想象一下这样的场景:自动驾驶汽车行驶在暴雨中,挡风玻璃上的雨刷疯狂摆动,摄像头捕捉到的画面已经模糊不清。但车辆的检测系统依然信心满满地告诉你------前方道路"一切正常"。这听起来有些科幻,却是在真实世界中屡见不鲜的技术困境。
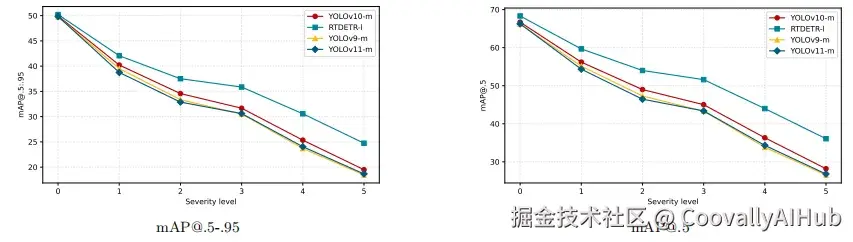
现代目标检测器在标准条件下确实表现得相当出色,可一旦遇上模糊、噪声、压缩伪影或恶劣天气,它们的表现就可能急转直下。更让人头疼的是,这些系统往往不会主动承认自己"看不清"了,反而继续以高置信度输出预测结果。
这不正是我们常说的"盲目自信"吗?
当"不知道"比"知道"更重要
说起来,计算机视觉领域的学者们一直在思考一个问题:如何让模型具备"自我意识",能够判断当前输入是否超出了它能够处理的范围?
传统的做法是依赖置信度分数或预测不确定性。这种方法在轻度扰动下还算有效,但遇到强图像退化时就显得力不从心。试想一下,当一张图片严重模糊到几乎看不出任何物体时,检测器可能根本找不到目标------但这并不意味着系统已经"意识到"自己正处于不适合工作的环境中。恰恰相反,它可能只是安静地给出了一个空白结果,既不报错也不预警。
这种情境下,我们需要的不再是预测结果的可靠性,而是对输入本身质量的评估。换句话说,我们需要一个专门负责"检查输入质量"的模块,与原有的检测器并行工作。
一场与退化图像的博弈
为什么不直接在检测器的特征空间中构建一个"退化流形"呢?
所谓 "退化流形" ,简单来说就是一个按照图像退化类型和程度来组织的高维空间。在这个空间里,受到相同类型退化影响的图像会聚集在一起,不同类型的退化则相互远离。这种组织方式完全基于图像的视觉保真度,而不是它们包含的语义内容。
实现这个想法需要几个关键步骤:
首先,提取多层次特征。 研究者们从检测器的主干网络中提取多个层次的特征图。浅层特征负责纹理和高频统计信息,深层特征则编码更抽象、更语义化的内容。不同类型的退化会对这些层次产生不同的影响。
接着,构建正负样本对。 对同一张原始图像,应用相同的退化组合(比如"模糊+噪声")生成两个不同的退化版本,它们构成正样本对,应该在嵌入空间中靠近。而如果对退化图像再进行一次分辨率降低处理,得到的就是难负样本,应该与原始退化图像在空间中远离。
然后,通过对比学习优化空间结构。 这个过程中,同一退化类型的图像被拉近,不同类型的被推远,最终形成一个几何上有序的表示空间。
最后,设定一个参考点。 从干净的训练图像中计算出一个"纯净原型",作为正常操作条件的基准。在推理时,只需计算新图像与这个原型的余弦距离,就能得到退化分数。
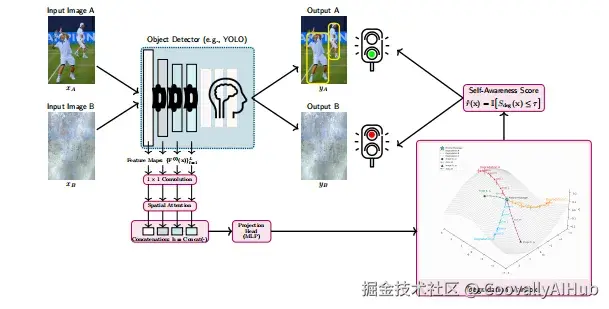
整个流程让我想起了一个有趣的类比:这就像让检测器同时拥有一个"质检员",专门负责检查输入图像的质量,而不干预检测任务本身。
自我意识,从何而来?
