- 输入维度通常是 NdotV 和 roughness
- 输出是 BRDF 中和视角相关的那部分(常记成 A,B 或 FGD)
实时时就不再做积分,只做:
- 2D 纹理采样
- 少量乘加(比如 spec = F0 * A + B)
为什么要它:
- 直接积分要很多采样循环(几十到上百次)才能稳定,实时不现实。
- LUT 把"复杂积分"变成"1次查表 + 几次ALU",在大量像素下非常划算。
Unity 里与环境相关的 cubemap 主要有三类来源:
-
全局环境反射(Skybox / Reflection Probe 结果)
-
某个具体 Reflection Probe 的 cubemap
-
你自己绑定的自定义 cubemap
获取"当前场景环境反射"的 cubemap(最常见)
在 Built-in / URP / HDRP 中,shader 都可以直接访问 Unity 注入的环境反射纹理。
Built-in pipeline:
Unity 会自动提供:
unity_SpecCube0
unity_SpecCube0_HDR
shader 里可以直接:
samplerCUBE unity_SpecCube0;
half4 col = UNITY_SAMPLE_TEXCUBE(unity_SpecCube0, dir);
这通常是:
-
当前物体所在位置对应的 Reflection Probe
-
或 fallback 到 skybox
并且已经是预过滤(mip 链按 roughness 用)。
如果启用了 box projection,还会有额外参数:
unity_SpecCube0_BoxMin
unity_SpecCube0_BoxMax
unity_SpecCube0_ProbePosition
URP:
URP 通过宏封装,实际变量类似:
TEXTURECUBE(_GlossyEnvironmentCubeMap);
但一般不要直接写变量名。
使用:
SAMPLE_TEXTURECUBE_LOD
或通过:
GlossyEnvironmentReflection()
在 URP 的 lighting.hlsl 中可以看到实现。
HDRP:
HDRP 不直接暴露 raw cubemap。
它走的是:
-
reflection atlas
-
probe volume
-
cluster-based sampling
你通过:
EvaluateReflectionProbes()
或:
SampleEnv()
而不是直接 samplerCUBE。
++HDRP 的环境数据存储在 atlas 中++,并通过索引查找。
能否"读取场景里某个具体 Reflection Probe 的 cubemap"?
默认不能。
Unity ++不允许 shader 枚举或查询场景资源。++
Shader 只能访问:
-
当前++渲染物体绑定的 probe(Unity++ 自动++选择++)
-
或你手动传入的纹理
如果你想访问某个指定 probe:
必须在 C# 里:
-
获取 probe.texture
-
通过 material.SetTexture() 传给 shader
++shader 本身无法主动"查询场景里有哪些 cubemap"。++
你在 shader 中使用:
UNITY_SAMPLE_TEXCUBE(unity_SpecCube0, R);
你得到的是:
-
已经预过滤的 cubemap
-
包含 mip chain
-
经过 HDR decode(需要 DecodeHDR)
它不是原始 cubemap,而是:
经过 convolution 的 specular IBL 版本
如果你想获得"未预过滤"的原始环境图,是做不到的(除非你自己传)。
目的是自定义 FGD / IBL 计算
典型做法:
float3 R = reflect(-V, N);
float mip = roughnessToMip(roughness);
float3 env = SAMPLE_TEXTURECUBE_LOD(unity_SpecCube0, R, mip);
然后再乘你的 FGD 项。
这就是标准 split-sum IBL。
资源绑定由渲染管线控制,shader不具有权限
它以前是这么会讲话的?我怎么不记得

Key Breakdown:
-
ee (like 'bee')
-
kwi (like 'quick' without the 'ck')
-
rek (like 'wreck')
-
TANG (rhymes with 'sang', primary stress)
-
gyuh (soft 'g' sound)
-
lur (like 'blur')
 YouTube
YouTube
An equirectangular projection (or plate carrée) is a map projection that maps spherical coordinates---specifically, longitude and latitude---directly to a 2:1 rectangular image, where meridians are vertical lines and parallels are horizontal . It is widely used for 360-degree panoramic photography, VR, and mapping, providing an easy linear mapping of 360° horizontal (yaw) and 180° vertical (pitch) views.
