在最近这段时间里,MCP 和 Skills 可以说是 AI 圈里最热门的两个词了,我们总能刷到很多关于它们的讨论。
如果你:
已经接过 MCP,却发现输出并不稳定;
或者写过 Skills,却不确定什么时候还需要引入 MCP;
又或者正在疑惑:为什么我的 AI 用起来感觉有点降智了,可以怎么优化?
那这篇文章或许能帮你把这几件事搞明白。
我们会把 MCP 和 Skills 分开讲清楚:各自解决什么问题,各自的边界在哪。
然后再把它们放回同一条链路里,看看它们是如何分层协作的。
最后用一个小例子走一遍执行过程------根据 Git 提交记录自动生成周报。
先划重点
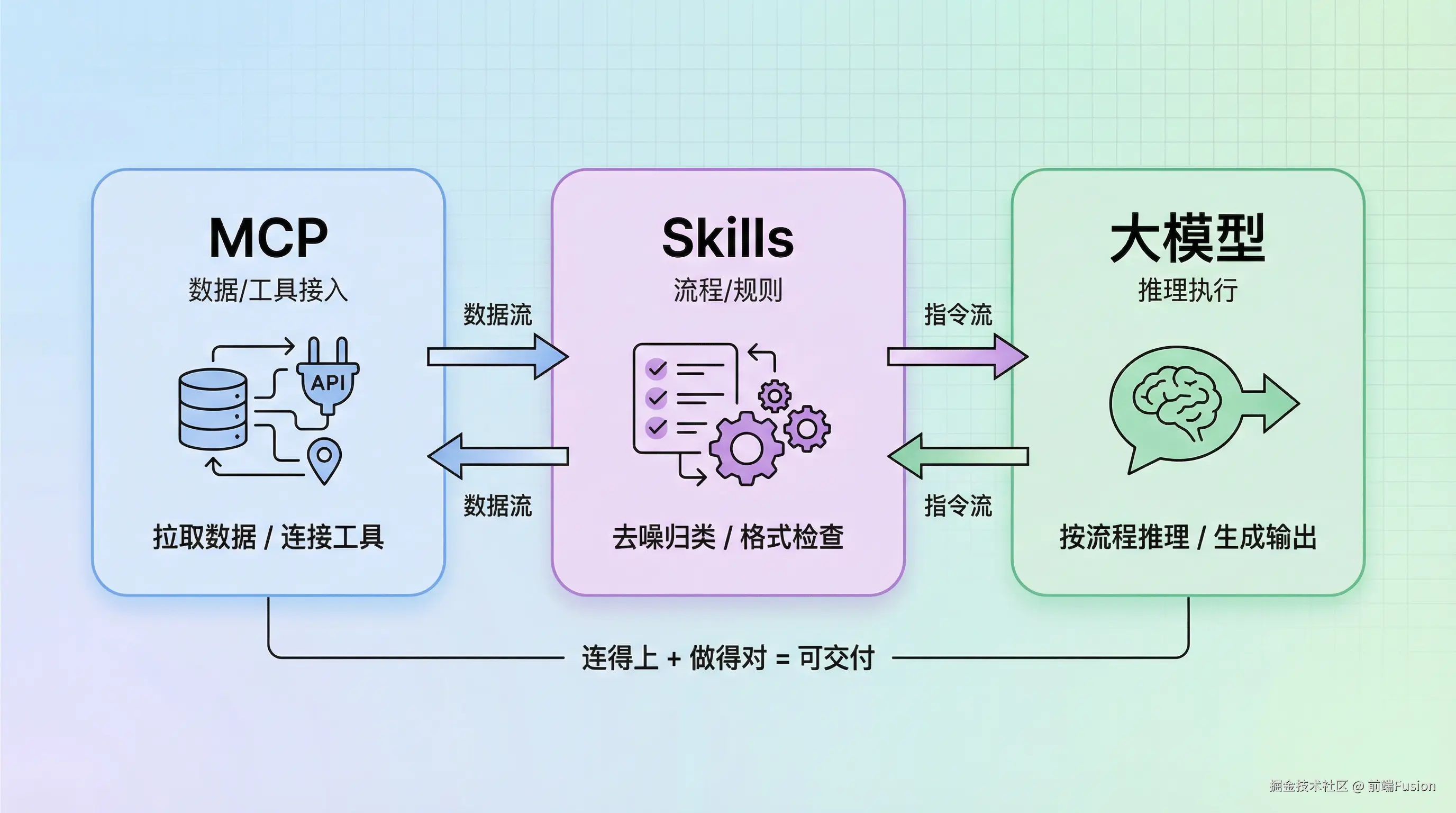
大模型只负责推理 ,不负责行动。
MCP解决的是:模型能不能连上外部能力。
Skills解决的是:连上之后流程能不能稳定交付。MCP 负责数据从哪来,Skills 负责拿到数据后怎么走,模型负责在这条路径上推理。
先从大模型的短板说起
大模型(LLM)本身只会做一件事:预测下一段文本。
它可以思考,可以分析语言,可以从给定的上下文信息中推导出答案。
但它无法仅靠自己执行具体有意义的任务。
比如让它联网搜索最新资料,或者直接发一封邮件。