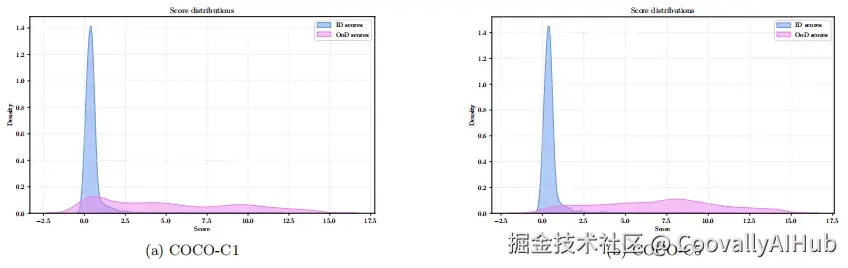
实验结果表明,这种方法确实能有效区分干净图像和退化图像。在COCO数据集上的测试中,该方法在不同退化程度下都取得了优异的AUROC分数(一种衡量分类性能的指标)。尤其值得一提的是,当退化程度达到5级时,AUROC可以超过97%。
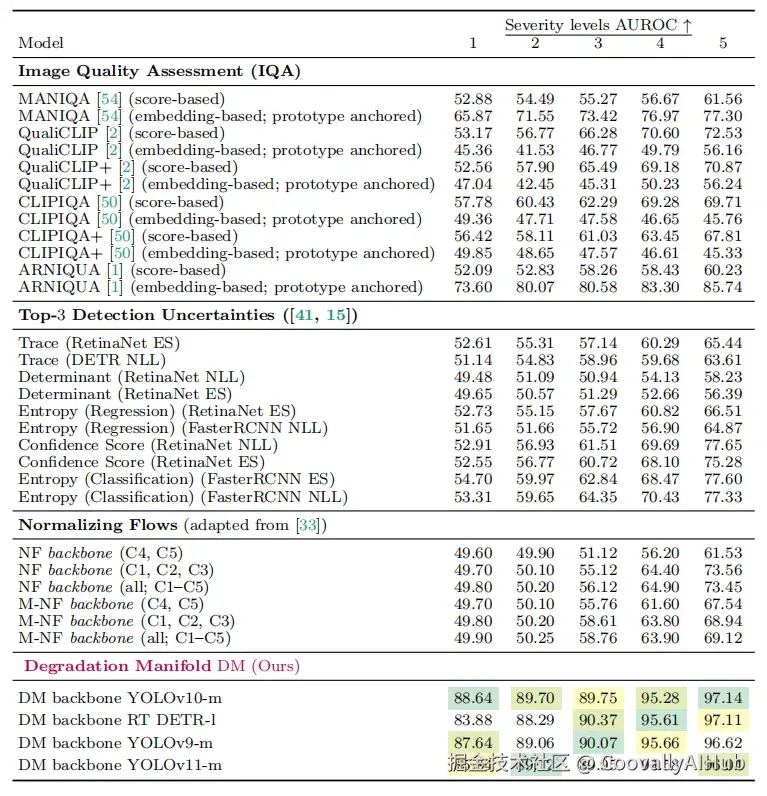
更令人印象深刻的是,这种能力可以很好地迁移到未见过的数据集上。研究人员在KITTI、BDD等自动驾驶数据集上进行了零样本测试,结果依然保持稳定。这意味着模型学到的是退化本身的特征,而不是特定数据集的统计特性。
从t-SNE可视化结果中可以清楚地看到,不同类型的退化图像在嵌入空间中形成了明显的聚类。高斯模糊、运动模糊、噪声、JPEG压缩......每一种都有自己独特的"领地"。而干净图像则紧凑地聚集在一起,无论它们来自哪个数据集。
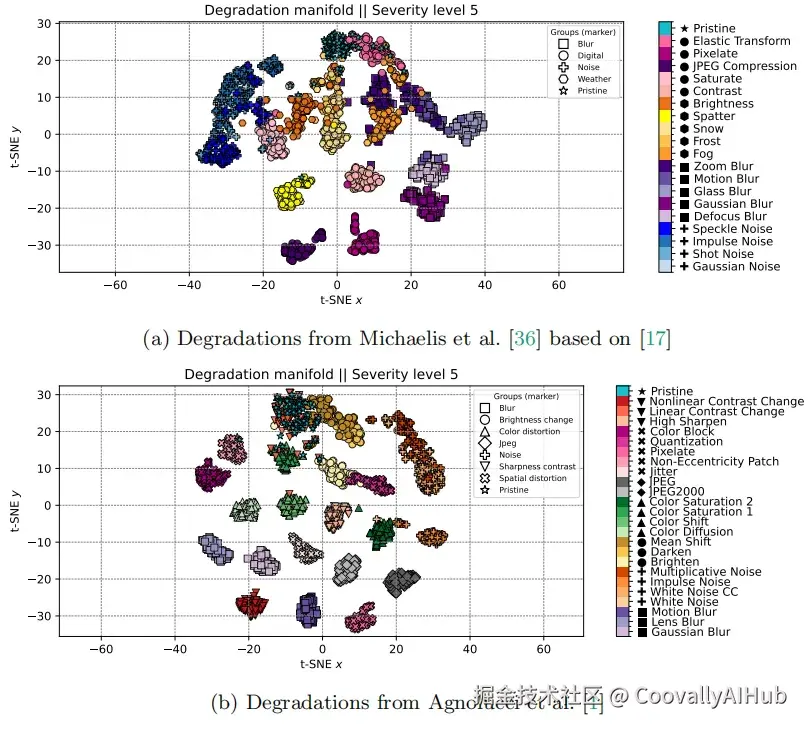
有趣的是,即使是在自然天气变化这种更复杂的场景中,该方法也表现出了不错的区分能力。在雾、雪、雨等恶劣天气条件下,退化分数明显高于晴朗天气。
输出不确定性,为何不够?
你可能会问:既然已经有了置信度分数,为什么还需要专门设计一个退化监测模块?
原因在于,输出层面的不确定性本质上是一种"事后判断"。 它依赖于检测器是否找到了目标、以多高的置信度认为那是目标。当图像严重退化导致检测器根本找不到任何目标时,这种机制就失效了------没有输出,也就无法评估。
