SR-IOV、MR-IOV 和 SIOV 是 PCIe 体系中围绕 I/O 虚拟化演进出的三类重要技术。它们的出发点,都是想通过硬件直通的方式,让虚拟机和容器绕开软件模拟层,直接操作硬件,从而在资源共享的同时,还能取得高性能。
但这三个技术的命运却不一样,SR-IOV已经成为数据中心基础设施的中流砥柱,MR-IOV已经被扫到角落积灰,SIOV则是未来的新星技术。
今天,就让霞姐带大家一起简单分析一下这三个技术吧!
一、SR-IOV(Single-Root I/O Virtualization)
1. 技术简介
SR-IOV是2007年纳入到PCIe规范里面的一项技术。
在之前的传统虚拟化方案里,虚拟机的设备需要由虚拟化层软件模拟,I/O数据路径通常需要经过额外的软件转发与内存拷贝,中断也需要由虚拟层捕获并模拟转发。这样就导致了硬件的性能被软件瓶颈锁住不能得到发挥。
SR-IOV的核心思想是:将原本需要虚拟化层软件转发的数据平面,直接下沉到硬件完成。
通过SR-IOV技术,网卡、NVMe SSD、GPU等PCIe外设,可以对外呈现出一个PF(物理功能)和多个VF(虚拟功能)。VF之间具有独立的发送/接收队列、中断向量以及DMA上下文。部分设备还支持基于VF的带宽限制与QoS控制,从而降低不同虚拟机之间的资源干扰。
PF驱动运行于虚拟化层(宿主机),负责VF的管理,比如创建VF、将VF分配给虚拟机。
而在数据平面的实际的业务过程中,只需要虚拟机和对应VF直接配合完成即可,不需要虚拟化层参与。
与virtio等半虚拟化方案相比,SR-IOV绕过了传统虚拟化层软件的数据转发路径,显著减少了VM-Exit、软件转发和中断模拟开销,因此能够获得接近裸机的I/O性能。这样一来,业务性能得到显著提升。
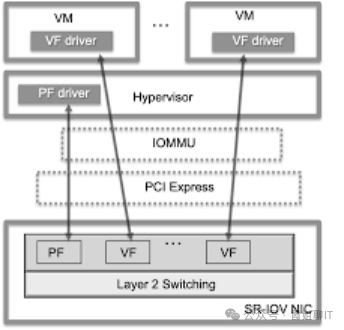
2. 软硬件各组件职责划分
(1) 设备硬件层(PCIe设备)
设备厂家需要按照PCIe规范要求,实现具备SR-IOV能力的设备。
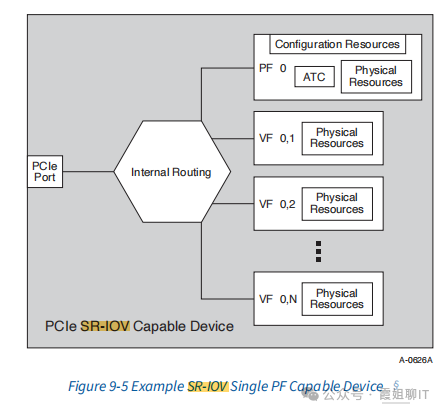
① PF (Physical Function):
A.拥有完整的、独立的PCIe配置空间,驱动可通过它查询和配置 VF 的数量、偏移等。
B.提供VF的资源配置信息(如每个VF的BAR 大小、MSI-X 条目数)。
