前阵子写了 手把手带你 Windows 安装 Hermes Agent,并接入飞书,一直没有用起来,究其原因:有没有不用天天喂上下文、不用折腾 WSL 的 Agent?
最近有个项目冒头很快:OpenHuman ,现在大概 2.3 万 Star (截至 2026 年 5 月),还在 Early Beta。

一、它是什么?
OpenHuman 是 tinyhumansai 团队做的开源桌面 Agent,私密、简单、功能强大。
和 OpenClaw、Hermes 一样,都能写代码、调工具、接消息渠道。但它是:
- 桌面 UI 为主,装完简单配置就能使用;
- 118+ 服务一键 OAuth(Gmail、GitHub);
- 每 20 分钟自动把新数据拉进本地记忆(不用你自己写轮询);
- 记忆落在本机 SQLite + Obsidian 能打开的
.md文件里------这点和 Karpathy 那套「LLM 维护 Markdown 知识库」是同一套思路。
连上 Gmail、GitHub,auto-fetch 按文档大约每 20 分钟往本机记忆里灌一轮;具体怎么切块、怎么叠成树、Obsidian 里长什么样,我放在下面细说。
Hermes 看你平时怎么用、慢慢学;OpenClaw 常得靠插件/MCP 把上下文送进去;OpenHuman 则是 OAuth 连账号,本地压 Markdown,还能同步进 Obsidian vault。
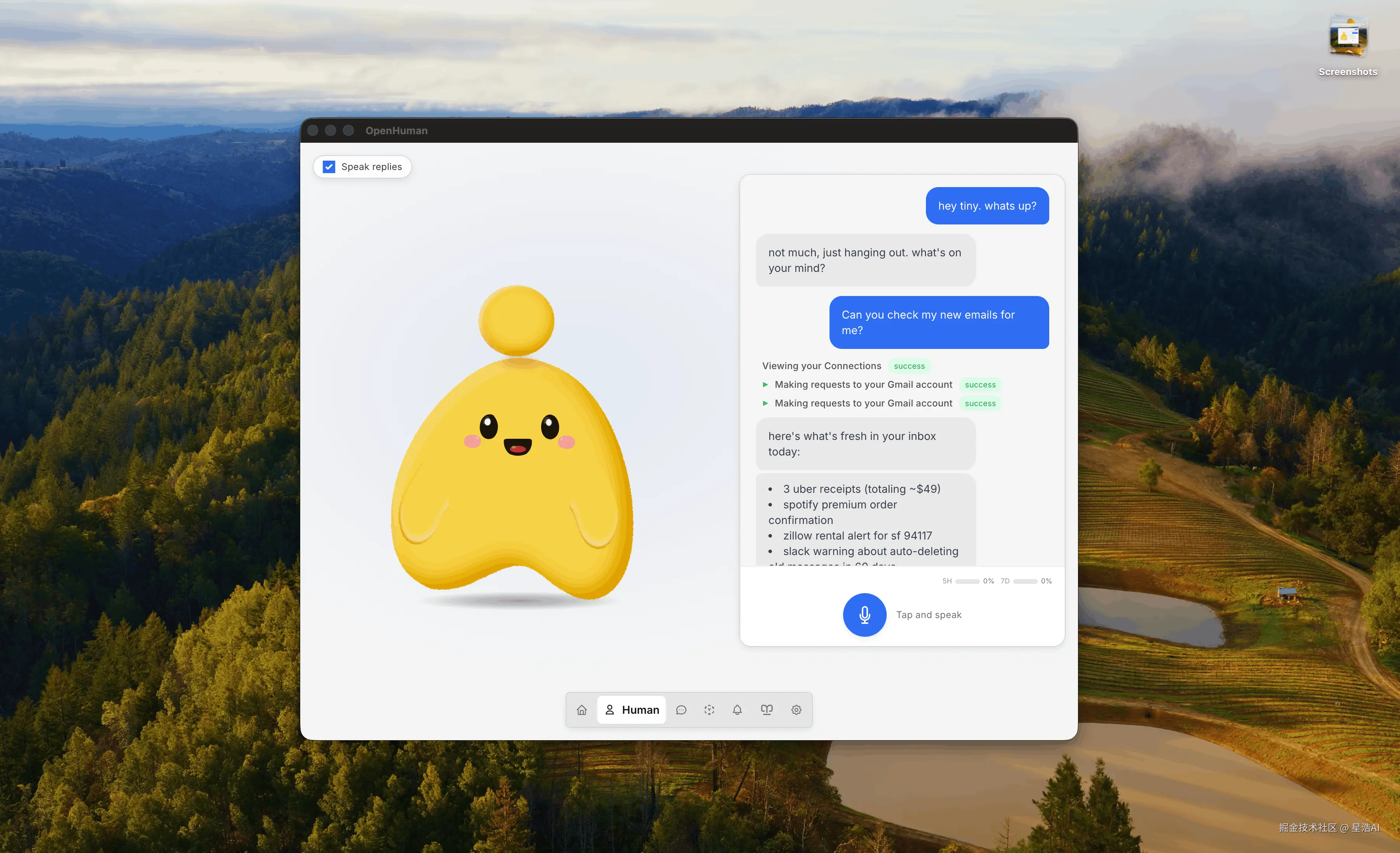
桌面里有个 桌面吉祥物(mascot) ,能语音、能看屏,文档写还能进 Google Meet 当参会者。对不想折腾终端 CLI 的人,这是现成的桌面入口。
