Day 16 编程实战:PCA主成分分析与技术指标降维
实战目标
- 理解PCA的最大方差投影原理
- 掌握主成分的可解释性分析
- 学习主成分数量的选择方法
- 对比降维前后模型性能
1. 导入必要的库
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, TimeSeriesSplit, cross_val_score
from sklearn.metrics import accuracy_score, roc_auc_score, classification_report
from sklearn.pipeline import Pipeline
import warnings
warnings.filterwarnings('ignore')
# 预设样式
sns.set_style("whitegrid")
#启用LaTeX渲染(设为False避免LaTeX依赖)
plt.rcParams['text.usetex'] = False
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['mathtext.fontset'] = 'dejavusans' # 或 'stix'2. 生成金融数据
python
def generate_financial_data(ts_code):
"""生成金融数据"""
data_path = Path(r"E:\AppData\quant_trade\klines\kline2014-2024")
kline_file = data_path / f"{ts_code}.csv"
df = pd.read_csv(kline_file, usecols=["trade_date", "close", "vol"],
parse_dates=["trade_date"])\
.rename(columns={"vol": "volume"})\
.sort_values(by=["trade_date"])\
.reset_index(drop=True)
df['return'] = df['close'].pct_change()
# 技术指标
# RSI
delta = df['return'].fillna(0)
gain = delta.where(delta > 0, 0).rolling(14).mean()
loss = -delta.where(delta < 0, 0).rolling(14).mean()
rs = gain / (loss + 1e-10)
df['rsi'] = 100 - (100 / (1 + rs))
# MACD
ema12 = df['close'].ewm(span=12, adjust=False).mean()
ema26 = df['close'].ewm(span=26, adjust=False).mean()
df['macd'] = ema12 - ema26
df['macd_signal'] = df['macd'].ewm(span=9, adjust=False).mean()
# 均线比率
df['ma5'] = df['close'].rolling(5).mean()
df['ma20'] = df['close'].rolling(20).mean()
df['ma_ratio'] = df['ma5'] / df['ma20'] - 1
# 波动率
df['volatility'] = df['return'].rolling(20).std()
# 成交量比率
df['volume_ratio'] = df['volume'] / df['volume'].rolling(10).mean()
# 动量指标
for lag in [1, 2, 3, 5, 10]:
df[f'momentum_{lag}'] = df['return'].shift(lag).fillna(0)
# 目标变量:次日收益率
df['future_return'] = df['return'].shift(-1)
# 删除缺失值
df = df.dropna()
return df
# 生成数据
ts_code = "300033.SZ"
df = generate_financial_data(ts_code)
print(f"数据形状: {df.shape}")
# 特征选择
feature_cols = ['rsi', 'macd', 'macd_signal', 'ma_ratio', 'volatility',
'volume_ratio', 'momentum_1', 'momentum_2', 'momentum_3',
'momentum_5', 'momentum_10']
X = df[feature_cols].values
y_continuous = df['future_return'].values
print(f"特征数量: {len(feature_cols)}")
print(f"样本数量: {len(X)}")
# 按时间划分
split_idx = int(len(X) * 0.7)
X_train = X[:split_idx]
X_test = X[split_idx:]
y_train_cont = y_continuous[:split_idx]
y_test_cont = y_continuous[split_idx:]
print(f"\n训练集: {len(X_train)} 样本")
print(f"测试集: {len(X_test)} 样本")
# 数据标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)数据形状: (2450, 18)
特征数量: 11
样本数量: 2450
训练集: 1715 样本
测试集: 735 样本
python
def generate_financial_data_with_many_features(ts_code):
"""生成包含20个技术指标的金融数据"""
data_path = Path(r"E:\AppData\quant_trade\klines\kline2014-2024")
kline_file = data_path / f"{ts_code}.csv"
df = pd.read_csv(kline_file, usecols=["trade_date", "open", "high", "low", "close", "vol"],
parse_dates=["trade_date"])\
.rename(columns={"vol": "volume"})\
.sort_values(by=["trade_date"])\
.reset_index(drop=True)
df['return'] = df['close'].pct_change()
# 生成20个技术指标
# 1. RSI
delta = df['return'].fillna(0)
gain = delta.where(delta > 0, 0).rolling(14).mean()
loss = -delta.where(delta < 0, 0).rolling(14).mean()
rs = gain / (loss + 1e-10)
df['rsi'] = 100 - (100 / (1 + rs))
# 2-3. MACD
ema12 = df['close'].ewm(span=12, adjust=False).mean()
ema26 = df['close'].ewm(span=26, adjust=False).mean()
df['macd'] = ema12 - ema26
df['macd_signal'] = df['macd'].ewm(span=9, adjust=False).mean()
# 4-5. 移动平均线
for period in [5, 10, 20, 60]:
df[f'ma_{period}'] = df['close'].rolling(period).mean()
# 6-7. 价格与均线比率
df['ma5_ratio'] = df['close'] / df['ma_5'] - 1
df['ma20_ratio'] = df['close'] / df['ma_20'] - 1
# 8. 波动率
df['volatility'] = df['return'].rolling(20).std()
# 9-10. 布林带
df['bb_upper'] = df['ma_20'] + 2 * df['volatility'] * df['close']
df['bb_lower'] = df['ma_20'] - 2 * df['volatility'] * df['close']
df['bb_width'] = (df['bb_upper'] - df['bb_lower']) / df['ma_20']
# 11-12. 成交量指标
df['volume_ma'] = df['volume'].rolling(10).mean()
df['volume_ratio'] = df['volume'] / df['volume_ma']
# 13-16. 动量指标
for lag in [1, 2, 5, 10]:
df[f'momentum_{lag}'] = df['return'].shift(lag).fillna(0)
# 17. ATR
price = df['close']
high = df['high']
low = df['low']
tr = np.maximum(high - low, np.abs(high - price.shift(1)), np.abs(low - price.shift(1)))
df['atr'] = tr.rolling(14).mean()
# 18. OBV
obv = (np.sign(df['return']) * df['volume']).cumsum()
df['obv'] = obv
# 19-20. 随机指标
low_14 = df['close'].rolling(14).min()
high_14 = df['close'].rolling(14).max()
df['stoch_k'] = 100 * (df['close'] - low_14) / (high_14 - low_14)
df['stoch_d'] = df['stoch_k'].rolling(3).mean()
# 目标变量
df['target'] = (df['return'].shift(-1) > 0).astype(int)
df = df.dropna()
return df
# 生成数据
ts_code = "300033.SZ"
df = generate_financial_data_with_many_features(ts_code)
print(f"数据形状: {df.shape}")
# 技术指标列
technical_cols = ['rsi', 'macd', 'macd_signal', 'ma_5', 'ma_10', 'ma_20', 'ma_60',
'ma5_ratio', 'ma20_ratio', 'volatility', 'bb_width', 'volume_ratio',
'momentum_1', 'momentum_2', 'momentum_5', 'momentum_10', 'atr', 'obv',
'stoch_k', 'stoch_d']
X = df[technical_cols].values
y = df['target'].values
print(f"技术指标数量: {len(technical_cols)}")
print(f"样本数量: {len(X)}")
print(f"目标分布: {y.mean():.2%}")
# 时间划分
split_idx = int(len(X) * 0.7)
X_train = X[:split_idx]
X_test = X[split_idx:]
y_train = y[:split_idx]
y_test = y[split_idx:]
print(f"\n训练集: {len(X_train)} 样本")
print(f"测试集: {len(X_test)} 样本")数据形状: (2412, 31)
技术指标数量: 20
样本数量: 2412
目标分布: 48.51%
训练集: 1688 样本
测试集: 724 样本3. 数据标准化
主成分分析要求数据必须标准化
python
# 标准化(PCA必需)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("标准化后特征统计:")
print(f"训练集均值: {X_train_scaled.mean(axis=0).round(4)}")
print(f"训练集标准差: {X_train_scaled.std(axis=0).round(4)}")
# 相关性热图
plt.figure(figsize=(14, 12))
corr_matrix = pd.DataFrame(X_train_scaled, columns=technical_cols).corr()
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
sns.heatmap(corr_matrix, mask=mask, cmap='coolwarm', center=0,
square=True, linewidths=0.5, cbar_kws={"shrink": 0.8})
plt.title('20个技术指标相关性矩阵', fontsize=14)
plt.tight_layout()
plt.show()
print("\n高度相关的特征对(相关系数 > 0.8):")
corr_flat = corr_matrix.unstack()
high_corr = corr_flat[(corr_flat > 0.8) & (corr_flat < 1)]
for idx, val in high_corr.head(10).items():
print(f" {idx[0]} ↔ {idx[1]}: {val:.3f}")标准化后特征统计:
训练集均值: [-0. 0. 0. -0. 0. 0. -0. 0. 0. -0. -0. 0. 0. 0. -0. 0. 0. 0.