C.执行VF间的硬件级隔离:独立的发送/接收队列、DMA 通道、中断向量、带宽限制等。
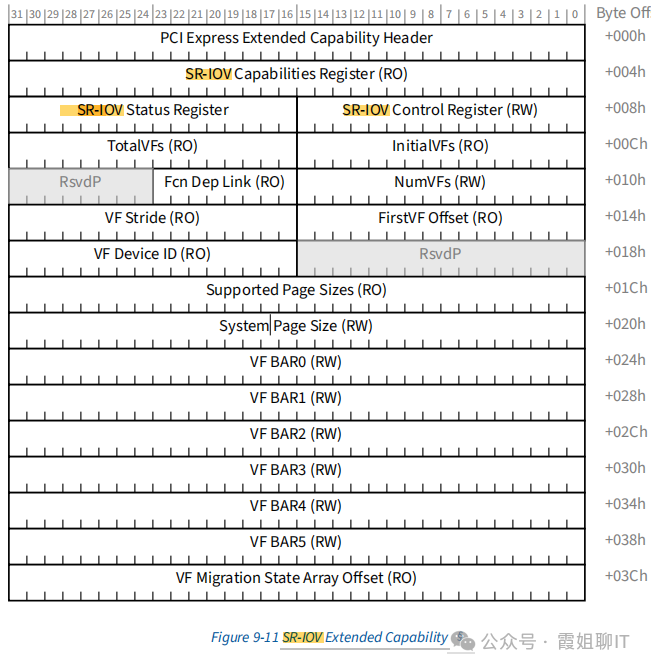
② VF (Virtual Function):
A.是一种轻量化的PCIe功能,与同一PF下的其他VF共享物理设备资源。
B.每个VF拥有逻辑上独立的配置空间,会被分配唯一的BDF,支持软件枚举,但其大部分配置能力受PF控制或继承PF。
C.每个VF在PCIe枚举中表现为独立功能,并具有自身的BAR寄存器映射,用于访问其MMIO控制区域和队列资源。
D.每个VF拥有独立的MSI-X表。
E.每个VF发起DMA请求时都会携带自身的Requester ID(BDF)。IOMMU根据该标识查表完成地址转换与访问隔离。
(2) PF驱动
①初始化阶段:
A.探测PF设备,读取它的SR-IOV Capability结构。
B.调用内核PCI 子系统接口,如pci_enable_sriov创建指定数量的 VF。
②运行时管理:
A.动态调整VF 数量。
B.通过PF 的专用管理队列或mailbox机制,配置VF的资源,比如网卡的话可配置MAC地址、VLAN、带宽限制、QoS 等
C.处理VF的FLR(Function Level Reset)请求。
D.提供VF的passthrough接口(如创建 VFIO 设备节点)。
PF驱动不参与 VM 的实际数据收发(DMA、中断等完全由VM 中的VF驱动直接与硬件交互)。
(3) Hypervisor
A. 创建VF:通过PF驱动在宿主机上创建VF
(例如echo 8 > /sys/class/net/eth0/device/sriov_numvfs)。
B. 将VF分配给VM:通过VFIO框架将VF设备从宿主机PCI驱动解绑,绑定到 vfio-pci 驱动。
C. 配置IOMMU 映射:为VM 的GPA空间建立 IOMMU 页表,这样VF发起的DMA请求即可直接访问VM内存。
同时设置中断重映射条目,将VF的 MSI-X中断定向到VM的vCPU。
D. 模拟虚拟PCIe 热插拔:QEMU 通过 VFIO 提供的接口,向 VM 的 ACPI/PCI 总线通告一个虚拟的PCIe 设备(背后对应真实的 VF)。VM 内核枚举该设备后加载VF驱动。对于大多数情况,热插拔不是必须步骤。
E. 处理VM 迁移前的状态保存。不过,除非有硬件辅助或特殊协议,否则迁移非常困难。
(4) VF驱动
