一、概述
Graphify 是一个 AI 编码助手技能和 Python 库,旨在将包含代码、文档、研究论文、图像和视频等多种文件的目录转换为一个可查询的、结构化的知识图谱。
通过利用基于 AST 的提取技术处理代码,以及基于 LLM 的语义提取技术处理非结构化数据,与直接读取原始文件相比,它在处理复杂查询时能够显著减少token消耗(最多可减少 71.5 倍)。
该项目的存在是为了解决大型、多模态研究或工程代码库中的"上下文窗口溢出"问题,提供结构清晰性和持久的图谱导航。
主要功能
-
多模态提取 :通过
tree-sitter支持 25 种编程语言(包括 Dart、Verilog 和 PHP),并通过 Claude 和 Whisper 支持非结构化数据(PDF、图片、Markdown、视频/音频)。 -
结构化分析:自动识别"God Nodes"(高度集中的枢纽节点)以及跨不同领域的"意外连接"(例如,特定代码实现与研究论文引用之间的关联)。
-
交互式可视化:生成可搜索的 HTML/vis.js 图、Obsidian 知识库,以及可供代理爬取的 Wiki。
-
增量更新:使用 SHA256 语义缓存确保仅重新处理已变更的文件,并包含一个文件观察器以实现实时同步。
-
代理集成:提供一个 MCP(模型上下文协议)服务器,供 AI 代理直接与图谱交互,并为 Claude Code、Cursor、Aider 和 Trae 等平台提供专门的技能
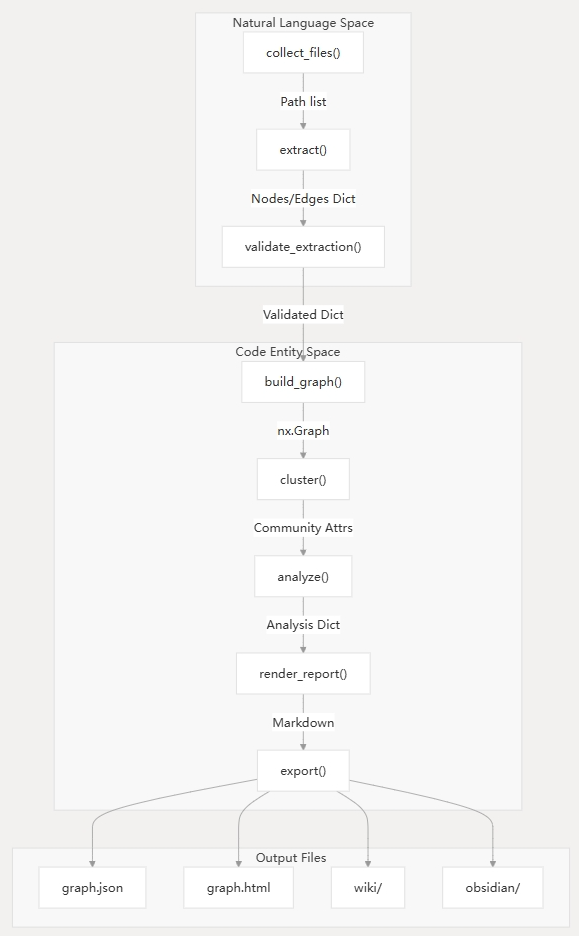
高级管道流程
该系统以线性管道的方式运行,每个阶段都隔离在自己的模块中,通过普通的 Python 字典和 NetworkX 图对象进行通信。
graphify 管道流程
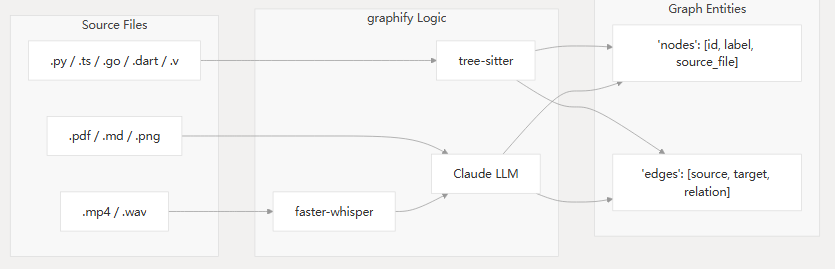
子系统关系
graphify 通过几个专门的子系统,弥合了原始源文件与结构化图数据之间的差距:
| 子系统 | 核心模块 | 职责 |
|---|---|---|
| 检测 | detect.py |
发现文件并按类型分类(代码、文档、论文、图像、视频) |
| 提取 | extract.py |
使用 tree-sitter 进行 AST 结构提取,使用 LLM/Whisper 进行语义关系提取 |
| 图逻辑 | build.py、cluster.py |
将提取内容组装成 NetworkX 图,并应用 Leiden 社区检测 |
| 分析 | analyze.py |
计算节点中心性和跨社区"意外连接" |
| 接口 | serve.py、watch.py |
提供 MCP 服务器和实时文件系统监控 |
实体映射:从源文件到图
快速入门与安装
本页提供安装 graphify、注册 Claude Code 技能以及验证安装设置的分步指南。graphify 能够将包含代码、文档、论文、图像或视频的目录转换为可查询的知识图谱。
安装
graphify 以 Python 包 graphifyy 的形式分发。它需要 Python 3.10 或更高版本。
基础安装
基础安装包含核心图谱组装引擎(networkx)以及通过 tree-sitter 对超过 20 种编程语言 的结构化提取支持。
pip install graphifyy可选依赖组
graphify 使用可选依赖项来保持基础安装的轻量化,同时支持 PDF、Office 文档、视频转录等特殊数据类型。
| 依赖组 | 安装命令 | 用途 |
|---|---|---|
mcp |
pip install "graphifyy[mcp]" |
安装 MCP(模型上下文协议)服务器所需依赖 |
neo4j |
pip install "graphifyy[neo4j]" |
安装 Neo4j 驱动,用于将图谱直接注入 Neo4j 数据库 |
pdf |
pip install "graphifyy[pdf]" |
安装 pypdf 和 html2text,用于论文/文档的导入 |
watch |
pip install "graphifyy[watch]" |
安装 watchdog,用于实时文件系统监控 |
svg |
pip install "graphifyy[svg]" |
安装 matplotlib,用于静态 SVG 图谱渲染 |
leiden |
pip install "graphifyy[leiden]" |
安装 graspologic,用于高级社区检测(仅限 Python < 3.13) |
office |
pip install "graphifyy[office]" |
安装 python-docx 和 openpyxl,用于 Word/Excel 文件处理 |
video |
pip install "graphifyy[video]" |
安装 faster-whisper 和 yt-dlp,用于视频转录 |
all |
pip install "graphifyy[all]" |
安装上述所有可选依赖项 |
注册 Claude Code 技能
安装完成后,必须将 graphify 注册为技能,才能在 AI 编程助手(如 Claude Code)中使用 /graphify 命令。
graphify install 命令
graphify install 命令会自动完成注册流程。它会执行以下操作:
-
部署技能 :将技能清单(如
SKILL.md)从包中复制到助手配置目录(如~/.claude/skills/graphify/SKILL.md)。 -
更新配置 :对于 Claude Code,它会更新或创建
~/.claude/CLAUDE.md文件,并添加_SKILL_REGISTRATION代码块,从而启用/graphify触发命令。 -
多平台支持 :支持多种平台,包括
claude、codex、opencode、aider、copilot、claw、droid、trae、hermes、kiro、antigravity和windows。 -
版本追踪 :在技能目录中写入
.graphify_version文件,用于追踪更新。
图示说明 :该流程图显示了
install函数如何连接本地 Python 包与 AI 助手的配置空间。(标题:技能注册与配置流程)
VScode copilot 安装
graphify vscode install
skill installed -> C:\Users\86130\.copilot\skills\graphify\SKILL.md
.github\copilot-instructions.md -> created
验证安装设置
为确保 graphify 已正确安装且其依赖项已解决,请执行以下验证步骤:
1. 检查 CLI 入口点
验证 graphify 命令是否在您的 PATH 中可用:
graphify --help2. 验证平台安装
您可以检查目标路径来验证技能的安装情况。例如,对于 claude 平台:
ls ~/.claude/skills/graphify/SKILL.md3. CI 风格验证
该项目使用 CI 工作流来验证端到端功能。您可以通过运行测试套件在本地模拟:
pip install pytest
python -m pytest tests/ -q --tb=short图示说明 :此图展示了
graphify命令(技能的核心)如何协调从原始文件到最终图谱报告的转换流程。(标题:管道执行与验证)
CI 工作流
graphify 通过 GitHub Actions 维护了一个稳健的 CI 管道:
- 触发条件 :每次推送到
main分支和版本分支(v1-v4)或提交拉取请求时运行。
二、核心架构
graphify 架构设计为一个线性、模块化的流水线,将非结构化或半结构化数据(代码、文档、论文、图像、音频和视频)转换为结构化的、可导航的知识图谱。流水线的每个阶段都封装在一个专用模块中,通过标准的 Python 字典和 NetworkX 图对象进行通信。
流水线概述
系统遵循严格的顺序流程:检测 → 提取 → 构建 → 聚类 → 分析 → 报告 → 导出。这种模块化设计支持增量更新,例如可以在不从源文件重新提取的情况下重新运行聚类或分析。
在 v0.5.0 版本中,通过引入 build_merge() 进一步增强了该能力,支持安全的增量更新,防止在处理部分块时丢失数据。
高级数据流
下图说明了系统如何从自然语言/文件空间转换到代码实体/图空间,并包含多模态转录层。
图示:流水线阶段转换
模块职责
每个模块执行离散的转换。关注点分离确保了基于 AST 的提取(快速、本地)与基于 LLM 的语义推理(较慢、外部)的解耦。
| 模块 | 主要功能 | 输入 → 输出 |
|---|---|---|
detect.py |
detect() |
目录 → 分类的文件清单(代码/文档/图像/视频) |
transcribe.py |
transcribe() |
音频/视频 → 通过 faster-whisper 生成文本转录 |
extract.py |
extract() |
文件 → 节点/边提取字典列表 |
build.py |
build() / build_merge() |
提取字典 → networkx.Graph 或 DiGraph |
cluster.py |
cluster() |
图 → 带有社区和内聚属性的图 |
analyze.py |
god_nodes() |
图 → 识别出的枢纽节点和"意外"连接 |
report.py |
generate() |
图 + 分析结果 → GRAPH_REPORT.md 审计追踪 |
子系统关系
graphify 通过几个专门的子系统,弥合了原始源文件与结构化图数据之间的差距:
| 子系统 | 核心模块 | 职责 |
|---|---|---|
| 检测 | detect.py |
发现文件并按类型分类(代码、文档、论文、图像、视频) |
| 提取 | extract.py |
使用 tree-sitter 进行 AST 结构提取,使用 LLM/Whisper 进行语义关系提取 |
| 图形逻辑 | build.py, cluster.py |
将提取结果组装成 NetworkX 图,并应用 Leiden 社区检测 |
| 分析 | analyze.py |
计算节点中心性和跨社区"意外连接" |
| 接口 | serve.py, watch.py |
提供 MCP 服务器和实时文件系统监控 |
| 导出 | export.py |
to_json() / to_html() → 持久化和可视化(Obsidian、Neo4j 等) |
提取输出模式
原始文件与图组装之间的桥梁是一个标准化的 JSON 模式。每个提取器(适用于 25+ 语言的 AST,或适用于音频的 Whisper)都必须输出符合此模式的数据,以便 validate.py 进行验证。
节点与边的要求
-
节点 :必须包含
id、label、file_type和source_file。最近的更新还使用了norm_label以实现跨文件的稳健匹配。 -
边 :必须包含
source、target、relation、confidence和source_file。
置信度标签
为了维护"诚实的审计追踪",每条边都带有一个置信度级别标签:
| 标签 | 含义 |
|---|---|
| EXTRACTED(已提取) | 在源文件中明确发现(例如 Tree-sitter AST 导入) |
| INFERRED(已推断) | 通过启发式方法或 LLM 上下文推导得出 |
| AMBIGUOUS(不明确) | 不确定性关系,在报告中标出以供审查 |
管道阶段(子页面)
有关每个阶段的详细技术实现,请参阅以下子页面:
-
文件检测与分类 :介绍
detect.py如何发现文件、应用.graphifyignore并将文件分类为论文、代码或视频等类型。 -
提取引擎:深入介绍基于 AST 的 25+ 语言提取(包括 Dart、Verilog 和 MJS)以及针对视频/音频的多模态转录。
-
图组装与聚类 :介绍
build.py如何合并提取结果、处理deduplicate_by_label(),以及cluster.py如何使用 Leiden 算法进行社区检测。 -
