|-------------------------------------------------------------------------------------------------------------|
| 导读 普通聊天机器人只需要回答得对,而 Agent 不一样:它会调用工具、读写文件、执行命令、访问外部系统。只要它能"行动",安全边界就必须从入口、权限、运行环境、凭证、网络、上下文和回滚多个层面一起设计。 |
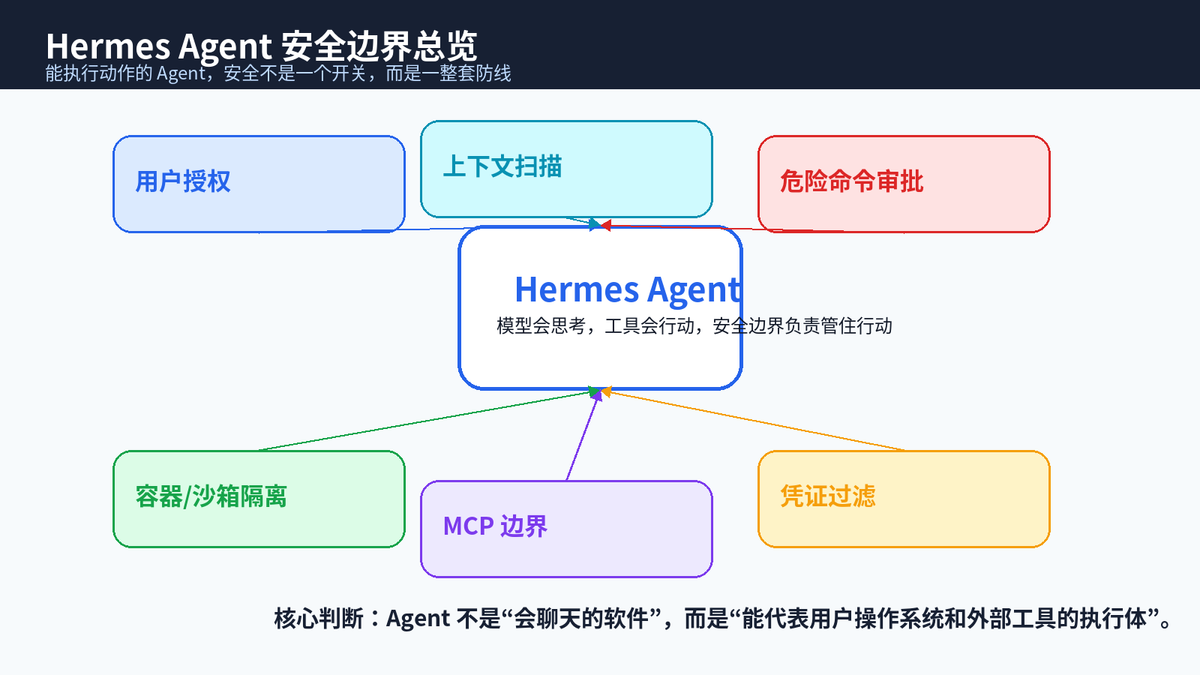
一、先说结论:Hermes 的安全边界到底在保护什么?
Hermes Agent 的安全设计,可以用一句话理解:不要让模型的"想法"直接变成系统里的"动作"。模型可以提出计划,但执行命令、读取文件、访问网页、调用 MCP Server、修改项目代码之前,都需要经过一层或多层安全控制。
这套设计背后的现实问题很简单:Agent 可能受到 Prompt Injection 影响,可能误判任务意图,可能执行破坏性命令,可能把密钥暴露给工具,可能通过浏览器访问内网地址,也可能在多用户 Gateway 场景中被未授权用户调用。Hermes 的思路不是赌模型永远正确,而是把风险拆成多个边界逐层处理。

二、第一层:用户授权,先判断"谁能和 Agent 说话"
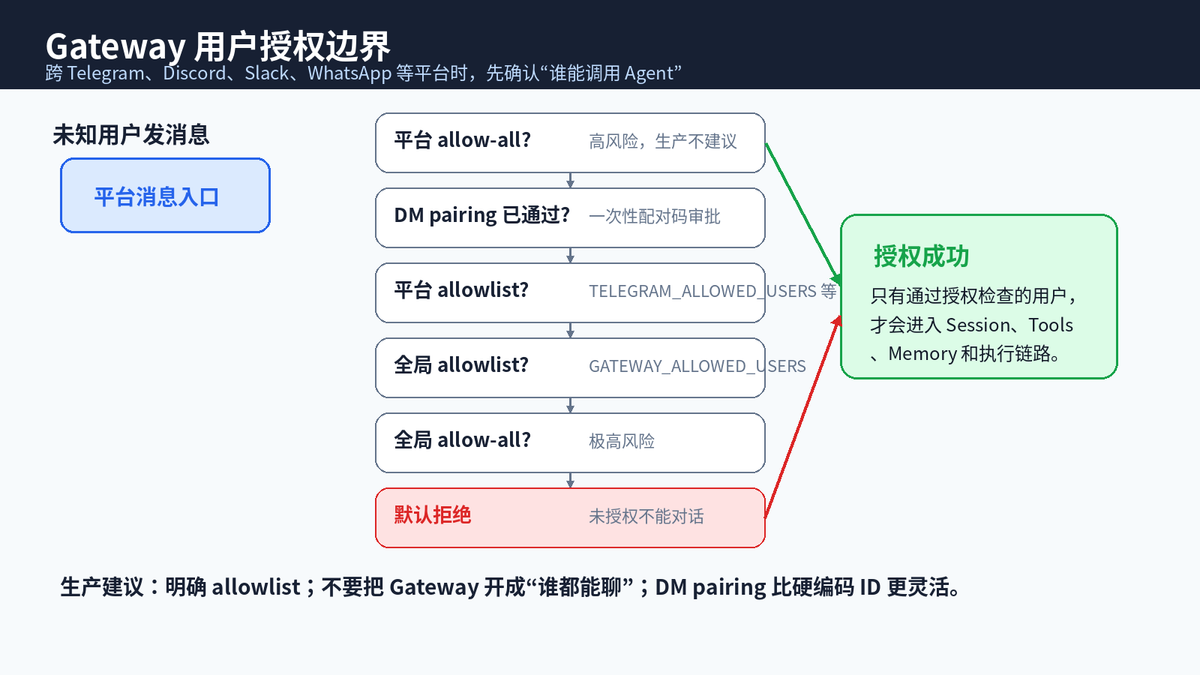
当 Hermes 只在本地 CLI 里使用时,风险主要来自当前用户自己;但一旦它接入 Telegram、Discord、Slack、WhatsApp、Signal、Matrix、Teams 等消息平台,就变成一个可被远程触达的 Agent 服务。这个时候,最先要守住的不是命令执行,而是入口授权。
