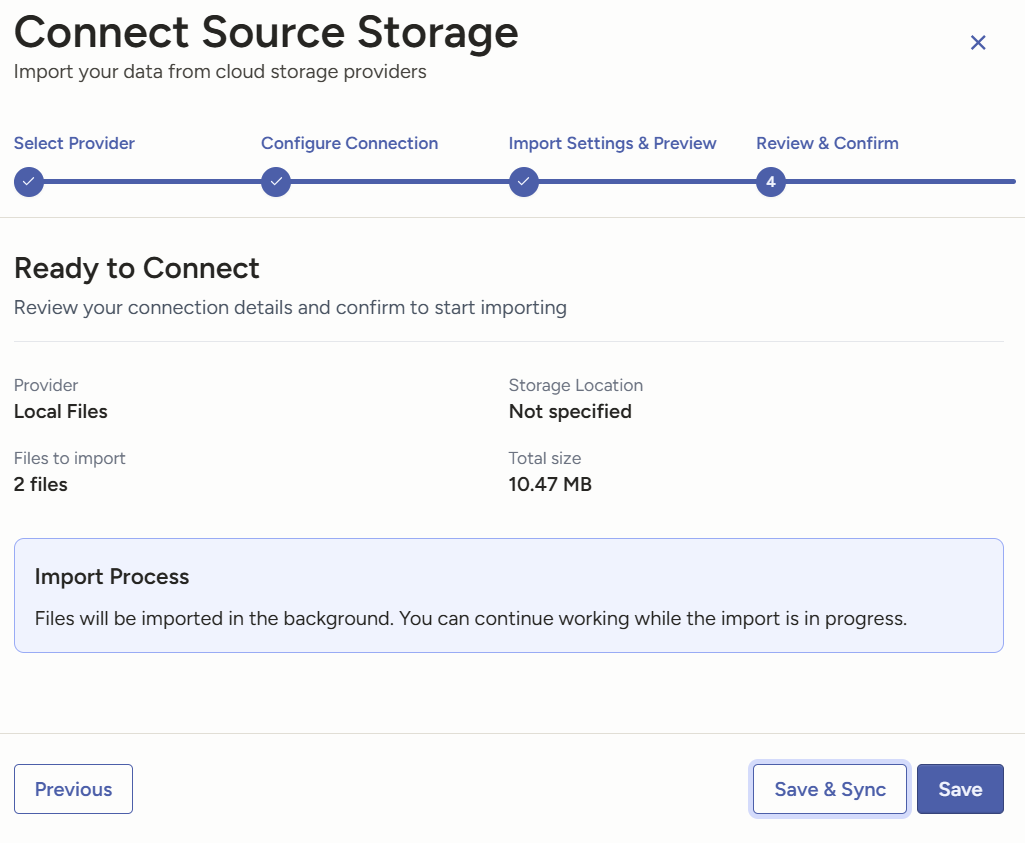
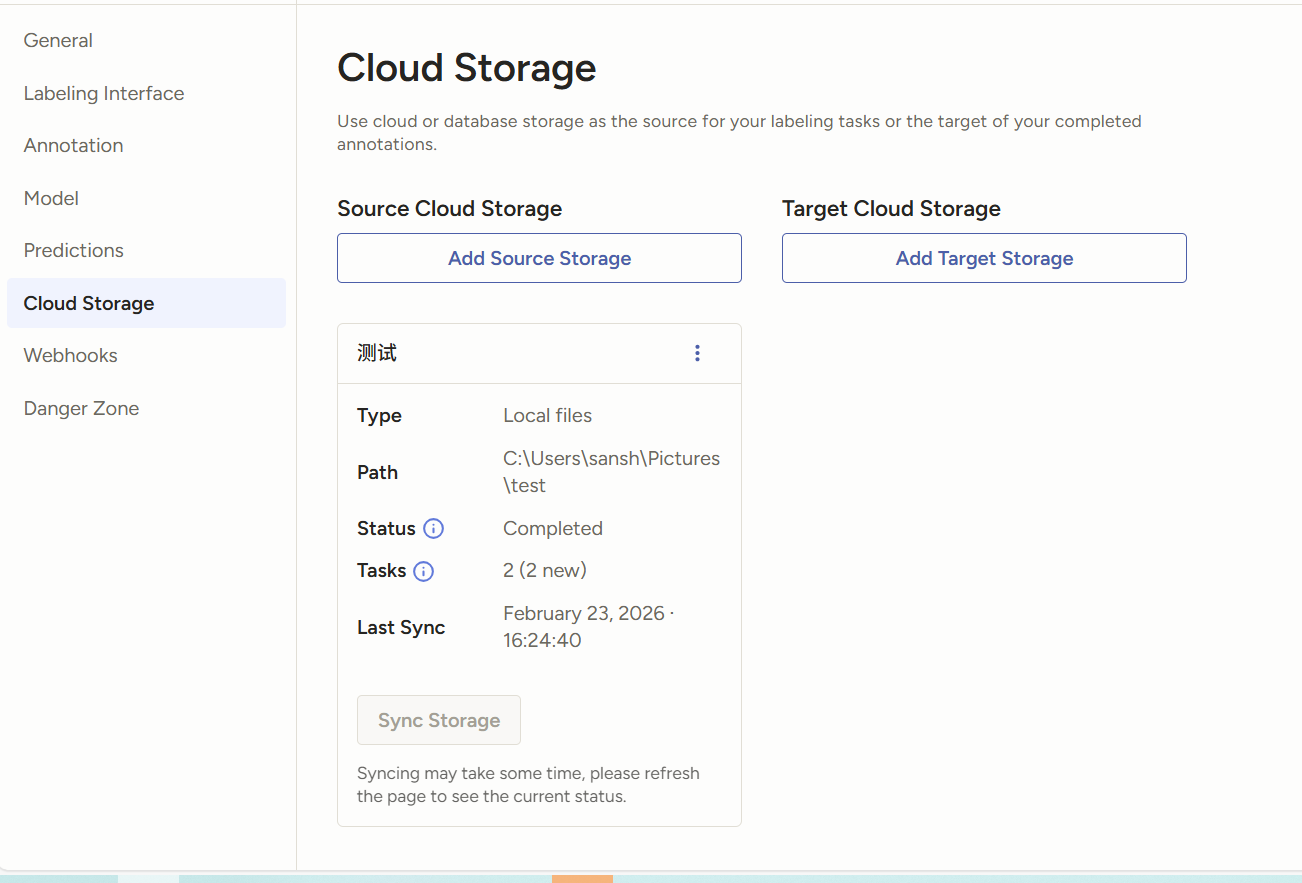
可以看到这里已经导入了,回到这里,可以看到这里有两个图片了。
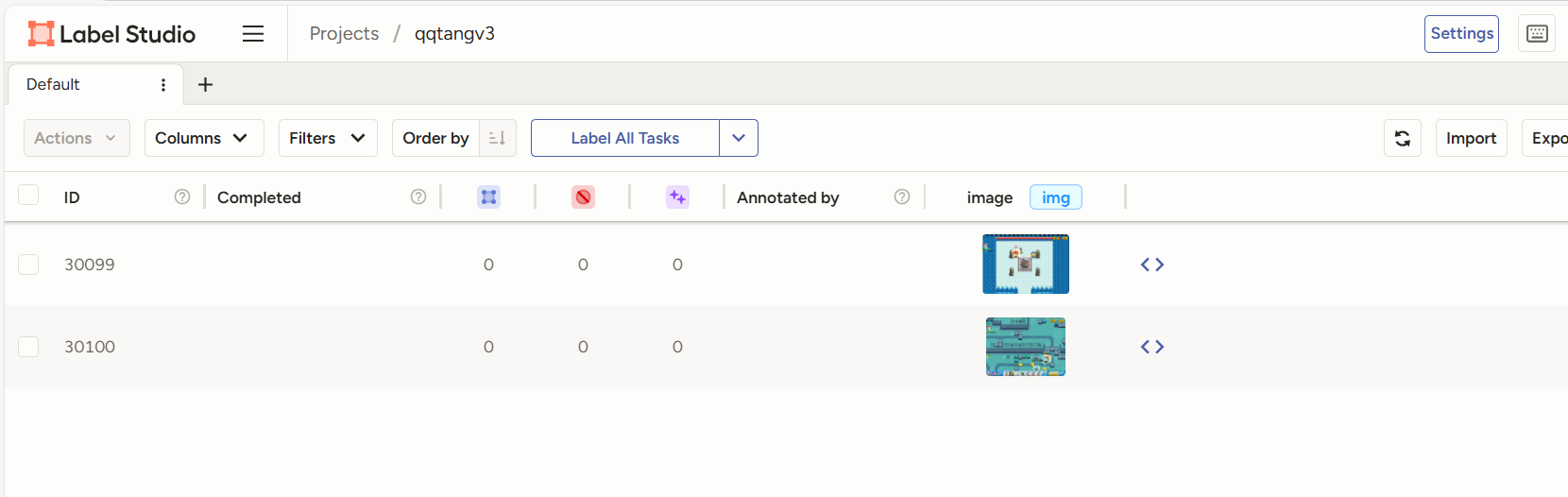
书回正题,总之我们创建成功之后,就是这样(考虑到整数便于计算,这里我改成了用两百张图片)。
(默认的序号是按图片的id排序的,这里我们改成内部id)
现在我们点进去第一个开始标记。
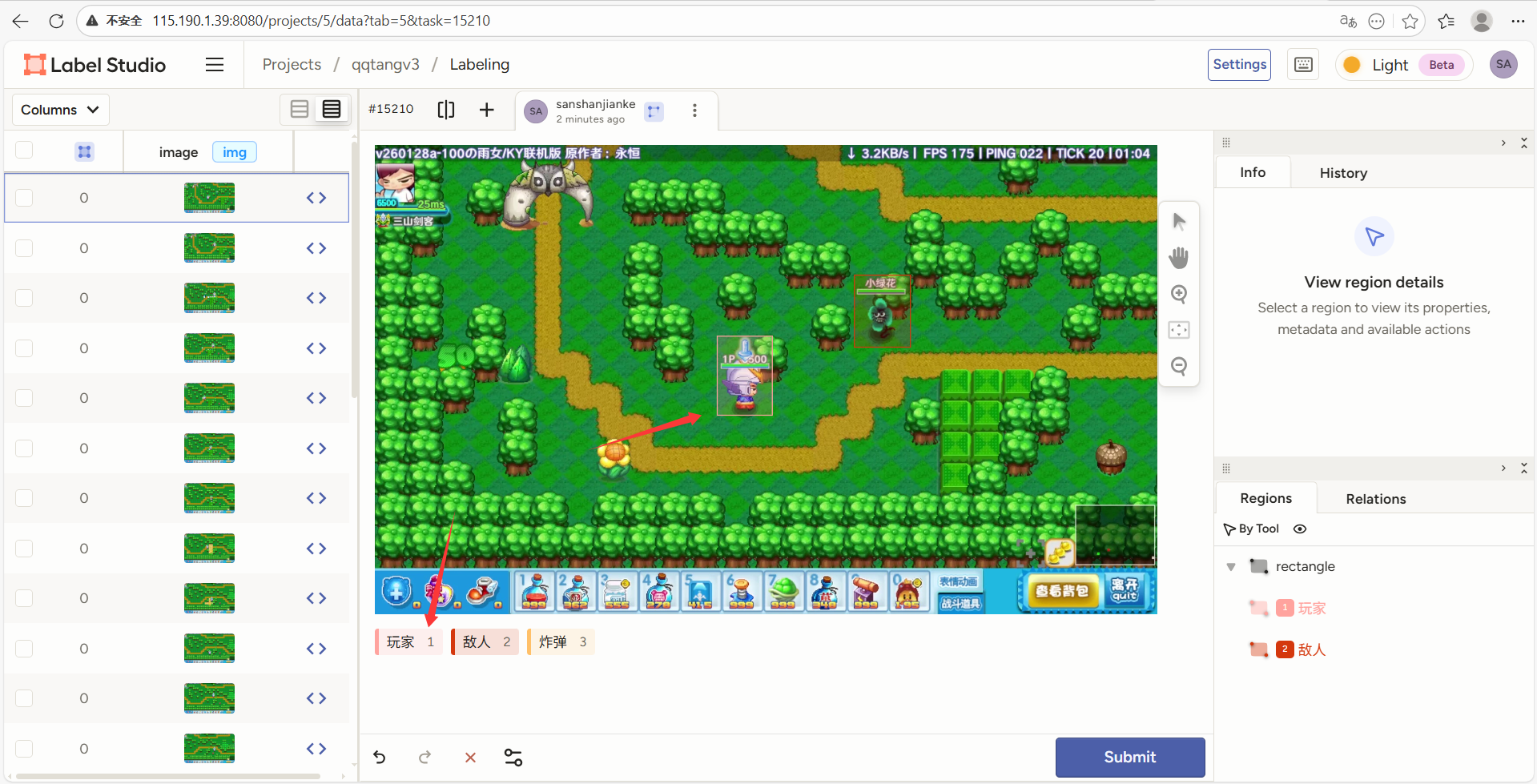
如图所示,点击下面的标签,或者按快捷键(数字),把你需要标记的物体拉个框框标起来就行,尽量在完整的包括对象的同时,尽量小。
可以看到不同的标签,框出来的是不同的颜色(注意不要框错了,框错了AI就学坏了)