没有工具,它最多只能把「应该怎么做」说得很像,但无法把事情真正做成。
所以大模型需要工具来执行有意义的任务。
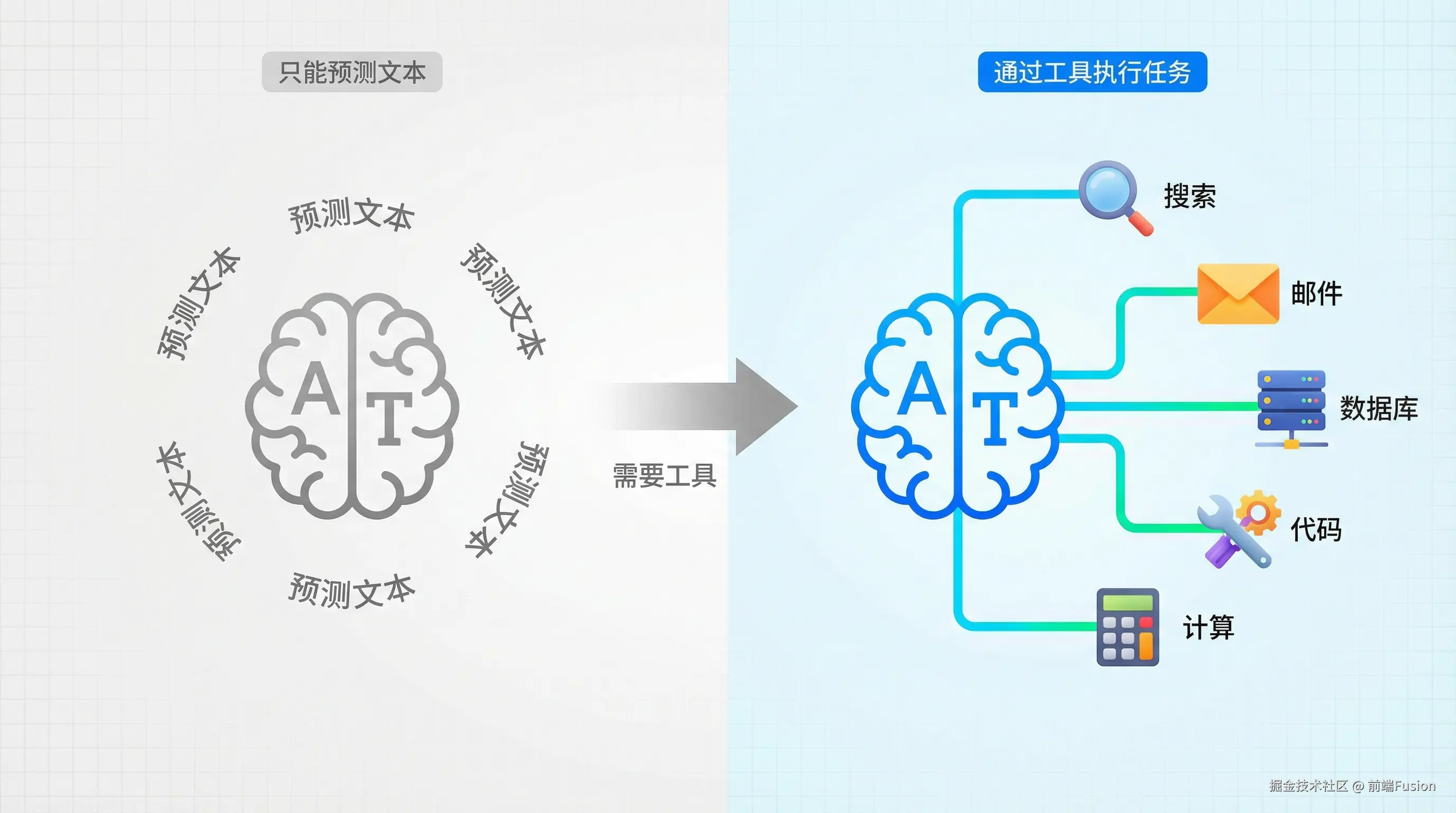
各种工具层层叠加,协同工作
我们还是用「联网搜索」这个例子往下推一步。
你在一些产品里看到的大模型能联网搜索最新资料,并不是因为大模型自己突然学会了上网。
更常见的情况是:产品在模型旁边接了一个搜索/检索工具,让它可以去查询外部信息源(比如搜索引擎、知识库),再把结果交回给模型生成回答。
当我们把更多工具接进来,它当然会更强。
但新的问题也会马上出现。
拿一个很常见的任务来说:每周整理工作周报。
我们手动整理周报通常要翻好几个地方:看看这周提交了哪些代码、开了哪些会、完成了什么功能,然后一个个记下来。
如果想让 AI 自动帮你生成,它就需要同时连上好几个工具:从 GitLab 拉提交记录、从 Notion 读取项目文档、从日历拿会议安排,最后按固定格式输出。
这就是典型的多工具协同场景。
工具越多,就越像在强行拼凑一堆不同的东西。
每个工具都像在说它自己的语言,API 的工作方式也没有统一标准,需要传递的信息各不相同。
这时候,就需要一个标准来把连接方式统一起来。