Hermes Gateway 的授权检查会按顺序判断:平台级 allow-all、DM pairing 已批准用户、平台 allowlist、全局 allowlist、全局 allow-all,最后默认拒绝。这个默认拒绝很重要,因为 Agent 一旦被陌生人调用,就可能被诱导去执行文件操作、访问外部系统或泄露上下文。
|-------------------------------------------------------------------------------------------------------------|
| 落地建议 生产环境不要使用 GATEWAY_ALLOW_ALL_USERS=true。更稳妥的做法是:使用平台 allowlist 或 DM pairing,并把 Gateway 运行目录限制在非敏感路径。 |
三、第二层:危险命令审批,让"高风险动作"停下来问一句
Agent 最危险的能力之一,是通过 terminal 工具执行 shell 命令。比如删除文件、清空目录、修改系统配置、重置 Git 状态、杀进程、启动或停止服务,这些操作一旦执行,后果可能比一句错误回答严重得多。
Hermes 的危险命令审批机制,会在命令执行前检查危险模式。如果命中,就进入人类审批流程。CLI 里用户可以选择 once、session、always 或 deny;消息平台里则通过 yes/no 类回复来批准或拒绝。
Hermes 还支持 manual、smart、off 三种审批模式。manual 是默认模式,危险命令总是询问用户;smart 会使用辅助模型评估风险,低风险自动放行,高风险自动拒绝,不确定时升级为人工审批;off 则会绕过安全提示,相当于 YOLO,只适合高度可信环境。

四、第三层:运行时隔离,命令到底跑在哪里?
