Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
大型语言模型的智能体能力:架构、习得、安全性与未来路径

摘要
从单体语言模型向模块化、技能赋能智能体的转变,标志着大型语言模型(LLMs)实际部署方式的一次根本性转折。智能体技能------即按需加载的、由指令、代码和资源组成的可组合包------使得动态能力扩展无需重新训练成为可能,而无需将所有程序性知识编码于模型权重之中。这一范式通过渐进式上下文披露、可移植技能定义以及与模型上下文协议(MCP)的集成得以形式化。本综述对智能体技能领域进行了全面阐述,该领域在过去几个月中发展迅速。我们围绕四个轴向组织该领域内容:(一)架构基础,审视SKILL.md规范、渐进式上下文加载以及技能与MCP的互补作用;(二)技能获取,涵盖基于技能库的强化学习(SAGE)、自主技能发现(SEAgent)以及组合式技能合成;(三)大规模部署,包括计算机使用智能体(CUA)技术栈、GUI grounding进展,以及在OSWorld和SWE-bench基准测试上的进展;(四)安全领域,近期实证分析显示26.1%的社区贡献技能存在漏洞,这促使我们提出技能信任与生命周期治理框架------一个基于四层关卡机制的权限模型,将技能来源映射至分级的部署能力。我们识别出七大开放性挑战------从跨平台技能可移植性到基于能力的权限模型------并提出了实现可信、自我改进的技能生态系统的研究议程。与先前广泛涵盖LLM智能体或工具使用的综述不同,本文特别聚焦于新兴的技能抽象层及其对下一代智能体系统的影响。相关精选资源集合可在 https://github.com/scienceaix/agentskills 获取。
关键词:智能体技能、大语言模型、工具调用、计算机使用智能体、模型上下文协议、技能库、自主人工智能、渐进式披露、安全性
1.引言
大规模语言模型的能力已显著扩展,但作为自主智能体,其实际效用仍受限于一个根本矛盾:通用模型虽具备广泛知识,却缺乏现实任务所需的专业化流程性专长。微调方法虽能部分解决这一问题,但代价高昂且可组合性有限。检索增强生成(RAG)虽能提供外部知识,但其检索到的内容是被动的------既无法规定多步骤工作流程,也无法捆绑可执行代码,更无法在运行时动态调整智能体的工具权限。
智能体技能通过引入一种模块化的、基于文件系统的抽象机制,解决了这一矛盾,使智能体能够按需获取领域专业知识。在此范式中,技能并非一个模型或提示模板,而是一个自包含的软件包:它包含一个结构化的指令文件(SKILL.md)、可选的脚本、参考文档和资产,并组织在一个目录中。当相关任务出现时,智能体可以发现、加载并遵循该目录中的内容1。其与传统工具的区别在于架构层面:工具执行并返回结果,而技能则通过注入程序性知识、修改执行上下文以及实现信息的渐进式披露,来预备智能体以解决问题。
Anthropic于2025年10月通过在其Claude产品界面推出"智能体技能"功能正式确立了这一概念2,随后于2025年12月将其作为开放标准发布3。在四个月内,其开源仓库anthropics/skills收获了超过62,000个GitHub星标,来自Atlassian、Figma、Canva、Stripe和Notion等合作伙伴开发的技能被收录至精选目录,其他前沿模型提供商也独立采用了结构完全相同的架构体系。
这种快速趋同反映了一个更广泛的共识:当智能体从研究原型转向生产部署时,行业需要标准化的机制来封装、分发和管理过程性专业知识。模型上下文协议(Model Context Protocol,MCP)的成熟,为此提供了互补的基础设施层。该协议是一种将智能体连接至外部数据和工具的开源标准,已于2025年12月捐赠给Linux基金会的智能体人工智能基金会4。技能与MCP共同定义了一个新兴的智能体技术栈:技能提供"做什么",而MCP则提供"如何连接"。