框完之后点submit提交,然后框下一个。
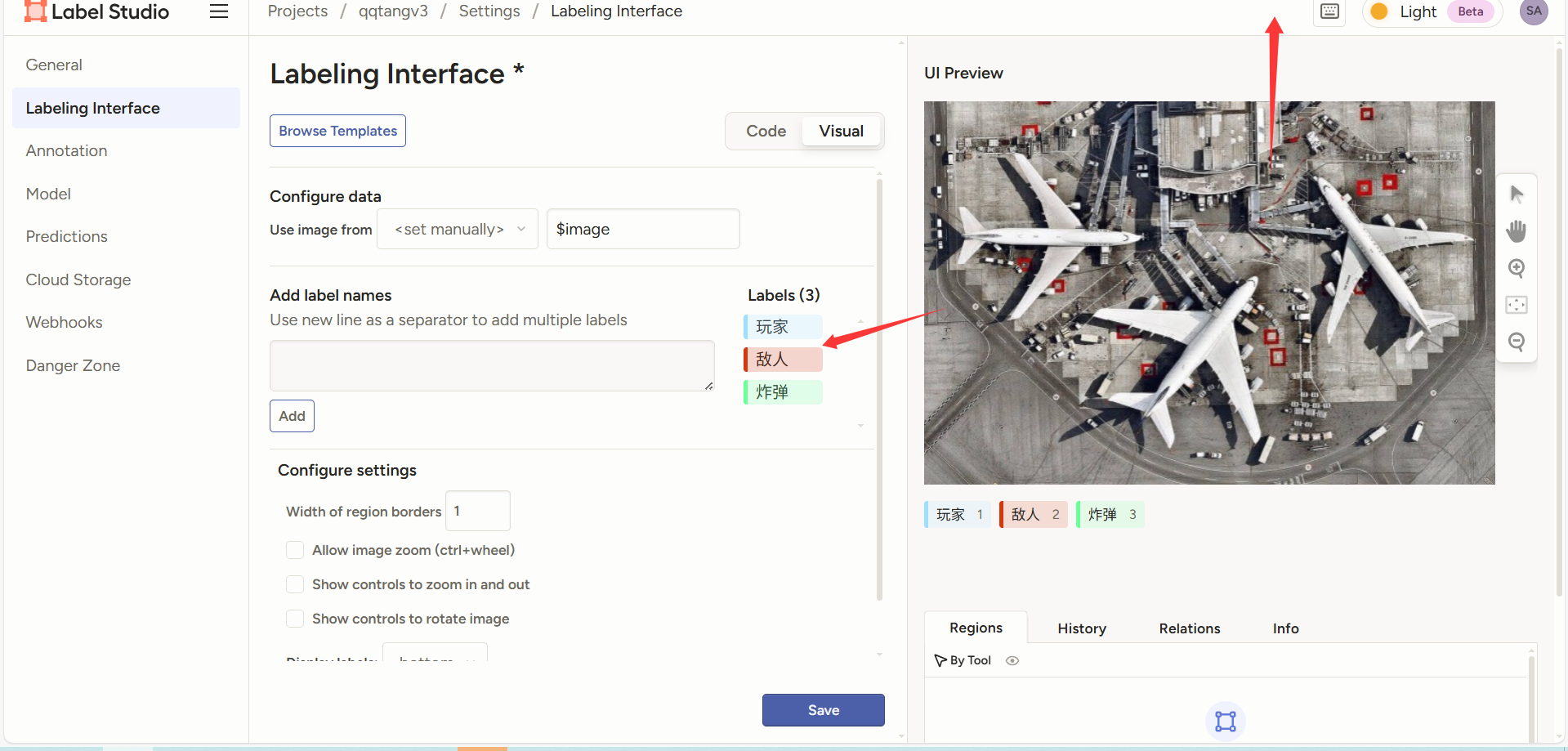
刚刚我发现这个标签的颜色不太对,颜色差异太小了,容易弄混,所以点击setting重新改了一下。
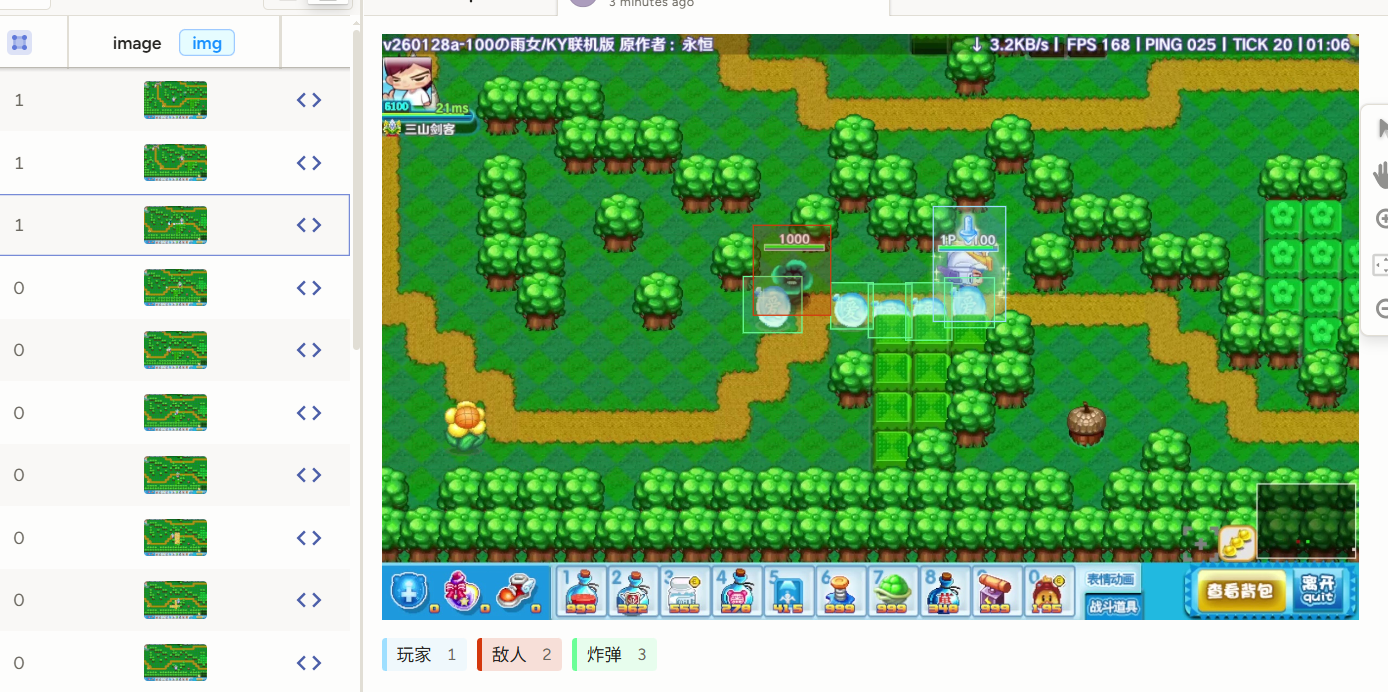
现在看起来就好多了。
标记的时候需要注意一下,如果需要的精度比较高的话,建议第一轮训练的时候,如果有一些物体被遮挡住,只标记那些可以明显的可以推断出来的物体,如果遮挡了4/5之类的就不要标了。等到第二轮训练AI有了一定经验之后,再保标,防止过拟合。
经过一个多小时的标记,我放弃了,只标了150个,实在不想搞了,就这样凑合用吧,这活真不是人干的。
如果你有几万个数据的话,后面我会讲怎么用AI标记。