同样是执行一条命令,跑在本机和跑在容器里,风险完全不同。local 后端意味着命令直接以当前用户权限访问本机文件系统;docker、modal、daytona、vercel_sandbox、singularity 等后端则把执行环境和宿主机隔开。
官方文档把 terminal backend 分成多种:local 适合个人开发和可信场景;ssh 适合把执行放到远程机器;docker 适合生产 Gateway;modal/daytona/vercel_sandbox 适合云端沙箱;singularity 适合 HPC 或共享机器。

Docker 后端还会使用安全参数进行加固,例如 drop capabilities、no-new-privileges、限制进程数、tmpfs 挂载、资源限制等。理解这一点很关键:容器不是为了"跑得更方便",而是为了让 Agent 的错误操作不直接伤到宿主机。
五、第四层:凭证过滤,不把所有密钥交给模型生成的代码
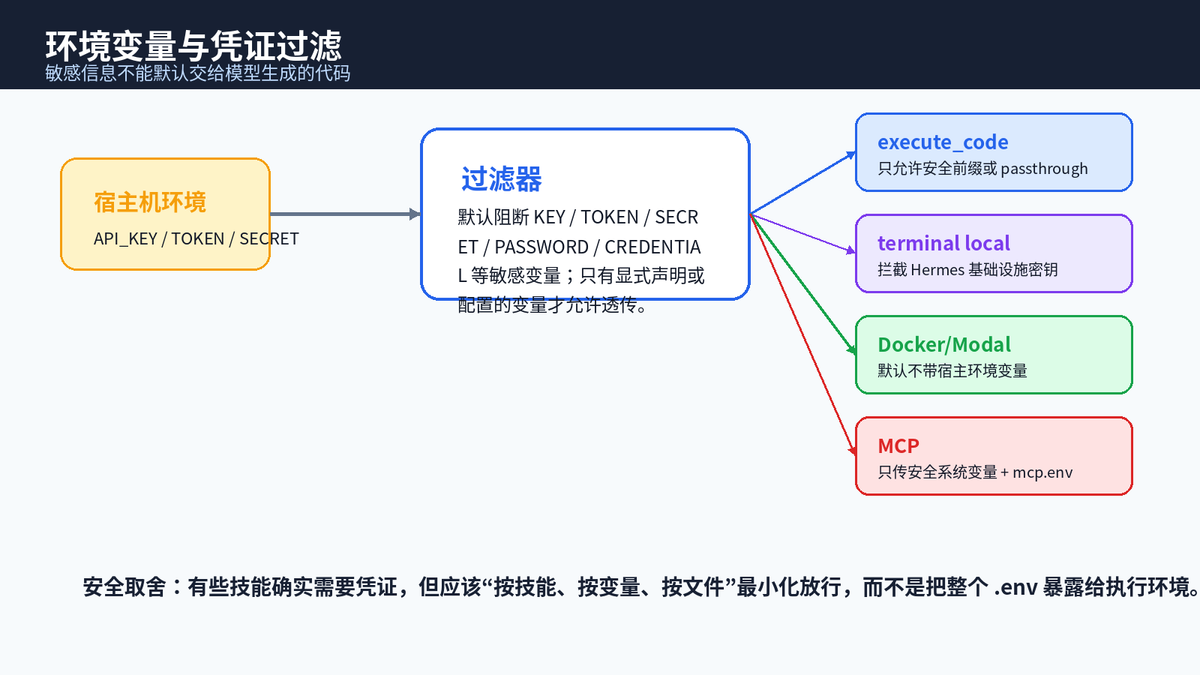
Agent 经常需要访问外部服务,比如 GitHub、Google Workspace、数据库、内部 API。问题是,凭证一旦进入模型可见上下文或任意执行环境,就可能通过错误日志、工具输出、恶意网页、Prompt Injection 被外传。
Hermes 的思路是默认过滤敏感环境变量,只有明确声明或配置的变量才允许透传。execute_code 会拦截包含 KEY、TOKEN、SECRET、PASSWORD、CREDENTIAL、PASSWD、AUTH 等敏感关键词的变量;Docker/Modal 默认不带宿主环境变量;技能需要的变量可以通过 required_environment_variables 声明;凭证文件则可按只读方式挂载。