是否需要"非常尖锐的镜面反射"(低 roughness、头发高光那种窄 lobe)在环境里还能看出细节。粗糙一点的反射,高分辨率几乎全被 mip 糊掉了。
Specular IBL 里的 mip:不同粗糙度下的预卷积环境, 由 roughness 主动选择 LOD
你理解的 mip 是对的:
它确实是"同一张纹理的多级分辨率版本,用于 LOD"。
但在 specular IBL 里,它不只是"远处用低分辨率",而是被主动拿来当卷积结果用。这是语境差异导致的理解冲突。
关键区别在于:
普通贴图的 mip :
→ 为了抗 alias / 做距离 LOD
→ 由硬件根据导数 自动选
Specular IBL 里的 mip:
→ 被当作"不同粗糙度下的预卷积环境 "
→ 由 roughness 主动选择 LOD
这两种用途完全不同。
导数从哪里来
在 fragment/pixel shader 里,GPU 以 2×2 pixel quad 为单位并行执行。
同一 quad 内,硬件可以直接比较相邻像素的插值结果,从而得到:
ddx(u), ddy(u)
ddx(v), ddy(v)
这不是数值微分,而是:
ddx(u) = u(x+1,y) - u(x,y)
ddy(u) = u(x,y+1) - u(x,y)
这些导数是屏幕空间导数。
LOD 的基本公式(简化版)
GPU 会估算一个 footprint(像素覆盖的纹理面积),核心量是:
ρ ≈ max( |∂u/∂x|, |∂u/∂y|, |∂v/∂x|, |∂v/∂y| )
然后:
lod ≈ log2( ρ * textureSize )
直观理解:
-
如果一个像素在纹理空间覆盖很多 texel
→ ρ 大
→ lod 大
→ 用更高 mip(更模糊)
-
如果像素在纹理空间只覆盖很小区域
→ ρ 小
→ lod 小
→ 用低 mip(清晰)
导数大小由两件事决定:
-
你的纹理坐标变化速度
例如:
-
UV 被大比例缩放
-
三角形在屏幕上很小
-
透视缩放严重
-
法线/反射向量变化剧烈
-
-
屏幕投影关系
透视投影下远处物体 UV 变化更快 → 导数更大 → 更高 mip
所以"自动选 mip"是由:
屏幕空间几何变化 → 插值 → quad 内差分 → 硬件 LOD 公式
驱动的。
和 spec IBL 的区别
在普通纹理 你用的是:tex2D()
硬件自动根据导数选 mip。
在 spec IBL 里:
你通常会用:texCUBElod()或 SAMPLE_TEXTURECUBE_LOD()
此时你手动提供 mip。
因为你不希望: LOD 由屏幕尺寸决定 ,而是由:roughness 决定。
这两种 LOD 逻辑完全不同。
为什么必须手动 LOD 做 IBL?
如果你让硬件自动选 mip:
-
远处物体会更模糊
-
近处更清晰
但物理上:
粗糙度才决定模糊程度,
和屏幕距离无关。
所以 IBL 必须:
用 roughness → mip 映射,
覆盖掉硬件导数 LOD。
原来如此,也就是说mip的不同使用,平常的那种是为了lod,那是一种mip,而这里的mip是为了让不同的roughness作为参数影响不同的效果,相当于在硬件的上层接管了对mip的控制,mip只是一个概念,一个实现方法,而不是具体的某个图
不只是"远处用低分辨率",而是被主动拿来当卷积结果用
specIBL ≈ prefilteredEnv(R, roughness) * FGD(NoV, roughness)
在 PBR split-sum IBL 里:
specIBL ≈ prefilteredEnv(R, roughness) * FGD(NoV, roughness)
这里的 prefilteredEnv 实际上是:
Env 与 GGX lobe 的卷积结果。
而在实时里,这个卷积通常被"烘焙进 cubemap 的 mip 链"。
也就是说:
mip0 = 几乎未卷积(sharp)
mip1 = 略微模糊
mip2 = 更模糊
...
