索引数据在内存里的命中率通常比表数据高是为什么?
索引比数据更小、更紧凑、访问频率更高,所以它在内存里的"存活率"天然比表数据高。
下面从几个维度拆解原因:
索引比表数据"小",同样内存能装更多
- 表数据 :一行记录包含所有字段(可能有很多列,包括大字段如
TEXT、BLOB),一页(16KB)能存放的行数有限。 - 索引:只存索引列的值 + 主键值(如果是二级索引),每条记录很小,一页能存放的索引条目数远多于表数据行数。
结果:同样大小的 Buffer Pool,能缓存的索引页数量远多于数据页数量,索引页被淘汰的概率更低。
查询总是先经过索引(索引的"入口"地位)
几乎所有的查询(除了全表扫描)都是先走索引:
- 先在索引树里定位到主键值。
- 再通过主键去聚簇索引拿数据。
因此:
- 索引页 被访问的次数更多(每条查询都可能访问)。
- 数据页 只有在回表时才被访问。
结果:索引页的访问频率天然高于数据页,LRU 算法会把高频页留在内存里。
索引访问更集中(热点更集中)
- 索引:往往是树状结构,根节点和上层中间节点被几乎所有查询访问(因为任何查询都要从根往下走)。这些节点一旦进入内存,几乎永远不会被淘汰,成为"永久热数据"。
- 数据:分散在各处,即使同一张表,不同行的访问频率差异很大(有的行很少被查)。
结果:索引的热点集中在少数页上,更容易长期驻留内存;数据的热点分散,很多页虽然被访问但频率不够高,容易被淘汰。
索引的访问模式更"规律"
- 索引扫描:往往是有序的(比如范围查询),访问的页相对连续,预读机制(read-ahead)能提前把相邻索引页加载进来,进一步提高命中率。
- 数据回表:是随机的(根据主键值去散落的数据页里找),很难预读,数据页的加载更被动。
结果:索引页更容易被批量加载并留在内存里。
举例对比
假设一张 user 表有 1000 万行,每行 200 字节,主键是 id,有一个二级索引 idx_name。
- 数据页:每页 16KB,约能存 80 行,共约 12.5 万页。
- 索引页 (二级索引):每条
(name, id)约 30 字节,每页能存约 500 条,共约 2 万页。
如果 Buffer Pool 能存 10 万页:
- 可以完全缓存所有索引页(2万页)还有大量剩余空间。
- 但只能缓存约 80% 的数据页(10万 vs 12.5万)。
实际运行时,索引页全部在内存,数据页部分在内存,命中率自然不一样。
总结
| 原因 | 说明 |
|---|---|
| 体积小 | 索引页更紧凑,同样内存能装更多页。 |
| 访问频率高 | 每条查询都走索引,索引页被反复访问。 |
| 热点集中 | 索引树的根/中层节点是全局热点,永不淘汰。 |
| 访问模式连续 | 索引扫描连续,预读命中率高。 |
所以,你在调优数据库时,如果发现 Buffer Pool 不够大,优先保证索引能被完全缓存,这是提升查询性能的关键。
这个 SQL 在做什么?
sql
EXPLAIN SELECT last_name, first_name, hire_date
FROM employees
WHERE last_name = '鸭';SELECT last_name, first_name, hire_date:要查询的列是last_name、first_name、hire_date。FROM employees:从employees表里查。WHERE last_name = '鸭':条件是last_name这个字段的值等于字符串'鸭'(这里用鸭举例,实际是某个具体的姓氏)。
加上 EXPLAIN 后,MySQL 不会返回真正的员工数据,而是返回一张表,描述它执行计划的每一步 。其中有一列叫 Extra,如果这一列显示 Using index ,就意味着这个查询使用了覆盖索引,显示Using index condition就意味着使用了索引下推,需要回表但次数减少了。
要理解索引下推,必须先看 MySQL 的"大楼"是怎么分工的。
Server 层(大脑/指挥官)
这是 MySQL 的上层部分,包含了连接器、查询缓存、分析器、优化器、执行器等。
- 职责: 它负责逻辑层面的事。比如:这条 SQL 语法对不对?怎么查最快(生成执行计划)?最后拿到的数据是不是还要过滤一下?