|-----------------------------------------------------------------------------------------|
| 关键判断 "能拿到密钥"不等于"应该默认拿到所有密钥"。更好的设计是:按技能、按工具、按任务最小化授权,并且让凭证尽量停留在执行边界,而不是进入 Prompt 正文。 |
六、第五层:MCP 安全边界,外部工具接得越多,治理越重要
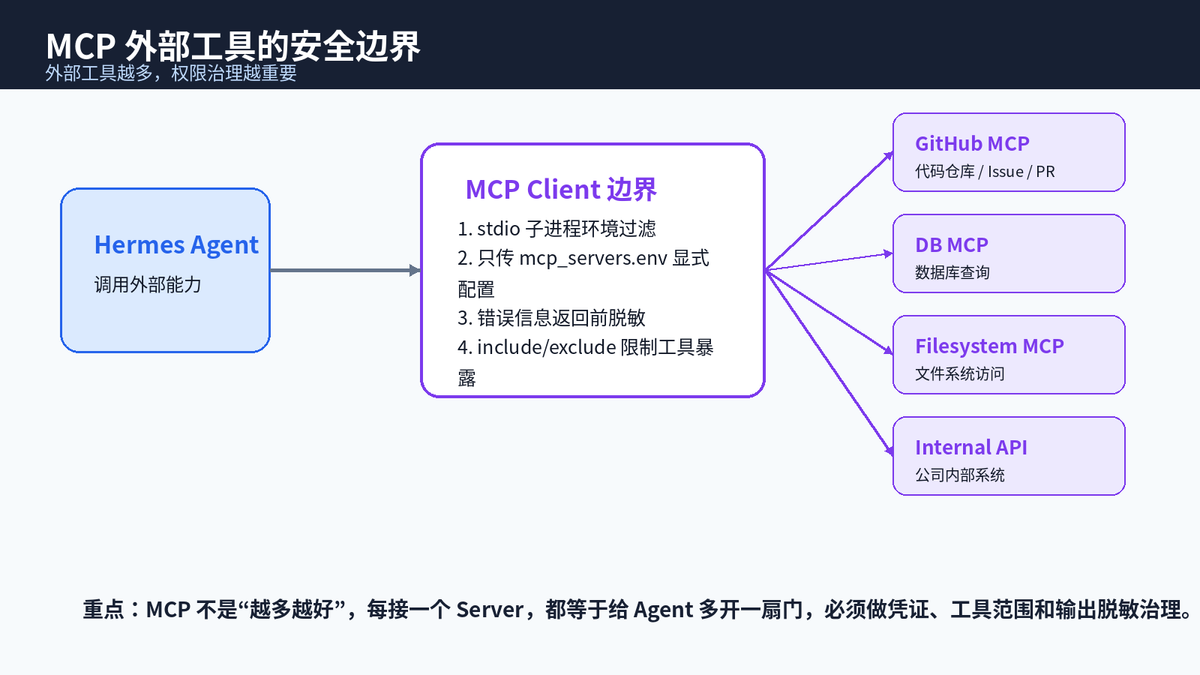
MCP 让 Hermes 可以接入 GitHub、数据库、文件系统、浏览器栈、公司内部 API 等外部工具。能力强了,风险也随之扩大:每接一个 MCP Server,就相当于给 Agent 多开一扇门。
Hermes 对 MCP 子进程的环境变量做了隔离:默认只传 PATH、HOME、USER、LANG、LC_ALL、TERM、SHELL、TMPDIR 和 XDG_* 这类安全系统变量;其他 API key、token、secret 会被剥离。只有在 mcp_servers.env 中显式配置的变量才会传入对应 MCP Server。
此外,MCP 工具的错误信息返回给模型前会做脱敏,例如 GitHub PAT、OpenAI-style key、Bearer token、token=、key=、API_KEY=、password=、secret= 等模式会被替换为 REDACTED。
七、第六层:Web、Browser 与 SSRF 防护,防止 Agent 被诱导访问内网