最后一级 = 接近常数球谐
当 roughness 增大时,你主动采样更高 mip。
这不是距离导致的 LOD,是 BRDF lobe 变宽导致的"角域低通滤波"。
高分辨率 cubemap 只对低 roughness 有意义。
为什么高分辨率经常没意义
假设:
你的 roughness = 0.4
GGX lobe 的半角宽度可能已经覆盖几十度的立体角。
这意味着:
反射方向周围的环境细节都会被卷积平均掉。
就算 cubemap 是 4K,
最终参与积分的是一个"大范围加权平均"。
结果自然"糊"。
这不是分辨率丢失,而是物理上 lobe 宽。
什么时候分辨率真的重要?
只有在:
roughness 很低(比如 0.02 ~ 0.1)
GGX lobe 非常尖锐,接近 delta。
这时:
采样主要集中在一个很小的角域范围。
此时 cubemap 分辨率不足,就会:
-
灯条边缘不锐
-
高频细节糊
-
镜面像低质量 SSR
所以:
高分辨率 cubemap 只对低 roughness 有意义。
一个更精确的角域理解
GGX 的 lobe 宽度大致与 α² 成正比(α≈roughness)。
当 α 增大时:
你在球面上做的是大面积加权平均。
而 mip 本质就是:
对球面信号做低通滤波。
所以"被 mip 糊掉"其实等价于:
"BRDF 在角域做低通卷积"。
只是 mip 是近似实现。
「 角域 」(Angular Domain)通常是相對於「空域」(Spatial Domain)的一個概念。
在電腦圖形學與渲染的語境下,「 角域 」(Angular Domain)通常是相對於「 空域」(Spatial Domain)的一個概念。
接續你提到的「粗糙度」話題,這兩個「域」決定了我們如何處理光影細節:
- 空域 (Spatial Domain): 指的是物體在三維空間中的「位置」或貼圖上的「像素座標」。當我們談論物體的形狀、邊緣或細節分佈時,我們是在空域討論。
- 角域 (Angular Domain): 指的是光線射入或反射的「方向」。因為光線在球面上是依據角度(θ, φ)分佈的,所以反射的模糊程度、高光的大小,本質上都是在「角度的維度」上進行運算。 -University of Delaware +2
為什麼粗糙度跟「角域」有關?
當你說「解析度被 Mip 糊掉」時,其實涉及了這兩個域的轉換:
- 角域的擴張: 粗糙度越高,光線反射的方向就越不固定(角域範圍變大、變散)。
- 空域的模糊: 為了模擬這種「角域的擴散」,引擎會去抓取反射貼圖中較模糊的層級(Mipmap)。這本質上是用空域的模糊(低解析度像素)來模擬角域的散射(光線方向不一致)。
簡單類比
- 空域: 就像你在地圖上找一個具體的地址。
- 角域: 就像你站在原地,轉動頭部觀察四周不同的方位。
在 PBR 渲染中, ++預過濾環境貼圖 (Pre-filtered Environment Map) 就是將「角域」資訊預先存進「空域」貼圖的過程。粗糙度就是控制你要從這個角度分佈中取多大的範圍。++
在圖形學、訊號處理或影像處理中,「 低通」(Low-pass)是一個非常核心的概念。
簡單來說: 「低」指的是低頻(Low Frequency),「通」指的是通過(Pass)。
什麼是低通濾波(Low-pass Filtering)?
低通濾波的作用就是: 「讓平緩的訊號通過,濾掉劇烈變化的訊號。」
低通濾波 (Low-pass Filter)
這是一個 目的。當我們說「對反射進行低通濾波」時,意思就是我們要去掉反射中那些清晰的細節,讓它變模糊。
低通卷積 (Low-pass Convolution)
這是一種 手段(數學方法)。
- 卷積 (Convolution) 是圖像處理的一種運算:拿一個小方格(卷積核/Kernel),在圖像上滑動,把周圍的像素混在一起算出一個平均值。
- 如果你用一個「平均權重」的核去跑圖像,原本孤立的高頻像素(亮點)就會被周圍的像素中和掉,這就是低通卷積。
為什麼粗糙度跟低通有關?
