2月16日,Qwen3.5 正式发布,并推出 Qwen3.5 系列的第一款模型------ Qwen3.5-Plus 的开放权重版本!作为原生视觉-语言模型,Qwen3.5-Plus 在推理、编程、智能体能力与多模态理解等全方位基准评估中表现优异,助力开发者与企业显著提升生产力。
Qwen3.5 采用创新的混合架构,将线性注意力(Gated Delta Networks)与稀疏混合专家(MoE)相结合,实现出色的推理效率:总参数量达 3970 亿,每次前向传播仅激活 170 亿参数,在保持能力的同时优化速度与成本。并将语言与方言支持从 119 种扩展至 201 种,为全球用户提供更广泛的可用性与更完善的支持。
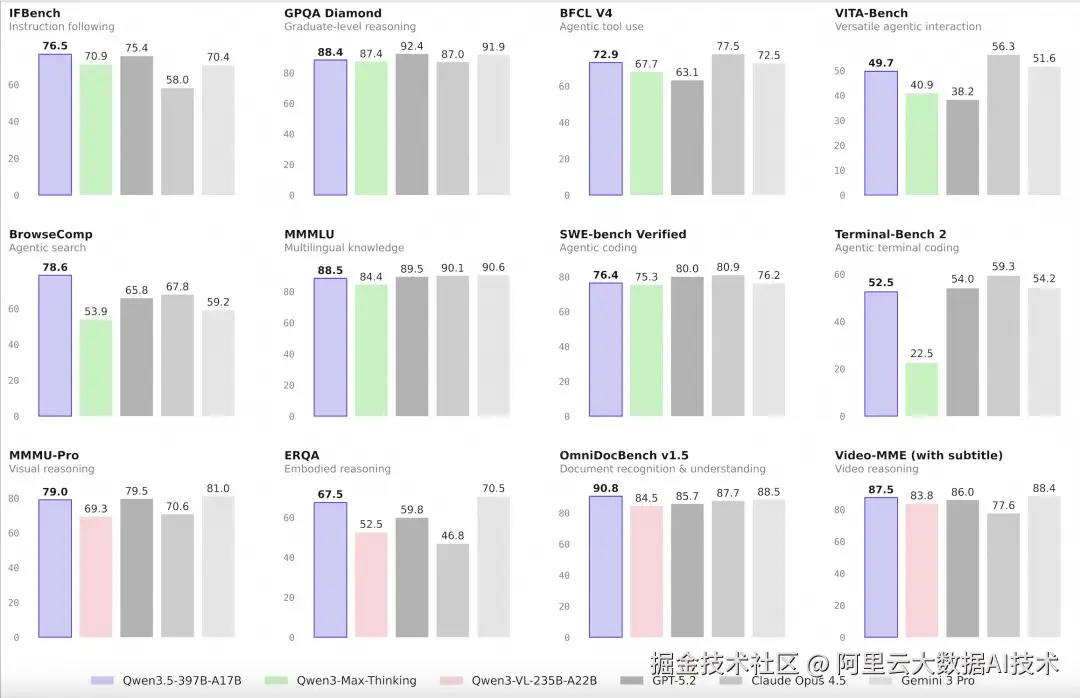
Qwen3.5-Plus 性能表现
随着大模型能力边界的持续拓展,训练与推理基础设施正面临前所未有的工程挑战:更大规模的训练数据、更复杂的多模态对齐,以及规模化 Agent 训练带来的计算与通信开销。
为支撑新一代 Qwen 模型在算法创新与工程落地间的高效协同,阿里云人工智能平台 PAI(Platform for AI)与 Qwen 团队深度共建,围绕异构计算资源调度、混合精度训练等核心环节系统性地升级了全链路训练基础设施。
异构训练框架 PAI-Maestro 支持原生多模态模型高效训练
为支持原生多模态模型的高效训练,Qwen3.5 在训练基础设施层面进行了系统性创新,引入了异构训练框架 PAI-Maestro。该框架针对多模态训练中视觉编码器等异构组件与语言模型主干网络在计算特性、内存需求和通信模式上的显著差异,设计了模块化解耦的并行策略:将视觉 Transformer、语言模型等不同模态组件的张量并行、流水线并行和数据并行策略进行独立配置与动态协同,避免了传统方案中"一刀切"并行策略导致的计算资源浪费和通信瓶颈。同时利用不同模态数据对异构组件的稀疏激活特性进行基于样本调度的组件间计算掩盖,消除异构模块对端到端训练性能的负面影响。
基于这一方案 PAI-Maestro 在端到端训练流程中几乎完全消除了多模态组件引入的性能损耗。在混合包含文本、图像、视频的训练数据集上,Qwen3.5 的训练吞吐量达到了接近100%的相对纯文本训练效率。这意味着模型可以在不牺牲训练速度的前提下,无缝融合多模态能力,大幅降低多模态大模型的训练成本与工程复杂度,为原生多模态架构的规模化落地提供了关键基础设施支撑。