MCP 就是这个标准
MCP,全称 Model Context Protocol(模型上下文协议)。
说白了,它就是一套标准规则,让 AI 能和各种外部工具对接起来。
你可以把 MCP 想象成 USB-C 接口。
USB-C 提供了连接各种电子设备的标准方式。
MCP 做的事情类似,它为 AI 应用提供了连接外部系统的标准方式 ,例如文档系统、代码库、数据库、本地文件系统。
更具体地说,MCP 是大模型与各种工具、服务之间的中间层 ,负责翻译。
它把不同工具、服务的语言转化为一种统一的语言,让大模型能够更简单地连接并访问外部资源与外部数据库。
如果用最简的链路来记,它看起来像这样:
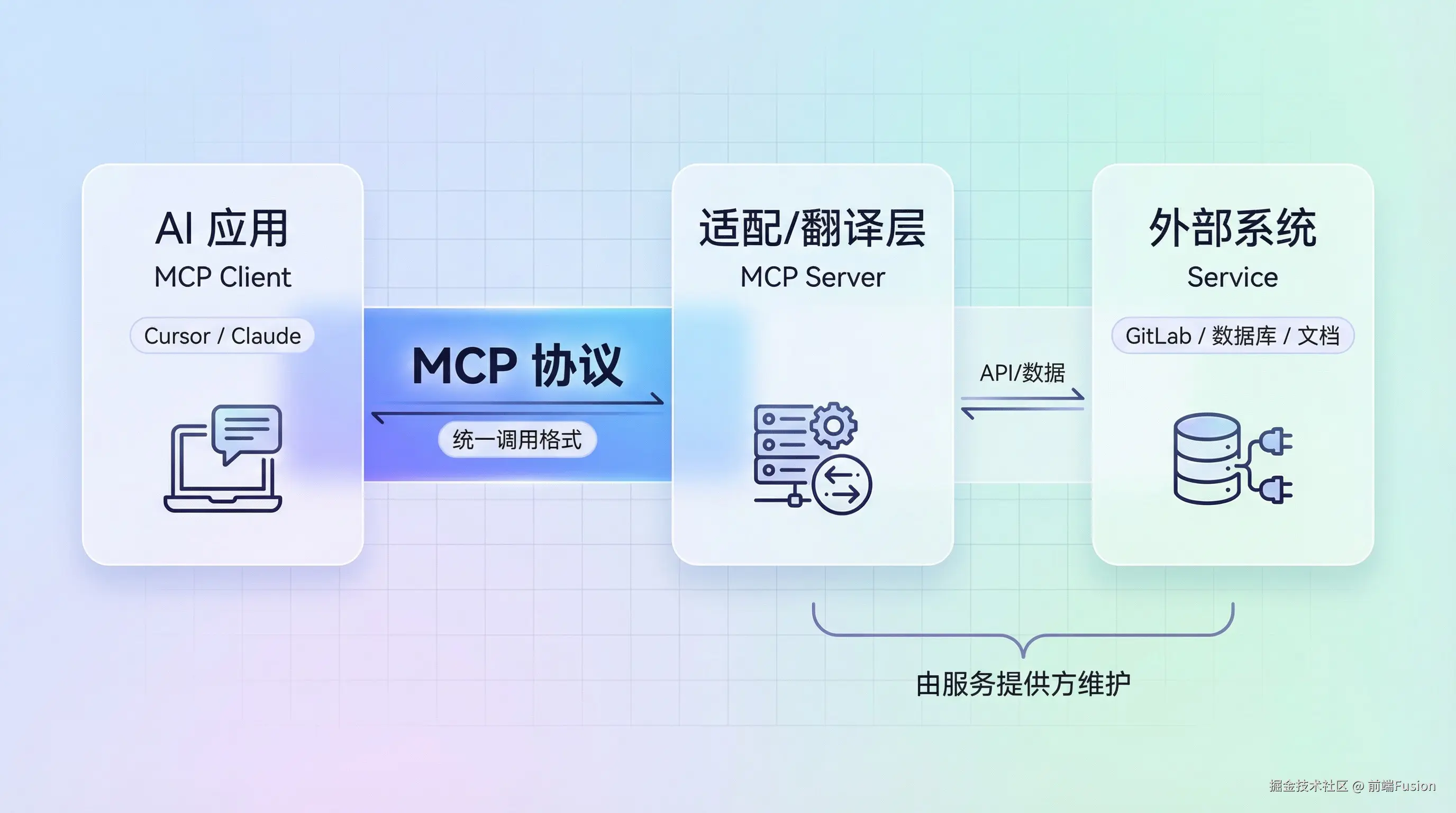
MCP Client 是你正在用的 AI 应用端,比如 Cursor、Claude 这类客户端。
MCP Server 更像一层适配/翻译层,由服务提供方构建和维护。它把某个外部系统的能力包装成大模型能理解、能调用的统一形态。
Service 才是最终的外部系统,比如 GitLab、数据库、文件系统。
而 MCP 就是 Client 和 Server 之间的一套统一协议。