目前仓库状态:
- ⭐ GitHub 约 2.3 万 Star(涨得很快,数字会随时间变)
- 📦 Early Beta,Issue 和 Release 都很勤
- 📜 协议是 GPL-3.0 (以仓库 LICENSE 为准;不是 OpenClaw / Hermes 的 MIT,商用要自己看清楚)
二、核心功能一览
| 功能 | 说明 |
|---|---|
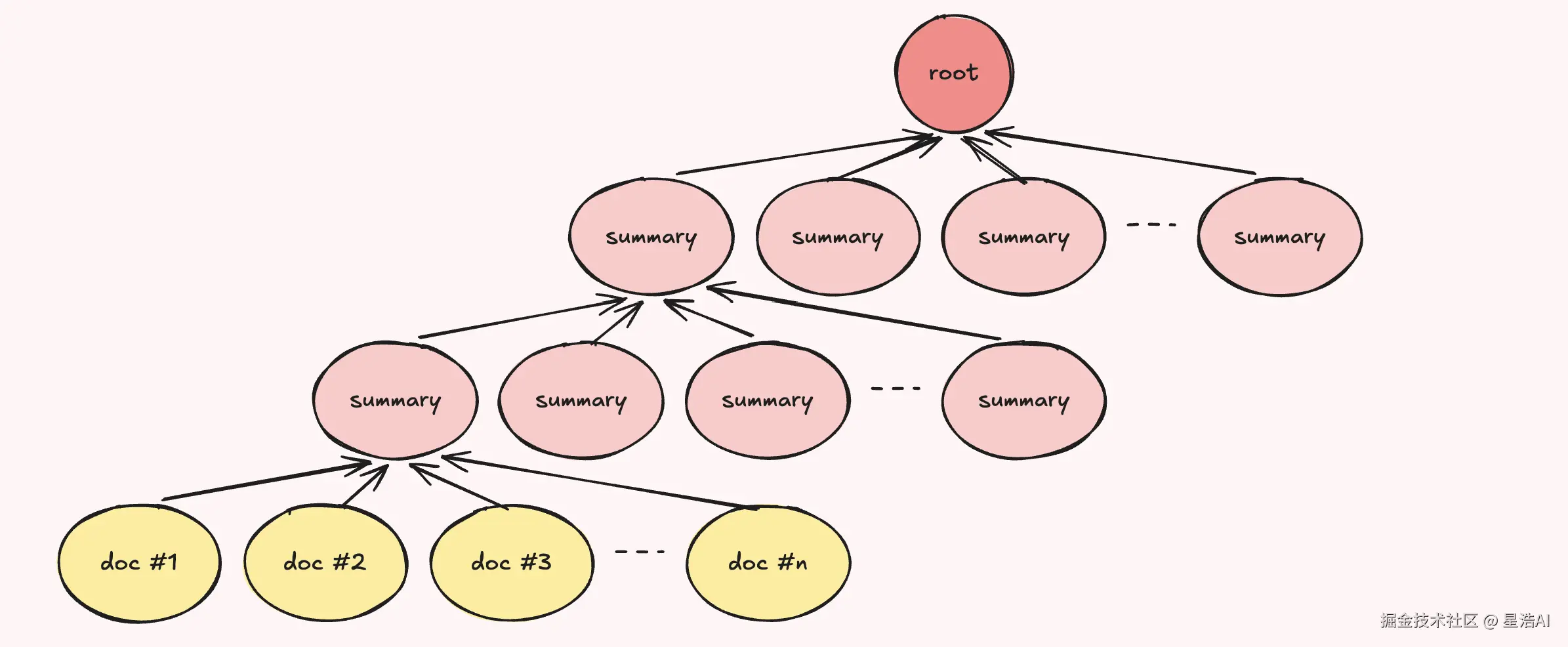
| Memory Tree | 邮件、聊天、文档等进本地流水线,切成 ≤3k token 的 Markdown 块,再叠成摘要树 |
| Obsidian Wiki | 同一批内容同步成 vault 里的 .md,你能打开看、能手改(类似自建 LLM Wiki,见下文) |
| Auto-fetch | 已连接的服务每 20 分钟自动同步一次 |
| TokenJuice | 工具输出、网页、邮件进模型前先压缩,官方自称能省不少 token |
| 模型路由 | 推理 / 快模型 / 视觉自动分流,走官方订阅;也支持 Ollama 本地 |
| 原生工具 | 搜索、爬虫、Coder 全套(git、lint、test...)、语音、还能进 Google Meet |
| 桌面吉祥物 | 会说话、有口型,停手打字后后台还能继续想事儿 |
Gmail、GitHub、Slack、日历这些,在设置里 OAuth 连上就行,不用像 OpenClaw 那样自己写插件搬数据。
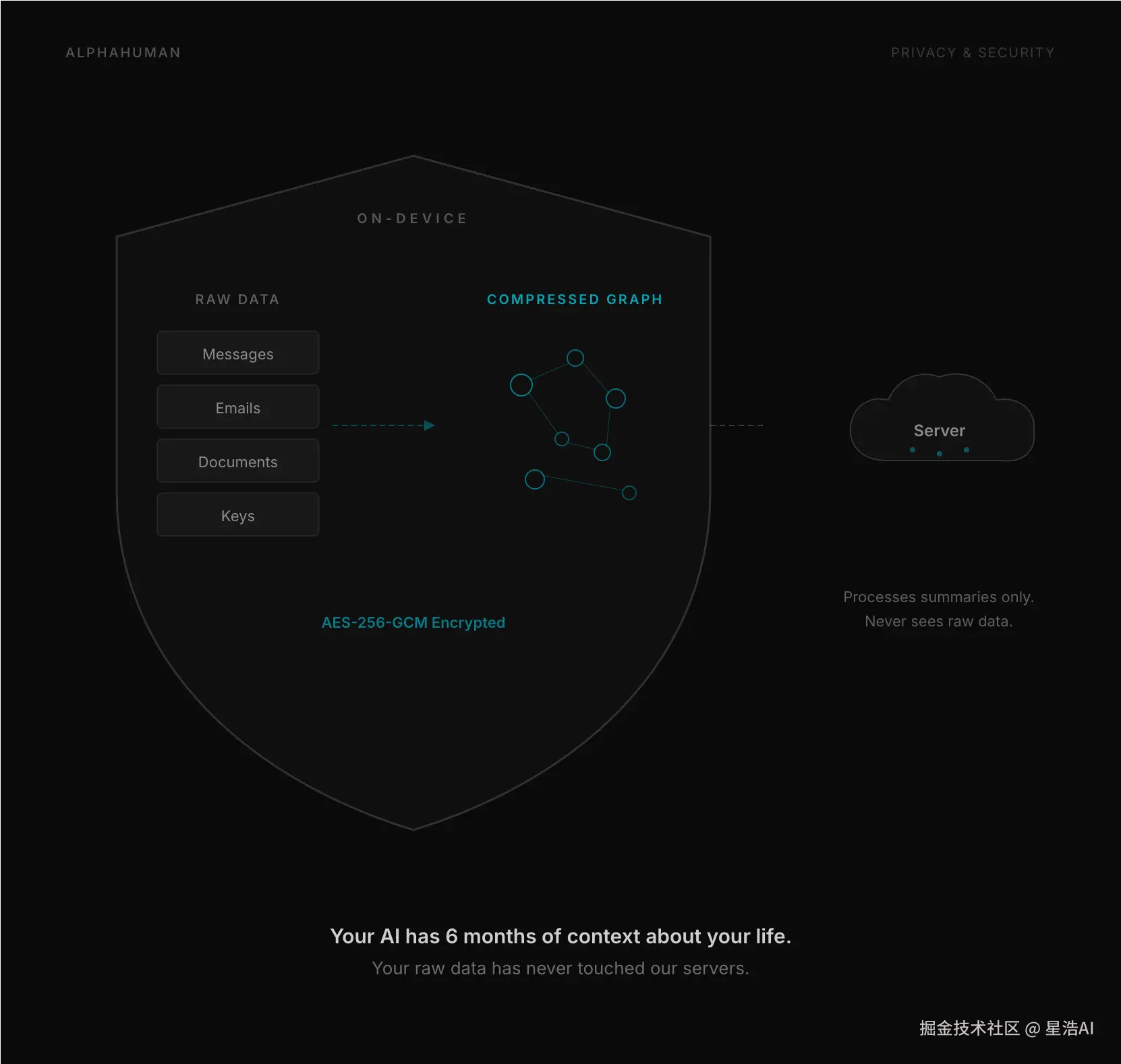