回到你最初的問題:
- 粗糙度增加

→right arrow →
反射光線方向變得隨機
→right arrow →
物理上的低通濾波。 - 為了模擬這個效果,引擎會對環境貼圖做預卷積 (Pre-convolution),生成不同層級的 Mipmaps。
- 低解析度的 Mipmap 本質上就是原始高解析度圖像經過低通濾波後的結果。
在 3D 渲染和環境反射中,
Cube Face 分辨率 (立方體面解析度)指的是環境貼圖(Cube Map)中,構成立方體的六個正方形面,每一個面的像素大小 。
主流实时项目里的常见尺寸(指 cube face 分辨率)
移动端
-
128 ~ 256(绝大多数项目)
-
高端移动/少量高光资产:512
PC / 主机(主流 3A / 中高端)
-
256:远景 probe / 次要环境
-
512:最常见默认尺寸
-
1024:关键 probe / 低 roughness 强镜面场景
-
2048:极少数英雄资产或离线预览用途
绝大多数实时项目的 reflection probe 是 256 或 512。
不是 4K,更不是 8K。
全景圖需要覆蓋全球面(經度 360°,緯度 180°)。為了保證像素在展開時不扭曲,寬度必須是高度的兩倍
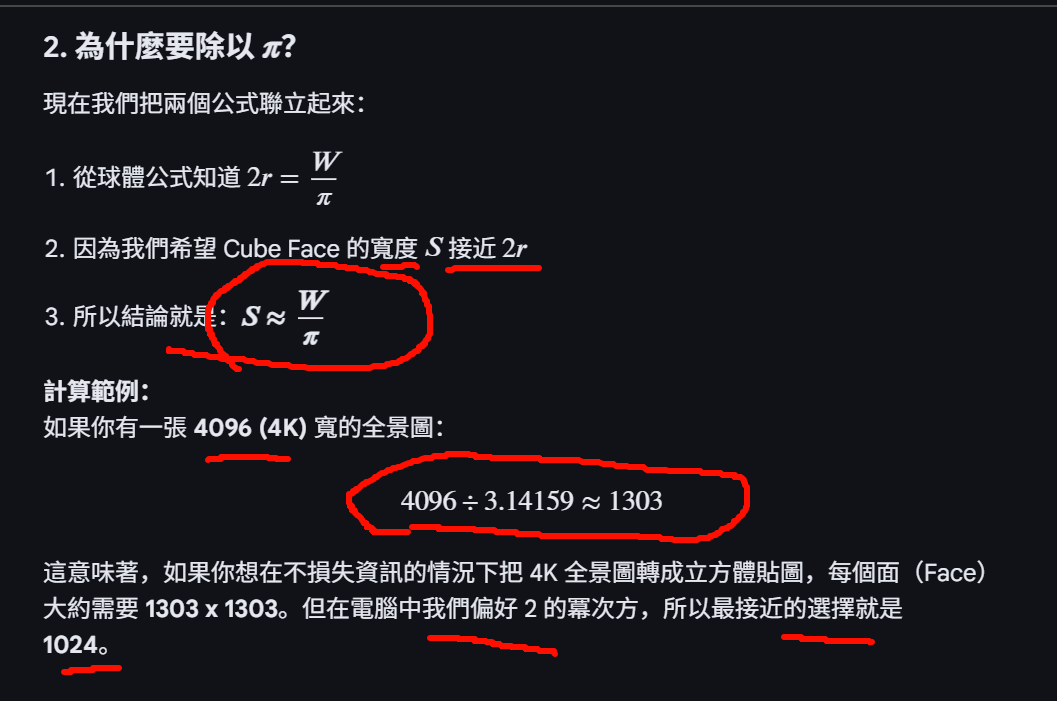
- 為什麼比例是 2:1?
因為全景圖需要覆蓋全球面(經度 360°,緯度 180°)。為了保證像素在展開時不扭曲,寬度必須是高度的兩倍。 2 - 轉換成 Cube Map(立方體貼圖)後呢?