MCP Server 会把某个外部系统的能力,按这套协议「包装」成大模型能理解、能调用的统一形态。
AI 客户端再按同一套协议去调用它,于是大模型就能间接用上各种外部工具。
MCP 把「能不能连上」解决了。
更准确地说,MCP 实际上就是一套给大模型用外部工具的标准规范。
它把大模型和工具之间的集成方式统一起来,让「接入」这件事简单了很多。
为什么有了 MCP 还不够
到这里,模型已经能连上外部系统了。
能拿到数据,甚至能触发一些操作。
但连接并不等于任务完成。
前面我们提过周报这个场景,这里继续沿用它往下走。
我们的不少工作痕迹,其实都会留在各种系统里,Git 的提交记录就是其中一种。
同样的思路也可以扩展到很多日常信息源:这周参加了哪些会议、讨论过哪些问题、项目文档更新了什么。
那能不能把这些信息自动拉出来,先汇总成当周做了什么,再按固定格式生成一份周报呢?
现在我们已经接入了一个 GitLab 的 MCP Server,大模型终于能自动把这周的提交拉出来了。

如图,大模型借助 MCP 连接到 GitLab,并成功拉取了这周的提交记录。
它把 commit 记录一条条罗列出来,然而交付出来的并不是你想要的周报内容。
大模型如何基于这些信息生成周报呢?
