文章目录
-
- 概述
- 从局部结果中建立"全局共识"
- 背景介绍
- 方法解释
-
- [利用数据增强计算 I sub I_{\text{sub}} Isub](#利用数据增强计算 I sub I_{\text{sub}} Isub)
- [利用正态近似计算 I sub I_{\text{sub}} Isub](#利用正态近似计算 I sub I_{\text{sub}} Isub)
- 基于可逆跳跃的模型选择
- 实验部分
概述

参考论文:Distributed Computation for Marginal Likelihood based Model Choice
我们正处于一个被"海量数据集 "包围的时代。这些数据集往往十分庞大,更棘手的是,许多数据还面临严格的隐私和安全限制。面对这个挑战,一个直观的解决方案是"分而治之"。将庞大的数据集分割为若干小块,分配给不同的计算机处理,最后将各个部分的结果合并起来。但问题是它真的这么简单吗?
当我们把数据分块后,一个合乎逻辑的想法是采用"投票"机制。让每个数据块的计算独立分析,找出它看来最好的模型,然后进行投票,最后得票最多的模型称为最终赢家。------ 然而,研究指出,这种方法是行不通的。当数据被分割份数越多的时候,这种投票方案的可靠性反而会下降。这是因为,每个数据分片相比于整体,其统计功效(statistical power)是不足的。一个模型可能仅凭运气在某个小数据块上看起来是赢家,而当分割数量增多时,这些随机的局部胜利所产生的"噪声"会淹没真实的信号。
摘要部分:
- 提出通用的分布式贝叶斯模型选择方法,使用边际似然,并将数据集划分为不重叠的子集,这些子集仅由各个工作节点本地访问,不共享任何数据。(通过对每个子集上的后验分布进行MC采样近似整个数据集的模型证据,进而为每个子集生成一个模型证据。
- 使用一种新颖的组合方法,利用生成样本的汇总统计量(summary statistics)来矫正划分带来的影响。
从局部结果中建立"全局共识"

论文的核心贡献在于提出了一个新的分解方式,它能正确合并来自分散数据块的分析结果。这与投票机制有着本质的区别:投票模型只关心哪个模型在局部胜出 ,而新方法评估的则是所有数据分片上,胜出模型的参数彼此间的吻合程度。
这个方法的关键在于引入了一个至关重要的"修正项 "(在论文中称为积分Isub)。通过类比来理解这个概念:这个修正项衡量的是所有独立数据块分析结果之间的"重叠度"或"一致性",也就是"共识"。
它确保了一个在每个数据块上看起来都表现不错的模型,在作为一个整体的数据集上同样表现出色。 这个"共识"积分项起到了一个关键的制衡作用。一个在所有分片上看起来不错,但其结果之间重叠度很低(共识度低)的模型,会被这个修正项"惩罚",从而避免被错误的选为全局最优解。
然而这种方式并非完美无瑕,引出一个无法避免的权衡问题。
论文 命题4和5指出,随着数据分割的分数(S)增加,潜在的近似误差会随着增长。这意味着,虽然可以通过增加计算机数量来缩短计算时间,但需要接接受最终结果可能会与在完整数据集上运行得出的"真实"结果有更大的误差。
尽管存在速度与精度的权衡,但这种新方法在现实世界中带来的回报是惊人的,它使得过去那些因计算量过大而遥不可及的分析成为了可能。
- 第一个例子(粒子物理学): 研究人员分析了一个包含1100万次观测的希格斯玻色子数据集。使用传统方法对这样一个数据集进行完整的贝叶斯分析,预计需要超过450小时(将近3周)。然而,通过采用新的分布式方法,他们将计算时间惊人地缩短到了"不到30分钟"。
- 第二个例子(遗传学): 在对英国生物样本库(UK Biobank)的遗传数据进行分析时,一项原本预计耗时超过200小时的计算任务,最终只用了1个小时就完成了。
这些戏剧性的时间缩减,不仅仅是效率的提升,更是质的飞跃。它让科学家们能够在前所未有的超大规模数据集上执行复杂的贝叶斯分析,从而解锁了过去被计算能力牢牢锁住的科学洞见。
背景介绍
分布式贝叶斯计算大体上遵循 MapReduce 或 "拆分 - 应用 - 合并"(split-apply-combine)计算框架(Dean & Ghemawat, 2008;Wickham, 2011)。该分布式贝叶斯计算流程可描述为三个关键步骤:
- 拆分(Split):将数据集划分为多个子集,并分配至各个节点(计算节点);
- 应用(Apply):每个计算节点基于本地子集独立计算后验分布;
- 合并(Combine):聚合所有计算节点的后验分布,形成统一结果。
合并步骤涉及多个概率分布的合成,属于信念聚合 (belief aggregation)的广义范畴 ------ 这是元分析与概率预测领域的一个研究热点(West, 1984;Genest, 1984;Dietrich, 2010)。这篇文章的目标是明确如何在上述计算框架中实现基于边缘似然的贝叶斯模型选择。研究发现,用于模型选择的信念聚合规则与固定模型推断的聚合规则在多个关键方面存在差异,并探讨了这些差异带来的理论与计算层面的影响。
信念聚合:指将多个独立的概率分布(各节点的局部后验)合成一个统一分布的过程。---- 在分布式贝叶斯计算中,每个节点输出"局部后验"本质是对"全局后验"的一个"信念(概率判断)",信念聚合就是把这些分散的信念整合为一个更可靠的全局信念。
- 在元分析 中,需要整合多个独立研究的结论;在概率预测中,需要合并多个预测模型的结果,这两种都属于"信念聚合"的范畴。
- "固定模型推断"指分析过程中模型结构是确定的(比如已知使用线性回归模型,仅需估计参数),此时信念聚合规则通常是"专家乘积融合(product-of-experts pooling)",即把每个节点的局部后验分布相乘,得到全局后验分布(这种规则的合理性在于,当模型固定时,全局数据的似然是各分片数据似然的乘积,因此后验分布也满足"分片乘积"的性质)
