📑 目录
文章目录
- [1 Web服务整体架构与流程](#1 Web服务整体架构与流程)
-
- [1.1 完整请求流程](#1.1 完整请求流程)
- [1.2 核心性能瓶颈](#1.2 核心性能瓶颈)
- [2 IO模型](#2 IO模型)
-
- [2.1 什么是IO](#2.1 什么是IO)
- [2.2 IO的两个阶段(理解所有模型的关键)](#2.2 IO的两个阶段(理解所有模型的关键))
- [2.3 五种网络IO模型详解](#2.3 五种网络IO模型详解)
-
- [2.3.1 阻塞型IO(Blocking IO)](#2.3.1 阻塞型IO(Blocking IO))
- [2.3.2 非阻塞型IO(Non-blocking IO)](#2.3.2 非阻塞型IO(Non-blocking IO))
- [2.3.3 信号驱动式IO(Signal-driven IO)](#2.3.3 信号驱动式IO(Signal-driven IO))
- [2.3.4 异步IO(Asynchronous IO)](#2.3.4 异步IO(Asynchronous IO))
- [==2.3.5 **IO多路复用** (IO Multiplexing)==](#==2.3.5 IO多路复用 (IO Multiplexing)==)
- [2.4 五种IO模型对比总结](#2.4 五种IO模型对比总结)
- [2.5 C10K问题的解决](#2.5 C10K问题的解决)
- [3 零拷贝技术](#3 零拷贝技术)
-
- [3.1 传统IO的问题](#3.1 传统IO的问题)
- [3.2 零拷贝技术演进](#3.2 零拷贝技术演进)
- [3.3 MMAP (内存映射)](#3.3 MMAP (内存映射))
- [3.4 Sendfile](#3.4 Sendfile)
- [==3.5 DMA辅助的Sendfile (Gather Copy)==](#==3.5 DMA辅助的Sendfile (Gather Copy)==)
- [3.6 四种技术对比](#3.6 四种技术对比)
- [3.8 零拷贝的边界](#3.8 零拷贝的边界)
- [4 主流Web服务器](#4 主流Web服务器)
-
- [4.1 Apache--经典的Web服务器](#4.1 Apache--经典的Web服务器)
-
- [4.1.2 Prefork模式--Apache的"远古时代"](#4.1.2 Prefork模式--Apache的"远古时代")
- [4.1.2 Worker模式--进程+线程的折中方案](#4.1.2 Worker模式--进程+线程的折中方案)