数据默认在 ~/.openhuman(Windows 同理在用户目录),库文件是 memory_tree/chunks.db,wiki 在 wiki/。没主动发进对话的内容,按文档说法是不往外传的。
三、和 OpenClaw、Hermes 对比
| OpenClaw | Hermes Agent | OpenHuman | |
|---|---|---|---|
| 协议 | MIT | MIT | GPL-3.0 |
| 上手 | 终端、Gateway 为主 | 终端 + hermes setup,Win 常要 WSL |
桌面 UI |
| 记忆 | 依赖插件 / 自建 | 学习循环,跨会话检索 | 记忆树 + Obsidian,可接 agentmemory |
| 接第三方 | 自己接 MCP、插件 | 自己配 | 118+ OAuth |
| 定时拉第三方进记忆 | 没有内置 | 无(靠使用过程学习,非 OAuth 轮询) | 每 20 分钟 auto-fetch |
| 模型费用 | 自带 Key | 自带 Key | 官方一套订阅 + 压缩 |
| 工具 | 偏代码、网关 | 47+ 工具,技能能进化 | 代码 + 搜索 + 语音 + Meet |
要是你已经在 Cursor / Claude Code 里用了 agentmemory ,OpenHuman 可以在 config.toml 里设 memory.backend = "agentmemory",跟现有记忆共用,不用另起一套。这块我之前的文章里写过:如何为AI编程工具构建持久化记忆:用 agentmemory 形成知识复利。
官方宣传的「几分钟建立上下文」,流程是连账号 → auto-fetch → Memory Tree 压进 Obsidian。
