目录
[Greedy Search](#Greedy Search)
[Beam Search](#Beam Search)
[Beam search](#Beam search)
采样策略
随机采样
按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
Greedy Search

思路:直接选择分布中概率最大的token当作解码出来的词,但是该问题在于,总是选择概率最大的词,将会生成很多重复的句子
优点:计算简单高效
缺点:文本重复,没有多样性
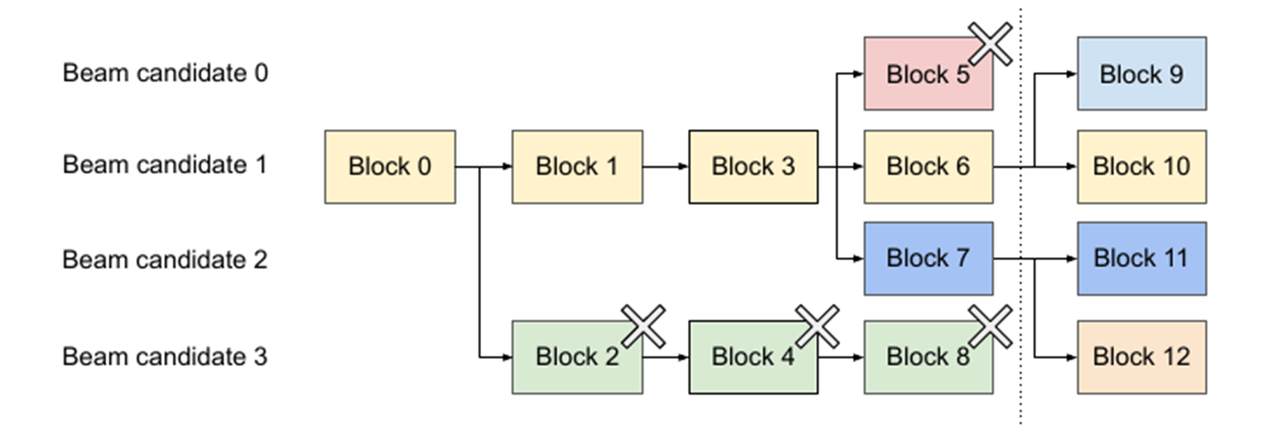
Beam Search
-
在第一个时间步,A和C是最优的两个,因此得到了两个结果
[A],[C],其他三个就被抛弃了; -
第二步会基于这两个结果继续进行生成,在A这个分支可以得到5个候选人,
[AA],[AB],[AC],[AD],[AE],C也同理得到5个,此时会对这10个进行统一排名,再保留最优的两个,即图中的[AB]和[CE]; -
第三步同理,也会从新的10个候选人里再保留最好的两个,最后得到了
[ABD],[CED]两个结果。
可以发现,beam search在每一步需要考察的候选人数量是贪心搜索的num_beams倍,因此是一种牺牲时间换性能的方法。
思路:beam search是对贪心策略一个改进。思路也很简单,就是稍微放宽一些考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。是一种启发式图搜索算法,通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率,但缺点就是有可能存在潜在的最佳方案被丢弃,因此Beam Search算法是不完全的,一般用于解空间较大的系统中。
优点:不仅仅关注当下的策略,一定程度上保证了最终得到的序列概率是最优的。
缺点:Beam Search虽然比贪心强了不少,但还是会生成出空洞、重复、前后矛盾的文本。
上方法都有各自的问题,而 top-k 采样和 top-p 采样是介于贪心解码和随机采样之间的方法,也是目前 大模型 解码策略中常用的方法。
vllm采样策略
Beam search
假如beam size是2,也就是每次保留最好的两条路径
top_K
Top-k 采样是对贪心策略的优化,它从排名前 k 的 token 中进行抽样,允许其他分数或概率较高的token 也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。
Top-k Sampling 是一种随机采样策略。
【top-k 采样思路】:在每一步,只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。
思路:在每一步,先确定一个k值,然后从概率最高的k个词中随机选择下一个词。
优点:通过引入随机性,可以避免贪心解码的局部最优问题。
缺点:k的选择可能会影响生成文本的质量。
-
它可能会导致生成的文本不符合常识或逻辑。这是因为 top-k 采样只考虑了单词的概率,而没有考虑单词之间的语义和语法关系。例如,如果输入文本是"我喜欢吃",那么即使饺子的概率最高,也不一定是最合适的选择,因为可能用户更喜欢吃其他食物。
-
它可能会导致生成的文本过于简单或无聊。这是因为 top-k 采样只考虑了概率最高的 k 个单词,而没有考虑其他低概率但有意义或有创意的单词。例如,如果输入文本是"我喜欢吃",那么即使苹果、饺子和火锅都是合理的选择,也不一定是最有趣或最惊喜的选择,因为可能用户更喜欢吃一些特别或新奇的食物。
因此,我们通常会考虑 top-k 和其它策略结合,比如 top-p。
top_p
top-k 有一个缺陷,那就是"k 值取多少是最优的?"非常难确定。于是出现了动态设置 token 候选列表大小策略------即核采样(Nucleus Sampling)。
top_p是对top_k 的优化。
思路:Top-p Sampling,也称为Nucleus Sampling,是一种更加精细的采样策略,它选择累计概率超过某个阈值p的最小集合,然后从这个集合中随机采样。
例如,如果 p=0.9,那么我们只从累积概率达到 0.9 的最小单词集合中选择一个单词,而不考虑其他累积概率小于 0.9 的单词。这样可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
可以同时使用 top-k 和 top-p。如果 k 和 p 同时启用,则 p 在 k 之后起作用。
min_p
Min P所做的事情很简单:设置了一个最低值,只有达到这个值的token才会被考虑。
这个值会根据最高概率token置信度而变化。