简单来说就是你先标记几百个,然后拿这几百个去训练AI,让AI学会标记之后,自动给你剩下的几万个标记起来,你只需要一张一张的看,然后修改一下存在问题的就行了。
总之不管那些,我们继续搞,把那些没标记的隔离掉,然后全部选中导出。
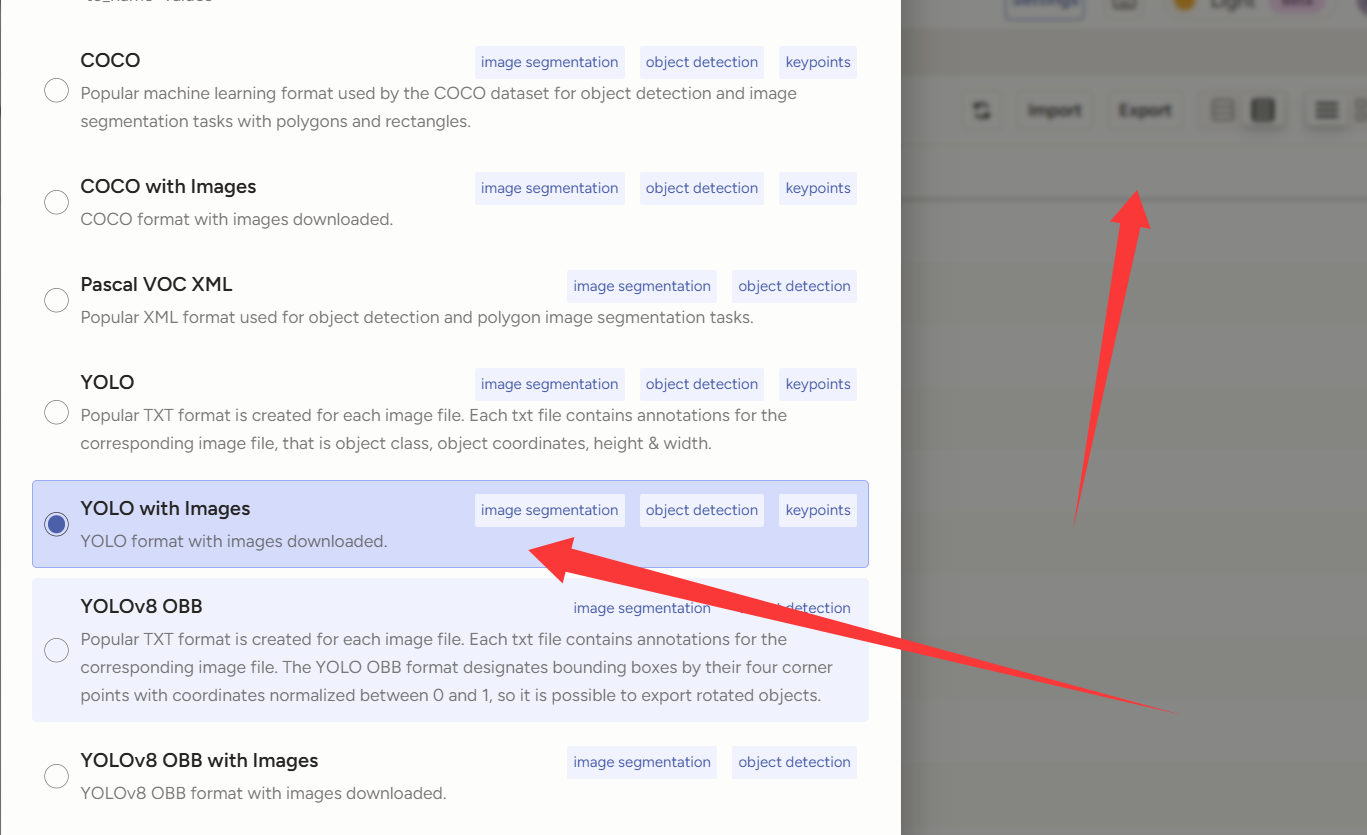
理论上导出的数据应该是带图片的,但很难蚌,导出的压缩包的img里都是空的。
由于我是搭在服务器上的,只好从服务器里重新下载回来。
训练
接下来我们创造一个目录结构,然后放进我们之前创建的yolo2目录中

其中images是放置图片的,labels是存放标签信息的,里面的数据其实是标签的坐标信息,两者的文件一一对应。
其下又分了两个目录,一个是训练集一个是验证集
简单理解的话,训练集是给AI学的,AI学完之后,会用验证集里的内容验证一下自己学的对不对。
我们按4:1的形式,每五张图片抽一张出来做验证。

都放进之后,我们再创建一个文件,我就随便起名叫 test.yaml