针对大规模样本数据集的高效计算方法相关研究,大致可分为两大类。Bardenet 等人(2017)、Jahan 等人(2020)及 Zhu 等人(2017)已发表综述,重点聚焦大数据场景下的贝叶斯方法。
- 第一类:基于小批量(随机子集)加速计算
从完整数据中抽取小批量子集,用子集近似整个数据的后验分布,从而降低计算成本。
- 第二类:通过并行处理(分治方法)缩短时间
将数据拆分后分配给多个节点并行计算,在合并结果。
这篇文章选择研究"分治方法",是因为小批量算法在实际场景中存在难以克服的问题:比如所有数据集中存储在单节点不可行(数据量远超节点内存)。 以及隐私限制,通信成本过高等原因。----- 大样本下通常使用"拉普拉斯近似"计算边际似然,但上述障碍使得直接计算拉普拉斯近似(需要确定后验众数,黑塞矩阵,需要大量跨节点通信)变得困难; 而分治方法无需集中数据,通信成本低,因此在这类场景中更具可行性。
归一化常量,贝叶斯因子,数据增强与条件共轭,分布式贝叶斯推断,共识蒙特卡洛 等相关概念可以参考之前写的文章:
【分布式贝叶斯推断】基于Consensus Monte Carlo(共识蒙特卡洛)与"product-of-experts"的后验分解方法
【贝叶斯推断】(分布式)可逆跳跃马尔科夫链蒙特卡洛(Distributed RJMCMC)
方法解释

模型证据的分解:利用贝叶斯定理与基础代数运算,可推导出边际似然的恒等式,使其适用于分布式计算:
命题1:完整数据的模型证据可以分解为:
p ( y ) = α S ∏ s = 1 S p ~ ( y s ) ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s ) d θ ( 5 ) p(y) = \alpha^S \prod_{s=1}^S \tilde{p}(y_s) \int_\Theta \prod_{s=1}^S \tilde{p}(\theta|y_s) \, d\theta(5) p(y)=αSs=1∏Sp~(ys)∫Θs=1∏Sp~(θ∣ys)dθ(5)
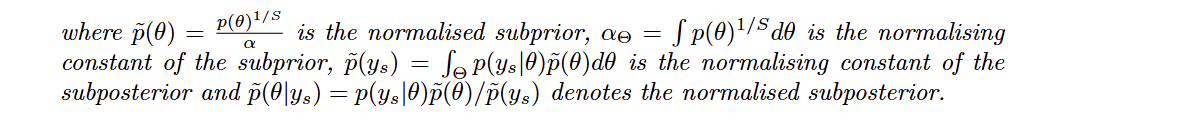
α \alpha α 可通过解析方法计算 :例如,若 p ( θ ) p(\theta) p(θ) 是正态分布,分片先验等价于先验方差的膨胀 N ( 0 , Σ ) 1 / S ∝ N ( 0 , S Σ ) \mathcal{N}(0,\Sigma)^{1/S}\propto\mathcal{N}(0,S\Sigma) N(0,Σ)1/S∝N(0,SΣ),因此 α \alpha α可轻松得到;拉普拉斯先验也满足类似性质 L ( 0 , σ ) 1 / S ∝ L ( 0 , S σ ) {\mathcal{L} ( 0, \sigma)^{1/ S}}\propto \mathcal{L} ( 0, S\sigma ) L(0,σ)1/S∝L(0,Sσ)。但对指数族 的部分分布需谨慎处理:当 S 过大时,积分 ∫ Θ p ( θ ) 1 / S d θ \int_\Theta p(\theta)^{1/S}d\theta ∫Θp(θ)1/Sdθ会趋于无穷(因为过多概率质量被推到分布尾部),因此建议根据具体情况逐一验证。
局部证据 p ~ ( y s ) \tilde{p}(y_s) p~(ys) 可由各计算节点通过常规采样方法(比如MCMC)计算得到。
最困难的部分是计算最后一项积分:
I sub : = ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s ) d θ ( 7 ) I_{\text{sub}} := \int_{\Theta} \prod_{s=1}^{S} \tilde{p}(\theta | y_s) \, d\theta (7) Isub:=∫Θs=1∏Sp~(θ∣ys)dθ(7)
后文讨论了两种方法估计积分 I sub I_{\text{sub}} Isub , 一种是数据增强与吉普斯采样 的精确方法,另一种是基于正态近似的近似方法。
利用数据增强计算 I sub I_{\text{sub}} Isub
数据增强的潜在变量有助于计算式(7)的估计量,假设潜在变量 z s z_s zs 在给定 θ \theta θ 时相互独立,则增强后完整数据的后验与子后验成比例,即:
p ( θ ∣ y 1 : S , z 1 : S ) ∝ p ( θ ) p ( y 1 : S , z 1 : S ∣ θ ) ∝ ∏ s = 1 S p ( y s , z s ∣ θ ) p ( θ ) 1 / S p(\theta|y_{1:S}, z_{1:S}) \propto p(\theta)p(y_{1:S}, z_{1:S}|\theta) \propto \prod_{s=1}^{S} p(y_s, z_s|\theta)p(\theta)^{1/S} p(θ∣y1:S,z1:S)∝p(θ)p(y1:S,z1:S∣θ)∝s=1∏Sp(ys,zs∣θ)p(θ)1/S ∝ ∏ s = 1 S p ( y s , z s ∣ θ ) p ~ ( θ ) ∝ ∏ s = 1 S p ~ ( θ ∣ y s , z s ) . \propto \prod_{s=1}^{S} p(y_s, z_s|\theta)\tilde{p}(\theta) \propto \prod_{s=1}^{S} \tilde{p}(\theta|y_s, z_s). ∝s=1∏Sp(ys,zs∣θ)p~(θ)∝s=1∏Sp~(θ∣ys,zs).