- [4.1.3 Event模式--Apache的"现代化改造"](#4.1.3 Event模式--Apache的"现代化改造")
- [4.1.4 三种工作模式对比](#4.1.4 三种工作模式对比)
- [4.2 Nginx--高性能Web服务器](#4.2 Nginx--高性能Web服务器)
1 Web服务整体架构与流程
1.1 完整请求流程
浏览器 → DNS解析 → 建立TCP连接 → 发送HTTP请求 → Web服务器(如Nginx/Apache) → 应用服务器(如uWSGI/PHP-FPM) → 业务处理 → 返回HTTP响应 → 关闭/复用连接
1.2 核心性能瓶颈
| 瓶颈类型 | 具体问题 | 优化方向 |
|---|---|---|
| 网络IO | 海量并发连接处理(C10K问题) | IO多路复用 |
| 磁盘IO | 静态文件高效传输 | 零拷贝技术 |
| 计算资源 | 用户态/内核态切换、数据拷贝开销 | 减少上下文切换 |
2 IO模型
陌生的话去复习一下操作系统知识。
用于解决网络并发问题
2.1 什么是IO
在Linux系统中,一切皆文件,IO操作本质上是对**文件描述符(File Descriptor, fd)**的读写。
| IO类型 | 操作对象 | 典型场景 |
|---|---|---|
| 网络IO | Socket套接字 | HTTP请求响应、数据库连接 |
| 磁盘IO | 文件系统 | 读取静态文件、日志写入 |
2.2 IO的两个阶段(理解所有模型的关键)
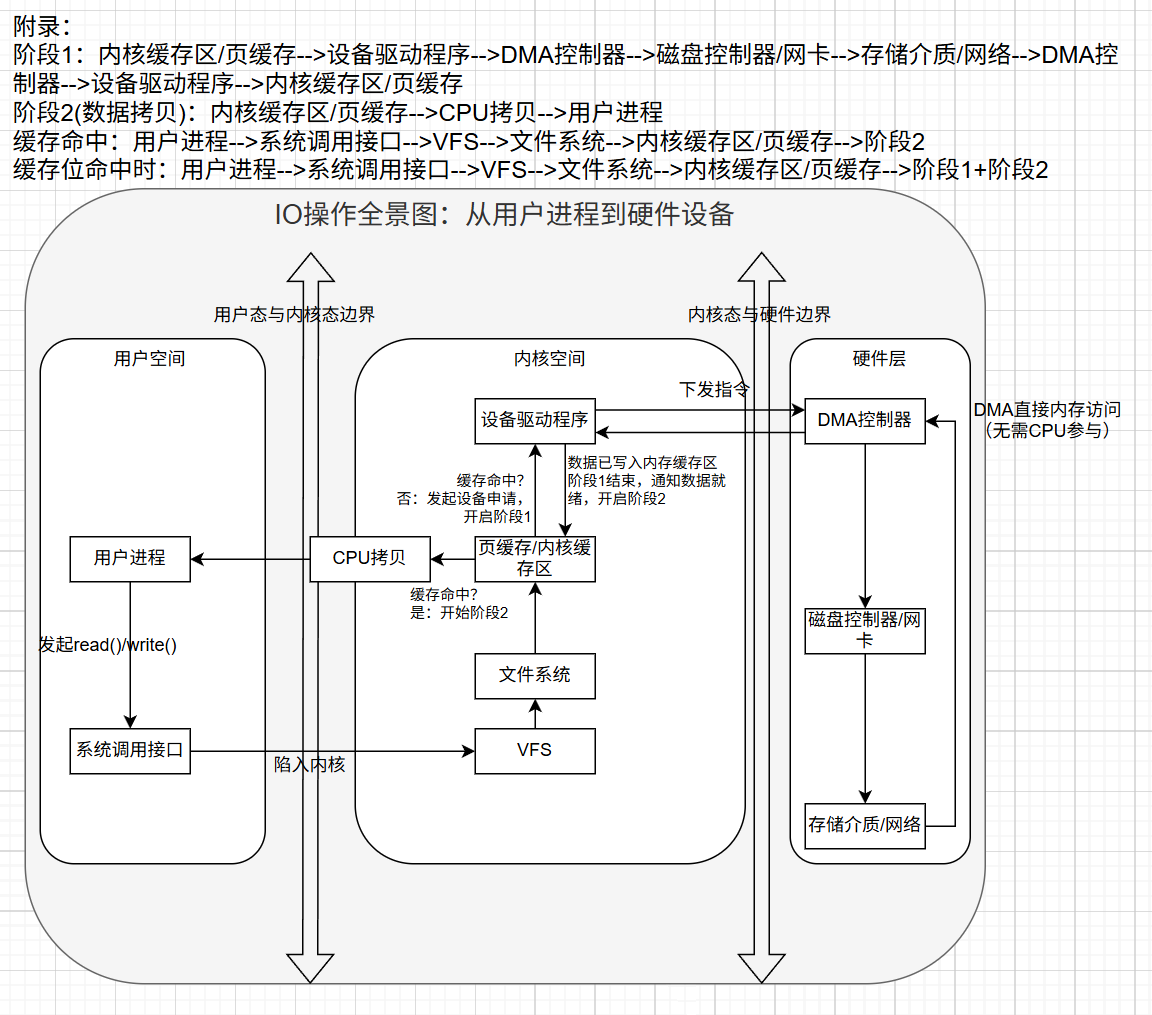
| 阶段 | 操作 | 耗时 | 优化重点 |
|---|---|---|---|
| 阶段①:等待数据准备 | 内核等待数据从磁盘/网卡到达内核缓冲区 | 长(毫秒~秒级) | 主要优化点 |
| 阶段②:数据拷贝 | CPU将数据从内核缓冲区复制到用户进程内存 | 短(微秒级) | 次要优化点 |
重要:阶段①的耗时通常是阶段②的1000倍以上
2.3 五种网络IO模型详解
2.3.1 阻塞型IO(Blocking IO)
特征:两个阶段都阻塞,进程挂起等待
bash
用户进程:[发起read] → [挂起等待...] → [数据就绪] → [拷贝中...] → [返回]
↑ 阻塞! ↑ 阻塞!- 缺点:一个连接一个线程,并发量受限
- 类比:去餐厅吃饭,点完菜一直站在柜台等
2.3.2 非阻塞型IO(Non-blocking IO)
特征:阶段①不阻塞(轮询检查),阶段②阻塞
bash
用户进程:[read]→[EAGAIN]→[read]→[EAGAIN]→[read]→[拷贝...]→[返回]