四、Memory Tree 是啥?
向量库擅长回答「跟这句话像的是什么」。但日常问 Agent 的往往是:
- 今天有啥事?
- 某某客户最近咋样?
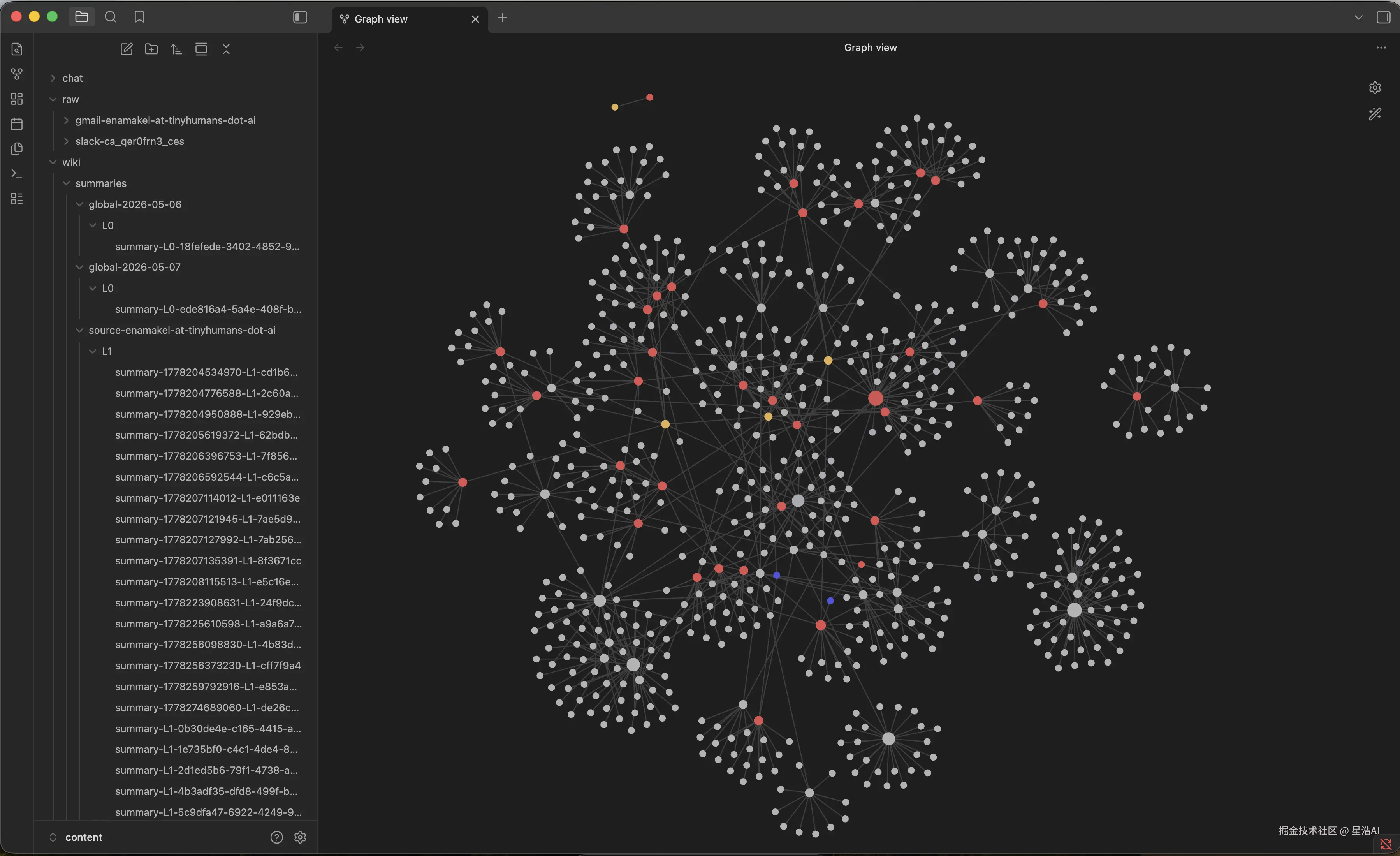
OpenHuman 用 三层树 来存:按来源(Source)、按实体/项目(Topic)、按天(Global)。chunk 有确定性 ID,热路径不调 LLM,重的摘要放后台 worker,免得卡界面。
桌面底部有个 Intelligence 页,能看占了多少盘、多少来源、多少 chunk、实体关系图,还能一键用 obsidian:// 打开 vault。对我这种不喜欢「记忆查不到出处」的人来说,这点比纯 RAG 顺眼。
| 页面上常见指标 | 含义 |
|---|---|
| Storage | chunks.db + Obsidian vault 总大小 |
| Sources | 已 ingest 的来源数(每个 Gmail 标签、Slack 频道各算一个) |
| Chunks | 库里 ≤3k token 的块数量 |
| Topics | 按「热度」建起来的实体主题树数量 |
| Memory graph | 实体关系力导向图,auto-fetch 跑几天后会更密 |
| Ingest 热力图 | 类似 GitHub 贡献图,能看出哪天同步断了 |
和 Karpathy / Obsidian 那套的关系:
OpenHuman 官方明确说灵感来自 Karpathy 的 obsidian-wiki 工作流。