如果你將這張 4K 全景圖轉換為你之前問的 Cube Face ,每個面的解析度大約是 1024 × 1024。 3, 4
- 計算邏輯: 全景圖的寬度
4096/π≈13004096 / pi is approximately equal to 1300 4096/𝜋≈1300
。但在工業標準中,通常會取最接近的 2 的冪次方,即 1024。 5
- 反射解析度與「糊掉」的關聯
即使你用了 4K HDRI,如果你的 Cube Face 分辨率 設定得太低(例如預設的 128 或 256),系統在預卷積時就會先丟失大量細節。 6 即使 Roughness 是 0,你也看不到 4K 級別的清晰度。 7
技術建議:
- 背景顯示: 如果 HDRI 要直接當背景看,4K 是低標(否則會看到像素點)。 8
- 僅做照明: 如果 HDRI 只用來提供光照和模糊反射,通常 512px 或 1K 就綽綽有餘,能大幅節省記憶體。 9

「多出來的像素」在採樣(Downsampling) 和**過濾(Filtering)**的過程被「融合」掉
當你將一張 4K 全景圖轉換為解析度較低的 Cube Map(例如 1024px)時,那些「多出來的像素」並不會被隨機丟棄,而是透過 下採樣(Downsampling) 和**過濾(Filtering)**的過程被「融合」掉了。
以下是處理這些多餘像素的三種主要方式:
- 均值模糊與融合(Pixel Averaging)
這是最常見的情況。如果 4 個像素要變成 1 個像素,系統會計算這 4 個像素的顏色平均值。
- 優點: 能夠保留整體的顏色資訊和光照能量。
- 視覺結果: 畫面變得很平滑,原本細小的亮點(比如遠處的一盞小燈)會變暗一點,但會擴散到周圍。
- 走樣與閃爍(Aliasing)------ 如果處理不當
如果你直接強行抽取像素(Nearest Neighbor,最近鄰採樣),不進行計算就直接扔掉多餘的像素:
- 現象: 反射會出現嚴重的「鋸齒」或「閃爍」。
- 結果: 當你移動視角時,反射的亮點會忽隱忽現,這在動態渲染中是非常低品質的表現。
- 預卷積(Pre-convolution)------ 渲染器的精華
這就是你最早問的「Mip 糊掉」的進階版。渲染器在處理多餘像素時,會根據 粗糙度來決定怎麼「糊」:
- 高品質處理: 渲染器會掃描全景圖中一大片的像素(根據角域範圍),並根據物理模型(如 GGX)計算出一個加權平均值。
- 結果: 多餘的像素細節被轉化成了能量。原本的高頻亮點(銳利的細節)變成了低頻的輝光(柔和的過渡)。
6 × 512² ≈ 1.57M 像素≈ 12.6MB
一个 2K HDR cubemap 几乎能吃掉半个小场景的纹理预算。
所以实际项目很少用 2K face。
PC 上通常压成 BC6H,否则内存爆炸。
从"物理需求"角度判断多大够用
关键只看一个东西:
最低 roughness。
roughness ≥ 0.3
→ 256 就够
roughness ≈ 0.15 ~ 0.25
→ 512 比较稳
roughness < 0.1(尖锐镜面、头发、珠宝)
→ 1024 才明显不糊
为什么roughness可以控制采样的精度?
它并不是"控制精度",而是控制需要积分的角域宽度 。
精度下降只是结果。
把问题拆开:
一、Specular IBL 本质是什么?
