一、选择【句向量】模型
首先,我们前一节说到了,计算知识库向量的模型,和后续取问题向量的模型,必须是同一个版本的同一个模型,而且这种模型不是 deepseek v3 这种【词向量】模型,而是【句向量】模型。
模型和模型之间亦有本质差异。
所以,我建议大家可以直接在自己的电脑上装一个轻量的【句向量】模型。
关于模型,如果是生产需要,可以优先考虑以下几款:
- Alibaba-NLP/gte-Qwen2-1.5B-instruct
- intfloat/multilingual-e5-large-instruct
- BAAI/bge-m3
其中 bg3-m3 独有的【混合检索】属于独家秘籍,它可以同时输出 常规向量,类似于关键词权重的稀疏向量, 因此生产环境可以优先尝试 BAAI/bge-m3 这个模型。
如果只是想搞个极致轻量级的,本地测试学习跑通流程,那我可以尝试以下几款:
- BAAI/bge-small-zh-v1.5,约90M,维度512,Token最大长度512
- moka-ai/m3e-small,约90M,维度768,Token最大长度512
- jinaai/jina-embeddings-v2-small-zh,约120M,维度512,Token最大长度8192
除非对长文本,长切片有较高需求,否则本地学习快速启动建议优先选 BAAI/bge-small。
本文我们会优先以 BAAI/bge-small 为例进行学习讲解。
后续各位有生产或者长文本需求,可以依靠思路自行拓展。
二、下载【句向量】模型并验证
2.1 下载模型
首先,我们先去 ollama.com/ 官网,下载一个 ollama 客户端,ollama 是一款自动化的模型管理和下载工具,你可以把它当作模型界的 pip或者npm就行。
下载之后,你可能会安装一个GUI桌面应用,无视它。
打开你的命令行工具,cmd或者bash,执行命令:
bash
ollama --version如果显示ollama version is 0.15.5 或者其他版本即代表安装ok。
然后,执行如下命令:
bash
ollama pull quentinz/bge-small-zh-v1.5注意,上面这个名字哈,这是 quentinz 打包后提供的模型。
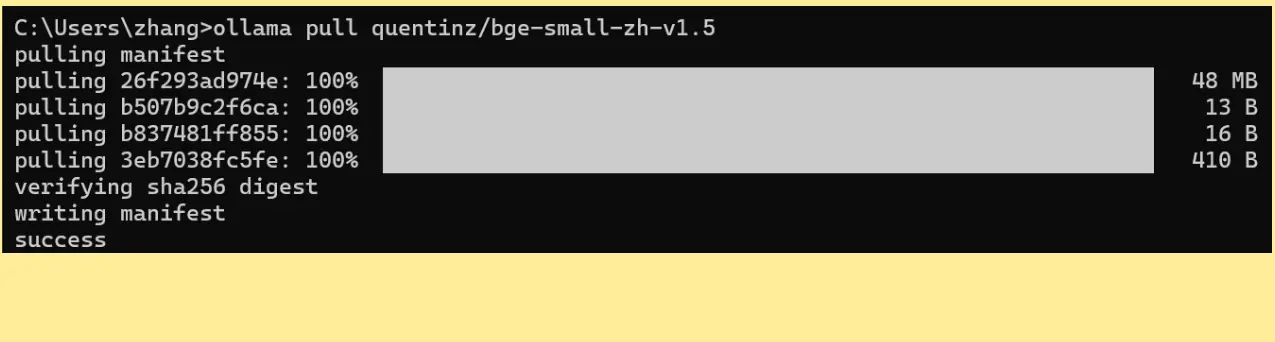
下载完成之后,就该测试这个模型了。
2.2 测试模型
我们核心思路是要通过 ollama 快速启动一个http服务,作为私有的AI API 服务使用。
这里,你有两个选择:
- 只需要保证上面让你无视的那个
ollama GUI正常打开即可,哪怕是收起到托盘也行。 - 新起一个cmd或者bash,执行
ollama serve。
以上两种方式二选一,就可以保证你使用http的形式调用所有通过它Pull下来的模型。
接下来就是测试,如果你是cmd或者powershell,执行以下命令:
cmd
curl http://localhost:11434/api/embeddings -d "{ \"model\": \"quentinz/bge-small-zh-v1.5\", \"prompt\": \"测试文本\" }"如果是bash,则执行:
bash
curl http://localhost:11434/api/embeddings -d '{
"model": "quentinz/bge-small-zh-v1.5",
"prompt": "测试一下"
}'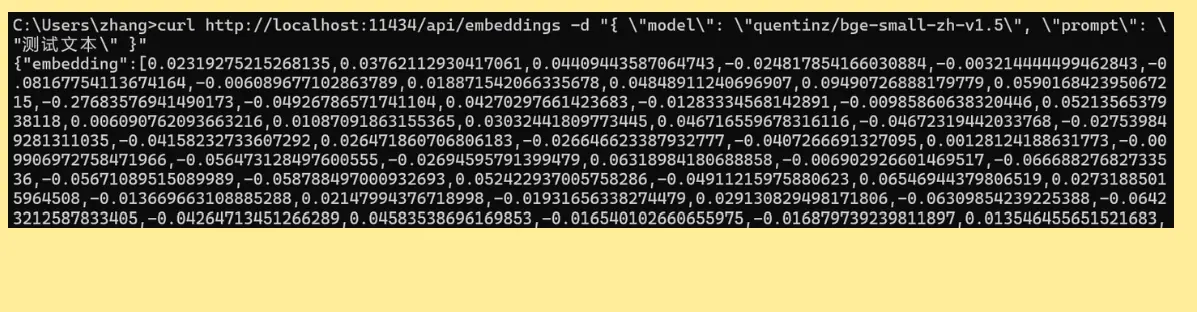
如果你能看到返回一个拥有巨大数组的JSON,那就代表你成功调用了模型。
这个数组的长度如果你复制下来,数一下,会发现这是个长度 512的数组,就是"测试一下"四个字所代表的向量。
还记得上一节的知识点吗?
数组中每一个元素中的浮点数,正是 quentinz/bge-small-zh-v1.5 模型对 "测试一下" 这四个数,从各个维度特征的评估值。
三、下载向量数据库和切片器
执行在demo工程pip安装依赖:
bash
pip install chromadb ollama langchain-text-splitters-
chromadb: 向量数据库本体。
-
ollama: 用来在 Python 里方便地调用你刚才那个 bge-small 模型。
-
langchain-text-splitters: langchain是目前应用最广泛的Agent开发库,没有之一,但我们这次只用它一个很小的功能,也就是拆分器,所以暂时只安装这个即可。
很好,下完这两个库,完成本节目标我们需要下载安装的依赖就备齐了。
在 demo 工程github.com/zhangshichu...里,我已经生成好了 requirements.txt,你可以直接执行以下命令安装即可:
bash
pip install -r requirements.txt即可安装所有需要的依赖。
下一步预告
下节课,我们将开始撰写RAG系统的代码,首当其冲的便是文档切片。
敬请期待!