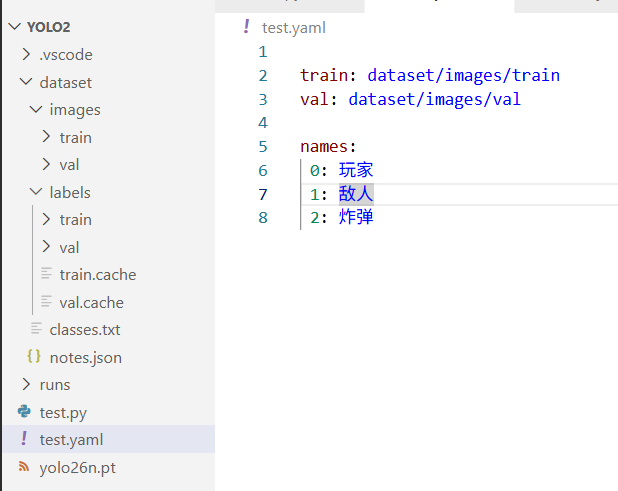
该yaml的内容,描述了训练图片的路径和验证集的路径。
下面的name则是标签名,这个标签名按照你之前设置的标签的先后顺序填就行了。
保存完之后,我们正式写训练脚本。

训练脚本很简单,我们以yolo26n.pt模型为预训练模型,然后训练的数据描述文件也就是我们刚才写的那个。
代码解释我让AI解释一下。
model = YOLO("yolo26n.pt")
- 含义:指定预训练模型的权重文件。
- 注意 :你写的
yolo26n.pt看起来像是一个笔误或者非官方文件名。Ultralytics 官方通常使用yolov8n.pt,yolov8s.pt,yolov11n.pt等。 - 建议 :
- N (Nano): 速度最快,精度最低,适合移动端或边缘设备。