0. 0.]
训练集标准差: [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]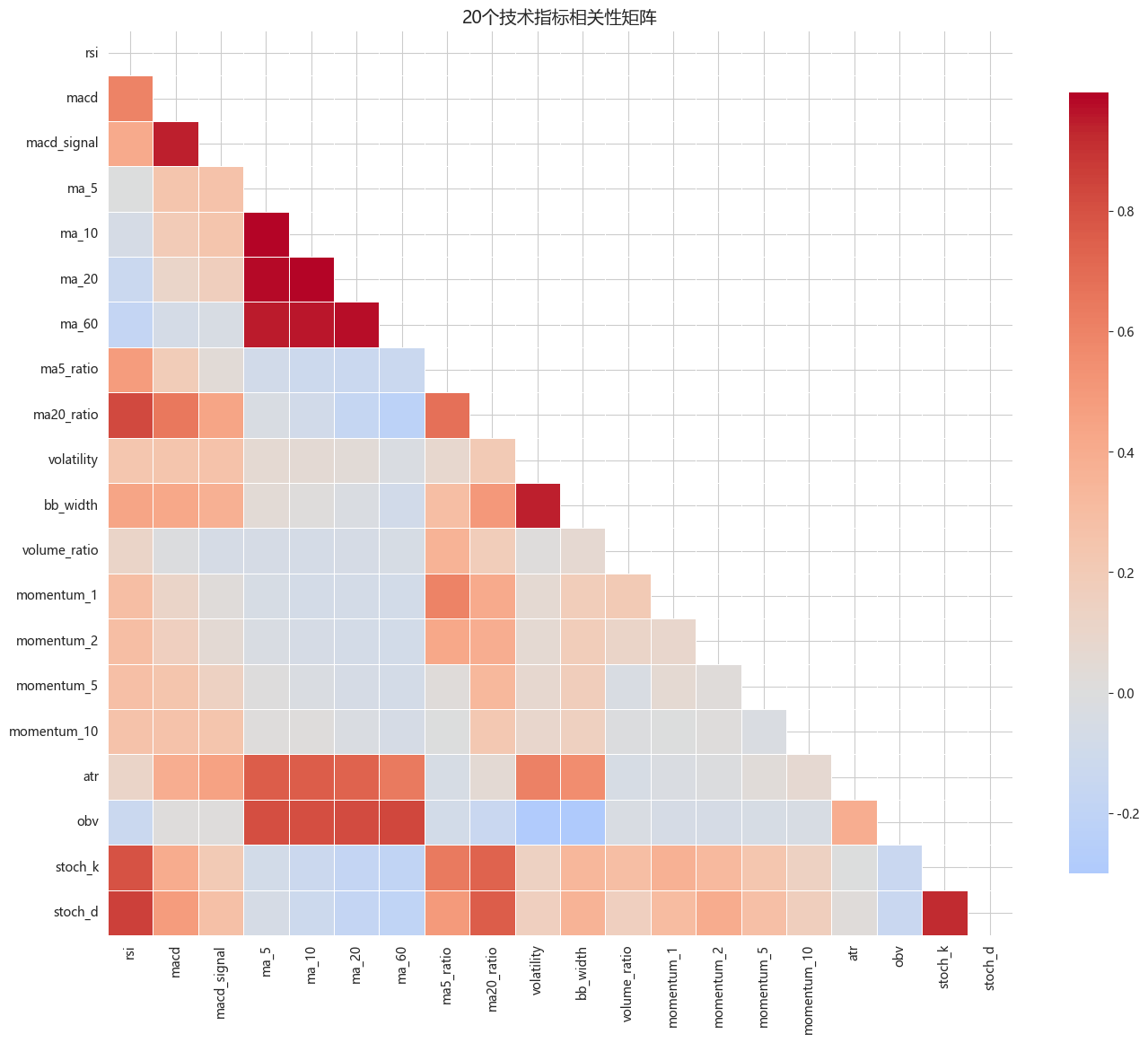
高度相关的特征对(相关系数 > 0.8):
rsi ↔ ma20_ratio: 0.827
rsi ↔ stoch_d: 0.857
macd ↔ macd_signal: 0.942
macd_signal ↔ macd: 0.942
ma_5 ↔ ma_10: 0.997
ma_5 ↔ ma_20: 0.986
ma_5 ↔ ma_60: 0.949
ma_5 ↔ obv: 0.810
ma_10 ↔ ma_5: 0.997
ma_10 ↔ ma_20: 0.9944. PCA核心原理演示
4.1 2D数据PCA可视化
python
def visualize_pca_2d():
"""在2D数据上演示PCA原理"""
np.random.seed(42)
# 生成椭圆分布数据
t = np.linspace(0, 2*np.pi, 100)
x = np.cos(t) * 2 + np.random.randn(100) * 0.2
y = np.sin(t) * 0.5 + np.random.randn(100) * 0.2
X_2d = np.column_stack([x, y])
# 标准化
X_2d_scaled = (X_2d - X_2d.mean(axis=0)) / X_2d.std(axis=0)
# PCA
pca_2d = PCA(n_components=2)
pca_2d.fit(X_2d_scaled)
# 获取主成分方向
components = pca_2d.components_
mean = pca_2d.mean_
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 原始数据
axes[0].scatter(X_2d_scaled[:, 0], X_2d_scaled[:, 1], alpha=0.6)
# 绘制主成分方向
for i, (comp, var) in enumerate(zip(components, pca_2d.explained_variance_)):
direction = comp * np.sqrt(var) * 2
axes[0].arrow(mean[0], mean[1], direction[0], direction[1],
head_width=0.1, head_length=0.1, fc=f'C{i}', ec=f'C{i}',
label=f'PC{i+1} (方差={var:.3f})')
axes[0].set_xlabel('特征1')
axes[0].set_ylabel('特征2')
axes[0].set_title('原始数据与主成分方向')
axes[0].legend()
axes[0].axis('equal')
axes[0].grid(True, alpha=0.3)
# PCA变换后
X_pca_2d = pca_2d.transform(X_2d_scaled)
axes[1].scatter(X_pca_2d[:, 0], X_pca_2d[:, 1], alpha=0.6)
axes[1].set_xlabel('PC1')
axes[1].set_ylabel('PC2')
axes[1].set_title('PCA变换后(数据已去相关)')
axes[1].axis('equal')
axes[1].grid(True, alpha=0.3)
plt.suptitle('PCA原理演示:找到方差最大的投影方向', fontsize=14)
plt.tight_layout()
plt.show()
print(f"PC1解释方差比例: {pca_2d.explained_variance_ratio_[0]:.2%}")
print(f"PC2解释方差比例: {pca_2d.explained_variance_ratio_[1]:.2%}")
visualize_pca_2d()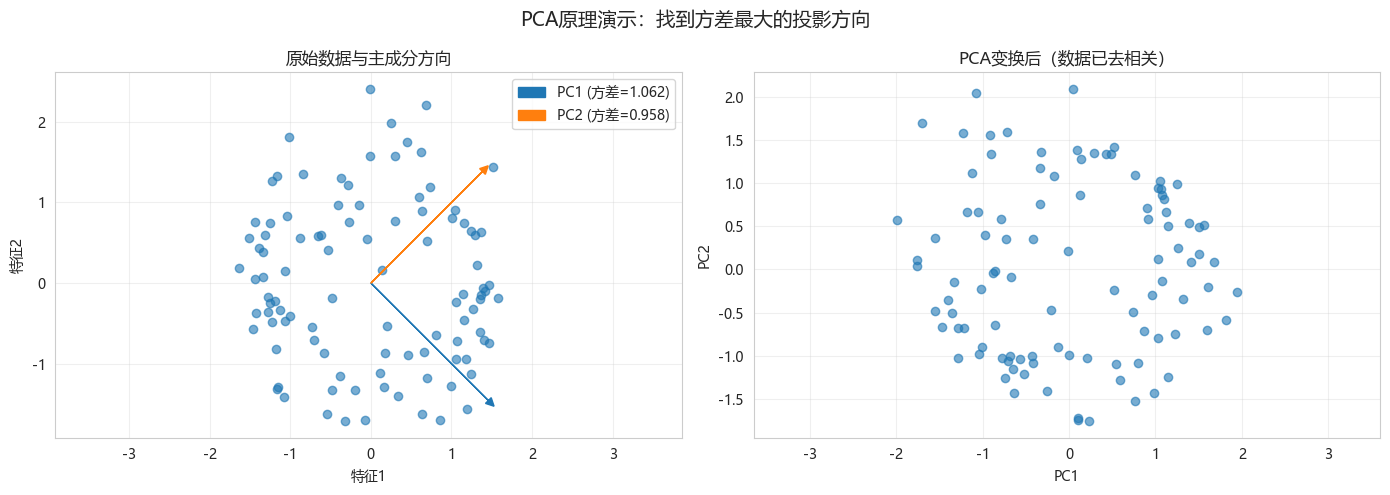
PC1解释方差比例: 52.55%
PC2解释方差比例: 47.45%4.2 特征值分布
python
# 拟合PCA
pca_full = PCA()
pca_full.fit(X_train_scaled)
# 特征值(方差)
eigenvalues = pca_full.explained_variance_
explained_variance_ratio = pca_full.explained_variance_ratio_
cumsum_ratio = np.cumsum(explained_variance_ratio)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(range(1, len(eigenvalues)+1), eigenvalues, 'bo-', linewidth=2, markersize=6)
plt.xlabel('主成分编号')
plt.ylabel('特征值(方差)')
plt.title('Scree Plot(肘部法则)')
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.bar(range(1, len(explained_variance_ratio)+1), explained_variance_ratio, alpha=0.7, label='单个')
plt.step(range(1, len(cumsum_ratio)+1), cumsum_ratio, 'r-', linewidth=2, label='累积')