图分析:识别"上帝节点"(为清晰起见,从度数重命名而来)以及跨越社区边界的"意外连接"。
-
报告生成 :介绍
GRAPH_REPORT.md的组装过程以及 Token 缩减指标的计算方法(例如,针对 Karpathy 代码库实现 71.5 倍缩减)。
系统交互图
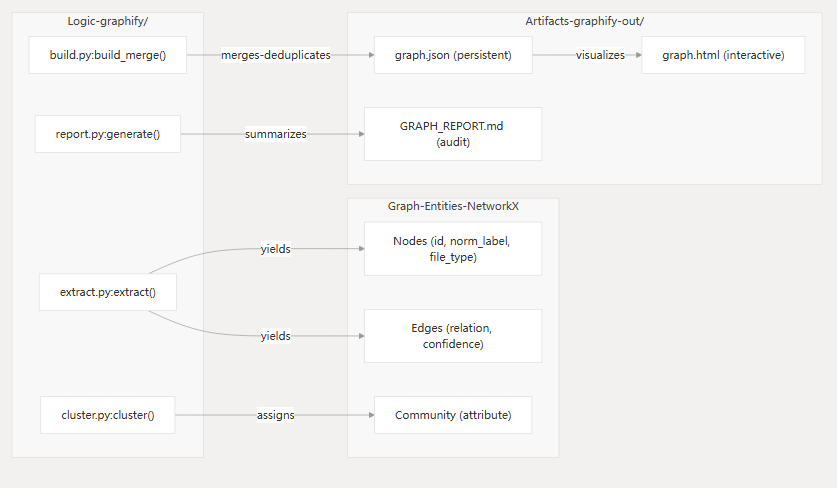
此图将内部 Python 逻辑映射到最终的图实体和输出构件。
图示:逻辑到实体的映射
2.1 文件检测与分类
graphify/detect.py 模块负责目标目录内文件的初始发现、过滤和分类。它是整个流程的入口点,决定哪些文件值得索引,哪些文件出于安全或噪音原因应当被忽略,以及语料库的规模是否适合进行基于图谱的分析。
文件发现与过滤
文件发现由 detect() 函数处理,它使用 os.walk 递归扫描根目录,并包含专门逻辑来忽略噪音、敏感数据以及匹配用户定义忽略模式的文件。
降噪与忽略逻辑
为防止图谱被构建产物或依赖项充斥,detect() 会在遍历过程中即时剪枝目录树:
-
排除的目录 :跳过
node_modules、__pycache__、.git、venv、dist等常见文件夹。 -
模式匹配 :以
_venv、_env或.egg-info结尾的目录也会被忽略。 -
隐藏文件 :以
.开头的文件(点文件)默认会被跳过,除非它们位于graphify-out/memory/目录中。 -
.graphifyignore:_is_ignored()辅助函数会检查文件是否匹配从.graphifyignore文件中加载的模式。该搜索会从扫描目录向上遍历到 git 根目录。
安全与敏感文件
_is_sensitive() 辅助函数使用一组正则表达式(_SENSITIVE_PATTERNS)来识别并跳过可能包含机密的文件,例如 .env 文件、SSH 密钥(id_rsa)、证书(.pem)和云凭证。
分类与启发式规则
文件被发现后,classify_file() 会为其分配一个 FileType 枚举值。根据扩展名的分类规则如下:
| 文件类型 | 扩展名 | 说明 |
|---|---|---|
| CODE(代码) | .py, .ts, .js, .go, .rs, .dart, .v, .sv 等 |
由 tree-sitter 提取器支持 |
| DOCUMENT(文档) | .md, .mdx, .txt, .rst, .html, .docx, .xlsx |
通用文档和 Office 文件 |
| PAPER(论文) | .pdf 或信号密集的 .md/.txt |
学术论文(ArXiv、期刊) |
| IMAGE(图像) | .png, .jpg, .jpeg, .gif, .webp, .svg |
多模态资产 |
| VIDEO(视频/音频) | .mp4, .mov, .webm, .mp3, .wav 等 |
用于转录的媒体文件 |
学术论文启发式规则
Graphify 的一个独特功能是能够区分标准文档和学术论文。如果遇到 .md 或 .txt 文件,_looks_like_paper() 会扫描前 3000 个字符以寻找学术信号,需要至少命中 3 个 _PAPER_SIGNALS,包括:
-
ArXiv ID(如
1706.03762) -
LaTeX 引用模式(
\cite{...}) -
编号引用(
[1]、[23]) -
学术用语("we propose"、"literature"、"abstract")
-
DOI 字符串或期刊/会议记录提及
Office 文件转换
Graphify 支持将 Microsoft Office 格式转换为 Markdown,以便于图谱导入:
-
DOCX :
docx_to_markdown()使用python-docx提取标题、段落和表格。 -
XLSX :
xlsx_to_markdown()使用openpyxl将工作表转换为 Markdown 表格。
语料健康度阈值
Graphify 会基于词数和文件数计算语料库的"健康度",并通过检测结果中的 warning 字段向用户提供指导:
| 阈值 | 数值 | 含义 |
|---|---|---|
下界(CORPUS_WARN_THRESHOLD) |
5万词 | 若语料小于此值,警告内容可能适合单个 LLM 上下文窗口 |
上界(CORPUS_UPPER_THRESHOLD) |
50万词 | 警告提取和分析的 Token 成本较高 |
文件数上界(FILE_COUNT_UPPER) |
200个文件 | 警告文件数量可能导致处理时间过长 |
PDF 的词数通过 pypdf 提取文本估算,而文本文件则通过 count_words() 中的空白字符分割进行计数。
增量检测与清单管理
为避免重新处理未变更的文件,Graphify 实现了一个基于清单(manifest)的增量系统。清单存储在 graphify-out/manifest.json 中,将文件路径映射到其上次的 mtime(修改时间)和 size(大小)。
detect_incremental() 函数将当前文件系统状态与保存的清单进行比较:
-
调用
detect()获取当前文件列表 -
将每个文件的
st_mtime和st_size与load_manifest()的数据进行对比 -
返回
added、modified和deleted路径的字典
清单管理辅助函数
| 函数 | 功能 |
|---|---|
save_manifest(files_list) |
将所有给定路径的当前 mtime 和 size 记录到 JSON 清单中 |
load_manifest() |
从磁盘检索存储的清单 |
2.2 提取引擎
提取引擎是 Graphify 的主要摄入与解析层,负责将原始源代码、学术论文、网页内容和音视频媒体转换为统一的图谱模式。它采用混合方法:基于 tree-sitter 的确定性AST(抽象语法树)解析(支持 20+ 种语言)、专门的网页摄取,以及针对多模态数据的 AI 驱动转录。
基于 AST 的结构化提取
该引擎使用 tree-sitter 对代码实体及其关系进行确定性提取 。与基于 LLM 的提取不同,这一过程纯粹基于结构,确保类层次结构、方法定义和导入图的 100% 准确性。
支持的语言与提取器函数
该引擎支持 20 多种语言,包括对 Dart、Verilog/SystemVerilog、PHP 以及移动/系统语言的专门支持:
| 语言 | 提取器函数 | 捕获的主要实体 |
|---|---|---|
| Python | extract_python |
类、方法、函数、导入、继承、调用 |
| JS / TS | extract_js |
类、方法、函数、导出、调用,支持 .mjs / .ejs |
| Go | extract_go |
结构体、方法、构造函数、调用 |
| Rust | extract_rust |
结构体、Impl 块、方法、函数、调用 |
| Java | extract_java |
类、接口、方法、导入 |
| C / C++ | extract_c, extract_cpp |
函数、类、头文件包含、调用 |
| PHP | extract_php |
类、Trait、静态属性、容器绑定 |
| Dart | extract_dart |
类、Mixin、扩展、方法 |
| Verilog / SV | extract_verilog |
模块、接口、实例、端口 |
LanguageConfig 模式
大多数提取器由一个通用的 LanguageConfig 数据类驱动,它将 tree-sitter 节点类型映射到图实体。通过简单地定义类、函数和调用的 AST 节点名称,即可添加对新语言的支持。
多模态摄取
URL 摄取(ingest.py)
ingest 模块将外部 URL 转换为可导入图的 Markdown 文件。根据 URL 类型使用专门的提取器:
-
arXiv (
_fetch_arxiv):提取论文的摘要、标题和作者 -
推文 (
_fetch_tweet):使用 oEmbed 提取推文文本和元数据 -
网页 (
_fetch_webpage):使用html2text将 HTML 转换为干净的 Markdown
音视频转录(transcribe.py)
该引擎使用 faster-whisper 对本地文件或 YouTube 链接进行高性能转录:
-
领域感知提示 :
build_whisper_prompt使用"上帝节点"(语料库顶层抽象)为 Whisper 提供技术语境提示,提高专业术语的识别准确率 -
URL 支持 :
download_audio使用yt-dlp获取音频流进行转录
验证与缓存
语义缓存(cache.py)
为确保增量更新期间的性能,Graphify 实现了基于 SHA256 的语义缓存:
-
存储位置 :缓存的提取结果存储在
graphify-out/cache/目录中,命名为{hash}.json -
Markdown 优化 :对于
.md文件,仅对正文内容进行哈希计算,忽略 YAML frontmatter 的变化,防止不必要的缓存失效 -
机制 :
load_cached在解析前检查文件哈希;若匹配,则从 JSON 缓存加载节点/边列表
模式强制(validate.py)
在图组装之前,所有提取字典都会针对核心模式进行验证:
-
节点必需字段 :
id、label、file_type、source_file -
边必需字段 :
source、target、relation、confidence、source_file -
置信度级别 :边被标记为
EXTRACTED(基于 AST)、INFERRED(调用图/启发式)或AMBIGUOUS(不明确)
提取模式
节点模式
| 字段 | 类型 | 描述 |
|---|---|---|
id |
str | 通过 _make_id 生成的稳定 ID |
label |
str | 人类可读的名称 |
file_type |
str | code、document、paper、image 或 rationale |
source_file |
str | 源文件的路径 |
边模式
| 字段 | 类型 | 描述 |
|---|---|---|
source |
str | 源节点的 ID |
target |
str | 目标节点的 ID |
relation |
str | 关系类型(如 contains、calls、inherits、imports) |
confidence |
str | EXTRACTED、INFERRED 或 AMBIGUOUS |
weight |
float | 边强度(提取的结构化边为 1.0) |
添加新语言提取器
要在 graphify/extract.py 中添加对新语言的支持,请遵循以下实现模式:
-
定义 LanguageConfig:创建一个配置实例,指定类、函数和调用的节点类型
-
实现提取器 :创建一个函数
extract_LANGUAGE(path: Path) -> dict,用于初始化解析器并调用通用的walk()辅助函数 -
处理导入 :如果该语言有独特的导入语法,实现自定义的
import_handler(参见_import_python或_import_js) -
注册扩展名 :更新
collect_files和主extract()分发器,以识别新的文件扩展名
2.3 图组装与聚类
该阶段将原始的提取字典转换为结构化的 NetworkX 图,并应用社区检测算法将数据组织成有意义的聚类,从而弥合单个文件提取与整体可导航知识图谱之间的差距。
图组装
组装过程由 graphify/build.py 处理。它将多个提取输出(来自 graphify/extract.py)合并为一个统一的图结构,同时确保模式的完整性、保留关系方向并注入语义元数据。
实现细节
核心逻辑位于两个主要函数中:
-
build(extractions, *, directed=False):一个包装器,用于合并提取字典列表、累加 Token 计数并连接节点、边和超边列表。 -
build_from_json(extraction, *, directed=False):主要的构造函数,用于初始化networkx.DiGraph(如果启用有向)或networkx.Graph对象。