- 它不直接碰数据: 它只负责下达指令,不负责去磁盘上翻找文件。
存储引擎层(手脚/仓库管理员)
这是 MySQL 的下层部分,最常用的是 InnoDB。
- 职责: 它负责数据的存储和提取。
- 它听指令办事: Server 层说"给我找索引是 A 的数据",它就去翻磁盘,把数据找出来交给 Server 层。
什么是"回表"?(背景知识)
在理解下推前,要懂回表。
假设你有一个联合索引 (name, age),但你查询的是 select *。
- 引擎先去索引树里找到 name 匹配的记录。
- 但索引树里通常不包含所有字段(比如没有地址、电话),于是引擎要根据主键 ID,回主表再查一次,拿到完整记录。这就是回表 。回表是很耗时的(涉及磁盘 I/O)。
什么是索引下推(ICP)?
索引下推 的核心就是:能让存储引擎在找数据的时候多做点事,尽量减少回表的次数。
1. 没有索引下推时(MySQL 5.6 之前)
- Server 层指令: "给我找所有姓'张'的人。"
- 存储引擎: "好,我找到 100 个姓张的人,把他们的主键 ID 全给你。"
- Server 层: "拿到 100 个 ID 了。我现在挨个去回表,把这 100 人的完整数据取回来。取完后,我再自己判断:这 100 人里谁是'男'的?哦,只有 10 个。"
- 缺点: 引擎明明知道索引里可能有性别/年龄信息,但它不管,一股脑把 100 个 ID 全传回去,导致 Server 层做了 100 次回表,而实际上只有 10 个是有用的。
2. 有了索引下推时(MySQL 5.6 之后)
- Server 层指令: "给我找姓'张',且性别为'男'的人。过滤条件我'下推'给你了。"
- 存储引擎: "好。我在找索引的时候,看到姓'张'的就顺便看看他是不是'男'(因为这个信息就在联合索引里)。如果不匹配,我直接扔掉,不告诉你。"
- 存储引擎: "最后只找到了 10 个匹配的,把这 10 个 ID 给你。"
- Server 层: "太好了,我只需要做 10 次回表。"
- 优点: 减少了 90 次回表操作,大大降低了磁盘 I/O,速度飞快。
为什么要强调"主要用在联合索引上"?
这是因为索引下推利用的是索引中已经存在但无法直接通过索引定位(Range Scan)的列。
举个具体例子:
假设索引是 (name, age)。
SQL:
SELECT * FROM user WHERE name LIKE '张%' AND age = 20;- 正常索引定位: 由于 name 是模糊查询(张%),根据最左前缀原则,只有 name 这一列能用到索引来快速定位范围。age = 20 这个条件在定位时是没法用的。
索引下推: 虽然 age 不能用来"定位"范围,但 age 的数据就在这个索引树里啊!
- 下推前: 引擎把所有姓"张"的都传给 Server 层回表。
- 下推后: 引擎在扫描索引时,直接判断 age 是不是 20,不是 20 的直接过滤,不回表。
但又有一个坑,如果把SQL改为:
SQL:
SELECT * FROM user WHERE name LIKE '%张%' AND age = 20;就因为左模糊查询(以 % 开头)导致索引"失效"了,存储引擎连快速定位"起点"的机会都没有了,无法实现"索引寻址"(Index Seek):只能变成"索引扫描"(Index Scan)或全表扫描。
核心原因:B+ 树是按"顺序"排列的
数据库的索引(B+ 树)就像一本排好序的字典。
如果你建立了一个联合索引 (name, age),在索引树里,数据是这样排列的:
- 先按 name 排序:安琪拉、曹操、鲁班、张飞、张三、诸葛亮......
- name 相同时按 age 排序:张三(20岁)、张三(25岁)......
