关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
前面专门介绍了Apache Calcite动态数据源基于原生connection的使用方法。使用起来有点不太方便,能不能像JDBC一样查询数据呢?
正好前面分享了Spring 6.x的JdbcClient用法,我们直接一步到位,使用JdbcClient查询。
02 最佳实践配置
Apache Calcite是一个标准SQL解析器、验证器和优化器框架,支持多种后端数据源。这里就不多介绍了,直接看用法。
2.1 依赖引入
xml
<!-- Apache Calcite -->
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.38.0</version>
</dependency>
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-csv</artifactId>
<version>1.38.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<!--- 根据需要引入 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>2.2 配置数据源
要使用JDBC的客户端,就需要配置数据源。
java
@Bean
public DataSource calciteDataSource() throws Exception {
Properties prop = new Properties();
prop.put("lex", "MYSQL");
prop.put("model", "src/main/resources/calcite-model.json");
Connection connection = DriverManager.getConnection("jdbc:calcite:", prop);
SingleConnectionDataSource calciteDataSource = new SingleConnectionDataSource(connection, true);
return calciteDataSource;
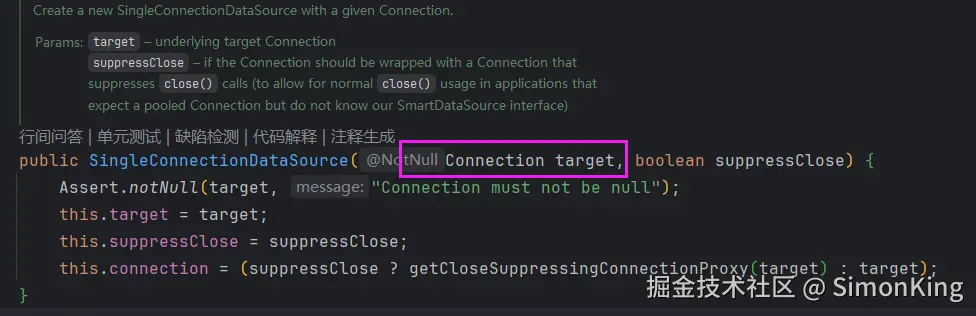