节点去重与优先级
系统通过三层解析策略处理重复实体:
-
文件级 :提取器使用
seen_ids集,确保每个文件中的节点 ID 最多发出一次。 -
跨文件 :
G.add_node()是幂等的。节点按提取顺序添加(AST 优先,然后是语义)。由于最后设置的属性获胜,语义节点会覆盖 AST 节点,确保更丰富的标签和跨文件上下文优先。 -
语义合并 :调用技能在构建图之前,使用基于
node["id"]的显式seen集来合并缓存结果与新的语义结果。
ID 归一化与标签注入
为处理 LLM 生成的 ID 与 AST 提取的 ID 之间的差异,Graphify 采用归一化策略:
-
_normalize_id:将字符串转换为仅包含小写字母数字的格式。 -
这使得当标点符号或大小写存在差异时(例如
Session_Validate与session_validate),边仍然能够存活。 -
deduplicate_by_label:合并共享归一化标签(通过norm_label)的节点,将所有边引用重写到"规范"节点(优先选择不带_c1等块后缀的 ID)。
边的有向性与超边
虽然结构聚类通常将图视为无向,但 Graphify 保留了关系原始的语义方向:
-
方向保留 :在
add_edge期间,source和target作为内部属性_src和_tgt存储,防止无向图在可视化过程中丢失流向(例如"A → references → B")。 -
超边 :组关系(例如涉及 5 个节点的"认证流程")存储在图全局元数据字典
G.graph["hyperedges"]中。
社区检测(聚类)
图组装完成后,graphify/cluster.py 使用 Leiden 算法 将节点划分为社区,为"社区文章"和最终报告提供组织骨架。
Leiden 处理流程
系统优先尝试使用 graspologic.partition.leiden 进行高质量聚类,必要时回退到 networkx.community.louvain_communities。
| 功能 | 实现逻辑 |
|---|---|
| 孤立节点处理 | 度数为 0 的节点被单独检测,并分配到各自单节点社区 |
| 超大社区分割 | 超过图大小 25%(至少 10 个节点)的社区,通过在子图上进行第二轮 Leiden 递归分割 |
| 稳定性 | 社区 ID 按大小(降序)重新索引,确保社区 0 始终是最大的聚类 |
| 输出安全 | 抑制 graspologic 的输出,防止 ANSI 转义序列破坏 Windows PowerShell 缓冲区 |
凝聚度评分
对于检测到的每个社区,Graphify 计算凝聚度评分(Cohesion Score)。这是实际社区内边数与最大可能边数(n(n-1)/2)的比率。
-
1.0:表示一个"团"(clique)或单节点社区。
-
低分:表示一个松散的聚类,可能代表一个宽泛的类别或噪声。
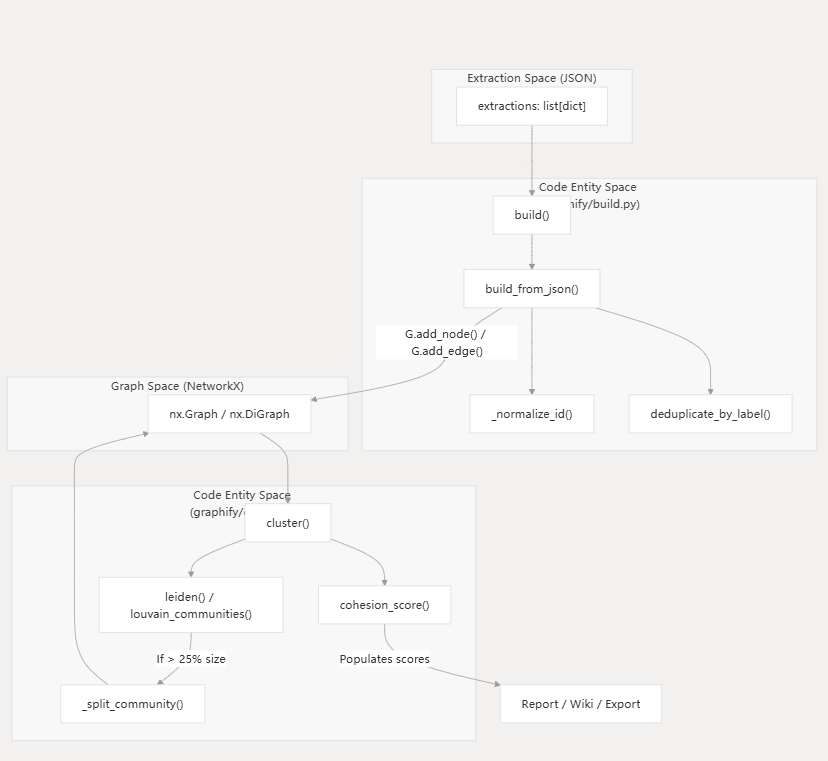
数据流:从提取到图谱
以下示意图说明了提取引擎的原始 JSON 数据如何被构建和聚类模块处理,以生成最终的 nx.Graph。
流程:从提取到聚类
与可视化的集成2
组装和聚类结果直接被 to_html 等导出函数(位于 graphify/export.py)使用。
可视化逻辑
-
社区颜色 :节点根据社区 ID 从
COMMUNITY_COLORS分配颜色。 -
超边渲染 :如果存在超边,
_hyperedge_script会生成 Vis.js 脚本,在参与节点周围绘制阴影区域(凸包)。 -
节点大小:节点大小根据其在图中的度(degree)决定,以突出中心实体。
系统组件映射
以下示意图将高层系统职责映射到具体函数和类。

2.4 图分析
图分析阶段将原始的 NetworkX 图转化为可操作的架构洞察。通过应用结构启发式和社区感知算法,它能识别最重要的实体、发现跨不同源类型之间的非显而易见关系,并为人工或智能体探索提供高价值的入口点建议。
分析引擎核心逻辑
分析引擎位于 graphify/analyze.py 中,作用于组装和聚类阶段生成的 nx.Graph。其核心关注点包括识别"上帝节点"(中心枢纽)、"意外连接"(跨边界边),并为增量更新提供差异分析。
上帝节点识别
god_nodes 函数通过按度中心性(节点总连接数)对节点进行排序,来识别代码库的核心抽象。
为确保结果代表有意义的架构实体而非结构工件,算法通过 _is_file_node 和 _is_concept_node 应用了严格的过滤流程:
| 过滤的实体类型 | 识别信号 | 排除原因 |
|---|---|---|
| 文件级中心节点 | 标签匹配源文件名 | 这些节点积累的是机械性的导入和包含边,并非逻辑抽象 |
| 方法桩(Method Stubs) | 标签以 . 开头并以 () 结尾 |
AST 提取的方法是类的子节点;类本身才应成为上帝节点 |
| 孤立函数 | 标签以 () 结尾且度 ≤ 1 |
结构孤立的函数不构成中心枢纽 |
| 概念节点 | source_file 为空或无文件扩展名 |
手动注入或推断的语义标签是有意为之,而非被发现的結構性枢纽 |
意外连接与评分
surprising_connections 函数检测能够连接系统中距离较远部分的边。其策略取决于语料库是多源还是单源:
-
跨文件与跨社区策略
-
多文件语料库 :使用
_cross_file_surprises寻找连接不同文件的边,并按综合异常分数(Surprise Score)排序。 -
单文件语料库 :使用
_cross_community_surprises识别具有高中介中心性且连接由 Leiden 检测出的不同社区的边。
-
异常评分算法
对于多文件图,每条跨文件边都通过 _surprise_score 进行评估,分数基于结构信号聚合得出:
| 信号 | 分数加成 | 理由 |
|---|---|---|
| 置信度(Confidence) | +3(不明确)、+2(推断) | 源代码中未明确表述的连接(例如通过 LLM 推断得出)更值得关注 |
| 跨类型(Cross-Type) | +2 | 代码实体与论文(PDF)或图像之间的连接高度不显而易见 |
| 跨仓库(Cross-Repo) | +2 | 不同顶级目录或仓库之间的连接 |
| 跨社区(Cross-Community) | +1 | Leiden 算法将节点放置在不同社区之间的桥梁连接 |
| 语义相似性(Semantic Similarity) | ×1.5 乘数 | 没有结构基础的非显而易见概念连接得分更高 |
| 外围到中心节点(Peripheral-to-Hub) | +1 | 一个度 ≤ 2 的节点直接连接到度 ≥ 5 的中心节点 |
增量分析:图谱差异
为支持 --update 模式和文件监听,graph_diff 会比较前一图谱状态与新图谱状态,总结变更内容。
数据流:从代码到差异洞察
下图说明了代码实体空间(文件和 AST 节点)中的变化如何转化为分析空间(差异摘要)。
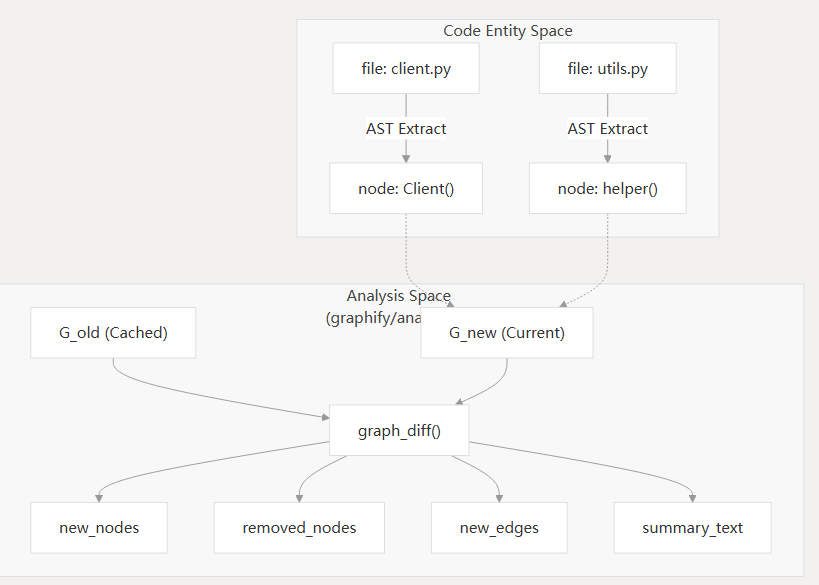
问题建议启发式
suggest_questions 函数生成自然语言提示,引导用户关注图谱中尚未充分探索或复杂的领域。它使用三种主要启发式:
-
中心节点探索 :针对上帝节点生成探索问题(例如:"
Client类如何在它的 15 个连接实体之间进行协调?") -
意外连接调查 :针对高得分异常连接生成调查问题(例如:"为什么
auth.py与README.md存在推断连接?") -
架构追问:基于图谱结构引导用户深入理解设计决策和系统边界
📦 输出内容
执行 Graphify 后,graphify-out/ 文件夹中会生成以下输出:
| 输出文件 | 描述 |
|---|---|
graph.html |
交互式、可点击的知识图谱可视化,支持筛选搜索和社区查找 |
GRAPH_REPORT.md |
纯语言摘要报告,包含上帝节点、发现的意外连接,以及由此产生的建议问题 |
graph.json |
可持久化的图数据文件,兼容 NetworkX node_link_data 模式 |
⚙️ 技术要点速览
| 技术点 | 说明 |
|---|---|
| 图分析算法 | 度中心性(Degree Centrality)、中介中心性(Betweenness Centrality) |
| 节点过滤 | 排除文件级节点、方法桩、孤立函数,保留语义概念节点 |
| 异常评分 | 综合置信度、跨类型、跨仓库、跨社区等多维度信号进行加权评分 |
| 增量更新 | 支持 --update 模式,仅处理变更文件 |
| 输出格式 | HTML 交互图谱 + Markdown 分析报告 + JSON 数据 |
更多关于分析阶段的技术细节,可参考 Graphify 源码分析(CSDN) 和 Pyshine 技术评测。
2.5 报告生成
graphify/report.py 模块负责将分析管道的各类输出整合成一个易读的 Markdown 文件:GRAPH_REPORT.md。这份报告既是审计追踪记录,也是知识图谱结构的执行摘要,清晰展示了核心抽象、非显而易见的关系以及代码或文档中可能存在的空白。
generate() 函数概述
generate() 函数是报告生成的入口点,它综合了来自先前所有检测、聚类与分析阶段的数据来组装最终的报告文档。
报告数据聚合流程
下面的图例说明了最终报告字符串中,不同来源的数据是如何被聚合起来的:
图示:报告数据聚合
报告章节
生成的 GRAPH_REPORT.md 报告包含以下几个关键部分:
1. 语料库检查与摘要
该部分评估当前语料库是否足够大,以至于能从图谱分析中获得价值。提供的高级统计信息包括:
-
节点/边数量:图谱的总规模
-
社区数量:Leiden 算法检测到的集群数
-
置信度分析:
-
EXTRACTED(已提取)结构边占比 -
INFERRED(推断)LLM 推断边占比 -
AMBIGUOUS(不明确)低置信度边占比
-
-
Token 消耗:提取和分析阶段消耗的总输入/输出 Token
-
推断边平均置信度(如有)
2. 社区枢纽(导航)
为防止报告成为一个"死胡同",generate() 会自动生成指向 _COMMUNITY_*.md 文件的 Wiki 链接。这确保通过 Obsidian 或 Wiki 浏览的用户可以直接从审计报告跳转到特定社区的深入分析文档。
_safe_community_name 辅助函数确保文件名已正确清理,且与导出逻辑保持一致。
3. 上帝节点与意外连接
-
上帝节点 :列出
analyze.god_nodes识别出的连接数最多的节点,代表系统的核心抽象。 -
意外连接:展示跨文件或跨社区边界的关系,包括关系类型、涉及的原文件、置信度及其置信度评分、以及分析期间生成的任何解释性说明。语义相似关系会有特殊标记。
4. 超边
如果图谱包含组关系(超边),这些关系会被列出,包含成员节点、标签及其置信度评分。
5. 社区
对于检测到的每个社区,报告会提供以下信息:
-
社区标签(由 Leiden 算法自动生成或人工指定的描述性名称)
-
凝聚度评分(社区的密集程度,范围 0.0 到 1.0)
-
代表性节点列表(最多 8 个,展示社区内容)
在显示社区节点时,report.py 会自动过滤方法/函数桩等仅作为结构噪音的节点,只保留真正有意义的实体。
6. 不明确边(需审阅)
置信度为 AMBIGUOUS 的边会被单独列出,包含源标签、目标标签、源文件路径及关系类型。这些边表明提取结果不确定性高,需要人工审阅。
7. 知识空白
基于提取结果,报告自动识别潜在的知识空白:
-
孤立节点(度 ≤ 1 且不是文件节点或概念节点):这些节点只有一个连接或没有连接,表示可能存在缺失的边或未记录的组件
-
薄弱社区(节点数 < 3 的社区):太小而无法成为有意义的集群,可能是噪音或需要提取更多连接
-
高不明确性警告 :当超过 20% 的边为
AMBIGUOUS时,提示用户审阅不明确边部分
8. 建议问题
基于分析结果,报告自动生成自然语言提示,引导用户聚焦图谱中尚未充分探索或复杂的领域。问题会附上"为什么这个图特别适合回答此问题"的说明,问题不足时将显示无信号提示。
关键函数速查
| 函数 | 位置 | 功能描述 |
|---|---|---|
generate |