场景 A:WHERE name LIKE '张%'(前缀匹配)
- 过程: 像翻字典一样,你直接翻到"张"字开头的页码。
- 结果: 存储引擎能立刻定位到姓"张"的数据范围。在这个范围内,它可以利用"索引下推"顺便检查 age 是不是 20。
场景 B:WHERE name LIKE '%张%'(全模糊/左模糊)
- 过程: 你要找名字里包含"张"的人。它可以是"张三",也可以是"老张",还可以是"光头张"。
- 尴尬点: 在排好序的字典里,"老张"在 L 部,"光头张"在 G 部,"张三"在 Z 部。
- 结果: 索引的"顺序性"完全没用了。存储引擎无法跳过 任何数据,它必须从头到尾扫一遍。
为什么这时候"索引下推"救不了场?
虽然理论上,存储引擎在"全表扫描"或者"全索引扫描"的过程中,也可以顺便判断 age=20,但这种情况通常不叫"索引下推"的典型应用,原因如下:
-
性能差距太巨大:
- name LIKE '张%':利用索引只扫描 10 行(假设姓张的就 10 个),回表 0-10 次。
- name LIKE '%张%':必须扫描 100 万行 (假设表有 100 万数据),这种扫描叫 Full Table Scan (全表扫描) 或 Full Index Scan。
-
优化器的"嫌弃":
- 当优化器发现 name LIKE '%张%' 无法通过索引快速定位数据时,它会认为:"反正都要全表扫描,我干脆直接读主键索引(聚簇索引)拿完整数据好了,省得我还得在二级索引和主表之间跳来跳去。"
- 一旦决定全表扫描,就不存在所谓的"利用二级索引过滤数据"了。
再看这样的例子
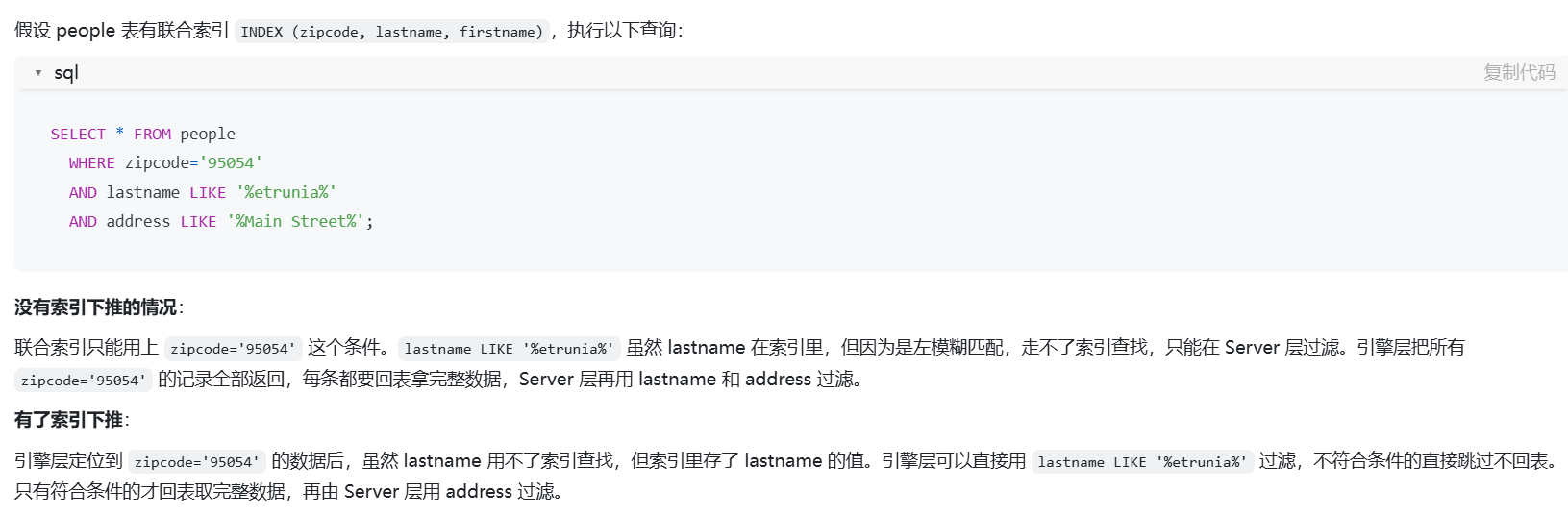
索引下推(ICP)生效的前提是:必须先有"一部分索引"能被用来"定位(Range Scan/Ref)"数据的起始范围。
让我们对比一下刚才问的例子和图片里的例子:
- 刚才的例子:WHERE name LIKE '%张%'
- 索引: (name, age)
- 执行过程: 索引的第一列 name 就是 % 开头。由于没有最左前缀,MySQL 连索引的"门"都进不去。
- 结果: 存储引擎没法通过索引定位到任何一个特定的"范围",它只能做全表扫描。既然已经是全表扫描了,索引下推也就失去了"减少回表"的意义,因为代价已经封顶了。
- 图片里的例子:WHERE zipcode='95054' AND lastname LIKE '%etrunia%'
- 索引: (zipcode, lastname, firstname)
- 关键点: 这里的 zipcode 是等值查询(='95054')。
- 执行过程:
- 索引定位(Index Seek): 存储引擎可以利用 zipcode 这个第一列索引,飞快地定位到所有 zipcode='95054' 的索引记录块。
- 进入范围: 此时,引擎手里已经抓住了这 1000 条(假设)zipcode='95054' 的索引数据了。
- 索引下推发挥作用:
- 如果没有 ICP: 引擎要把这 1000 条 ID 全部给 Server 层,由 Server 层回表查 1000 次,再过滤 lastname。
- 如果有 ICP: 引擎发现这 1000 条索引里已经包含了 lastname 这一列的值。虽然 %etrunia% 这种左模糊没法用来"定位"范围,但在**已经定位好的范围里做"内存过滤"**是可以的!
- 结果: 引擎在内存里把 1000 条索引过滤一遍,发现只有 10 条符合 lastname LIKE '%etrunia%',于是只回表 10 次(用户要的是 SELECT *)。
总结:两者的本质区别
| 查询条件 | 索引能否"进门" (定位) | 索引下推能否介入 | 核心原因 |
|---|---|---|---|
| name LIKE '%张%' | 不能 | 不能 (或没意义) | 索引的第一列就无法定位,必须扫全表。 |
| zipcode='95054' AND lastname LIKE '%张%' | 可以 (靠 zipcode) | 可以 | zipcode 帮引擎进场了,进场后发现 lastname 就在手边,顺便滤掉。 |
| 换个生活化的比喻: |
- 刚才的例子(只有 %张%): 你要去图书馆找书名含"张"的书。管理员说:"书是按书名首字母排的,你要找中间含'张'的,我没法直接带你去那一排,你自己从第一排第一本开始一本本翻吧。"(全表扫描,索引失效)
- 图片例子(邮编 + %张%): 你找邮政编码是 95054 且名字含"张"的人。管理员说:"好,邮编是 95054 的都在第 5 货架,我带你过去。虽然这排书是按名字排的,我没法直接定位'张',但我可以就在第 5 货架这几个格子里 帮你翻一下,把名字含'张'的挑出来给你,你不用把整排书都搬回家查。"(索引下推成功)
结论:
索引下推是为了在已经缩小了的索引范围内,进一步利用索引里的其他列进行过滤。如果连第一步"缩小范围"都做不到,索引下推就无从谈起。
总结
- Server 层: 负责决策、过滤、计算。
- 存储引擎层: 负责读写、根据索引找 ID。
- 索引下推(ICP): 把原本属于 Server 层的"过滤"逻辑,下放到了存储引擎层。
- 核心价值: 减少回表次数,减少磁盘 I/O,提升查询性能。
一句话总结:
以前是"把东西都搬回家再挑",现在是"在仓库挑好了再搬回家"。