联网能力是 Agent 的重要能力,但也是典型攻击入口。一个恶意网页、一段工具返回内容,可能诱导 Agent 去访问内网管理后台、云厂商元数据地址、localhost 服务,造成 SSRF 类风险。
Hermes 对 URL-capable tools 进行访问校验,包括 web_search、web_extract、browser、vision 等。它会阻断私有网段、loopback、link-local、CGNAT、云元数据主机名、保留地址等,并且会在重定向链路的每一跳重新校验。DNS 失败也按 fail-closed 处理。
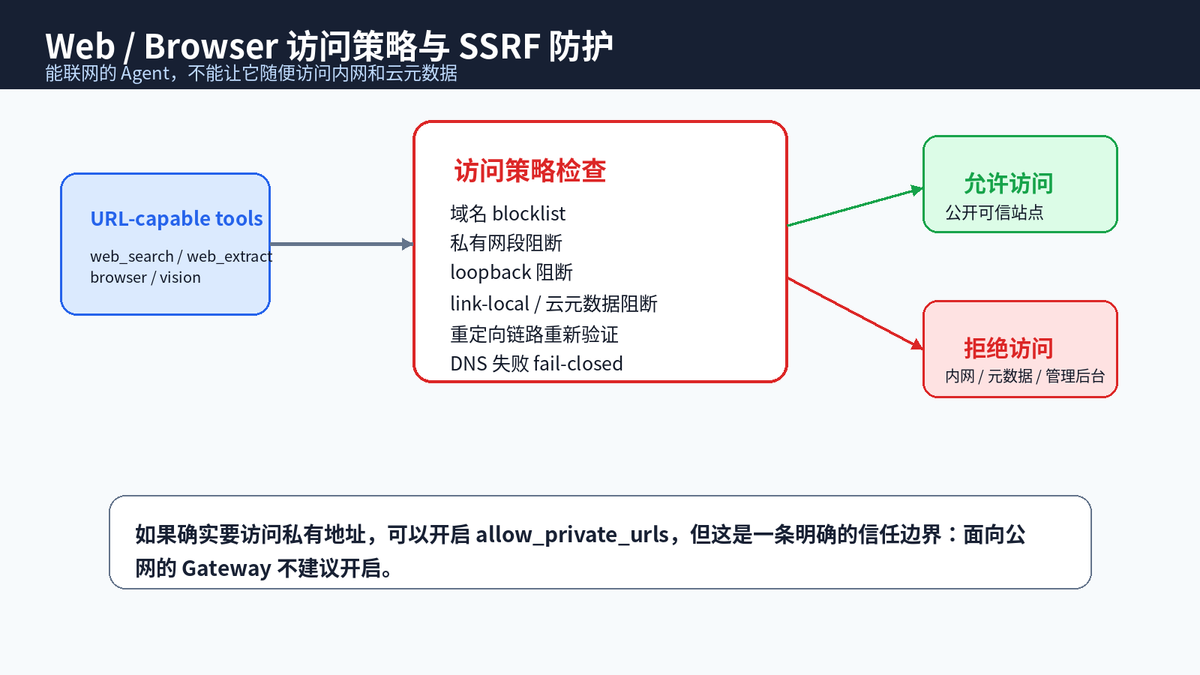
如果确实有访问内网的合理需求,可以通过 allow_private_urls 放开,但这本质上是在扩大信任边界。面向公网的 Gateway 不建议开启。
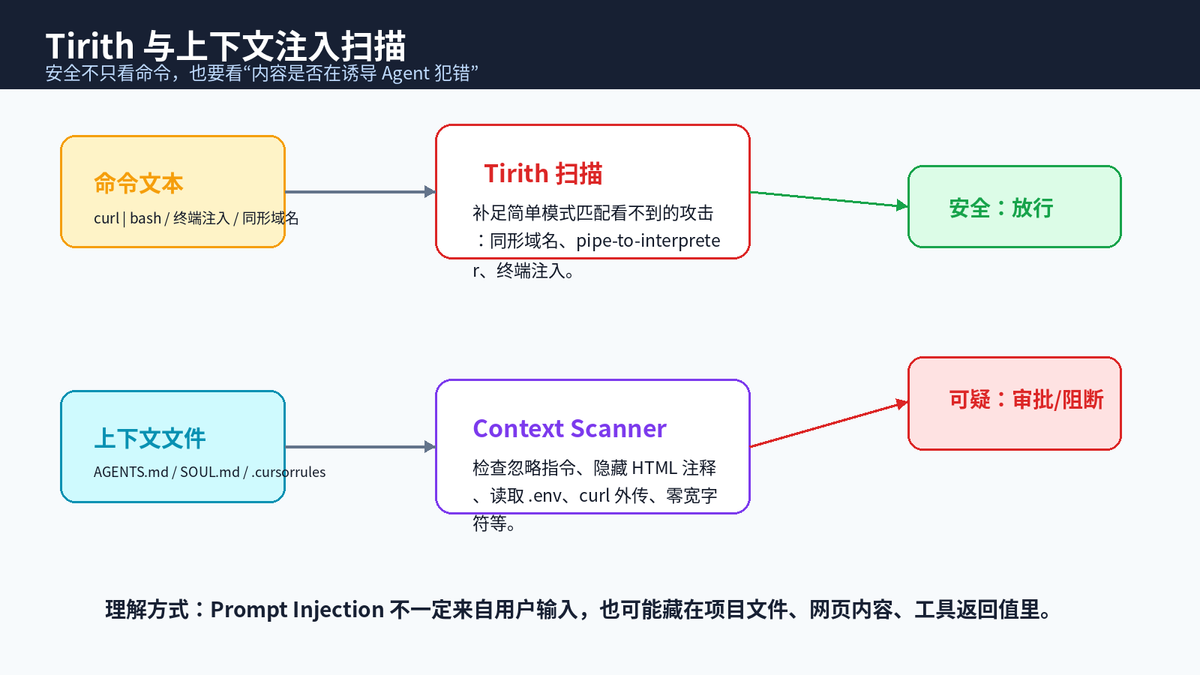
八、第七层:Tirith 与上下文文件扫描,防 Prompt Injection
很多人以为安全只发生在命令执行阶段,其实 Agent 的安全问题还可能藏在上下文里。项目里的 AGENTS.md、SOUL.md、.cursorrules,网页里的隐藏文本,工具返回值里的恶意指令,都可能诱导模型忽略原始规则、读取密钥、把凭证发到外部地址。
Hermes 集成 Tirith 做命令级内容扫描,用来发现同形域名、curl | bash、wget | sh、终端注入等模式。Tirith 的 verdict 会进入审批流:安全命令放行,可疑或阻断命令触发用户审批,默认选择是拒绝。