另一个问题是,输出不确定性与语义内容高度相关。 模型可能对没见过的新类别感到困惑,但这种困惑与图像质量无关。反过来,一些严重退化的图像可能因为低层统计特征与训练数据相似,反而获得较高的似然估计。
相比之下,基于特征空间的退化监测是一种"事前判断"。 它在检测器开始工作之前,就对输入质量进行了评估。这种评估完全基于图像本身的视觉保真度,与图像内容无关,也不依赖于检测结果。
不是完美的方案,但足够实用
当然,这种方法也有自己的局限性。它测量的是与正常成像条件的偏离程度,但并不直接预测任务失败的可能性。有些图像即使退化严重,关键目标可能依然可检测;而有些看似干净但语义复杂的图像,反而可能导致检测失败。
另外,当前的退化采样主要关注图像形成过程中的影响因素(噪声、模糊、压缩、分辨率等),并未覆盖语义分布偏移、领域变化或标签噪声等更复杂的情况。
不过,在多数实际应用场景中,能够提前感知输入质量下降并发出预警,已经是一个巨大的进步。这相当于为检测系统增加了一层"自知之明"------它不再盲目地给出预测,而是能够判断当前环境是否适合工作。
这种能力对于自动驾驶、安防监控、医疗影像等安全关键型应用尤为重要。在这些领域,让系统学会说"我不知道"或"我不确定",可能比追求更高的检测精度更有意义。
说起来,让机器具备"自我怀疑"的能力,或许正是通向更可靠人工智能的一条必经之路。毕竟,知道自己不知道什么,有时候比知道自己知道什么更为重要。