单个计算节点(仅访问 y s y_s ys)上的条件潜在变量后验为:
p ~ ( z s ∣ y s , θ ) ∝ p ( y s , z s ∣ θ ) p ~ ( θ ) ∝ p ( z s ∣ y s , θ ) p ( y s ∣ θ ) ∝ p ( z s ∣ y s , θ ) \tilde{p}(z_s|y_s,\theta) \propto p(y_s, z_s|\theta)\tilde{p}(\theta) \propto p(z_s|y_s,\theta)p(y_s|\theta) \propto p(z_s|y_s,\theta) p~(zs∣ys,θ)∝p(ys,zs∣θ)p~(θ)∝p(zs∣ys,θ)p(ys∣θ)∝p(zs∣ys,θ)
因此,条件于 θ \theta θ 时,子先验 p ~ ( θ ) \tilde{p}(\theta) p~(θ) 不产生影响。这为利用条件分布从 p ~ ( θ , z s ∣ y s ) \tilde{p}(\theta,z_s|y_s) p~(θ,zs∣ys) 中采样提供了吉布斯采样策略:若子先验的选择满足 ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s , z s ) d θ \int_{\Theta}\prod_{s=1}^{S}\tilde{p}(\theta|y_s,z_s)d\theta ∫Θ∏s=1Sp~(θ∣ys,zs)dθ 有闭式解,则可利用潜在变量后验生成的样本近似 I s u b I_{sub} Isub。
命题 2 :对增强数据似然 p ( y 1 : S , z 1 : S ∣ θ ) p(y_{1:S}, z_{1:S}|\theta) p(y1:S,z1:S∣θ) 采用数据增强方案,可得:
I s u b = E p ~ ( z 1 : S ∣ y 1 : S ) ∫ Θ ∏ s = 1 S p \~ ( θ ∣ y s , z s ) d θ ( 8 ) I_{sub} = \mathbb{E}{\tilde{p}(z{1:S}|y_{1:S})}\left\\int_{\\Theta}\\prod_{s=1}\^{S}\\tilde{p}(\\theta\|y_s,z_s)d\\theta\\right(8) Isub=Ep~(z1:S∣y1:S)∫Θs=1∏Sp\~(θ∣ys,zs)dθ(8)
其中 p ~ ( z 1 : S ∣ y 1 : S ) = ∏ s = 1 S p ~ ( z s ∣ y s ) \tilde{p}(z_{1:S}|y_{1:S}) = \prod_{s=1}^{S}\tilde{p}(z_s|y_s) p~(z1:S∣y1:S)=∏s=1Sp~(zs∣ys).
证明:详见附录(Buchholz 等,2022)。
由此,命题 2 给出了如下蒙特卡洛估计量:
I ^ s u b = 1 N ∑ i = 1 N ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s , z s i ) d θ ( 9 ) \hat{I}{sub} = \frac{1}{N}\sum{i=1}^{N}\int_{\Theta}\prod_{s=1}^{S}\tilde{p}(\theta|y_s,z_s^i)d\theta(9) I^sub=N1i=1∑N∫Θs=1∏Sp~(θ∣ys,zsi)dθ(9)
其中 ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s , z s i ) d θ \int_{\Theta}\prod_{s=1}^{S}\tilde{p}(\theta|y_s,z_s^i)d\theta ∫Θ∏s=1Sp~(θ∣ys,zsi)dθ 是解析计算的结果, z s i z_s^i zsi 是从吉布斯采样器等方法中得到的样本(算法 1 给出了采样器的具体实现)。附录中提供了逻辑回归中利用波利亚 - 伽马(Pólya-Gamma)数据增强的详细细节。该估计量的方差可通过与重要性采样的关联来理解。

命题 3 : 假设从潜在变量后验中独立同分布采样,则式(9)中估计量的方差为:
V a r I ^ s u b = I s u b 2 N V a r p ~ ( z 1 : S ∣ y 1 : S ) p ( z 1 : S ∣ y 1 : S ) ∏ s = 1 S p \~ ( z s ∣ y s ) \mathrm{Var}\:\hat{I}{\mathrm{sub}}=\frac{I{\mathrm{sub}}^2}{N}\mathrm{Var}{\tilde{p}(z{1:S}|y_{1:S})}\:\left\\frac{p(z_{1:S}\|y_{1:S})}{\\prod_{s=1}\^S\\tilde{p}(z_s\|y_s)}\\right VarI^sub=NIsub2Varp~(z1:S∣y1:S)∏s=1Sp\~(zs∣ys)p(z1:S∣y1:S)
证明:详见附录(Buchholz 等,2022)。
该式将估计量 I ^ s u b \hat{I}\mathrm{sub} I^sub的方差与联合条件后验 p ( z 1 : S ∣ y 1 : S ) p(z{1:S}|y_{1:S}) p(z1:S∣y1:S)和条件子后验乘积 p ~ ( z 1 : S ∣ y 1 : S ) \tilde{p}(z_{1:S}|y_{1:S}) p~(z1:S∣y1:S)的相对覆盖度关联起来:该比值的方差衡量了"条件子后验乘积"作为重要性采样提议分布的质量。
若提议分布的尾部比目标分布更薄,估计量的方差可能趋于无穷;随着分片数增加,条件子后验乘积对真实后验的近似效果会变差,估计量的方差也会增大。需注意,由于吉布斯采样引入了自相关,实际中 I ^ s u b \hat{I}_\mathrm{sub} I^sub 的方差会大于上述理论值。
利用正态近似计算 I sub I_{\text{sub}} Isub

依赖数据增强的模型属于受限类别,需要定制化采样器。更通用的 I s u b I_{\mathrm{sub}} Isub(式 7)估计方法是对每个子后验做正态近似 p ~ ( θ ∣ y s ) ≈ N ( θ ∣ μ s , Σ s ) \tilde{p}(\theta|y_s) \approx \mathcal{N}(\theta|\mu_s, \Sigma_s) p~(θ∣ys)≈N(θ∣μs,Σs),从而得到积分的近似:
I s u b = ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s ) d θ ≈ ∫ Θ ∏ s = 1 S N ( θ ∣ μ s , Σ s ) d θ I_{\mathrm{sub}} = \int_{\Theta} \prod_{s=1}^{S} \tilde{p}(\theta|y_s) d\theta \approx \int_{\Theta} \prod_{s=1}^{S} \mathcal{N}(\theta|\mu_s, \Sigma_s) d\theta Isub=∫Θs=1∏Sp~(θ∣ys)dθ≈∫Θs=1∏SN(θ∣μs,Σs)dθ