①初始化阶段:
申请VF的BAR内存区域(MMIO),并映射到VM内核地址空间。
初始化VF的队列、DMA缓冲区,设置MSI-X中断向量。
②运行时I/O:
发送路径:驱动将数据放入DMA缓冲区(VM物理内存),更新队列指针,写doorbell寄存器。该操作通常可直接到达硬件,而无需经过传统virtio路径中的VM-Exit与Hypervisor转发。
接收路径:硬件将数据DMA写入VM内存(通过IOMMU转换GPA→HPA),然后发送MSI-X中断。中断经IOMMU中断重映射后注入VM的vCPU,随后由VF驱动响应处理。
(5) 虚拟机内核
VM 内核无需知道自己是虚拟机,也无需任何特殊 SR-IOV 支持。
只要它有一个标准的设备驱动(该驱动支持VF 类型的硬件),就可以正常工作。
3. 产业现状
综合前文的技术分析可以看出,SR-IOV的改动工作主要集中在硬件厂商一侧。但由于它能显著提升I/O性能,支持该技术,能成为硬件厂商进入高端企业市场的入场券,相关产品也能因此获得较高的溢价,从而带来多方面的商业回报。
对于操作系统和虚拟化厂商而言,得益于SR-IOV规范的标准化程度较高,虽然仍需进行相应的适配工作,但整体投入产出比非常可观。支持SR-IOV后,厂商可将其作为高阶特性,通过许可证管理等模式获得丰厚收益。
对于最终用户来说,只需执行几条简单的配置命令,即可让虚拟机获得接近原生硬件的网络性能。
正是这种多方共赢的局面,使得SR-IOV获得了产业界的广泛支持。目前,几乎所有主流网卡厂商、部分GPU厂商、NVMe SSD厂商,以及主流的操作系统和虚拟化平台都已支持该技术。
目前,SR-IOV已广泛部署于云计算、高性能网络和NFV等场景,并成为主流企业级虚拟化平台的重要高性能I/O方案。
二、MR-IOV(Multi-Root I/O Virtualization)
1. 技术简介
MR-IOV 1.0规范于2008年由PCI-SIG发布。
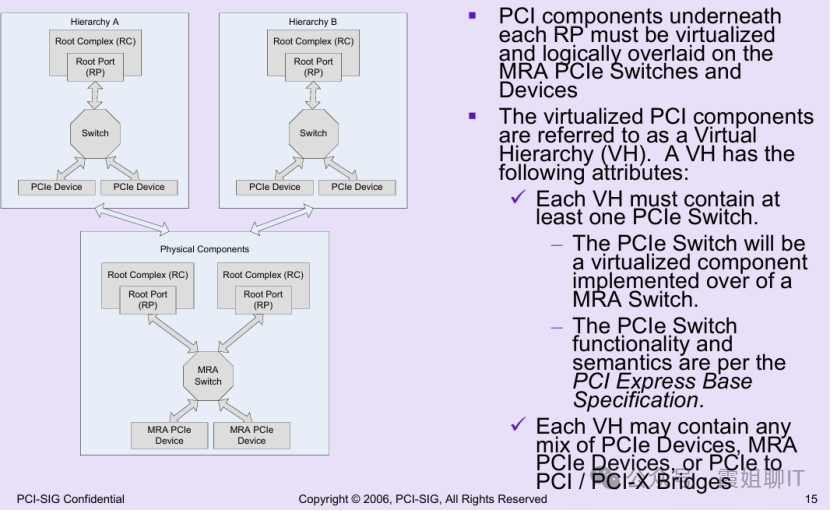
如下图所示,MR-IOV想将IO虚拟化能力从单服务器扩展到多服务器,
比如:现有数据中心中,昂贵、但利用率不高的NVMe SSD盘或者GPU卡可以被多台服务器共享,从而提升资源的利用率、简化管理并降低成本。
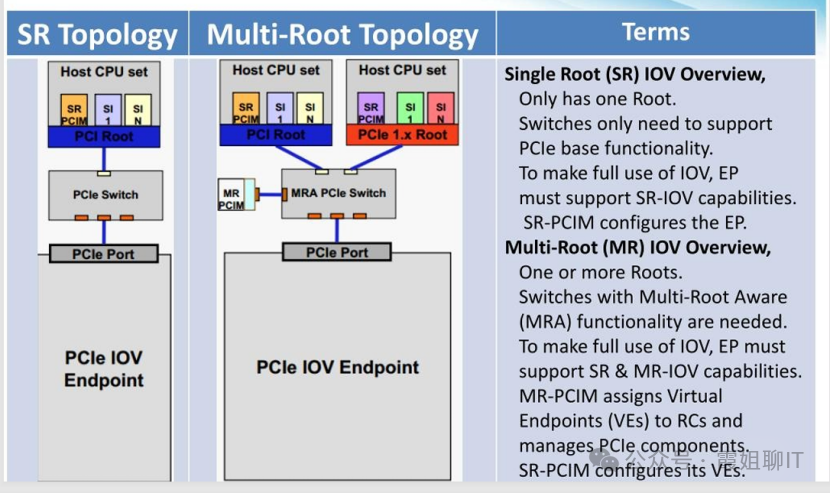
那它是如何做到的呢?