本次综述首次对智能体技能范式进行了全面而聚焦的探讨。尽管已有关于大型语言模型智能体的优秀综述5, 6、关于工具使用的研究7、以及关于图形用户界面智能体的论述8, 9,但尚无研究专门审视已作为一种统一架构原语而兴起的技能抽象层。我们的贡献在于:
- 对智能体技能架构的系统性分析,包括渐进式披露、SKILL.md 规范及其与 MCP 的关系(第 3 节)。
- 涵盖强化学习、自主探索、组合式合成以及人工知识封装等方法的技能获取分类法(第 4 节)。
- 对作为技能主要部署领域的计算机使用智能体栈的批判性评估,附定量基准分析(第 5 节)。
- 首次对智能体技能安全性的整合论述,综合了三项同步的实证研究,并提出一个创新的技能信任与生命周期治理框架,该框架将通过验证关卡的获取溯源映射至分级部署权限(第 6 节)。
- 阐述了该领域的七大开放挑战及未来研究议程(第 7 节)。
2.背景与范围
2.1 从提示工程到技能工程
代理技能的发展可理解为大语言模型能力扩展历经三种范式的演进过程。提示工程(2022--2023)表明,精心设计的指令能够激发出令人印象深刻的零样本和少样本行为,但提示本身具有瞬时性、非模块化特点,且难以进行版本管理或共享。工具调用与函数调用(2023--2024)使模型能够调用外部API,但每个工具是原子化的------即具有明确输入输出的单一函数。工具仅执行并返回结果,并不会重塑代理对任务的理解。
技能工程(2025年至今)引入了更高阶的抽象概念。技能是一种可包含指令、工作流程指引、可执行脚本、参考文档及元数据的组合单元,其内容经组织编排后能在相关情境下动态加载。其核心洞见在于,现实世界中的许多任务并非仅需单一工具调用,而是需要一个基于领域特定过程性知识进行协调决策的序列。以PDF处理技能为例,它不仅提供一个"填写表单"功能,更会教导智能体如何处理PDF文件、应使用哪些程序库、需处理哪些边界情况以及执行何种代码1。
2.2 与先前研究的关系
几项基础性研究已预示了技能范式的出现。Voyager 10在《我的世界》中为具身智能体引入了技能库,通过存储和组合LLM生成的程序来解决日益复杂的任务。CREATOR 11和《作为工具制造者的大语言模型》12探索了LLM能够创造自有工具的理念。Toolformer 13则展示了自我教授的工具使用能力。然而,这些研究主要关注受限环境中模型生成的技能。相比之下,"智能体技能"范式强调由人类编写、可移植且受管控的技能包,其设计目标是在异构智能体平台上实现生产环境部署。
2.3 研究范围与方法论
在本调查中,我们围绕"智能体技能"、"技能库"、"大语言模型工具使用"、"计算机使用智能体"及"模型上下文协议"等关键词,系统检索了arXiv、ACL Anthology、NeurIPS/ICML/ICLR会议论文集以及Anthropic的官方出版物。我们明确排除了早期综述中对通用大语言模型智能体架构及宽泛工具使用分类法的涵盖,转而聚焦于技能抽象层及其直接关联的生态系统。
3.架构基础
3.1 SKILL.md 规范
本质上,一项技能是一个包含SKILL.md文件的目录,该文件具有YAML前置元数据,用于指定名称和描述。代理在启动时仅预加载此元数据(通常只有几十个令牌)到其系统提示中,从而支持大型技能库而无需承担上下文成本。SKILL.md文件的正文部分包含流程性指令,仅在技能触发时加载。其他资源(脚本、参考文档、资产)存放在子目录中,按需加载1。
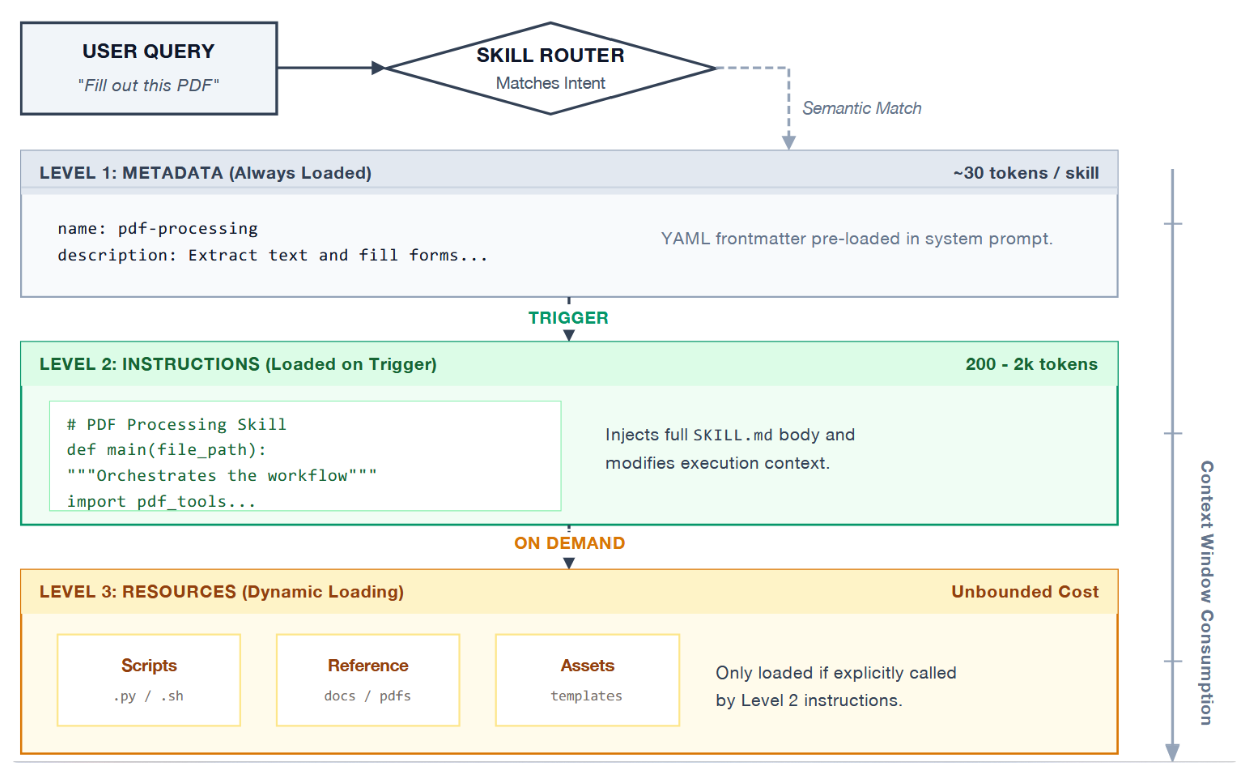