子后验正态近似的均值 μ s \mu_s μs 与协方差 Σ s \Sigma_s Σs 可通过各计算节点生成的子后验样本估计得到。利用"正态密度函数的乘积仍与另一个正态密度成比例"的性质,可得到闭式表达式:
∫ Θ ∏ s = 1 S N ( θ ∣ μ s , Σ s ) d θ = exp ( ∑ s = 1 S ξ s − ξ ) ( 10 ) \int_{\Theta} \prod_{s=1}^{S} \mathcal{N}(\theta|\mu_s, \Sigma_s) d\theta = \exp\left(\sum_{s=1}^{S} \xi_s - \xi\right)(10) ∫Θs=1∏SN(θ∣μs,Σs)dθ=exp(s=1∑Sξs−ξ)(10)
其中:
η s = Σ s − 1 μ s , Λ s = Σ s − 1 , \eta_s = \Sigma_s^{-1}\mu_s, \quad \Lambda_s = \Sigma_s^{-1}, ηs=Σs−1μs,Λs=Σs−1,
ξ s = − 1 2 ( p log 2 π − log ∣ Λ s ∣ + η s T Λ s − 1 η s ) , \xi_s = -\frac{1}{2}\left(p\log 2\pi - \log |\Lambda_s| + \eta_s^T\Lambda_s^{-1}\eta_s\right), ξs=−21(plog2π−log∣Λs∣+ηsTΛs−1ηs),
η = ∑ s = 1 S Σ s − 1 μ s , Λ = ∑ s = 1 S Σ s − 1 , \eta = \sum_{s=1}^{S} \Sigma_s^{-1}\mu_s, \quad \Lambda = \sum_{s=1}^{S} \Sigma_s^{-1}, η=∑s=1SΣs−1μs,Λ=∑s=1SΣs−1,
ξ = − 1 2 ( p log 2 π − log ∣ Λ ∣ + η T Λ − 1 η ) . \xi = -\frac{1}{2}\left(p\log 2\pi - \log |\Lambda| + \eta^T\Lambda^{-1}\eta\right). ξ=−21(plog2π−log∣Λ∣+ηTΛ−1η).
伯恩斯坦-冯·米塞斯定理的常规条件可为子后验的正态近似 p ~ ( θ ∣ y s ) ≈ N ( θ ∣ μ s , Σ s ) \tilde{p}(\theta|y_s) \approx \mathcal{N}(\theta|\mu_s, \Sigma_s) p~(θ∣ys)≈N(θ∣μs,Σs) 提供理论依据(详见 Ghosh & Ramamoorthi (2003))。由于式(10)涉及矩阵求逆与行列式计算,其计算复杂度为 O ( S p 3 ) O(Sp^3) O(Sp3)。我们利用 3.1 节开头所述的任意技术近似计算归一化常数 p ~ ( y s ) \tilde{p}(y_s) p~(ys)------需注意,正态近似仅用于估计 I s u b I_{\mathrm{sub}} Isub,不影响 p ~ ( y s ) \tilde{p}(y_s) p~(ys) 的估计。因此,算法 2 用于边缘似然的估计。

正态混合模型(mixtures of normals)
若后验分布是多峰的,简单正态近似会导致子后验乘积积分的近似效果较差。如 Neiswanger 等 (2013)、Scott 等 (2017) 所述,可利用正态混合模型或核密度估计器近似后验,这类方法在实际中表现良好。但当混合分量数或分片数 S S S 较大时,该方法的计算成本会变得过高:由于需要计算 S S S 个混合模型的乘积,最终分布乘积的计算复杂度为 O ( S k ) O(S^{k}) O(Sk) ( k k k 为混合分量数)。因此,这篇文章没有采用该方法。
命题 4 :假设 { μ s , Σ s } s = 1 S \left\{\mu_{s}, \Sigma_{s}\right\}{s=1}^{S} {μs,Σs}s=1S 是子后验正态近似 p ~ ( θ ∣ y s ) ≈ N ( θ ∣ μ s , Σ s ) \tilde{p}(\theta|y{s}) \approx \mathcal{N}(\theta|\mu_{s}, \Sigma_{s}) p~(θ∣ys)≈N(θ∣μs,Σs) 的参数,且
N ( θ ∣ μ , Σ ) ∝ ∏ s = 1 S N ( θ ∣ μ s , Σ s ) \mathcal{N}(\theta|\mu, \Sigma) \propto \prod_{s=1}^{S} \mathcal{N}(\theta|\mu_{s}, \Sigma_{s}) N(θ∣μ,Σ)∝∏s=1SN(θ∣μs,Σs) 是完整后验 p ( θ ∣ y ) p(\theta|y) p(θ∣y) 的正态近似,则对 I s u b I_{\mathrm{sub}} Isub 的正态近似满足:
∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s ) d θ = { ∫ Θ ∏ s = 1 S N ( θ ∣ μ s , Σ s ) d θ } E N ( μ , Σ ) ∏ s = 1 S p \~ ( θ ∣ y s ) N ( θ ∣ μ s , Σ s ) \int_{\Theta} \prod_{s=1}^{S} \tilde{p}(\theta|y_{s}) d \theta = \left\{\int_{\Theta} \prod_{s=1}^{S} \mathcal{N}(\theta|\mu_{s}, \Sigma_{s}) d \theta\right\} \mathbb{E}_{\mathcal{N}(\mu, \Sigma)}\left\\prod_{s=1}\^{S} \\frac{\\tilde{p}(\\theta\|y_{s})}{\\mathcal{N}(\\theta\|\\mu_{s}, \\Sigma_{s})}\\right ∫Θs=1∏Sp~(θ∣ys)dθ={∫Θs=1∏SN(θ∣μs,Σs)dθ}EN(μ,Σ)s=1∏SN(θ∣μs,Σs)p\~(θ∣ys)
证明:详见附录(Buchholz 等,2022)。
命题 5 : 假设 { μ s , Σ s } s = 1 S \left\{\mu_{s}, \Sigma_{s}\right\}{s=1}^{S} {μs,Σs}s=1S 是子后验正态近似 p ~ ( θ ∣ y s ) ≈ N ( θ ∣ μ s , Σ s ) \tilde{p}(\theta|y{s}) \approx \mathcal{N}(\theta|\mu_{s}, \Sigma_{s}) p~(θ∣ys)≈N(θ∣μs,Σs) 的参数,且