大模型并不知道该从这些信息里挑什么、合什么、滤什么,更不知道你真正想要的周报长什么样。
提交记录已经拿到了,原材料 不缺,但离一份能发出去的周报,还差一套加工流程。
简单来说,就是工具都买齐了,但没人告诉你工具该怎么用。
MCP 帮你把工具接进来了,但它并不天然包含流程、标准与检查点。
这就轮到 Skills 上场了。
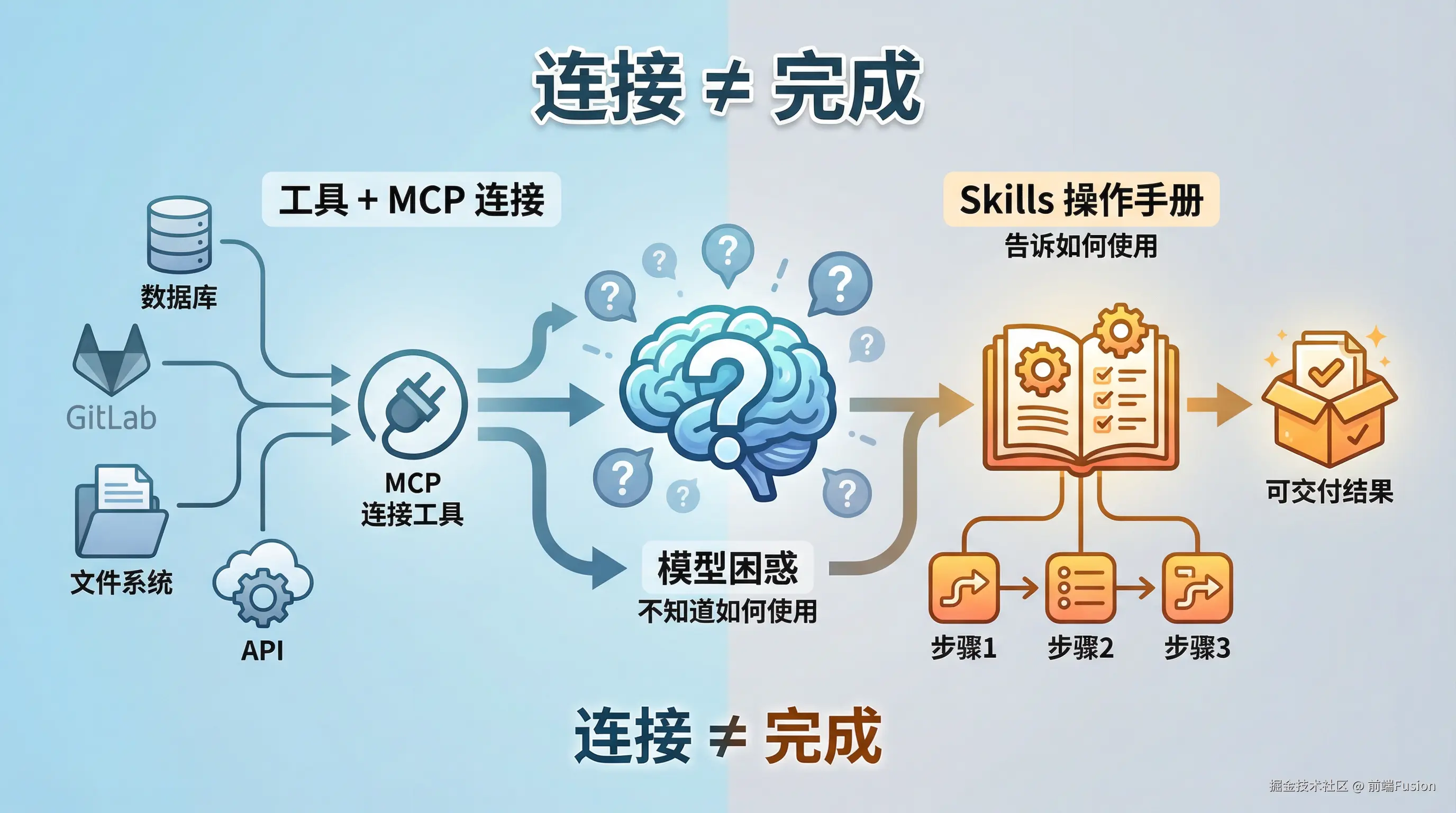
Skills 是什么
你可以把 Skills 当作是写给大模型的操作手册。
它解决的不是「能力」,而是「流程」。
MCP 负责把工具接进来,Skills 负责告诉大模型工具怎么用:
拿到数据之后,先做什么、后做什么,哪些步骤要检查,输出要长什么样。
它能把那些原本只存在于个人脑海、或每当团队新人加入时需要反复解释的知识体系沉淀下来。
更关键的是,Skills 把结果的可交付性放稳了。
它不只是让大模型输出一段看起来不错的文字,而是让大模型按步骤完成任务,并在关键节点做检查。