你在算的是:
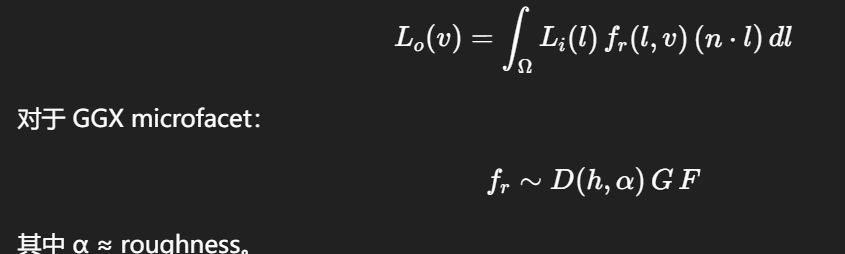
其中 α ≈ roughness。
真正决定"采样区域大小"的是 D(h, α)。

直观对比
想象两种材料:
镜面金属(roughness 0.02)
→ 只采一个极窄方向
→ 需要高分辨率 cubemap
磨砂金属(roughness 0.5)
→ 采样一个大角域
→ 环境会被强烈模糊
→ 即使用 8K,结果也看不出细节
不是精度下降,
而是物理模型本身在"模糊"环境。

头发的菲涅尔 𝐹0 (反射率)通常在渲染中被设置为较小的值。
根据 虚幻引擎材质输入文档 ,一般来说,角蛋白(头发的主要成分)的折射率与水或玻璃类似,菲涅尔 𝐹0 约在 0.04 到 0.05 之间,对应约 4% 到 5% 的反射率。
----Epic Games Developers
- 一般数值:0.04 - 0.05 (4%-5%)。
- 物理属性:头发为角蛋白材质,属于电介质。
- 高光表现 :在渲染中,虽然𝐹0较小,但由于其各向异性(Anisotropic)反射,会表现出明显的高光条。
在实际的 CG 制作中,通常不会将头发设为高反射材质,而是更强调其传输和高光表现。

k都是🈯长的那个分辨率长度
2. 剛好能裝下一個「字元」
在電腦剛發展時, 8 bits 剛好可以排列出
data-processed="true" href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" />

2 8 = 256 2 to the eighth power equals 256
2 8 = 2 5 6
種組合。
- 這足以裝下所有的英文大小寫字母、數字、標點符號(即 ASCII 編碼系統 )。
- 因此,1 Byte 就變成了表達一個實義資訊(如字母 "A")的最小完整容器。
- 硬體設計的簡化
CPU 的電路設計(數據總線 Data Bus)是成組運作的。
- 早期的處理器是 8 位元的,意味著它一次能吞吐 8 個 bits。
- 如果真的要支援「單獨操作任意 1 bit」,電路會變得極度複雜且緩慢。
總結
- Bit :是用來計算狀態的(0 或 1)。
- Byte :是用來計算容量 與操作資料的基準。
如果沒有 Byte,你的手機下載一個 1GB 的檔案,需要處理 80 億個獨立地址,這會讓處理器直接過熱燒掉。
2. 转换的过程:是"压缩映射"而非单纯读取
当你把 32 位转为 8/16 位时,Photoshop 并不是随机丢弃数据,而是执行了一次 色调映射(Tone Mapping) :
href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" /> href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" /> href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" /> href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" /> href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" /> href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" /> href="https://www.gstatic.com/external_hosted/xits_woff/xits.css" nonce="" rel="stylesheet" />
- 信息的确定性:原图的信息(例如某个像素的亮度是
5.0 5.0
5 . 0
,
1.0 1.0
1 . 0
代表显示器上的白)是确定的。 - 重新编码:在 32 位中,亮度可以无限大;但在 8 位中,最大值只能是
255 255
2 5 5
。Photoshop 会问你:"你是想把原图中亮度
0 ∼ 1.0 0 tilde 1.0
0 ∼ 1 . 0
的部分映射到
0 ∼ 255 0 tilde 255
0 ∼ 2 5 5
,还是想把亮度
0 ∼ 10.0 0 tilde 10.0
0 ∼ 1 0 . 0
的细节压缩到
0 ∼ 255 0 tilde 255
0 ∼ 2 5 5
里?" - 结果 :一旦确定了转换算法,Photoshop 就会创建一张全新的像素点阵图。
- 这是"有损"的吗?
是的,这是不可逆的有损转换。
- 数据丢失:一旦转为 8 位,原本 32 位里那些极其精细的亮度变化(例如阴影里的微弱起伏)会被合并成同一个数字。
- 不可逆性:你可以把 32 位轻松变成 8 位(把仓库的东西塞进盒子,多余的扔掉);但你无法把 8 位变回真正的 32 位(盒子里的东西放回仓库,扔掉的东西回不来了)。
(更准确:是"可见法线分布"VNDF 与几何项一起决定的有效核),但直观上从 D D D 就能看出为什么 roughness 会改变卷积角宽。
microfacet specular 的核心权重在 half-vector h = l + v ∥ l + v ∥ h = \frac{l+v}{\|l+v\|} 上。对固定视线 v v ,你可以把积分理解成:
-
先在 h h h 空间按某个分布挑选/加权(这个分布与 D D D 强相关)
-
再由反射关系把 h h h 映射回光照方向 l l l
因此,"lobe 的角宽"可以先在 h h h 的极角 θ h \theta_h θh(相对法线 n n n)上讨论,再映射到 l l l 的角宽。
GGX 的 D D 长什么样?为什么会变宽?