N ( θ ∣ μ , Σ ) ∝ ∏ s = 1 S N ( θ ∣ μ s , Σ s ) \mathcal{N}(\theta|\mu, \Sigma) \propto \prod_{s=1}^{S} \mathcal{N}(\theta|\mu_{s}, \Sigma_{s}) N(θ∣μ,Σ)∝∏s=1SN(θ∣μs,Σs) 是完整后验 p ( θ ∣ y ) p(\theta|y) p(θ∣y) 的正态近似。完整数据的精确边缘似然 p ( y ) p(y) p(y) 与近似边缘似然 p ^ ( y ) \hat{p}(y) p^(y) 分别为:
p ( y ) = α S ( ∏ s = 1 S p ~ ( y s ) ) ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s ) d θ , p ^ ( y ) = α S ( ∏ s = 1 S p ~ ( y s ) ) ∫ Θ ∏ s = 1 S N ( θ ∣ μ s , Σ s ) d θ . \begin{aligned} & p(y) = \alpha^{S}\left(\prod_{s=1}^{S} \tilde{p}(y_{s})\right) \int_{\Theta} \prod_{s=1}^{S} \tilde{p}(\theta|y_{s}) d \theta, \\ & \hat{p}(y) = \alpha^{S}\left(\prod_{s=1}^{S} \tilde{p}(y_{s})\right) \int_{\Theta} \prod_{s=1}^{S} \mathcal{N}(\theta|\mu_{s}, \Sigma_{s}) d \theta. \end{aligned} p(y)=αS(s=1∏Sp~(ys))∫Θs=1∏Sp~(θ∣ys)dθ,p^(y)=αS(s=1∏Sp~(ys))∫Θs=1∏SN(θ∣μs,Σs)dθ.
若子后验正态近似满足密度比界:
max s = 1 , ... , S sup θ ∈ Θ p ~ ( θ ∣ y s ) N ( θ ∣ μ s , Σ s ) ≤ A , max s = 1 , ... , S sup θ ∈ Θ N ( θ ∣ μ s , Σ s ) p ~ ( θ ∣ y s ) ≤ B , \max_{s=1, \ldots, S} \sup {\theta \in \Theta} \frac{\tilde{p}(\theta|y{s})}{\mathcal{N}(\theta|\mu_{s}, \Sigma_{s})} \leq A, \quad \max {s=1, \ldots, S} \sup {\theta \in \Theta} \frac{\mathcal{N}(\theta|\mu{s}, \Sigma{s})}{\tilde{p}(\theta|y_{s})} \leq B, s=1,...,Smaxθ∈ΘsupN(θ∣μs,Σs)p~(θ∣ys)≤A,s=1,...,Smaxθ∈Θsupp~(θ∣ys)N(θ∣μs,Σs)≤B,
则边缘似然近似的相对误差满足:
− S log B + log E N ( μ , Σ ) I ( θ ∈ Θ ) ≤ log p ( y ) p ^ ( y ) ≤ S log A . -S \log B + \log \mathbb{E}_{\mathcal{N}(\mu, \Sigma)}\left\\mathbb{I}(\\theta \\in \\Theta)\\right \leq \log \frac{p(y)}{\hat{p}(y)} \leq S \log A. −SlogB+logEN(μ,Σ)I(θ∈Θ)≤logp^(y)p(y)≤SlogA.
证明:详见附录(Buchholz 等,2022)。
若参数空间是无约束的(即 Θ = R dim ( θ ) \Theta=\mathbb{R}^{\operatorname{dim}(\theta)} Θ=Rdim(θ)),则 E N ( μ , Σ ) I ( θ ∈ Θ ) = 1 \mathbb{E}_{\mathcal{N}(\mu, \Sigma)}\left\\mathbb{I}(\\theta \\in \\Theta)\\right=1 EN(μ,Σ)I(θ∈Θ)=1,误差界可简化为
− S log B ≤ log p ( y ) p ^ ( y ) ≤ S log A 。 -S \log B \leq \log \frac{p(y)}{\hat{p}(y)} \leq S \log A。 −SlogB≤logp^(y)p(y)≤SlogA。
密度比的上确界是衡量两个概率分布差异的有效指标(Dümbgen 等,2021)。在伯恩斯坦 - 冯・米塞斯定理的条件下,随着分片规模增大,每个子后验正态近似的质量会提升;若分片数 S S S 固定,且 { μ s , Σ s } s = 1 S \left\{\mu_{s}, \Sigma_{s}\right\}_{s=1}^{S} {μs,Σs}s=1S 取真实后验的均值与方差,则 A A A 和 B B B 会随 n → ∞ n \rightarrow \infty n→∞ 趋于 1。需注意,命题 5 假设的是分片上子后验正态近似的最坏情况精度,而非平均精度。
推论1 :固定分片规模 n s n_s ns,总样本量为 n = S n s n = S n_s n=Sns。设 p ( y ) p(y) p(y) 为真实边缘似然, p ^ ( y ) \hat{p}(y) p^(y) 为命题 5 中的近似边缘似然。若:
sup θ ∈ Θ ∣ 1 S ∑ s = 1 S log p ^ ( θ ∣ y s ) N ( θ ∣ μ s , Σ s ) ∣ = O p ( 1 ) \sup_{\theta \in \Theta} \left| \frac{1}{S} \sum_{s=1}^{S} \log \frac{\hat{p}(\theta | y_s)}{\mathcal{N}(\theta | \mu_s, \Sigma_s)} \right| = \mathcal{O}_p(1) θ∈Θsup S1s=1∑SlogN(θ∣μs,Σs)p^(θ∣ys) =Op(1)
(其中 { y s , μ s , Σ s } s = 1 S \{y_s, \mu_s, \Sigma_s\}_{s=1}^{S} {ys,μs,Σs}s=1S 视为随机变量),则相对误差满足:
log p ( y ) p ^ ( y ) = O p ( S ) . \log \frac{p(y)}{\hat{p}(y)} = \mathcal{O}_p(S). logp^(y)p(y)=Op(S).