立即返回 轮询! 立即返回 轮询! 有数据!- 致命缺陷:CPU空转,大量系统调用开销
- 实际应用:很少单独使用,配合IO多路复用
2.3.3 信号驱动式IO(Signal-driven IO)
特征:阶段①不阻塞(信号通知),阶段②阻塞
- 优点:等待阶段不阻塞
- 缺点:Linux信号机制复杂,实际应用少
2.3.4 异步IO(Asynchronous IO)
特征:两个阶段都不阻塞,内核完成所有操作后通知
bash
用户进程:[发起aio_read] → [立即返回,继续执行...] → [收到完成通知] → [直接使用数据]
↑ ↑
内核完成数据准备+拷贝 数据已在用户缓冲区- 优点:最理想模型
- 现状:Windows IOCP成熟,Linux原生AIO不完善(网络IO支持差)
2.3.5 IO多路复用 (IO Multiplexing)
特征:阶段①阻塞在select/poll/epoll(但一个线程监视多个fd),阶段②阻塞
核心思想 :一个线程监视多个连接,哪个就绪处理哪个
三种实现对比
| 特性 | select | poll | epoll |
|---|---|---|---|
| 数据结构 | fd_set (位图) | 链表 | 红黑树 + 就绪链表 |
| 最大fd限制 | 1024 | 无限制 | 无限制 |
| 检查方式 | 遍历所有fd O(n) | 遍历所有fd O(n) | 回调通知 O(1) |
| 就绪通知 | 返回数量,需遍历查找 | 返回数量,需遍历查找 | 直接返回就绪fd列表 |
| 数据拷贝 | 每次调用拷贝fd_set | 每次调用拷贝链表 | mmap共享内存 |
| 时间复杂度 | O(n) | O(n) | O(1) |
| 适用场景 | 旧系统兼容 | 跨平台 | Linux高并发首选 |
epoll高效原理:
- fd状态变更时通过回调自动加入就绪链表,无需遍历
- 只返回就绪的fd,避免无效检查
2.4 五种IO模型对比总结
| 模型 | 阶段①(等待数据) | 阶段②(数据拷贝) | 线程模型 | 适用场景 |
|---|---|---|---|---|
| 阻塞I/O | 阻塞 | 阻塞 | 一个连接一个线程 | 低并发、简单应用 |
| 非阻塞I/O | 轮询检查 | 阻塞 | 需配合多路复用 | 很少单独使用 |
| I/O多路复用 | 阻塞在epoll/select | 阻塞 | 一个线程管理多个连接 | 高并发Web服务器 |
| 信号驱动I/O | 不阻塞,信号通知 | 阻塞 | 信号回调 | 实际应用少 |
| 异步I/O | 不阻塞 | 不阻塞 | 完全异步回调 | 理想但支持不完善 |