plt.xlabel('主成分编号')
plt.ylabel('方差解释比例')
plt.title('主成分方差解释率')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()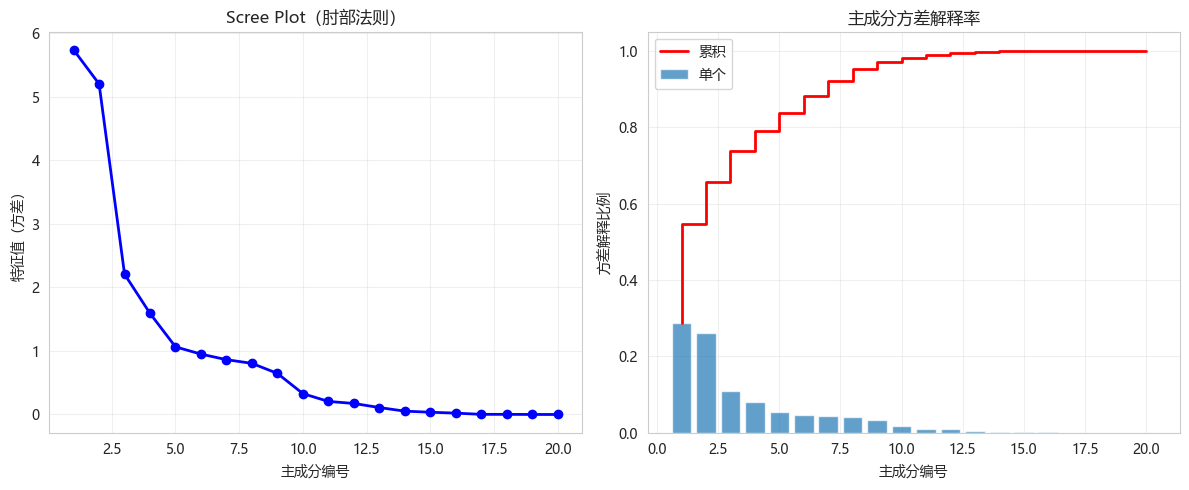
5. 主成分数量选择
5.1 累积方差法
python
def select_components_by_variance(pca, thresholds=[0.7, 0.8, 0.9, 0.95, 0.99]):
"""根据累积方差选择主成分数量"""
cumsum = np.cumsum(pca.explained_variance_ratio_)
results = []
for thresh in thresholds:
n = np.argmax(cumsum >= thresh) + 1
results.append({'threshold': f'{thresh:.0%}', 'n_components': n, 'actual_variance': cumsum[n-1]})
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(cumsum)+1), cumsum, 'bo-', linewidth=2)
plt.axhline(y=0.9, color='r', linestyle='--', label='90%')
plt.axhline(y=0.95, color='g', linestyle='--', label='95%')
plt.xlabel('主成分数量')
plt.ylabel('累积方差解释率')
plt.title('累积方差解释率曲线')
plt.legend()
plt.grid(True, alpha=0.3)
# 标记各阈值点
for thresh, n, var in [(r['threshold'], r['n_components'], r['actual_variance']) for r in results]:
plt.plot(n, var, 'ro', markersize=10)
plt.annotate(f'{thresh}: {n}个成分, var={var:.1%}',
xy=(n, var), xytext=(n+2, var-0.05))
plt.tight_layout()
plt.show()
results_df = pd.DataFrame(results)
print("\n不同阈值下的主成分数量:")
print(results_df.to_string(index=False))
return results_df
variance_results = select_components_by_variance(pca_full)
# 选择95%方差对应的成分数
n_components_95 = np.argmax(np.cumsum(pca_full.explained_variance_ratio_) >= 0.95) + 1
print(f"\n达到95%方差需要的主成分数: {n_components_95}")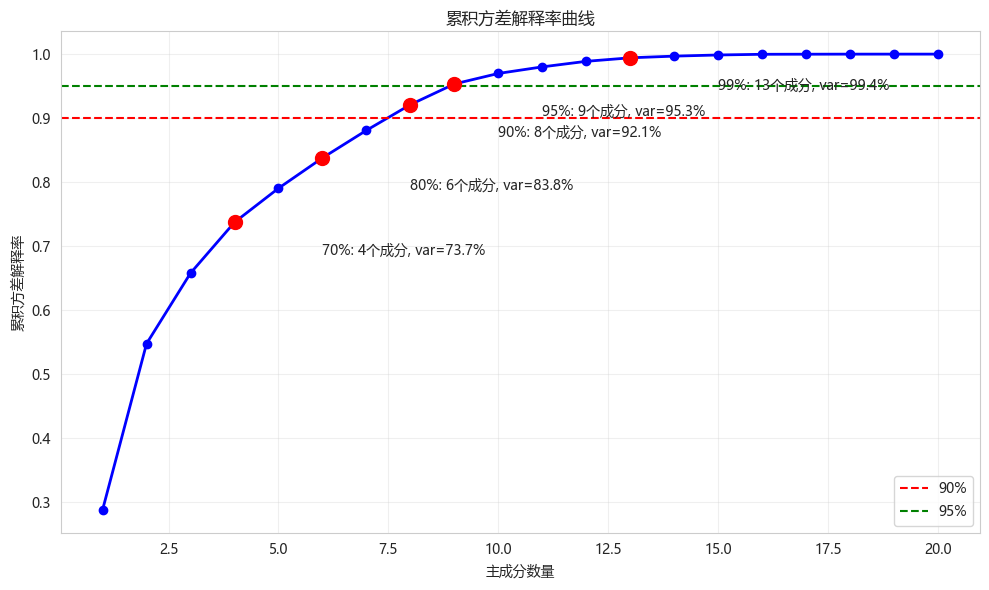
不同阈值下的主成分数量:
threshold n_components actual_variance
70% 4 0.736910
80% 6 0.837636
90% 8 0.921016
95% 9 0.953345
99% 13 0.994245
达到95%方差需要的主成分数: 95.2 主成分数量对模型性能的影响
python
def evaluate_pca_components(X_train, X_test, y_train, y_test, max_components=20):
"""评估不同主成分数量对模型性能的影响"""
scores_train = []
scores_test = []
auc_scores = []
n_components_list = list(range(1, min(max_components, X_train.shape[1]) + 1))
for n in n_components_list:
# PCA变换
pca = PCA(n_components=n)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 随机森林
rf = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
rf.fit(X_train_pca, y_train)
train_acc = accuracy_score(y_train, rf.predict(X_train_pca))
test_acc = accuracy_score(y_test, rf.predict(X_test_pca))
test_auc = roc_auc_score(y_test, rf.predict_proba(X_test_pca)[:, 1])
scores_train.append(train_acc)
scores_test.append(test_acc)
auc_scores.append(test_auc)
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
axes[0].plot(n_components_list, scores_train, 'b-o', label='训练集', linewidth=2)
axes[0].plot(n_components_list, scores_test, 'r-s', label='测试集', linewidth=2)
axes[0].set_xlabel('主成分数量')