证明:详见附录 (Buchholz 等,2022)。
命题 5 与推论 1 表明:分布式策略通过分片数 S S S 获得的计算收益,与近似误差之间存在权衡。
实际上,我们将式 (5) 转换到对数域:
log p ^ ( y ) = S log α + ∑ s = 1 S log p ^ ( y s ) + log ∫ Θ ∏ s = 1 S N ( θ ∣ μ s , Σ s ) d θ . \log \hat{p}(y) = S \log \alpha + \sum_{s=1}^{S} \log \hat{p}(y_s) + \log \int_{\Theta} \prod_{s=1}^{S} \mathcal{N}(\theta | \mu_s, \Sigma_s) d\theta. logp^(y)=Slogα+s=1∑Slogp^(ys)+log∫Θs=1∏SN(θ∣μs,Σs)dθ.
对应的估计量是 S + 2 S+2 S+2 项的和,其方差随 S S S 线性增长;此外,若通过马尔可夫链的 N N N 个样本估计 log p ^ ( y s ) \log \hat{p}(y_s) logp^(ys),其均方误差通常为 O ( 1 / N ) O(1/N) O(1/N),因此更多模拟可降低该误差。综上,若 MCMC 采样的误差较小,且分片规模足够大以保证子后验正态近似的质量合理,我提出的方法可得到完整数据边缘似然的良好近似。
基于可逆跳跃的模型选择
仅当候选模型数量较少时,计算候选集中每个模型的边缘似然才是可行的。但在许多实际场景中,往往需要在大量(可能具有不同支撑集)的模型中选择,典型例子是变量选择(每个模型对应特定的变量组合)。
可逆跳跃方法(Green, 1995)可构造同时遍历模型与对应参数空间的马尔可夫链:给定数据的模型后验概率 p ( m i ∣ y ) p(m_i|y) p(mi∣y)(见式 1),可通过采样器在该模型上的相对探索时间得到。
分布式可逆跳跃马尔可夫链蒙特卡洛(RJMCMC)
模型的修正专家乘积信念聚合规则
p ( m i ∣ y ) ∝ { ∏ s = 1 S p ~ ( m i ∣ y s ) } α i S ( ∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s , m i ) d θ ) ( 6 ) p(m_i|y) \propto \left\{\prod_{s=1}^{S}\tilde{p}(m_i|y_s)\right\}\alpha_i^S\left(\int_\Theta\prod_{s=1}^{S}\tilde{p}(\theta|y_s,m_i)d\theta\right)(6) p(mi∣y)∝{s=1∏Sp~(mi∣ys)}αiS(∫Θs=1∏Sp~(θ∣ys,mi)dθ)(6)
阐明了如何利用可逆跳跃方法进行分布式贝叶斯模型选择:计算节点只需计算子后验模型概率
p ~ ( m i ∣ y s ) ∝ p ~ ( y s ∣ m i ) p ( m i ) 1 / S \tilde{p}(m_i|y_s) \propto \tilde{p}(y_s|m_i)p(m_i)^{1/S} p~(mi∣ys)∝p~(ys∣mi)p(mi)1/S 与子后验 p ~ ( θ ∣ y s , m i ) ∝ p ( y s ∣ θ , m i ) p ( θ ∣ m i ) 1 / S \tilde{p}(\theta|y_s,m_i) \propto p(y_s|\theta,m_i)p(\theta|m_i)^{1/S} p~(θ∣ys,mi)∝p(ys∣θ,mi)p(θ∣mi)1/S; 子后验积分
∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s , m i ) d θ \int_\Theta\prod_{s=1}^{S}\tilde{p}(\theta|y_s,m_i)d\theta ∫Θ∏s=1Sp~(θ∣ys,mi)dθ 可在合并步骤中评估,项 α i S \alpha_i^S αiS 可在拆分步骤中确定。随后利用信念聚合规则 重构完整的后验模型概率。同样,可对每个子后验做正态近似 p ~ ( θ ∣ y s , m i ) ≈ N ( θ ∣ μ s i , Σ s i ) \tilde{p}(\theta|y_s,m_i) \approx \mathcal{N}(\theta|\mu_s^i,\Sigma_s^i) p~(θ∣ys,mi)≈N(θ∣μsi,Σsi),从而近似积分:
∫ Θ ∏ s = 1 S p ~ ( θ ∣ y s , m i ) d θ ≈ ∫ Θ ∏ s = 1 S N ( θ ∣ μ s i , Σ s i ) d θ . \int_\Theta\prod_{s=1}^{S}\tilde{p}(\theta|y_s,m_i)d\theta \approx \int_\Theta\prod_{s=1}^{S}\mathcal{N}(\theta|\mu_s^i,\Sigma_s^i)d\theta. ∫Θs=1∏Sp~(θ∣ys,mi)dθ≈∫Θs=1∏SN(θ∣μsi,Σsi)dθ.