我之前写过一篇《OpenAI 大神 Karpathy 开源:用 Obsidian 实现 LLM Wiki 知识库管理方法》。OpenHuman 把 wiki 维护自动化了:定时拉 Gmail/GitHub,切块叠树,Intelligence 里还能一键 obsidian:// 打开 vault。
如果你已经按那篇文章搭过 Obsidian 知识库,上手 OpenHuman 的 wiki 目录会顺眼很多;区别是,这边主要是 Agent 往 vault 里写,你负责看和改,而不是全靠对话里手动让模型整理。
五、安装
❝
建议 16GB+ 内存。
方式一:官网下安装包
打开 tinyhumans.ai/openhuman,下 DMG / EXE,不想敲命令就走这条。
方式二:脚本安装(和 README 一致)
macOS / Linux:
ruby
curl -fsSL https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.sh | bashWindows(PowerShell):
ruby
irm https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.ps1 | iex装完之后建议这么走
- 打开桌面应用,走一遍短 onboarding
- OAuth 连上你常用的(我先会试 Gmail + GitHub)
- 等 auto-fetch 跑一轮,或在 Intelligence 里点 Run ingest
- 看记忆指标有没有涨,再开始对话。
首次打开会问你打算自动化哪些事、怎么管理工作流,界面比较「产品化」。
项目地址 :github.com/tinyhumansa...
中文 README :github.com/tinyhumansa...