axes[0].set_ylabel('准确率')
axes[0].set_title('主成分数量 vs 模型准确率')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
axes[1].plot(n_components_list, auc_scores, 'g-^', linewidth=2)
axes[1].set_xlabel('主成分数量')
axes[1].set_ylabel('AUC')
axes[1].set_title('主成分数量 vs 模型AUC')
axes[1].grid(True, alpha=0.3)
# 标记最佳
best_idx = np.argmax(auc_scores)
axes[1].axvline(x=n_components_list[best_idx], color='r', linestyle='--',
label=f'最佳: {n_components_list[best_idx]}个主成分')
axes[1].legend()
plt.tight_layout()
plt.show()
print(f"最佳主成分数量: {n_components_list[best_idx]}")
print(f"最佳测试集AUC: {auc_scores[best_idx]:.4f}")
return n_components_list[best_idx]
best_n = evaluate_pca_components(X_train_scaled, X_test_scaled, y_train, y_test)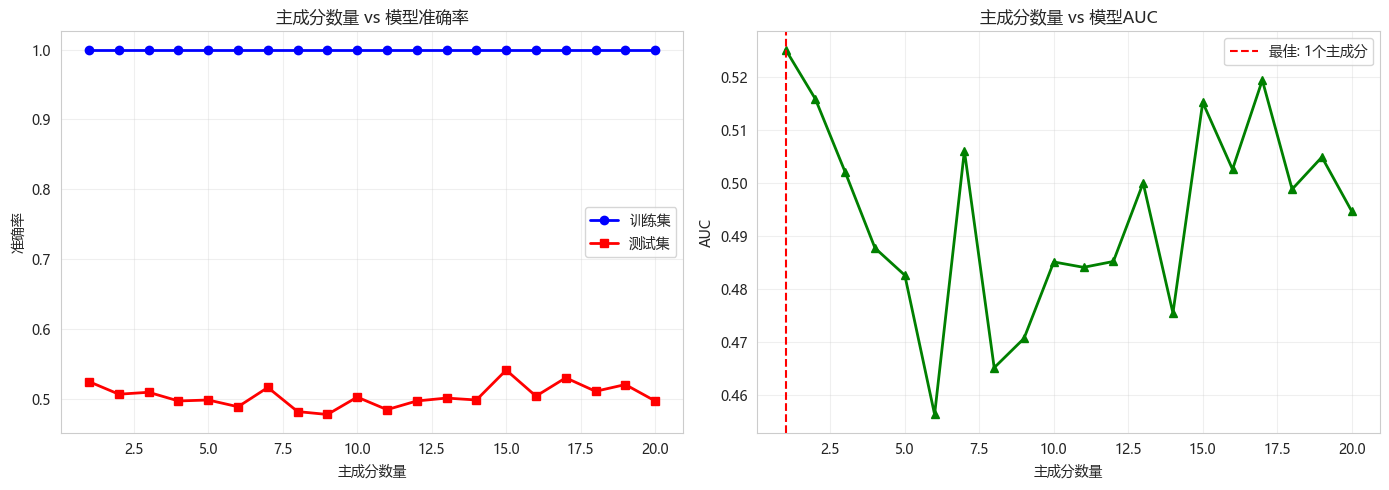
最佳主成分数量: 1
最佳测试集AUC: 0.52516. 主成分可解释性分析
6.1 载荷矩阵分析
python
def analyze_loadings(pca, feature_names, n_components=5):
"""分析PCA载荷矩阵,找出每个主成分最重要的特征"""
loadings = pca.components_.T # shape: (n_features, n_components)
print("="*70)
print("主成分载荷矩阵分析")
print("="*70)
for i in range(min(n_components, loadings.shape[1])):
print(f"\n主成分 PC{i+1} (方差解释率: {pca.explained_variance_ratio_[i]:.2%})")
print("-"*50)
# 找出载荷绝对值最大的5个特征
abs_loadings = np.abs(loadings[:, i])
top_indices = np.argsort(abs_loadings)[-8:][::-1]
print(" Top 8 特征(正载荷→正相关,负载荷→负相关):")
for idx in top_indices:
loading_val = loadings[idx, i]
sign = "正相关" if loading_val > 0 else "负相关"
print(f" {feature_names[idx]:15s}: {loading_val:.4f} ({sign})")
return loadings
# 分析前5个主成分的载荷
loadings = analyze_loadings(pca_full, technical_cols, n_components=5)======================================================================
主成分载荷矩阵分析
======================================================================
主成分 PC1 (方差解释率: 28.69%)
--------------------------------------------------
Top 8 特征(正载荷→正相关,负载荷→负相关):
ma20_ratio : 0.3364 (正相关)
stoch_d : 0.3212 (正相关)
stoch_k : 0.3187 (正相关)
rsi : 0.3163 (正相关)
ma_60 : -0.2802 (负相关)
ma_20 : -0.2617 (负相关)
ma5_ratio : 0.2549 (正相关)
obv : -0.2494 (负相关)
主成分 PC2 (方差解释率: 26.01%)
--------------------------------------------------
Top 8 特征(正载荷→正相关,负载荷→负相关):
ma_5 : 0.3666 (正相关)
atr : 0.3652 (正相关)
ma_10 : 0.3547 (正相关)
ma_20 : 0.3326 (正相关)
ma_60 : 0.2932 (正相关)
macd : 0.2695 (正相关)
macd_signal : 0.2480 (正相关)
obv : 0.2444 (正相关)
主成分 PC3 (方差解释率: 11.04%)
--------------------------------------------------
Top 8 特征(正载荷→正相关,负载荷→负相关):
volatility : 0.4452 (正相关)
bb_width : 0.3660 (正相关)
ma5_ratio : -0.3326 (负相关)
obv : -0.2798 (负相关)
macd_signal : 0.2764 (正相关)
momentum_1 : -0.2525 (负相关)
atr : 0.2467 (正相关)
volume_ratio : -0.2356 (负相关)
主成分 PC4 (方差解释率: 7.95%)