图1:智能体技能的渐进式揭示架构。为在保持任意深度程序性知识可访问性的同时最小化上下文窗口消耗,信息被分为三个阶段加载。令牌估算值为各技能近似平均值;改编自Zhang、Lazuka与Murag的研究1。
这种三级渐进式披露是决定性的架构创新。正如张等人所阐述的:构建一项技能"如同为新员工编写入职指南"1。第一级充当目录;第二级提供章节内容;第三级则提供技术附录。
3.2 技能执行生命周期
当用户请求与技能描述匹配时,智能体触发两阶段执行:首先,该技能的指令及所需资源将以隐藏(元)消息形式注入会话上下文------模型可见但用户界面不予渲染;其次,智能体的执行上下文被修改:预授权工具(如特定的bash命令、文件读写权限)被激活,智能体随即基于增强的上下文继续完成任务。关键在于,技能执行改变的是智能体的准备工作,而非直接修改输出。这使技能区别于函数调用------后者由工具直接生成结果。技能是在智能体生成响应前,重塑其认知与行动能力的基础。
3.3 能动性栈:技能与 MCP
模型上下文协议(Model Context Protocol,MCP)于2024年11月发布14,并于2025年12月捐赠给智能体人工智能基金会4,它提供了一个互补层。MCP标准化智能体如何连接外部数据源和工具,通过JSON-RPC 2.0 协议包含三个基本组件:工具(模型调用函数)、资源(应用控制数据)和提示(用户调用模板)15。
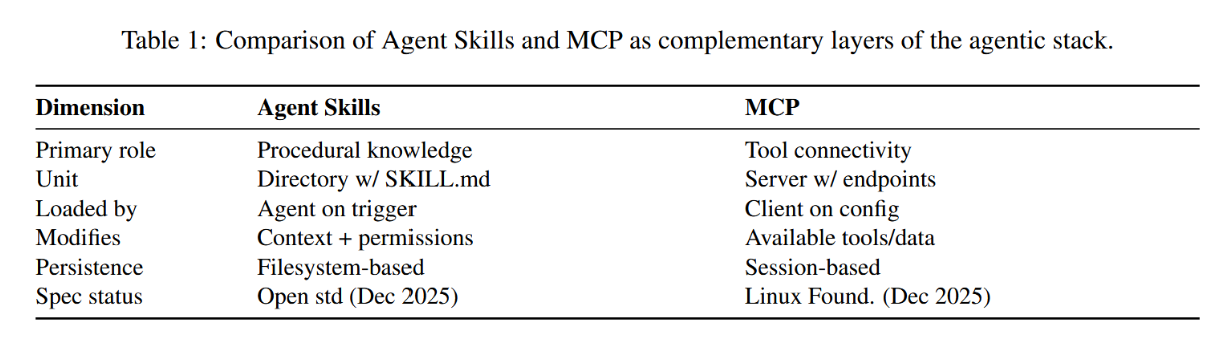
表1:智能体技能与模型上下文协议作为智能体堆栈互补层的对比。
3.4 高级工具使用集成
Anthropic 2025年11月发布的"高级工具使用"功能16引入了三项深化技能与工具集成的机制:(1) 工具搜索工具,支持以编程方式从大型注册库中发现相关工具,将令牌开销降低最高达85%;(2) 编程式工具调用,模型通过代码而非结构化JSON执行工具,使Opus 4.5的调用准确率从79.5%提升至88.1%;(3) 工具学习,允许模型研读工具文档以提升调用质量。这些功能解决了实践中的瓶颈问题:随着技能库规模扩大,智能体需要高效机制在技能工作流中发现并调用恰当工具。
4.技能习得与学习
技能范式的核心问题在于技能如何被创造、精炼与整合。我们在表2中总结了四种不同的习得模式。
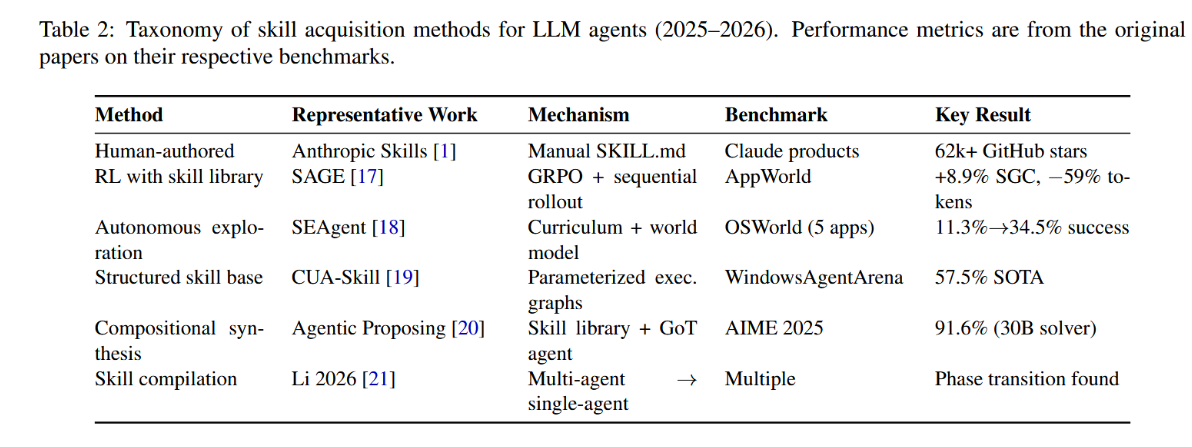
表2:LLM智能体技能习得方法分类(2025--2026)。性能指标源自各原始论文在其相应基准测试上的报告。
4.1 人工撰写技能
最具即时影响力的获取方式是人类直接创作。Anthropic的框架在设计上有意使其易于实现:一项技能可以简单到只是一个包含几十行指令的Markdown文件1。Claude Code中的"技能创建元技能"能够通过自然语言描述构建新技能的基本框架,自动生成目录结构、SKILL.md文件及配套脚本集。在Atlassian、Canva和Sentry等企业的实际部署中,已产出多款编码专有工作流程的生产级技能。
2025年12月发布的合作伙伴目录2建立了一个审核流程:合作伙伴提交技能,经安全和质量审核后方可收录。该模式效仿了应用商店的治理机制,但由于技能本质上是结构化文档而非可执行应用程序,其准入门槛显著降低。
4.2 基于技能库的强化学习
SAGE(Skill Augmented GRPO for self-Evolution,技能增强型GRPO自进化框架)17 代表了一种通过强化学习获取技能最为严谨的方法。其核心创新在于"顺序推演":智能体并非在孤立任务中训练,而是部署于一系列相似任务链中,先前任务生成的技能得以保存并在后续任务中复用。技能集成奖励机制结合了基于结果的验证信号与一项额外激励,该激励旨在奖励高质量、可复用技能的创造。在AppWorld测试环境中,SAGE实现了72.0%的任务目标完成率和60.7%的场景目标完成率------相较于无技能库的基线GRPO实现了8.9%的绝对性能提升------同时所需交互步骤减少了26%,生成令牌数降低了59%。这种效率提升对于生产部署尤其重要,因为令牌消耗量直接关联成本。