对应到上文提到的周报生成这个例子,就是把「提交记录」转化为「周报」:
MCP 负责把提交记录拉进来,Skills 则负责把「去噪、归类、按固定结构输出」这条流程写清楚。
渐进式披露:大量知识不撑爆上下文
当我们把流程写得越来越细,另一个问题就出现了。
这么多规则、这么多约束,一次性塞进上下文并不现实。
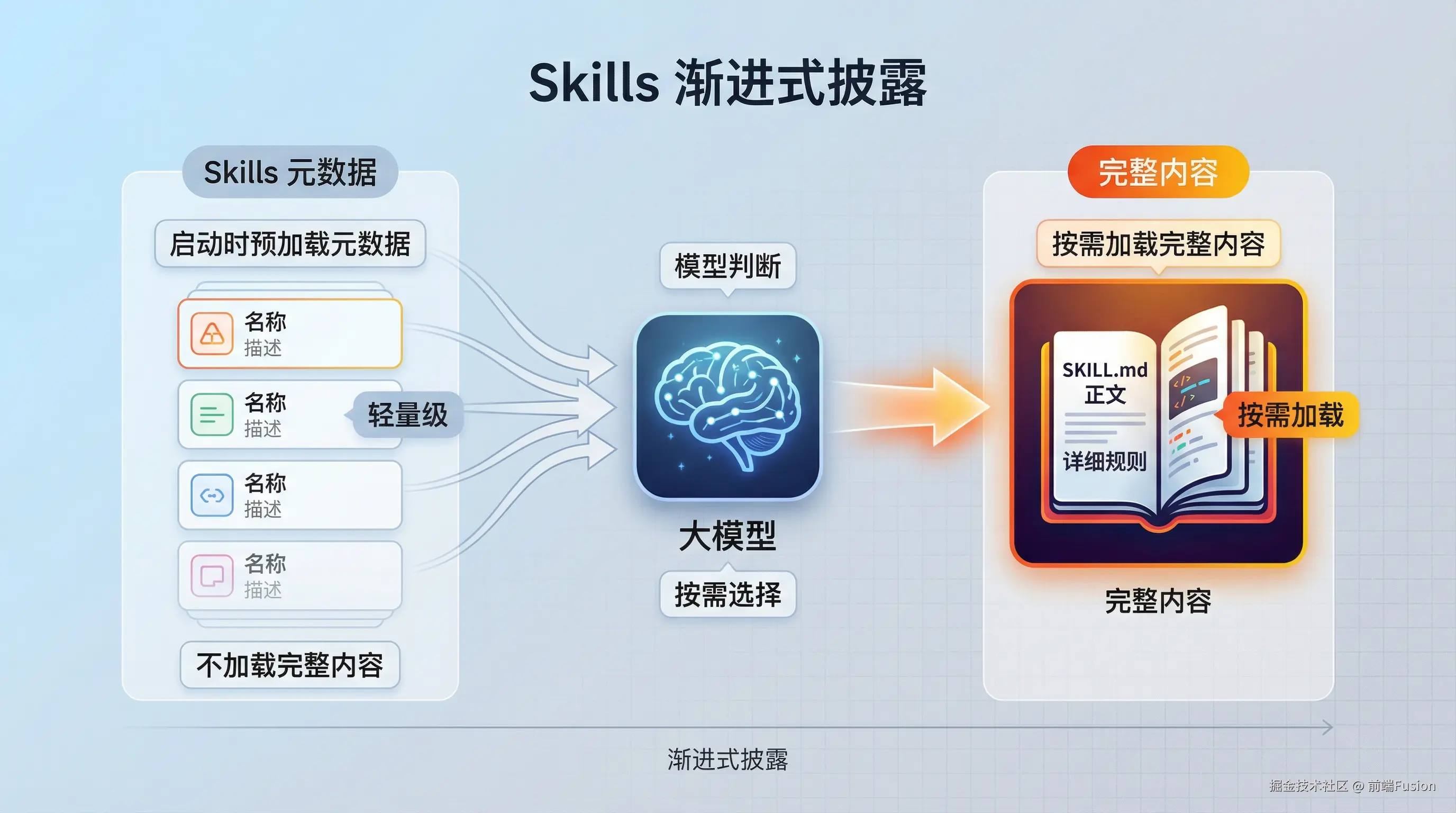
Skills 的一个重要设计是 渐进式披露。
启动时,大模型会将所有已安装技能的名称和描述预加载到其系统提示中。
这些元数据只提供足够的信息,让大模型知道何时应使用每个技能,而无需将所有内容加载到上下文中。
当大模型判断某个 Skill 与当前任务相关时,才会读取完整的 SKILL.md 正文来加载细节。
这意味着技能的正文可以包含大量信息,却不会每次都把上下文撑爆。
为什么 Skills 和 MCP 能完美协同?