同时,Context files 在进入系统提示词前会扫描 Prompt Injection 风险,例如"忽略之前的指令"、隐藏 HTML 注释、尝试读取 .env、curl 外传凭证、零宽字符和双向覆盖字符等。
九、Checkpoints 与 /rollback:最后一道"可恢复"安全网
安全系统不能只考虑"拦住",还要考虑"拦不住时如何恢复"。Hermes 的 Checkpoints 与 /rollback 机制,就是为文件修改和破坏性操作准备的恢复通道。
官方文档说明,Checkpoints 可以在 write_file、patch、rm、rmdir、cp、install、mv、sed -i、truncate、dd、shred、输出重定向、git reset/clean/checkout 等操作前自动拍快照。它使用一个共享的 shadow git store,位于 ~/.hermes/checkpoints/store/,不会触碰项目自己的 .git。
需要注意的是,Checkpoints v2 默认关闭,需要 per-session 使用 --checkpoints 或在 config.yaml 里启用。它适合作为 Agent 文件操作的安全网,但不是替代正常 Git 分支、代码评审和备份策略。

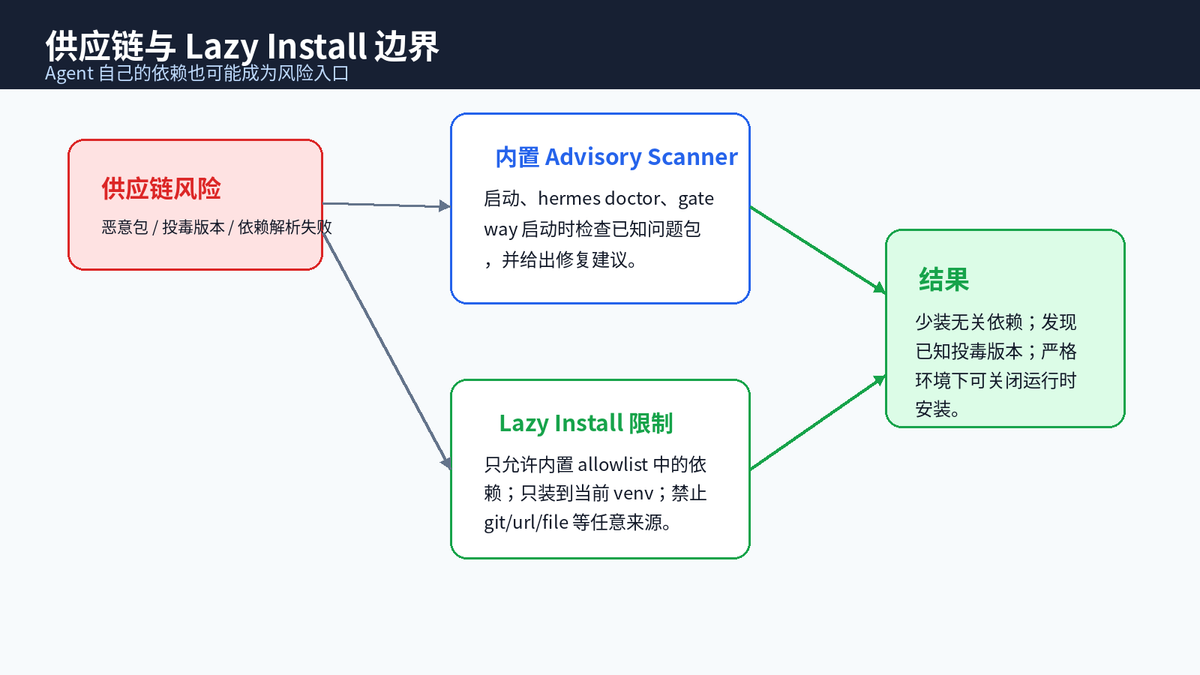
十、供应链安全:Agent 自身依赖也要被纳入边界
Agent 系统往往依赖很多可选能力:语音、消息平台、记忆插件、云服务、模型供应商 SDK 等。如果把所有 extras 一次性装完,既膨胀,也更容易被依赖投毒、包失效、镜像污染影响。