}因为DataSource是一个接口,需要我们自行构建或者使用其实现类,并且可以设置connection的类。DataSourceBuilder的构建方式行不通,我们只能使用其子类。
SingleConnectionDataSource类刚好可以满足我们的条件。当然也可以自行去兼容,我们这里怎么简单怎么来。
2.3 配置文件
配置文件需要配置一个jdbcd的方言,否则调用会报错。
properties
spring.data.jdbc.dialect=mysql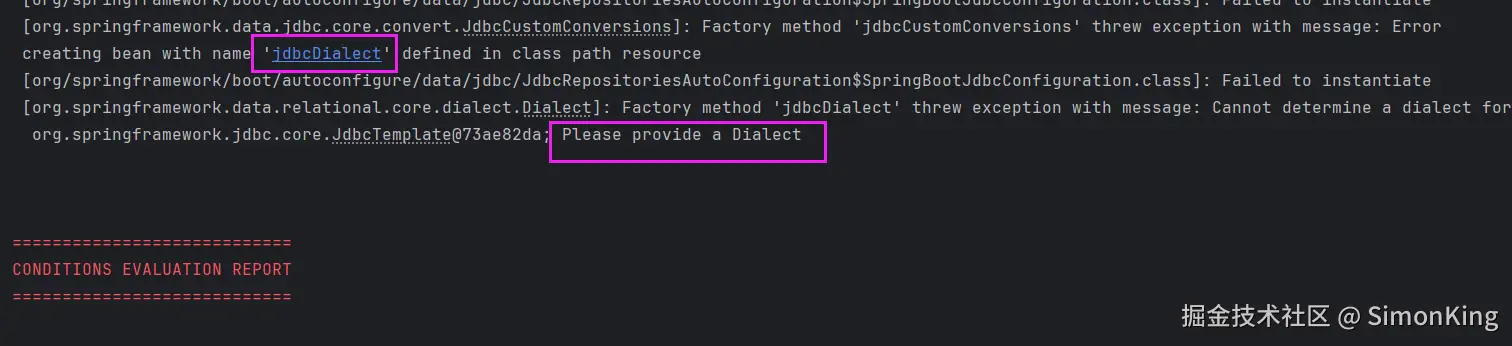
2.4 模型文件
模型文件之前已经介绍了,想要了解可以看看之前的文章:《多数据源:CSV、内存对象可以通过SQL查询,甚至联查,你敢信!》
json
{
"version": "1.0",
"defaultSchema": "MEM",
"schemas": [
{
"name": "MEM",
"type": "custom",
"factory": "org.apache.calcite.adapter.java.ReflectiveSchema$Factory",
"operand": {
"class": "com.simonking.boot.calcite.schema.UserSchema"
}
},
{
"name": "CSV",
"type": "custom",
"factory": "org.apache.calcite.adapter.csv.CsvSchemaFactory",
"operand": {
"directory": "csv",
"flavor": "scannable"
}
},
{
"name": "MYSQL_DB",
"type": "custom",
"factory": "org.apache.calcite.adapter.jdbc.JdbcSchema$Factory",
"operand": {
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test",
"jdbcUser": "root",
"jdbcPassword": "root"
}
}
]
}03 实战
我们分别从内存、CSV、mysql这三个数据源实战,应该可以覆盖常用的场景了。
3.1 内存实战
模拟内存数据
java
public class UserSchema {