因为它们各管一段:
MCP 让模型能够与外部数据、外部工具进行交互。
Skills 让模型能够按照你的意愿行事,沿着正确的路径前进,遵循正确的步骤。
它们并不是互相取代的关系,而是分层协作。
没有 MCP,Skills 无数据可用。
Skills 写得再好,如果大模型连提交记录都拿不到,流程就无从启动。
没有 Skills,MCP 只是工具接口。
数据即使拿到了,模型也只是做一遍泛泛的罗列或总结,结果很难直接用。
放在同一条链路上,才能形成闭环。
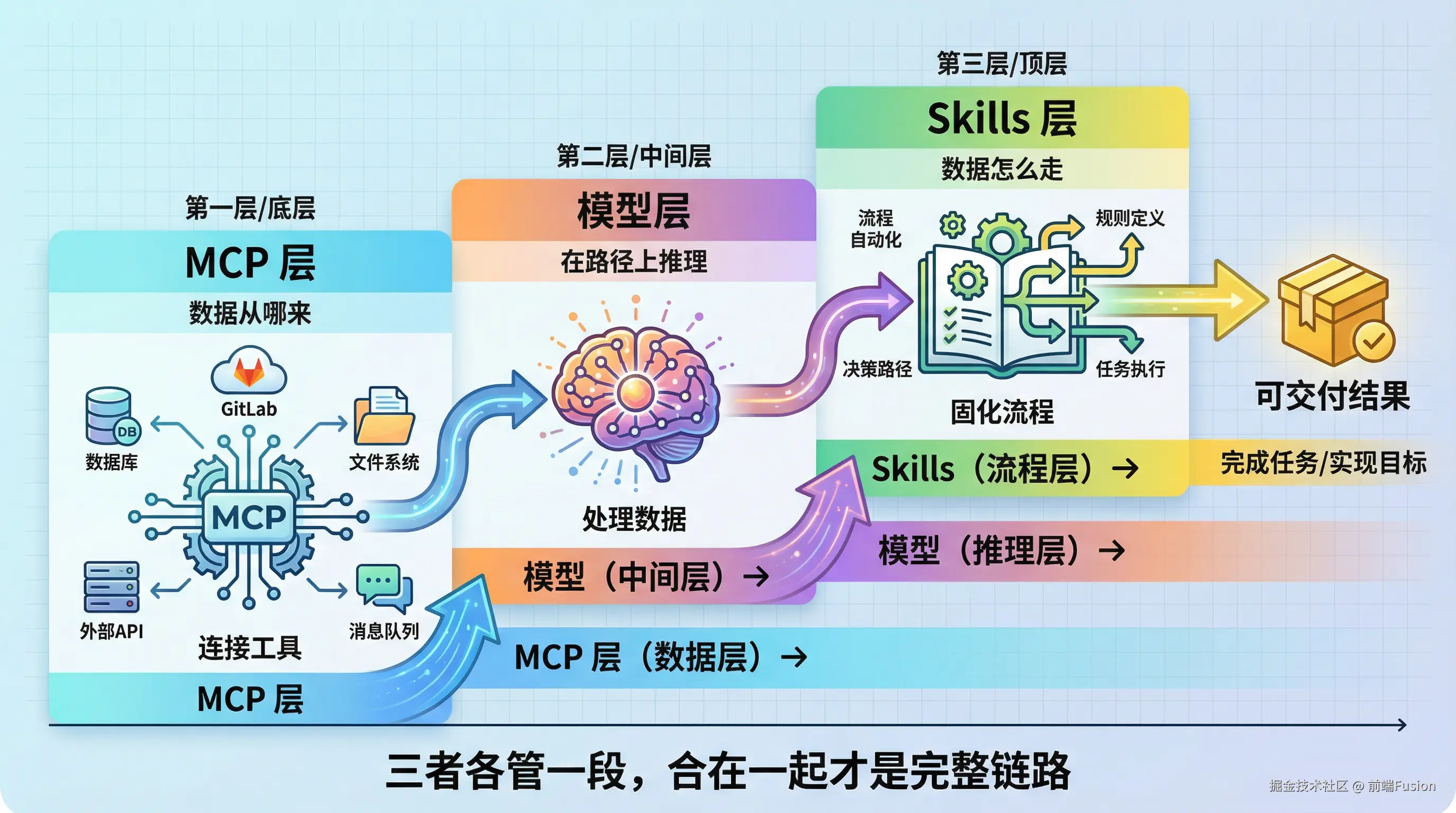
用伪代码来看这条链路,大致是这样。
sql
MCP Server(GitLab)
→ 拉取本周 commit 数据
→ 返回结构化信息给模型
Skill(周报生成规范)
→ 过滤掉 merge commit 与 CI 自动提交
→ 按功能模块归类
→ 为每个模块写一句摘要
→ 输出固定结构(本周完成 / 风险阻塞 / 下周计划)
→ 格式检查,确认可直接发出
模型
→ 在 MCP 提供的数据上,按 Skill 规定的路径推理与输出MCP 负责数据从哪来,Skills 负责拿到数据后怎么走,模型负责在这条路径上推理。
三者各管一段,合在一起才是一个完整的执行链路。
从周报生成看:MCP 与 Skills 如何协同工作
前面我们一直在用周报这个场景来讲分工,也看到了单独用 MCP 时的局限:数据能拿到,但输出停在罗列。
现在把 Skills 加进来,看看完整链路如何协同运转。
Skills 通过配置固化流程
前面提到,MCP 解决了数据可达性,但模型不知道该怎么处理这些数据。
Skills 就是通过配置把「应该怎么做」固化下来。
我在实现这个 Skills 时,会约束以下三个层面:
- 输出结构 ------ 固定章节、标题层级、编号格式
- 处理规则 ------ 不直接粘贴 commit、过滤技术细节、强调提炼总结
- 语言风格 ------ 自然简洁,避免 AI 腔

如图是我写在 Skill.md中的部分约束规则,有了这些约束,
模型就知道该从原始 commit 数据里挑什么、滤什么、怎么组织。