4.3 自主技能发现
SEAgent 18 致力于解决一个互补性挑战:智能体能否自主探索先前未接触软件的操作技能?该框架引入了用于逐步轨迹评估的世界状态模型,以及能够从持续更新的软件指南记忆库中生成渐进复杂任务的课程生成器。其"专家到通才"的训练策略将领域专属智能体的知识整合到统一模型中。在OSWorld平台的五个新型软件环境中,SEAgent将任务成功率从11.3%提升至34.5%,较具竞争力的UI-TARS基线实现了23.2个百分点的突破性提升。
4.4 结构化技能库
CUA-Skill 19 采用知识工程方法,将人类计算机使用专业知识编码为参数化的执行图和组合图。每项技能均具备类型化参数、前置条件和可组合性规则。CUA-Skill 智能体支持动态技能检索、参数实例化以及具备记忆感知的故障恢复机制。在 WindowsAgentArena 基准测试中,该方法实现了目前最优的 57.5% 成功率,显著超越了那些缺乏结构化技能表示的方法。
4.5 组合技能合成
代理式提议20表明技能可在问题解决过程中动态组合。一个专用智能体从技能库中选取并组合模块化推理技能,将问题求解建模为目标驱动过程。采用该方法、参数量为300亿的求解器在AIME 2025数学竞赛基准测试中达到91.6%的准确率,证明技能组合能够产生超越单一技能的综合能力。
4.6 技能编译:从多智能体到单智能体
Li 21的一项启发性发现表明,多智能体系统常可被"编译"为单智能体技能库,在保持准确性的同时显著降低令牌使用量和延迟。然而,这种压缩存在相变现象:当技能库规模超过临界值后,技能选择的准确性会急剧下降。这一发现对技能库管理具有实际意义:单个智能体能够有效管理的技能数量存在根本性限制。
5.部署:计算机使用代理栈
计算机使用代理(CUAs)已成为技能范式的主要部署领域,因为通过图形用户界面操作计算机本质上需要组合感知、推理与行动的序列,这自然契合了技能抽象的映射关系。
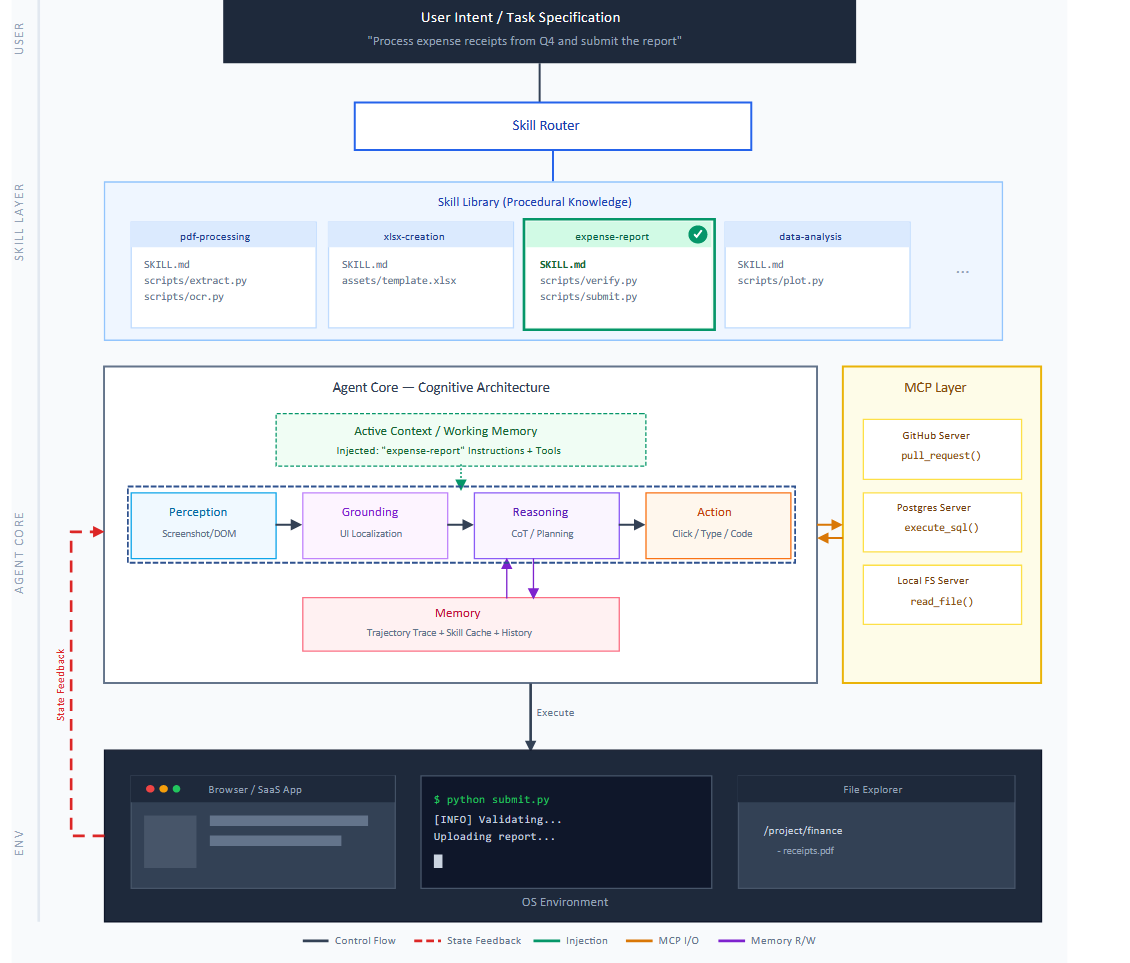
图2:配备技能库的计算机使用智能体架构图,展示技能库、感知-锚定-执行管道、MCP连接层与操作系统环境之间的协同机制。活跃技能(高亮显示)由路由器选择并注入智能体上下文。
5.1 图形用户界面智能体架构
CUA架构的技术前沿已取得快速发展。2025年1月提出的UI-TARS 22通过增强感知、统一动作建模与系统二推理,在十项GUI基准测试中树立了全新基准。其后续版本UI-TARS-2 23引入了可扩展轨迹生成的数据飞轮,并稳定了多轮强化学习训练,在OSWorld上达到47.5%的准确率,在AndroidWorld上达到73.3%的准确率。
智能体S224提出了一种组合式通用-专家框架,该框架采用混合式接地机制以实现精确的图形用户界面定位,在OSWorld基准测试中,相较于Claude Computer Use和UI-TARS分别取得了18.9%与32.7%的相对性能提升。
OpenCUA 25提供了最全面的开源框架,其核心是AgentNet------首个涵盖三大操作系统、超过200个应用程序的大规模CUA数据集。OpenCUA-72B在OSWorld-Verified基准上取得了45.0%的成绩,这是当前最强的开源成果。该研究以亮点论文形式发布于NeurIPS 2025,标志着该领域的成熟。
5.2 图形用户界面接地技术进展