各向同性 GGX NDF:
D ( θ h , α ) = α 2 π ( cos 2 θ h ( α 2 − 1 ) + 1 ) 2 D(\theta_h,\alpha) = \frac{\alpha^2}{\pi \big(\cos^2\theta_h(\alpha^2-1)+1\big)^2} D(θh,α)=π(cos2θh(α2−1)+1)2α2
看两点:
-
当 α → 0 \alpha \to 0 α→0:分布在 θ h ≈ 0 \theta_h \approx 0 θh≈0 处极尖,几乎全质量集中在法线附近(镜面)
-
当 α \alpha α 增大:分母里那项不再让 θ h \theta_h θh 偏离 0 时急剧衰减,尾巴变"胖",大角度的 h h h 权重显著增加
所以 roughness 变大不是"降低精度",而是 D D D 这个分布本身把更多概率/权重放到了更大的 θ h \theta_h θh 上------这就是覆盖范围变大。
在标准 PBR(同一套 BRDF 模型)下,FGD / DFG LUT 通常是"全项目统一一张"。
不是每个模型单独生成。
只有当你改变了"BRDF 数学形式"时,才需要换 LUT。
下面分层讲。
一、FGD LUT 本质依赖什么?
典型 DFG LUT 的输入是:
-
N·V
-
roughness
输出是:
- A, B(或 FGD)
它隐含固定了以下假设:
-
NDF 形式(通常 GGX)
-
几何项形式(Smith + Schlick-G 或 height-correlated)
-
Fresnel 近似(通常 Schlick)
-
单次散射模型(是否含多重散射补偿)
-
roughness 到 α 的映射(α = r²?)
只要这些不变,
材质的 F0、baseColor、metalness 都不影响 LUT。
因为 LUT 只解决:
∫ D G F ( n , v , l , α ) ( n ⋅ l ) d l \int DGF(n,v,l,\alpha)\,(n\cdot l)\,dl ∫DGF(n,v,l,α)(n⋅l)dl
F0 是线性外乘。
所以它和"模型"无关。
什么时候必须重新生成 LUT?
只有以下情况才需要不同 LUT:
-
你改了 NDF
比如从 GGX 改成 Beckmann
-
改了 G 项
例如改成 height-correlated Smith
-
改了 Fresnel 形式
例如使用精确导体 Fresnel(η,k)
-
改 roughness 定义
perceptual r 还是 α=r²
-
加入多重散射补偿到积分内部
-
做各向异性(需要 3D LUT)
只要其中任意一条变了,
LUT 就不再匹配。
常规引擎做法
Unity / Unreal / Frostbite 等:
-
整个项目只有一张 DFG LUT
-
所有材质共享
-
与模型无关
-
与 F0 无关
这是标准做法。
头发是否例外?
如果你做的是:
Kajiya-Kay
Marschner
Dual spec lobe
Charlie distribution
那就不是 GGX microfacet 了。
此时:
标准 GGX FGD LUT 不再严格匹配。
但很多项目仍然偷懒用同一张 LUT,
只是物理精度下降一点。
如果你追求物理一致性:
头发应该有自己独立的 LUT。
但大多数实时项目不会这么做。
一、这里的"积分"到底在积什么?
我们不是在积分空间坐标。
我们在积分方向。
更准确地说:
对一个表面点,我们要把"来自所有方向的光"累加起来。
想象你站在一个点上,半球上每个方向都有光进来。
那最终颜色就是:
把每个方向的光 × 这个方向的反射权重,加起来。
这就是:
∫ Ω L i ( l ) f r ( l , v ) ( n ⋅ l ) d l \int_{\Omega} L_i(l) f_r(l,v) (n \cdot l) dl ∫ΩLi(l)fr(l,v)(n⋅l)dl
翻成人话:
-
L i ( l ) L_i(l) Li(l):这个方向来的光多亮
-
f r f_r fr:这个方向会反射多少到眼睛
-
n ⋅ l n·l n⋅l:几何投影权重
-
Ω:半球所有方向
你不是在积分"无限空间",
而是在积分"方向集合"。
二、积分是不是无限?