可逆跳跃方法特别适用于分解式(6),因为采样器会同时探索模型与对应的参数空间------各计算节点的 RJMCMC 输出中,可直接得到 p ~ ( m i ∣ y s ) \tilde{p}(m_i|y_s) p~(mi∣ys)、 μ s i \mu_s^i μsi 和 Σ s i \Sigma_s^i Σsi 的估计值。因此,拆分方法可与可逆跳跃算法有效结合(如算法 3 所示),附录(Buchholz 等,2022)提供了更多细节。

RJMCMC 存在一些已知问题,可能限制其在分治方法中的有效性:可逆跳跃采样器难以调参,且收敛速度通常较慢;当模型非嵌套时,构造合适的提议分布也极具挑战性;此外,目标模型需被充分探索,才能得到可靠的估计。
实验部分
实验设置
整体实验设置如下:模型参数的先验方差设为 1、均值设为 0;采用随机分片方法,即 S S S个分片的样本量约为 n / S n/S n/S;采样方式为无放回均匀采样(另有说明除外)。将采样器运行 20 次,每次迭代都会用不同的随机种子初始化分片与蒙特卡洛采样器,因此结果的变异是"分片(不同划分)"与"蒙特卡洛采样(不同链)"变异的组合。生成的蒙特卡洛样本数为 10000,其中前 2000 个样本作为预热 (burn-in) 阶段被舍弃。
若完整数据集的估计能在合理时间内完成,会将对数边缘似然的估计误差与完整数据集的估计结果进行对
比。
评估指标
文章使用均方根误差(RMSE),定义为:
M S E = E ∥ log p ( y ) − log p ^ ( y ) ∥ 2 \sqrt{\mathrm{MSE}}=\sqrt{\mathbb{E}\left\|\log p(y)-\log\hat{p}(y)\right\|^2} MSE =E∥logp(y)−logp^(y)∥2
其中 p ^ ( y ) \hat{p}(y) p^(y)是通过本文提出的分解方法得到的近似值。相对 RMSE 定义为:
% M S E = E ∥ log p ( y ) − log p ^ ( y ) ∥ 2 log p ( y ) × 100 \%\sqrt{\mathrm{MSE}}=\frac{\sqrt{\mathbb{E}\|\log p(y)-\log\hat{p}(y)\|^2}}{\log p(y)}\times100 %MSE =logp(y)E∥logp(y)−logp^(y)∥2 ×100
使用相对 RMSE 的合理性,源于要估计的目标量本身的规模。
实验部分探讨以下问题:
(a)朴素投票策略、上采样似然与基于共识蒙特卡洛(CMC)的重要性采样,能否作为本文方法的替代方案?
(b)基于数据增强的方法与基于正态近似的方法,在数据上的表现有何差异?
(c)近似 I sub I_{\text{sub}} Isub引入的误差,相较于对数边缘似然的整体规模,其量级如何?
(d) I sub I_{\text{sub}} Isub的误差随分片数的变化规律是什么?
(e)在超大规模数据集上使用分布式方法,能获得哪些实际收益?
(f)分布式方法在可逆跳跃马尔可夫链蒙特卡洛(RJMCMC)中的可靠性如何?
- 方法验证与对比 (Experiments 1)
这一部分主要回答了"为什么我们需要这个新方法"以及"哪种近似策略更好"。