--------------------------------------------------
Top 8 特征(正载荷→正相关,负载荷→负相关):
volatility : 0.4441 (正相关)
bb_width : 0.3629 (正相关)
macd : -0.3534 (负相关)
macd_signal : -0.3464 (负相关)
volume_ratio : 0.2815 (正相关)
ma5_ratio : 0.2721 (正相关)
momentum_1 : 0.2538 (正相关)
momentum_10 : -0.2378 (负相关)
主成分 PC5 (方差解释率: 5.32%)
--------------------------------------------------
Top 8 特征(正载荷→正相关,负载荷→负相关):
momentum_5 : 0.7157 (正相关)
momentum_10 : -0.5695 (负相关)
volume_ratio : -0.2623 (负相关)
macd_signal : -0.1835 (负相关)
stoch_d : 0.1210 (正相关)
ma5_ratio : -0.1120 (负相关)
macd : -0.1115 (负相关)
stoch_k : 0.0652 (正相关)6.2 主成分命名
python
def name_principal_components(loadings, feature_names, n_components=5):
"""根据载荷为每个主成分命名"""
names = []
for i in range(min(n_components, loadings.shape[1])):
abs_loadings = np.abs(loadings[:, i])
top_idx = np.argsort(abs_loadings)[-5:][::-1]
# 根据高载荷特征推断主题
pos_features = [(feature_names[idx], loadings[idx, i]) for idx in top_idx if loadings[idx, i] > 0.2]
neg_features = [(feature_names[idx], loadings[idx, i]) for idx in top_idx if loadings[idx, i] < -0.2]
# 命名逻辑
if any('momentum' in f for f, _ in pos_features):
names.append('动量因子')
elif any('ma' in f for f, _ in pos_features) or any('ma' in f for f, _ in neg_features):
names.append('趋势因子')
elif any('rsi' in f for f, _ in pos_features) or any('stoch' in f for f, _ in pos_features):
names.append('超买超卖因子')
elif any('volume' in f for f, _ in pos_features):
names.append('量能因子')
elif any('volatility' in f for f, _ in pos_features) or any('atr' in f for f, _ in pos_features):
names.append('波动率因子')
else:
names.append(f'综合因子{i+1}')
# 输出命名结果
print("\n" + "="*60)
print("主成分命名建议")
print("="*60)
for i, name in enumerate(names):
var_ratio = pca_full.explained_variance_ratio_[i]
cum_ratio = np.sum(pca_full.explained_variance_ratio_[:i+1])
print(f"PC{i+1} ({var_ratio:.1%} / 累积{cum_ratio:.1%}): {name}")
name_principal_components(loadings, technical_cols)============================================================
主成分命名建议
============================================================
PC1 (28.7% / 累积28.7%): 趋势因子
PC2 (26.0% / 累积54.7%): 趋势因子
PC3 (11.0% / 累积65.7%): 趋势因子
PC4 (8.0% / 累积73.7%): 趋势因子
PC5 (5.3% / 累积79.0%): 动量因子7. PCA降维实战
7.1 使用前3个主成分
python
# 选择前3个主成分
pca_3 = PCA(n_components=3)
X_train_pca = pca_3.fit_transform(X_train_scaled)
X_test_pca = pca_3.transform(X_test_scaled)
print(f"原始特征数: {X_train_scaled.shape[1]}")
print(f"PCA降维后特征数: {X_train_pca.shape[1]}")
print(f"3个主成分累计方差解释率: {np.sum(pca_3.explained_variance_ratio_):.2%}")
# 查看3个主成分的方差解释
for i, var in enumerate(pca_3.explained_variance_ratio_):
print(f" PC{i+1}: {var:.2%}")