report.py#L15 |
主要的报告生成器,消耗几乎所有前置阶段的输出 |
_safe_community_name |
report.py#L8-L12 |
清理社区名称,确保其符合文件命名规范 |
| 置信度统计 | report.py#L9-L16 |
对 EXTRACTED、INFERRED 和 AMBIGUOUS 标签进行分类 |
_is_file_node |
analyze.py |
用于过滤文件级节点,此类节点被认为是结构噪音而非逻辑抽象 |
Token 成本节约
Graphify 生成的 graph.json 与 GRAPH_REPORT.md 非常精简,每次查询所需的 Token 数可比直接读取原始文件最高减少 71.5 倍。SHA256 缓存机制确保更新时仅重新处理变更过的文件。
性能数据方面,在一个包含代码库、5 篇论文和 4 张图片在内的 52 个混合文件语料的测试中,平均查询成本从约 123K tokens 降至约 1.7K tokens。
输出文件
执行 Graphify 后,graphify-out/ 文件夹会生成以下主要输出:
| 输出文件 | 描述 |
|---|---|
GRAPH_REPORT.md |
核心输出。AI 助手的结构化导航入口,提供知识图谱的纯语言总结 |
graph.html |
交互式图谱可视化,可在浏览器中点击探索 |
graph.json |
可持久化的图数据文件,兼容 NetworkX node_link_data 模式 |
cache/ |
语义缓存目录,用于增量更新 |
wiki/ |
(可选)社区 Wiki 页面 |
注意事项
实际使用中,GRAPH_REPORT.md 的内容质量直接决定了 Token 压缩是否有效 。有用户反馈,在部分项目中 GRAPH_REPORT.md 生成了空白报告------Graphify 的核心集成路径在实际运行中可能失效,而官方文档对这种情况几乎只字不提。建议在使用前对目标项目进行充分测试。
本回答由 AI 生成,内容仅供参考,请仔细甄别。
三、 导出与可视化
Graphify 管线的最后阶段是导出,将内部的 NetworkX 图与社区结构转化为多种人类可读和机器可互操作的格式。这些导出旨在支持交互式探索、深度知识管理以及与图数据库(如 Neo4j)的集成。
数据流概览
导出函数主要消费由 build_from_json 函数装配的 networkx.Graph 对象。该图即使处于无向模式下,也会保留边方向信息(通过 _src 和 _tgt 属性存储),以确保显示准确性。元数据(如社区标签 community_labels、"上帝节点"列表 god_node_list、超边 hyperedges 等)会被提取并传递给导出函数,以丰富输出内容。
交互式可视化
Graphify 提供了两种主要方式来可视化图结构:静态和交互式。
HTML 可视化
-
使用 vis.js 创建基于浏览器的交互式图谱。
-
采用力导向布局引擎(forceAtlas2Based)实现节点位置动态计算与平滑探索。
-
基于内置的
COMMUNITY_COLORS调色板按社区着色,不同社区采用不同颜色标识。 -
提供可搜索的侧边栏面板,支持按节点名称/标签进行筛选查找。
-
支持超边(Hyperedges)的可视化:通过凸包扩展算法(convex hull expansion)将构成超边的节点组所占据的区域用半透明阴影面片渲染,以直观表达组关系。
SVG 导出
- 使用 matplotlib 生成静态矢量图形,适用于快速预览或嵌入文档。
性能限制
为保证可视化性能,交互式图谱有节点数量限制:MAX_NODES_FOR_VIZ 设置为 5,000 个节点,超出此上限的图谱将跳过 HTML 导出,以避免浏览器渲染崩溃。
错误处理
在 v0.4.23 版本中,引入了一项修复:当图超过节点限制时,to_html 会优雅失败(即跳过交互式 HTML 导出,但不影响整体处理流程),避免整个 _rebuild_code 管线崩溃。
知识管理
Obsidian 知识库选择
-
生成一个 Markdown 文件夹:每个节点成为一个独立文件,用于长期存储和浏览提取的知识。
-
使用
to_obsidian在实体之间创建[[wikilink]]格式的链接,使知识库内的笔记可以相互索引和跳转。 -
使用
to_canvas生成图谱的 2D 画布文件,在 Obsidian 中提供图形化的节点布局概览。
Wiki 导出
-
to_wiki函数(在 v0.4.14 版本中添加)生成 类 Wikipedia 风格的互联文章集合。 -
它会创建一个
index.md作为入口文件,接着为每个社区和每个"上帝节点"生成详细文章。 -
使用
_safe_filename函数确保文件名在不同操作系统(Windows/Linux/macOS)之间兼容。
机器互操作性
为支持高级图查询(如 Cypher)或与 Gephi 等外部工具集成,Graphify 支持多种标准图交换格式:
| 格式 | 函数 | 用途 |
|---|---|---|
| JSON | to_json |
标准的 node_link_data 格式输出,用于 Web 集成或程序化处理 |
| GraphML | to_graphml |
XML 格式,可直接在 Gephi、yEd、Cytoscape 等外部图工具中打开 |
| Cypher | to_cypher |
输出批量的 MERGE 语句,支持手动导入 Neo4j 数据源 |
| Neo4j | push_to_neo4j |
通过 Neo4j Python 驱动将图谱内容直接注入 / 写入 Neo4j 数据库,无需手动执行 Cypher |
节点 ID 协调
build_from_json 函数能够协调不同来源的节点 ID:即使 LLM 生成的 ID 在大小写或标点符号上与 AST 提取器生成的 ID 存在差异,边关系(edges)仍然能够正确保留。
导出净化
为确保导出的数据在不同操作系统和 Web 环境下安全、兼容,Graphify 采用了几种净化处理函数,用于在技术标识符与安全的文件系统/Web 表示之间建立桥梁:
| 函数 | 功能 |
|---|---|
_normalize_id |
将字符串去除非字母数字符号,统一转换为小写字母 + 数字 + 下划线,用于内部 ID 的一致性匹配 |
sanitize_label |
剥离控制字符并转义 HTML 特殊字符,用于防止 Web 导出时的 XSS 跨站脚本攻击 |
_strip_diacritics |
将 Unicode 字符进行 NFKD(标准分解形式)+ 音调符号剥离,实现不同操作系统之间的文件名安全性和全局匹配一致性 |
如需继续翻译后续章节(如 4.1 CLI Commands),请随时告知。
3.1 HTML 与 SVG 可视化
Graphify 提供了两种主要的可视化导出格式:基于 vis.js 构建的交互式 HTML 仪表板和通过 matplotlib 生成的静态 SVG 渲染图。这些可视化让用户能够直观地探索图谱中的结构关系、社区聚类以及节点层面的元数据信息。
交互式 HTML 导出(to_html)
to_html 函数会生成一个可直接在浏览器中打开的 HTML 文件,包含可搜索、可筛选和可交互的知识图谱。它使用 vis.js 库进行渲染,并配有用于元数据检查的自定义侧边栏。
可视化约束与性能限制
为确保浏览器渲染性能,可视化功能通过 MAX_NODES_FOR_VIZ 常量设置了严格的硬性限制:最大节点数不得超过 5,000 。从 v0.4.23 版本开始,如果图谱超出此限制,to_html 会直接抛出 ValueError,避免生成无法使用的文件。
节点的大小会根据其度(degree)动态调整,计算公式为:15 + (√G.degree(node_id) × 5),最大值限制为 45。
样式与脚本架构
为了降低代码的维护复杂性,HTML 生成逻辑被拆分为三个独立模块:
| 模块 | 功能 | 行号参考 |
|---|---|---|
_html_styles() |
定义 CSS 样式:深色主题背景(#0f0f1a)、侧边栏布局以及搜索结果样式 |
L28-L58 |
_html_script() |
注入核心 JavaScript 逻辑:vis.DataSet 初始化、搜索功能和节点聚焦处理器 |
L104-L183 |
_hyperedge_script() |
注入超边渲染逻辑:通过 HTML5 Canvas API 将超边渲染为半透明凸包阴影区域 | L61-L101 |
物理引擎与交互功能
交互式图谱采用 forceAtlas2Based 作为其物理引擎求解器。为优化资源占用,图结构稳定后物理动画会自动禁用。
主要交互功能包括:
-
实时搜索:按标签名称过滤节点
-
社区图例:可点击的图例,支持高亮或淡化特定社区
-
信息面板 :点击节点后,侧边栏自动填充
source_file、file_type和度统计信息
数据结构与流程图
下方示意图展示了内部图谱数据如何转换为交互式 HTML 组件的过程。
图示:HTML 可视化数据流
静态 SVG 导出(to_svg)
to_svg 函数为文档撰写或快速预览提供了静态替代方案。它借助 matplotlib 和 NetworkX 内置的布局引擎生成矢量图。
实现细节
| 配置项 | 实现方式 | 行号参考 |
|---|---|---|
| 布局算法 | 使用 nx.spring_layout 进行节点定位 |
L284 |
| 着色方案 | 根据节点所属社区 ID,从 COMMUNITY_COLORS 调色板中分配颜色 |
L20-L23,L287 |
| 标签显示 | 为保持密集图谱的可读性,仅对度高于特定阈值或被标记为"上帝节点"的节点显示标签 | L291-L294 |
可视化逻辑映射
下方示意图将高层可视化概念映射到具体的实现常量和函数。
图示:可视化逻辑桥接
导出函数对比
| 函数 | 输出格式 | 核心库 | 关键特性 |
|---|---|---|---|
to_html |
.html |
vis.js | 交互式、支持搜索、社区过滤、物理引擎 |
to_svg |
.svg |
matplotlib | 静态、矢量格式、基于度的大小缩放 |
安全与清理机制
在任何节点标签或元数据写入 HTML 或 SVG 输出之前,系统都会通过 sanitize_label 函数进行清理处理。该函数会剥离控制字符,并限制标签长度不超过 256 个字符。
在 to_html 的 JavaScript 负载中,系统还额外使用了 esc() 辅助函数,防止在向 DOM 的 innerHTML 注入数据时发生 XSS 跨站脚本攻击
3.2 Obsidian 知识库与画布导出
Obsidian 导出子系统会将分析生成的图谱转换为一个功能完备的 Obsidian 知识库。这套工具支持用户通过基于 Markdown 的本地化界面来浏览提取出的知识内容,具体包括:为每个节点生成带 YAML 前置元数据的 Markdown 文件、社区级别的概览页面、自动生成的 Dataview 查询语句,以及通过 Obsidian Canvas 格式提供的可视化呈现。
导出机制概述
导出过程主要由 graphify/export.py 中的两个函数完成:
| 函数 | 功能描述 | 源码参考 |
|---|---|---|
to_obsidian |
生成目录结构,图谱中的每个节点会对应生成一个带 YAML 前置元数据的 .md 文件 |
L330-L459 |
to_canvas |
生成一个 .canvas JSON 文件,使用基于网格的布局算法在 Obsidian 内部对节点及其关系进行可视化 |
L461-L518 |
数据流:从图谱到知识库
下方示意图展示了从内部 NetworkX 图结构到 Obsidian 知识库物理文件结构的转换过程。
(图示部分已省略)
to_obsidian 导出详解
to_obsidian 函数会创建一个结构化的知识库,既便于人类阅读,也方便自动化工具(Agent)进行遍历抓取。
1. 节点清理与 Wiki 链接
为了确保与文件系统及 Obsidian 内部链接机制的兼容性,节点名称会经过一个清理正则表达式的处理,将 /、\、: 等字符替换为下划线 _。系统还会使用 _strip_diacritics 对字符进行归一化处理,以保证文件名的跨平台安全性。所有内部链接均使用标准的 [[Wikilink]] 语法,方便 Obsidian 解析文件之间的连接关系。