它想通过增加一个MRA(Multi-Root Aware)交换机来实现跨服务器的硬件直通。
MRA交换机可构建可被多个Root Complex共享的PCIe交换Fabric,并为每个接入的服务器创建独立的虚拟层级(即VH Virtual Hierarchy)。
从每个服务器(即RC)的角度看,它认为自己拥有一个完整的、独立的PCIe层级结构,包括Switch和Device。
底层的MRA交换机负责识别不同RC的事务,在内部维护多个独立的虚拟层级上下文,保证彼此隔离。
这样就实现了多台主机对同一套PCIe设备的透明、隔离共享,解决了SR-IOV无法跨主机共享设备的痛点。
2. 为何没有流行?
从上文的描述中看,容易让人误以为,只需将传统PCIe交换机替换为MRA交换机即可实现MR-IOV。但打开来看,它带来的改动是巨大且全方位的:
(1) MRA Root Port
需要为每个VH维护独立的状态和资源映射表,支持 MR 事务封装协议,能在数据链路层插入/移除 VP 标签,还增加了拥塞管理功能,并且不转发属于其他 VH 的 TLP。
(2) MRA Switch
需要具备多上游端口,可同时连接多个Root Complex;
内部为每个VH 维护一组逻辑 PCIe 到 PCIe 桥,形成独立的虚拟交换机;
支持VP 标签处理与 RESET DLLP,并为每个物理链路配备一个物理热插拔控制器和每个 VH 一个虚拟热插拔控制器。
(3) MRA Endpoint
除了支持SR-IOV 的 PF/VF 外,还必须实现一个 Base Function(BF),专门用于 MR-PCIM 的管理;每个 VH 看到的虚拟端点(VE)拥有独立的 Type 0 配置空间、BAR、MSI/MSI-X 和复位控制,硬件需要为不同 VH 复制大量配置状态。
(4) 管理实体
引入了全局的MR-PCIM,负责发现所有设备、划分 VH、分配 VE、配置 MRA Switch 和 BF;
每个VH 内部仍然有各自的 SR-PCIM 负责常规的 PF/VF 枚举与配置,形成两级管理栈。
(5) 链路协议
在数据链路层增加了VP 标签(插入在序列号和 TLP 头之间),用于标识 TLP 所属的 VH,且标签被 LCRC 保护但不影响 ECRC;
新增RESET DLLP,可同时对最多 16 个 VP 发出复位请求并完成握手,保证复位可靠传播。
(6) 资源复制
与SR-IOV 仅为 VF 复制少量资源不同,MR-IOV 需要为每个 VH 独立复制完整的 PCIe 配置空间、地址映射、中断表、热插拔状态和错误处理上下文,硬件开销显著增大。
更重要的是,PCIe协议本身最初是围绕"单Root、本地互连、强控制域"设计的,而MR-IOV试图将其扩展为跨主机共享Fabric,这使得枚举、复位、错误恢复、热插拔以及资源所有权管理的复杂度急剧上升。
3. 产业化现状
****可以想见,设备厂商对支持MR-IOV 技术的动力是普遍不足的。****因为多台服务器共享同一张I/O 卡,会直接减少企业对硬件数量的需求,从而导致厂商的产品总销量显著下降。
PLX(后被博通收购)虽然在交换机芯片上率先实现了MR-IOV 标准,但由于上下游:包括服务器Root Port 和终端设备,普遍缺乏配套的 MRA 支持,最终未能形成产业化。