# 可视化3个主成分
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(X_train_pca[:, 0], X_train_pca[:, 1], X_train_pca[:, 2],
c=y_train, cmap='coolwarm', alpha=0.6)
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.set_title('前3个主成分3D可视化')
plt.colorbar(scatter, label='目标')
plt.tight_layout()
plt.show()原始特征数: 20
PCA降维后特征数: 3
3个主成分累计方差解释率: 65.74%
PC1: 28.69%
PC2: 26.01%
PC3: 11.04%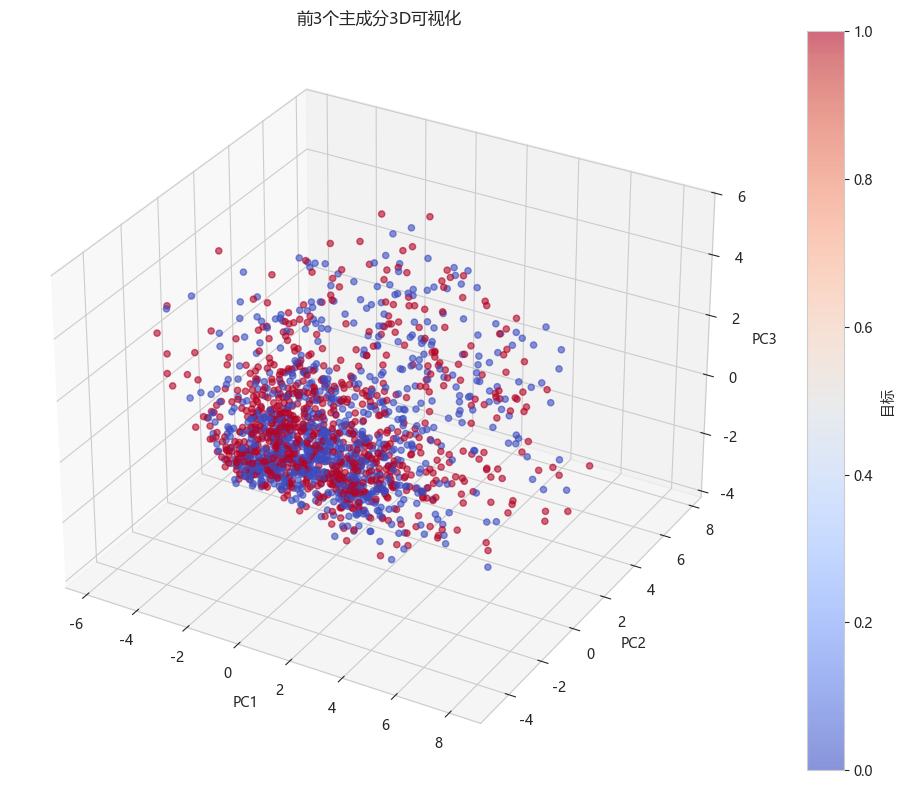
7.2 降维前后模型性能对比
python
print("="*60)
print("降维前后随机森林性能对比")
print("="*60)
# 原始特征模型
rf_original = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
rf_original.fit(X_train_scaled, y_train)
y_pred_orig = rf_original.predict(X_test_scaled)
y_proba_orig = rf_original.predict_proba(X_test_scaled)[:, 1]
# PCA降维后模型
rf_pca = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
rf_pca.fit(X_train_pca, y_train)
y_pred_pca = rf_pca.predict(X_test_pca)
y_proba_pca = rf_pca.predict_proba(X_test_pca)[:, 1]
print(f"\n{'模型':<15} {'准确率':<12} {'AUC':<12} {'特征数':<10}")
print("-"*50)
print(f"{'原始特征':<15} {accuracy_score(y_test, y_pred_orig):<12.4f} {roc_auc_score(y_test, y_proba_orig):<12.4f} {X_train_scaled.shape[1]:<10}")
print(f"{'PCA降维(3维)':<15} {accuracy_score(y_test, y_pred_pca):<12.4f} {roc_auc_score(y_test, y_proba_pca):<12.4f} {3:<10}")
# 训练时间对比
import time
start = time.time()
rf_original.fit(X_train_scaled, y_train)
time_orig = time.time() - start
start = time.time()
rf_pca.fit(X_train_pca, y_train)
time_pca = time.time() - start
print(f"\n训练时间对比:")
print(f" 原始特征: {time_orig:.2f}秒")
print(f" PCA降维: {time_pca:.2f}秒")
print(f" 速度提升: {time_orig/time_pca:.1f}x")============================================================
降维前后随机森林性能对比
============================================================
模型 准确率 AUC 特征数
--------------------------------------------------
原始特征 0.5221 0.5189 20
PCA降维(3维) 0.5097 0.5020 3
训练时间对比:
原始特征: 0.32秒
PCA降维: 0.23秒
速度提升: 1.4x7.3 ROC曲线对比
python
from sklearn.metrics import roc_curve
plt.figure(figsize=(10, 8))
fpr_orig, tpr_orig, _ = roc_curve(y_test, y_proba_orig)
fpr_pca, tpr_pca, _ = roc_curve(y_test, y_proba_pca)
plt.plot(fpr_orig, tpr_orig, 'b-', linewidth=2,
label=f'原始特征 (AUC={roc_auc_score(y_test, y_proba_orig):.4f})')
plt.plot(fpr_pca, tpr_pca, 'r-', linewidth=2,
label=f'PCA降维 (AUC={roc_auc_score(y_test, y_proba_pca):.4f})')
plt.plot([0, 1], [0, 1], 'k--', linewidth=1, label='随机分类器')
plt.xlabel('假阳性率 (FPR)')
plt.ylabel('真阳性率 (TPR)')
plt.title('降维前后ROC曲线对比')
plt.legend(loc='lower right')
plt.grid(True, alpha=0.3)
plt.show()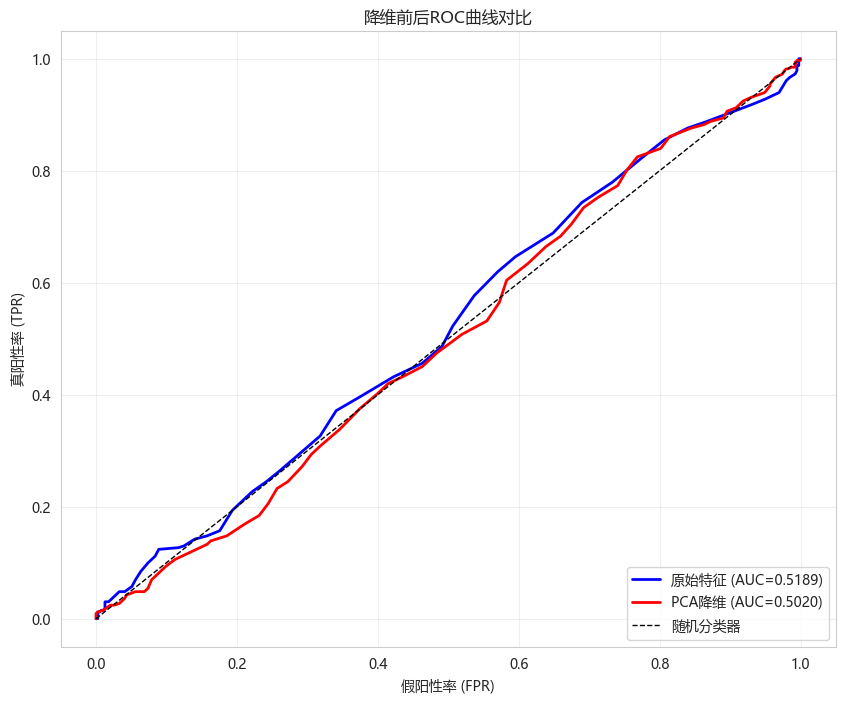
8. 不同主成分数量的对比
python