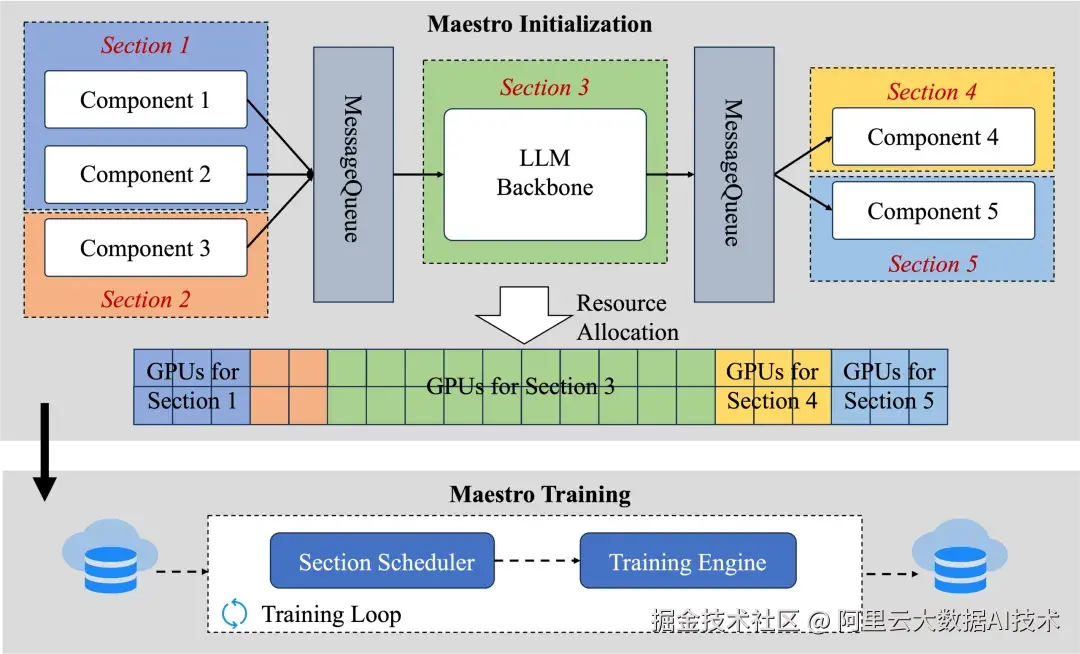
PAI-Maestro 架构图
原生 FP8 低精度训练:高效稳定的大模型低精度预训练方案
在低精度训练方面,PAI 团队和 Qwen 团队一起在预训练阶段和 RL 阶段精心设计了原生 FP8 低精度训练流程。在预训练阶段,我们采用细粒度的 FP8 混合精度策略,将 FP8 应用于激活值存储、MoE 专家分发及 GEMM 计算。为了应对低精度训练过程中数值不稳定导致 loss spike 的潜在风险,我们设计了轻量级运行时监控机制,动态追踪模型各部分权重、激活值、梯度值分布,在此基础上我们在对数值稳定性敏感的层保留高精度表示。该一方案在支撑模型稳定训练数十万亿 token 的同时,将激活显存占用降低约50%,并带来超过10%的端到端训练加速,显著提升了大规模训练的效率与可扩展性。
在强化学习工作流中,我们同样在训练引擎和推理引擎均引入了 FP8 精度。这种端到端的精度一致性有效消除了训练引擎和推理引擎之间的精度不匹配问题,降低了训练崩溃的风险,同时加快了与环境的交互过程,为高效、稳定的策略优化提供了坚实基础。
云原生的 Agentic RL 架构
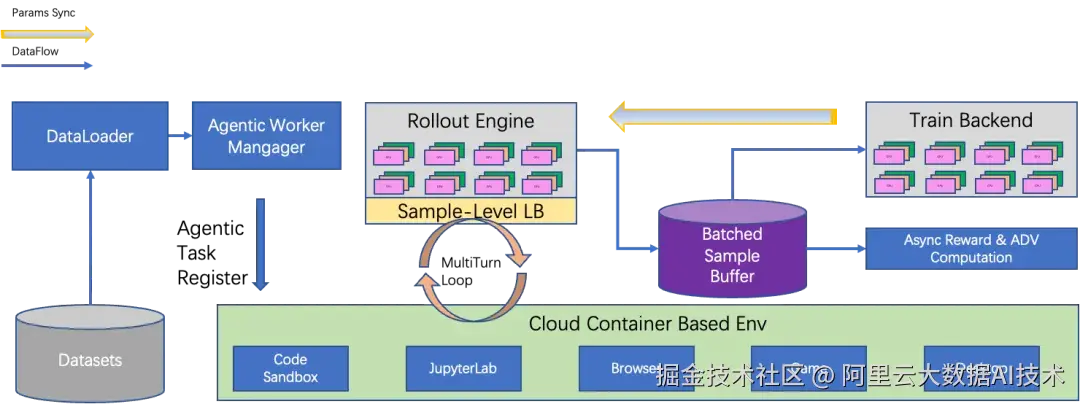
云原生 Agentic 环境架构
为提升 Qwen 3.5 模型在 Agent 场景下的性能表现,阿里云 PAI 团队联合阿里云容器服务团队联合自研了一套云原生 Agentic 环境架构。该架构以容器云服务为底座,可支持数十万并发轨迹,并具备容纳百万级镜像的能力。通过引入镜像公共层缓存预读取、OSS 加速器等关键技术,有效解决了高并发场景下环境镜像拉取失败率过高的挑战。同时,团队构建了统一的 Agentic 环境可观测性系统,实现了分钟级的轨迹失败自动归因和告警能力。依托上述技术创新与突破,成功将因环境问题导致的轨迹失败率从1%显著降低至0.05%(即万分之五)。
总结
在模型尺寸持续扩展、集群规模不断扩大、输入序列日益增长、数据模态日趋多元的行业演进背景下,大模型训练与推理基础设施所面临的挑战正呈现出高度的系统性与复杂性。阿里云 PAI 团队始终以打造业界顶尖的大模型基础设施为使命,与 Qwen 团队深度协同,直面 Qwen 系列模型带来的世界级技术挑战,持续锤炼高性能、高可靠、高可用的训推一体化平台,致力于为内外客户提供坚实、领先且值得信赖的 AI 基础设施服务。