其核心技术被保留并演进为厂商私有的Multi-Host / Fabric多主机共享方案,在高端存储系统、高可用集群和嵌入式多 SoC 互联等场景中获得了实际应用。
因此,尽管标准MR-IOV 未能产业化,当前的多主机 PCIe 共享技术仍具有明确的市场需求。主流技术路线可归纳为以下三种:
(1) 通过PCIe Fabric:
以Broadcom 和 Microchip的PCIe交换机为核心,构建多主机与多Endpoint之间的池化连接,Endpoint只需支持 SR-IOV 即可。这是对 MR-IOV 理念最直接的继承。
(2) 通过高级网卡集成Multi-Host:
以Mellanox ConnectX 系列为代表,单张网卡可划分为多个独立 PCIe 接口,直接连接多台主机 CPU。该方案成本较低,但支持的 host 数量有限。
(3) 通过网络交换:
利用以太网或InfiniBand 网络实现 I/O 池化,适用于跨机架、大范围的资源池化场景,但延迟和开销均高于 PCIe 直连方式。
从产业演进角度看,MR-IOV虽然未能成功标准化落地,但其"多主机共享高速互连资源"的核心理念,正在通过PCIe Fabric、CXL Fabric以及Composable Infrastructure等新架构重新实现。
三、SIOV(Scalable I/O Virtualization)
1. 技术简介
SIOV是Intel 2017年内部提出的规范,它的提出是为了突破SR-IOV的局限性:
(1)PCIe SR-IOV机制能够支持的VF数量存在较强的实现限制,实际产品中通常仅提供几十到数百个VF。这无法满足数据中心中单服务器数百上千的容器/虚拟机需求。
这是因为SR-IOV需要PCIe设备为每个VF提供完整的PCIe功能(如配置空间、中断表等),每增加一个VF,芯片面积、功耗、验证复杂度都线性增长。
(2)VF资源切片较粗,无法根据租户需求灵活调整,导致资源利用率偏低。
SIOV技术2018年形成Intel内部规范,2022年被贡献给了OCP组织,2025年被PCI-SIG组织纳入PCIe规范。
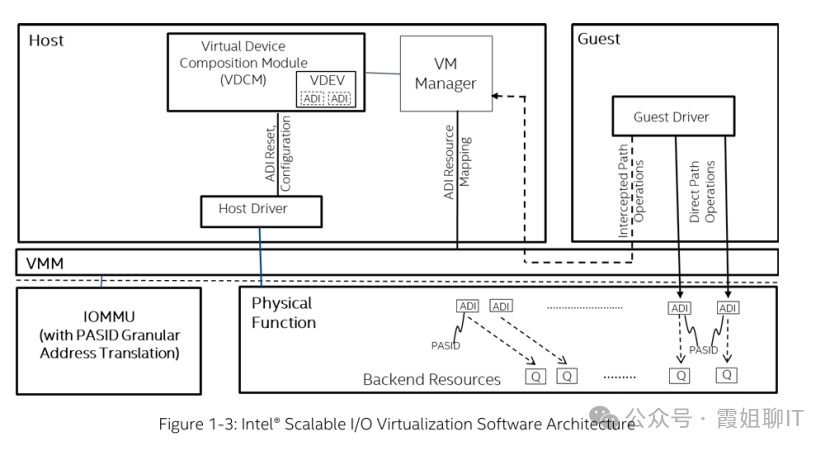
SIOV改变了SR-IOV中由硬件直接构造虚拟PCIe功能的思路,将虚拟设备的组合、生命周期管理和资源编排从硬件中抽离出来,交由软件定义的VDCM(Virtual Device Composition Module)负责。
(1)硬件不再预制虚拟设备,只保留一个极简的"资源池"和一张 PASID 映射表。在SIOV中,虚拟化粒度不再是PCIe Function,而是基于PASID标识的独立I/O上下文。
(2)软件(VDCM)负责管理虚拟设备:创建、销毁、配置资源配额、分配 PASID。
SIOV本质是Shared Work Queue思想。
这样带来的好处是很明显的:
(1) 扩展性的提升:
硬件只需要维护映射表项,每个表项只占用几十字节,不再需要为每个虚拟设备复制庞大的配置空间,因此单个设备支持的虚拟接口(SDI)数量可以达到数千甚至上万,这种轻量级、可动态编排的虚拟I/O接口尤其适合云原生场景中的容器级资源分配。