def compare_components(X_train, X_test, y_train, y_test):
"""对比不同主成分数量的模型性能"""
components_range = [3, 5, 7, 10, 15, 20]
results = []
for n in components_range:
if n > X_train.shape[1]:
continue
pca = PCA(n_components=n)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
rf = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
rf.fit(X_train_pca, y_train)
auc = roc_auc_score(y_test, rf.predict_proba(X_test_pca)[:, 1])
cum_var = np.sum(pca.explained_variance_ratio_)
results.append({
'n_components': n,
'cumulative_variance': cum_var,
'auc': auc
})
results_df = pd.DataFrame(results)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
axes[0].plot(results_df['n_components'], results_df['cumulative_variance'], 'bo-', linewidth=2)
axes[0].set_xlabel('主成分数量')
axes[0].set_ylabel('累积方差解释率')
axes[0].set_title('累积方差 vs 主成分数量')
axes[0].grid(True, alpha=0.3)
axes[1].plot(results_df['n_components'], results_df['auc'], 'ro-', linewidth=2)
axes[1].set_xlabel('主成分数量')
axes[1].set_ylabel('AUC')
axes[1].set_title('模型AUC vs 主成分数量')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("\n不同主成分数量对比:")
print(results_df.to_string(index=False))
return results_df
compare_results = compare_components(X_train_scaled, X_test_scaled, y_train, y_test)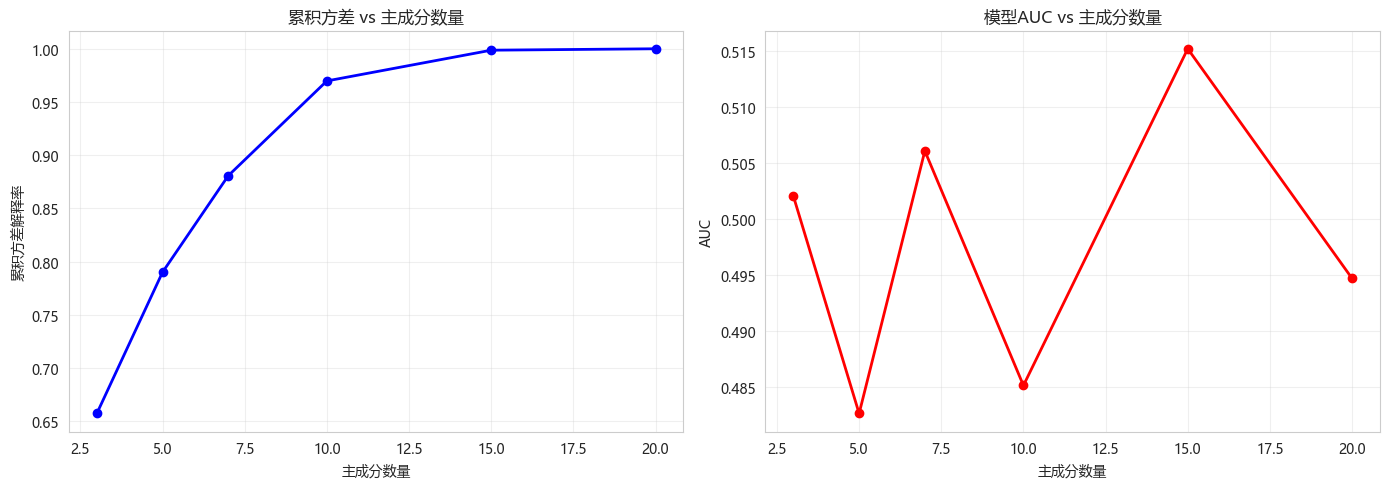
不同主成分数量对比:
n_components cumulative_variance auc
3 0.657367 0.502029
5 0.790126 0.482611
7 0.880775 0.506073
10 0.969787 0.485113
15 0.998664 0.515202
20 1.000000 0.4946809. PCA可视化与解释
9.1 前两个主成分的散点图
python
pca_2 = PCA(n_components=2)
X_pca_2 = pca_2.fit_transform(X_train_scaled)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
scatter = plt.scatter(X_pca_2[:, 0], X_pca_2[:, 1], c=y_train, cmap='coolwarm', alpha=0.6)
plt.colorbar(scatter, label='目标')
plt.xlabel(f'PC1 ({pca_2.explained_variance_ratio_[0]:.1%})')
plt.ylabel(f'PC2 ({pca_2.explained_variance_ratio_[1]:.1%})')
plt.title('PCA降维可视化(按目标着色)')
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.scatter(X_pca_2[:, 0], X_pca_2[:, 1], alpha=0.5)
plt.xlabel(f'PC1 ({pca_2.explained_variance_ratio_[0]:.1%})')
plt.ylabel(f'PC2 ({pca_2.explained_variance_ratio_[1]:.1%})')
plt.title('PCA降维可视化(无着色)')
plt.grid(True, alpha=0.3)
plt.suptitle('PCA降维可视化(前2个主成分)', fontsize=14)
plt.tight_layout()
plt.show()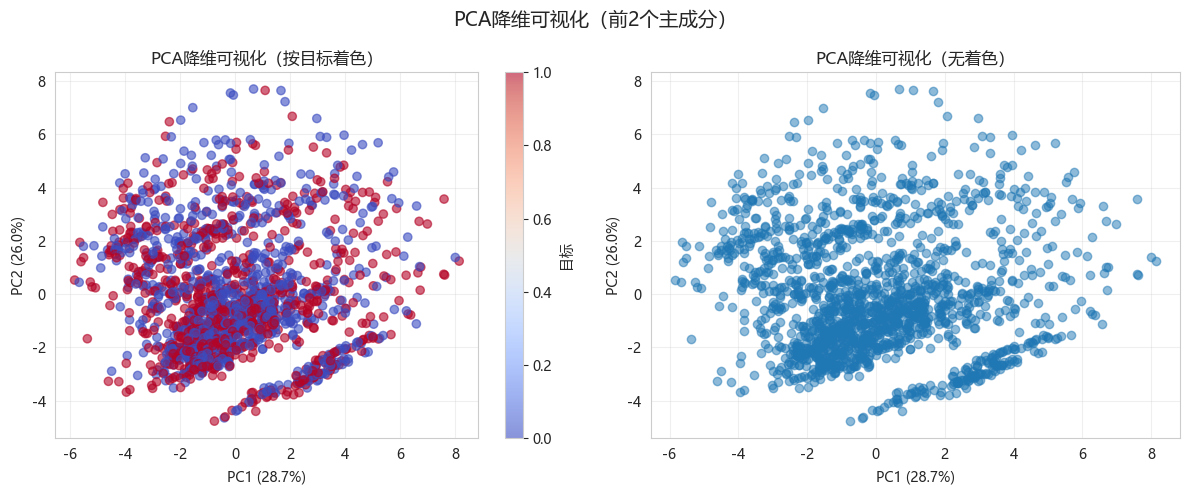
9.2 热力图对比
python
# 原始特征相关性
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 原始特征相关矩阵
corr_original = pd.DataFrame(X_train_scaled, columns=technical_cols).corr()
sns.heatmap(corr_original, ax=axes[0], cmap='coolwarm', center=0,
cbar_kws={"shrink": 0.8})
axes[0].set_title(f'原始特征相关矩阵 ({X_train_scaled.shape[1]}维)')