精准的图形用户界面定位------即识别正确的屏幕交互元素------始终是CUAs的核心能力。UGround 26作为ICLR 2025口头报告论文,基于130万张屏幕截图中的1000万个GUI元素进行训练,构建了规模最大的GUI视觉定位数据集,其绝对性能超越现有模型高达20%。Jedi框架27通过界面分解与合成技术将定位数据扩展至400万样本,成功将OSWorld智能体成功率从5%提升至27%。Yuan等人28的研究取得了惊人成果:基于强化学习的自我进化训练使一个70亿参数模型在ScreenSpot-Pro基准上达到47.3%的准确率,仅用3000个训练样本便以24.2个百分点的优势超越720亿参数的UI-TARS模型。与之相似,GUI-Actor29通过基于注意力的动作头实现免坐标视觉定位,其70亿参数模型在ScreenSpot-Pro基准上也超越了UI-TARS-72B模型。
5.3 基准测试概况
表3呈现了当前CUA基准测试的发展状况。该领域已取得显著进展:在OSWorld上,成功率从2024年初的个位数攀升至2025年12月超越人类水平的表现(72.6%对比72.36%的人类基线)。然而,更具挑战性的场景------专业应用(ScreenSpot-Pro)、长周期任务(OS-Marathon 30)以及混合图形界面-代码工作流(CoAct-1 31)------仍暴露出明显的性能差距。
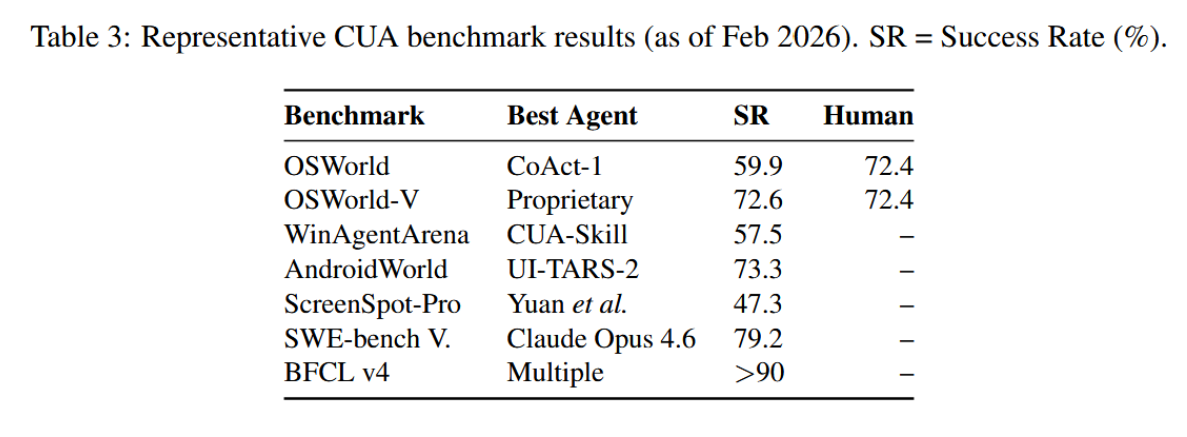
表3:代表性CUA基准测试结果(截至2026年2月)。SR = 成功率(%)。
6.智能体技能安全性
智能体技能的快速普及引入了一个重要且新颖的攻击面。与传统软件包不同,技能将自然语言指令与可执行代码相结合,并以智能体完全信任的形式存在。在2025年10月至2026年2月期间同期发表的三项研究,首次对这一威胁态势进行了实证性描述。
6.1 通过技能实现的提示词注入
Schmotz等人32的研究表明,智能体技能可实现"极其简单"的提示词注入攻击。攻击者通过在冗长的SKILL.md文件及引用脚本中嵌入恶意指令,能够窃取内部文件或密码等敏感数据。尤为关键的是,作者揭示了一款主流编程智能体的系统级防护机制存在被绕过的风险:用户针对特定任务的良性操作批准若包含"不再询问"选项,该授权状态会延续至语义相近的危险操作中。此类攻击利用了技能机制的根本信任模型------技能一旦加载,其指令即被视作权威上下文执行。
6.2 大规模漏洞
Liu等人33开展了首次大规模实证安全分析,从两大主流市场收集了42,447个技能,并利用SkillScan------一个结合静态分析与基于LLM语义分类的多阶段检测框架------对31,132个技能进行了分析。研究结果发人深省:26.1%的技能至少存在一个漏洞,涵盖四大类别的14种不同模式:提示词注入、数据外泄(13.3%)、权限提升(11.8%)及供应链风险。捆绑可执行脚本的技能存在漏洞的可能性是纯指令型技能的2.12倍(OR=2.12,p < 0.001)。5.2%的技能表现出强烈暗示恶意意图的高危模式。
6.3 已确认恶意技能
一项后续研究34通过行为验证来自两个社区注册库的98,380项技能,构建了首个经过确认的恶意技能真实数据集。在包含632个漏洞的157项已确认恶意技能中,作者识别出两种攻击原型:通过供应链技术窃取凭证的数据窃取者 ,以及通过指令操纵颠覆智能体决策的代理劫持者。单一的产业化攻击者通过模板化的品牌仿冒手段,占已确认攻击案例的54.1%。
6.4 迈向治理框架
上述发现------从通过受信任技能文件进行的提示注入32,到42,447个社区技能中26.1%的漏洞率33,再到已确认的大规模恶意行为者34------共同表明当前的隐式信任模型是不可持续的。然而,尚无先前工作提出一种能够综合考虑技能来源多样性、SKILL.md格式特有的渐进式披露攻击面以及运行时信任演进需求的集成治理架构。