2.5 C10K问题的解决
| 方案 | 模型 | 能否解决C10K | 原因 |
|---|---|---|---|
| 阻塞IO + 多线程 | 阻塞IO | 不能 | 1万线程,内存耗尽 |
| 非阻塞IO + 轮询 | 非阻塞IO | 不能 | CPU 100%空转 |
| IO多路复用 | epoll | 能 | 单线程管理,内存<100MB |
Nginx解决C10K的核心:epoll IO多路复用 + 非阻塞socket
3 零拷贝技术
解决文件传输效率问题
3.1 传统IO的问题
发送文件的4次拷贝,4次切换 :
图片源于Linux-零拷贝技术
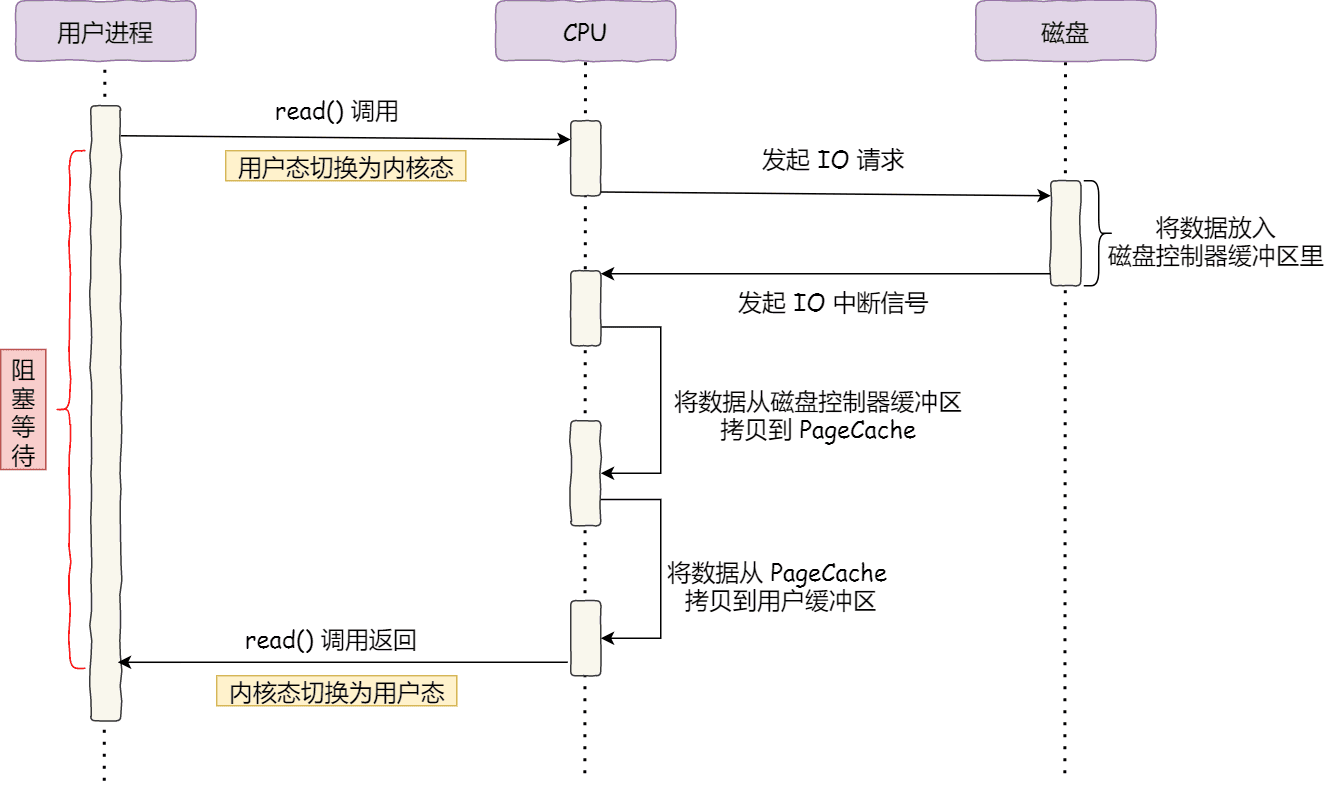
| 操作 | 次数 | 问题 |
|---|---|---|
| 上下文切换 | 4次 | 用户态↔内核态切换开销 |
| CPU拷贝 | 2次 | 主要优化目标 |
| DMA拷贝 | 2次 | 必要,硬件完成,无法避免 |
关键发现:用户进程只是"中转站",并不处理数据,两次CPU拷贝是多余的
3.2 零拷贝技术演进
bash
传统IO (4拷贝4切换)
↓ 减少1次CPU拷贝
MMAP (3拷贝4切换)
↓ 减少2次切换,不经过用户空间
Sendfile (3拷贝2切换)
↓ 真正的零拷贝,CPU完全不参与
DMA Sendfile (2拷贝2切换)3.3 MMAP (内存映射)
原理:用户空间直接映射内核缓冲区,跳过"内核→用户"的CPU拷贝
bash
磁盘 → 内核缓冲区 ←──MMAP映射──→ 用户空间(直接访问)
↑ ↓
└────DMA拷贝────┘ 拷贝到Socket缓冲区 → 网卡- 优化:减少1次CPU拷贝
- 仍有问题:4次上下文切换,write时可能仍有CPU拷贝
3.4 Sendfile
原理:数据完全不经过用户空间,内核直接在内核空间传递
bash
用户进程:sendfile(socket_fd, file_fd, offset, count)
↓
内核:磁盘 ──DMA──→ 内核缓冲区 ──CPU拷贝──→ Socket缓冲区 ──DMA──→ 网卡- 优化:2次上下文切换,1次CPU拷贝
- 局限:无法修改数据(加密、压缩),仍有一次CPU拷贝
3.5 DMA辅助的Sendfile (Gather Copy)
原理 :利用DMA的Gather操作,网卡直接从内核缓冲区取数据,CPU完全不参与
bash
磁盘 ──DMA──→ 内核缓冲区 ──描述符──→ DMA Gather ──→ 网卡
↑ ↑
PageCache 网卡直接读取
0次CPU拷贝!