(2) 灵活性提升:
VDCM由软件定义后,可以在几毫秒内为一个容器创建一个 SDI,容器停止时立即销毁并回收资源,不需要PCIe热插拔或复位整个设备。
SDI 的大部分状态(如 PASID 映射、资源配置)由 VDCM 在软件中维护,迁移时只需保存/恢复这些软件上下文,不再需要硬件支持复杂的状态捕获。
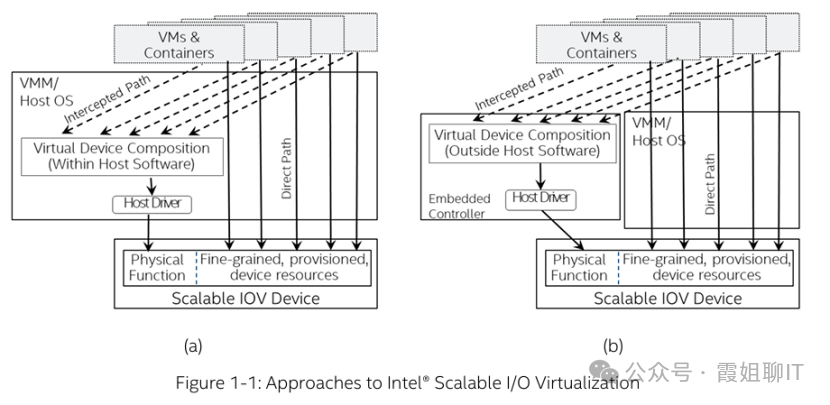
进一步的,如下图b所示,可以将 VDCM 放到独立的嵌入式控制器(如 BMC、管理 SoC)中,还能获得更多的好处:
(1) 卸载宿主机CPU:控制面的操作不再消耗宿主机计算资源。
(2) 故障隔离:即使宿主机内核崩溃,管理面仍可正常工作。
(3) 安全增强:VDCM 与租户环境物理隔离,防止恶意租户篡改配置。
2. 软硬件要求
SIOV的实现需要硬件、管理软件、操作系统内核和虚拟机VM四方配合。
(1) 硬件层面 需要按PCIe规范实现硬件并提供驱动:
A. 可分配设备接口(ADI):
设备上的一组可被分配的后端资源(如DSA引擎上下文、NVMe队列对等)。
从架构角度看,ADI本质上更接近"可分配的硬件工作队列上下文",而不再是传统PCIe意义上的独立Function。
B. 快速路径(Direct Path):
在初始化完成后,VM中运行的Guest Driver通过快速路径向ADI提交I/O请求。
这些数据流可直接访问硬件,不再经过Hypervisor或VDCM的软件模拟,从而实现了接近物理设备的I/O性能。
C. 辅助技术:
SIOV的实现还需硬件支持PCIe PASID(进程地址空间ID),以便区分来自不同ADI的DMA请求。配合IOMMU技术,可以保证不同虚拟设备内存访问的隔离性与安全性。
D. PF驱动
宿主机管理员通过PF驱动与硬件交互,为VDCM提供能力。
(2) 软件/固件层面:负责灵活定义
A. 虚拟设备组合模块(VDCM):负责实现和管理虚拟设备。
它通过调用PF驱动分配底层ADI,并将这些ADI组合成虚拟设备 (VDEV) 呈现给虚拟机。
在虚拟机运行时,它还负责处理控制路径上的拦截操作,例如模拟部分配置类MMIO访问。
VDCM可集成在VMM/Hypervisor内部,也可放置在专用的独立安全处理器/控制器中。
B. 宿主机内核:
需要新增SIOV扩展能力检测等功能。
同时,内核中的IOMMU驱动和VFIO子系统的功能也需扩展以支持SIOV,例如:
通过iommufd_device_bind_pasid()等新API来支持基于PASID的虚拟设备。
C. 客户机驱动(Guest Driver):
对于上层应用而言通常无需感知SIOV,但Guest Driver仍需支持对应的SIOV设备模型。
该驱动在使用上几乎与传统的SR-IOV VF驱动无异,同样是通过"直接路径"访问硬件。
仅在某些特定操作(如设备初始化)被VDCM捕获和处理时,才会通过"拦截路径"访问。
(3) 软硬件协同:一个完整的工作流程
当硬件和软件都准备就绪后,SIOV的工作流程大致如下:
A. 启动与发现:宿主机启动时,PF驱动检测并启用SIOV功能。
B. 注册与初始化:PF驱动将SIOV能力注册到内核,并创建一个或多个ADI实例。
