本文介绍了使用TensorFlow实现多层感知机(MLP)进行MNIST手写数字分类的方法。通过构建包含两个隐藏层的神经网络,采用Sigmoid激活函数和Sigmoid交叉熵损失函数,利用Adam优化器进行训练。代码展示了数据预处理、模型构建、训练过程及测试评估的完整流程,最终输出训练损失曲线和测试准确率。关键概念包括MLP结构、反向传播算法、one-hot编码、占位符等深度学习基础知识。该实现为深度学习初学者提供了完整的神经网络实践案例。
目录
[TensorFlow 实现多层感知机学习](#TensorFlow 实现多层感知机学习)
TensorFlow 实现多层感知机学习
多层感知机构成了人工神经网络中最为复杂的网络架构,它本质上由多层感知机堆叠而成。
多层感知机的学习架构可通过以下层级表示:输入层 → 隐藏层 → 输出层
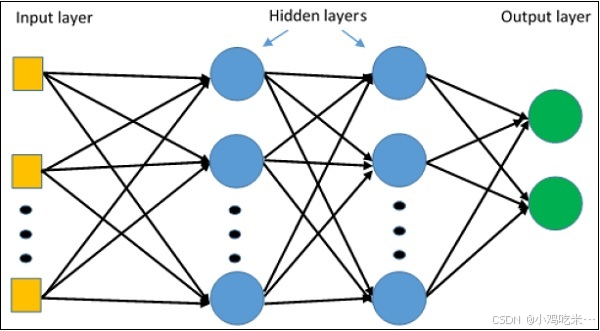
多层感知机(MLP)网络通常适用于监督学习场景,其经典的学习算法为反向传播算法。
接下来,我们将基于多层感知机实现一个图像分类任务,以 MNIST 手写数字识别为例展开代码实现。
python
# 导入MNIST数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# 模型超参数
learning_rate = 0.001 # 学习率
training_epochs = 20 # 训练轮数
batch_size = 100 # 批次大小
display_step = 1 # 日志打印步长
# 网络结构参数
n_hidden_1 = 256 # 第一个隐藏层的特征数
n_hidden_2 = 256 # 第二个隐藏层的特征数
n_input = 784 # MNIST数据集输入维度(28*28像素展开为一维向量)
n_classes = 10 # MNIST数据集分类数(0-9共10个数字)
# 定义TensorFlow计算图的输入占位符
x = tf.placeholder("float", [None, n_input]) # 输入特征占位符
y = tf.placeholder("float", [None, n_classes])# 标签占位符
# 定义第一层隐藏层的权重和偏置
h = tf.Variable(tf.random_normal([n_input, n_hidden_1]))
bias_layer_1 = tf.Variable(tf.random_normal([n_hidden_1]))
# 计算第一层隐藏层输出(Sigmoid激活函数)
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, h), bias_layer_1))
# 定义第二层隐藏层的权重和偏置
w = tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2]))
bias_layer_2 = tf.Variable(tf.random_normal([n_hidden_2]))
# 计算第二层隐藏层输出(Sigmoid激活函数)
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, w), bias_layer_2))
# 定义输出层的权重和偏置
output = tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
bias_output = tf.Variable(tf.random_normal([n_classes]))
# 计算输出层结果(无激活函数,直接输出logits)
output_layer = tf.matmul(layer_2, output) + bias_output
# 定义损失函数(Sigmoid交叉熵损失)
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = output_layer, labels = y
))
# 定义优化器(Adam优化器,最小化损失函数)
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# 也可使用梯度下降优化器:
# optimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost)
# 初始化绘图参数,用于记录每轮损失
avg_set = []
epoch_set = []
# 初始化所有模型变量
init = tf.global_variables_initializer()
# 启动TensorFlow会话,执行计算图
with tf.Session() as sess:
sess.run(init)
# 开始训练循环
for epoch in range(training_epochs):
avg_cost = 0.
# 计算总批次数
total_batch = int(mnist.train.num_examples / batch_size)
# 遍历所有批次进行训练
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 喂入数据,执行优化器
sess.run(optimizer, feed_dict = {x: batch_xs, y: batch_ys})
# 计算当前批次的损失,累计求平均
avg_cost += sess.run(cost, feed_dict = {x: batch_xs, y: batch_ys}) / total_batch
# 按步长打印训练日志
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost))
# 记录每轮的平均损失
avg_set.append(avg_cost)
epoch_set.append(epoch + 1)
print("Training phase finished")
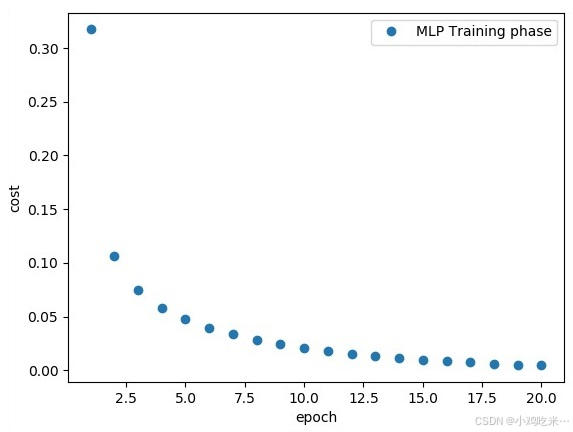
# 绘制训练损失变化曲线
plt.plot(epoch_set, avg_set, 'o', label = 'MLP Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# 测试模型:计算预测准确率
correct_prediction = tf.equal(tf.argmax(output_layer, 1), tf.argmax(y, 1))
# 将布尔值转换为浮点型,计算平均值即为准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# 喂入测试集数据,评估模型准确率
print("Model Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))上述代码运行后会生成训练损失变化曲线,横轴为训练轮数(epoch),纵轴为损失值(cost),曲线数值分布如下:
plaintext
0.30
0.25
0.20
0.15
0.10
0.05
0.00横轴刻度:2.5、5.0、7.5、10.0、12.5、15.0、17.5、20.0
核心术语与知识点说明
- 多层感知机(MLP):一种前馈人工神经网络,包含输入层、至少一个隐藏层和输出层,层间为全连接结构,隐藏层使用非线性激活函数实现特征映射。
- 反向传播算法:MLP 的核心训练算法,通过计算输出层的损失,将误差从后向前逐层传递,更新各层的权重和偏置,以最小化损失函数。
- One-hot 编码:一种分类标签的编码方式,将 n 个类别表示为 n 维向量,每个样本的标签对应向量中仅有一位为 1,其余为 0(如数字 5 对应 0,0,0,0,0,1,0,0,0,0)。
- 占位符(placeholder) :TensorFlow 中用于接收外部输入的张量,在会话执行时通过
feed_dict喂入数据。 - Adam 优化器:一种自适应学习率的优化算法,结合了动量法和 RMSProp 的优点,收敛速度比传统梯度下降更快。
- 交叉熵损失:分类任务中常用的损失函数,用于衡量模型预测的概率分布与真实标签分布的差异,Sigmoid 交叉熵适用于多分类场景。
- tf.argmax:返回张量在指定维度上最大值的索引,用于将模型输出的 logits 转换为预测的类别标签。