*来源:graphify/export.py#L14-L17, L335-L338, L403-L408*
2. 文件结构与前置元数据
每个节点会被导出为一个 Markdown 文件,其中包含:
-
YAML 前置元数据 :包括
type、source_file、community和degree等元数据字段。 -
关系列表 :按关系类型(如
calls、inherits、defines)分类的入边和出边列表。 -
Dataview 集成:如果用户安装了 Dataview 插件,会自动注入查询语句,动态列出相邻节点。
*来源:graphify/export.py#L387-L393, L397-L410, L415-L420*
3. 社区笔记与桥接节点
-
社区笔记 :针对
cluster.py中 Leiden 算法识别出的每个社区,系统会创建一个独立的笔记文件(例如Community 1.md),列出社区内所有成员节点,并在可用时提供该社区的高层摘要信息。 -
桥接节点:能够连接多个社区的节点会被标记为"桥接节点"(Bridge Nodes),以此突出显示架构层面的耦合关系。
*来源:graphify/export.py#L435-L445, L448-L450*
4. 图谱视图配置
导出过程会自动生成 .obsidian/graph.json 配置文件。该文件会使用 COMMUNITY_COLORS 调色板,根据节点所属的社区 ID 对 Obsidian 原生图谱视图中的节点进行颜色编码。
*来源:graphify/export.py#L20-L23, L452-L458*
to_canvas 导出详解
to_canvas 函数会创建一个 Obsidian Canvas(.canvas)文件,为图谱提供空间布局视图。
实现逻辑
Canvas 导出采用基于网格的定位系统来避免节点重叠,具体技术细节如下:
| 特性 | 实现细节 |
|---|---|
| 布局算法 | 节点被放置在一个网格中。网格宽度通过总节点数的平方根计算得出:int(math.sqrt(len(G))) + 1 |
| 节点表示 | Canvas JSON 中的每个节点都被表示为一个文件类型的卡片,指向其对应的 .md 文件 |
| 边数量限制 | 为了保证 Obsidian 界面中的性能表现,强制设定了 200 条边 的硬性上限,只有前 200 条边会被导出到画布中 |
| 颜色映射 | Canvas 节点会根据其所属的社区 ID 分配颜色(1-6),以匹配知识库的整体视觉主题 |
| 路径安全性 | Canvas 中的文件路径均以知识库根目录为基准的相对路径(例如 filename.md),而非绝对路径 |
*来源:graphify/export.py#L465-L467, L472-L474, L476-L480, L482-L490;tests/test_export.py#L141-L154*
Canvas 生成示意图
(图示部分已省略)
技术参考:关键函数
_strip_diacritics(text: str) -> str
该函数定义在 graphify/export.py 中。它将 Unicode 文本归一化为 NFKD 形式,并移除组合字符,以确保文件名在不同操作系统之间具有良好的兼容性。
*来源:graphify/export.py#L14-L17*
to_obsidian(G, communities, path, ...)
这是知识库生成的主入口函数,定义在 graphify/export.py 中。其核心操作包括:
-
遍历
G.nodes(data=True)中的所有节点 -
按边类型对相邻节点进行分组
-
使用
Path(path).mkdir(parents=True, exist_ok=True)写入 Markdown 文件内容
*来源:graphify/export.py#L341-L343, L383, L397-L400*
to_canvas(G, communities, path)
这是 Canvas 生成的主入口函数,定义在 graphify/export.py 中。其核心操作包括:
-
对节点进行过滤,确保它们存在于图中
-
使用取模运算,将社区整数值映射到 Obsidian 的 1-6 颜色范围
-
将结果序列化为一个扩展名为
.canvas的 JSON 文件
3.3 Wiki 导出
Wiki 导出模块(graphify/wiki.py)提供了一种将结构化知识图谱转换为类维基百科风格文档集的机制。该模块生成的 Markdown 文章集专门设计为可供 LLM Agent 通过内部 wiki 链接([[Article Name]])进行"爬取",以理解代码库的架构。
概览与数据流
该子系统的核心入口点是 to_wiki 函数,它接收一个 NetworkX 图对象和社区元数据,输出一个包含 .md 文件的目录。
导出过程生成三种不同类型的 Markdown 文件:
| 文件类型 | 用途 | 命名规则 |
|---|---|---|
| 索引(Index) | 入口点,列出所有社区和重要节点 | index.md |
| 社区文章(Community Article) | Leiden 社区的高层概览 | 社区名称.md |
| 重要节点文章(God Node Article) | 对高中心度节点的深度剖析 | 节点名称.md |
数据流:从图谱到 Wiki
(图示部分已省略)
社区文章
社区文章提供一个相关节点聚类的主题概览,包含以下组件:
组件说明
| 组件 | 内容 | 代码来源 |
|---|---|---|
| 元数据表头 | 显示节点数量和凝聚度评分(在聚类阶段计算) | wiki.py#L49-L52 |
| 核心概念 | 按度数(连接数)排序,列出社区中前 25 个节点 | wiki.py#L33-L65 |
| 跨社区链接 | 使用 _cross_community_links 辅助函数,识别与其他社区的关系 |
wiki.py#L13-L22, 68-L73 |
| 审计追踪 | 社区内边置信度(EXTRACTED, INFERRED, AMBIGUOUS)的统计分布 | wiki.py#L81-L86 |
如果一个社区超过 25 个节点,会自动添加截断提示。
重要节点文章
"重要节点"(God nodes)是代码库中承载核心抽象的节点(度数最高的节点)。它们的文章提供了其在系统中角色与作用的细粒度视图。
邻居分组
与社区文章列出节点的方式不同,重要节点文章会按关系类型 (如 calls、references、contains)对邻居进行分组。
-
排序逻辑:邻居节点按自身的度数排序,确保最重要的相关内容排在前面。
-
置信度标签 :每个关系都标注了提取置信度,格式如
[[OtherNode]] (EXTRACTED),便于审计。 -
社区上下文:文章明确链接到该重要节点所属的社区。
markdown
# 重要节点文章示例结构
- 该节点所属的社区链接
- **calls** 关系组(按被调用节点度数排序):
- [[HighImportanceNode]] (EXTRACTED)
- [[MediumImportanceNode]] (INFERRED)
- **contains** 关系组
- ...实现细节
文件名清理
为确保跨操作系统兼容并防止路径遍历攻击,_safe_filename 函数会对节点和社区标签进行清理:
| 字符 | 替换方式 | 目的 |
|---|---|---|
| 空格 | 转换为下划线 (_) |
提高 URL 友好性 |
斜杠 (/) 和冒号 (:) |
转换为短划线 (-) |
防止路径穿越 |
导航与可爬取性
每个生成的 Markdown 文章底部都包含一个返回 index.md 的页脚链接。
索引文件本身按以下规则排序:
-
社区:按规模(大小)降序排列,最大的社区排在最前
-
重要节点:按边数(度数)降序排列
这种分层结构可引导 LLM Agent 从宏观架构概览逐步深入到具体的实现细节。
性能限制与截断
为防止 token 消耗失控,Wiki 导出设置了多重截断策略:
| 限制项 | 上限 | 代码来源 |
|---|---|---|
| 社区文章节点列表 | 25 项 | wiki.py#L33 |
| 社区文章关系列表 | 12 条 | wiki.py#L69 |
| 重要节点文章每类关系 | 20 个连接 | wiki.py#L120 |
降级处理
为确保导出过程的稳健性,模块实现了多项安全降级:
| 场景 | 处理方式 | 代码来源 |
|---|---|---|
| 元数据中的重要节点 ID 在图谱中不存在 | 静默跳过,防止导出崩溃 | wiki.py#L203-L207 |
| 未提供社区标签 | 默认命名文章为 Community_N.md |
wiki.py#L188 |
总结
Wiki 导出模块的核心价值在于:
-
Agent 可爬取:通过标准 wiki 链接格式,LLM Agent 可以像人类浏览文档一样遍历代码架构
-
分层导航:从索引 → 社区 → 重要节点 → 具体邻居,支持不同粒度的信息获取
-
审计友好:每个关系都保留置信度标签,便于追溯边来源
-
资源可控:多重截断策略确保导出内容不会超出 LLM 上下文限制
4. 接口与集成
本页概述了用户和外部系统与 graphify 交互的方式。该系统设计为接口无关,通过命令行接口(CLI)支持直接的人机交互,通过模型上下文协议(MCP)支持自动化的智能体工作流,通过文件监听器支持后台同步,并通过自定义技能和 Git 钩子与 AI 编码助手深度集成。
交互概览
graphify 在原始文件系统数据和结构化知识之间架起桥梁。下图展示了各种接口如何与核心逻辑及生成的 graphify-out/ 产物进行交互。
系统接口映射
(图示部分已省略)
CLI 参考
主要入口点是 graphify 命令,由 graphify/__main__.py 管理。它通过将专门的技能清单复制到相应的配置目录,处理在 13 多个平台(包括 Claude、Cursor 和 Kiro)上的安装。
-
安装 :
graphify install [platform]注册该工具,并设置CLAUDE.md或AGENTS.md指令 -
执行 :支持完整流水线运行、增量更新(
--update),以及--cluster-only或--deep等专用模式 -
子命令 :包括用于 URL 提取的
add、用于 BFS/DFS 遍历的query,以及用于 Git 集成的hook
有关完整的标志和子命令列表,请参见 CLI 参考。
MCP 服务器(serve.py)
graphify 包含一个模型上下文协议(MCP)服务器,允许 LLM 使用标准化工具集以编程方式浏览图谱。这对于需要在无需读取整个 GRAPH_REPORT.md 的情况下探索关系的智能体特别有用。
-
核心工具 :
query_graph、get_node、get_neighbors、get_community、god_nodes和shortest_path -
搜索 :使用
norm_label进行 Unicode 安全、不区分大小写的节点查找 -
约束:对工具输出强制执行 Token 预算,以防止上下文窗口溢出
有关工具定义和遍历逻辑的详细信息,请参见 MCP 服务器(serve.py)。
文件监听器(watch.py)
watch.py 模块提供后台监控以保持图谱同步。它使用"分叉"更新逻辑来平衡速度和成本。
-
即时重建:代码变更会触发基于 AST 的重建,这由于避免了 LLM API 调用而实现零成本
-
延迟更新:文档/图像变更(需要 LLM 积分)会被标记为待更新,提示用户手动运行
-
防抖:实现了防抖机制,以避免在活动输入会话期间过度重建
有关 watch() 流水线的详细信息,请参见 文件监听器(watch.py)。
Claude Code 技能集成
graphify 技能是一个清单,用于指导智能体如何调用流水线。它定义了 /graphify 触发器,并提供了多步执行计划。
-
持久化 :关系存储在
graphify-out/graph.json中,使上下文能够在会话之间保留 -