C. VDCM准备就绪:VDCM模块启动,准备接管虚拟设备的管理工作。
D. 创建虚拟设备:当需要为一个新的VM创建虚拟设备时,Hypervisor请求VDCM创建VDEV。VDCM根据请求,从PF驱动分配的ADI中选择一个或多个,组合成一个VDEV实例。
E. 分配与映射:VDCM为该VDEV生成一个虚拟的PCI配置空间,并通过IOMMU等机制,将VDEV的物理资源映射给VM,实现资源隔离。
F. VM启动与初始化:VM启动后,其Guest Driver会发现这个新的PCI设备,并执行初始化操作。
此时对设备配置空间的读写被视为"慢路径"(Intercepted Path),会触发VM Exit,并由VDCM进行模拟处理。
G. ****运行阶段:****初始化完成后,Guest Driver通过VDEV发送I/O请求。这些请求将直接通过快速路径到达硬件ADI,无需Hypervisor介入,从而提供高性能数据通路。
H. ****关闭与清理:****当VM关闭时,VDCM会清理VDEV所使用的ADI等所有资源,并将其释放回资源池,供后续使用。
3. 产业化现状
处理器层面,Intel的至强处理器Sapphire Rapids已支持SIOV特性;
设备层面,Intel的以太网800系列网络控制器及Microchip公司的PCIe交换机和SSD控制器等也加入了支持的阵营。
Linux社区正在推进相关API与补丁,例如,引入了
iommufd_device_bind_pasid()等新API来支持基于PASID的虚拟设备,并能探测PCI设备的SIOV能力。
KVM等主流虚拟化平台也已开始进行适配。例如,Intel VMX引入了对PASID虚拟化的支持,建立Guest PASID到Host PASID的映射。
但是,当前公开的部署案例有限,这也说明SIOV距离全面普及仍需时间。总体来看,SIOV正在将I/O虚拟化从"固定PCIe功能切分"逐步推向"基于上下文与队列的软件定义资源编排",这一方向与云原生基础设施、AI集群以及CXL时代的资源池化趋势高度一致。
所以虽然目前SIOV技术仍处于早期,但其未来在超大规模云数据中心、AI集群及各类高性能计算场景中的应用前景十分值得期待。
四、总结
经过这些年的发展,PCIe I/O虚拟化技术已经从最初的SR-IOV,逐步演进到MR-IOV、SIOV以及更广义的PCIe/CXL Fabric资源池化架构。
其中,SR-IOV凭借简单、标准化、性能高等优势,已经成为当前数据中心I/O虚拟化的主流方案;
MR-IOV虽然因体系复杂度和产业协同成本过高而未能成功普及,但它"多主机共享高速互连资源"的理念,却深刻影响了后续PCIe Fabric与Composable Infrastructure的发展方向;
而SIOV则进一步将I/O虚拟化从"固定PCIe Function切分"推进到"基于上下文与队列的软件定义资源编排",开始更加契合云原生、AI集群以及CXL时代的大规模资源池化需求。
这三代技术的演进,本质上反映了整个数据中心基础设施的发展趋势:
从设备独占到资源共享;
从固定硬件功能到软件定义基础设施;
从单机性能优化到数据中心级资源池化。
而PCIe虚拟化,也仍然在继续演进。