作者测试了如果只是简单地在每个数据分片(shard)上计算局部边缘似然,然后进行"多数投票"或"Borda计数"会怎样 。结果当分片数量较少时(每个分片数据多),这些简单方法还行;但当分片数量增加(例如切成10份以上),简单投票法就无法选出正确的模型了 。
随着分割数的增加,正确的模型6在两种投票机制下都不在被优先选择。

随着分割数从 1 增加到 50,共识蒙特卡洛(IS CMC)方法的结果始终非常稳定,箱线图几乎没有变化。相比之下,文中近似方法(approx)的结果虽然也能保持稳定,但在分割数增多时,其波动略大于IS CMC。传统上采样方法(mean/median):在分割数较少时表现尚可,但在分割数增多时会变得极不稳定。
数据增强 vs. 正态近似(Experiment 2):
使用飞行准点率预测数据集(32万+样本)的逻辑回归模型 。

上图表示在航班数据上进行逻辑回归时,不同方法对 归一化常数(normalising constant,即 log evidence) 的估计表现。基于算法 2 的近似方法(random approx):在所有分割数下都表现出极高的稳定性和准确性,即使分割数增加到 50,其估计值依然紧贴真实参考值。基于算法 1 的条件共轭方法(random cond /stratified cond):随着分割数的增加,估计值变得越来越不可靠,与真实值的偏差越来越大,即使使用了分层采样(stratified cond)也无法改善这一趋势。
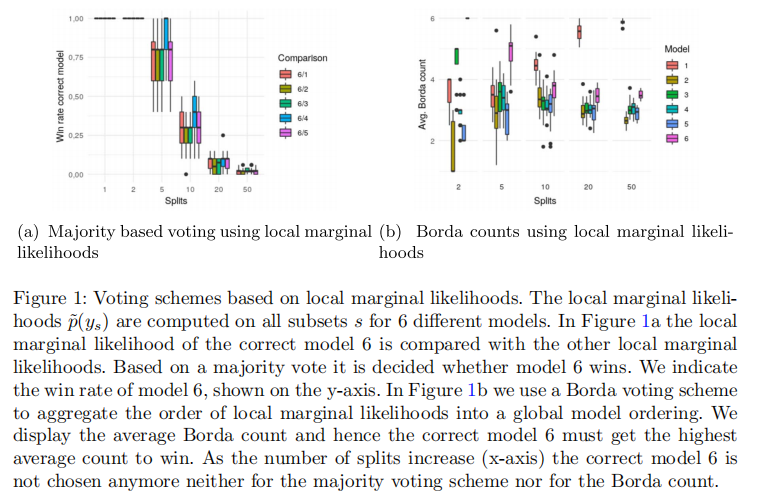
玩具模型验证 (Experiment 3):
(图 4)展示了在合成高斯模型上,使用算法 2计算的对数贝叶斯因子(log Bayes factor, log BF)。在数据分割数增加时,依然能保持稳定且一致的结果。------ 即使每个分割中的观测数大幅减少(从 10,000 降到 200),模型 6 的优势地位也没有动摇,从而保证了在分布式计算场景下,依然能做出可靠的模型选择。
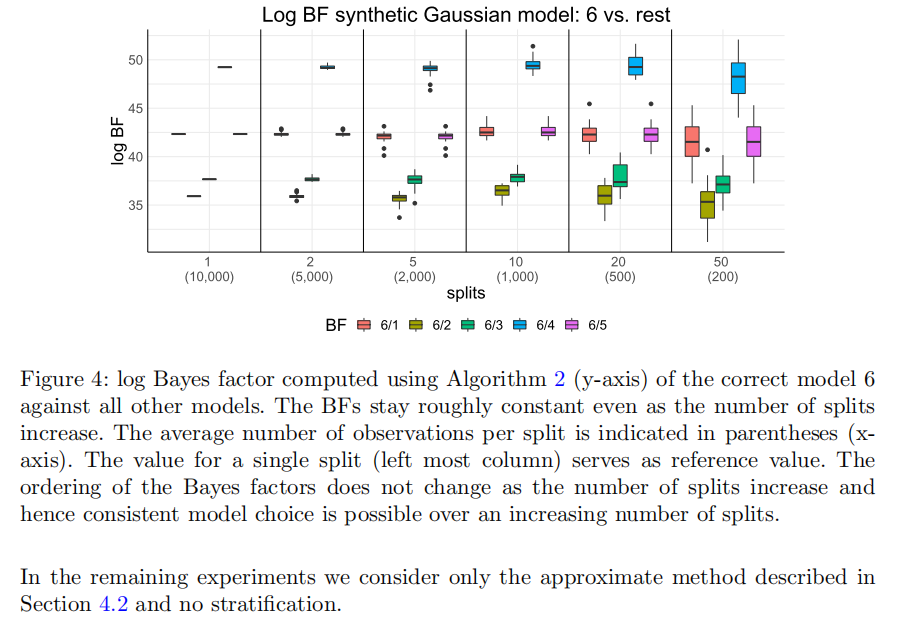
大规模真实数据应用 (Experiments 4, 5)
(图 5)展示了在希格斯(Higgs)数据集上,使用算法 2计算两个模型(Model 1 和 Model 2)的归一化常数。
在同一尺度下,Model1和log evidence 始终高于model2 ,说明前者对数据的拟合更好,同时,随着分割数增加,两个模型的log evidence 都呈现轻微的下降趋势。
(图 6)聚焦于线性回归任务(带稀疏性先验),通过算法 2计算两个特征数量不同的模型的归一化常数(log evidence),对比了HLA 数据集子集(10%)和全量 HLA 数据集在不同数据分割数(splits)下的估计表现,核心结论是分割数增加会导致估计值出现向下偏差。
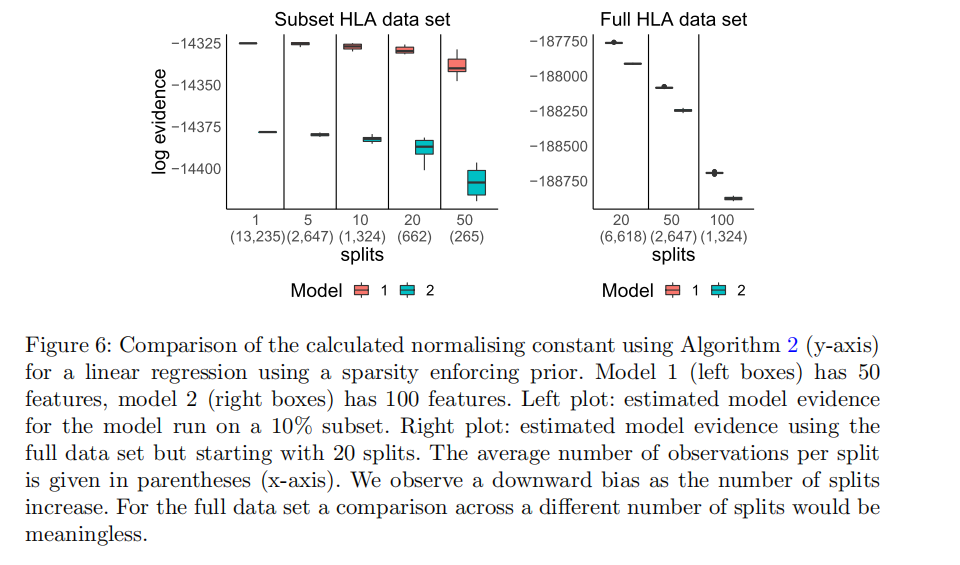
Model 1包含50个特征,Model 2 包含100个特征。左图:HLA 数据集的10% 子集;右图:HLA全量数据集。
前沿扩展:可逆跳跃 MCMC (Experiment 6)
作者尝试将该方法应用于 RJMCMC(一种可以在不同维度模型间跳跃的采样算法),这是一个非常大胆的尝试 。 结果表明,如果数据分片太小,局部马尔可夫链可能无法充分探索所有可能的模型空间,导致合并结果时方差巨大 。
这仅仅是一个概念验证(proof of concept),在实际操作中需要保证每个分片有足够的数据量以确保混合良好。