不占用Socket缓冲区!技术细节:
- 内核构建文件描述符(物理地址+长度+偏移)
- DMA控制器根据描述符列表,从分散的物理页收集数据,直接发送到网卡
- CPU只传递描述符,不触碰数据
3.6 四种技术对比
| 指标 | 传统IO | MMAP | Sendfile | DMA Sendfile |
|---|---|---|---|---|
| 上下文切换 | 4次 | 4次 | 2次 | 2次 |
| 数据拷贝总次数 | 4次 | 3次 | 3次 | 2次 |
| CPU拷贝次数 | 2次 | 1次 | 1次 | 0次 |
| 数据经过用户空间 | 经过 | 经过 | 不经过 | 不经过 |
| CPU参与数据搬运 | 全程 | 部分 | 部分 | 完全不参与 |
| 能否处理数据 | 可以 | 可以 | 不可以 | 不可以 |
| 适用场景 | 小数据处理 | 大文件随机访问 | 静态文件服务器 | 高性能静态文件 |
3.8 零拷贝的边界
| 场景 | 原因 | 解决方案 |
|---|---|---|
| 需要修改数据 | SSL加密、Gzip压缩 | 使用普通IO,或硬件卸载 |
| 文件不在PageCache | 需磁盘IO | 预热文件,或使用直接IO |
| 网卡不支持Gather | 老网卡/虚拟网卡 | 升级网卡,接受普通Sendfile |
| 小文件传输 | 系统调用开销 > 拷贝开销 | 小文件用普通IO,或合并发送 |
4 主流Web服务器
4.1 Apache--经典的Web服务器
🔭Apache从进程模型到事件驱动:
Apache是Web服务器的"老祖宗",1995年诞生,经历了从进程模型到事件驱动的演进。理解Apache的三代MPM(Multi-Processing Module,多处理模块),就是理解Web服务器架构的演进史。
- Apache Event模式是"向Nginx学习"的产物,但受限于历史架构,无法完全达到Nginx的简洁高效
- Nginx的成功证明:对于IO密集型服务,事件驱动 + 非阻塞IO + 零拷贝是终极答案
- 现代高性能服务器(Redis、Node.js、Netty、Envoy)都遵循这一模式
4.1.2 Prefork模式--Apache的"远古时代"
核心机制:预派生子进程,每个请求独占一个进程
bash
# Prefork 进程模型
# 每个进程:fork() → 处理一个请求 → 等待下一个或退出
主进程 (Master)
│
├─► 预派生子进程1 ──► 接收请求A ──► 处理 ──► 释放连接
│
├─► 预派生子进程2 ──► 接收请求B ──► 处理 ──► 释放连接
│
├─► 预派生子进程3 ──► 接收请求C ──► 处理 ──► 释放连接
│
└─► ...最多256个(默认)
# 关键问题:
1. 进程创建/销毁开销大(fork()成本)
2. 内存占用高(每个进程独立地址空间,5-10MB+)
3. 进程数上限 = 并发上限(默认MaxRequestWorkers 256)
4. KeepAlive长连接会占用进程,降低并发能力性能数据:
- 每个进程内存占用:5-15MB(取决于加载模块)
- 最大并发:250(默认)~ 1024(极限)
- 进程切换开销:上下文切换 + TLB刷新
适用场景:
- 需要稳定兼容旧模块(如某些PHP扩展)
- 低访问量、求稳定的内部系统
- 需要进程隔离(一个请求崩溃不影响其他)
4.1.2 Worker模式--进程+线程的折中方案
核心机制:多进程 + 多线程混合,进程稳定、线程轻量
bash
# Worker 进程-线程模型
主进程 (Master)
│
├─► 子进程1───┬─► 线程1 ──► 处理请求A
│ ├─► 线程2 ──► 处理请求B
│ ├─► 线程3 ──► 处理请求C
│ └─► ..................(每个进程25个线程)
│
├─► 子进程2 ──┬─► 线程1 ──► 处理请求D
│ └─► ...
│
└─► ...多个子进程(默认3个,可调)
# 改进点:
1. 线程创建开销 < 进程创建(线程共享地址空间)
2. 内存占用降低(线程栈通常1MB vs 进程5MB+)
3. 并发能力提升(进程数 × 线程数)
#新问题:
1. KeepAlive长连接仍会阻塞线程,一个线程被KeepAlive占用,就无法处理其他请求
2. 线程安全问题(模块需要线程安全)
3. 进程崩溃会导致该进程内所有线程的请求丢失Worker模式的KeepAlive陷阱:
bash
# 场景:100个线程,100个长连接(KeepAlive)
线程1 ──► 连接A(空闲KeepAlive)
线程2 ──► 连接B(空闲KeepAlive)
..................