我们提出一个技能信任与生命周期治理框架(图3),它将本综述中的各项见解整合为一个原则性的治理模型。该框架包含三个组成部分:
(1)验证关卡。四个顺序关卡(G1--G4)提供纵深防御。G1应用静态分析(模式匹配和依赖扫描)来标记已知漏洞特征。G2使用基于LLM的语义分类来检测技能声明意图与实际指令之间的不匹配,以应对Schmotz等人32识别的间接提示注入向量。G3在行为沙箱中执行技能,以检测静态分析无法发现的副作用,这基于已确认的恶意技能平均跨越3个攻击链阶段、含有4.03个漏洞的发现34。G4验证提议的权限清单:这是一份所需能力(工具、文件路径、网络访问)的正式声明,将与G3中观察到的行为进行比对。
(2)信任层级。框架根据技能通过的关卡及其来源,将其分配至四个层级(T1--T4)之一。关键见解在于,映射并非二元(安全/不安全)而是渐进的,遵循最小权限原则。未经审查的社区技能(T1)仅获得指令级访问权限,且工具完全隔离。供应商认证技能(T4)获得全部能力。这直接回应了捆绑可执行脚本会使漏洞风险增加2.12倍33的发现:T1和T2技能永远不会被授予脚本执行权限。
(3)生命周期信任演进。已部署技能受到持续的运行时监控。异常行为(意外的工具调用、权限边界探测)会触发降级或撤销。反之,具有清洁运行历史的技能可获得晋升。这创建了一种类似于软件包管理生态系统中声誉体系的激励结构。
该框架特意具备架构感知能力:它直接映射到第3节中识别的三个渐进式披露层级。第1级元数据是T1层级唯一暴露的组件;第2级指令在T2及以上层级可访问;第3级可执行脚本需要T3或T4信任。这种对应关系确保治理决策基于实际的攻击面,而非统一应用。
7.开放挑战与研究议程
我们识别出定义智能体技能研究前沿的七个开放挑战:
挑战一:跨平台可移植性。尽管"智能体技能"已作为开放标准发布,但真正意义上的跨平台可移植性仍处于愿景阶段。为Claude开发的技能可能隐式依赖其特定能力(代码执行环境、工具签名、模型行为)。实现真正的可移植性需要:(a)通用技能运行时,或(b)面向不同智能体平台的技能编译方案。
挑战二:大规模技能选择。Li 21 发现技能选择准确性会随技能库规模增长出现相变。当企业技能库扩展至数百或数千项技能时,路由问题------即针对给定查询确定应激活哪些技能------将面临组合爆炸的挑战。高级工具使用功能16通过工具搜索部分解决了该问题,但根本的扩展性难题依然存在。
挑战三:技能组合与编排。现实任务通常需要组合多种技能。CUASkill的组合图19与Agentic Proposing的动态组合20提供了初步解决方案,但针对多技能编排的原则性框架------包括冲突解决、资源共享与故障恢复------仍待完善。
挑战四:基于能力的权限模型。当前技能执行采用隐式信任机制:技能一旦加载,即可引导智能体使用任何可用工具。第六章节的安全研究结果表明,这种信任模式存在可利用漏洞。建立基于能力的权限系统,即每项技能声明所需权限,并由智能体或用户显式授予权限,将能显著减少攻击面。
挑战五:技能验证与测试。与拥有单元测试和CI/CD流程的软件包不同,当前技能体系缺乏标准化测试框架。Anthropic的评估指南35提供了原则性指导,但未包含技能专用工具。自动化技能验证------确认技能仅执行声明功能而无越界行为------仍是与AI安全和形式化方法交叉的开放性技术难题。
挑战六:持续技能学习中的灾难性遗忘问题。Shenfeld等人36探究预训练大语言模型能否在不损害现有能力的前提下学习新技能,发现自蒸馏技术提供了可行路径。然而,动态加载技能与模型基础能力之间的相互作用------技能是否会无意中"覆盖"有用的默认行为------仍缺乏深入理解。