审计追踪 :该技能强调
EXTRACTED、INFERRED和AMBIGUOUS边类型,以提供代码库的"诚实"视图
技能到代码实体映射
该图将高层智能体指令映射到底层 Python 实现和配置。
(图示部分已省略)
有关平台特定清单的详细信息,请参见 Claude Code 技能集成。
Git 钩子集成(hooks.py)
为确保图谱永远不会偏离源内容,graphify 提供了自动化的 Git 钩子。
-
提交后/切换后:在提交或分支切换后自动触发结构更新,以保持图谱与源代码同步
-
Python 检测 :包含识别正确解释器(例如
uv、pipx或venv)的逻辑,以确保钩子在正确环境中运行
有关钩子安装和 _PYTHON_DETECT 逻辑的详细信息,请参见 Git 钩子集成.
Graphify CLI 参考
Graphify 的命令行接口(CLI)是与知识图谱交互的主要入口。它负责处理 Agent 技能的安装、流水线执行、图查询与导出等核心操作。
安装命令
安装命令用于将 Graphify 注册为 AI 编码助手的技能:
| 命令 | 说明 |
|---|---|
graphify install |
将 Graphify 注册为 Claude Code 或 Cursor 的技能 |
graphify install --platform codex |
为 Codex 平台注册技能 |
graphify cursor install |
为 Cursor 安装(与 graphify install 等效,别名形式) |
安装命令会执行以下操作:
-
技能部署 :将平台特定的技能文件(如
skill.md、skill-windows.md、skill-codex.md)从包中复制到助手的本地配置目录。 -
版本追踪 :在目标目录写入
.graphify_version文件,用于追踪更新并防止过时版本警告。 -
清单注册 :对于 Claude Code,向
~/.claude/CLAUDE.md追加注册块,以启用/graphify触发命令。 -
插件注入 :对于 OpenCode,安装特定插件并在
.opencode/opencode.json中注册。
支持平台
Graphify 支持 13+ 个 AI 编码助手平台,包括 Claude、Codex、OpenCode、Aider、Copilot、Claw、Droid、Trae、Trae-CN、Hermes、Kiro、Antigravity、Gemini、Cursor 等。
包名说明 :PyPI 上的安装包名为
graphifyy(因为graphify这个名字仍在回收中),但 CLI 命令仍然是graphify。
基准测试命令
graphify benchmark 通过比较使用知识图谱回答问题时所需的 Token 数量与朴素方式(读取整个原始语料库)的效率来评估知识图谱:
| 参数 | 说明 |
|---|---|
[graph_path] |
可选,指定图谱 JSON 文件的路径(默认为 graphify-out/graph.json) |
-
Token 估算:使用每 token 4 个字符的标准近似值。
-
指标:通过从匹配样本问题的节点进行 BFS 遍历,计算减少比率(reduction_ratio)。
-
BFS 遍历:从排名前 3 的匹配节点进行广度优先搜索(默认深度 = 3),构建代表性上下文窗口。
核心流水线标志
/graphify 命令是 AI 助手触发的主要入口点:
| 标志 | 说明 | 实现 |
|---|---|---|
--update |
增量更新。仅基于 SHA256 哈希重新提取变更文件 | 使用 graphify/cache.py 进行语义命中,使用 graphify/analyze.py 进行差异分析 |
--mode deep |
启用激进的推断边提取 | 在 LLM 提取期间扩展关系启发式 |
--cluster-only |
跳过提取,仅对现有图谱重新运行社区检测 | 调用 graphify/cluster.py 重新计算 Leiden 社区 |
--watch |
监控目录的变更 | 在 graphify/watch.py 中实现,带有防抖机制 |
--no-viz |
禁用 HTML/SVG 生成 | 跳过 graphify/export.py 中的可视化导出 |
--wiki |
生成类 Wikipedia 风格的 Markdown 知识库 | 调用 graphify/wiki.py:to_wiki |
--graphml |
导出 GraphML 格式,用于 Gephi 等外部工具 | 调用 graphify/export.py:to_graphml |
--budget |
限制输出为特定 Token 数量 | 将子图数据转移到下一个提示时至关重要 |
查询与分析命令
这些命令允许用户直接与构建好的图谱进行交互:
| 命令 | 说明 |
|---|---|
query "<问题>" |
使用自然语言在图谱中搜索相关概念 |
path |
使用 NetworkX 算法查找两个实体之间的最短路径 |
explain |
提供节点、其邻居及其社区上下文的详细摘要 |
add |
通过 ingest.py 摄取远程资源(arXiv、推文、网页)并将其合并到本地图谱中 |
save-result |
将当前图谱状态持久化到命名检查点 |
hook install |
安装 Git 钩子(post-commit/post-checkout)以保持图谱同步 |
图验证
在 CLI 或技能组装图谱之前,系统会验证提取的 JSON 以确保数据完整性:
-
必填字段 :节点必须有
id、label、file_type和source_file;边必须有source、target、relation、confidence和source_file。 -
强制检查 :
validate_extraction函数检查悬挂边(指向不存在节点 ID 的边)和无效的置信度级别(必须为 EXTRACTED、INFERRED 或 AMBIGUOUS)。
常用命令速查
| 操作 | 命令 |
|---|---|
| 基础安装 | pip install graphifyy && graphify install |
| 为 Cursor 安装 | graphify cursor install |
| 为 Codex 安装 | graphify install --platform codex |
| 运行 /graphify 技能 | 在 AI 助手中输入 /graphify |
| 查询知识图谱 | /graphify query "你的问题" |
| 路径查询 | /graphify path |
| 解释节点 | /graphify explain |
4.2 MCP 服务器(serve.py)
graphify/serve.py 模块实现了一个模型上下文协议(MCP)stdio 服务器。该服务器将处理完成的知识图谱以一组交互式工具的形式暴露给 AI 智能体(例如 Claude)。它允许智能体执行语义搜索、遍历关系并探索社区结构,而无需将整个图谱加载到其上下文窗口中。
架构与数据流
该服务器通过将 graph.json 文件(由组装流水线生成)加载到 networkx.Graph 对象中来运行。然后,它通过标准输入/输出(stdio)监听 JSON-RPC 请求。
一个专门的 _filter_blank_stdin 辅助函数用于防止由某些 MCP 客户端(如 Claude Desktop)发送的空行所导致的 Pydantic 验证错误;它安装了一个操作系统级别的管道来中继 stdin,同时丢弃空行。
数据流程图
该图显示了智能体的自然语言请求如何通过 serve.py 工具集被转换为图操作。
(图示部分已省略)
数据流:从内部图到工具输出
此图说明了从内部 networkx.Graph 结构到可供 LLM 使用的工具输出的转换过程。
(图示部分已省略)
核心组件
1. 图加载与安全性
服务器使用 _load_graph 初始化内存中的图表示,解析路径并验证其是否为 .json 文件。它依赖于组装流水线已将图放置在 graphify-out/ 目录中。
安全性由 _subgraph_to_text 强制执行,它使用来自 graphify/security.py 的 sanitize_label 来剥离控制字符,并防止输出在 UI 中渲染时出现提示注入或跨站脚本攻击(XSS)。
2. 搜索与评分
当智能体使用 query_graph 时,服务器使用以下方法执行搜索:
-
关键词评分 :
_score_nodes计算相关性得分。它在norm_label(或label)中匹配时给予 1.0 分,在source_file路径中匹配时给予 0.5 分。 -
Unicode 归一化 :
_strip_diacritics通过归一化为 NFKD 并去除组合字符,确保搜索对变音符号不敏感。 -
遍历 :从得分最高的节点开始,服务器执行广度优先搜索(BFS) 以获取广泛的上下文,或执行**深度优先搜索(DFS)**以追踪特定的逻辑链。
3. Token 预算强制执行
为防止上下文窗口溢出,_subgraph_to_text 在强制执行 token_budget 的同时,将发现的节点和边转换为文本格式:
-
启发式规则 :假设大约每 3 个字符对应 1 个 token(
char_budget = token_budget * 3)。 -
优先级排序 :节点按其**度(连通性)**进行排序,以确保中心抽象在外围细节之前被包含。
-
截断:如果输出超出预算,将被硬截断并附加警告。
可用工具
服务器向 MCP 客户端公开以下工具:
| 工具名称 | 用途 | 关键参数 |
|---|---|---|
query_graph |
使用 BFS/DFS 遍历搜索图谱。返回相关节点/边 | question, mode (bfs/dfs), depth, token_budget |
get_node |
检索特定节点的完整元数据 | label (ID 或 Label) |
get_neighbors |
列出直接邻居和边关系 | label, relation_filter |
get_community |
列出属于特定 Leiden 集群的所有节点 | community_id |
god_nodes |
识别连接最紧密的"中心枢纽"节点 | top_n |
graph_stats |
节点/边数量的摘要和社区分布 | N/A |
shortest_path |
查找两个特定实体之间的逻辑路径 | start_label, end_label |
实现细节:遍历逻辑
遍历函数弥合了用户意图与底层 networkx 图结构之间的差距:
-
_bfs:使用基于前沿的方法逐层探索。 -
_dfs:使用堆栈追踪深层路径。
遍历与序列化逻辑图
该图显示了 BFS/DFS 遍历以及子图序列化的内部逻辑流程。
(图示部分已省略)
使用与启动
服务器通常通过 CLI 使用 serve 命令启动,但也可以通过 serve() 函数以编程方式调用:
python
from graphify.serve import serve
# 启动 stdio 服务器,寻找默认图路径
serve(graph_path="graphify-out/graph.json")要求:
-
必须安装
mcpPython 包(pip install graphifyy[mcp])。 -
目标目录中必须存在有效的
graph.json文件。
与 MCP 框架的兼容性
服务器遵循 MCP 框架,这是一个开放标准,它为 AI 智能体访问外部工具和资源提供了一个标准接口。该框架支持多种传输机制,每种机制都针对不同的集成场景进行了优化(见 deepwiki-mcp 架构中的示例)。Graphify 的实现通过 stdio 进行通信,确保了与 Claude Code、Windsurf 以及其他任何 MCP 兼容客户端的即插即用兼容性。
💎 总结:为什么这很重要
MCP 服务器集成是 Graphify 的一个关键功能:
-
结构化访问 :智能体不再需要处理原始的
GRAPH_REPORT.mdMarkdown 文本,而是可以通过工具直接查询图谱的拓扑结构。 -