public final User[] users;
public UserSchema() {
// 模拟数据
this.users = new User[]{
new User(1, "zhangsan", 18),
new User(2, "admin", 20),
new User(3, "lisi", 22)
};
}
/**
* @Description: 字段类型
**/
@AllArgsConstructor
public class User {
/** 用户id */
public final Integer id;
/** 用户名 */
public final String name;
/** 年龄 */
public final Integer age;
}
}案例
java
@Autowired
private JdbcClient jdbcClient;
@Test
void contextLoads01() {
UserVO userVO = jdbcClient
.sql("select * from MEM.users where id = ?")
.param(1)
.query(UserVO.class)
.single();
System.out.println(JSON.toJSONString(userVO));
}结果

3.2 CSV实战
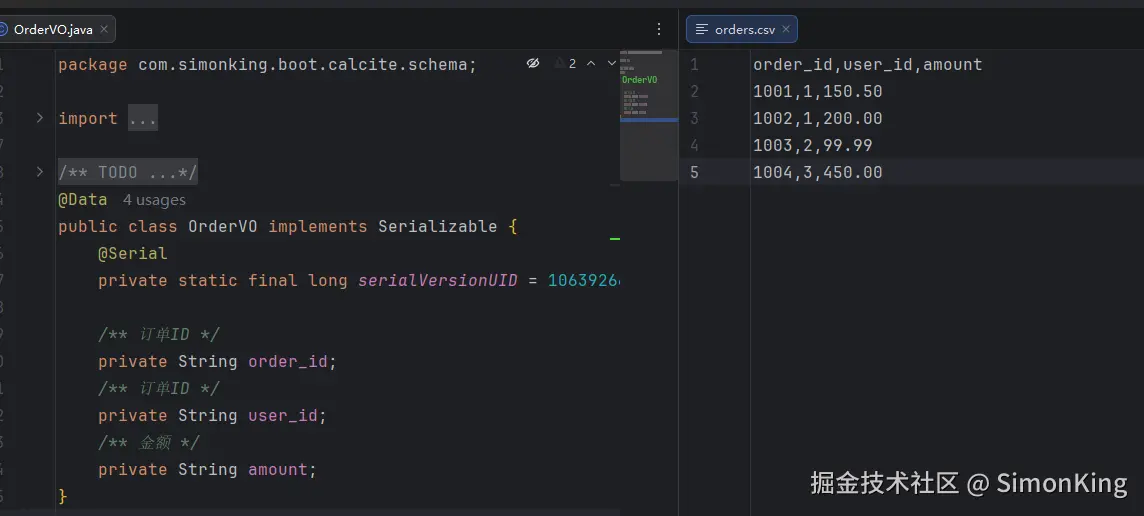
模拟数据
案例
java
@Autowired
private JdbcClient jdbcClient;
@Test
void contextLoads01() {
OrderVO orderVO = jdbcClient
.sql("select * from CSV.orders where user_id = :userId")
.param("userId", 2)
.query(OrderVO.class)
.single();
System.out.println(JSON.toJSONString(orderVO));
}结果

坑点
CSV数据源查询的时候有个小问题,上面的接受的实体使用的参数类型都是String。正常来讲order_id、user_id应该为Integer或Long类型,amount应该为BigDecimal类型。
开始我就是这么定义的,结果发现执行报错:

从报错中可以看出calcite是通过StringAccessor来解析的,源码中包含了IntegerAccessor但是没有调用到。
解决方案
没有在官网中找到明确的文档,但是从官方给的example找到了答案:
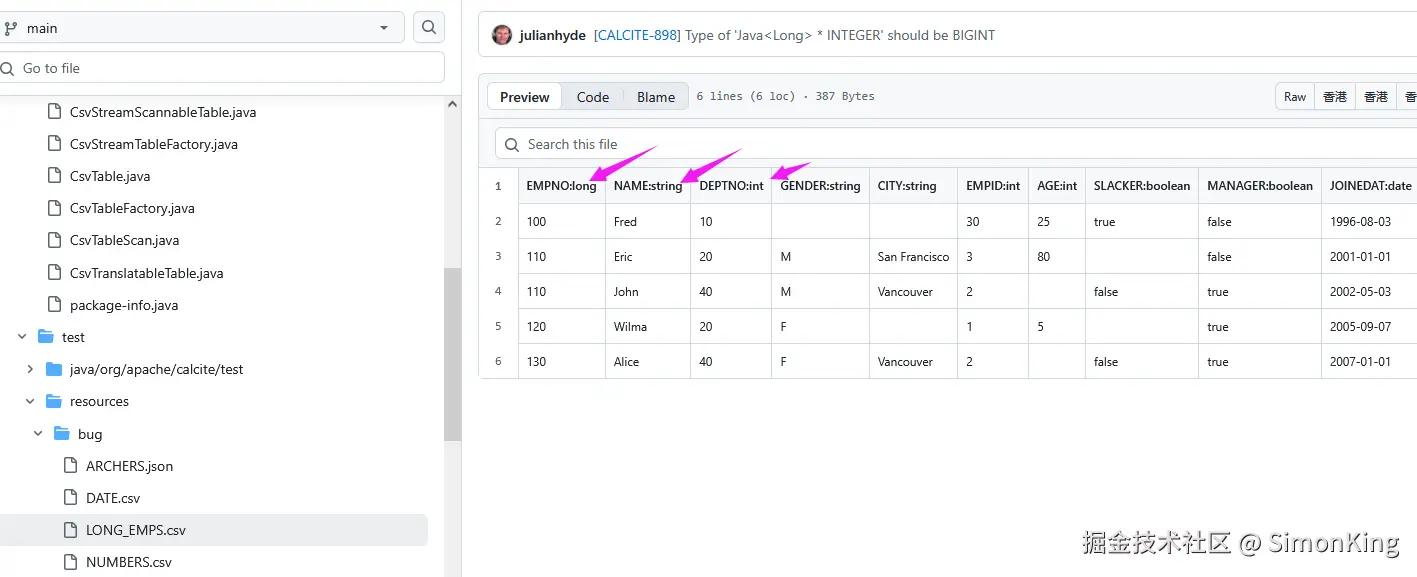
直接在字段后面直接指定类型并用冒号隔开。这里使用的是基础数据类型。BigDecimal可以使用double处理。
我们看看结果吧。
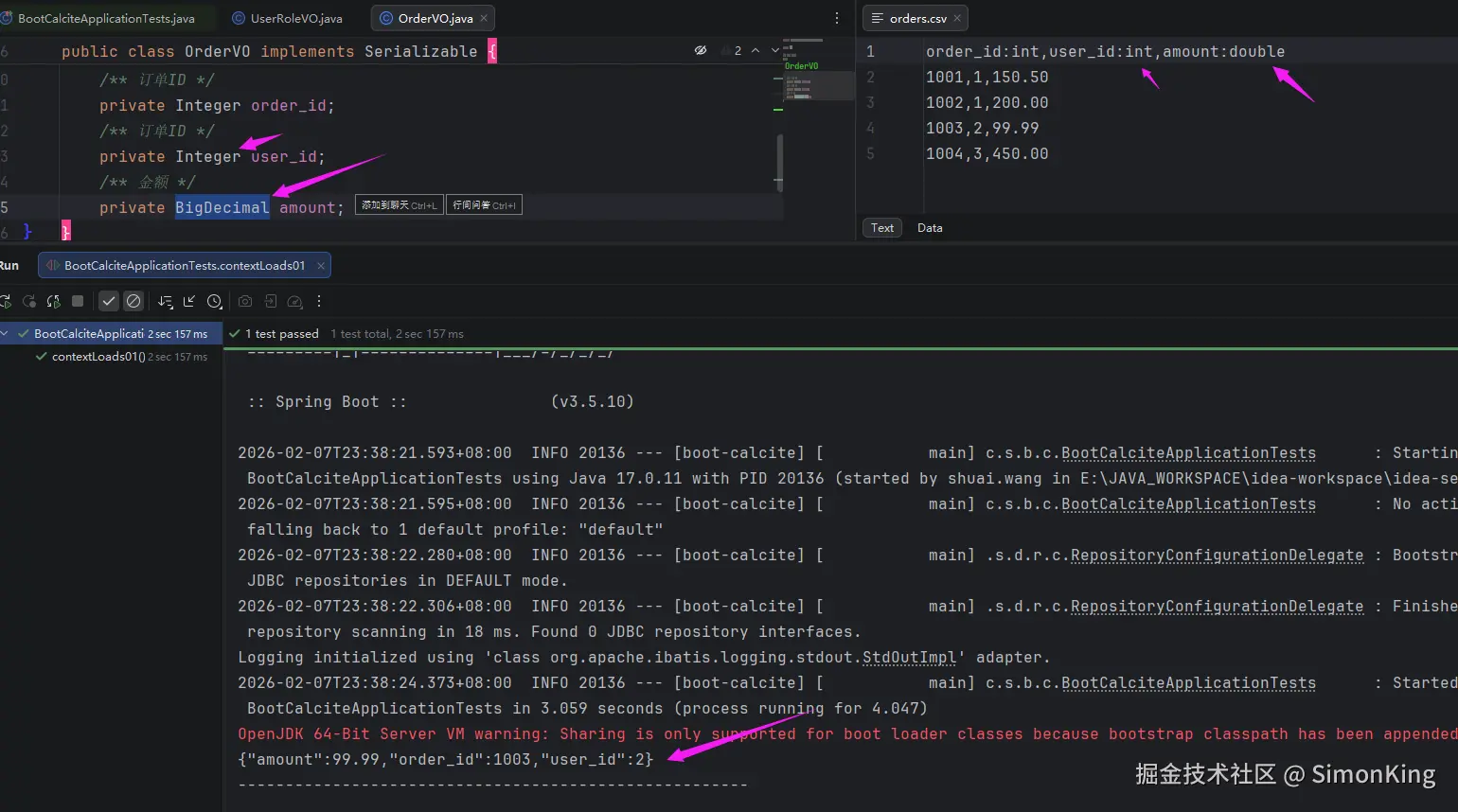
3.3 Mysql实战
模拟数据
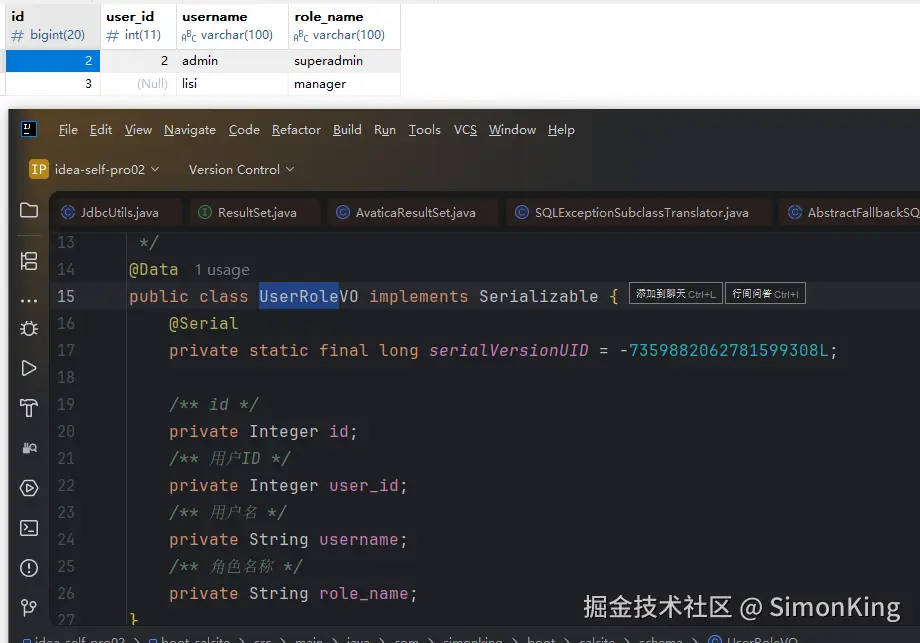
案例
java
@Autowired
private JdbcClient jdbcClient;
@Test
void contextLoads01() {
UserRoleVO userRoleVO = jdbcClient
.sql("select * from MYSQL_DB.user_roles where user_id = :userId")
.param("userId", 2)
.query(UserRoleVO.class)
.single();
System.out.println(JSON.toJSONString(userRoleVO));
}结果

3.4 联查
为了方便,我们就不定义实体了,直接使用Map接收。
java
List<Map<String, Object>> list = jdbcClient.sql("""
SELECT * FROM CSV.orders o
INNER JOIN MEM.users u ON o.user_id = u.id
INNER JOIN MYSQL_DB.user_roles r
ON u.id = r.user_id
WHERE u.id = :userId
""")
.param("userId", 2)
.query()
.listOfRows();
System.out.println(JSON.toJSONString(list));结果

这里的查询不受定义的字段类型的影响。
04 小结
原本想着之前使用connection方式已经完成了案例,改造成JdbcClient应该很顺利,但是没有想到还需遇到的意想不到的问题,好在都解决了。后面项目中使用就可以直接使用JdbcClient愉快的干活了。