挑战七:评估方法论。现有基准测试主要评估智能体的任务完成度,鲜少直接评估技能质量。需要建立针对技能复用性(技能能否跨任务泛化?)、可组合性(能否与其他技能协同?)与可维护性(对环境变化的鲁棒性如何?)的量化指标,以评估技能生态系统而非单次智能体运行效果。
8.讨论
智能体技能范式代表着从整体智能到模块化专业知识的转变。这一转变带来的实际影响超越了技术架构层面。对组织而言,技能提供了一种机制,能够将制度性知识编码为可经受人员更迭的形式------相当于标准操作流程的数字化版本。对于人工智能生态系统,开放的技能标准会产生网络效应:贡献至公共领域的每一项技能都在为所有用户提升平台价值。然而安全挑战真实而紧迫。Liu等人33发现的26.1%漏洞率不仅是一个技术指标,更反映了开放性与安全性之间的根本矛盾------这种矛盾自软件包管理器到应用商店,始终存在于每个主要软件生态系统中。我们提出的信任与生命周期治理框架(图3)通过将信任决策从二元化的接受/拒绝解耦为分级体系,使权限与溯源信息和验证深度相匹配,从而提供了一条原则性的发展路径。技能生态系统目前正处于"前治理"阶段,未来数月内关于验证流程、权限模型和信任层级的决策将塑造其未来数年的发展轨迹。从研究视角看,最具前景的方向在于技能获取与部署的交叉领域。SAGE17与SEAgent18的研究表明智能体可通过经验学习技能,但这些习得技能属于模型内部表征------无法像人类编写的SKILL.md文件那样被检查、共享或治理。弥合这一鸿沟------使智能体不仅能学习技能,更能将其外化为可移植、可审计的实例------将实现技能获取范式与部署范式的统一。
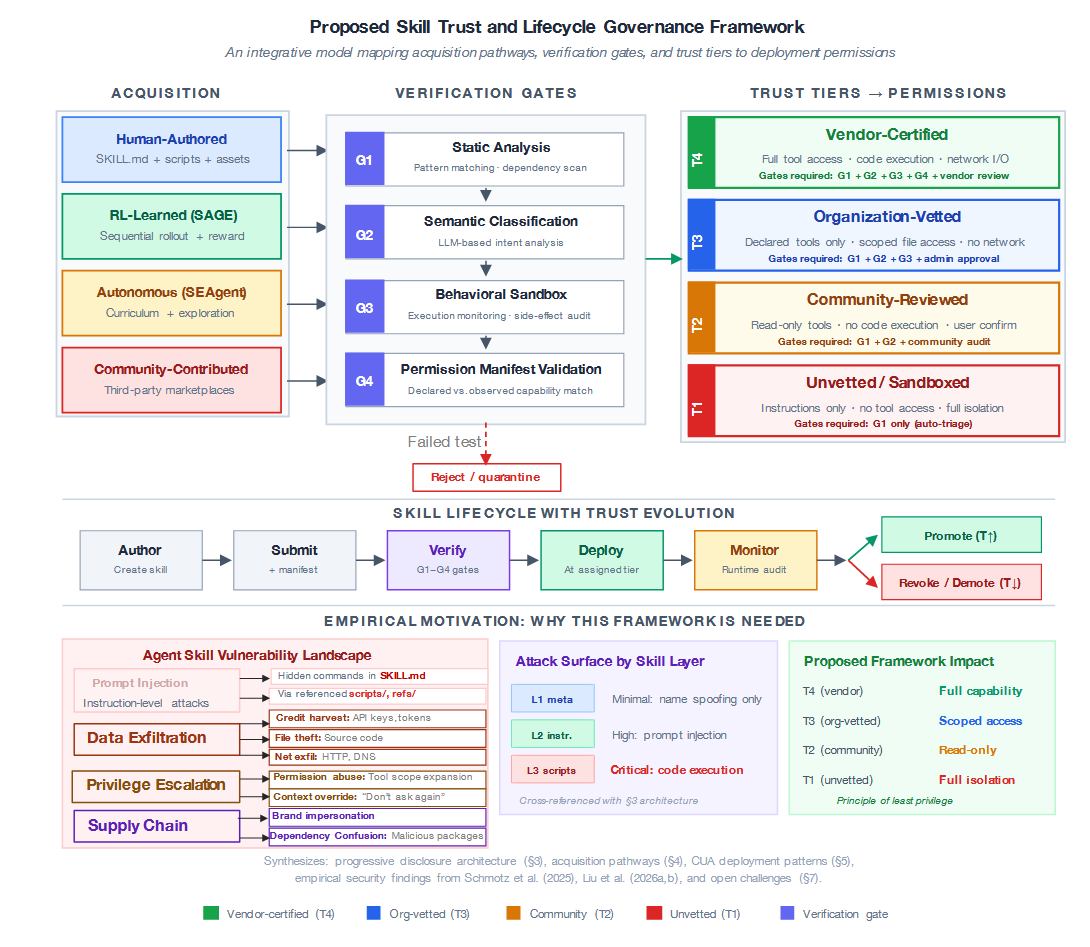
图3:技能信任与生命周期治理框架。该整合模型------本调研的原创贡献------将第4节识别的四条技能获取路径,通过四阶段验证流程(G1--G4)映射至四个信任层级(T1--T4),并依据最小权限原则决定部署许可。生命周期流(中下部)通过运行时监测实现信任演进。实证依据(下部面板)综合了第3节的架构攻击面分析与三项独立研究的安全发现32, 33, 34。此前尚无研究提出跨越技能溯源、验证与运行时权限的统一治理模型。
9.总结
智能体技能已成为下一代基于大语言模型的智能体基础抽象范式。通过将程序性专业知识封装为可组合、可移植且动态加载的模块,技能体系化解了通用模型与专业化任务需求间的矛盾。从2025年10月Anthropic的首发到同年12月的开放标准化,该范式已获多家前沿模型供应商采纳------生态系统的迅猛发展印证了行业对此抽象层的共识。本综述从四个维度追溯了技能范式的发展脉络:架构基础、获取方法、CUA技术栈中的部署实践及安全性。该领域进展显著:一年前尚属理想化的基准测试结果如今已成常态,而安全治理、跨平台可移植性、技能组合等新挑战已构成下一阶段的前沿议题。未来发展需在多方向同步推进:建立可产生可检视产出的原则性技能学习算法、构建兼顾可用性的鲁棒权限模型、开发超越任务完成度评估的技能质量评价框架,以及平衡开放与安全的管理架构。智能体技能范式虽处于早期阶段,但其发展轨迹预示,该范式将在未来数年人类与人工智能系统的协同中扮演核心角色。
10.引用文献
- 1 Barry Zhang, Keith Lazuka, and Mahesh Murag. Equipping agents for the real world with agent skills. https://www.anthropic.com/engineering/ equipping-agents-for-the-real-world-with-agent-skills, 2025. Anthropic Engineering Blog, Oct 2025.