线程100 ──► 连接Z(空闲KeepAlive)
# 结果:所有线程被占用,新请求无法处理,虽然连接空闲,但线程被绑定,并发能力归零。
# 临时解决方案:
KeepAliveTimeout 5 # 缩短超时时间
MaxKeepAliveRequests 100 # 限制请求数
但这违背了HTTP长连接的设计初衷4.1.3 Event模式--Apache的"现代化改造"
Apache Event模式是"向Nginx学习"的产物,但受限于历史架构,无法完全达到Nginx的简洁高效
核心机制:事件驱动(epoll) + 专门线程管理KeepAlive
bash
# Event 事件驱动模型
主进程 (Master)
│
├─► 子进程1───┬─► 监听线程(epoll)
│ │ ├─► 连接A:新请求 ──► 交给工作线程
│ │ ├─► 连接B:KeepAlive ──► 挂起
│ │ ├─► 连接C:新请求 ──► 交给工作线程
│ │ └─► 连接D:数据到达 ──► 唤醒处理
│ ├─► 工作线程池(处理实际请求)
│ │ ├─► 线程1:处理请求A
│ │ ├─► 线程2:处理请求C
│ │ └─► ..................
│ └─► KeepAlive管理(轻量级线程)
├─► 挂起空闲连接,不占用工作线程
└─► 新请求到达时,唤醒并分配给工作线程
# 革命性改进:
1. 使用epoll管理连接(一个线程监视成千上万个)
2. 工作线程只处理"活跃请求",不被KeepAlive阻塞
3. KeepAlive连接由专门线程管理,资源占用极低
本质:从"一个连接一个线程" → "一个线程管理多个连接"
这正是Nginx的核心思想传统Worker模式:
连接 → 占用线程 → K e e p A l i v e 空闲 → 线程被占用 → 并发下降 \begin{aligned} 连接\rightarrow 占用线程 \rightarrow KeepAlive空闲\rightarrow 线程被占用\rightarrow 并发下降 \end{aligned} 连接→占用线程→KeepAlive空闲→线程被占用→并发下降
Event模式:
连接 → e p o l l 监视 → K e e p A l i v e 空闲 → 挂起 ( 不占用线程 ) → 并发保持 ↓ 新请求到达 → e p o l l 通知 → 分配工作线程 → 处理完成 → 释放线程 \begin{aligned} 连接\rightarrow &epoll监视\rightarrow KeepAlive空闲\rightarrow 挂起(不占用线程)\rightarrow 并发保持\\ & \downarrow\\ &新请求到达\rightarrow epoll 通知\rightarrow 分配工作线程\rightarrow 处理完成\rightarrow 释放线程 \end{aligned} 连接→epoll监视→KeepAlive空闲→挂起(不占用线程)→并发保持↓新请求到达→epoll通知→分配工作线程→处理完成→释放线程
Event模式详解:
- 主线程使用epoll管理所有连接
- 专门线程处理KeepAlive长连接,避免阻塞工作线程
- 解决了Worker模式下KeepAlive阻塞线程的问题
4.1.4 三种工作模式对比
| 维度 | Prefork | Worker | Event |
|---|---|---|---|
| 进程模型 | 一个请求一个进程 | 多进程+多线程 | 多进程+epoll+线程池 |
| IO模型 | 阻塞IO | 阻塞IO | IO多路复用(epoll) |
| KeepAlive处理 | 进程被占用 | 线程被占用 | 专门线程管理,不阻塞 |
| 内存占用 | 极高(每进程5-15MB) | 中等(每线程1MB) | 低(单线程管理万级连接) |
| 并发能力 | 低(~250) | 中等(~1000) | 高(~10000+) |
| 稳定性 | 最高(进程隔离) | 中(线程崩溃影响进程) | 中 |
| 兼容性 | 最好(所有模块) | 一般(需线程安全) | 一般 |
| 适用场景 | 低并发、求稳定 | 中等并发 | 高并发(推荐) |
| 与Nginx对比 | 慢10倍+ | 慢5倍+ | 差距缩小,但仍慢2-3倍 |
演进逻辑:Prefork → Worker → Event,逐渐从进程模型转向事件驱动。