如果设为0.1,那意味着它只会允许概率至少是最大概率token的1/10。
如果设置为0.05,则会允许至少是最大概率token的1/20的token
vllm采样参数
temperature
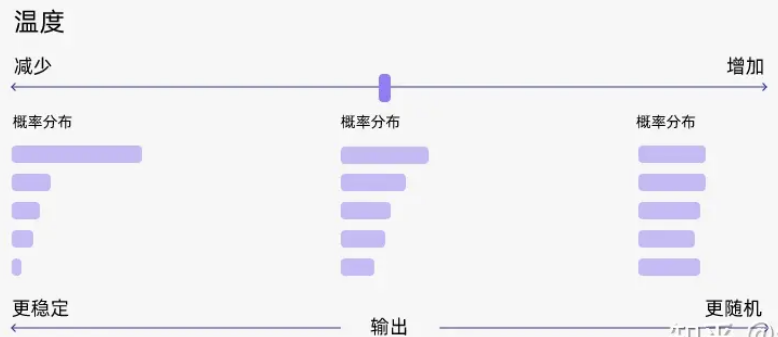
temperature这个参数可以告诉机器如何在质量和多样性之间进行权衡。
较低的 temperature 意味着更高的质量,而较高的 temperature 意味着更高的多样性。
length_penalty
这个长度惩罚参数也是用于束搜索过程中,在束搜索的生成中,候选序列的得分通过对数似然估计计算得到,即得分是负对数似然。
length_penalty的作用是将生成序列的长度应用于得分的分母,从而影响候选序列的得分,
当length_penalty > 1.0时,较长的序列得到更大的惩罚,鼓励生成较短的序列;
当length_penalty< 1.0时,较短的序列得到更大的惩罚,鼓励生成较长的序列,默认为1,不受惩罚
presence_penalty
存在惩罚:一种固定的惩罚,如果一个token已经在文本中出现过,就会受到惩罚。
这会导致模型引入更多新的token/单词/短语,从而使其讨论的主题更加多样化,话题变化更加频繁,
而不会明显抑制常用词的重复。
frequency_penalty
频率惩罚:让token每次在文本中出现都受到惩罚。这可以阻止重复使用相同的token/单词/短语,
同时也会使模型讨论的主题更加多样化,更频繁地更换主题。
repetition_penalty
参数影响模型在生成文本时对已生成词的偏好。在默认情况下,模型在生成下一个词时,
会根据训练数据中词的频率和上下文来预测下一个词的概率。然而,这种机制有时会导致模型生成重复的词或短语,特别是在长文本生成中。
当设置 repetition_penalty 参数时,模型在计算下一个词的概率时,会降低已生成词的概率,从而减少重复。
具体来说,如果一个词已经被生成过,它的概率会被乘以 repetition_penalty 的倒数。例如,如果 repetition_penalty 设置为 1.2,那么一个已经生成过的词的概率将被乘以 1/1.2,即 0.833,从而降低其被再次选择的概率。
调参技巧
将参数设为零的规则:
temperature:
对于每个提示语只需要单个答案:零。
对于每个提示语需要多个答案:非零。
频率惩罚和存在惩罚:
当问题仅存在一个正确答案时:零。
当问题存在多个正确答案时:可自由选择。
Top-p/Top-k:
在 temperature 为零的情况下:输出不受影响。
在 temperature 不为零的情况下:非零。
如果您使用的语言模型具有此处未列出的其他参数,将其保留为默认值始终是可以的。
当参数非0时,参数调整的技巧:
先列出那些应该设置为非零值的参数,然后去 playground 尝试一些用于测试的提示语,看看哪些效果好。但是,如果上述规则说要将参数值保持为零,则应当将其保持为零!
调整temperature/top-p/top-k的技巧:
为了使模型输入内容拥有更多的多样性或随机性,应当增加temperature。
在 temperature 非零的情况下,从 0.95 左右的 top-p(或 250 左右的 top-k )开始,根据需要降低 temperature。
注意:如果有太多无意义的内容、垃圾内容或产生幻觉,应当降低 temperature 和 降低top-p/top-k。
如果 temperature 很高而模型输出内容的多样性却很低,应当增加top-p/top-k。
Tip: 虽然有些模型能够让我们同时调整 top-p 和 top-k ,但我更倾向于只调整其中一个参数。top-k 更容易使用和理解,但 top-p 通常更有效。
调整频率惩罚和存在惩罚的技巧:
为了获得更多样化的主题,应当增加存在惩罚值。
为了获得更多样化且更少重复内容的模型输出,应当增加频率惩罚。
注意:如果模型输出的内容看起来零散并且话题变化太快,应当降低存在惩罚。
如果有太多新奇和不寻常的词语,或者存在惩罚设置为零但仍然存在很多话题变化,应当降低频率惩罚。
总结
-
top-k 采样和 top-p 采样是介于贪心解码和随机采样之间的方法,也是目前大模型解码策略中常用的方法。
-
可以同时使用 top-k 和 top-p。如果 k 和 p 同时启用,则 p 在 k 之后起作用。
-
top-k和beam search区别:top-k自始至终只有一个序列进行预测,k只用于规定采样的范围,每步只采样一个token作为结果。而beam search会保留num_beams个序列进行预测。
参考资料
https://openatomworkshop.csdn.net/674530193a01316874d8108b.html