- S (Small): 速度和精度的平衡点,适合大多数通用场景。
- M/L/X: 模型更大,精度更高,但推理慢,显存占用大。
- 推荐 :先用
yolov8n.pt或yolov8s.pt跑通流程,如果精度不够,再换大的。
data="test.yaml"
- 含义:数据集配置文件的路径。
- 建议 :
- 确保 YAML 文件里的
path(根目录)、train(训练集图片路径)、val(验证集图片路径)填写正确。 - 关键点 :检查
names里的类别数量是否和你的标注文件一致。如果 YAML 里写错类别数,训练会报错或读不出标签。
- 确保 YAML 文件里的
epochs=5(训练轮数)
- 含义:整个数据集被训练多少遍。
- 现状 :5 轮太少了。这通常仅用于测试代码是否能跑通(Debug)。在实际任务中,模型还没来得及学习特征就会停止。
- 建议 :
- 微调 :如果你有大量数据,建议设置为 50 ~ 100。
- 从头训练 :建议 100 ~ 300。
- 技巧 :YOLO 会自动保存最佳模型(best.pt),所以你可以把 epochs 设得大一点(如 300),配合
patience(早停参数),当模型不再提升时会自动停止,不用怕浪费时间。
imgsz=640(输入图像尺寸)
- 含义:训练时将图片缩放到的尺寸。默认 640x640。
- 影响 :
- 尺寸越大 :能识别出更小的物体,精度通常更高,但训练速度变慢 ,显存占用暴增。
- 尺寸越小:训练极快,显存占用低,但小物体可能看不清。
- 建议 :
- 默认
640是最通用的。 - 如果你的目标物体很小 (例如航拍图、零件缺陷检测),尝试改成
1024或1280。 - 如果显存不够用,先降低这个参数(如
480或320)。
- 默认
batch=16(批大小)