Token 效率:BFS/DFS 遍历和 Token 预算强制执行确保了即使在大型代码库中,智能体每次对话的成本也能得到控制。
-
自主基础设施 :随着 MCP 在 AI 编码助手中的普及,Graphify 将代码库图谱作为一组 LLM 可调用工具暴露出来的能力,使其成为了自主智能体理解代码库结构化知识的基础设施层。
4.3 文件监听器(watch.py)
graphify/watch.py 模块提供了一个后台监听服务,能够随着底层语料库的变化自动同步知识图谱。它采用二分更新逻辑来最小化 LLM 成本:代码变更触发即时、确定性的 AST 重建,而语义变更(文档、论文、图像)则通知用户需要进行基于 LLM 的更新。
watch() 概览
watch() 函数是文件监听服务的入口点。它利用 watchdog 库来观察目标目录及其子目录中的文件系统事件。
防抖(Debounce)机制
为防止在快速保存文件(例如"全部保存"命令或 Agent 写入多个文件)时重复触发流水线,watch.py 实现了一个防抖定时器,默认延时为 3.0 秒。
-
事件捕获 :
Handler类继承自FileSystemEventHandler,捕获所有非目录且匹配_WATCHED_EXTENSIONS的事件。 -
累积 :将变更的路径添加到一个集合(changed set)中,并使用
time.monotonic()更新last_trigger时间戳。 -
冷却 :主循环等待,直到
(time.monotonic() - last_trigger) >= debounce后才处理累积的这批文件。
监听的扩展名
监听器按文件类型过滤,仅处理定义在 detect.py 中的特定文件扩展名,以避免构建产物或隐藏目录带来的噪音。
| 分类 | 来源变量 | 典型扩展名 |
|---|---|---|
| 代码(Code) | CODE_EXTENSIONS |
.py, .ts, .js, .go, .rs, .php, .dart 等 |
| 文档(Docs) | DOC_EXTENSIONS |
.md, .txt, .rst, .pdf |
| 论文(Papers) | PAPER_EXTENSIONS |
.pdf(结合论文启发式规则处理) |
| 图像(Images) | IMAGE_EXTENSIONS |
.png, .jpg, .jpeg, .webp, .svg |
更新逻辑流程
监听器使用 _has_non_code() 辅助函数来区分结构性变更(代码)和语义变更(非代码)。
仅代码重建(_rebuild_code)
如果变更的文件批次中仅包含代码扩展名 ,watch.py 会执行一个"即时"重建流水线。该流水线是确定性的,且不产生 LLM Token 成本,因为它依赖于 tree-sitter AST 提取。
_rebuild_code 流水线执行以下步骤:
-
检测与提取 :调用
detect()查找所有文件,并对代码文件调用extract()。 -
状态保留 :尝试加载现有的
graph.json。它保留"语义"节点(文档/图像)以及标记为INFERRED或AMBIGUOUS的边,同时用新的 AST 数据替换与代码相关的节点。 -
构建 :调用
build_from_json()创建一个 NetworkX 图G。 -
聚类 :运行
cluster()和score_all()进行社区检测。 -
分析 :识别"上帝节点"(
god_nodes())、"意外连接"(surprising_connections())并提出建议问题(suggest_questions())。 -
导出 :更新
graphify-out/graph.json并覆盖GRAPH_REPORT.md。如果图谱未超过MAX_NODES_FOR_VIZ,还会尝试更新graph.html。 -
清理 :如果之前设置了
needs_update标志,则将其删除。
语义通知(_notify_only)
如果变更文件中包含任何文档、论文或图像,监听器无法在不经过 LLM 处理的情况下安全地重建图谱。此时,它会调用 _notify_only()。
-
标记 :在
graphify-out/needs_update处创建一个包含字符串"1"的文件。 -
通知 :向控制台打印一条消息,指示用户在 Claude Code 中运行
/graphify --update以执行语义重新提取。
系统集成图示
文件事件到操作的映射
该图展示了文件系统事件如何被分类,并被路由到 AST 流水线或通知系统。
(图示部分已省略)
数据流:代码重建 vs 语义更新
该图在"自然语言空间"(用户通知)和"代码实体空间"(具体函数和文件)之间建立了桥梁。
(图示部分已省略)
实现细节
依赖处理
watchdog 库是一个可选依赖项。watch() 函数对 watchdog.observers 和 watchdog.events 执行延迟导入。如果缺少该库,会抛出 ImportError 并提示安装。
在 macOS 上,监听器默认使用 PollingObserver,以确保跨不同文件系统事件限制的兼容性。
_rebuild_code 中的状态合并
_rebuild_code 的一个关键特性是它能够保留先前 LLM 运行产生的语义上下文。它会过滤现有节点,保留所有 file_type != "code" 的节点,并过滤边,保留 confidence 标记为 INFERRED 或 AMBIGUOUS 的边。
这确保了在代码结构即时更新的同时,代码与文档之间的高层语义链接不会丢失。
错误处理
_rebuild_code 函数被包裹在一个宽泛的 try...except 块中。如果流水线的任何阶段(提取、聚类或报告生成)失败,它会打印异常并返回 False,确保监听器进程不会崩溃。
技术要点速览
| 技术点 | 说明 |
|---|---|
| 监听库 | watchdog(可选依赖,延迟导入) |
| 防抖时间 | 默认 3.0 秒 |
| 代码变更成本 | 零 Token 成本(仅 AST 解析) |
| 语义变更处理 | 设置 needs_update 标志 + 控制台提示 |
| 状态保留 | 保留非代码节点 + INFERRED/AMBIGUOUS 边 |
| 错误恢复 | 失败时返回 False,进程不崩溃 |
| macOS 兼容 | 使用 PollingObserver |
6. Testing
Graphify 的测试套件确保了知识图谱构建管道的完整性,以及其提取、分析和导出模块的准确性。该套件采用模块化结构,每个核心功能脚本都有对应的测试文件,并辅以端到端管道测试来验证所有阶段的集成。
测试架构
测试策略分为细粒度的单元测试和高层级的集成测试。所有测试均通过利用基于 AST 的提取和本地文件测试夹具,设计为无需 LLM 依赖即可运行。
| 测试类别 | 目的 | 关键文件 |
|---|---|---|
| 单元测试 | 验证各个模块逻辑(例如检测、语言特定提取、聚类) | test_detect.py、test_languages.py、test_cluster.py、test_hooks.py |
| 集成测试(E2E) | 从原始文件到最终导出的完整线性管道 | tests/test_pipeline.py |
| 测试夹具 | 用于生成可预测图谱的静态代码和文档样本 | tests/fixtures/ |
端到端管道测试
主要的集成测试定义在 tests/test_pipeline.py 中。它使用辅助函数 run_pipeline(),协调 graphify 工作流的九个阶段,包括检测、提取、build_from_json、聚类、god_nodes 以及各种导出函数。
E2E 测试执行的关键验证包括:
-
图完整性:确保生成的 NetworkX 图包含节点和边
-
社区分配:验证每个节点都通过聚类模块被分配到了社区
-
分析准确性:检查"上帝节点"(高中心性实体)是否被正确识别并包含在最终报告中
-
幂等性:在相同的语料库上运行两次管道,确保节点和边的数量保持一致
单元测试与测试夹具
graphify/ 目录中的每个模块在 tests/ 中都有对应的测试文件。这些测试关注边缘情况和模块内部的具体逻辑:
-
语言提取器 :
tests/test_languages.py和tests/test_multilang.py验证 tree-sitter 能否正确识别 Java、C++、Go、Rust 和 TypeScript 中的类、方法和调用 -
图组装 :
tests/test_build.py验证提取字典是否正确合并到 NetworkX 对象中,以及遗留键(如from/to)是否被规范化 -
导出格式 :
tests/test_export.py确保to_json、to_cypher和to_html生成包含预期属性(如community)的有效文件 -
Git 钩子 :
tests/test_hooks.py测试post-commit和post-checkout钩子的幂等安装与移除
运行测试
测试使用 pytest 执行。该套件已集成到 CI 工作流中,通常在 Python 3.10+ 上运行。开发者可以使用以下命令在本地运行测试套件:
bash
# 运行所有测试
python -m pytest tests/ -q --tb=short
# 仅运行特定模块的测试(例如 Export)
pytest tests/test_export.py
# 仅运行管道集成测试
pytest tests/test_pipeline.pyGraphify 端到端管道测试
Graphify 的端到端管道测试定义在 tests/test_pipeline.py 文件中,是确保整个知识图谱构建流程正确性的关键验证手段。
测试目的
端到端测试旨在完整验证从原始文件输入到最终知识图谱导出的整个生命周期,确保所有核心模块能够正确协同工作。这些测试被设计为无需 LLM 依赖即可运行,通过利用基于 AST 的提取和本地文件测试夹具来实现。
测试核心流程
端到端测试协调 Graphify 工作流的九个主要阶段:
-
检测阶段 :通过
detect()函数扫描目标目录,发现所有文件并按类型分类(代码、文档、论文、图像、视频) -
提取阶段 :调用
extract()函数,使用 tree-sitter 进行 AST 结构提取 -
构建阶段 :通过
build_from_json()函数将提取结果合并到 NetworkX 图对象中 -
聚类阶段 :运行
cluster()函数应用 Leiden 社区检测算法 -
分析阶段 :通过
god_nodes()识别高中心性实体("上帝节点") -
报告生成 :生成
GRAPH_REPORT.md审计追踪文档 -
HTML 可视化:导出交互式 HTML 图谱
-
JSON 导出 :生成
graph.json数据文件 -
其他格式导出:验证 GraphML、Cypher 等格式的导出
关键验证点
| 验证项 | 描述 |
|---|---|
| 图完整性 | 确保生成的 NetworkX 图包含节点和边,图结构有效 |
| 社区分配 | 验证每个节点都通过聚类模块被正确分配了社区 ID |
| 分析准确性 | 检查"上帝节点"(高中心性实体)是否被正确识别并包含在最终报告中 |
| 幂等性 | 在相同的语料库上运行两次管道,确保节点和边的数量保持一致,验证管道的确定性行为 |
运行方式
开发者可以使用以下命令运行端到端测试:
bash
# 运行所有测试(包括 E2E 测试)
python -m pytest tests/ -q --tb=short
# 仅运行管道集成测试
pytest tests/test_pipeline.py此外,Graphify 项目通过 GitHub Actions 维护了持续的 CI 管道,确保每次推送到 main 分支或提交拉取请求时,端到端测试都会自动执行。
6.2 单元测试与测试夹具(Test Fixtures)
本页面详细介绍了 Graphify 的单元测试套件以及用于验证其管道的静态测试夹具(fixtures)。该测试套件遵循与核心库相同的模块化结构,确保管道的每个阶段------从文件检测到报告生成------都能在隔离环境下独立验证功能正确性。
测试套件概览
测试架构遵循核心模块与测试文件之间的 1:1 映射关系。这些测试利用一套多语言夹具来验证 AST 提取、图构建和导出格式。