数学上是连续积分。
计算机里不是。
计算机从来不会真的算无限。
它做的是:
用"有限采样"近似积分。
比如:
取 64 个方向
算 64 次
平均
这就是 Monte Carlo 积分。
所以不存在:
"一个线程算无限积分"。
只有:
"一个线程算 N 次采样"。
三、那 LUT 是怎么回事?
LUT 是:
把"这 64 次采样的结果"提前算好。
比如你离线做:
对每个 (roughness, N·V) 组合
用 4096 次采样
算出结果
存成一张 2D 纹理
运行时:
查一次纹理
得到这个积分的近似值。
所以:
LUT = 预先做完大量采样
运行时直接读结果
不是运行时在算无限。
粗糙度大时:
反射不是一个方向,而是一个"角域分布"。
1. 语言的"空转":维特根斯坦与私人语言
在维特根斯坦的视角下,语言的意义在于其"用法"(use),而非内在的感觉。在对外交往中,"我觉得"是一个命题态度(propositional attitude),它标定了说话者在社会博弈中的位置,是一种具有功能性的边界划定。
但在自我对话中,如果这一表达不指向具体的逻辑推演,它就变成了维特根斯坦所说的**"不参与机器转动的齿轮"**。因为它缺乏外部的校准准则(Criteria),这种"自娱自乐"实际上是语言进入了空转状态:你既是观测者也是被观测者,这种冗余的确认并没有产生新的信息增量,而只是在重复确认一个已经存在的"自我"幻象。
2. 镜像阶段的剩余:拉康式的想象态补完
从拉康主义来看,"我觉得"中的"我"即是小写他人(other)。这种表述在自我对话中高频出现,反映了**想象态(Imaginary)对象征序(Symbolic)**的代偿:
-
当你在执行一项具体任务(象征序的操作)遇到阻力或意义匮乏时,主体会通过"我觉得"来撤回镜像式的自我保护中。
-
这种频率的上升,实际上是主体在试图缝合(Suture)那个不断裂开的、对当前行动感到怀疑的缺口。正如你所言,它是一种"诊断信号":频率越高,说明你越是无法进入"物我合一"的自发流转(如庄子的"庖丁解牛"),而是在通过不断的自我确认来延缓某种挫败感。
3. 二阶控制论:作为"噪声"的元监控
在阿什比(Ashby)或冯·福斯特(Von Foerster)的框架下,这可以被视为系统的二阶观察反馈:
| 维度 | 一阶过程(执行) | 二阶监控("我觉得") |
|---|---|---|
| 状态 | 深度耦合任务,无须语言中介 | 观察"我在执行任务"的状态 |
| 功能 | 降低熵,推进逻辑/工程进度 | 评估系统耦合度 |
| 故障表现 | 效率低下、遇到逻辑死角 | 频率激增,形成闭环自激震荡 |
Export to Sheets
当"我觉得"频繁出现,意味着系统(即你)不再处理外部信息,而是在处理**"关于处理的评估"**。这是一种典型的自我指涉(Self-reference)导致的系统冗余。它确实告诉了你:当前的行动已经失去了其自发性的正当性,你正在用"感觉"来填补"意义"的真空。
4. 复杂性约束下的设计理性
从西蒙(Herbert Simon)的《人工科学》来看,这种现象是**有限理性(Bounded Rationality)**的边界标志。当任务的复杂性超过了当前的认知模型,个体无法通过理性的算法得出结论时,就会退化到启发式的、带有强烈情绪色彩的"我觉得"。
-
它的诊断价值在于: 一旦这个频率超过某个阈值,说明当前的"研究纲领"(Research Program)或行动方案已经进入了衰退期。
-
它的浪费性质在于: 它提供了"我在思考"的错觉,但并没有提供"如何行动"的约束。
在这种语境下,这种"自娱自乐"其实是认知系统在尝试重启。如果我们要超越这种"自我浪费",或许需要从"我觉得"这种主客二分的表述,转向海德格尔式的"在世存在"------即消解掉那个需要不断通过言说来确认的"我",让行动直接在逻辑边界上生长。