Hermes 使用 advisory scanner 检查已知受影响的 Python 包版本,并在 CLI 启动、hermes doctor、Gateway 启动等场景提醒用户。它还采用 lazy install:只有首次使用某项能力时才安装依赖,并且安装被限制在当前 venv、只允许内置 allowlist 中的 PyPI 包名和版本范围,不允许 git URL、file 路径或自定义 index-url。
十一、生产部署安全清单:从"能跑"到"敢跑"
如果只是本地测试 Hermes,很多风险还能靠使用者自己兜底;如果要作为团队 Gateway 或长期运行的自动化 Agent,就必须按生产服务的标准部署。
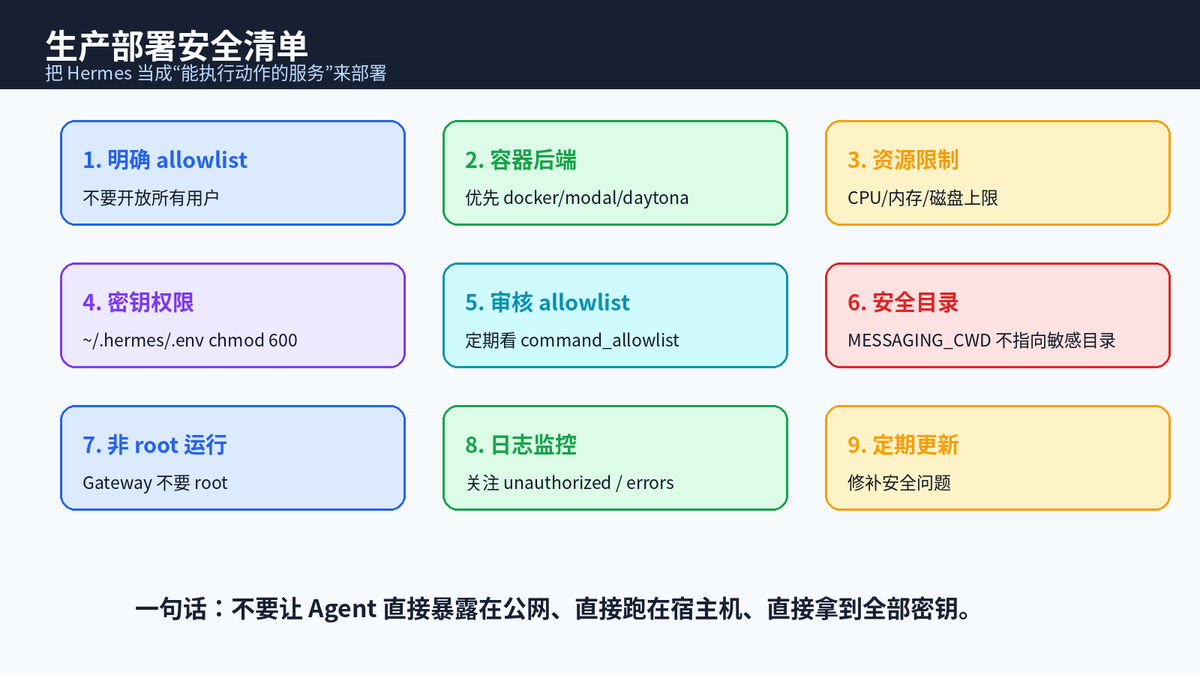
推荐实践包括:配置明确 allowlist,不开放全部用户;使用 docker、modal、daytona 或 vercel_sandbox 等隔离后端;设置 CPU、内存、磁盘限制;.env 文件 chmod 600;定期检查 command_allowlist;MESSAGING_CWD 不指向敏感目录;Gateway 不以 root 运行;监控日志;保持版本更新。
十二、源码阅读路线:想深入就沿着安全链路读
如果你只是写文章或做技术调研,看官方文档已经够用;如果你要做二次开发,就应该沿着"入口 -> 审批 -> 执行 -> 回滚 -> 日志"的路径去读 GitHub 源码。
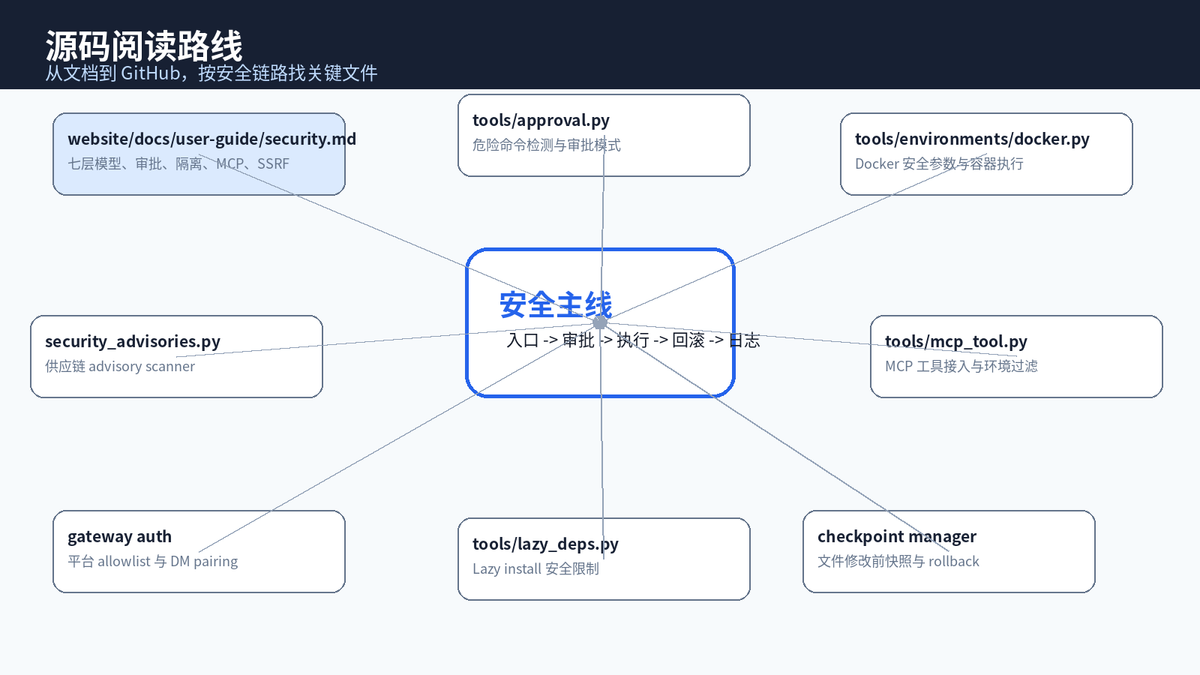