完整链路的执行过程
当 MCP 和 Skills 协同工作时,执行链路是这样的:
第一步:MCP 拉取数据。
通过 GitLab 的 MCP Server,把本周的提交记录拉进来。
这一步提供原始材料:
这些是未经处理的原始数据,接下来交给 Skills 约束处理。
第二步:Skills 约束处理。
模型按照 Skills 的规则处理数据:
- 过滤掉 merge commit 和 CI 自动提交
- 按功能模块归类
- 为每个模块提炼一句话摘要
- 组织成固定结构(本周完成 / 下周计划)
第三步:模型在约束下推理。
模型不是自由发挥,而是在 Skills 规定的路径上推理与输出。
每个环节都有检查点,确保结果可交付。
协同后的输出
最终生成的周报是这样的:

这时候的输出已经是可以直接使用的可交付状态。
不需要二次整理,不需要手动调格式。
MCP 负责获取数据,Skills 负责约束流程,两者协同工作,把「能看到数据」变成了「可以交付结果」。
小结
我们正处在模型能力飞速进化的时代。
模型越来越强,但真正决定结果的,往往不是它有多聪明,而是路径有没有被划清。
想让模型稳定地按你的意愿做事,关键不只是接入更多能力,还要把防护栏立起来。
当你下次觉得「AI 好像有点降智了?」,不妨想一想:
是缺了外部连接工具,还是缺少了流程约束?
把这两层分开想清楚,比堆更多能力更重要。
延伸阅读
- 通过 Skills 和 MCP Server 扩展 Claude 的能力 claude.com/blog/extend...
- 你真的需要 Skills 吗? www.youtube.com/watch?v=FsD...
- MCP 清晰解读:为什么重要 www.youtube.com/watch?v=7j_...
- 为 React 组件构建一个 MCP Server www.youtube.com/watch?v=fUX...
感谢您的阅读。
这里会持续记录我对技术、工程实践与新趋势的思考,可关注微信公众号 前端Fusion 获取后续更新。
如果您喜欢这篇文章,欢迎点赞或分享。