# PCA后特征相关矩阵(应为对角矩阵)
X_pca_full = pca_full.transform(X_train_scaled)
corr_pca = pd.DataFrame(X_pca_full, columns=[f'PC{i+1}' for i in range(X_pca_full.shape[1])]).corr()
sns.heatmap(corr_pca, ax=axes[1], cmap='coolwarm', center=0,
cbar_kws={"shrink": 0.8})
axes[1].set_title('PCA后特征相关矩阵(已去相关)')
plt.tight_layout()
plt.show()
print("\nPCA的一个重要性质:新特征之间相互正交(无相关性)")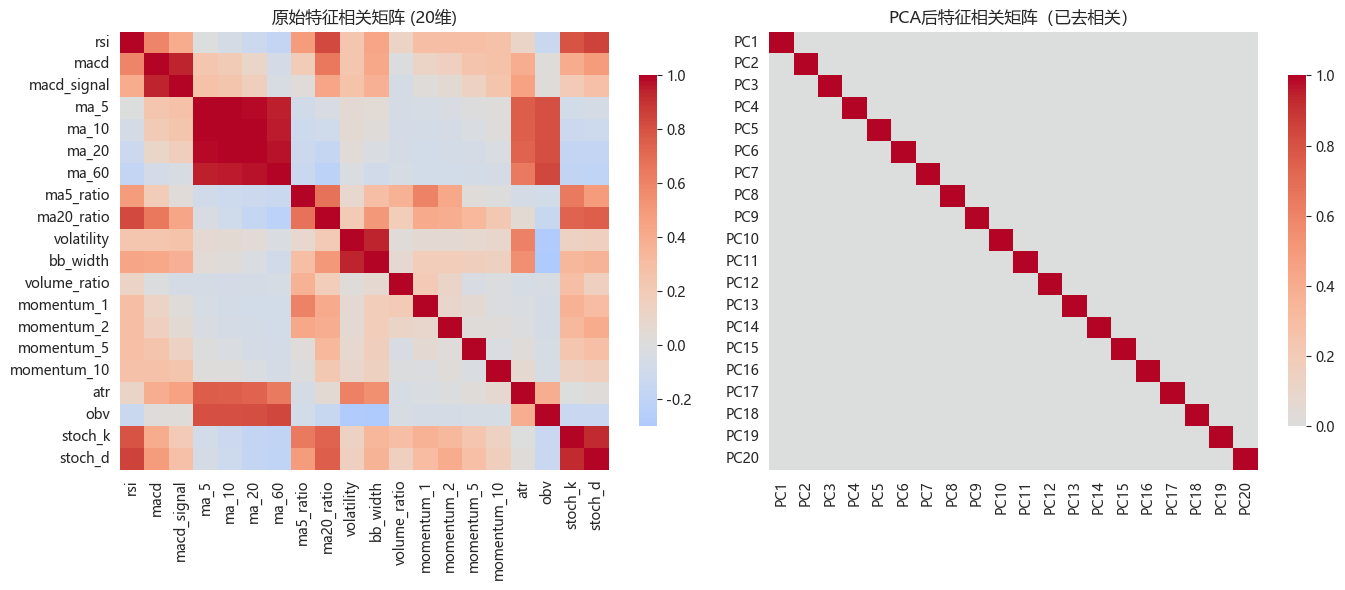
PCA的一个重要性质:新特征之间相互正交(无相关性)10. PCA vs 特征选择对比
10.1 方差阈值特征选择
python
from sklearn.feature_selection import VarianceThreshold
# 方差阈值选择(保留方差>0.1的特征)
selector = VarianceThreshold(threshold=0.1)
X_train_var = selector.fit_transform(X_train_scaled)
X_test_var = selector.transform(X_test_scaled)
selected_features = [technical_cols[i] for i in range(len(technical_cols)) if selector.get_support()[i]]
print(f"原始特征数: {X_train_scaled.shape[1]}")
print(f"方差阈值选择后: {X_train_var.shape[1]} 个特征")
print(f"保留的特征: {selected_features}")
#训练模型
rf_var = RandomForestClassifier(n_estimators=100, random_state=42)
rf_var.fit(X_train_var, y_train)
var_auc = roc_auc_score(y_test, rf_var.predict_proba(X_test_var)[:, 1])
print(f"方差阈值选择 AUC: {var_auc:.4f}")原始特征数: 20
方差阈值选择后: 20 个特征
保留的特征: ['rsi', 'macd', 'macd_signal', 'ma_5', 'ma_10', 'ma_20', 'ma_60', 'ma5_ratio', 'ma20_ratio', 'volatility', 'bb_width', 'volume_ratio', 'momentum_1', 'momentum_2', 'momentum_5', 'momentum_10', 'atr', 'obv', 'stoch_k', 'stoch_d']
方差阈值选择 AUC: 0.518910.2 方法对比
python
print("="*60)
print("降维方法综合对比")
print("="*60)
results_compare = pd.DataFrame([
{'方法': '原始特征', '特征数': X_train_scaled.shape[1],
'累积方差': '100%', 'AUC': roc_auc_score(y_test, y_proba_orig)},
{'方法': 'PCA(3主成分)', '特征数': 3,
'累积方差': f'{np.sum(pca_3.explained_variance_ratio_):.1%}',
'AUC': roc_auc_score(y_test, y_proba_pca)},
{'方法': '方差阈值选择', '特征数': X_train_var.shape[1],
'累积方差': 'N/A', 'AUC': var_auc}
])
print(results_compare.to_string(index=False))============================================================
降维方法综合对比
============================================================
方法 特征数 累积方差 AUC
原始特征 20 100% 0.518934
PCA(3主成分) 3 65.7% 0.502029
方差阈值选择 20 N/A 0.51893411. 今日总结
-
PCA核心原理:
- 找到方差最大的投影方向
- 通过特征分解协方差矩阵求解
- 主成分之间相互正交
-
主成分数量选择:
- 累积方差解释率(常用95%阈值)
- Scree Plot(肘部法则)
- 交叉验证(面向具体任务)
-
可解释性分析:
- 载荷矩阵:原始特征与主成分的关系
- 载荷绝对值越大,相关越强
- 可根据载荷为主成分命名
-
注意事项:
- 使用前必须标准化
- PCA假设线性关系
- 可解释性降低
-
扩展作业
- 作业1:尝试使用核PCA处理非线性数据
- 作业2:使用PCA进行异常检测(重构误差)
- 作业3:对比PCA和其他降维方法(t-SNE, UMAP)
- 作业4:在实际股票数据上测试不同主成分数量的策略表现
-
今日收获(3个)
- 理解了PCA的最大方差投影原理
- 掌握了载荷矩阵解读和主成分命名方法
- 学会了用PCA降维提升模型训练速度
-
量化思考
- PCA可以帮助识别市场的主要风险因子
- 降维后的特征可以用于构建更稳定的模型
- 主成分命名需要结合业务知识
- 适合特征高度相关的场景