可以先从 website/docs/user-guide/security.md 建立七层模型,再看危险命令审批、terminal 后端、Docker 环境、MCP 工具、Checkpoint Manager、Lazy Deps、Gateway Auth、Security Advisories 等模块。GitHub Release 中也能看到很多安全修复线索,比如路径穿越、shell injection、symlink boundary、prompt injection bypass、cron prompt injection scanner、.env 权限等。
十三、总结:Hermes 的安全设计给 AI Agent 工程带来什么启发?
**第一,安全边界要分层。**用户授权、命令审批、容器隔离、凭证过滤、MCP 边界、上下文扫描、输入净化,各管一段风险。
**第二,默认应该保守。**Gateway 默认拒绝未授权用户,凭证默认过滤,内网地址默认阻断,危险命令默认需要审批。
**第三,执行环境要隔离。**能跑 Docker、云沙箱或远程机器,就不要让生产 Agent 直接在宿主机上乱跑。
**第四,凭证要最小权限。**只把任务真正需要的变量或文件交给对应工具,避免把整份 .env 暴露出去。
**第五,必须考虑恢复能力。**Checkpoints 与 /rollback 让文件误改后有机会回退,但仍不能代替正常 Git 和备份。
|--------------------------------------------------------------------------------------|
| 一句话收尾 Hermes Agent 的安全边界不是为了限制 Agent,而是为了让 Agent 可以真正进入生产环境:敢执行、可审批、能隔离、可追踪、能恢复。 |