| 测试文件 | 目标模块 | 主要关注点 |
|---|---|---|
test_detect.py |
graphify/detect.py |
文件发现、忽略模式(ignore patterns)和分类 |
test_extract.py |
graphify/extract.py |
Python AST 提取和基础逻辑 |
test_multilang.py |
graphify/extract.py |
JavaScript/TypeScript、Go 和 Rust 提取逻辑 |
test_languages.py |
graphify/extract.py |
Java、C、C++、Ruby、C#、Kotlin、Scala 和 PHP 提取逻辑 |
test_transcribe.py |
graphify/transcribe.py |
Whisper 提示和转录缓存 |
test_hooks.py |
graphify/hooks.py |
Git 钩子安装、幂等性和移除 |
test_cache.py |
graphify/cache.py |
SHA256 哈希处理和 YAML 前置元数据剥离 |
test_build.py |
graphify/build.py |
NetworkX 图组装和遗留键(legacy keys)规范化 |
test_hypergraph.py |
graphify/build.py |
超边(hyperedges)的保留和去重 |
test_export.py |
graphify/export.py |
HTML、JSON、GraphML 和 Canvas(Obsidian 画布)生成 |
test_claude_md.py |
graphify/__main__.py |
CLAUDE.md 规则注入和 settings.json 钩子 |
多语言夹具
Graphify 使用一套全面且高度代表性的"示例"文件(位于 tests/fixtures/ 中),用于验证特定于每种语言的提取器(extractors)。这些文件包含了 AST 解析器必须能够识别的、具有代表性的代码结构------类、方法、导入和调用,涵盖各语言的主流语法特性。
提取逻辑验证点
系统会逐一验证特定语言的提取器(例如,extract_js、extract_go、extract_rust)是否能准确无误地从底层代码中识别出完整的代码实体及其关系(边)。
数据流:从夹具文件到提取结果
下框图展示了如何将一个特定的夹具文件处理成 Graphify 内部统一的提取模式。
图示:代码实体提取流程
受支持语言的测试用例
为确保对主流语法结构的精确覆盖,每种语言都设置了专门的测试用例:
| 语言 | 测试文件 | 核心验证内容 |
|---|---|---|
| TypeScript | sample.ts |
验证 HttpClient 类的定义、get/post 方法的提取,以及 EXTRACTED 调用关系的捕获 |
| Go | sample.go |
验证 Server 结构体、Start 方法,以及 NewServer 构造函数模式 |
| Rust | sample.rs |
验证 Graph 结构体、impl 块,以及 build_graph 函数 |
| C / C++ | sample.c / sample.cpp |
验证函数检测、#include 到 imports 关系的映射,以及构造函数捕获 |
| PHP | sample.php |
验证 ApiClient 类的定义,以及专门的 Laravel 风格模式(例如 $listen 数组和容器调用) |
这一详尽的多语言覆盖是整个 Graphify 项目中 AST 解析正确性的基石。
文件检测与 Git 钩子
test_detect.py 和 test_hooks.py 套件用于验证系统能够正确地发现文件并集成到实际开发工作流中。
检测启发式规则
<!-- 此处描述文件类型分类和忽略逻辑等 -->
-
分类 :验证
.py文件能否被正确映射到FileType.CODE,同时准确区分出FileType.PAPER(学术论文)。 -
论文信号检测 :通过提供包含 LaTeX 风格引用和摘要标题的 Markdown 文件,测试
_looks_like_paper启发式规则。 -
忽略逻辑 :验证
.graphifyignore中的模式(例如vendor/)是否被严格遵守,并确保搜索过程在遇到.git边界时正确停止,不会向上层目录漫延。
Git 钩子生命周期管理
test_hooks.py 确保 install() 和 uninstall() 函数能够正确管理 post-commit 和 post-checkout 脚本。它还会验证钩子是否已标有 _HOOK_MARKER 以实现幂等性操作,并确保在非 Windows 平台上正确设置了可执行位。
多媒体与转录测试
test_transcribe.py 涵盖了与 faster-whisper 的集成,这是 Graphify 处理音视频文件的核心途径。
转录逻辑
-
缓存机制 :验证
transcribe()在存在现有.txt文件时是否直接返回,而非重复计算。 -
Whisper 提示注入 :测试
build_whisper_prompt(),确保将"上帝节点"(God Nodes)标签作为上下文域提示注入到转录过程中,以改进专业术语的识别精度。 -
强制重新运行 :确保
force=True参数能正确地绕过缓存,彻底重新运行 Whisper 模型。
语义缓存与超图测试
提取管道使用基于 SHA256 的语义缓存来避免重复解析未变更的文件,并使用超图结构来表示组级关系。
缓存哈希机制
-
前置元数据排除 :
test_cache.py验证了在.md文件中更改 YAML 前置元数据(frontmatter)是否 不会 改变哈希值,从而确保语义的稳定性。这避免了因文档的元信息变动而触发不必要的全量重处理。 -
往返校验 :验证
save_cached和load_cached是否能返回完全相同的结果字典。
超图持久化
-
生存能力 :
test_hypergraph.py确保超边(例如auth_flow)能完整地经历build_from_json往返,并正确出现在最终的graph.json中。 -
报告集成 :验证
graphify/report.py在存在此类关系时,是否在生成的GRAPH_REPORT.md中包含专用的 "Hyperedges" 章节。
7 Worked Examples & Benchmarks
本页概述了位于 worked/ 目录下的参考语料库。这些示例既作为 Graphify 管道的功能测试,也用于衡量提取准确性、社区检测质量和 Token 缩减效率。每个示例都展示了系统的特定能力,涵盖了从简单的基于 AST 的代码分析到复杂的研究论文和图像等多模态数据提取。
参考语料库概述
worked/ 目录包含四个不同的场景,旨在测试 Graphify 引擎的不同部分:
| 示例 | 主要用途 | 关键指标/数据规模 |
|---|---|---|
| Simple Example | 文档与代码管道 | 7 个文件、2 种语言、清晰的调用层次 |
| httpx Benchmark | 库代码库分析 | 144 个节点、330 条边、6 个社区 |
| Karpathy Repos | 大规模跨仓库分析 | 52 个文件、71.5 倍 Token 缩减 |
| Mixed Corpus | 多模态数据提取 | Python + Markdown + arXiv + 图像 |
来源:Worked Examples & Benchmarks
系统数据流:从源文件到图谱
以下流程图展示了这些工作示例如何通过 Graphify 管道,将原始文件转换为基准报告中呈现的结构化实体。
(图示部分已省略)
Simple Example (Document Pipeline)
worked/example 语料库代表一个标准的微服务架构,包含 5 个 Python 模块(api.py、storage.py、parser.py、validator.py、processor.py)和 2 个 Markdown 文件(architecture.md、notes.md)。
关键发现:
-
Graphify 成功识别出
api.py作为中心枢纽 -
将
storage.py识别为"上帝节点"(God Node),因为它具有来自其他模块的高入向连接度 -
该示例完全基于 AST 和 Markdown 运行,语义提取的 Token 成本为零
*来源:worked/example/README.md 第9-18行、第37-47行*
httpx Benchmark (Library Codebase)
基于 httpx 库的合成版本,该基准测试了在 6 个 Python 文件中复杂类层次结构和异步模式的提取能力,生成了一个包含 144 个节点 和 330 条边 的密集图。
关键发现:
-
识别出
Client、AsyncClient和Response作为跨 6 个检测到社区的主要架构桥梁节点 -
突出了"意外连接",例如
DigestAuth与Response在头部解析方面的连接
*来源:worked/httpx/README.md 第5-15行、第36-39行*
Karpathy Repos Benchmark (71.5x Token Reduction)
这是旗舰级的性能基准测试。它提取了跨越三个独立代码仓库(nanoGPT、minGPT、micrograd)以及 5 篇 arXiv PDF 和 4 张图片,总共 52 个文件。
关键发现:
-
演示了 Graphify 寻找跨仓库连接 的能力,例如链接
nanoGPT和minGPT中的Block实现 -
实现了 71.5 倍 的 Token 缩减,使得 LLM 能够以远低于直接读取原始文件的成本对整个语料库进行推理
-
该数据被国内外大量技术社区和博客引用,成为 Graphify 核心差异化竞争力的标志性数字
*来源:worked/karpathy-repos/README.md 第5-29行、第68-71行;GRAPH_REPORT.md 第12-23行*
Mixed Corpus Benchmark (Multi-modal)
worked/mixed-corpus 聚焦于多模态集成 能力。它利用 graphify/detect.py 的启发式规则,根据 arXiv ID 模式(如 1706.03762)将文件分类为"论文",并演示了技术图示(如 attention_arabic.png)如何被集成到图谱中。
该示例产生了 3 个不同的社区:图谱分析、聚类/评分和图构建。
*来源:worked/mixed-corpus/README.md 第7-15行、第36-41行*
社区实践案例
除了官方基准,Graphify 在社区中也涌现出多种落地场景:
| 实践方向 | 具体案例 | 来源 |
|---|---|---|
| 故障管理图谱化 | 将报警数据、团队信息、历史故障日志处理成图谱,辅助事件复盘和根因定位 | hn.svelte.dev |
| 知识库自动化 | 将 Obsidian 笔记库自动转化为可交互的知识图谱,支持社区发现和反向链接导航 | CSDN |
| 架构审计与导航 | 在 Cursor 中集成 Graphify,让 AI 基于图谱而非逐文件检索来回答架构相关提问 | CSDN |
| 多工具协同增效 | 将 Graphify 与 Lynkr、axon、claude-context 串联使用,整体开发效率提升近 300% | 网易 |
关键指标总结
| 指标 | 数值 |
|---|---|
| 最大 Token 缩减 | 71.5 倍 (52 文件混合语料) |
| httpx 基准 | 144 节点 / 330 边 / 6 社区 |
| 社区聚类方式 | Leiden 算法,基于图拓扑,零向量库开销 |
| 语义提取成本 | 仅对非代码文件调用 LLM |
| 多模态支持 | 代码 / Markdown / PDF / arXiv / 图像 / 视频 / 音频 |
实体映射:基准报告到代码
以下图示将 GRAPH_REPORT.md(如 worked/ 目录中生成的报告)中的高层概念映射到生成它们的特定 Python 类和函数。