- 2 Anthropic. Introducing agent skills. https://www.anthropic.com/news/skills, 2025. Product Announcement, Oct 2025.
- 3 Anthropic. Agent skills open standard. https://agentskills.io, 2025. Open standard specification.
- 4 Anthropic. Donating the model context protocol and establishing the agentic AI foundation. https://www. anthropic.com/news/donating-the-model-context-protocol-and-establishing-of-the-agentic-ai 2025. Dec 9, 2025.
- 5 Junyu Luo et al. Large language model agent: A survey on methodology, applications and challenges. arXiv preprint arXiv:2503.21460, 2025.
- 6 Aske Plaat et al. Agentic large language models: A survey. arXiv preprint arXiv:2503.23037, 2025.
- 7 Changle Qu et al. Tool learning with large language models: A survey. Frontiers of Computer Science, 19(8), 2025.
- 8 Chaoyun Zhang et al. Large language model-brained GUI agents: A survey. arXiv preprint arXiv:2411.18279, 2024. Updated May 2025.
- 9 Xueyu Hu et al. OS agents: A survey on MLLM-based agents for general computing devices use. In Proceedings of the Association for Computational Linguistics (ACL), 2025.
- 10 Guanzhi Wang et al. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023.
- 11 Cheng Qian et al. CREATOR: Tool creation for disentangling abstract and concrete reasonings of large language models. In Findings of EMNLP, 2024.
- 12 Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, and Denny Zhou. Large language models as tool makers. arXiv preprint arXiv:2305.17126, 2023.
- 13 Timo Schick et al. Toolformer: Language models can teach themselves to use tools. 2024.
- 14 Anthropic. Introducing the model context protocol. https://www.anthropic.com/news/ model-context-protocol, 2024. Nov 2024.
- 15 Model Context Protocol. Model context protocol specification (2025-11-25). https:// modelcontextprotocol.io/specification/2025-11-25, 2025.
- 16 Anthropic. Introducing advanced tool use on the claude developer platform. https://www.anthropic.com/ engineering/advanced-tool-use, 2025. Nov 24, 2025.
- 17 Jiongxiao Wang et al. Reinforcement learning for self-improving agent with skill library. arXiv preprint arXiv:2512.17102, 2025.
- 18 Zeyi Sun, Ziyu Liu, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Tong Wu, Dahua Lin, and Jiaqi Wang. SEAgent: Selfevolving computer use agent with autonomous learning from experience. arXiv preprint arXiv:2508.04700, 2025.
- 19 Tianyi Chen et al. CUA-Skill: Develop skills for computer using agent. arXiv preprint arXiv:2601.21123, 2026.
- 20 Zhengbo Jiao et al. Agentic proposing: Enhancing large language model reasoning via compositional skill synthesis. arXiv preprint arXiv:2602.03279, 2026.
- 21 Xiaoxiao Li. When single-agent with skills replace multi-agent systems and when they fail. arXiv preprint arXiv:2601.04748, 2026.
- 22 Yujia Qin et al. UI-TARS: Pioneering automated GUI interaction with native agents. arXiv preprint arXiv:2501.12326, 2025.
- 23 Haoming Wang et al. UI-TARS-2 technical report: Advancing GUI agent with multi-turn reinforcement learning. arXiv preprint arXiv:2509.02544, 2025.
- 24 Saaket Agashe et al. Agent S2: A compositional generalist-specialist framework for computer use agents. arXiv preprint arXiv:2504.00906, 2025.
- 25 Xinyuan Wang et al. OpenCUA: Open foundations for computer-use agents. In Advances in Neural Information Processing Systems (NeurIPS), 2025. Spotlight.
- 26 Boyu Gou et al. UGround: Universal visual grounding for GUI agents. In International Conference on Learning Representations (ICLR), 2025. Oral.
- 27 Tianbao Xie et al. Scaling computer-use grounding via user interface decomposition and synthesis. In Advances in Neural Information Processing Systems (NeurIPS), 2025. Spotlight.
- 28 Xinbin Yuan et al. Enhancing visual grounding for GUI agents via self-evolutionary reinforcement learning. arXiv preprint arXiv:2505.12370, 2025.
- 29 Qianhui Wu et al. GUI-Actor: Coordinate-free visual grounding for GUI agents. arXiv preprint arXiv:2506.03143, 2025.
- 30 Jing Wu et al. OS-Marathon: Benchmarking computer-use agents on long-horizon repetitive tasks. arXiv preprint arXiv:2601.20650, 2026.
- 31 Linxin Song et al. CoAct-1: Computer-using agents with coding as actions. arXiv preprint arXiv:2508.03923, 2025.
- 32 David Schmotz, Sahar Abdelnabi, and Maksym Andriushchenko. Agent skills enable a new class of realistic and trivially simple prompt injections. arXiv preprint arXiv:2510.26328, 2025.
- 33 Yi Liu et al. Agent skills in the wild: An empirical study of security vulnerabilities at scale. arXiv preprint arXiv:2601.10338, 2026.
- 34 Yi Liu et al. Malicious agent skills in the wild: A large-scale security empirical study. arXiv preprint arXiv:2602.06547, 2026.
- 35 Anthropic. Demystifying evals for AI agents. https://www.anthropic.com/engineering/ demystifying-evals-for-ai-agents, 2025.
- 36 Idan Shenfeld, Mehul Damani, et al. Self-distillation enables continual learning. arXiv preprint arXiv:2601.19897, 2026.