- 含义:一次训练喂给模型的图片数量。
- 影响 :
- Batch 越大:训练梯度更稳定,显存占用越高。
- Batch 越小:显存占用低,但梯度震荡,可能需要调整学习率。
- 建议(显存调试法) :
- 如果你的显存是 8G :尝试
batch=16。 - 如果显存是 12G/16G :尝试
batch=32或64。 - 如果报错
CUDA out of memory:减半(改为 8, 4, 甚至 2)。 - 如果显存没满,尽量调大,能加快训练速度。
- 如果你的显存是 8G :尝试
device=0(设备)
- 含义:指定训练硬件。
- 建议 :
0: 使用第 1 块 NVIDIA 显卡(最常用)。1: 如果你有两块卡,想用第 2 块。cpu: 强制用 CPU(速度极慢,不推荐)。mps: 如果你是 Mac (M1/M2/M3 芯片),用这个。[0,1]: 使用多卡并行训练(需要显卡够多)。
workers=4(数据加载线程数)
- 含义:负责读取图片和预处理数据的线程数量。
- 影响:设置太小,GPU 训练完一张图,需要等 CPU 读下一张图,导致 GPU 空转。
- 建议 :
- Windows 用户 :建议保持 4 或 8。Windows 下如果设得太大(如 16+)容易报错或多进程卡死。
- Linux 用户 :通常可以设为 8 或 CPU 核心数,能显著提升数据加载速度
训练完成之后,可以在run目录下找到last.pt和best.py,一个是最后一次训练的模型,一个是训练的最好的一个模型。
其中还生成了各种.png文件,特别是results.png,描述了训练的结果如何,读者可以根据关键词向AI询问,这里就不过多介绍了。
有了这两个模型,你就能像之前测试一样使用了。
先写到这里,后面自动化AI标记日后再更。